
Nginx数据结构之散列表
1. 散列表(即哈希表概念)
散列表是根据元素的关键码值而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,
以加快查找速度。这个映射函数 f 叫做散列方法,存放记录的数组叫做散列表。
若结构中存在关键字和 K 相等的记录,则必定在 f(K) 的存储位置上。由此,不需要比较便可直接取得所查记录。我们称这
个对应关系 f 为散列方法,按这个思想建立的表则为散列表。
对于不同的关键字,可能得到同一散列地址,即关键码 key1 ≠ key2,而 f(key1) = f(key2),这种现象称为碰撞。对该散列
方法来说,具有相同函数值的关键字称作同义词。综上所述,根据散列方法 H(key) 和处理碰撞的方法将一组关键字映像到一
个有限的连续的地址集(区间)上,并以关键字在地址集中的 "象" 作为记录在表中的存储位置,这种表便称为散列表,这一
映像过程称为散列造表或散列,所得的存储位置称为散列地址。
1.1 如何解决碰撞问题
通常有两个简单的解决方法:分离链接法和开放寻址法。
分离链接法,就是把散列到同一个槽中的所有元素都放在散列表外的一个链表中,这样查询元素时,在找到这个槽后,还得遍
历链表才能找到正确的元素,以此来解决碰撞问题。
开放寻址法,即所有元素都存放在散列表中,当查找一个元素时,要检查规则内的所有表项(例如,连续的非空槽或者整个空
间内符合散列方法的所有槽),直到找到所需的元素,或者最终发现元素不在表中。开放寻址法中没有链表,也没有元素存放
在散列表外。
Nginx 的散列表使用的是开放寻址法。
开放寻址法有许多种实现方法,Nginx 使用的是连续非空槽存储碰撞元素的方法。例如,当插入一个元素时,可以按照散列方
法找到指定槽,如果该槽非空且其存储的元素与待插入元素并非同一个元素,则依次检查其后连续的槽,直到找到一个空槽来
放置这个元素为止。查询元素时也是使用类似的方法,即从散列方法指定的位置起检查连续的非空槽中的元素。
2. Nginx 散列表的实现
2.1 ngx_hash_elt_t 结构体
对于散列表中的元素,Nginx 使用 ngx_hash_elt_t 结构体来存储。
typedef struct {
/* 指向用户自定义元素数据的指针,如果当前 ngx_hash_elt_t 槽为空,则 value 的值为 0 */
void *value;
/* 元素关键字的长度 */
u_short len;
/* 元素关键字的首地址 */
u_char name[1];
} ngx_hash_elt_t;
每一个散列表槽都由 1 个 ngx_hash_elt_t 结构体表示,当然,这个槽的大小与 ngx_hash_elt_t 结构体的大小(即
sizeof(ngx_hash_elt_t))是不相等的,这是因为 name 成员只用于指出关键字的首地址,而关键字的长度是可变的。一个槽
占用多大的空间是在初始化散列表时决定的。
2.2 ngx_hash_t 结构体
基本的散列表由 ngx_hash_t 结构体表示。
typedef struct {
/* 指向散列表的首地址,也是第 1 个槽的地址 */
ngx_hash_elt_t **buckets;
/* 散列表中槽的总数 */
ngx_uint_t size;
} ngx_hash_t;
因此,在分配 buckets 成员时就决定了每个槽的长度(限制了每个元素关键字的最大长度),以及整个散列表所占用的空
间。
基本散列表的结构示意图
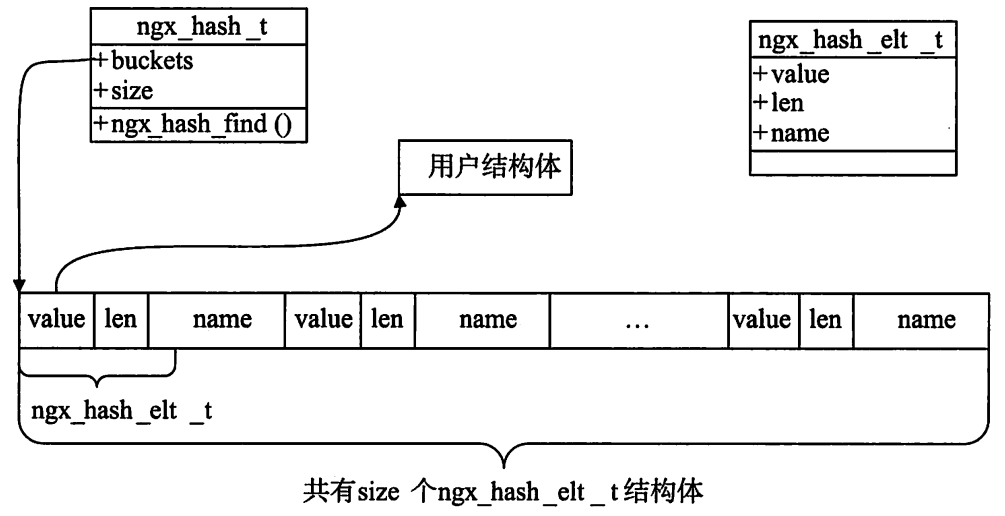
如上图,散列表的每个槽的首地址都是 ngx_hash_elt_t 结构体,value 成员指向用户有意义的结构体,而 len 是当前这
个槽中 name(也就是元素的关键字)的有效长度。ngx_hash_t 散列表的 buckets 指向了散列表的起始地址,而 size 指出
散列表中槽的总数。
2.3 ngx_hash_init_t 结构体
typedef struct {
/* 指向普通的完全匹配散列表 */
ngx_hash_t *hash;
/* 用于初始化添加元素的散列方法 */
ngx_hash_key_pt key;
/* 散列表中槽的最大数目 */
ngx_uint_t max_size;
/* 散列表中一个槽的大小,它限制了每个散列表元素关键字的最大长度 */
ngx_uint_t bucket_size;
/* 散列表的名称 */
char *name;
/* 内存池,用于分配散列表(最多3个,包括1个普通散列表、1个前置通配符散列表、1个后置通配符散列表)
* 中的所有槽 */
ngx_pool_t *pool;
/* 临时内存池,仅存在于初始化散列表之前。它主要用于分配一些临时的动态数组,
* 带通配符的元素在初始化时需要用到这些数组 */
ngx_pool_t *temp_pool;
} ngx_hash_init_t;
该结构体用于初始化一个散列表。
2.4 ngx_hash_key_t 结构体
typedef struct {
/* 元素关键字 */
ngx_str_t key;
/* 由散列方法算出来的关键码 */
ngx_uint_t key_hash;
/* 指向实际的用户数据 */
void *value;
}ngx_hash_key_t;
2.3 ngx_hash_init():初始化一个基本散列表
/* 计算该实际元素 name 所需的内存空间(有对齐处理),而 sizeof(void *) 就是结束哨兵的所需内存空间 */
#define NGX_HASH_ELT_SIZE(name) \
(sizeof(void *) + ngx_align((name)->key.len + 2, sizeof(void *)))
/*
* @hinit:该指针指向的结构体中包含一些用于建立散列表的基本信息
* @names:元素关键字数组,该数组中每个元素以ngx_hash_key_t作为结构体,存储着预添加到散列表中的元素
