

分布式笔记
一、分布式全局ID
数据库表,每张表都会有一个唯一标识,通常都使用id。id通常都使用自增的方式,在分库分表的情况下,就会产生不同分片上的id重复的问题,导致id在全局不唯一,业务上就可能会出现问题。为了使分布式系统下,id能够全局唯一,下面介绍几种实现方案。
1、使用UUID作为全局主键
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写。使用UUID是可以保证每条记录的id都是不同的。但它的缺点是UUID是长度为32位的字母数字组成的字符串,太长,并且没有啥实际意义。
分布式数据库中间件中MyCat不支持UUID方式,Sharding-Jdbc支持UUID,配置如下:
spring.shardingsphere.sharding.tables.t_order.key-generator.column=id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=UUID
2、统一id序列生成器
id的值统一从一个集中的id的序列生成器中获取。这种方式,MyCat支持,Sharding-Jdbc不支持。
MyCat支持中有两种实现方式:本地文件方式 和 数据库方式。本地文件方式的方式,当MyCat重启时,id的取值又会从头开始取,而数据库方式就解决了这个问题。
- 优点:ID集中管理,避免重复
- 缺点:并发量大时,id生成器压力较大
MyCat中通过配置实现统一id序列生成器
server.xml配置文件:

sequnceHandlerTyper属性配置:
- 0:本地文件方式生成唯一id
- 1:数据库方式生成唯一id
- 2:通过雪花算法生成唯一id
本地文件方式
对应的配置文件sequence_conf.properties
# T_ORDER表示表的名字,HISIDS 表示使用过的历史分段(一般无特殊需要可不配置),MINID 表示最小 ID 值,MAXID 表示最大ID 值,CURID 表示当前 ID 值。
T_ORDER.HISIDS=
T_ORDER.MINID=1001
T_ORDER.MAXID=1000000000
T_ORDER.CURID=1000
sql插入语句:
insert into order(id,name) values(next value for MYCATSEQ_T_ORDER,'test');
数据库方式
在数据库中建立一张表,存放 sequence 名称(name),sequence 当前值(current_value),步长(increment)等信息。
建表语句在/conf目录下 dbseq.sql文件中,首次使用前要到数据库执行下,然后在表中插入自己业务表对应的配置,例如:
INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES ('ORDER', 100000, 1);
数据库方式的配置文件 sequence_db_conf.properties:
# 指定 sequence 相关配置在哪个节点上
ORDER=dn1
3、雪花算法(SnowFlake)
SnowFlake是由Twitter提出的分布式id算法。它的结果是一个64bit大小的long型整数。

- 第1位固定0,表示正数;
- 41位时间戳,用来记录时间戳,毫秒级。转换成年,可以使用69年;
- 5位机房(workerId)+5位机器(datacenterId),统称为工作机器id,2的10次方等于1024,即可以记录部署1024个节点;
- 12位序列号,用来记录同毫秒内产生的不同id。可以记录同一机器同一时间截(毫秒)内产生的4096个ID序号。
雪花算法生成的id按时间趋势递增,所以理论上当时间回调时,可能会引起id重复。
MyCat和Sharding-Jdbc均支持雪花算法。
mycat下配置
server.xml配置文件:
<property name="sequnceHandlerType">2</property>
sequence_time_conf.properties文件配置:
# 多个mycat节点下每个mycat配置的WORKID,DATAACENTERID不同,组成唯一标识,总共支持32*32=1024 种组合
WORKID=10 # 0-31 任意整数
DATAACENTERID=01 # 0-31 任意整数
Sharding-Jdbc下配置
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=345
spring.shardingsphere.sharding.tables.t_order.key-generator.props.max.tolerate.time.difference.milliseconds=10 # 最大容忍的回调时间
二、分布式事务和数据一致性方案
单体应用中一般只使用一台数据库,这时要实现事务是比较容易的,但在分布式项目中,一个方法里有时会操作多个数据库,那么此时要如何保证ACID呢?
