深入理解JVM(③)各种垃圾收集算法
前言
从如何判定对象消亡的角度出发,垃圾收集算法可以划分为“引用计数式垃圾收集”(Reference Counting GC)和“追踪式垃圾收集”(Tracing GC)两大类,这两类也常被称作“直接垃圾收集”和“间接垃圾收集”。由于主流Java虚拟机中使用 的都是“追踪式垃圾收集”,所以后续介绍的垃圾收集算法都是属于追踪式的垃圾收集。
分代式收集理论
当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”的理论进行设计。
主要建立在两个分代假说之上:
1、弱分代假说:绝大多数对象都是“朝生夕灭”的。
2、强分代假说:熬过越多次垃圾收集过程的对象就越难以消亡。
这两个分代假说奠定了多款常用的垃圾收集器的一致设计原则:收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。
把分代收集理论具体放到现在商用的Java虚拟机里,设计者一般至少会把Java堆划分为新生代(Young Generation) 和 老年代(Old Generation两个区域。在新生代中,每次垃圾收集时都有大批对象死去,而每次回收后存活的少量对象,将会逐步晋升到老年代中存放。
标记-清除算法
标记-清除算法,分为“标记”和“清除”两个阶段:首先标记所有需要回收的对象,标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。
这个算法有两个主要的缺点:
第一个是执行效率不稳定,如果Java堆中有大部分是需要回收的对象,这个会进行大量标记和清除动作,导致标记和清除两个过程的执行效率随着对象数量增长而降低。
第二个是内存碎片化问题,标记、清除之后会产生大量不连续的内存碎片,空间碎片太多会导致当需要大对象时找不到足够的连续内存,而提前触发另一次垃圾收集动作。
因为这两个缺点的原因,才会产生后续一些针对于修复这两个缺点的算法。
标记清除算法示意图:

标记复制算法
标记复制算法也被简称为复制算法,为了解决标记清除算法面对大量可回收对象时执行效率低的问题,而产生的一种称为“半区复制”的垃圾收集算法。