* @nelts: 元素关键字数组中元素个数
*/
ngx_int_t ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)
{
u_char *elts;
size_t len;
u_short *test;
ngx_uint_t i, n, key, size, start, bucket_size;
ngx_hash_elt_t *elt, **buckets;
if (hinit->max_size == 0)
{
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build %s, you should "
"increase %s_max_size: %i",
hinit->name, hinit->name, hinit->max_size);
return NGX_ERROR;
}
for (n = 0; n < nelts; n++)
{
/* 这个判断是确保一个 bucket 至少能存放一个实际元素以及结束哨兵,如果有任意一个实际元素
* (比如其 name 字段特别长)无法存放到 bucket 内则报错返回 */
if (hinit->bucket_size < NGX_HASH_ELT_SIZE(&names[n]) + sizeof(void *))
{
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build %s, you should "
"increase %s_bucket_size: %i",
hinit->name, hinit->name, hinit->bucket_size);
return NGX_ERROR;
}
}
/* 接下来的测试针对当前传入的所有实际元素,测试分配多少个 Hash 节点(也就是多少个 bucket)会比较好,
* 即能省内存又能少冲突,否则的话,直接把 Hash 节点数目设置为最大值 hinit->max_size 即可。 */
test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log);
if (test == NULL)
{
return NGX_ERROR;
}
/* 计算一个 bucket 除去结束哨兵所占空间后的实际可用空间大小 */
bucket_size = hinit->bucket_size - sizeof(void *);
/* 计算所需 bucket 的最小个数,注意到存储一个实际元素所需的内存空间的最小值也就是
* (2*sizeof(void *)) (即宏 NGX_HASH_ELT_SIZE 的对齐处理),所以一个 bucket 可以存储
* 的最大实际元素个数就为 bucket_size / (2 * sizeof(void *)),然后总实际元素个数 nelts
* 除以这个值就是最少所需要的 bucket 个数 */
start = nelts / (bucket_size / (2 * sizeof(void *)));
start = start ? start : 1;
/* 如果这个 if 条件成立,意味着实际元素个数非常多,那么有必要直接把 start 起始值调高,否则在后面的
* 循环里要执行过多的无用测试 */
if (hinit->max_size > 10000 && nelts && hinit->max_size / nelts < 100)
{
start = hinit->max_size - 1000;
}
/* 下面的 for 循环就是获取 Hash 结构最终节点数目的逻辑。就是逐步增加 Hash 节点数目(那么对应的
* bucket 数目同步增加),然后把所有的实际元素往这些 bucket 里添放,这有可能发生冲突,但只要
* 冲突的次数可以容忍,即任意一个 bucket 都还没满,那么就继续填,如果发生有任何一个 bucket
* 满溢了(test[key] 记录了 key 这个 hash 节点所对应的 bucket 内存储实际元素后的总大小,如果它大
* 于一个 bucket 可用的最大空间 bucket_size,自然就是满溢了),那么就必须增加 Hash 节点、增加
* bucket。如果所有实际元素都填完后没有发生满溢,那么当前的 size 值就是最终的节点数目值 */
for (size = start; size <= hinit->max_size; size++)
{
ngx_memzero(test, size * sizeof(u_short));
for (n = 0; n < nelts; n++)
{
if (names[n].key.data == NULL)
{
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"%ui: %ui %ui \"%V\"",
size, key, test[key], &names[n].key);
#endif
/* 判断是否满溢,若满溢,则必须增加 Hash 节点、增加 bucket */
if (test[key] > (u_short) bucket_size)
{
goto next;
}
}
/* 这里表示已将所有元素都添放到 bucket 中,则此时的 size 即为所需的节点数目值 */
goto found;
next:
continue;
}
size = hinit->max_size;
ngx_log_error(NGX_LOG_WARN, hinit->pool->log, 0,
"could not build optimal %s, you should increase "
"either %s_max_size: %i or %s_bucket_size: %i; "
"ignoring %s_bucket_size",
