

针对seata设计思想的理解:
Seata介绍:
1, Seata(原名Fescar) 是阿里2018年开源的分布式事务的框架。Fescar的开源对分布式事务框架领域影响 很大。作为开源大户,Fescar来自阿里的GTS,经历了好几次双十一的考验,一经开源便颇受关注。后 来Fescar改名为Seata。Fescar虽然是二阶段提交协议的分布式事务,但是其解决了XA的一些缺点。XA是基于数据库实现分布式事务的协议,本质上和两阶段提交一样,需要数据库支持,MySQL
5.6以及以上版本支持此协议。
2, Seata的设计思想其实就是在以前两阶段提交(2PC)分布式事务,以及TCC 分布式事务的改进,还借用了队列+消息表事务最终一致性分布式事务的思想。所以要理解seata思想,无非就是理解它对以前那些分布式事务的改进点就行。因此有必要先理解 2PC 的缺点,TCC的缺点,以及队列+消息表事务最终一致性分布式事务的思想。
两阶段提交(2PC)的缺点:
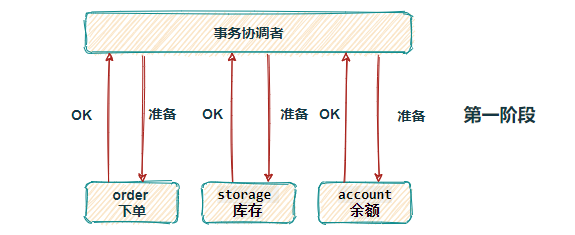
显而易见,在第一阶段,各个服务上的事务没有正式提交,就是做了修改操作,没有执行数据库commit操作,只是ok 准备提交,mysql事务隔离级别是提交读,因此各个服务所对应的订单表,库存表,余额表,都被锁住了,别的线程无法读。大大降低了并发效率。
继续看第二个阶段
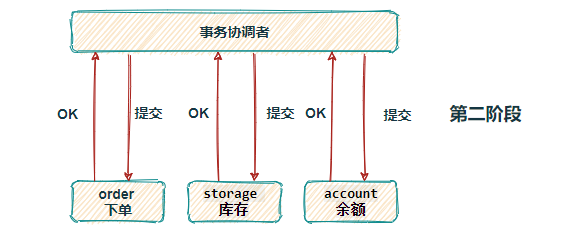
如果第一个阶段全部OK了,在第二个阶段才会正式执行数据库commit操作,数据库会释放锁资源。如果在第一个阶段有某个服务执行异常,或者失败了,会在第二个阶段通知各个服务进行数据库回滚操作。
TCC缺点:
1, 所谓的 TCC 编程模式,也是两阶段提交的一个变种,不同的是 TCC 为在业务层编写代码实现的两阶段提交。TCC 分别指 Try、Confirm、Cancel ,一个业务操作要对应的写这三个方法。
2, 以订单和扣库存为例,Try 阶段去占库存,Confirm 阶段则实际扣库存。要理解这句话,做如下说明:在try阶段,下单服务把订单状态不直接修改成已经下单,修改成正在下单,并且提交数据库的commit操作,库存服务不直接把库存表的库存数字段的数据直接从100减去1,而是预先增设一个库存冻结数字段,把1纳入到库存冻结数字段。此时可以保证另外的线程,在查询库存的时候,需要查询库存数字段(100)和库存冻结数字段(1),做减法,得到真实的库存99。然后到了第二个阶段,如果第一个阶段都OK的话,才会真实的把订单状态修改成已经下单,把库存表库存数字段的数据直接减成99,把冻结字段1改成0。如果第一个阶段不OK的话,会进行补偿机制,只需要把库存冻结字段里面的1改成0,而不需要动库存数字段。意味在失败情况下的整个过程里面,库存表里面的库存数100始终都没有动过,保证了数据的一致性。
3, 分析以上的设计思想,不存在资源阻塞的问题,因为每个方法都直接进行事务的提交,一旦出现异常通过则 Cancel 来进行补偿,这种补偿式是业务上的补偿,跟数据库的回滚操作是一个功效。这也就是常说的补偿性事务。缺点很明显,对业务的侵入太强。需要额外的增加冻结库存数字段,和修改冻结库存数字段的方法。
队列+消息表事务最终一致性分布式事务缺点:
1, 思想很好,缺点:程序员使用的时候,过于复杂,增加开发成本。不再在此多描述。
Seata分布式事务的基本设计思想:
1, 沿用了2PC两阶段提交思想,同时也会像TCC那样,在第一个阶段会执行数据库的commit操作,可是不会像TCC那样,采用冻结数据的方式,去完成第一个阶段(try)。 而是真实的在第一个阶段修改了数据,并且执行数据库的commit操作。比如:下单操作,修改订单为已经下单,执行数据库的commit操作,到库存服务,真实的把库存减去1,执行数据库commit操作。那问题来了,如果在第一个阶段某个服务异常或者失败了,如何回滚,或者做像TCC做业务上的补偿机制。Seata针对这个问题,会借用队列+消息表事务最终一致性分布式事务的思想。就是会在订单表新建一张表 undo_log日志表(快照表)。库存服务创建一张 undo_log日志表(快照表),在第一个阶段,会各自记录订单表和库存表的数据修改,这些记录操作,不是由程序员去编写程序做记录,而是由seata去解析sql的方式去做记录。undo_log表同时还会记录全局事务ID和各个服务的分支事务ID,一个全局事务ID包含多个服务分支事务的ID。到了第二个阶段,如果第一个阶段有某个服务发生异常或者失败,到了第二个阶段,会始终贯穿一个全局事务,根据这个全局事务ID,去找到各自的服务,查询undo_log表的修改数据,得到这些修改数据,就可以做数据库的逆向操作,就是把修改好的数据,又恢复成http请求前的样子。如果在第一个阶段都是OK的话,在第二个阶段,只需要把各种服务里面的undo_log表里面的修改数据删除掉就行了。
2, 以上的seata思想流程做得很完整,光完整还不够,还要严谨,seata在第一个阶段的时候,当业务代码修改业务数据的时候,seata同时会分析业务数据操作的sql,并且把修改数据保存的unlog日志表里面,这几个操作是要保证在本地的一个事务里面去完成,不能出现业务数据表做了修改,而修改数据没有纳入unlog表的情况。看下图表示第一个阶段
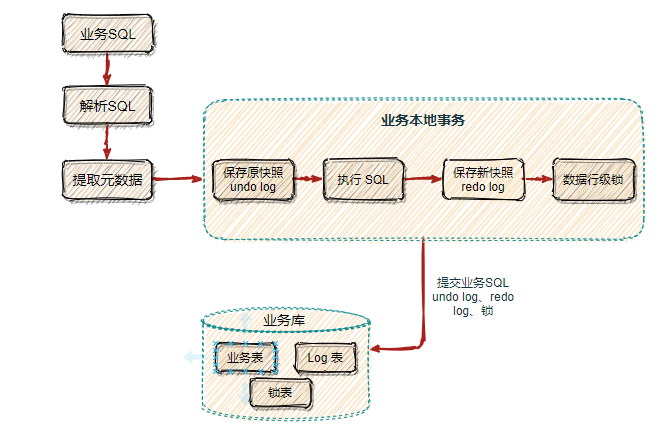
看了这个图可以看出,seata先会解析sql,得到修改的元数据,把修改的元数据保存undo.log快照表到执行sql 把业务数据到业务表里面都是在一个本地事务里面。
3, 总体看seata,它分为两大角色:
(TC): 全局事务协调者。用来协调全局事务和各个分支事务(不同服务)的状态, 驱动全局事务和各个分支事务的回滚或提交。
(RM): 资源管理者。一般指业务数据库代表了一个分支事务(Branch Transaction),管理分支事务与 TC 进行协调注册分支事务并且汇报分支事务的状态,驱动分支事务的提交或回滚。
另外seata还利用了异步队列来完成那些完整的流程。通过上面的分析,那些流程是怎么协调完成的呢?靠的就是上面的角色,加异步队列来完成。比如:订单服务和库存服务的事务会由各自的RM(资源管理者,分支事务)去管理,统一由TC(全局事务协调者)去分派和协调。如果第一个阶段都是OK的,那么订单的RM(资源管理者,分支事务)和库存的RM(资源管理者,分支事务)。会注册到TM(全局事务协调者)为OK状态。那么到了第二个阶段,TM从注册中心发觉都是OK的,会利用异步队列来通知各个订单服务对应的RM和库存对应的RM。 把各自本地的unlog日志表的信息删除掉。如果第一个阶段某个RM失败了。意味着无法注册到TM为OK状态,那么TM会通过异步队列,通知各自的RM进行数据恢复到http请求请的样子。最后看图:
如果都是OK的。
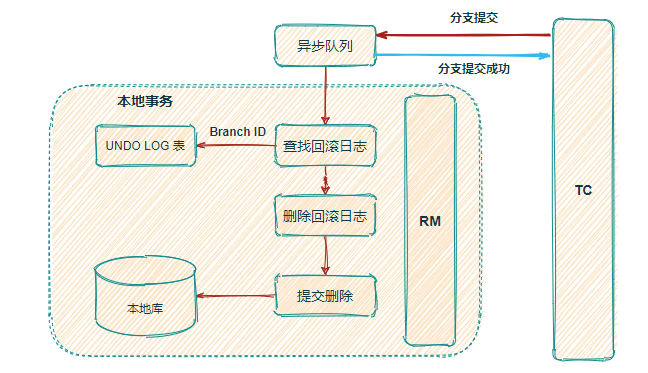
如果是失败的,要进行数据恢复操作,那么流程图会复杂很多,如下:
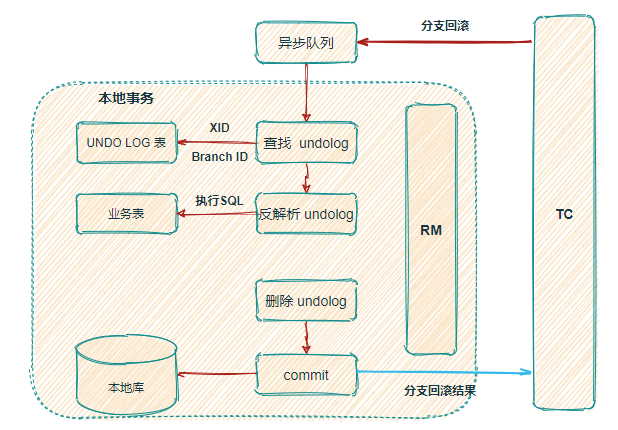
看上面的图,多了一个很关键的操作,就是 反解析 undolog,执行Sql。进行数据恢复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号