基于XA协议的两阶段提交
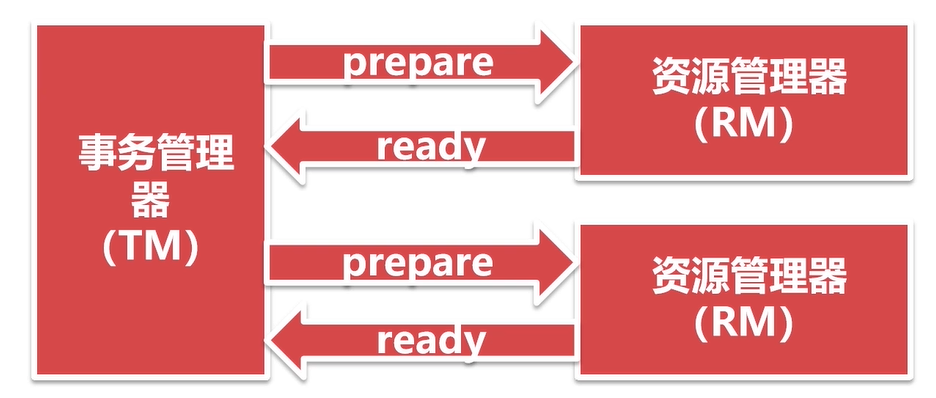
XA是由X/Open组织提出的分布式事务的规范。由一个事务管理器(TM)和多个资源管理器(RM)组成。提交分为两个阶段:prepare 和 commit,准备阶段和提交阶段,提交之前要让所有的数据库先进行准备,都准备好后由事务管理器统一发出commit指令。
第一阶段:
第二阶段:
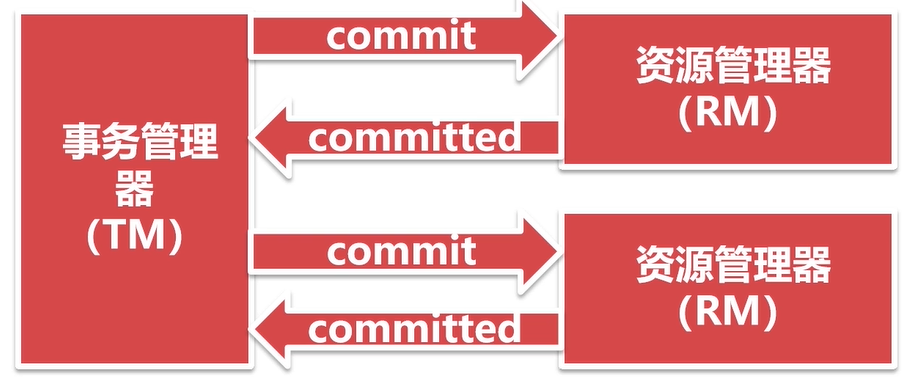
特点:
- 保证数据的强一致性;
- commit阶段如果出现问题,事务出现不一致,可能需要人工处理;
- 效率低下,性能与本地事务相差10倍。
Mysql 5.7 及以上版本均支持XA协议,Mysql Connector/J 5.0 以上支持XA协议。Java系统中,数据源采用Atomikos。
MyCat和Sharding-Jdbc均已实现分布式事务
MyCat server.xml配置文件中:
<!--分布式事务开关,0 为开启分布式事务,1 为不开启分布式事务,2 为开启分布式事务但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
MyCat和Sharding-Jdbc分布式事务都是默认开启的。
事务补偿机制
事务补偿机制就是,针对每一个操作,都注册一个与其对应的补偿(撤销)操作,在执行失败时,调用补偿操作来撤销之前的操作。
例如A给B转账200元,整个事务由A账户减200和B账户加200组成。如果过程中出现异常,那么我们的补偿机制就是给A加上200元:
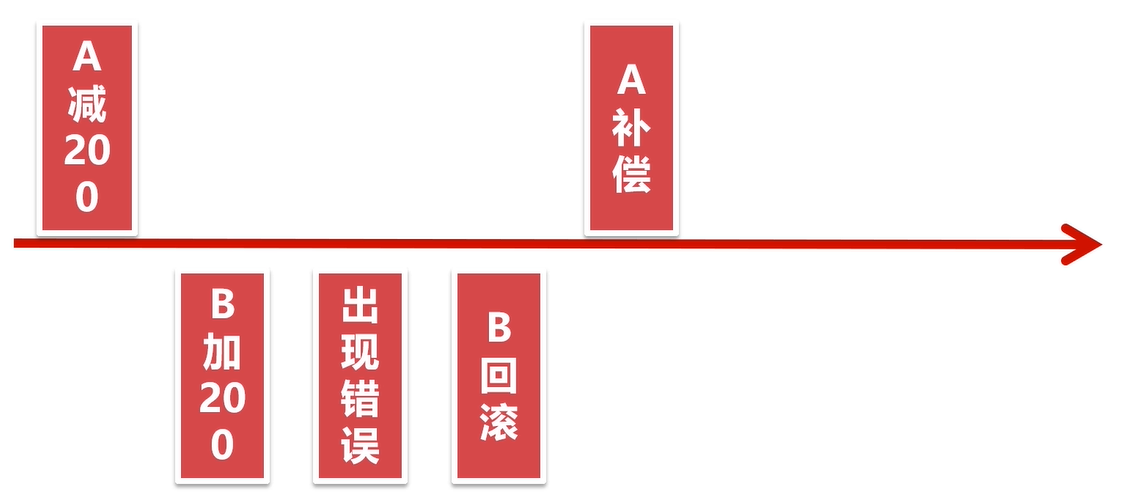
机制特点:
- 逻辑清晰,流程简单;
- 数据一致性比XA还要差,可能出错的点比较多;
- 属于应用层的一种补偿方式,程序员要写大量代码。
基于本地消息表+定时任务的最终一致性方案
将本是屋外的操作,记录在消息表中。其他事务提供操作接口,定时任务轮询本地消息表,将未执行的消息发送给操作接口。操作接口处理成功,返回成功标识,处理失败返回失败标识。定时任务街道标识,更新消息的状态,定时任务可以按照一定的周期反复执行。对于屡次失败的消息,可以设置最大失败次数,超过最大次数失败的消息,不在进行接口的调用,等待人工处理。
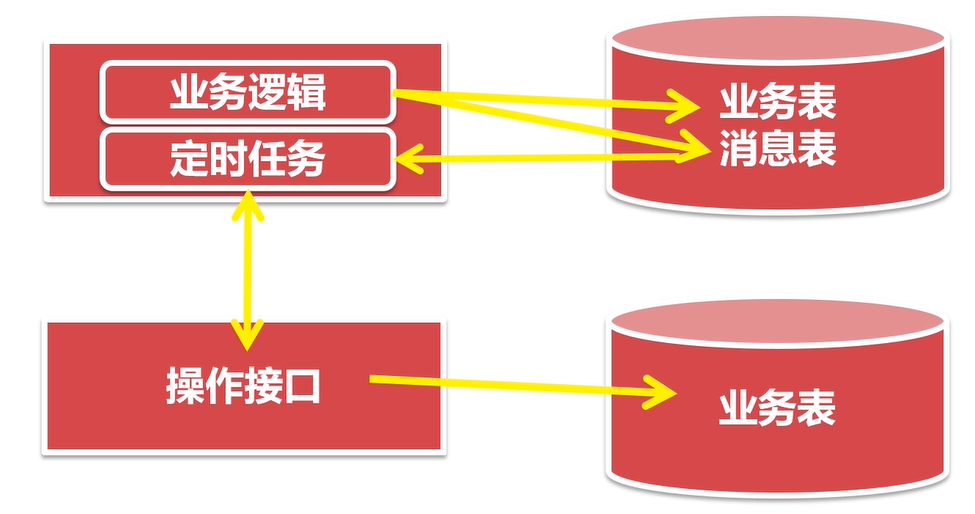
以电商系统商品下单为例:
这个过程涉及两个系统,一个是电商系统,一个是支付宝系统,电商系统下订单时,订单表中该条订单数据状态是“未支付”,然后用户使用支付宝付款,支付宝系统中会有一张消息表,记录该笔交易的信息,其中有一个消息状态的字段,此时是消息“未发送”状态。用户付款成功,支付宝会回调电商系统的接口,将订单表中的“未支付”状态改成“已支付”,修改成功后该回调接口返回一个success给支付宝系统,然后支付宝系统会将消息表中的“未发送”状态改为“发送成功”。这个回调过程中如果回调接口没有回调成功,支付宝系统会使用定时任务继续尝试回调,尝试了10次都没成功,那么将放弃尝试,并将消息表的发送状态改为“发送失败”。此时用户已经付款了,但是电商系统中的订单支付状态还是未支付,这时就需要电商客服人工介入处理了。
以上这个例子就是基于本地消息表+定时任务实现的最终一致性方案,它避免了分布式的事务,并最终实现了数据一致性。
