
Nginx 采用的是多进程(单线程) & 多路IO复用模型,使用了 I/O 多路复用技术的 Nginx,就成了”并发事件驱动“的服务器,同时使用sendfile等技术,最终实现了高性能。主要从以下几个方面讲述Nginx高性能机制:
- Nginx master-worker进程机制。
- IO多路复用机制。
- Accept锁及REUSEPORT机制。
- sendfile零拷贝机制
1、Nginx进程机制
1.1、Nginx进程机制概述
许多web服务器和应用服务器使用简单的线程的(threaded)、或基于流程的(process-based)架构, NGINX则以一种复杂的事件驱动(event-driven)的架构脱颖而出,这种架构能支持现代硬件上成千上万的并发连接。
NGINX有一个主进程(master process)(执行特定权限的操作,如读取配置、绑定端口)和一系列工作进程(worker process)和辅助进程(helper process)。如下图所示:
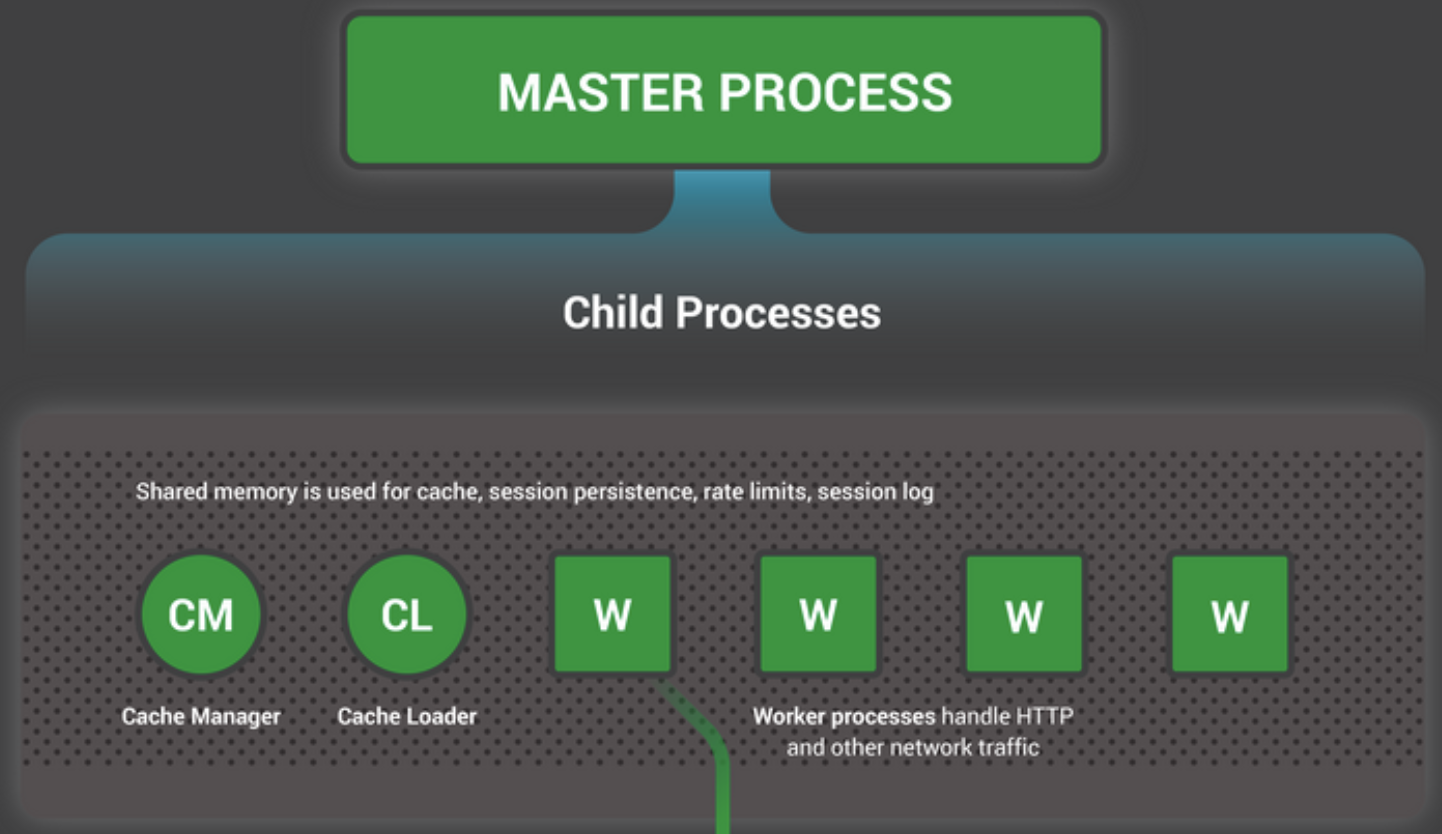
如下所示:
# service nginx restart * Restarting nginx # ps -ef --forest | grep nginx root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf nginx 32476 32475 0 13:36 ? 00:00:00 _ nginx: worker process nginx 32477 32475 0 13:36 ? 00:00:00 _ nginx: worker process nginx 32479 32475 0 13:36 ? 00:00:00 _ nginx: worker process nginx 32480 32475 0 13:36 ? 00:00:00 _ nginx: worker process nginx 32481 32475 0 13:36 ? 00:00:00 _ nginx: cache manager process nginx 32482 32475 0 13:36 ? 00:00:00 _ nginx: cache loader process
如上4核服务器所示,NGINX主进程创建了4个工作进程和2个缓存辅助进程(cachehelper processes)来管理磁盘内容缓存(on-disk content cache)。如果我们不配置缓存,那么就只会有master、worker两个进程,worker进程的数量,通过配置文件worker_process进行配置(一般worker_process数与服务器CPU核心数一致),如下所示:
$ cat nginx.conf|grep process worker_processes 3; $ ps -ef|grep nginx 501 33758 1 0 四03上午 ?? 0:00.02 nginx: master process ./bin/nginx 501 56609 33758 0 11:58下午 ?? 0:00.00 nginx: worker process 501 56610 33758 0 11:58下午 ?? 0:00.00 nginx: worker process 501 56611 33758 0 11:58下午 ?? 0:00.00 nginx: worker process
NGINX根据可用的硬件资源,使用一个可预见式的(predictable)进程模型:
- Master主进程执行特权操作,如读取配置和绑定端口,还负责创建少量的子进程(以下三种进程)。
- Cache Loader缓存加载进程在启动时运行,把基于磁盘的缓存(disk-based cache)加载到内存中,然后退出。缓存加载进程的调度很谨慎,所以其资源需求很低。
- Cache Manager缓存管理进程周期性运行,并削减磁盘缓存(prunes entries from the disk caches)来使缓存保持在配置的大小范围内。
- Worker工作进程才是执行所有实际任务的进程:处理网络连接、读取和写入内容到磁盘,与upstream服务器通信等。
多数情况下,NGINX建议每1个CPU核心都运行1个工作进程,使硬件资源得到最有效的利用。你可以在配置中设置如下指令:
worker_processes auto;
当NGINX服务器运行时,只有Worker工作进程在忙碌。每个工作进程都以非阻塞的方式处理多个连接,以减少上下文切换的开销。 每个工作进程都是单线程且独立运行的,抓取并处理新的连接。进程间通过共享内存的方式,来共享缓存数据、持久性会话数据(session persistence data)和其他共享资源。
1.2、Master进程
nginx启动后,系统中会以daemon的方式在后台运行,后台进程包含一个master进程和多个worker进程。当然nginx也是支持多线程的方式的,只是我们主流的方式还是多进程的方式,也是nginx的默认方式。我们可以手动地关掉后台模式,让nginx在前台运行,并且通过配置让nginx取消master进程,从而可以使nginx以单进程方式运行。生产环境下肯定不会这么做,所以关闭后台模式,一般是用来调试用的。
master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。
1.3、Worker进程
每一个Worker工作进程都是使用NGINX配置文件初始化的,并且主节点会为其提供一套监听套接字(listen sockets)。 worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。
所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。所以Worker工作进程通过等待在监听套接字上的事件(accept_mutex和kernel socketsharding)开始工作。事件是由新的incoming connections初始化的。这些连接被会分配给状态机(statemachine)—— HTTP状态机是最常用的,但NGINX还为流(原生TCP)和大量的邮件协议(SMTP,IMAP和POP3)实现了状态机。