hinit->name, hinit->name, hinit->max_size,
hinit->name, hinit->bucket_size, hinit->name);
found:
/* 找到需创建的 Hash 节点数目值,接下来就是实际的 Hash 结构创建工作。
* 注意:所有 buckets 所占的内存空间是连接在一起的,并且是按需分配(即某个 bucket 需多少内存
* 存储实际元素就分配多少内存,除了额外的对齐处理)*/
/* 初始化test数组中每个元素的值为 sizeof(void *),即ngx_hash_elt_t的成员value的所占内存大小 */
for (i = 0; i < size; i++)
{
test[i] = sizeof(void *);
}
/* 遍历所有的实际元素,计算出每个元素在对应槽上所占内存大小,并赋给该元素在test数组上的
* 相应位置,即散列表中对应的槽 */
for (n = 0; n < nelts; n++)
{
if (names[n].key.data == NULL)
{
continue;
}
/* 找到该元素在散列表中的映射位置 */
key = names[n].key_hash % size;
/* 计算存储在该槽上的元素所占的实际内存大小 */
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
len = 0;
/* 对test数组中的每个元素(也即每个实际元素在散列表中对应槽所占内存的实际大小)
* 进行对齐处理 */
for (i = 0; i < size; i++)
{
if (test[i] == sizeof(void *))
{
continue;
}
test[i] = (u_short) (ngx_align(test[i], ngx_cacheline_size));
/* len 统计所有实际元素所占的内存总大小 */
len += test[i];
}
if (hinit->hash == NULL)
{
hinit->hash = ngx_pcalloc(hinit->pool, sizeof(ngx_hash_wildcard_t)
+ size * sizeof(ngx_hash_elt_t *));
if (hinit->hash == NULL)
{
ngx_free(test);
return NGX_ERROR;
}
buckets = (ngx_hash_elt_t **)
((u_char *) hinit->hash + sizeof(ngx_hash_wildcard_t));
}
else
{
/* 为槽分配内存空间,每个槽都是一个指向 ngx_hash_elt_t 结构体的指针 */
buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *));
if (buckets == NULL)
{
ngx_free(test);
return NGX_ERROR;
}
}
/* 分配一块连续的内存空间,用于存储槽的实际数据 */
elts = ngx_palloc(hinit->pool, len + ngx_cacheline_size);
if (elts == NULL)
{
ngx_free(test);
return NGX_ERROR;
}
/* 进行内存对齐 */
elts = ngx_align_ptr(elts, ngx_cacheline_size);
/* 使buckets[i]指向 elts 这块内存的相应位置 */
for (i = 0; i < size; i++)
{
if (test[i] == sizeof(void *))
{
continue;
}
buckets[i] = (ngx_hash_elt_t *) elts;
elts += test[i];
}
/* 复位teset数组的值 */
for (i = 0; i < size; i++)
{
test[i] = 0;
}
for (n = 0; n < nelts; n++)
{
if (names[n].key.data == NULL)
{
continue;
}
/* 计算该实际元素在散列表的映射位置 */
key = names[n].key_hash % size;
/* 根据key找到该实际元素应存放在槽中的具体位置的起始地址 */
elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]);
/* 下面是对存放在该槽中的元素进行赋值 */
elt->value = names[n].value;
elt->len = (u_short) names[n].key.len;
ngx_strlow(elt->name, names[n].key.data, names[n].key.len);
/* 更新test[key]的值,以便当有多个实际元素映射到同一个槽中时便于解决冲突问题,
* 从这可以看出Nginx解决碰撞问题使用的方法是开放寻址法中的用连续非空槽来解决 */
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
/* 遍历所有的槽,为每个槽的末尾都存放一个为 NULL 的哨兵节点 */
for (i = 0; i < size; i++)
{
if (buckets[i] == NULL)
{
continue;
}
elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]);
elt->value = NULL;
}
ngx_free(test);
hinit->hash->buckets = buckets;
hinit->hash->size = size;
#if 0
for (i = 0; i < size; i++) {