基于MQ消息队列的最终一致性方案
这个方案的原理、流程与本地消息表方案类似,不同点是本地消息表改为了MQ,定时任务改为了MQ的消费者。
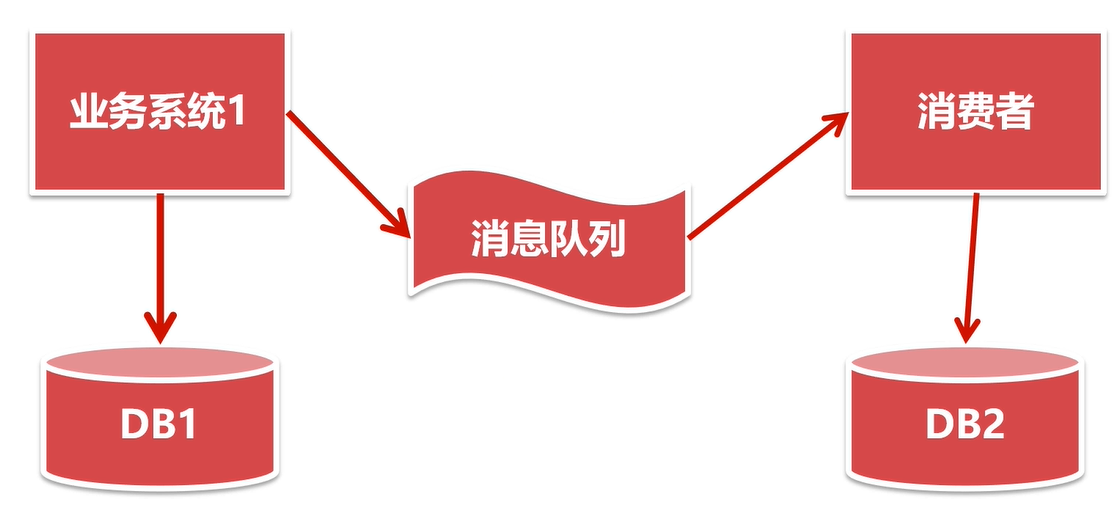
特点:
- 不依赖定时任务,基于MQ更高效可靠;
- 适合于一个公司内部的不同系统;
- 不同公司之间的系统无法基于MQ,使用本地消息表更合适。
数据一致性
CAP原理
在分布式系统中,我们经常听到CAP原理,
- C - Consistent(一致性)具体是指,操作成功以后,所有的节点,在同一时间,看到的数据都是完全一致的。所以,一致性,说的就是数据一致性。
- A - Availability(可用性)指服务一致可用,在规定的时间内完成响应。
- P - Partition tolerance(分区容错性)指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供服务。
CAP原理指出,这3个指标不能同时满足,最多只能满足其中的两个。
分布式系统的话P是必须满足的。那么A和C当中,要满足数据一致性,那么不同节点数据同步的过程中,就需要阻塞,这样可用性就无法保证了。如果要满足可用性,那么就需要同步非阻塞,这样不同节点之间的数据某一时刻可能就不一致。所以分布式系统只能是AP或者CP。
ACID
在关系型数据库中,最大的特点就是事务处理,也就是ACID。ACID是事务处理的4个特性。
- A - Atomicity(原子性)事务中的操作要么都做,要么都不做。
- C - Consistency(一致性),系统必须始终处在强一致状态下。
- I - Isolation(隔离性),一个事务的执行不能被其他事务所干扰。
- D - Durability(持久性),一个已提交的事务对数据库中数据的改变是永久性的。
ACID强调的是强一致性,要么全做,要么全不做,所有的用户看到的都是一致的数据。传统的数据库都有ACID特性,它们在CAP原理中,保证的是CA。但是在分布式系统大行其道的今天,满足CA特性的系统很难生存下去。ACID也逐渐的向BASE转换。
BASE
BASE是Basically Available(基本可用), Soft-state(软状态), Eventually consistent(最终一致)的缩写。
- 基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。 - 软状态(Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有两到三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。 - 最终一致性(Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
BASE模型是传统ACID模型的反面,不同与ACID,BASE强调牺牲高一致性,从而获得可用性,数据允许在一段时间内的不一致,只要保证最终一致就可以了。
在分布式事务的解决方案中,它们都是依赖了ACID或者BASE的模型而实现的。像基于XA协议的两阶段提交和实物补偿机制就是基于ACID实现的。而基于本地消息表和基于MQ的最终一致方案都是通过BASE原理实现的。
三、分布式接口幂等性
什么是幂等性?
