CLIP论文笔记
CLIP
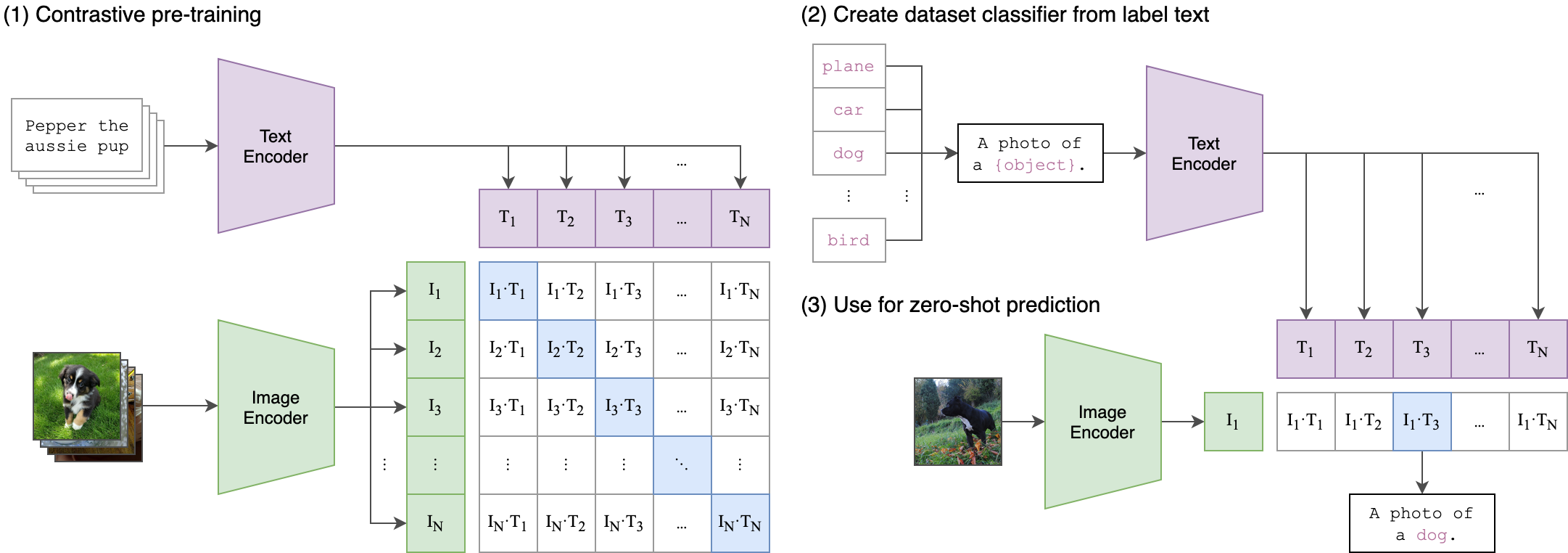
一、论文基本信息
- 标题:"Learning Transferable Visual Models From Natural Language Supervision"
- 作者:Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
- 发表年份:2021
- 发表期刊 / 会议:International Conference on Machine Learning (ICML)
- 论文链接:https://arxiv.org/pdf/2103.00020
- 仓库地址:openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image (github.com)
二、摘要
-
研究目的
- 探索直接从自然语言监督中学习可迁移的视觉模型,以克服传统计算机视觉模型在监督形式上的局限,提高模型通用性和适用性。
-
方法概述
- 通过对比学习预测图像与文本的正确配对,使用大量(图像,文本)对数据进行预训练。预训练后利用自然语言引用学习到的视觉概念,实现模型到下游任务的零样本迁移。
-
主要结果
- 在 30 多个不同的计算机视觉数据集上进行基准测试,模型在多数任务上有非平凡的迁移能力,在零样本设置下常与完全监督的基线模型竞争,如在 ImageNet 上匹配 ResNet - 50 的零样本准确率。
-
结论与意义
- 证明了从自然语言监督学习通用视觉表示的可行性,为计算机视觉研究提供新方法,推动跨模态学习和多模态应用发展。
三、引言
-
研究背景
- 预训练方法在 NLP 领域取得成功,但计算机视觉领域仍依赖于在有标注数据集上预训练模型。自然语言作为监督信号具有优势,其通用性可表达更广泛视觉概念,且能实现灵活的零样本迁移。
-
研究问题提出
- 能否通过直接从网络文本学习的可扩展预训练方法在计算机视觉领域取得突破,利用自然语言监督学习通用视觉模型并实现零样本迁移。
-
研究目的和意义
- 目的是开发一种从自然语言监督中学习视觉模型的方法,提高模型通用性和可迁移性。意义在于减少对特定任务标注数据的依赖,推动计算机视觉向更智能方向发展,为多模态应用奠定基础。
四、相关工作
-
前人研究综述
- 回顾了利用自然语言监督学习视觉表示的相关工作,包括早期通过预测文本中的名词和形容词、流形学习、训练多模态深度玻尔兹曼机等方法,以及近期基于 Transformer 的语言建模、掩码语言建模和对比目标的研究。
- 介绍了从自然语言监督学习视觉表示的不同方法,如将视觉特征与语言模型结合的多模态输入和两阶段微调等操作。
-
现有研究的优点与不足
- 优点:一些方法展示了从自然语言监督学习视觉表示的潜力,预训练语言模型在 NLP 领域取得成功为视觉领域提供借鉴。
- 不足:现有方法存在局限性,如监督范围有限、使用静态 softmax 分类器缺乏动态输出、模型规模和数据量相对较小等。
-
与本研究的关系
- 本研究在此基础上,通过创建大规模数据集和选择高效预训练方法,进一步探索从自然语言监督中学习可迁移视觉模型,克服现有研究的不足。
五、方法
-
模型架构
- 图像编码器:考虑 ResNet - 50 和 Vision Transformer 两种架构,对 ResNet 进行了改进,如使用 ResNetD 改进和抗锯齿池化,替换全局平均池化层为注意力池化机制;Vision Transformer 则紧密遵循其原始实现并做了少量修改。
- 文本编码器:采用基于 Transformer 的架构,基于 Radford 等人描述的架构修改,使用特定参数设置,如 63M 参数、12 层、512 宽模型,8 个注意力头,对文本进行编码操作。
-
训练数据
- 创建了一个包含 4 亿(图像,文本)对的大规模数据集 WIT,通过搜索包含特定查询词的图像 - 文本对,并平衡每个查询的样本数量来构建,以覆盖广泛视觉概念。
-
对比学习目标