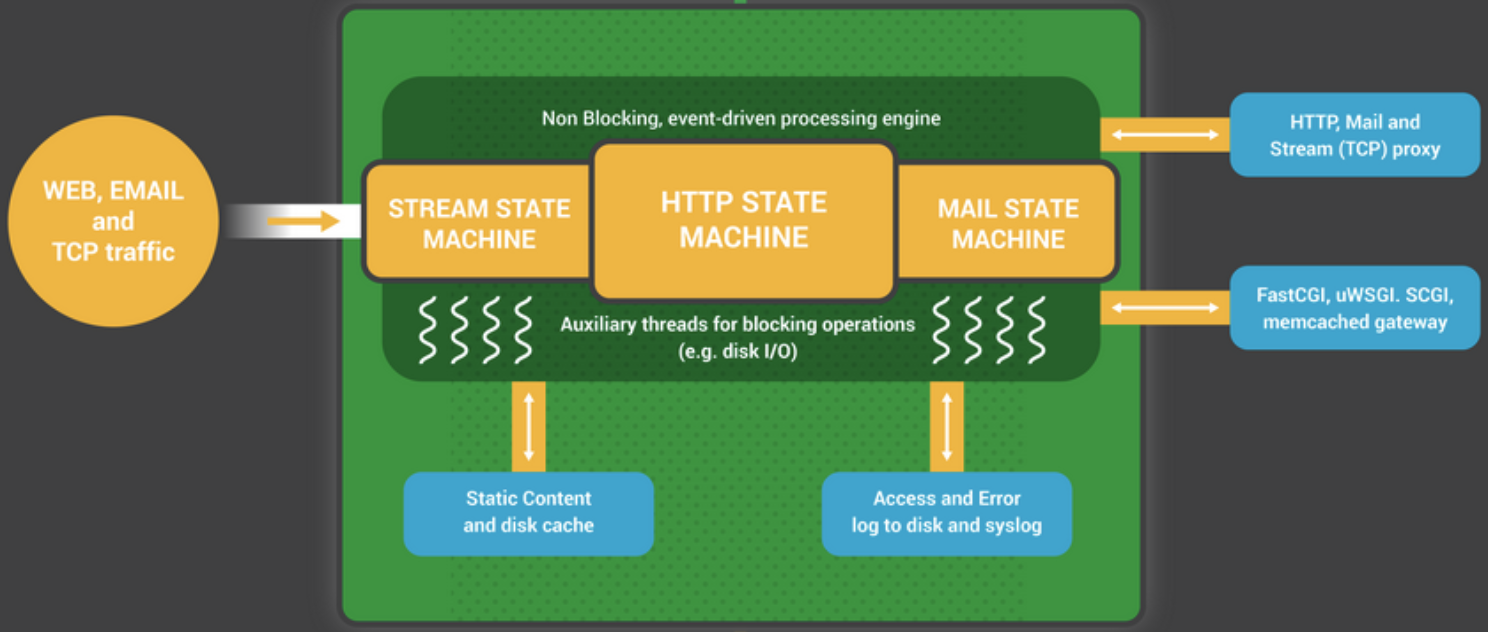
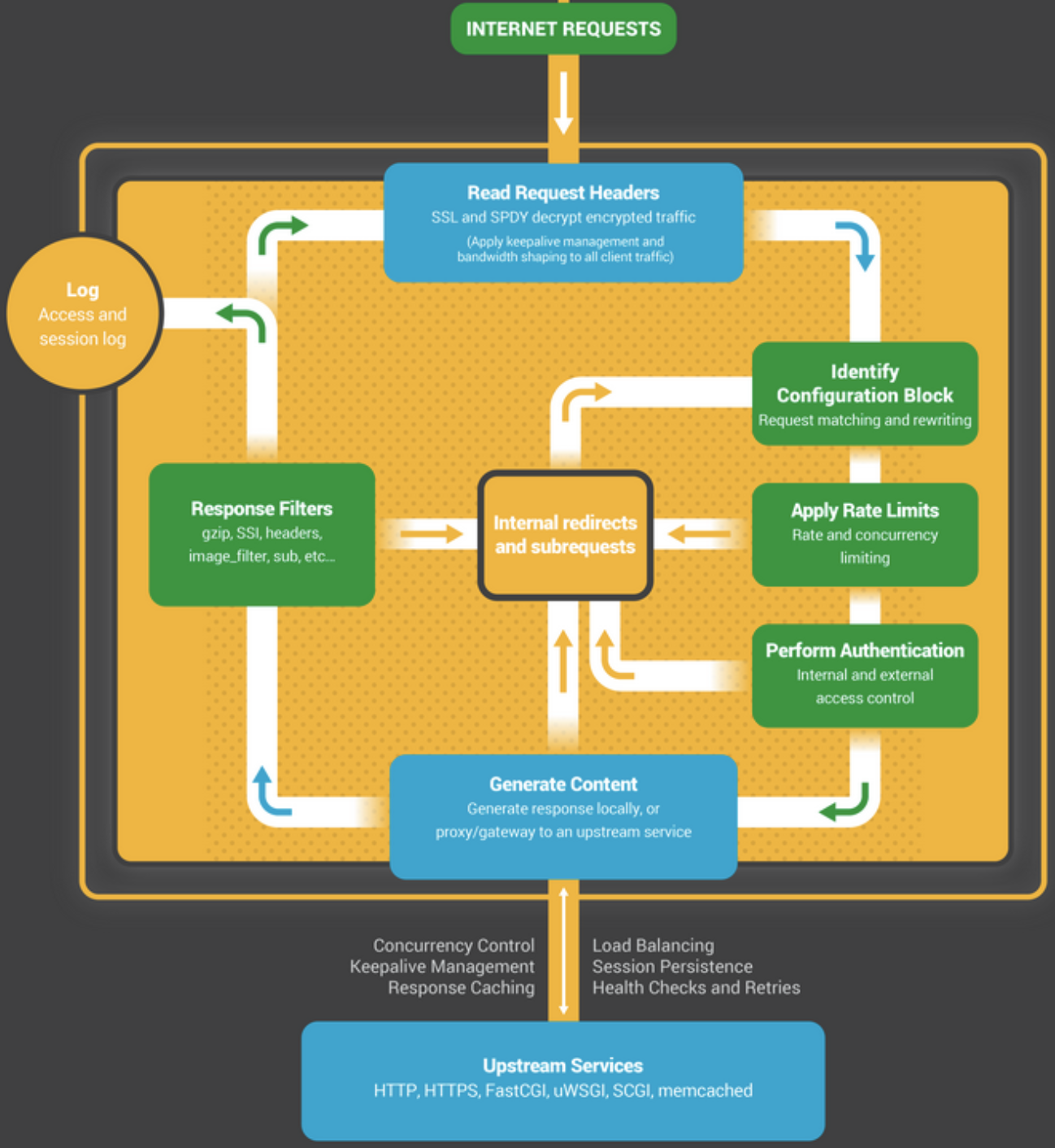
状态机本质上是一组告知NGINX如何处理请求的指令。大多数和NGINX具有相同功能的web服务器也使用类似的状态机——只是实现不同。如下图所示,就是一个HTTP请求的生命周期:
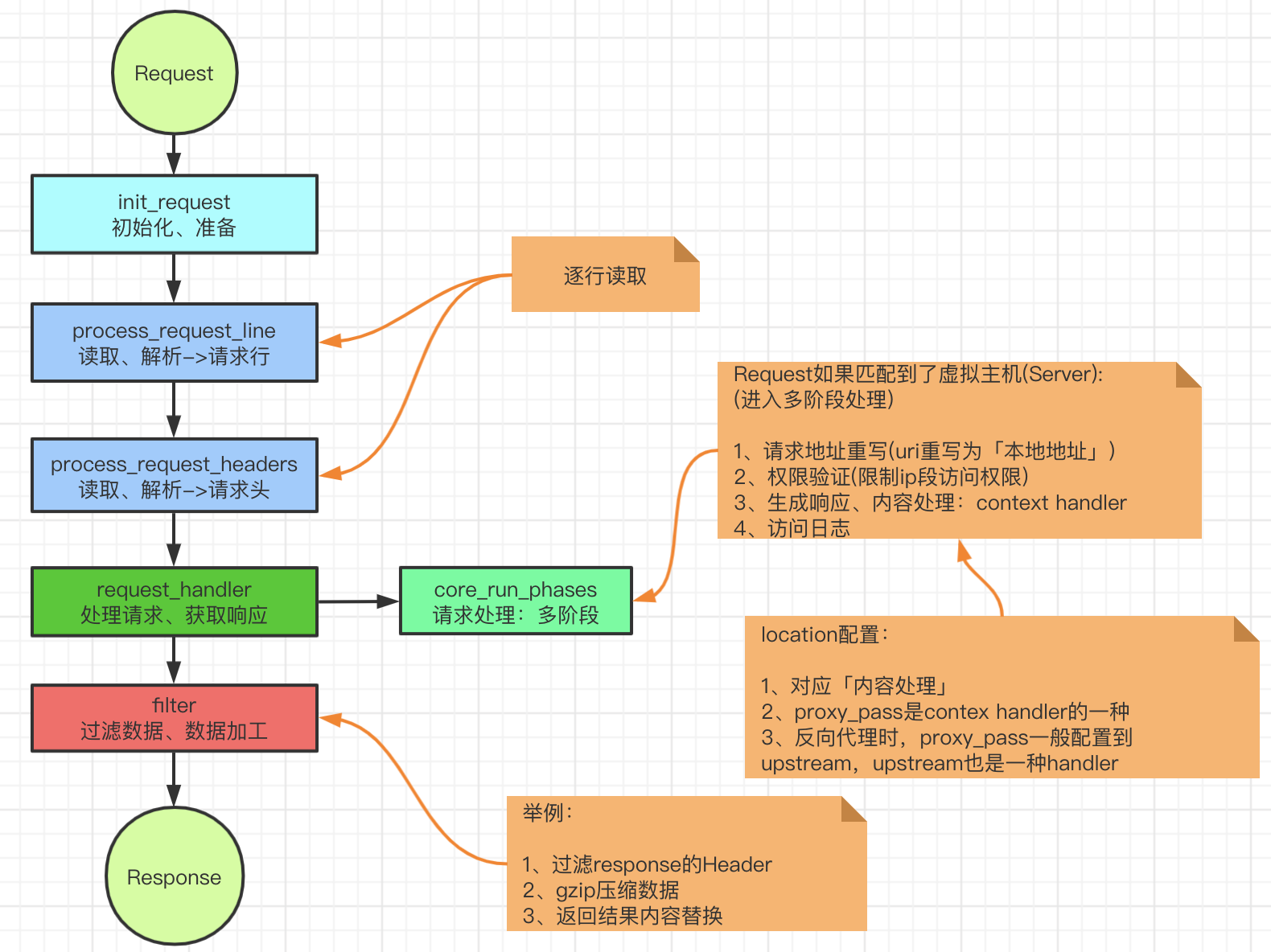
关于Nginx的处理流程,也可以如下图所示:
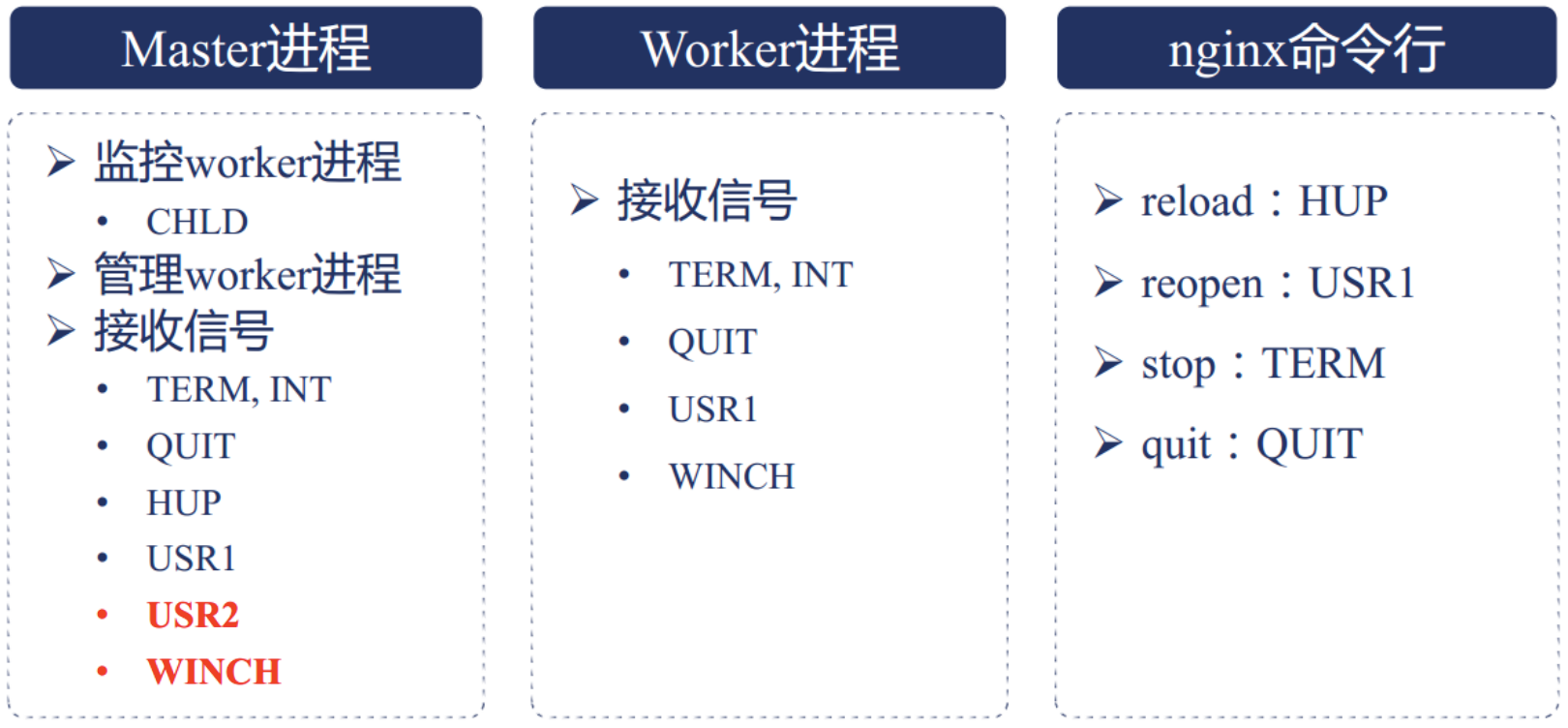
1.4、 Nginx信号管理
Nginx可以通过信号的方式进行管理,信号在Master-Worker的关系以及对应的命令行,如下图所示:
其具体使用方式为:
# 以下SIG有无前缀含义一样,如SIGHUP和HUP等同 kill -信号 进程号
Nginx主要是通过信号量来控制Nginx,所以我们常用的Nginx命令也都可以通过信号的方式进行执行。具体含义如下所示:
The master process of nginx can handle the following signals:
SIGINT, SIGTERM Shut down quickly. //nginx的进程马上被关闭,不能完整处理正在使用的nginx的用户的请求,等同于 nginx -s stop
SIGHUP Reload configuration, start the new worker process with a new con‐figuration, and gracefully shut down
old worker processes. //nginx进程不关闭,但是重新加载配置文件。等同于nginx -s reload
SIGQUIT Shut down gracefully. //优雅的关闭nginx进程,在处理完所有正在使用nginx用户请求后再关闭nginx进程,等同于nginx -s quit
SIGUSR1 Reopen log files. //不用关闭nginx进程就可以重读日志,此命令可以用于nginx的日志定时备份,按月/日等时间间隔分割有用等同于nginx -s reopen
SIGUSR2 Upgrade the nginx executable on the fly. //nginx的版本需要升级的时候,不需要停止nginx,就能对nginx升级
SIGWINCH Shut down worker processes gracefully. //配合USR2对nginx升级,优雅的关闭nginx旧版本的进程。
While there is no need to explicitly control worker processes normally, they support some signals too:
SIGTERM Shut down quickly.
SIGQUIT Shut down gracefully.
SIGUSR1 Reopen log files.
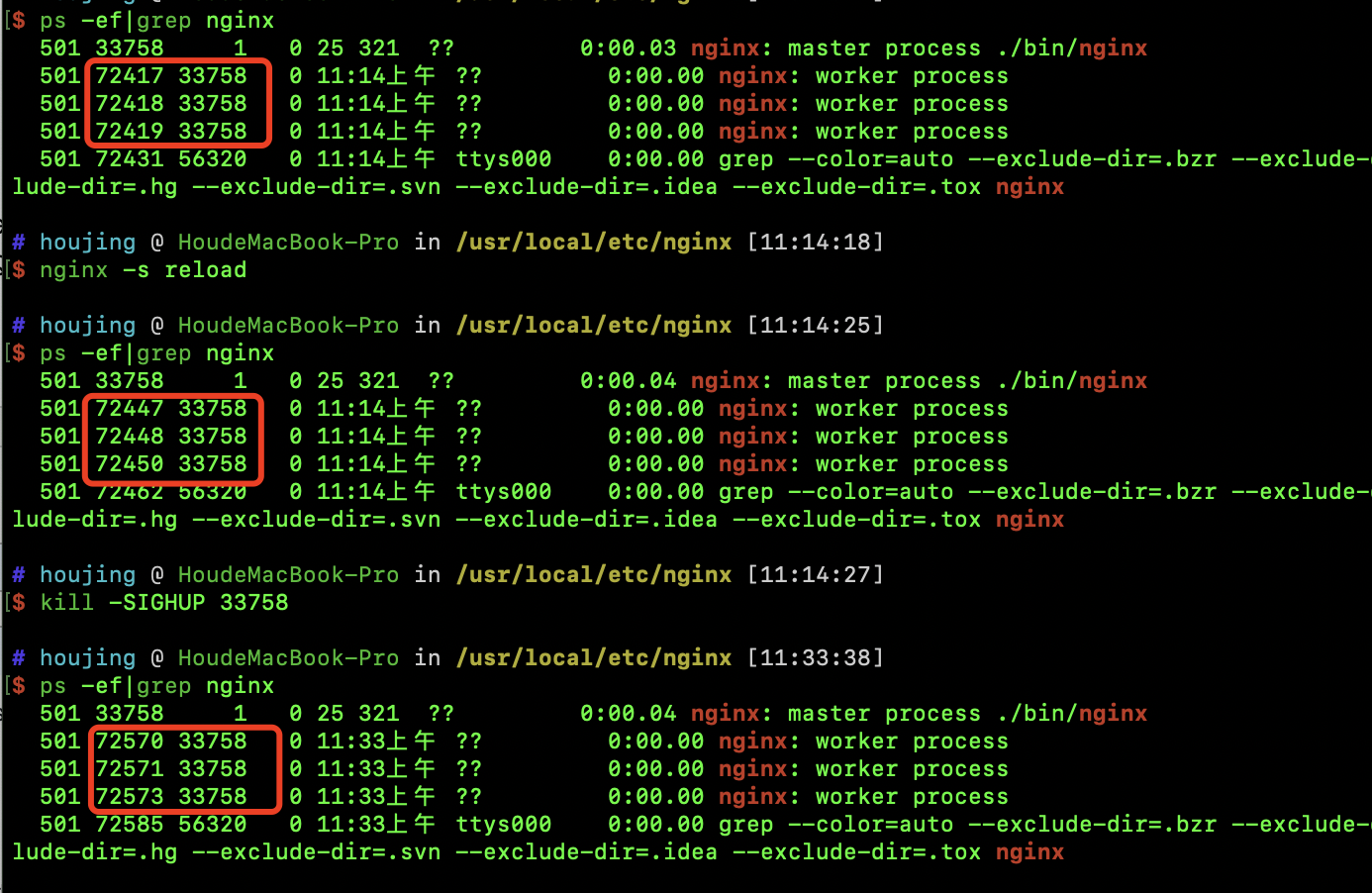
1.4.1、配置热加载Reload
如下图所示,NGINX的进程体系结构具有少量的Worker工作进程,因此可以非常有效地更新配置,甚至可以更新NGINX二进制文件本身。
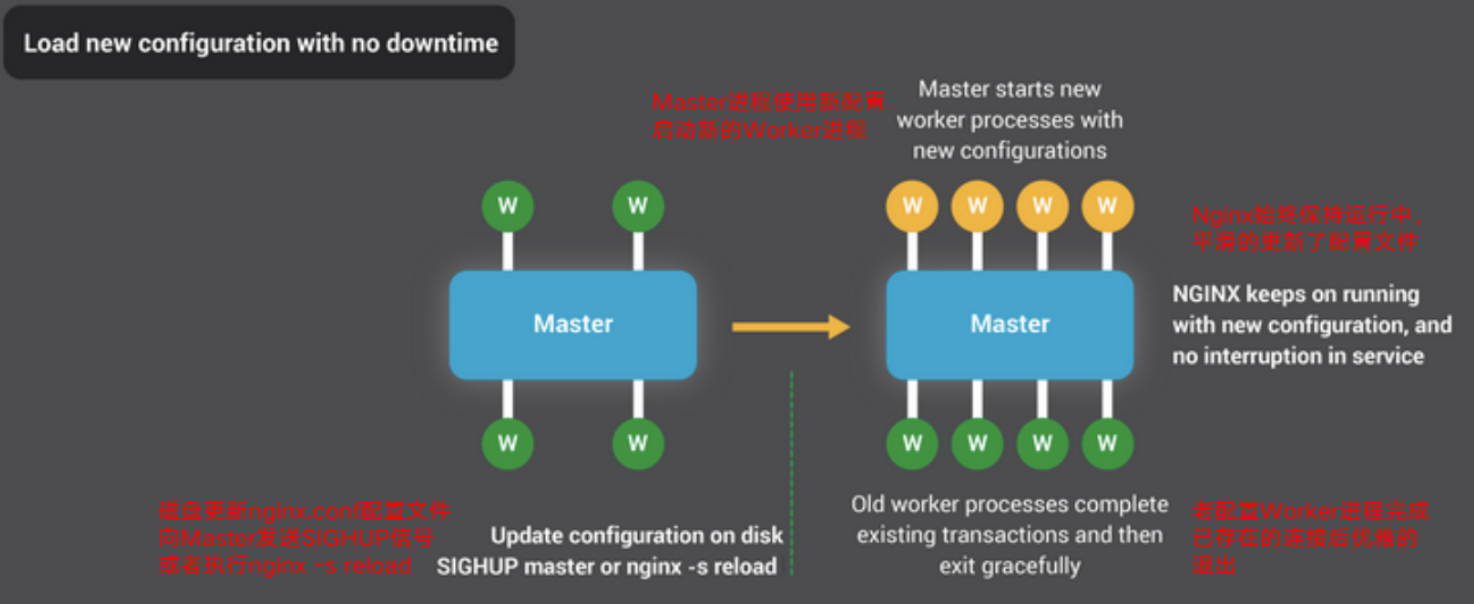
更新NGINX配置是一个非常简单,轻量且可靠的操作。它通常仅意味着运行nginx -s reload命令,该命令检查磁盘上的配置并向主进程发送SIGHUP信号。当主进程收到SIGHUP时,它将执行以下两项操作:
- 重新加载配置并派生一组新的工作进程。这些新的工作进程立即开始接受连接和处理流量(使用新的配置设置)。
- 指示旧工作进程正常退出。工作进程停止接受新连接。当前的每个HTTP请求完成后,工作进程就会干净地关闭连接(即,没有持久的keepalive)。一旦所有连接都关闭,工作进程将退出。
此重新加载过程可能会导致CPU和内存使用量的小幅上升,但是与从活动连接中加载资源相比,这通常是察觉不到的。您可以每秒多次重载配置(许多NGINX用户正是这样做的)。即使当有许多版本NGINX工作进程等待连接关闭时也很少有问题出现,而且实际上这些连接很快被处理完并关闭掉。
详细过程如下:
- 向master进程发送HUP信号(reload)命令
- master进程校验配置语法是否正确
- master进程打开新的监听端口
- master进程用新配置启动新的worker子进程
- master进程向老worker子进程发送QUIT信号
- 老woker进程关闭监听句柄,处理完当前连接后结束进程
如下图所示,所有的Worker进程都是新开启的进程:
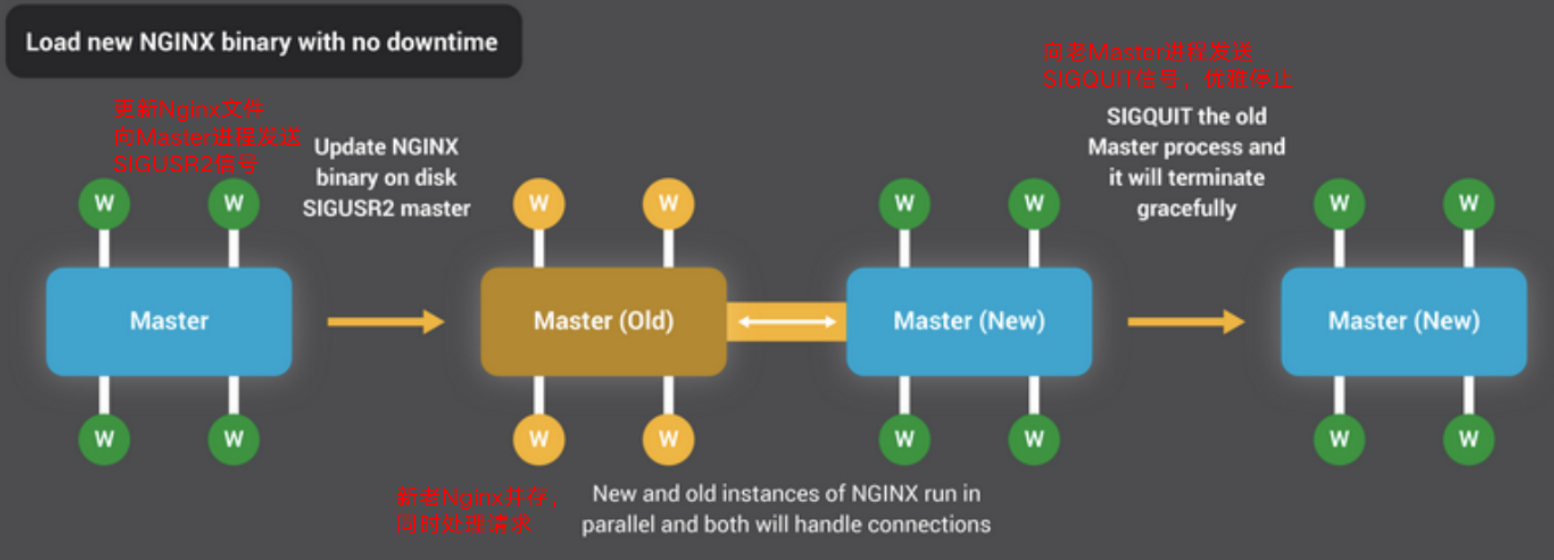
1.4.2、Nginx平滑升级
Nginx可以支撑无缝平滑升级,即通过信号SIGUSR2和SIGWINCH,NGINX的二进制升级过程实现了高可用性:您可以动态升级软件,而不会出现断开连接,停机或服务中断的情况。
二进制升级过程与正常配置热加载的方法类似。一个新的NGINX主进程与原始主进程并行运行,并且它们共享侦听套接字。这两个进程都是活动的,并且它们各自的工作进程都处理流量。然后,您可以向旧的主机及其工作人员发出信号,使其优雅地退出,如下图所示:
如下图所示示例:
第一阶段新老Master、Worker共存,同时新Master也是老Master的一个子进程。

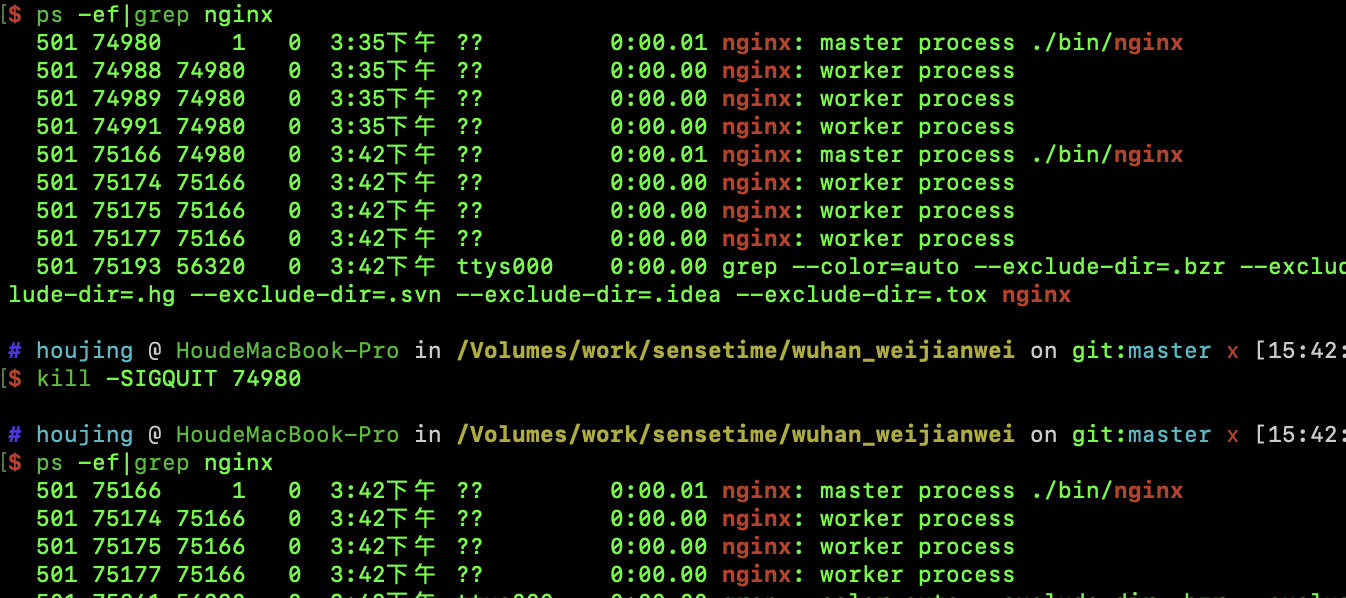
第二阶段,新Nginx替代老Nginx提供服务。如下所示通过SIGWINCH信号停老Worker服务,但是老Master还在,可以直接kill SIGQUIT掉master。