f(f(x)) = f(x)
幂等元素运行多次,还等于它原来的运行结果。
在系统中,一个接口运行多次,与运行一次的效果是一致的,这就是接口的幂等性。
什么情况下需要幂等性?
重复提交、接口重试、前端抖动等,这些情况下需要进行幂等性设计。
例如:
用户同一时刻多次点击下单,后台应该只给他生成一个订单。
支付时,由于网络问题导致重发,此时应该只扣一次钱。
并不是所有接口都需要满足幂等性,要根据业务而定。
如何实现幂等性?
核心思想:通过唯一的业务单号保证幂等。
- 非并发情况下,查询业务单号有没有操作过,没有才执行操作。
- 并发情况下,整个操作过程加锁。
select操作
不会对业务数据有影响,天然幂等。
delete操作
根据唯一业务单号删除数据的话,第一次已经删除了数据,后再来删除也不会有影响。
如果是根据其他字段删除数据的话,需要根据业务而定。例如删除所有未支付的订单,第一次已经将所有未支付的订单删除了,此时又有新的未支付订单入库,那么第二次是否要把新入库的数据也删除,就要根据业务需求来定了。
update操作
如果你更改的字段值是一个固定值,这种情况下,是幂等性的,多次重复修改结果还是一样的。
如果你更改的字段值是变化的,比如是自增的,那么这种情况下就需要实现幂等性了。可以更新操作时传入数据版本号,通过乐观锁实现幂等性。
insert操作
需要实现幂等性,新增时还没有唯一业务单号的,此时我们可以使用token来保证幂等性。
混合操作
如果能找到唯一的业务单号,则可以使用分布式锁实现幂等。如果没有则可以通过token保证幂等。
分布式锁实现幂等性详解
上面说的唯一业务单号和token,其实是一个意思,就是要保证唯一性,有业务单号,可以使用业务单号上分布式锁,没有业务单号的情况下使用token代替来上锁。
以token方式为例:
后端提供一个获取token的请求,请求中获取token后要将token放到redis缓存中,前端获取到token后放到隐藏域中,当发起业务请求时将token一并携带到后端,后端可以根据token值获取一把分布式锁,保证多次请求按序执行。获取到锁后还需要到redis中获取这个token缓存值,能够获取到才能继续执行业务逻辑,获取到后将这个缓存删除,保证后面的请求获取不到就不会再次执行业务逻辑了。
四、分布式限流
什么是限流?
限流,目的是通过对请求进行限速来保护系统,如果达到限速值就可以采取一定的手段,例如拒绝服务、排队、等待。限流是保证系统高可用的重要手段。
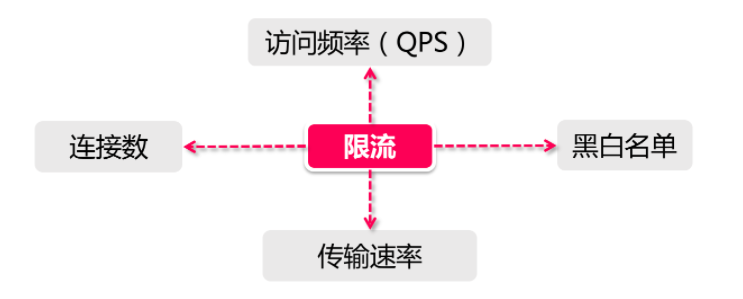
几种主要的限流规则:
-
QPS和连接数控制:
针对上图中的连接数和QPS(query per second)限流来说,我们可以设定IP维度的限流,也可以设置基于单个服务器的限流。在真实环境中通常会设置多个维度的限流规则,比如设定同一个IP每秒访问频率小于10,连接数小于5,再设定每台机器QPS最高1000,连接数最大保持200。 -
传输速率
对于“传输速率”大家都不会陌生,比如资源的下载速度。有的网站在这方面的限流逻辑做的更细致,比如普通注册用户下载速度为100k/s,购买会员后是10M/s,这背后就是基于用户组或者用户标签的限流逻辑。 -
黑白名单
黑白名单是各个大型企业应用里很常见的限流和放行手段,而且黑白名单往往是动态变化的。举个例子,如果某个IP在一段时间的访问次数过于频繁,被系统识别为机器人用户或流量攻击,那么这个IP就会被加入到黑名单,从而限制其对系统资源的访问,这就是我们俗称的“封IP”。白名单就相当于御赐金牌在身,可以自由穿梭在各种限流规则里,畅行无阻。
什么是分布式限流?
