
金利道分享-基于Spark Streaming预测股票走势
一、实验目的
通过本实验对基于Spark Streaming流式计算框架有所全面了解,掌握对DStreams抽象的操作。
二、实验内容
实验内容针对新浪股票数据接口,基于Spark Streaming实时接收并处理数据,并对特定的某一支股票走势进行简单预测。
三、实验要求
以小组为单元进行实验,每小组5人,小组自协商一位组长,由组长安排和分配实验任务,具体参加试验内容中实验过程。小组成员需要对流式计算有所了解,特别是对Spark Streaming流式计算框架有所了解和学习。
四、准备知识
4.1 Spark Streaming流式计算框架
在Spark Streaming上实现DStream,它是基于Spark处理引擎的一个修改版本。Spark Streaming由三部分组成,如图4.1所示
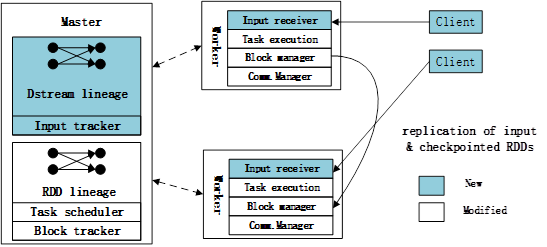
图4.1 Spark Streaming组件
图4.1显示了Spark Streaming在Spark Core上所做的修改:
(1)master跟踪DStream lineage,并调度任务来计算新的RDD分区。
(2)工作节点接收数据,保存输入分区和已计算的RDD,并执行任务。
(3)客户端用于发送数据给系统。
如图4.1所示,如图中所示,Spark Streaming 重用了 Spark 的许多组件,但仍然需要修改和添加多个组件来支持流处理。
从架构角度来看,Spark Streaming 和传统的流系统之间区别在于,Spark Streaming 将计算过程分解为小的、无状态的、确定的任务。每个任务都可以在集群中的任何节点或同时在多个节点运行。在传统系统的固定拓扑结构中,将部分计算过程转移到另一台机器是一个很大的动作。Spark Streaming 的做法,可以非常直接地在集群上进行负载均衡,应对故障或启动慢节点恢复。同理也能用于批处理系统——如 MapReduce。然而,由于 RDD 运行于内存中,Spark
Streaming 的任务执行时间会短得多,一般只有 50-200 毫秒。
不同于以前系统将状态存储在长时间运行的处理过程中,Spark Streaming 中的所有状态都以容错数据结构(RDD)来保存。由于 RDD 分区被确定性地计算出来,它可以驻留在任何节点上,甚至可以在多个节点上进行计算。这套系统试图最大限度地提高数据局部性,同时这种底层的灵活性使得推测执行和并行恢复成为可能。