ngx_str_t val;
ngx_uint_t key;
elt = buckets[i];
if (elt == NULL) {
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"%ui: NULL", i);
continue;
}
while (elt->value) {
val.len = elt->len;
val.data = &elt->name[0];
key = hinit->key(val.data, val.len);
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"%ui: %p \"%V\" %ui", i, elt, &val, key);
elt = (ngx_hash_elt_t *) ngx_align_ptr(&elt->name[0] + elt->len,
sizeof(void *));
}
}
#endif
return NGX_OK;
}
hash 数据结构的使用

2.4 ngx_hash_find()
/*
* 参数含义:
* - hash:是散列表结构体的指针
* - key:是根据散列方法算出来的散列关键字
* - name和len:表示实际关键字的地址与长度
*
* 执行意义:
* 返回散列表中关键字与name、len指定关键字完全相同的槽中,ngx_hash_elt_t结构体中value
* 成员所指向的用户数据.
*/
void *ngx_hash_find(ngx_hash_t *hash, ngx_uint_t key, u_char *name, size_t len)
{
ngx_uint_t i;
ngx_hash_elt_t *elt;
#if 1
ngx_log_error(NGX_LOG_ALERT, ngx_cycle->log, 0, "hf:\"%*s\"", len, name);
#endif
/* 对key取模得到对应的hash节点 */
elt = hash->buckets[key % hash->size];
if (elt == NULL)
{
return NULL;
}
/* 然后在该hash节点所对应的bucket里逐个(该bucket的实现类似数组,结束有
* 哨兵保证)对比元素名称来找到唯一的那个实际元素,最后返回其value值
* (比如,如果在addr->hash结构里找到对应的实际元素,返回的value就是
* 其ngx_http_core_srv_conf_t配置) */
while (elt->value)
{
if (len != (size_t) elt->len)
{
goto next;
}
for (i = 0; i < len; i++)
{
if (name[i] != elt->name[i])
{
goto next;
}
}
return elt->value;
next:
elt = (ngx_hash_elt_t *) ngx_align_ptr(&elt->name[0] + elt->len,
sizeof(void *));
continue;
}
return NULL;
}
2.5 Nginx提供的两种散列方法
/* 散列方法1:使用BKDR算法将任意长度的字符串映射为整型 */
ngx_uint_t ngx_hash_key(u_char *data, size_t len)
{
ngx_uint_t i, key;
key = 0;
for (i = 0; i < len; i++)
{
key = ngx_hash(key, data[i]);
}
return key;
}
/* 散列方法2:将字符串全小写后,再使用BKDR算法将任意长度的字符串映射为整型 */
ngx_uint_t ngx_hash_key_lc(u_char *data, size_t len)
{
ngx_uint_t i, key;
key = 0;
for (i = 0; i < len; i++)
{
key = ngx_hash(key, ngx_tolower(data[i]));
}
return key;
}
2.6 基本散列表的使用实例
Nginx 对虚拟主机的管理使用到了 Hash 数据结构,比如假设配置文件nginx.conf中有如下配置:
server {
listen 192.168.1.1:80;
server_name www.web_test2.com blog.web_test2.com;
...
server {
listen 192.168.1.1:80;
server_name www.web_test1.com bbs.web_test1.com;
...
当Nginx使用该配置文件启动后,如果来了一个客户端请求到192.168.1.1的80端口,那么Nginx需要做
一个查找,看当前请求该使用哪个Server配置。为了提高查找效率,在启动时,Nginx就将根据这些
server_name建立一个Hash数据结构。
在ngx_http.c的ngx_http_server_names方法中:
.
hash.key = ngx_hash_key_lc;
hash.max_size = cmcf->server_names_hash_max_size;
hash.bucket_size = cmcf->server_names_hash_bucket_size;
hash.name = "server_names_hash";
hash.pool = cf->pool;
if (ha.keys.nelts)
{
hash.hash = &addr->hash;
hash.temp_pool = NULL;
if (ngx_hash_init(&hash, ha.keys.elts, ha.keys.nelts) != NGX_OK)
{
goto failed;
}
}
...