- 给定一批 N(图像,文本)对,训练模型预测实际发生的配对。通过联合训练图像编码器和文本编码器,最大化真实对的图像和文本嵌入的余弦相似度,同时最小化错误配对的相似度,优化对称交叉熵损失。
-
训练过程
- 训练一系列 5 个 ResNets 和 3 个 Vision Transformers,共 32 个 epoch。使用 Adam 优化器,应用解耦权重衰减正则化,学习率采用余弦调度策略。采用混合精度训练、梯度检查点、半精度 Adam 统计和半精度随机舍入文本编码器权重等技术加速训练和节省内存,使用大的小批量大小 32,768。
六、实验
-
实验设置
- 数据集:使用超过 30 个现有计算机视觉数据集,包括 ImageNet、MS - COCO、Visual Genome、YFCC100M 等,涵盖图像分类、目标检测、OCR、动作识别、地理定位等多种任务。
- 对比方法:与多种现有方法对比,包括基于手工特征和机器学习算法的传统方法、基于深度学习的方法以及其他基于自然语言监督的方法。
- 评价指标:采用准确率、召回率、F1 值、零样本分类准确率等常用指标,在不同任务和数据集上评估模型性能。
-
主要结果
-
零样本迁移
- 在 ImageNet 上,CLIP 模型将零样本准确率从之前的 11.5% 提高到 76.2%,匹配 ResNet - 50 性能。通过提示工程和集成多个零样本分类器,在多个数据集上平均提高准确率近 5%。
- 与其他零样本方法对比,CLIP 在不同任务上表现各异,在一些任务上匹配或超过现有方法,在一些复杂任务上表现较弱,但在数据效率上有优势,其零样本转移能力与模型底层表示质量有关。
-
表示学习
- 通过线性分类器评估模型表示学习能力,在不同数据集上与现有模型对比。小的 CLIP 模型在某些数据集上优于部分 ResNet 模型,但不如一些基于 ImageNet - 21K 训练的模型和 EfficientNet 家族模型。然而,CLIP 模型的扩展性好,最大模型在某些指标上超过现有最佳模型。
- CLIP 模型学习到更广泛任务,包括地理定位、OCR、面部情感识别和动作识别等,在一些任务上对现有模型有较大改进,体现了自然语言监督的优势。
-
对自然分布转移的鲁棒性
- 与在 ImageNet 上训练的模型相比,CLIP 模型在自然分布转移数据集上的有效鲁棒性有很大提高,能减少 ImageNet 准确率和分布转移下准确率之间的差距。
- 通过将 CLIP 适应到 ImageNet 分布,发现虽然 ImageNet 准确率提高,但分布转移下的平均鲁棒性略有下降,不同的零样本到完全监督的过程中,有效鲁棒性逐渐降低。
-
-
结果分析
- CLIP 在不同任务和数据集上的性能表现得益于其独特的模型架构、训练方法和数据利用方式。
- 对比学习目标和大规模数据集的使用提高了模型的泛化能力和表示学习能力,提示工程和集成方法进一步提升了零样本迁移性能。
- 模型在复杂任务和分布转移情况下的表现揭示了其优势和局限性,为未来研究提供方向。
七、结论
-
研究成果总结
- 成功提出 CLIP 模型,通过自然语言监督的对比学习实现高效跨模态学习和通用视觉表示学习。
- 在多个计算机视觉任务上取得卓越性能,尤其在零样本学习方面表现出色,展示强大迁移学习能力和泛化性能。
- 证明大规模自然语言监督数据在视觉模型学习中的有效性,为计算机视觉领域开辟新方向。
-
研究的局限性
- 对数据依赖性强,数据质量和多样性影响模型性能,对一些特殊领域或小众数据集可能需进一步优化。
- 计算资源需求大,大规模模型训练和数据处理需要大量计算资源,限制部分研究机构和开发者应用。
- 模型具有黑盒性质,缺乏对图像和文本语义关联学习及决策过程的明确解释和可解释性。
-
未来研究方向
- 进一步探索更有效的跨模态学习方法和架构,提高模型性能和效率。
- 研究如何更好利用自然语言监督数据,包括筛选、增强和优化,以提高模型泛化能力和适应性。
- 加强对模型可解释性的研究,开发可视化和解释性工具,帮助理解模型决策过程和内部机制。
- 拓展 CLIP 应用领域,如医疗影像、自动驾驶、智能机器人等,探索在实际场景中的可行性和有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号