这些优势在批处理平台(Spark)上运行时可以很自然地获得。但依然需要进行显著的修改来支持流处理。
应用程序执行:
Spark Streaming 的应用从一个或多个输入流开始执行。系统加载数据流的方式,要么是通过直接从客户端接收记录数据,要么是通过周期性的从外部存储系统中加载数据,如 HDFS,外部的存储系统也可以被日志收集系统[9]所代替。在前一种方式下,由于 D-Streams 需要输入的数据被可靠地进行存储来重新计算结果,因此我们需要确保新的数据在向客户端程序发送确认之前,在两个工作节点间被复制。如果一个工作节点发生故障,客户端程序向另一个工作节点
发送未经确认的数据。
所有的数据在每一个工作节点上被一个块存储进行管理,同时利用主服务器上的跟踪器来让各个节点找到数据块的位置。由于我们的输入数据块和我们从数据块计算得到的 RDD 的分区是不可变的,因此对块存储的跟踪是相对简单的:每一个数据块只是简单的给定一个唯一 ID,并所有拥有这个 ID 的节点都能够对其进行操作(例如,如果多个节点同时计算它)。块存储将新的数据块存储在内存中,但会以 LRU 策略将这些数据块丢弃, 这在后面会进行描述。
为了确定何时开始一个新的时间周期,我们假设各个节点通过 NTP 进行了时钟同步,并且在每一个周期结束时每一个节点都会向主服务器报告它所接收到的数据块 IDs。主服务器之后会启动任务来计算这个周期内的输出 RDDs, 不需要其他任何同步。和其他的批处理调度器一样,一旦完成上个周期任务,它就简单地开始每个后续任务。
Spark Streaming 依赖于每一个时间间隔内 Spark 现有的批处理调度器,并加入了像DryadLINQ系统中的大量优化:(1)它对一个单独任务中的多个操作进行了管道式执行,如一个 map 操作后紧跟着另一个 map操作。(2)它根据数据的本地性对各个任务进行调度。(3)它对 RDD 的各个划分进行了控制,以避免在网络中数据的 shuffle。例如,在一个reduceByWindow 的操作中,每一个周期内的任务需要从当前的周期内“增加” 新的部分结果(例如,每一个页面的点击数),和“删除” 多个周期以前的结果。调度器使用相同的方式对不同周期内的状态 RDD 进行切分,以使在同一个节点的每一个 key 的数据(例如,一个页面) 在各时间分片间保持一致。
流处理优化:
尽管 Spark Streaming 建立在 Spark 之上,我们仍然必须优化这个批处理引擎以使其支持流处理。这些优化包括以下几个方面:
(1)网络通信:我们重写了 Spark 的数据层,通过使用异步 I/O 使得带有远程输入的任务,比如说reduce 任务,能够更快地获取它们。