调用ngx_hash_init前Hash数据结构初始状态
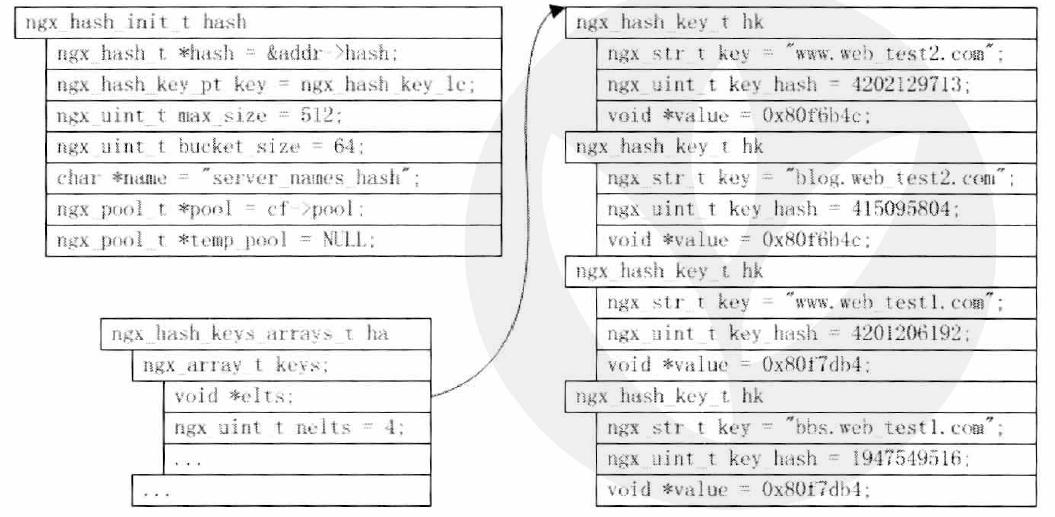
调用ngx_hash_init后Hash数据结构状态

图中,字段buckets指向的就是Hash节点所对应的存储空间,由于buckets是一个二级指针,那么*buckets本身是一个数组,每
一个数组元素用来存储映射到此的Hash节点。由于可能有多个实际元素映射到同一个Hash节点(即发生冲突),所以对实际元
素再次进行数组形式的组织存储在一个bucket内,这个数组的结束以哨兵元素NULL作为标记,而前面的每一个ngx_hash_elt_t
结构对应一个实际元素的存储。
3. Nginx 通配符散列表的实现
3.1 原理
支持通配符的散列表,就是把基本散列表中元素的关键字,用去除通配符以后的字符作为关键字加入。
例如,对于关键字为 "www.test." 这样带通配符的情况,直接建立一个专用的后置通配符散列表,
存储元素的关键字为 "www.test"。这样,如果要检索 "www.test.cn" 是否匹配 "www.test.",可用
Nginx 提供的专用方法 ngx_hash_find_wc_tail 检索,ngx_hash_find_wc_tail 方法会把要查询的
www.test.cn 转化为 www.test 字符串再开始查询。
同理,对于关键字为 "*.test.com" 这样带前置通配符的情况,也直接建立一个专用的前置通配符散
列表,存储元素的关键字为 "com.test."。如果我们要检索 smtp.test.com 是否匹配 *.test.com,
可用 Nginx 提供的专用方法 ngx_hash_find_wc_head 检索,ngx_hash_find_wc_head 方法会把要查
询的 smtp.test.com 转化为 com.test. 字符串再开始查询。
3.2 相应结构体
3.2.1 ngx_hash_wildcard_t 结构体
typedef struct {
/* 基本散列表 */
ngx_hash_t hash;
/* 当使用这个ngx_hash_wildcard_t通配符散列表作为某个容器的元素时,可以使用这个value
* 指针指向用户数据 */
void *value;
}ngx_hash_wildcard_t;
3.2.2 ngx_hash_combined_t 结构体
typedef struct {
/* 用于精确匹配的基本散列表 */
ngx_hash_t hash;
/* 用于查询前置通配符的散列表 */
ngx_hash_wildcard_t *wc_head;
/* 用于查询后置通配符的散列表 */
ngx_hash_wildcard_t *wc_tail;
}ngx_hash_combined_t;
注:前置通配符散列表中元素的关键字,在把 * 通配符去掉后,会按照 "." 符号分隔,并以倒序的
方式作为关键字来存储元素。相应地,在查询元素时也是做相同处理。
3.2.3 ngx_hash_keys_arrays_t 结构体
typedef struct {
/* 下面的keys_hash、dns_wc_head_hash、dns_wc_tail_hash都是简易散列表,而hsize指明了
* 散列表中槽的个数,其简易散列方法也需要对hsize求余 */
ngx_uint_t hsize;
/* 内存池,用于分配永久性内存 */
ngx_pool_t *pool;
/* 临时内存池,下面的动态数组需要的内存都由temp_pool内存池分配 */
ngx_pool_t *temp_pool;
/* 用动态数组以ngx_hash_key_t结构体保存着不含有通配符关键字的元素 */
ngx_array_t keys;
/* 一个极其简易的散列表,它以数组的形式保存着hsize个元素,每个元素都是ngx_array_t
* 动态数组。在用户添加的元素过程中,会根据关键码将用户的ngx_str_t类型的关键字添加
* 到ngx_array_t动态数组中。这里所有的用户元素的关键字都不可以带通配符,表示精确
* 匹配 */
ngx_array_t *keys_hash;
/* 用动态数组以ngx_hash_key_t结构体保存着含有前置通配符关键字的元素生成的中间关键字 */
ngx_array_t dns_wc_head;
/* 一个极其简易的散列表,它以数组的形式保存着hsize个元素,每个元素都是ngx_array_t
* 动态数组。在用户添加的元素过程中,会根据关键码将用户的ngx_str_t类型的关键字添加
* 到ngx_array_t动态数组中。这里所有的用户元素的关键字都带前置通配符 */
ngx_array_t *dns_wc_head_hash;
/* 用动态数组以ngx_hash_key_t结构体保存着含有后置通配符关键字的元素生成的中间关键字 */
ngx_array_t dns_wc_tail;
/* 一个极其简易的散列表,它以数组的形式保存着hsize个元素,每个元素都是ngx_array_t
* 动态数组。在用户添加的元素过程中,会根据关键码将用户的ngx_str_t类型的关键字添加
* 到ngx_array_t动态数组中。这里所有的用户元素的关键字都带后置通配符 */
ngx_array_t *dns_wc_tail_hash;
} ngx_hash_keys_arrays_t;
3.3 通配符散列表相关函数
3.3.1 ngx_hash_wildcard_init(): 初始化通配符散列表