所谓的分布式限流,它把整个分布式环境中所有服务器当做一个整体来考量。比如说针对IP的限流,我们限制了1个IP每秒最多10个访问,不管来自这个IP的请求落在了哪台机器上,只要是访问了集群中的服务节点,那么都会受到限流规则的制约。因此,我们必须将限流信息保存在一个“中心化”的组件上,这样它就可以获取到集群中所有机器的访问状态,目前有两个比较主流的限流方案:
- 网关层限流: 将限流规则应用在所有流量的入口处;
- 中间件限流: 将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量。
限流方案常用算法
令牌桶算法
Token Bucket令牌桶算法是目前应用最为广泛的限流算法,顾名思义,它有以下两个关键角色:
- 令牌:获取到令牌的Request才会被处理,其他Requests要么排队要么被直接丢弃;
- 桶:用来装令牌的地方,所有Request都从这个桶里面获取令牌。
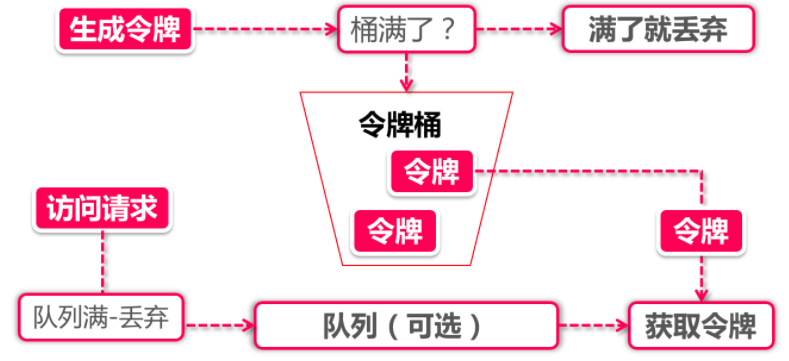
令牌生成:
这个流程涉及到令牌生成器和令牌桶,令牌桶是一个装令牌的地方,既然是个桶那么必然有一个容量,也就是说令牌桶所能容纳的令牌数量是一个固定的数值。
对于令牌生成器来说,它会根据一个预定的速率向桶中添加令牌,比如我们可以配置让它以每秒100个请求的速率发放令牌,或者每分钟50个。注意这里的发放速度是匀速,也就是说这50个令牌并非是在每个时间窗口刚开始的时候一次性发放,而是会在这个时间窗口内匀速发放。
在令牌发放器就是一个水龙头,假如在下面接水的桶子满了,那么自然这个水(令牌)就流到了外面。在令牌发放过程中也一样,令牌桶的容量是有限的,如果当前已经放满了额定容量的令牌,那么新来的令牌就会被丢弃掉。
令牌获取:
每个访问请求到来后,必须获取到一个令牌才能执行后面的逻辑。假如令牌的数量少,而访问请求较多的情况下,一部分请求自然无法获取到令牌,那么这个时候我们可以设置一个“缓冲队列”来暂存这些多余的令牌。
缓冲队列其实是一个可选的选项,并不是所有应用了令牌桶算法的程序都会实现队列。当有缓存队列存在的情况下,那些暂时没有获取到令牌的请求将被放到这个队列中排队,直到新的令牌产生后,再从队列头部拿出一个请求来匹配令牌。
当队列已满的情况下,这部分访问请求将被丢弃。在实际应用中我们还可以给这个队列加一系列的特效,比如设置队列中请求的存活时间,或者将队列改造为PriorityQueue,根据某种优先级排序,而不是先进先出。算法是死的,人是活的,先进的生产力来自于不断的创造,在技术领域尤其如此。
漏桶算法
Leaky Bucket。瞧见没,又是个桶,限流算法是跟桶杠上了,那么漏桶和令牌桶有什么不同呢?我们来看图说话:

漏桶算法的前半段和令牌桶类似,但是操作的对象不同,令牌桶是将令牌放入桶里,而漏桶是将访问请求的数据包放到桶里。同样的是,如果桶满了,那么后面新来的数据包将被丢弃。
漏桶算法的后半程是有鲜明特色的,它永远只会以一个恒定的速率将数据包从桶内流出。打个比方,如果我设置了漏桶可以存放100个数据包,然后流出速度是1s一个,那么不管数据包以什么速率流入桶里,也不管桶里有多少数据包,漏桶能保证这些数据包永远以1s一个的恒定速度被处理。
漏桶、令牌桶的区别
根据它们各自的特点不难看出来,这两种算法都有一个“恒定”的速率和“不定”的速率。令牌桶是以恒定速率创建令牌,但是访问请求获取令牌的速率“不定”,反正有多少令牌发多少,令牌没了就干等。而漏桶是以“恒定”的速率处理请求,但是这些请求流入桶的速率是“不定”的。
从这两个特点来说,漏桶的天然特性决定了它不会发生突发流量,就算每秒1000个请求到来,那么它对后台服务输出的访问速率永远恒定。而令牌桶则不同,其特性可以“预存”一定量的令牌,因此在应对突发流量的时候可以在短时间消耗所有令牌,其突发流量处理效率会比漏桶高,但是导向后台系统的压力也会相应增多。
滑动窗口(Rolling Window)
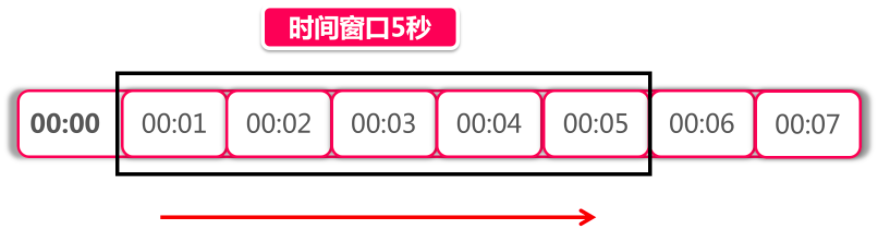
上图中黑色的大框就是时间窗口,我们设定窗口时间为5秒,它会随着时间推移向后滑动。我们将窗口内的时间划分为五个小格子,每个格子代表1秒钟,同时这个格子还包含一个计数器,用来计算在当前时间内访问的请求数量。那么这个时间窗口内的总访问量就是所有格子计数器累加后的数值。
比如说,我们在每一秒内有5个用户访问,第5秒内有10个用户访问,那么在0到5秒这个时间窗口内访问量就是15。如果我们的接口设置了时间窗口内访问上限是20,那么当时间到第六秒的时候,这个时间窗口内的计数总和就变成了10,因为1秒的格子已经退出了时间窗口,因此在第六秒内可以接收的访问量就是20-10=10个。
滑动窗口其实也是一种计算器算法,它有一个显著特点,当时间窗口的跨度越长时,限流效果就越平滑。打个比方,如果当前时间窗口只有两秒,而访问请求全部集中在第一秒的时候,当时间向后滑动一秒后,当前窗口的计数量将发生较大的变化,拉长时间窗口可以降低这种情况的发生概率。
Guava RateLimiter
Guava是Google出品的一款工具包(com.google.guava),在限流这个领域中,Guava也贡献了一份绵薄之力,在其多线程模块下提供了以RateLimiter为首的几个限流支持类。Guava是一个客户端组件,也就是说它的作用范围仅限于“当前”这台服务器,不能对集群以内的其他服务器施加流量控制。
尽管Guava不是面对分布式系统的解决方案,但是其作为一个简单轻量级的客户端限流组件,还是有必要认识一下。
引入pom:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
1、非阻塞限流
// 2.0表示限流组件每秒产生两个通行证,拿到通信证的请求才能被执行
RateLimiter limiter = RateLimiter.create(2.0);
@GetMapping("/tryAcquire")
public String tryAcquire(Integer count) {
// count代表每秒钟要消耗掉的令牌数,例如count=2,那么刚好每秒可以执行一个请求
if (limiter.tryAcquire(count)) {