也可以通过直接发送SIGQUIT信号,同时杀掉所有老Master、Worker:
2、IO多路复用(NIO)
2.1、IO模型
Nginx是基于NIO事件驱动的,是非阻塞的,还有很多中间件也是基于NIO的IO多路复用,如redis、tomcat、netty、nginx。
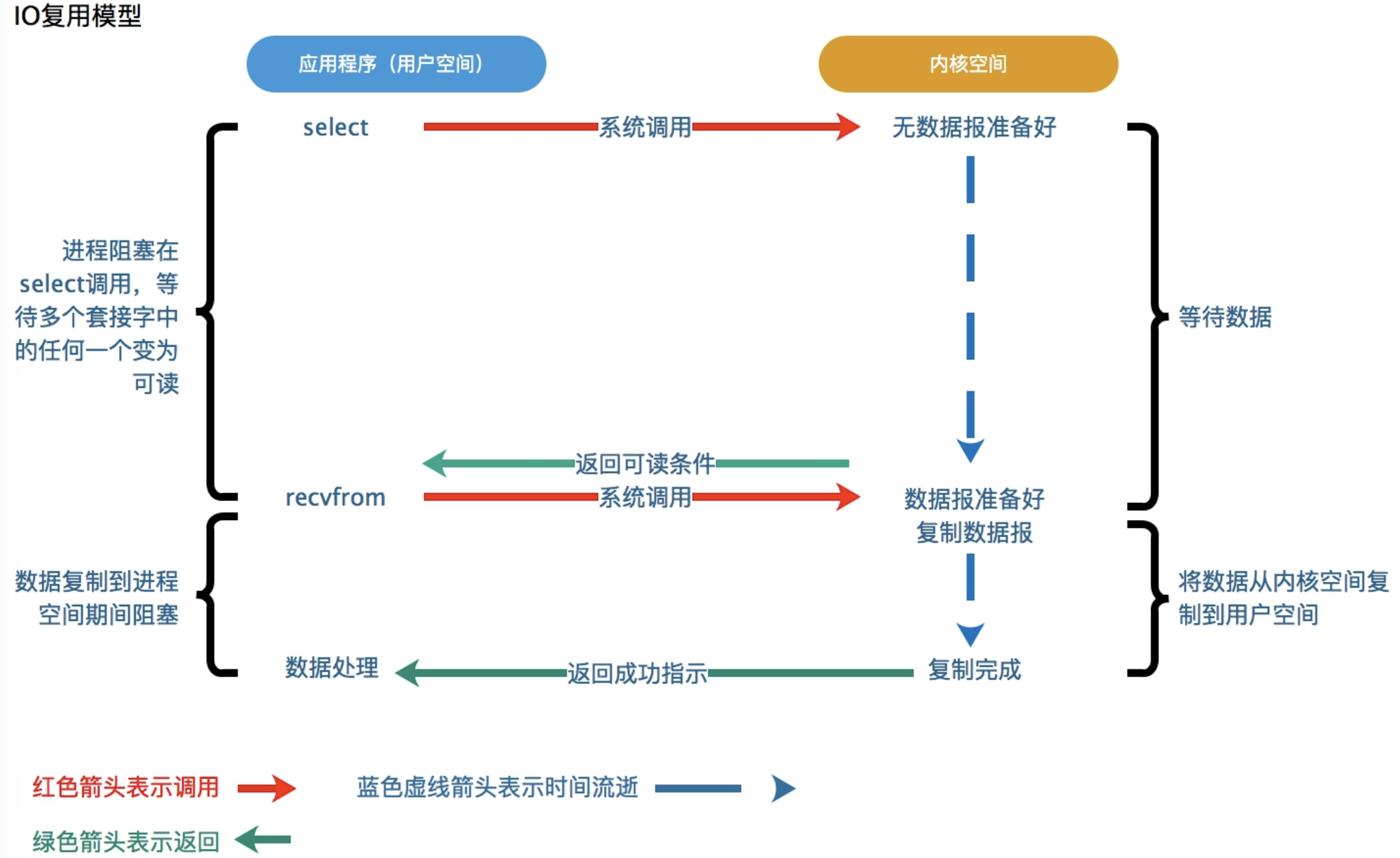
I/O复用模型会用到select、poll、epoll函数,在这种模型中,这时候并不是进程直接发起资源请求的系统调用去请求资源,进程不会被“全程阻塞”,进程是调用select或poll函数。进程不是被阻塞在真正IO上了,而是阻塞在select或者poll上了。Select或者poll帮助用户进程去轮询那些IO操作是否完成。
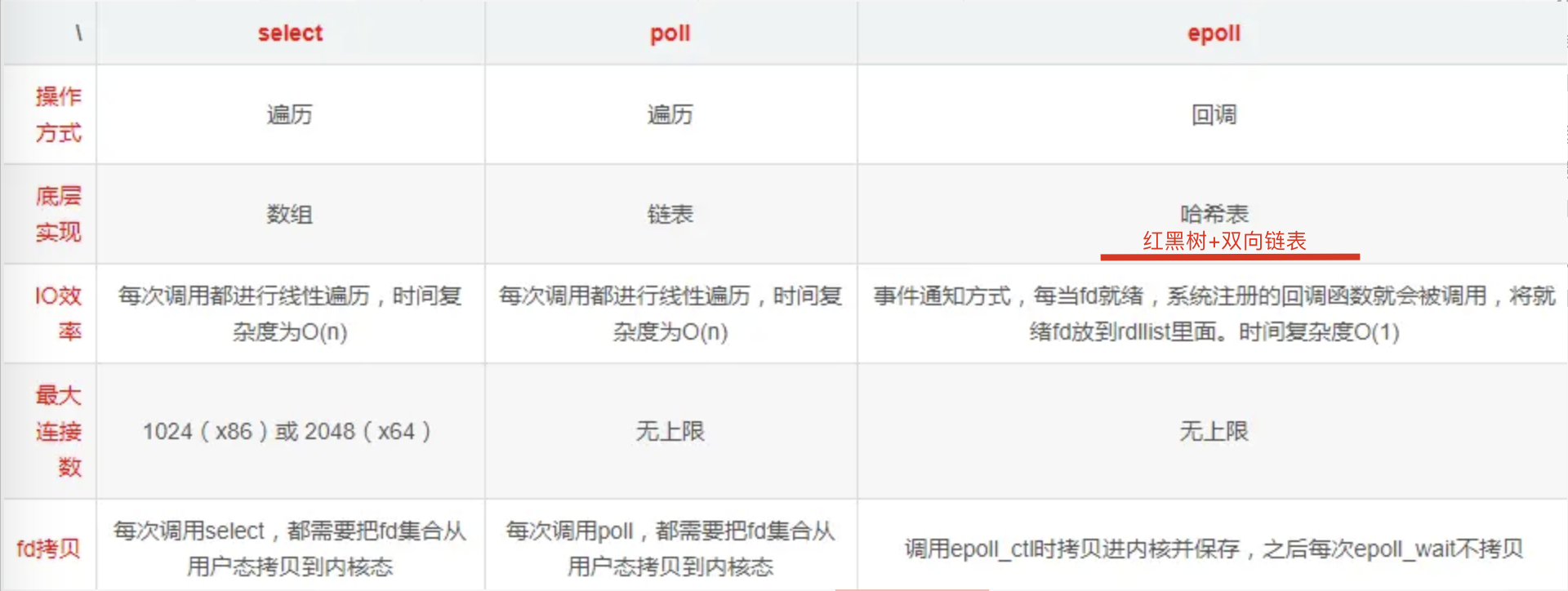
- select:基于数组实现,最多支持1024路IO。
- poll:基于链表实现IO管理无限制,可以超过1024,没有IO量的限制。
- epoll:linux 2.6以上才支持,是基于红黑树+链表,拥有更高的IO管理性能。
- kqueue:unix的内核支持,如Mac。
2.2、epoll
2.3.1、epoll概述
我们重点看看epoll,epoll提供了三个函数,epoll_create, epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄(也就是一个epoll instance);epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
① 执行 epoll_create
内核在epoll文件系统中建了个file结点,(使用完,必须调用close()关闭,否则导致fd被耗尽)
在内核cache里建了红黑树存储epoll_ctl传来的socket,
在内核cache里建了rdllist双向链表存储准备就绪的事件。
② 执行 epoll_ctl
如果增加socket句柄,检查红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,告诉内核如果这个句柄的中断到了,就把它放到准备就绪list链表里。所有添加到epoll中的事件都会与设备(如网卡)驱动程序建立回调关系,相应的事件发生时,会调用回调方法。
③ 执行 epoll_wait
立刻返回准备就绪表里的数据即可(将内核cache里双向列表中存储的准备就绪的事件 复制到用户态内存),当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
在io活跃数比较少的情况下使用epoll更有优势:因为链表时间复杂度o(n)。epoll同select、poll比较:
2.3.2、epoll水平触发与边缘触发
- Level_triggered(水平触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!!