/*
* 参数含义:
* - hinit:是散列表初始化结构体的指针
* - names:是数组的首地址,这个数组中每个元素以ngx_hash_key_t作为结构体,
* 它存储着预添加到散列表中的元素(这些元素的关键字要么是含有前
* 置通配符,要么含有后置通配符)
* - nelts:是names数组的元素数目
*
* 执行意义:
* 初始化通配符散列表(前置或者后置)。
*/
ngx_int_t ngx_hash_wildcard_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names,
ngx_uint_t nelts)
{
size_t len, dot_len;
ngx_uint_t i, n, dot;
ngx_array_t curr_names, next_names;
ngx_hash_key_t *name, *next_name;
ngx_hash_init_t h;
ngx_hash_wildcard_t *wdc;
/* 从临时内存池temp_pool中分配一个元素个数为nelts,大小为sizeof(ngx_hash_key_t)
* 的数组curr_name */
if (ngx_array_init(&curr_names, hinit->temp_pool, nelts,
sizeof(ngx_hash_key_t))
!= NGX_OK)
{
return NGX_ERROR;
}
/* 从临时内存池temp_pool中分配一个元素个数为nelts,大小为sizeof(ngx_hash_key_t)
* 的数组next_name */
if (ngx_array_init(&next_names, hinit->temp_pool, nelts,
sizeof(ngx_hash_key_t))
!= NGX_OK)
{
return NGX_ERROR;
}
/* 遍历names数组中保存的所有通配符字符串 */
for (n = 0; n < nelts; n = i)
{
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"wc0: \"%V\"", &names[n].key);
#endif
dot = 0;
/* 遍历该通配符字符串的每个字符,直到找到 '.' 为止 */
for (len = 0; len < names[n].key.len; len++)
{
if (names[n].key.data[len] == '.')
{
/* 找到则置位该标识位 */
dot = 1;
break;
}
}
/* 从curr_names数组中取出一个类型为ngx_hash_key_t的指针 */
name = ngx_array_push(&curr_names);
if (name == NULL)
{
return NGX_ERROR;
}
/* 若dot为1,则len为'.'距该通配符字符串起始位置的偏移值,
* 否则为该通配符字符串的长度 */
name->key.len = len;
/* 将通配符字符串赋值给name->key.data */
name->key.data = names[n].key.data;
/* 以该通配符字符串作为关键字通过key散列方法算出该通配符字符串在散列表中的
* 映射位置 */
name->key_hash = hinit->key(name->key.data, name->key.len);
/* 指向用户有意义的数据结构 */
name->value = names[n].value;
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"wc1: \"%V\" %ui", &name->key, dot);
#endif
dot_len = len + 1;
/* 若前面的遍历中已找到'.',则len加1 */
if (dot)
{
len++;
}
next_names.nelts = 0;
/* 当通配符字串的长度与len不等时,即表明dot为1 */
if (names[n].key.len != len)
{
/* 从next_names数组中取出一个类型为ngx_hash_key_t的指针 */
next_name = ngx_array_push(&next_names);
if (next_name == NULL)
{
return NGX_ERROR;
}
/* 将该通配符第一个'.'字符之后的字符串放在next_name中 */
next_name->key.len = names[n].key.len - len;
next_name->key.data = names[n].key.data + len;
next_name->key_hash = 0;
next_name->value = names[n].value;
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"wc2: \"%V\"", &next_name->key);
#endif
}
/* 这里n为names数组中余下尚未处理的通配符字符串中的第一个在names数组中的下标值,
* 该for循环是用于提高效率,其实现就是比较当前通配符字符串与names数组中的下一个
* 通配符字符,若发现'.'字符之前的字符串都完全相同,则直接将该通配符字符串'.'