log.info("success, rate is {}", limiter.getRate());
return "success";
} else {
log.info("fail, rate is {}", limiter.getRate());
return "fail";
}
}
2、限定时间的非阻塞限流
RateLimiter limiter = RateLimiter.create(2.0);
@GetMapping("/tryAcquireWithTimeout")
public String tryAcquireWithTimeout(Integer count, Integer timeout) {
if (limiter.tryAcquire(count, timeout, TimeUnit.SECONDS)) {
log.info("success, rate is {}", limiter.getRate());
return "success";
} else {
log.info("fail, rate is {}", limiter.getRate());
return "fail";
}
}
3、同步阻塞限流
RateLimiter limiter = RateLimiter.create(2.0);
@GetMapping("/acquire")
public String acquire(Integer count) {
limiter.acquire(count);
log.info("success, rate is {}", limiter.getRate());
return "success";
}
基于nginx的分布式限流
根据IP地址限制
nginx.conf配置文件
# 根据IP地址限制速度
# 1) 第一个参数 $binary_remote_addr
# binary_目的是缩写内存占用,remote_addr表示通过IP地址来限流
# 2) 第二个参数 zone=iplimit:20m
# iplimit名称可以自定义,是一块内存区域(记录访问频率信息),20m是指这块内存区域的大小
# 3) 第三个参数 rate=1r/s
# 比如100r/m,标识访问的限流频率
limit_req_zone $binary_remote_addr zone=iplimit:20m rate=1r/s;
server {
server_name www.jinsh.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:8080/;
# 基于IP地址的限制
# 1) 第一个参数zone=iplimit => 引用limit_req_zone中的zone变量
# 2) 第二个参数burst=2,设置一个大小为2的缓冲区域,当大量请求到来。
# 请求数量超过限流频率时,将其放入缓冲区域
# 3) 第三个参数nodelay=> 缓冲区满了以后,直接返回503异常
limit_req zone=iplimit burst=2 nodelay;
}
}
从服务器级别做限流
nginx.conf配置文件
# 根据服务器级别做限流
limit_req_zone $server_name zone=serverlimit:10m rate=100r/s;
server {
server_name www.jinsh.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:8080/;
# 基于服务器级别的限制
# 通常情况下,server级别的限流速率是最大的
limit_req zone=serverlimit burst=100 nodelay;
# 异常情况,返回504(默认是503)
limit_req_status 504;
}
}
基于连接数的限流
nginx.conf配置文件
# 基于连接数的配置
limit_conn_zone $binary_remote_addr zone=perip:20m;
limit_conn_zone $server_name zone=perserver:20m;
server {
server_name www.jinsh.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:8080/;
# 每个server最多保持100个连接
limit_conn perserver 100;
# 每个IP地址最多保持1个连接
limit_conn perip 5;
# 异常情况,返回504(默认是503)
limit_conn_status 504;
}
# 限制下载速度
location /download/ {
limit_rate_after 100m; # 下载100M后开始生效
limit_rate 256k; # 限制速度为256k/s
}
}
基于Redis+Lua的分布式限流
Lua
Lua是一个很小巧精致的语言,它的诞生(1993年)甚至比JDK 1.0还要早。Lua是由标准的C语言编写的,它的源码部分不过2万多行C代码,甚至一个完整的Lua解释器也就200k的大小。
使用Lua前,咱们的IntelliJ IDEA 需要先安装下插件,推荐EmmyLua。
下面一段脚本模拟限流:
-- 用作限流的Key
local key = 'My Key'
-- 限流的最大阈值=2
local limit = 2
-- 当前流量大小
local currentLimit = 0
-- 是否超出限流标准
if currentLimit + 1 > limit then
print 'reject'
return false
else
print 'accept'
return true
end
Redis+Lua代码实现
lua脚本
新建ratelimiter.lua文件,放到/src/main/resources目录下
-- 获取方法签名特征
local methodKey = KEYS[1]
redis.log(redis.LOG_DEBUG, 'key is', methodKey)
-- 调用脚本传入的限流大小
local limit = tonumber(ARGV[1])