原理是:将可用内存按容量划分为大小相等的两块,每次只使用其中的一块当这一块内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这种算法不用考虑空间碎片化,只需要移动堆指针,按顺序分配即可,实现简单,运行高效,但缺点也是显而易见的,就是将可用内存缩小了原来的一半。
标记复制算法示意图:
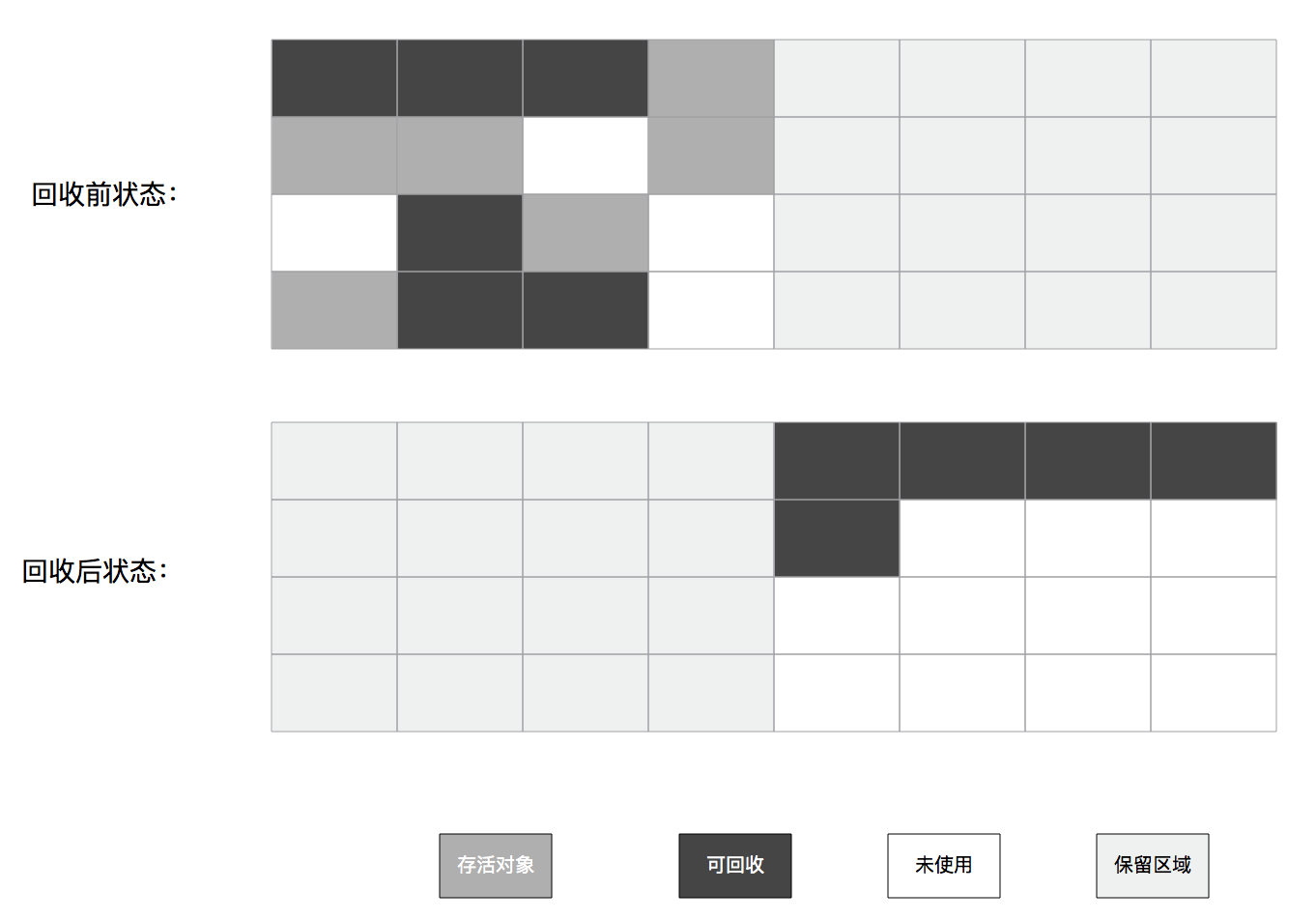
由于新生代里的对象“朝生夕灭”,针对这个特点,又产生了一种更优化的半区复制分代策略,称为“Appel式回收”。具体做法是把新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次分配内存只是用Eden和其中一块Survivor。当发生垃圾收集时,将Eden和Survivor中仍然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是说每次可利用的空间为新生代的90%,只有10%的空间会暂时“浪费”。
如果另外一块儿Survivor没有足够的空间存放存活的对象了,这些对象将通过分配担保机制直接进入到老年代。
标记整理算法
标记复制算法在对象存活率较高时就要进行较多的复制操作,效率将会降低。更关键的是,如果不浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
针对老年代对象的存亡特征,产生了另外一种有针对性的“标记整理”算法。标记的过程和“标记-清除”算法一样,也是判断对象是否属于垃圾的过程。但后续步骤是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。
标记整理算法示意图:

在这种算法中,在移动存活对象,尤其是在老年代这种每次回收都有大量对象存活区域,移动存活对象并更新所有引用这些对象的地方将会是一种极为负重的操作,而且这种移动操作必须在暂停用户应用程序才能进行(也就是“Stop The World”)。但是不移动又会造成内存空间碎片化。所以各有利弊,从垃圾收集的停顿时间来看,不移动对象停顿时间更短,但从整个程序的吞吐量来看,移动对象会更划算。所以要依情况而定。
还有一种“和稀泥”的解决方案,就是平时采用标记清除算法,直到内存空间碎片化程度已经大到影响对象分配时,再采用标记整理算法收集一次,以获得规整的内存空间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号