- Edge_triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!
select(),poll()模型都是水平触发模式,信号驱动IO是边缘触发模式,epoll()模型即支持水平触发,也支持边缘触发,默认是水平触发。
具体可以参考博文:7层网络以及5种Linux IO模型以及相应IO基础
3、Accept锁及REUSEPORT机制
3.1、Accept锁
Nginx这种多进程的服务器,在fork后同时监听同一个端口时,如果有一个外部连接进来,会导致所有休眠的子进程被唤醒,而最终只有一个子进程能够成功处理accept事件,其他进程都会重新进入休眠中。这就导致出现了很多不必要的schedule和上下文切换,而这些开销是完全不必要的。
在Linux内核的较新版本中,accept调用本身所引起的惊群问题已经得到了解决,但是在Nginx中,accept是交给epoll机制来处理的,epoll的accept带来的惊群问题并没有得到解决(应该是epoll_wait本身并没有区别读事件是否来自于一个Listen套接字的能力,所以所有监听这个事件的进程会被这个epoll_wait唤醒。),所以Nginx的accept惊群问题仍然需要定制一个自己的解决方案。
accept锁就是nginx的解决方案,本质上这是一个跨进程的互斥锁,以这个互斥锁来保证只有一个进程具备监听accept事件的能力。
3.2、Accept锁实现(accept_mutex)
实现上accept锁是一个跨进程锁,其在Nginx中是一个全局变量,声明如下:
ngx_shmtx_t ngx_accept_mutex;
nginx是一个 1(master)+N(worker) 多进程模型:master在启动过程中负责读取nginx.conf中配置的监听端口,然后加入到一个cycle->listening数组中。init_cycle函数中会调用init_module函数,init_module函数会调用所有注册模块的module_init函数完成相关模块所需资源的申请以及其他一些工作;其中event模块的module_init函数申请一块共享内存用于存储accept_mutex锁信息以及连接数信息。
因此这是一个在event模块初始化时就分配好的锁,放在一块进程间共享的内存中,以保证所有进程都能访问这一个实例,其加锁解锁是借由linux的原子变量来做CAS,如果加锁失败则立即返回,是一种非阻塞的锁。加解锁代码如下:
ngx_uint_t ngx_shmtx_trylock(ngx_shmtx_t *mtx) { return (*mtx->lock == 0 && ngx_atomic_cmp_set(mtx->lock, 0, ngx_pid)); } #define ngx_shmtx_lock(mtx) ngx_spinlock((mtx)->lock, ngx_pid, 1024) #define ngx_shmtx_unlock(mtx) (void) ngx_atomic_cmp_set((mtx)->lock, ngx_pid, 0)
可以看出,调用ngx_shmtx_trylock失败后会立刻返回而不会阻塞。那么accept锁如何保证只有一个进程能够处理新连接呢?要解决epoll带来的accept锁的问题也很简单,只需要保证同一时间只有一个进程注册了accept的epoll事件即可。Nginx采用的处理模式也没什么特别的,大概就是如下的逻辑:
尝试获取accept锁 if 获取成功: 在epoll中注册accept事件 else: 在epoll中注销accept事件 处理所有事件 释放accept锁
我们知道,所有的worker进程均是由master进程通过fork() 函数启动的,所以所有的worker进程也就继承了master进程所有打开的文件描述符(包括之前创建的共享内存的fd)以及变量数据(这其中就包括之前创建的accept_mutex锁)。worker启动的过程中会调用各个模块的process_init函数,其中event模块的process_init函数中就会将master配置好的listening数组加入到epoll监听的events中,这样初始阶段所有的worker的epoll监听列表中都包含listening数组中的fd。
当各个worker实际运行时,对于accept锁的处理和epoll中注册注销accept事件的的处理都是在ngx_trylock_accept_mutex中进行的。而这一系列过程则是在nginx主体循环中反复调用的void ngx_process_events_and_timers(ngx_cycle_t *cycle)中进行。
也就是说,每轮事件的处理都会首先竞争accept锁,竞争成功则在epoll中注册accept事件,失败则注销accept事件,然后处理完事件之后,释放accept锁。由此只有一个进程监听一个listen套接字,从而避免了惊群问题。
那么如果某个获取accept_mutex锁的worker非常忙,有非常多事件要处理,一直没轮到释放锁,那么某一个进程长时间占用accept锁,而又无暇处理新连接;其他进程又没有占用accept锁,同样无法处理新连接,这是怎么处理的呢?为了解决这个问题,Nginx采用了将事件处理延后的方式。即在ngx_process_events的处理中,仅仅将事件放入两个队列中:
ngx_thread_volatile ngx_event_t *ngx_posted_accept_events;
ngx_thread_volatile ngx_event_t *ngx_posted_events;