(2)时间间隔流水线化:因为每一个时间间隔内的任务都可能没有充分地使用集群的资源(比如说,在每一个时间间隔的末端, 可能只有很少的几个任务还在运行),所以,我们修改了 Spark的调度器,使它允许在当前的时间间隔还没有结束的时候调用下一个时间间隔的任务。例如,考虑我们在表 4.3 提到的 map + runningReduce 作业。我们之所以能够在时间间隔 1 的 reduce 操作结束之前就可以执行时间间隔 2 的 map 操作,这是因为每一步的 map操作都是独立的。
(3)任务调度:我们对 Spark 的任务调度器做了大量的优化,比如说手工调整控制消息的大小,使得每隔几百毫秒就可以启动上百个任务的并行作业。
(4)存储层:为了支持 RDDs 的异步检查点和性能提升,我们重写了 Spark 的存储层。因为 RDDs 是不可变的,所以可以在不阻塞计算和减慢作业的情况下通过网络对 RDDs 设置检查点。在可能的情况下,新的数据层还会使用零拷贝。
(5)lineage 截断:因为在 D-Streams 中 RDDs 之间的 lineage 可以无限增长,我们修改了调度器使之在一个 RDD 被设置检查点之后删除自己的 lineage,修改之后 RDDs 之间的 lineage 不能任意生长。类似地,对于 Spark 中的其他无限增长的数据结构来说,将会定期调用一个清理进程来清理它们。
(6)Master 的恢复:因为流应用需要不间断运行 7 天 24 小时,我们给 Spark 加入对 master 状态恢复的支持。
针对流处理所做的优化还提高了 Spark 在批处理标准测试上的性能,大概是之前的 2 倍. Spark 的引擎能够同时应对流处理和批处理,这是其强大之处。
内存管理:
在当前的 Spark Streaming 实现中,每个结点的块存储管理 RDD 的分片是以 LRU(最近最少使用)的方式,如果内存不够会依 LRU 算法将数据调换到磁盘。另外,用户可以设置最大的超时时间,当达到这个时间之后系统会直接将旧的数据块丢弃而不进行磁盘 I/O 操作(这个超时时间必须大于检查点间隔的时间)。我们发现在很多应用中,Spark Streaming 需要的内存并不是很多,这是因为一个计算中的状态通常比输入数据少很多(很多应用是计算聚合统计),并且任何可靠的流式处理系统都需要像我们这样通过网络来复制数据到多个结点。但是,Spark团队还是会探索优化内存使用的方式。
并行恢复:
DStreams的确定性使得可以使用两种有效却不适合常规流式系统的恢复技术来恢复工作节点状态:并行恢复和推测执行。此外,它也简化了主节点的恢复。
当集群中一个Worker失败,该节点上的RDD分片状态、Running中的任务,DStreams都会在其他Worker上重新并行计算。通过异步的复制RDD状态到其它的工作节点,系统可以周期性地设置RDDs状态地检查点。例如,在运行时统计页面浏览数的程序中,系统可能对于该计算每分钟选择一个检查点。然后,如果一个节点失败了,系统会检查所有丢失的RDD分片,然后启动一个任务从上次的检查点开始重新计算。多个任务可以同时启动去计算不同的分片,使得整个集群参与恢复。DStream在每个时间片中并行的计算RDDs的分区以及并行处理每个时间片中相互独立的操作(例如开始的map操作),因为可以从lineage中细粒度地获得依赖关系。
在上行流备份中,单个闲置机器执行了所有的恢复,然后开始处理新的纪录。在高负荷地系统中这需要很长时间才能跟上进度,这是因为在重建旧的状态过程中新的纪录会持续到达。事实上,假设在失败之前地工作量是,然后在恢复的每分钟中备份节点只能做一分钟地工作,但是会同时收到 分钟的新任务。因此,要在的时间内从上次失败节点中完全恢复 个单元的任务,则可以得到:。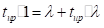
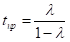
(4.1)
在其他线路中,所有的机器参与恢复,同时也处理新的纪录。假定在任务失败之前分布式集群中有台机器,剩余的台机器,现在每个机器需要恢复个工作,同时接收数据的速率是。它们追赶到来的数据流时间满足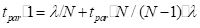
。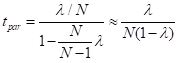
(4.2)
因此,拥有更多的节点,并行恢复能够跟上到来的数据流,这比上行留备份要快得多。
除了节点故障,在大型集群中另一个值得关注的问题是运行较慢的节点。幸运的是,DStreams同样也可以让我们像批处理系统那样减少较慢节点的影响,这是通过推测性(speculative)地运行较慢任务地备份副本实现的。这种推测执行在连续的处理系统中可能很难实现,因为它需要启动一个节点的新副本,填充新副本的状态,并追赶上较慢的副本。事实上,流式处理中的复制算法,比如Flux和DPC,主要在于研究两个副本之间的同步。
在Spark Streaming的实现中,使用了一个简单的阈值来检测较慢的节点:如果一个任务的运行时长比它所处的工作阶段中的平均值高1.4倍以上,那么就标记它为慢节点。