* 之后的字符串添加到next_names数组中 */
for (i = n + 1; i < nelts; i++)
{
/* 对该通配符字符串与names数组中的下一个通配符字符串进行比较,若不等,则
* 直接跳出该for循环,否则继续往下处理 */
if (ngx_strncmp(names[n].key.data, names[i].key.data, len) != 0)
{
break;
}
/* 对在该通配符字符串中没有找到'.'的通配符字符串下面不进行处理' */
if (!dot
&& names[i].key.len > len
&& names[i].key.data[len] != '.')
{
break;
}
/* 从next_names数组中取出一个类型为ngx_hash_key_t的指针 */
next_name = ngx_array_push(&next_names);
if (next_name == NULL)
{
return NGX_ERROR;
}
next_name->key.len = names[i].key.len - dot_len;
next_name->key.data = names[i].key.data + dot_len;
next_name->key_hash = 0;
next_name->value = names[i].value;
#if 0
ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0,
"wc3: \"%V\"", &next_name->key);
#endif
}
/* 若next_names数组中有元素 */
if (next_names.nelts)
{
h = *hinit;
h.hash = NULL;
if (ngx_hash_wildcard_init(&h, (ngx_hash_key_t *) next_names.elts,
next_names.nelts)
!= NGX_OK)
{
return NGX_ERROR;
}
wdc = (ngx_hash_wildcard_t *) h.hash;
if (names[n].key.len == len)
{
wdc->value = names[n].value;
}
name->value = (void *) ((uintptr_t) wdc | (dot ? 3 : 2));
}
else if (dot)
{
name->value = (void *) ((uintptr_t) name->value | 1);
}
}
if (ngx_hash_init(hinit, (ngx_hash_key_t *) curr_names.elts,
curr_names.nelts)
!= NGX_OK)
{
return NGX_ERROR;
}
return NGX_OK;
}
ngx_hash_combined_t通配符散列表的结构示意图
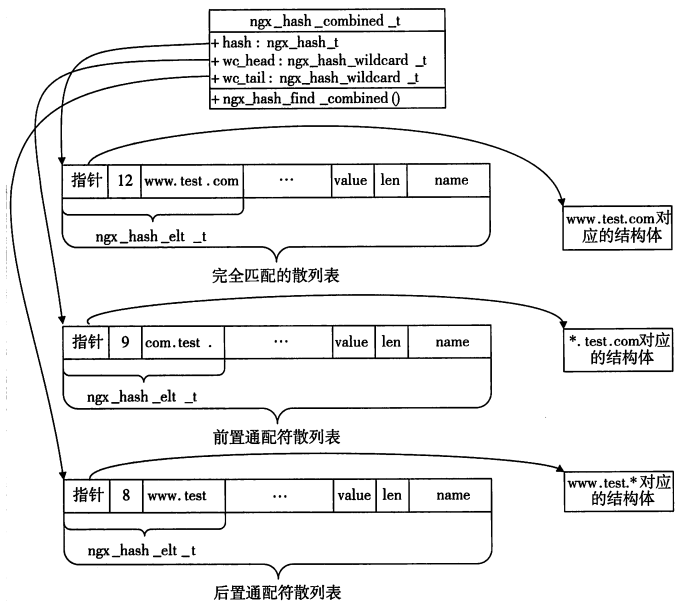
3.4 带通配符散列表的使用实例
散列表元素ngx_hash_elt_t中value指针指向的数据结构为下面定义的TestWildcardHashNode结构体,代码如下:
typedef struct {
/* 用于散列表中的关键字 */
ngx_str_t servername;
/* 这个成员仅是为了方便区别而已 */
ngx_int_t se;
}TestWildcardHashNode;
每个散列表元素的关键字是servername字符串。下面先定义ngx_hash_init_t和ngx_hash_keys_arrays_t变量,为初始化散列
表做准备,代码如下:
/* 定义用于初始化散列表的结构体 */
ngx_hash_init_t hash;
/* ngx_hash_keys_arrays_t用于预先向散列表中添加元素,这里的元素支持带通配符 */
ngx_hash_keys_arrays_t ha;
/* 支持通配符的散列表 */
ngx_hash_combined_t combinedHash;
ngx_memzero(&ha, sizeof(ngx_hash_keys_arrays_t));
combinedHash 是我们定义的用于指向散列表的变量,它包括指向 3 个散列表的指针,下面依次给这 3 个散列表指针赋值。
/* 临时内存池只是用于初始化通配符散列表,在初始化完成后就可以销毁掉 */
ha.temp_pool = ngx_create_pool(16384, cf->log);
if (ha.temp_pool == NULL)
{
return NGX_ERROR;
}
/* 假设该例子是在ngx_http_xxx_postconf函数中的,所以就用了ngx_conf_t类型的cf下的内存池
* 作为散列表的内存池 */
ha.pool = cf->pool;
/* 调用ngx_hash_keys_array_init方法来初始化ha,为下一步向ha中加入散列表元素做好准备 */
if (ngx_hash_keys_array_init(&ha, NGX_HASH_LARGE) != NGX_OK)