处理的网络事件主要牵扯到2个队列,一个是ngx_posted_accept_events,另一个是ngx_posted_events。其中,一个队列用于放accept的事件,另一个则是普通的读写事件;
ngx_event_process_posted会处理事件队列,其实就是调用每个事件的回调函数,然后再让这个事件出队。
那么具体是怎么实现的呢?其实就是在static ngx_int_t ngx_epoll_process_events(ngx_cycle_t *cycle, ngx_msec_t timer, ngx_uint_t flags)的flags参数中传入一个NGX_POST_EVENTS的标志位,处理事件时检查这个标志位即可。
这里只是避免了事件的消费对于accept锁的长期占用,那么万一epoll_wait本身占用的时间很长呢?这方面的处理也很简单,epoll_wait本身是有超时时间的,限制住它的值就可以了,这个参数保存在ngx_accept_mutex_delay这个全局变量中。
核心代码如下:
ngx_process_events_and_timers(ngx_cycle_t *cycle) { ngx_uint_t flags; ngx_msec_t timer, delta; /* 省略一些处理时间事件的代码 */ // 这里是处理负载均衡锁和accept锁的时机 if (ngx_use_accept_mutex) { // 如果负载均衡token的值大于0, 则说明负载已满,此时不再处理accept, 同时把这个值减一 if (ngx_accept_disabled > 0) { ngx_accept_disabled--; } else { // 尝试拿到accept锁 if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) { return; } // 拿到锁之后把flag加上post标志,让所有事件的处理都延后 // 以免太长时间占用accept锁 if (ngx_accept_mutex_held) { flags |= NGX_POST_EVENTS; } else { if (timer == NGX_TIMER_INFINITE || timer > ngx_accept_mutex_delay) { // 最多等ngx_accept_mutex_delay个毫秒,防止占用太久accept锁 timer = ngx_accept_mutex_delay; } } } } delta = ngx_current_msec; // 调用事件处理模块的process_events,处理一个epoll_wait的方法 (void) ngx_process_events(cycle, timer, flags); // 计算处理events事件所消耗的时间 delta = ngx_current_msec - delta; ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0, "timer delta: %M", delta); // 如果有延后处理的accept事件,那么延后处理这个事件 ngx_event_process_posted(cycle, &ngx_posted_accept_events); // 释放accept锁 if (ngx_accept_mutex_held) { ngx_shmtx_unlock(&ngx_accept_mutex); } // 处理所有的超时事件 if (delta) { ngx_event_expire_timers(); } // 处理所有的延后事件 ngx_event_process_posted(cycle, &ngx_posted_events); }
整个流程如下所示:

3.3、Accept锁开启是否一定性能高
上述分析的主要是accept_mutex打开的情况。对于不打开的情况,比较简单,所有worker的epoll都会监听listening数组中的所有fd,所以一旦有新连接过来,就会出现worker“抢夺资源“的情况。对于分布式的大量短链接来讲,打开accept_mutex选项较好,避免了worker争夺资源造成的上下文切换以及try_lock的锁开销。但是对于传输大量数据的tcp长链接来讲,打开accept_mutex就会导致压力集中在某几个worker上,特别是将worker_connection值设置过大的时候,影响更加明显。因此对于accept_mutex开关的使用,根据实际情况考虑,不可一概而论。
一般来说,如果采用的是长tcp连接的方式,而且worker_connection也比较大,这样就出现了accept_mutex打开worker负载不均造成QPS下降的问题。
目前新版的Linux内核中增加了EPOLLEXCLUSIVE选项,nginx从1.11.3版本之后也增加了对NGX_EXCLUSIVE_EVENT选项的支持,这样就可以避免多worker的epoll出现的惊群效应,从此之后accept_mutex从默认的on变成了默认off。
3.4、reuseport机制
3.4.1、reuseport机制描述
NGINX发布的1.9.1版本引入了一个新的特性:允许使用SO_REUSEPORT套接字选项,该选项在许多操作系统的新版本中是可用的,包括Bsd和Linux(内核版本3.9及以后)。该套接字选项允许多个套接字监听同一IP和端口的组合。内核能够在这些套接字中对传入的连接进行负载均衡。对于NGINX而言,启用该选项可以减少在某些场景下的锁竞争而改善性能。
如下图描述,当SO_REUSEPORT未开启时,一个单独的监听socket通知工作进程接入的连接,并且每个工作线程都试图获得连接。