7*24运行Spark Streaming的一个最终要求是能够容忍Spark master的故障[51]。Spark通过两个步骤来做到这些,第一步是当开始每个时序时可靠的记录计算的状态,第二步是当旧的master失败时,让计算节点连接到一个新的master并且报告它们的RDD分区。DStreams简化恢复的一个关键方面是,如果一个给定的RDD被计算两次是没有问题的。因为操作是确定的,这一结果与从故障中进行恢复类似。因为任务可以重新计算,这意味着当master重新连接时丢掉一些运行中的任务也是可以的。
Spark Sreaming目前的实现方式是将DStreams元数据存储在HDFS,记录(1)用户的DStreams图以及表明用户代码的Scala的函数对象,(2)最后的检查点的时间,还有(3)自检查点开始的RDD的ID号,其中检查点通过在每个时序进行重命名(原子操作)来更新HDFS文件。恢复后,新master会读取这个文件找到它断开的地方,并重新连接到计算节点,以便确定哪些RDD分区是在内存中。然后再继续处理每一个漏掉的时序。虽然Spark Streaming还没有优化恢复处理,但它是相当快了,100个节点的集群可以在12秒内恢复。
4.2 DStreams API
因为DStreams是主要的执行策略(描述如何将一个计算分解成多个步骤),因此它们被用在流式系统中实现了多个标准的操作,比如滑动窗口和增量式处理,以简单的对它们的执行批处理到各个小的时间间隔中。
在Spark Streaming中,用户使用函数API来注册一个或多个数据流。程序可以将输入数据流定义为从外部系统中读取数据,该系统通过从对节点端口监听或周期性地从一个存储系统(例如,HDFS)加载来获取数据。它可以适用于两种类型对这些数据流的操作:转换操作,从一个或多个父数据流创建一个新的DStreams。这些操作可能是无状态的,在这个时间周期内对RDD分别进行处理,或它们可能跨越周期来创建状态。输出操作,使得程序将数据写入外部系统。例如,save操作将DStreams中的每一个RDD输出到数据库。
DStreams支持在典型批处理框架中所拥有的无状态的转换操作,包括map,reduce,groupBy和join。我们在Spark中提供了所有操作。例如,一个程序使用以下的代码可以在DStreams的每一个时间周期内,运行一个规范的MapReduce WC程序实例。
pairs=words.map(w=>(w,1)) //构造键值对RDD,并统计数量
