ConcurrentHashMap的size方法是线程安全的吗?
前言
之前在面试的过程中有被问到,ConcurrentHashMap的size方法是线程安全的吗?
这个问题,确实没有答好。这次来根据源码来了解一下,具体是怎么一个实现过程。
ConcurrentHashMap的原理与结构
我们都知道Hash表的结构是数组加链表,就是一个数组中,每一个元素都是一个链表,有时候也会形象的把数组中的每个元素称为一个“桶”。在插入元素的时候,首先通过对传入的键(key),进行一个哈希函数的处理,来确定元素应该存放于数组中哪个一个元素的链表中。
这种数据结构在很多计算机语言中都能找到其身影,在Java中如HashMap,ConcurrentHashMap等都是这种数据结构。
但是这中数据结构在实现HashMap的时候并不是线程安全的,因为在HashMap扩容的时候,是会将原先的链表迁移至新的链表数组中,在迁移过程中多线程情况下会有造成链表的死循环情况(JDK1.7之前的头插法);还有就是在多线程插入的时候也会造成链表中数据的覆盖导致数据丢失。
所以就出现了线程安全的HashMap类似的hash表集合,典型的就是HashTable和ConcurrentHashMap。
Hashtable实现线程安全的代价比较大,那就是在所有可能产生竞争方法里都加上了synchronized,这样就会导致,当出现竞争的时候只有一个线程能对整个Hashtable进行操作,其他所有线程都需要阻塞等待当前获取到锁的线程执行完成。
这样效率是非常低的。
而ConcurrentHashMap解决线程安全的方式就不一样了,它避免了对整个Map进行加锁,从而提高了并发的效率。
下面将具体介绍一下JDK1.7和1.8的实现。
JDK1.7中的ConcurrentHashMap
JDK1.7中的ConcurrentHashMap采用了分段锁的形式,每一段为一个Segment类,它内部类似HashMap的结构,内部有一个Entry数组,数组的每个元素是一个链表。同时Segment类继承自ReentrantLock。
结构如下:
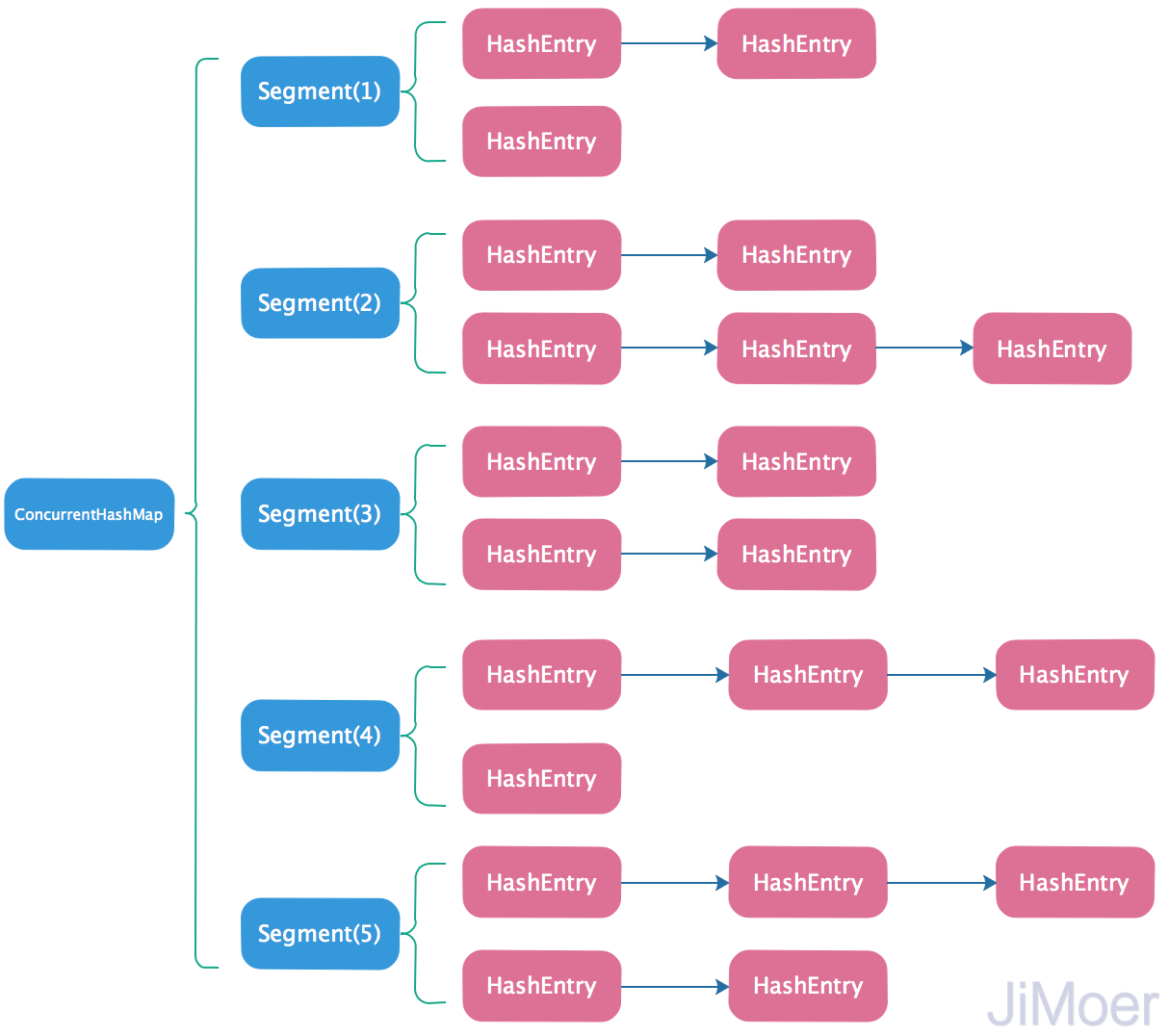
在HashEntry中采用了volatile来修饰了HashEntry的当前值和next元素的值。所以get方法在获取数据的时候是不需要加锁的,这样就大大的提升了执行效率。
在执行put()方法的时候会先尝试获取锁(tryLock()),如果获取锁失败,说明存在竞争,那么将通过scanAndLockForPut()方法执行自旋,当自旋次数达到MAX_SCAN_RETRIES时会执行阻塞锁,直到获取锁成功。
源码如下:
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 首先尝试获取锁,获取失败则执行自旋,自旋次数超过最大长度,后改为阻塞锁,直到获取锁成功。
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
JDK1.8后的ConcurrentHashMap
在JDK1.8中,放弃了Segment这种分段锁的形式,而是采用了CAS+Synchronized的方式来保证并发操作的,采用了和HashMap一样的结构,直接用数组加链表,在链表长度大于8的时候为了提高查询效率会将链表转为红黑树(链表定位数据的时间复杂度为O(N),红黑树定位数据的时间复杂度为O(logN))。
在代码上也和JDK1.8的HashMap很像,也是将原先的HashEntry改为了Node类,但还是使用了volatile修饰了当前值和next的值。从而保证了在获取数据时候的高效。
JDK1.8中的ConcurrentHashMap在执行put()方法的时候还是有些复杂的,主要是为了保证线程安全才做了一系列的措施。
源码如下:

- 第一步通过key进行hash。
- 第二步判断是否需要初始化数据结构。
- 第三步根据key定位到当前
Node,如果当前位置为空,则可以写入数据,利用CAS机制尝试写入数据,如果写入失败,说明存在竞争,将会通过自旋来保证成功。 - 第四步如果当前的
hashcode值等于MOVED则需要进行扩容(扩容时也使用了CAS来保证了线程安全)。 - 第五步如果上面四步都不满足,那么则通过
synchronized阻塞锁将数据写入。 - 第六步如果数据量大于
TREEIFY_THRESHOLD时需要转换成红黑树(默认为8)。
JDK1.8的ConcurrentHashMap的get()方法就还是比较简单:
- 根据
key的hashcode寻址到具体的桶上。 - 如果是红黑树则按照红黑树的方式去查找数据。
- 如果是链表就按照遍历链表的方式去查找数据。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
ConcurrentHashMap的size方法
JDK1.7中的ConcurrentHashMap的size方法,计算size的时候会先不加锁获取一次数据长度,然后再获取一次,最多三次。比较前后两次的值,如果相同的话说明不存在竞争的编辑操作,就直接把值返回就可以了。
但是如果前后获取的值不一样,那么会将每个Segment都加上锁,然后计算ConcurrentHashMap的size值。

JDK1.8中的ConcurrentHashMap的size()方法的源码如下:
/**
* {@inheritDoc}
*/
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
这个方法最大会返回int的最大值,但是ConcurrentHashMap的长度有可能超过int的最大值。
在JDK1.8中增加了mappingCount()方法,这个方法的返回值是long类型的,所以JDK1.8以后更推荐用这个方法获取Map中数据的数量。
/**
* @return the number of mappings
* @since 1.8
*/
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
无论是size()方法还是mappingCount()方法,核心方法都是sumCount()方法。
源码如下:
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
在上面sumCount()方法中我们看到,当counterCells为空时直接返回baseCount,当counterCells不为空时遍历它并垒加到baseCount中。
先看baseCount
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;
baseCount是一个volatile变量,那么我们来看在put()方法执行时是如何使用baseCount的,在put方法的最后一段代码中会调用addCount()方法,而addCount()方法的源码如下:

首先对baseCount做CAS自增操作。
如果并发导致了baseCount的CAS失败了,则使用counterCells进行CAS。
如果counterCells的CAS也失败了,那么则进入fullAddCount()方法,fullAddCount()方法中会进入死循环,直到成功为止。

那么CountCell到底是个什么呢?
源码如下:
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
一个使用了 @sun.misc.Contended 标记的类,内部一个 volatile 变量。
@sun.misc.Contended 这个注解是为了防止“伪共享”。
那么什么是伪共享呢?
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
所以伪共享对性能危害极大。
JDK 8 版本之前没有这个注解,JDK1.8之后使用拼接来解决这个问题,把缓存行加满,让缓存之间的修改互不影响。
总结
无论是JDK1.7还是JDK1.8中,ConcurrentHashMap的size()方法都是线程安全的,都是准确的计算出实际的数量,但是这个数据在并发场景下是随时都在变的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号