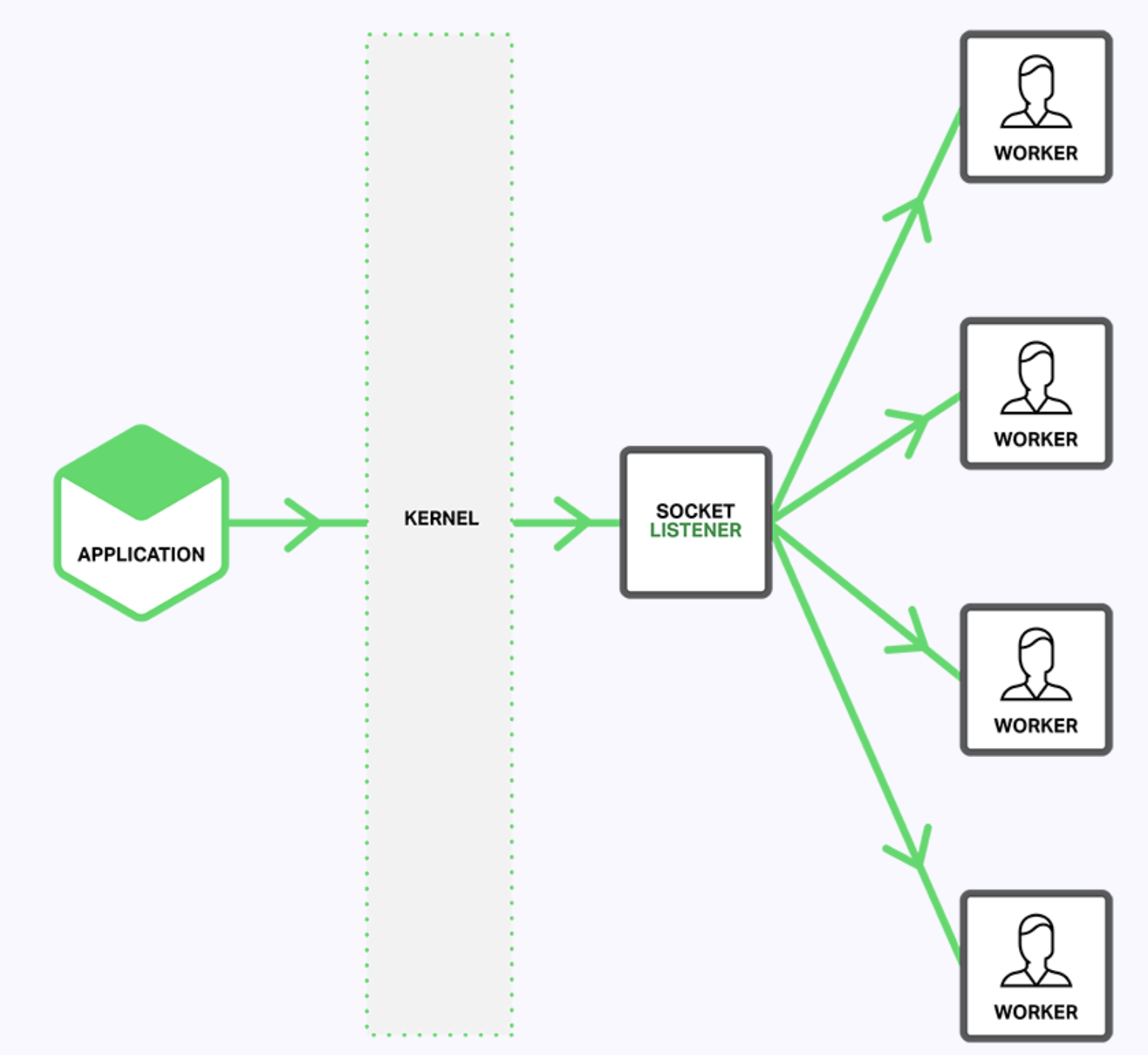
当SO_REUSEPORT选项启用时,存在对每一个IP地址和端口绑定连接的多个socket监听器,每一个工作进程都可以分配一个。系统内核决定哪一个有效的socket监听器(通过隐式的方式,给哪一个工作进程)获得连接。这可以减少工作进程之间获得新连接时的封锁竞争(译者注:工作进程请求获得互斥资源加锁之间的竞争),同时在多核系统可以提高性能。然而,这也意味着当一个工作进程陷入阻塞操作时,阻塞影响的不仅是已经接受连接的工作进程,也同时让内核发送连接请求计划分配的工作进程因此变为阻塞。
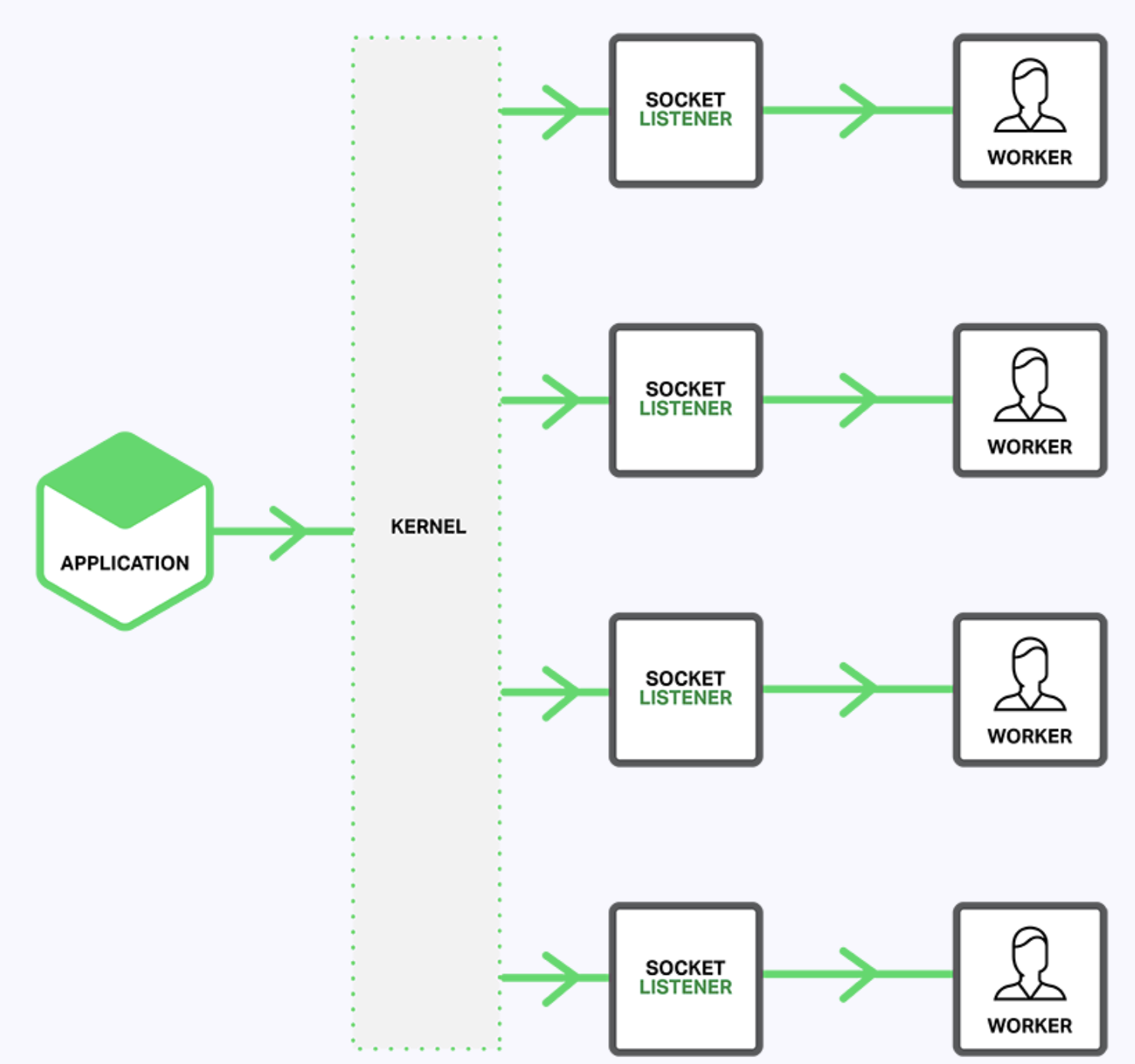
3.4.2、开启reuseport
要开启SO_REUSEPORT,需要为HTTP或TCP(流模式)通信选项内的listen项直接添加reuseport参数,就像下例这样:
http { server { listen 80 reuseport; server_name localhost; # ... } } stream { server { listen 12345 reuseport; # ... } }
引用reuseport参数后,accept_mutex参数将会无效,因为互斥锁对reuseport来说是多余的。如果没有开启reuseport,设置accept_mutex仍然是有效的。accept_mutex默认是开启的。
3.4.3、reuseport的性能测试
我在一个36核的AWS实例运行wrk基准测试工具,测试4个NGINX工作进程。为了减少网络的影响,客户端和NGINX都运行在本地,并且让NGINX返回OK字符串而不是一个文件。我比较三种NGINX配置:默认(等同于accept_mutex on),accept_mutex off和reuseport。如图所示,reuseport的每秒请求是其余的两到三倍,同时延迟和延迟标准差也是减少的。
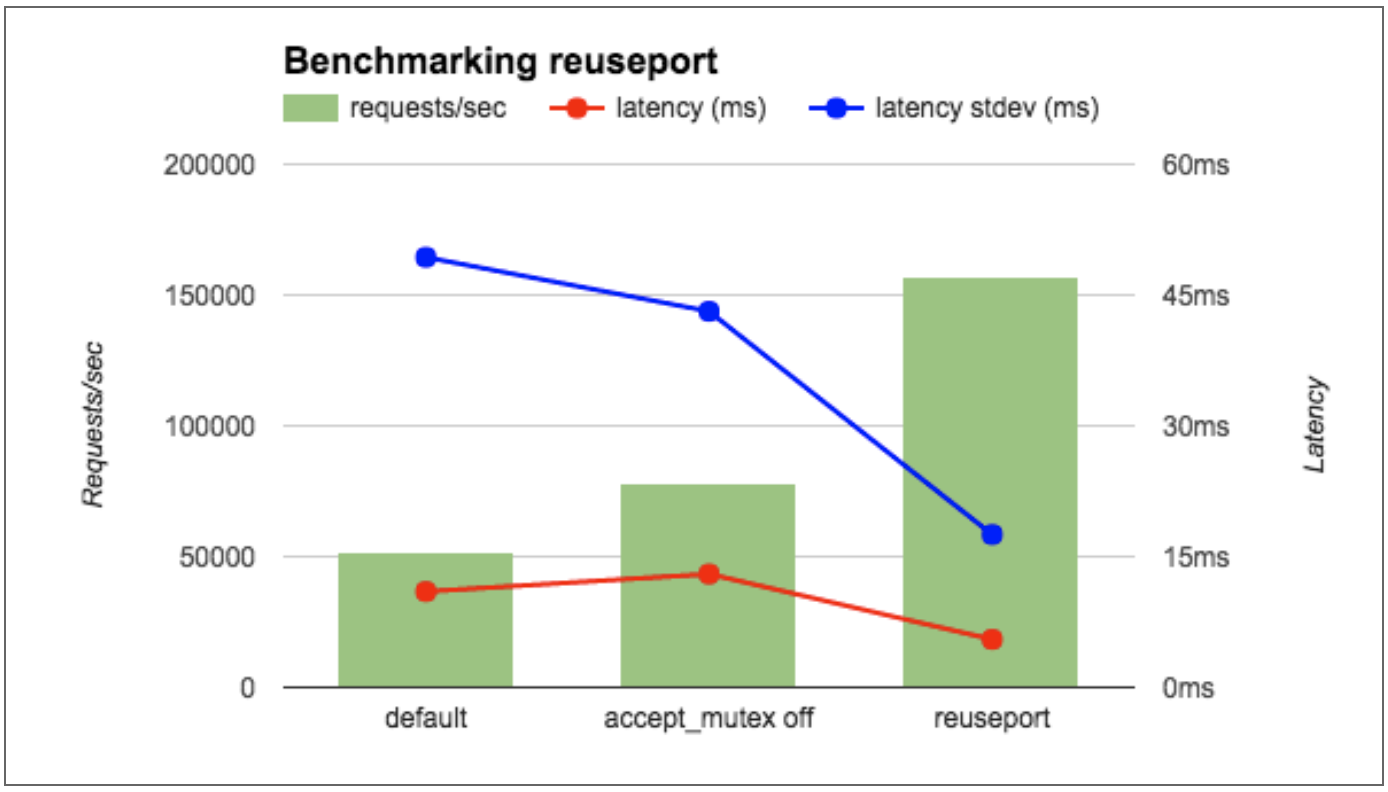
也运行了另一个相关的性能测试——客户端和NGINX分别在不同的机器上且NGINX返回一个HTML文件。如下表所示,用reuseport减少的延迟和之前的性能测试相似,延迟的标准差减少的更为显著(接近十分之一)。其他结果(没有显示在表格中)同样令人振奋。使用reuseport ,负载被均匀分离到了worker进程。在默认条件下(等同于 accept_mutex on),一些worker分到了较高百分比的负载,而用accept_mutex off所有worker都受到了较高的负载。

在这些性能测试中,连接请求的速度是很高的,但是请求不需要大量的处理。其他的基本的测试应该指出——当应用流量符合这种场景时 reuseport 也能大幅提高性能。(reuseport 参数在 mail 上下文环境下不能用在 listen 指令下,例如email,因为email流量一定不会匹配这种场景。)我们鼓励你先测试而不是直接大规模应用。关于测试NGNIX性能的一些技巧,看看Konstantin Pavlov在nginx2014大会上的演讲。
原文地址:Socket Sharding in NGINX Release 1.9.1
Nginx reuseport的原理参考另一篇博文:nginx源码分析—reuseport的使用
4、Sendfile机制
在Nginx作为WEB服务器使用的时候,会访问大量的本地磁盘文件,在以往,访问磁盘文件会经历多次内核态、用户态切换,造成大量的资源浪费(如下图右边部分),而Nginx支持sendfile(也就是零拷贝),实现文件fd到网卡fd的直接映射(如下图左侧部分),跳过了大量的用户态、内核态切换。如下图所示:

注:用户态、内核态切换一次大约耗费是5ms,而一次CPU时间片大约才10ms-100ms,因此在大量并发的情况下不断进行内核切换相当浪费CPU资源,建议配置打开sendfile。
配置文件如截图所示:
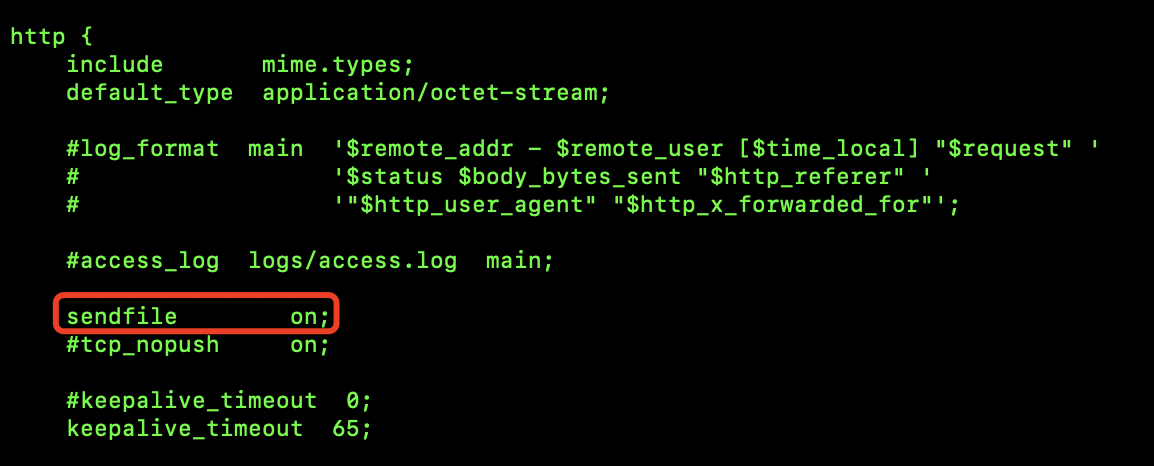
附录、模块化体系结构
如下图所示,就是Nginx的模块体系化结构:
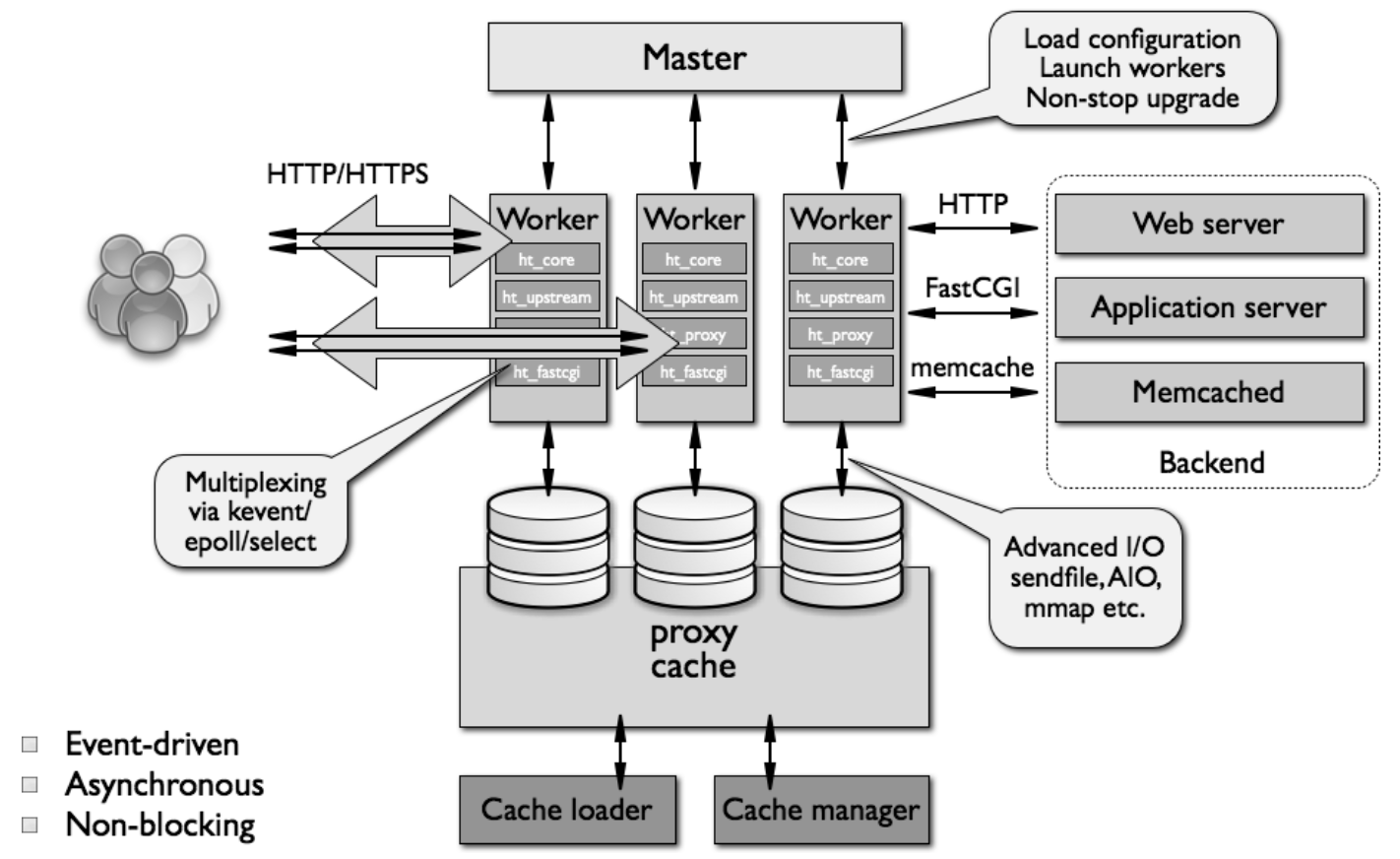
nginx的模块根据其功能基本上可以分为以下几种类型:
- event module: 搭建了独立于操作系统的事件处理机制的框架,及提供了各具体事件的处理。包括ngx_events_module, ngx_event_core_module和ngx_epoll_module等。nginx具体使用何种事件处理模块,这依赖于具体的操作系统和编译选项。
- phase handler: 此类型的模块也被直接称为handler模块。主要负责处理客户端请求并产生待响应内容,比如ngx_http_static_module模块,负责客户端的静态页面请求处理并将对应的磁盘文件准备为响应内容输出。
- output filter: 也称为filter模块,主要是负责对输出的内容进行处理,可以对输出进行修改。例如,可以实现对输出的所有html页面增加预定义的footbar一类的工作,或者对输出的图片的URL进行替换之类的工作。
- upstream: upstream模块实现反向代理的功能,将真正的请求转发到后端服务器上,并从后端服务器上读取响应,发回客户端。upstream模块是一种特殊的handler,只不过响应内容不是真正由自己产生的,而是从后端服务器上读取的。
- load-balancer: 负载均衡模块,实现特定的算法,在众多的后端服务器中,选择一个服务器出来作为某个请求的转发服务器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号