counts=pairs.reduceByKey((a,b)=>a+b) //聚合
此外,为了支持跨越多个周期的计算,DStreams提供了多个有状态的转换操作,这些操作包括:窗口、增量式聚合、状态跟踪等。这些操作是在基于标准的数据流处理技术的基础上例如滑动窗口。图4.2 用于单一关联和关联+可逆版本的操作执行的reduceByWindow。这两个版本为每个时间间隔只进行一次计数的计算,但是第二个版本的操作避免了对每一个窗口进行重新求和。方框表示RDDs,箭头表示用来计算窗口的操作[t,t+5)。
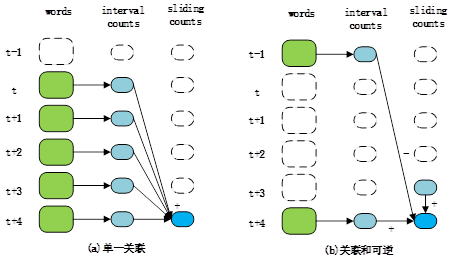
图4.2 用于单一关联和关联+可逆版本的操作执行的reduceByWindow
(1)窗口操作:window操作将每一个过去的时间周期的滑动窗口里的所有记录组合到一个RDD。例如,代码words.window(“5s”),会产生一个包含周期内单词的RDDs的DStream[0,5),[1,6),[2,7)等。
(2)增量式聚合操作:对于常用的聚合计算的用例,就像在一个滑动窗口上进行count或max操作,DStreams有增量reduceByWindow操作的几个变种操作。最简单的一个是仅仅用一个关联的合并函数来对值进行合并。例如,在上述代码中,用户可以写:pairs.ReduceByWindow(“5s”,(a,b)=>a+b)。对于每一个时间周期只对该周期的计数进行一次计算,但不得不反复地对过去的5秒去添加计数,如图4.2(a)所示。如果聚合函数也是可逆的,一个更加高效的版本还需要“减值和增量式维护状态的一个函数(图4.2(b)):paris.reduceByWindow(“5s”,
(a,b)=>a+b,(a,b)=>a-b))。
(3)状态跟踪:通常,应用程序为了对表示状态变化的事件流进行响应,需要对各类对象进行状态跟踪。
在Spark中可以使用批处理的操作来实现这些操作,通过将批处理操作应用到来自父数据流中不同时间的RDDs,例如,可以由updateStateByKey构建的RDDs,通过对旧的状态和每个周期的新事件进行分组来实现。最后,用户调用输出操作符将Spark Streaming的结果发送到外部系统(例如,展示在dashboard上)。我们提供了两个这样的操作:save操作,将Dstream中的每一个RDD写入到一个存储系统(例如,HDFS或HBase),和foreachRDD,在每一个RDD上执行一段用户代码段(任意的Spark代码)。例如,用户可以用counts.foreachRDD(rdd=>print(rdd.top(K)))来打印top K的计数。
