scala_基础
笔记前言:本笔记为scala的入门基础和scala基础使用。主要参考为书籍和推荐较高的博客。主要目的为供个人总结学习。
所有来自网络参考内容不一一列出。
一、面向过程
1.变量体
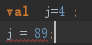
val 标识符:声明常量;如,val answer = 1.
var 标识符:声明变量;
scala变量类型无需声明,可根据初始变量的值进行自动定义(编译过程中),所以变量的声明和定义是一体化的,否则会报错。原理

1.1 两种标识符的区别和适用场景
尽量使用表达式代替变量的使用。val类似于java中final常量,是不可更改的。
2.函数,流程控制和异常处理
2.1 函数
def函数名称(参数列表):函数返回值类型={函数体}
def looper(x:long,y:long):Long={}
返回值为空值的函数声明方式
def unitTest(x:long,y:long):Unit={} / def unitTest(x:long,y:long)={}
示例:
def looper(x:long,y:long):Long={
var a = x;
var b = y;
while(a != 0){
val temp = a;
a = b % a;
b = temp;
}
b;//b为函数的返回值,(return b)
}
函数的调用没有变化:looper(123,3465);
2.1 流程控制
选择和循环没有变化,支持while,for,do while流程控制语句。
3.常用数据结构和文件操作
3.1多元组
val triple = (100, "adsf", "asdfg");
println(triple._1);
val (one, two, three) = triple;
one: Int
= 100;
two: String
= Scala;
three: String
= Spark;
print(one);
val one, two, _ = triple;
one: (Int, String, String)
= (100, Scala, Spark);
two: (Int, String, String)
= (200, Scala, Spark);
3.2 数组
//定长数组
val nums = new Array[Int](10);
val a = new Array[String](10);
val s = Array("Hello","World");
s(0) = "good bye";
//数组的初始化整型为0,字符串类型为null
val num = new Array[Int](10);
val s = new Array[String](10);
//变长数组
val b = ArrayBuffer[Int]();
b+=1;
b+=(1,2,3,5);
b++=Array(8,13,21);
println(b);
//多维数组
val matrix = Array.ofDim[Double](3,4);
matrix(2)(1) = 42;
matrix;
3.3文件
//读取本地文件
object FileOps{
def main(args:Array[String]){
val file = Source.fromFile("address"):
for(line<-file.getLines){
println(line);
}
file.close();
}
}
//读取网络文件
object FileOps1{
def main(args:Array[String]): Unit ={
val webFile = Source.fromURL("http://spark.apache.org/")
webFile.foreach(print)
webFile.close();
}
}
//scala中Source工具类提供了输入输出的文件操作,包括字节字符和输入流等。
3.4 键值对map
scala中有两种map集合
//不可变map
val map = Map("book"->10,"gun"->18,"ipad"->100);
for((k,v)<-map) yield(k,v*0.9);
//可变map
val scores = Scala.collection.mutable.Map("Scala"->7,"Hadoop"->8,"Spark"->10);
val HadoopScore = scores.getOrElse("Hadoop",0);//这个接口中说明存在Hadoop这个键值就返回响应的value值,否则返回设定的参数值“0”;
//增加操作
scores+=("R"->9);
//删除操作
scores-=("R"->9);
4.apply方法
applay方法属于类方法,对于一个类型进行初始化中,相当于类文件的构造方法。原理
二、面向对象
2.1类的定义
class Student{
private var privateAge = 0;
val name = "Scala";
def age = privateAge;
def isYounger(other:Student) = privateAge < other.pirvateAge;
}
2.2构造方法
主类构造方法和辅助构造方法;
2.3伴生对象实现scala中的静态属性
object University{
private var studentNo = 0;
def newStudentNo={
studuent += 1;
studentNo;
}
}
class University{
val id = University.newStudengNo;
private var number = 0;
def aClass(number:Int){this.number += number}
}
//类和伴生对象可以互相访问对方的属性,工程中需要把两者置于同一个文件中。伴生对象多用于工程中的配置文件。
2.4 继承
scala中的继承变化不大,基本在于语法,同时在构造器的继承中更类似C++中的继承机制。在子类对象实例的初始化中也是按照父类的构造方法先行的原则;
2.5 抽象
在属性中说到scala中的字段声明和初始化是一体的,但是在抽象类中存在一种字段是抽象字段,即没有进行初始化的字段。
abstract class SuperTeacher(val name:String){
var id:Int;
var age:Int;
}
2.6 特质(接口)
class ConcreteLogger extends Logger with Cloneable{
def concreteLog{
log("It's me!!!");
}
}
scala也是基于java虚拟机进行编译的,所以在scala中的特质最后还是需要编译成接口。
在scala中多继承的构造顺序是由左向右的。
三、语言特性
3.1高阶函数
map:定义一个转换,将转换遍历应用到列表的每个元素,返回一个新列表集。
(1 to 9).map("*" *_).foreach(println);
filter:保留列表中符合条件的列表元素。
(1 to 9).filter(_%2==0).foreach(println);
reduceLeft函数:从列表的左边往右边应用reduce函数。
println((1 to 9).reduceLeft(_*_));
split,sortWith函数:split将字符串按照指定的表达式规则进行拆分,sortWidth使用自定义的比较函数进行排序。
"spark is the most exciting thing happening in big data today".split(" ").sortWith(_.length<_.length).foreach(println);
自定义高阶函数:
def high_order_functions(f:(Double)=>Double)=f(0.5);
println(high_order_functions((x:Double)=>3*x));
//应用实例:词频统计
val result = rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect;//rdd为读取的rdd文本文件
四、并发编程
五、高级特性
六、项目实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号