Hadoop3.1.3最小化分布式部署方案
一、部署机器配置
物理机:
CPU:Intel i5-3337U @1.8GHz 双核四线程(10年前的老机器,可以说是强开了)
内存:8 GB
磁盘:240 GB SSD
VMware开三台乞丐版虚拟机,单台虚拟机配置如下:
CPU:1 core
内存:1 GB
硬盘:30 GB
操作系统:CentOS 7.5 最小化安装(图形化怕是跑不起来)
二、部署方案
机器一:NameNode + DataNode
机器二:ResourceManager + DataNode
机器三:DataNode + SecondaryNameNode
原因:NameNode管理元数据,SecondaryNameNode定期获取NameNode编辑日志,并更新到fsimage上,再拷贝回NameNode,减轻了NameNode节点工作压力。
ResourceManager作为资源管理节点,主要是跑Yarn,也需要独立资源。
三、部署过程
1、单机安装Linux操作系统、JAVA、HADOOP,修改环境变量JAVA_HOME、HADOOP_HOME等
2、关闭防火墙、配置节点间无密登录,编写节点同步脚本(rsync),修改HADOOP配置文件、IP地址映射
3、节点间拷贝、配置文件分发
4、起集群
①格式化NameNode
hdfs namenode -format
②机器一上启动start-dfs.sh,机器二启动start-yarn.sh,不然yarn也挂在机器一上了,负担甚重。
常用端口信息(Hadoop3.x vs Hadoop2.x):

四、路径说明
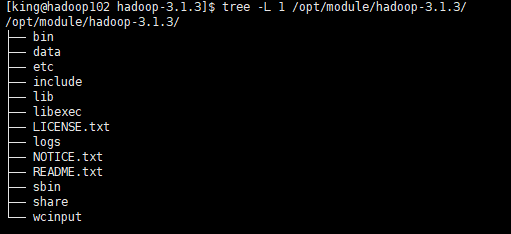
/bin Hadoop服务脚本
/data 节点相关信息
/etc 配置文件目录
/include 头文件目录
/lib 本地库
/libexec 一些函数库、执行文件及连接文件
/logs 日志
/sbin 启停Hadoop脚本
/share 依赖jar包、示例程序、文档
附:个性化配置信息
core-site.xml
<configuration>
<!-- NameNode addr -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- Save dir -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>king</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
mapred-site.xml
yarn.nodemanager.vmem-pmem-ratio是我自己设的,因为我每台虚机就分配了1G内存,实际发现跑多个WordCount程序就出现内存不足。
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
<!-- 指定虚拟内存virtual memory与物理内存physical memory比例,如果物理内存较小可以设大一些-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3.0</value>
</property>
</configuration>
yarn-site.xml
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
workers(前提是在/etc/hosts中配置好ip地址映射)(Hadoop2.x里叫slaves)
hadoop102
hadoop103
hadoop104
小结:总的来说,Hadoop部署还是非常简单的,关键是细心,弄明白每一项配置项是干什么的。我这个可以说是低配机器专属配置方案了- -|,等玩转了,打算自己家里部个集群,美滋滋~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号