4.3 Window Operations
Spark Streaming还提供了窗口计算,允许您在数据的滑动窗口上应用转换。下图说明了这个滑动窗口。
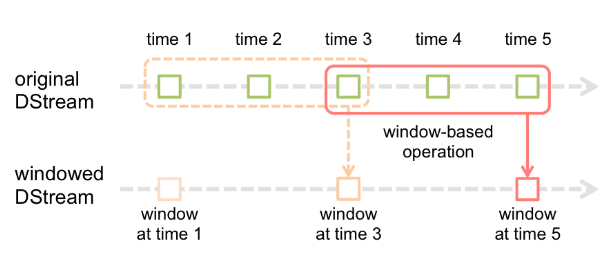
图4.3 Window Operations
如图4.3所示,每当窗口滑过源DStream时,落在窗口内的源RDD被组合并进行操作以产生窗口DStream的RDD。在这种具体情况下,操作应用于最近3个时间单位的数据,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
- windowLength窗口长度 - 窗口的持续时间(4.3图中的3)
- slideInterval滑动间隔 - 执行窗口操作的间隔(4.3图中的2)
这两个参数必须是源DStream的批间隔的倍数(图中的1)。
我们以一个例子来说明窗口操作。假设希望通过在过去30秒的数据中每10秒产生一个字数来扩展早期的示例。为此,必须在最近30秒的数据中对(word,1)对的对DStream应用reduceByKey操作。这是使用reduceByKeyAndWindow操作完成的。
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
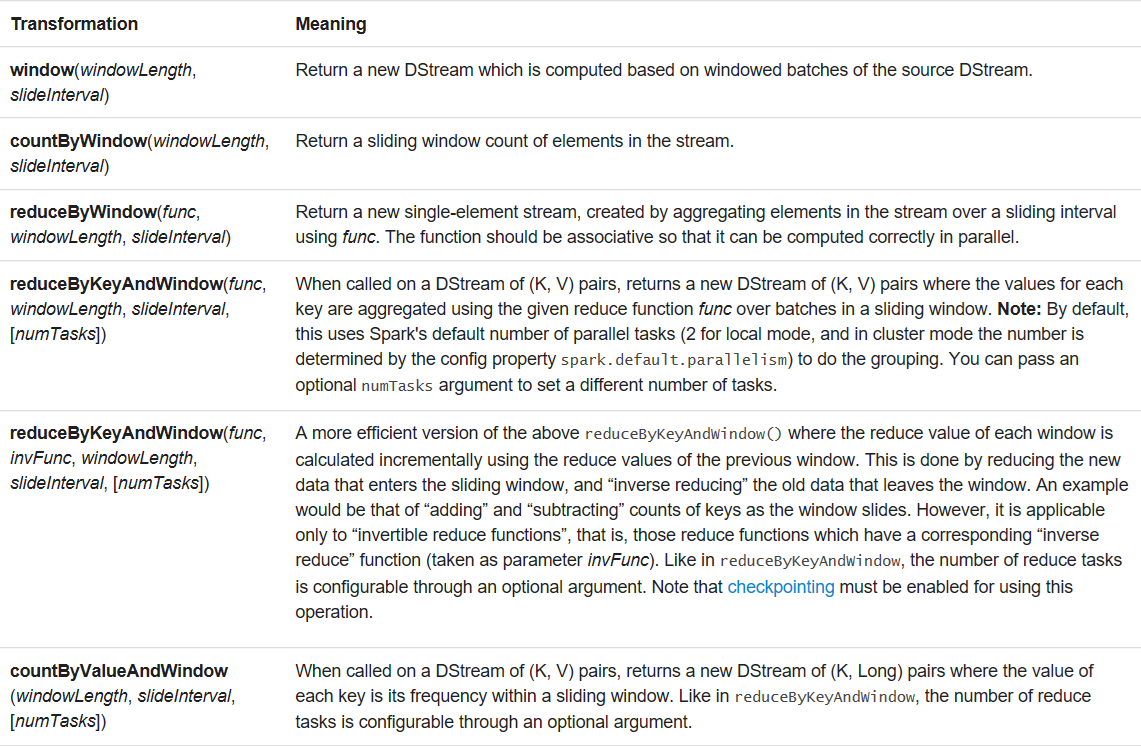
一些常见的窗口操作如下。所有这些操作都采用上述两个参数 - windowLength和slideInterval。
五、实验步骤
5.1 数据源
实验采用Sina股票数据接口。以字符串数据的形式范围,简单易用且直观。
5.2 测试数据源
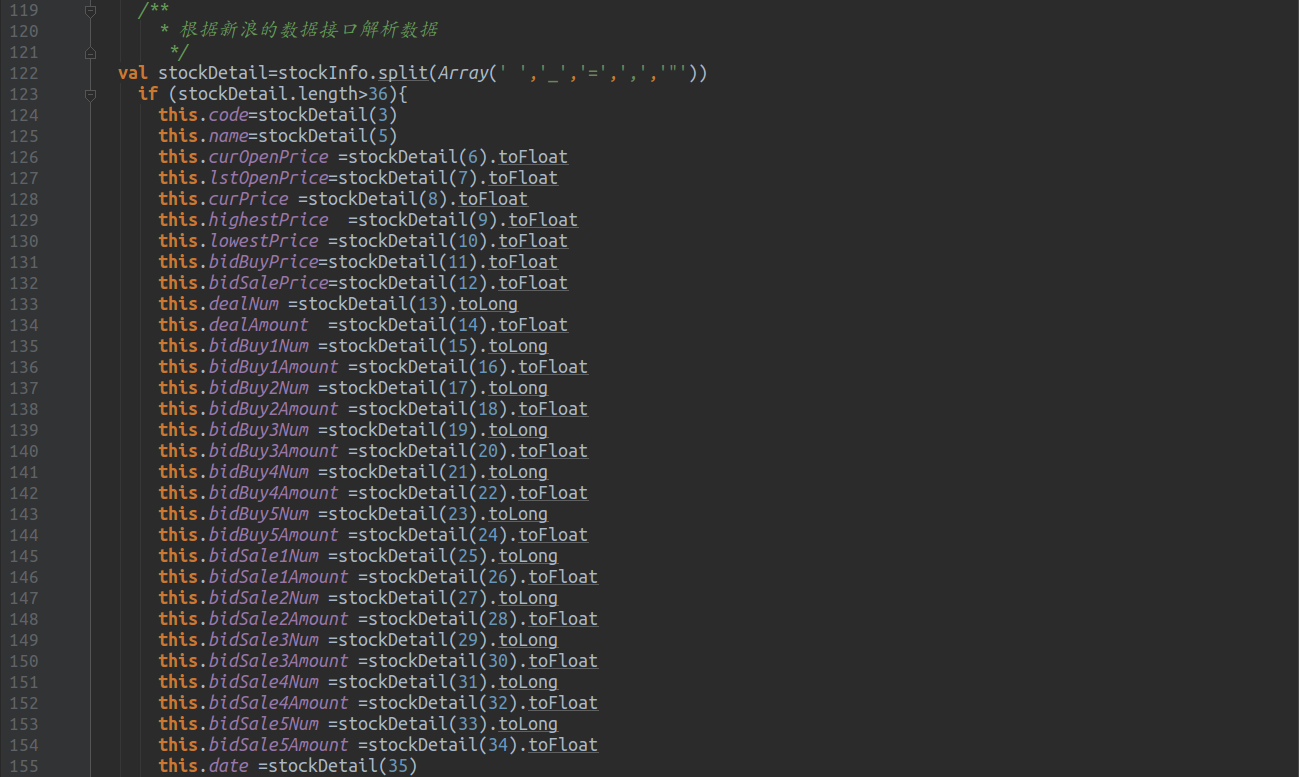
针对股票的数据接口,一下代码提供简单的测试,以解析返回的数据。
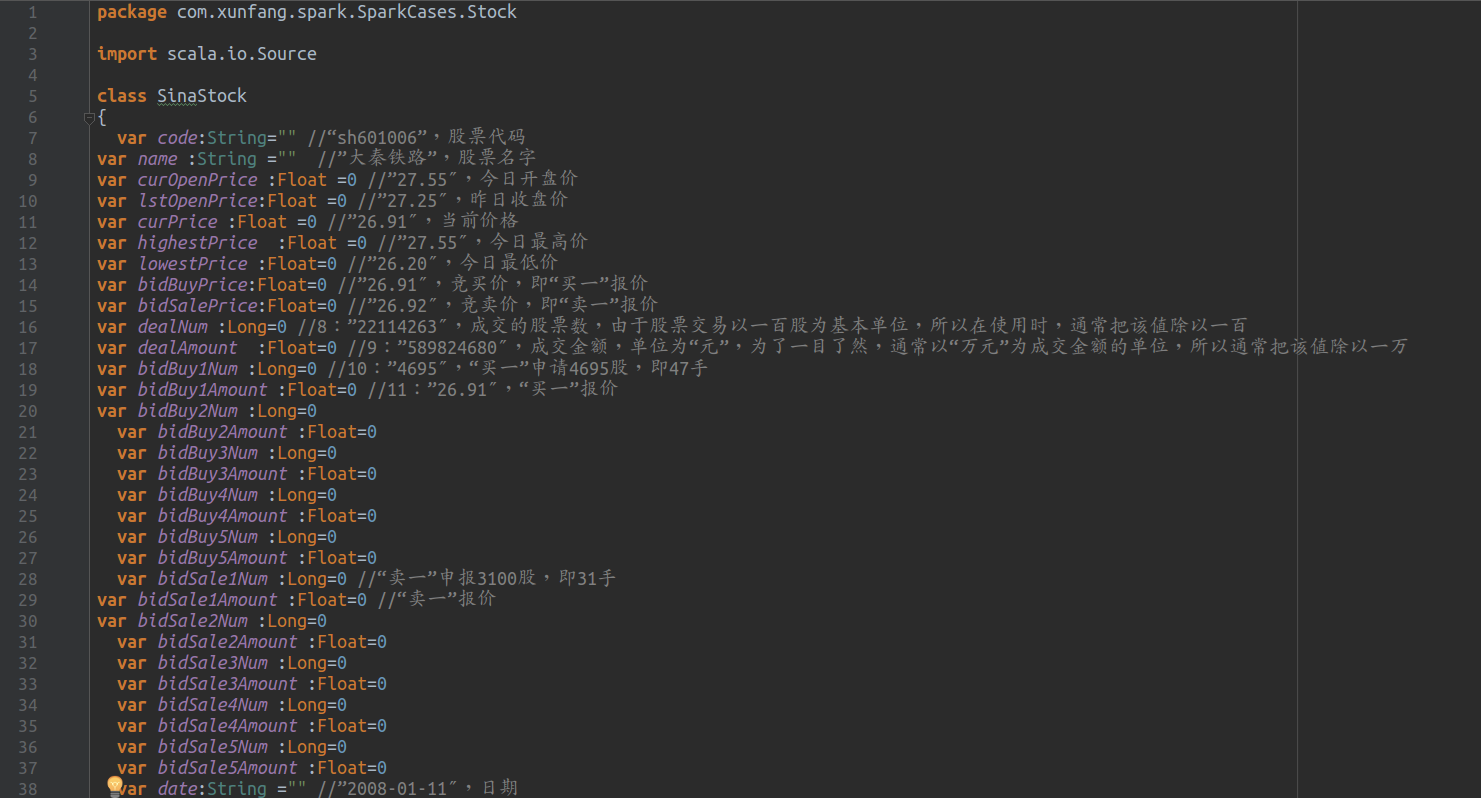
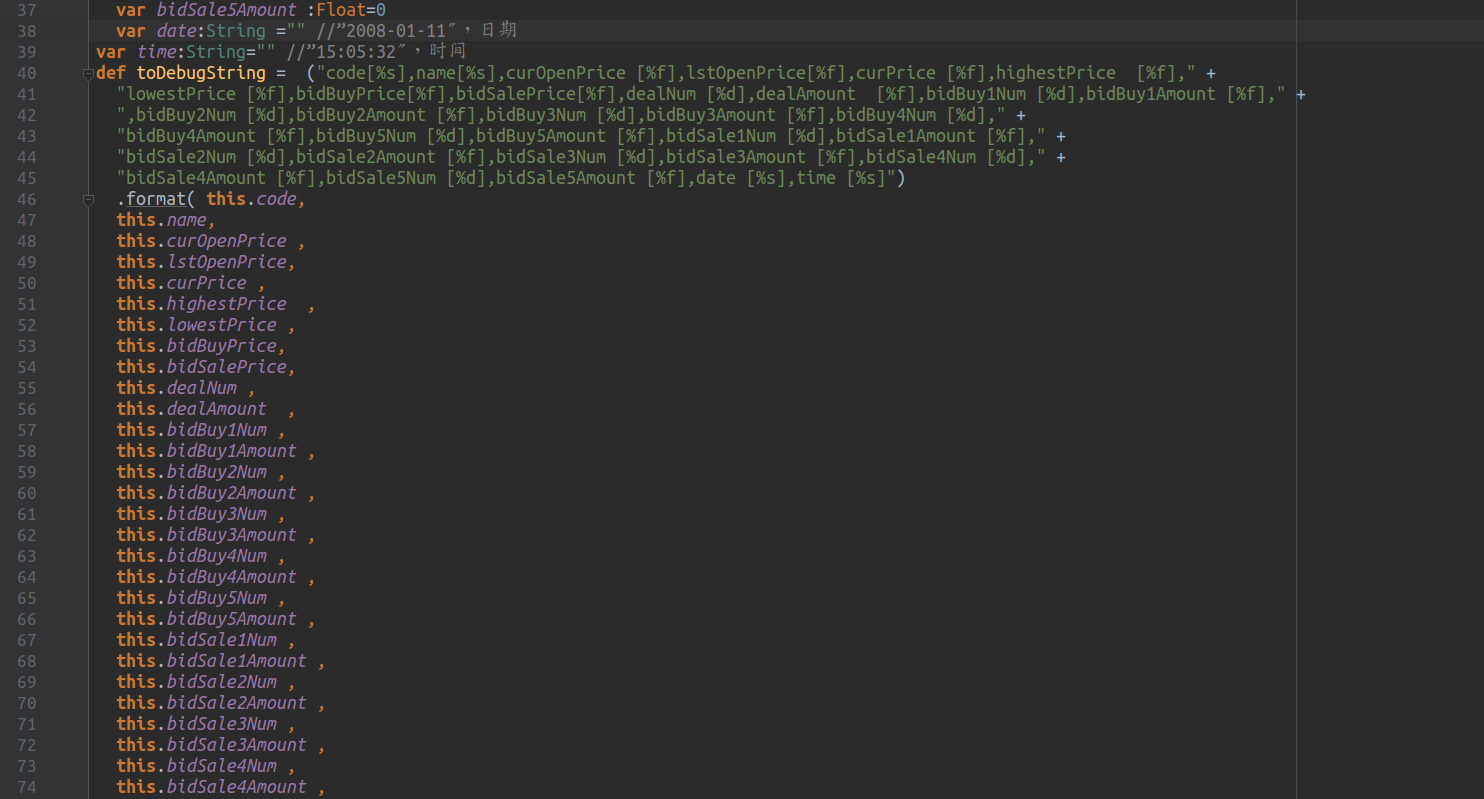
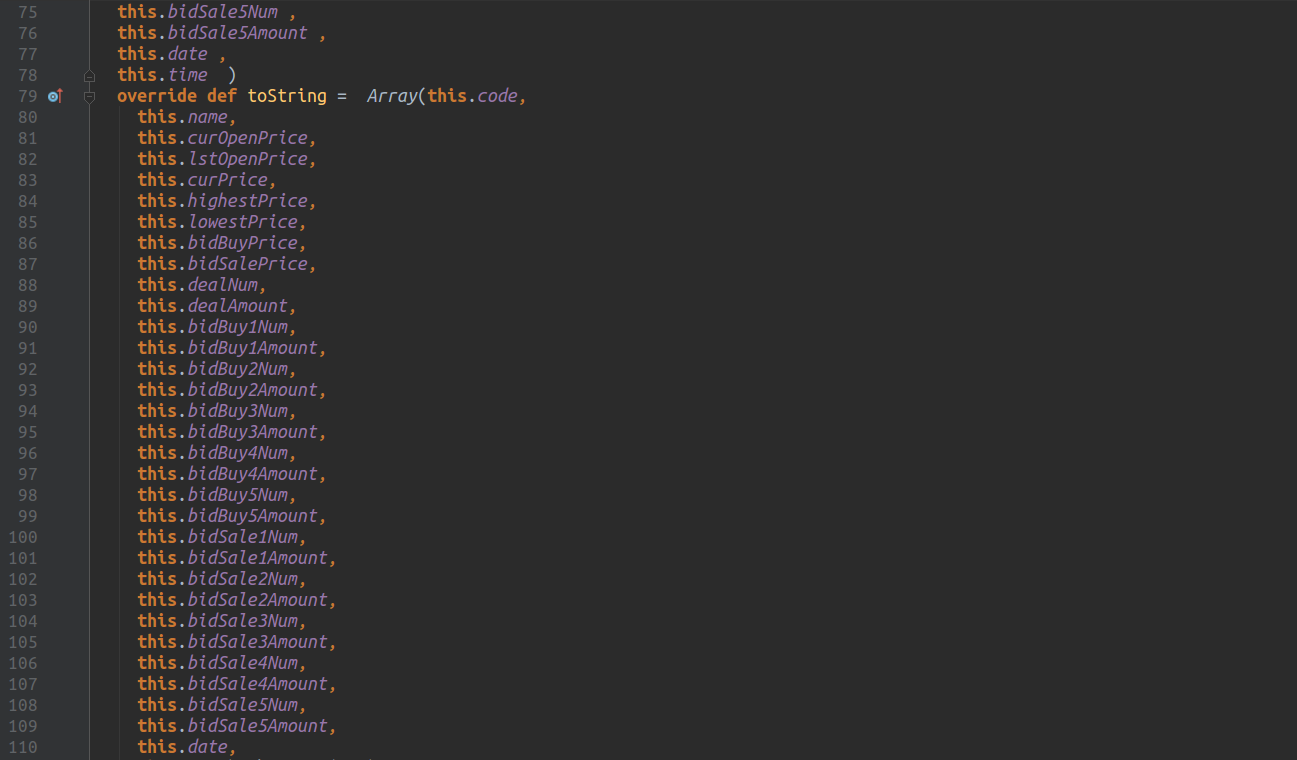

解析数据

伴生对象:
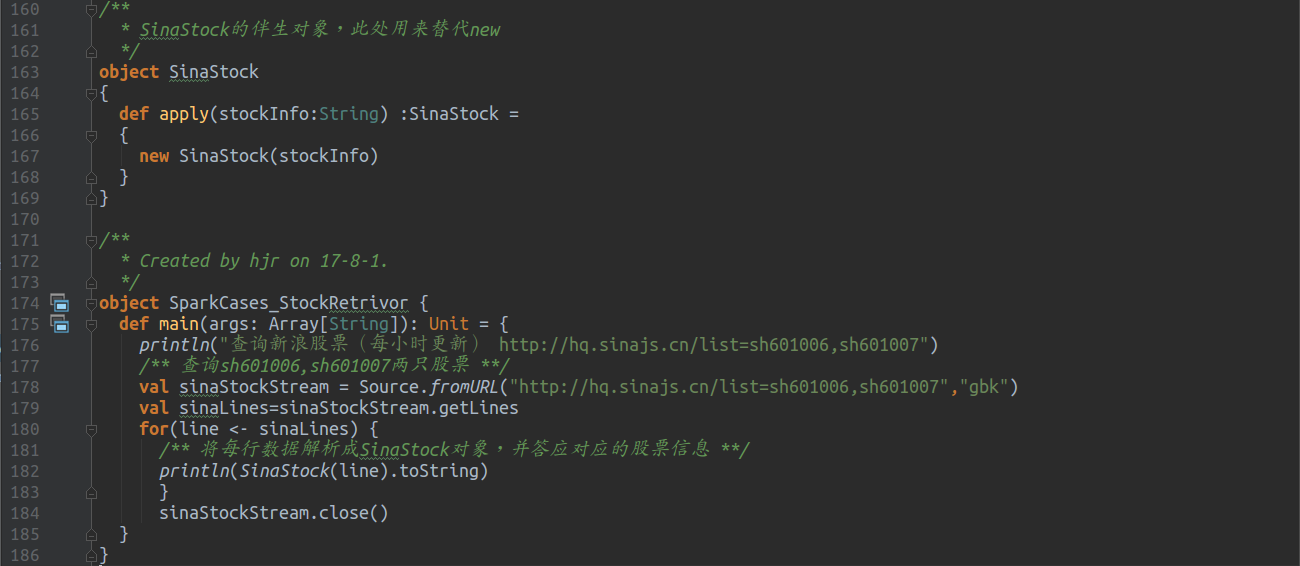
5.3 Spark Streaming编程