-- 获取当前流量大小
local count = tonumber(redis.call('get', methodKey) or "0")
-- 是否超出限流阈值
if count + 1 > limit then
-- 拒绝服务访问
return false
else
-- 没有超过阈值
-- 设置当前访问的数量+1
redis.call("INCRBY", methodKey, 1)
-- 设置过期时间
redis.call("EXPIRE", methodKey, 1)
-- 放行
return true
end
java 代码
限流类
package com.jinsh.redis_lua;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Service;
import java.util.Arrays;
@Service
@Slf4j
public class AccessLimiter {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisScript<Boolean> rateLimitLua;
public void limitAccess(String key, Integer limit) {
boolean acquired = stringRedisTemplate.execute(
rateLimitLua, // Lua script的真身
Arrays.asList(key), // Lua脚本中的Key列表
limit.toString() // Lua脚本Value列表
);
if (!acquired) {
log.error("your access is blocked, key={}", key);
throw new RuntimeException("Your access is blocked");
}
}
}
配置类
package com.jinsh.redis_lua;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.script.DefaultRedisScript;
@Configuration
public class RedisConfiguration {
@Bean
public DefaultRedisScript loadRedisScript() {
DefaultRedisScript redisScript = new DefaultRedisScript();
// 加载Lua脚本
redisScript.setLocation(new ClassPathResource("ratelimiter.lua"));
redisScript.setResultType(Boolean.class);
return redisScript;
}
}
conteoller调用测试:
package com.jinsh.redis_lua;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Slf4j
public class Controller {
@Autowired
private AccessLimiter accessLimiter;
@GetMapping("test")
public String test() {
accessLimiter.limitAccess("ratelimiter-test", 1);
return "success";
}
}
自定义注解封装限流
注解类:
package com.jinsh.redis_lua.annotation;
import java.lang.annotation.*;
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface AccessLimiter {
int limit();
String methodKey() default "";
}
切面类:
package com.jinsh.redis_lua.annotation;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import java.lang.reflect.Method;
import java.util.Arrays;
import java.util.stream.Collectors;
@Slf4j
@Aspect
@Component
public class AccessLimiterAspect {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisScript<Boolean> rateLimitLua;
@Pointcut("@annotation(com.jinsh.redis_lua.annotation.AccessLimiter)")
public void cut() {
log.info("cut");
}
@Before("cut()")
public void before(JoinPoint joinPoint) {
// 1. 获得方法签名,作为method Key
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
AccessLimiter annotation = method.getAnnotation(AccessLimiter.class);
if (annotation == null) {
return;
}
String key = annotation.methodKey();
Integer limit = annotation.limit();
// 如果没设置methodkey, 从调用方法签名生成自动一个key
if (StringUtils.isEmpty(key)) {
Class[] type = method.getParameterTypes();
key = method.getClass() + method.getName();