数据接口调试完毕,股票数据也解析好了,下面就开始Streaming。Spark Streaming一定会涉及数据源,且该数据源是一个主动推送的过程,即spark被动接受该数据源的数据进行分析。但Sina的接口是一个很简单的HttpResponse,无法主动推送数据,所以我们需要实现一个Custom Receiver,可参考 http://spark.apache.org/docs/latest/streaming-custom-receivers.html
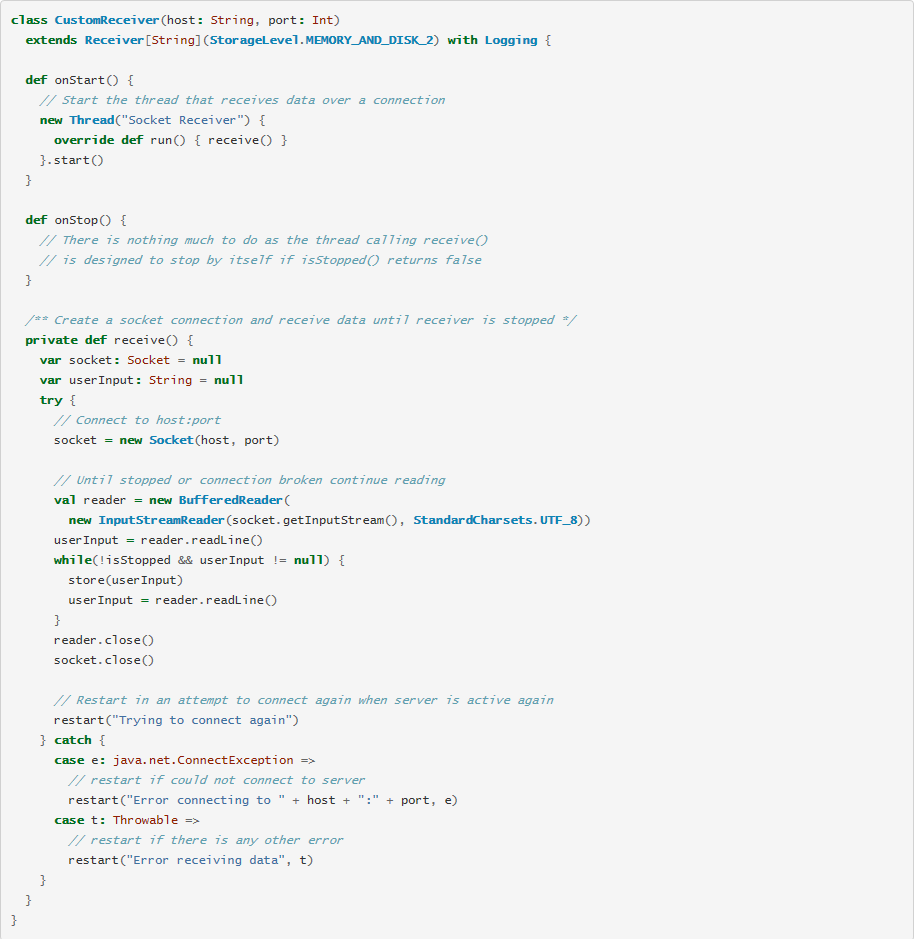
下面是具体的代码,其实定制化一个Receiver简单来说就是实现onStart/onStop。onStart用来初始化资源,给获取数据做准备,获取到的数据用store发送给SparkStreaming即可;onStop用来释放资源
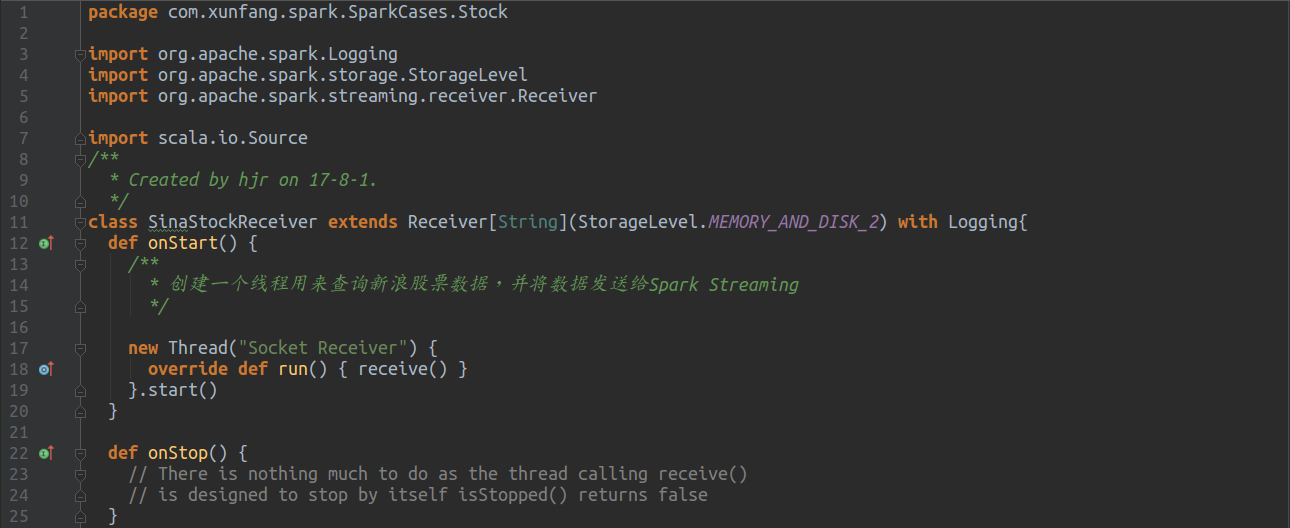
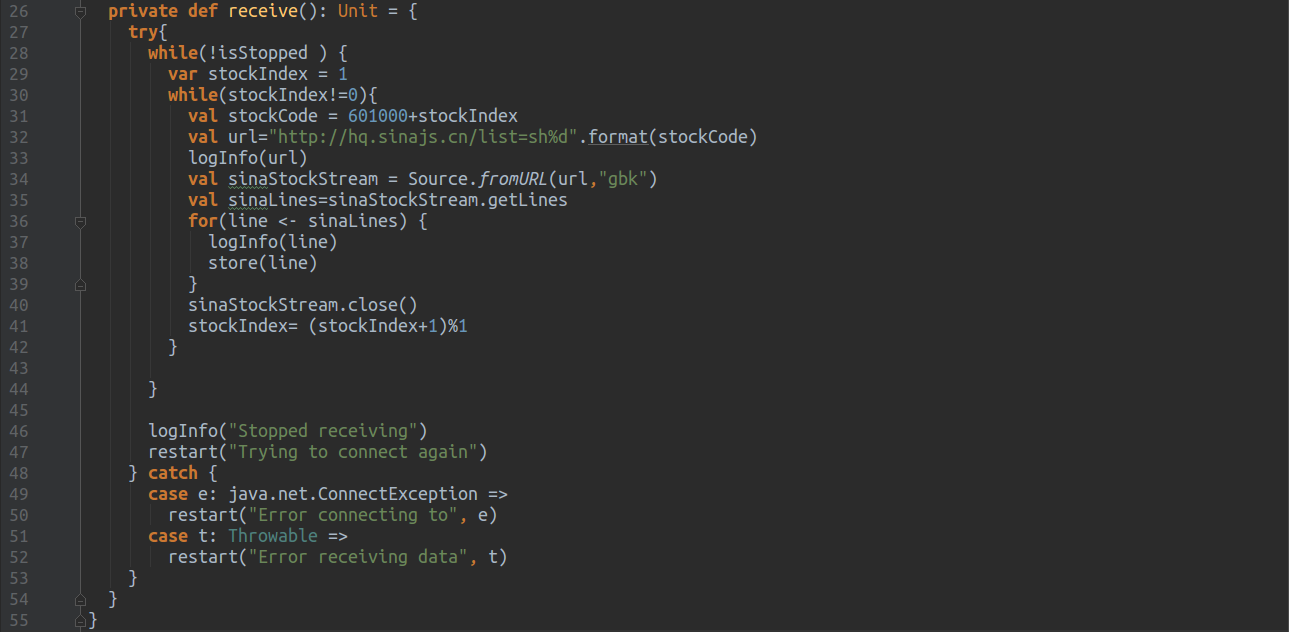
Receiver搞定之后就可以开始编写股票预测的main函数了,股票预测的方法之一,就是统计一段时间内股票上涨的次数,并展示上涨次数TopN的股票信息,但本文一切从简,并没有实现全部的功能,只是统计了股票上涨的次数,也就是对上涨与否进行WordCount。
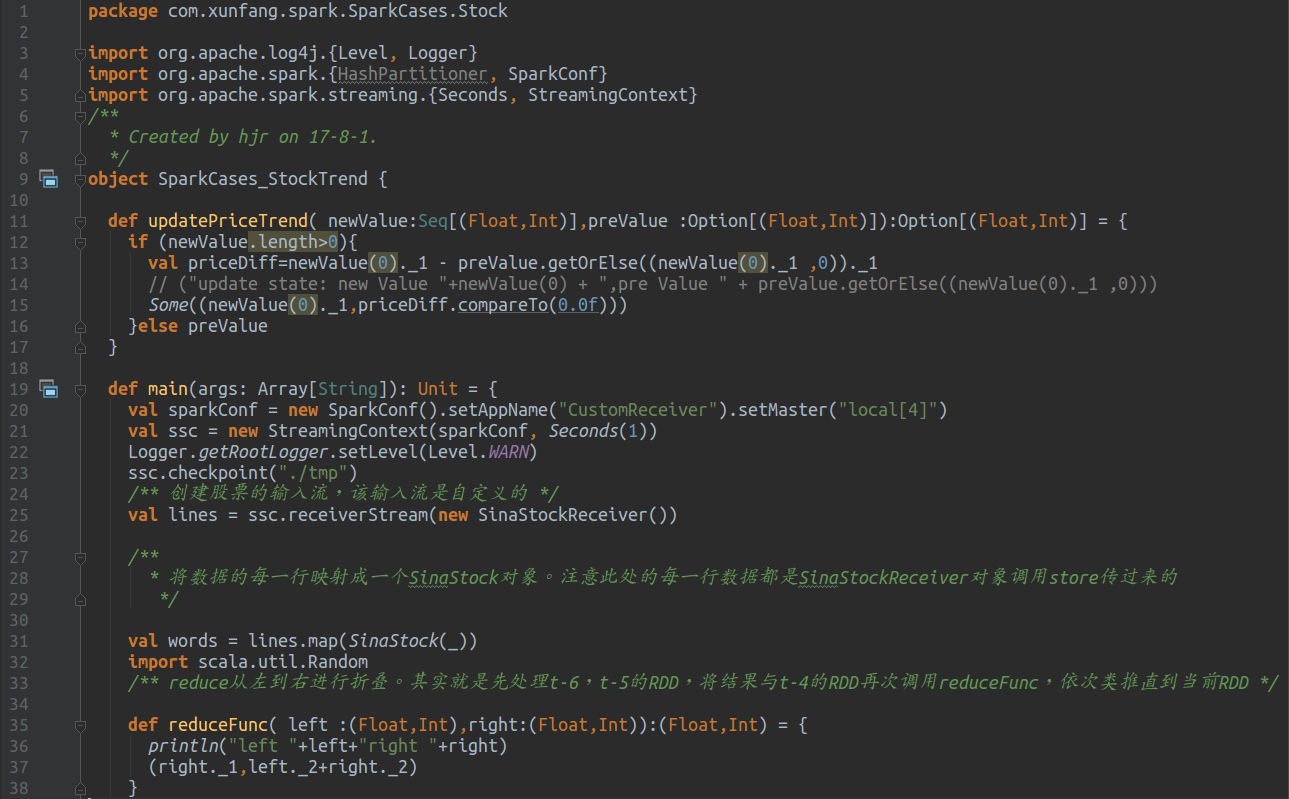
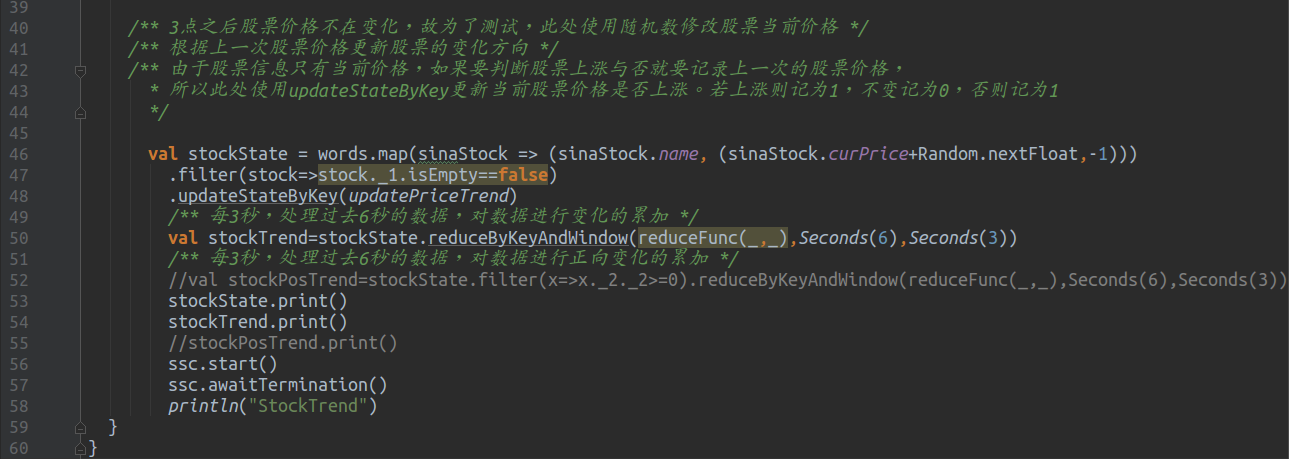
5.4 运行结果分析
由于ssc的时间间隔为1,所以每秒都会查询大同煤业的股票数据,这就是下面每个Time打印的第一行数据(因为stockState先进行print,所以每次查询的股票数据是第一行);又因为slide设置为3,所以每隔3秒会进行reduceFunc计算,该函数处理windowsize个RDD(此处设置为6),对这6个RDD按照时间先后顺序进行reduce。
需要特别说明的是spark的reduce默认从左到右进行fold(折叠),从最左边取两个数进行reduce计算产生临时结果,再与后面的数据进行reduce,以此类推进行计算,其实就是foldLeft。
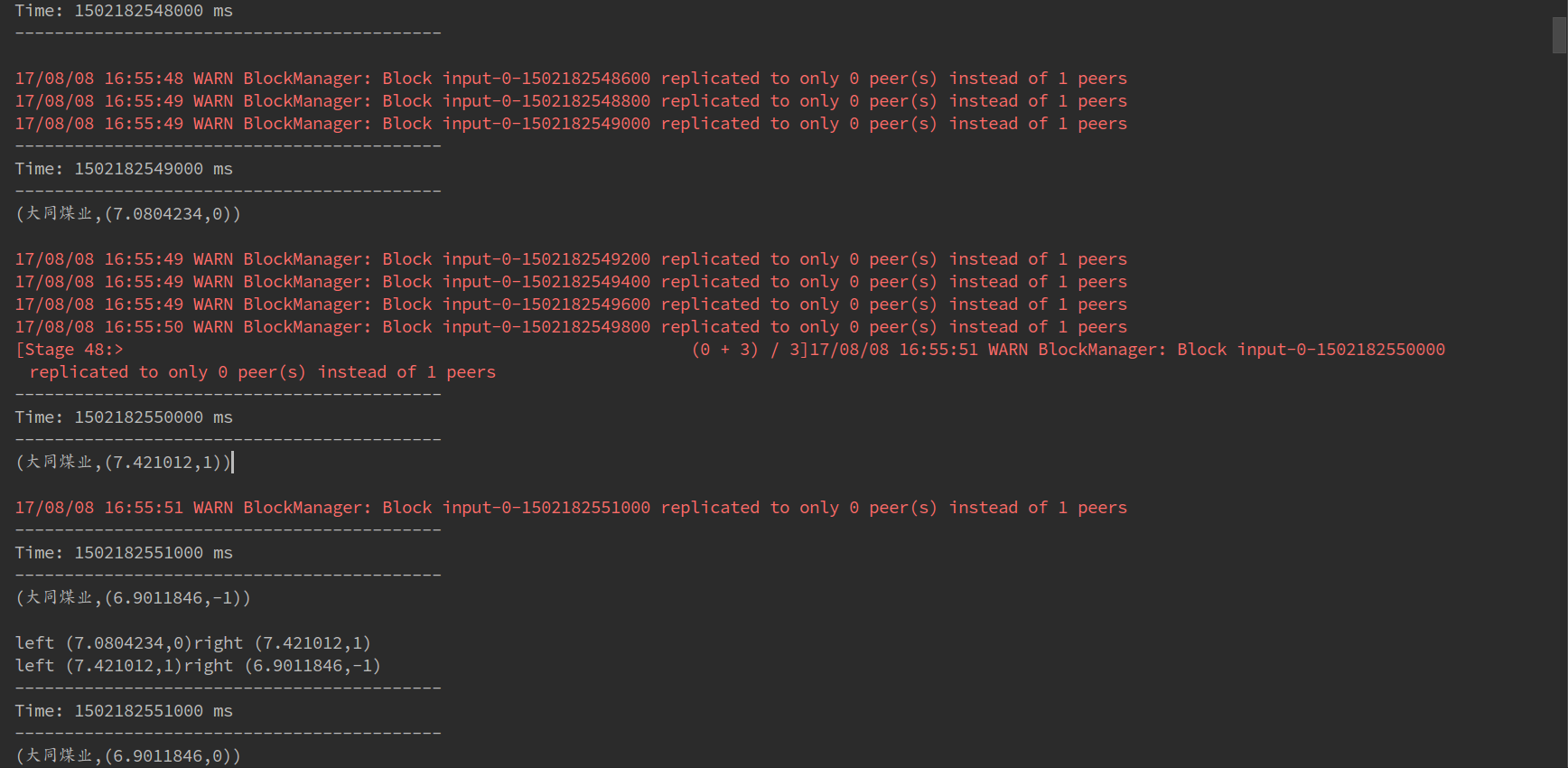

六、总结
实验针对新浪股票数据接口,基于Spark Streaming实时接收并处理数据,并对特定的某一支股票走势进行简单预测。使学生能够对Spark Streaming流式计算框架有所全面的了解,并掌握DStreams抽象的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号