if (type != null) {
String paramTypes = Arrays.stream(type)
.map(Class::getName)
.collect(Collectors.joining(","));
log.info("param types: " + paramTypes);
key += "#" + paramTypes;
}
}
// 2. 调用Redis
boolean acquired = stringRedisTemplate.execute(
rateLimitLua, // Lua script的真身
Arrays.asList(key), // Lua脚本中的Key列表
limit.toString() // Lua脚本Value列表
);
if (!acquired) {
log.error("your access is blocked, key={}", key);
throw new RuntimeException("Your access is blocked");
}
}
}
controller类测试:
package com.jinsh.redis_lua;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Slf4j
public class Controller {
@GetMapping("test-annotation")
@com.jinsh.redis_lua.annotation.AccessLimiter(limit = 1)
public String testAnnotation() {
return "success";
}
}
分布式限流要注意的问题
为什么需要匀速限流
我们做这样一个场景假设,在某个限流策略中我们设置了10r/s(每秒十个请求)的限流速率,在令牌桶算法的实现中,令牌生成器每秒会产生10个新令牌放入令牌桶。Guava的RateLimiter采用了一种“匀速”的策略生成令牌,也就是说,这10个令牌平均分到1秒钟的时间窗口中生成,每0.1秒产生一个令牌。如果在这一秒来了10个请求,这些请求会在一秒钟以内匀速消化掉。
假如我们不采用匀速发放,而是采用一把梭的模式发令牌,在每一秒开始的时候把令牌一次性发放,这样会带来什么问题呢?我们可以用两个场景来说明这种模式的弊端。
一个最明显的问题就是令牌利用率降低,比如说我在前一秒还有9个令牌,在下一秒刚开始就直接生产10个令牌,这时候令牌桶明显装不下,因此会丢弃掉9个令牌。如果在这一秒突然涌来了15个请求,由于这一秒的令牌都已经发放完毕,所以这种一把梭的发牌模式最多只能在当前时间窗口内处理10个请求,剩下的5个请求要延后到下一秒处理。而如果我们采用匀速发牌的模式,这15个请求会在下一秒的一开始就处理掉10个,剩下的请求每隔0.1秒就会获取到一个新令牌,这样一来,15个请求在一秒内就可以处理完。
除此之外,还有一个可能导致服务雪崩的问题,我们来看下面的图:
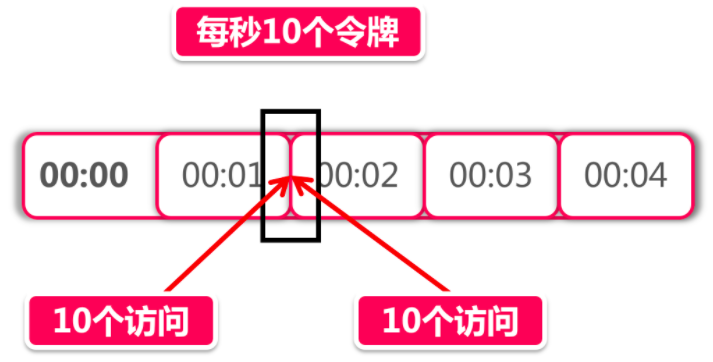
以上面的图为例,在00:01秒和00:02秒各有10个令牌发放。现在我化身为一个黑客,想方设法打出高额QPS(query per second)击垮后台服务,我想了这么一个方法,我专挑当前这一秒和下一秒交汇的时间发起攻击,假如在00:01秒这10个令牌没有被消耗,那么我在这一秒快结束的时候能瞬间发起10个访问。而在下一秒开始的时候由于又有10个新的令牌发放,我可以在下一秒刚到的极短时间里再发起10个访问。那么前后加起来,我可以瞬间向后台服务打出10+10=20的瞬时流量,当然20流量看起来并不大,我们如果把限流策略定为每秒1w个令牌,那么利用这种方式在理想情况下就可以打出2w的伤害,这就是一个比较可观的数字了。对于一些薄弱的后台服务,很有可能造成服务响应超时,如果发生在主链路,甚至会进一步引发服务雪崩。
基于上面这些情况,我们才需要将令牌按照一个“匀速”的频率放进令牌桶。除此之外,也可以利用前面提到的”滑动窗口“算法,尽量使流量平滑输出,不过即便是滑动窗口也并不能保证不会出现上面提到的人造流量峰值攻击,所以,使用匀速令牌桶才是理想的方案。
限流组件的失效
常在河边走,哪有不湿鞋,再牛的系统也不能保证100%的可用性,限流组件也不意外。尽管Redis和Nginx都是蛮靠谱的组件,但是明天和意外你永远不知道哪一个先来,珍惜当下的同时,对限流组件失效的情况,我们应该怎么办?
这是一个悖论似的问题,继续提供服务就相当于给了外部攻击者利用流量洪峰击垮系统的机会,而拒绝服务就相当于系统关门打烊了。我们可以参考Spring Cloud和其他限流开源方案的做法,当限流组件失效的时候,默认不启用限流服务。比如Spring Cloud的Gateway网关默认提供了Lua + Redis的限流功能,当Redis服务不可用的时候,Gateway就直接将所有访问请求做放行处理。
其实道理很简单,拒绝外部请求所造成的损失,远大于放行请求暴露出的潜在破绽。大家在设计自己的限流方案的同时,一定要记得考虑异常情况,如果是限流组件自身不可用的问题,那么就放弃限流,选择直接放行服务。
如何确定限流上界
对限流组件来说,如果能“卡在”系统处理能力的上限附近,那是再好不过的了。因此这个数值不能靠猜,而必须基于事实依据。那么事实从哪里来?压力测试!
压测不仅仅是无脑打高流量,找到系统的极限,而是在基于一个合理的“预估”访问量级之下,对系统进行全方位的摸底。执行全链路压测,它不仅包含压力测试,还有故障演练,异地多活演练(突然切断一整个机房),弹性伸缩(紧急上线新机器提高算力),服务降级(核心主链路降级演练,考察系统的最低可用性)等等复杂的流程。
因此,在确定限流上界之前,我们要根据当前业务规模预估一个合理的访问量级,再乘以一个系数(比如1.2)保证当前系统有一部分设计余量(预留少量弹性空间),通过压测找到系统瓶颈加以巩固,先确保当前系统在这个量级下的可用性。在此之上,向上打流量,反复进行多次测试后分析汇总性能指标(QPS和连接数),将限流的上界设置在指标的「平均值」或者「中位数」附近。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号