{
return NGX_ERROR;
}
如下代码,建立的 testHashNode[3] 这 3 个 TestWildcardHashNode 类型的结构体,分别表示可以用前置通配符匹配的散
列表元素、可以用后置通配符匹配的散列表元素、需要完全匹配的散列表元素。
TestWildcardHahsNode testHashNode[3];
testHashNode[0].servername.len = ngx_strlen("*.text.com");
testHashNode[0].servername.data = ngx_pcalloc(cf->pool, ngx_strlen("*.test.com"));
ngx_memcpy(testHashNode[0].servername.data, "*.test.com", ngx_strlen("*.test.com"));
testHashNode[1].servername.len = ngx_strlen("www.test.*");
testHashNode[1].servername.data = ngx_pcalloc(cf->pool, ngx_strlen("www.test.*"));
ngx_memcpy(testHashNode[1].servername.data, "www.test.*", ngx_strlen("www.test.*"));
testHashNode[2].servername.len = ngx_strlen("www.text.com");
testHashNode[2].servername.data = ngx_pcalloc(cf->pool, ngx_strlen("www.test.com"));
ngx_memcpy(testHashNode[2].servername.data, "www.test.com", ngx_strlen("www.test.com"));
for (i = 0; i < 3; i++)
{
testHashNode[i].seq = i;
/* 这里flag必须设置为NGX_HASH_WILDCARD_KEY,才会处理带通配符的关键字 */
ngx_hash_add_key(&ha, &testHashNode[i].servername,
&testHashNode[i], NGX_HASH_WILDCARD_KEY);
}
在调用ngx_hash_init_t的初始化函数前,先设置好ngx_hash_init_t中的成员,如槽的大小、散列方法等:
hash.key = ngx_hash_key_lc;
hash.max_size = 100;
hash.bucket_size = 48;
hash.name = "test_server_name_hash";
hash.pool = cf->pool;
ha的keys动态数组中存放的是需要完全匹配的关键字,如果keys数组不为空,那么开始初始化第 1 个散列表:
if (ha.keys.nelts)
{
/* 需要显式地把ngx_hash_init_t中的hash指针指向combinedHash中的完全匹配散列表 */
hash.hash = &combinedHash.hash;
/* 初始化完全匹配散列表时不会使用到临时内存池 */
hash.temp_pool = NULL;
/* 将keys动态数组直接传给ngx_hash_init方法即可,ngx_hash_init_t中的
* hash指针就是初始化成功的散列表 */
if (ngx_hash_init(&hash, ha.keys.nelts, ha.keys.nelts) != NGX_OK)
{
return NGX_ERROR;
}
}
下面继续初始化前置通配符散列表:
if (ha.dns_wc_head.nelts)
{
hash.hash = NULL;
/* ngx_hash_wildcard_init方法需要用到临时内存池 */
hash.temp_pool = ha.temp_pool;
if (ngx_hash_wildcard_init(&hash, ha.dns_wc_head.elts, ha.dns_wc_head.nelts) != NGX_OK)
{
return NGX_ERROR;
}
/* ngx_hash_init_t中的hash指针是ngx_hash_wildcard_init初始化成功的散列表,
* 需要将它赋到combinedHash.wc_head前置通配符散列表指针中 */
combinedHash.wc_head = (ngx_hash_wildcard_t *)hash.hash;
}
接着继续初始化后置通配符散列表:
if (ha.dns_wc_tail.nelts)
{
hash.hash = NULL;
hash.temp_pool = hs.temp_pool;
if (ngx_hash_wildcard_init(&hash, ha.dns_wc_tail.elts, ha.dns_wc_tail.nelts) != NGX_OK)
{
return NGX_ERROR;
}
/* ngx_hash_init_t中的hash指针是ngx_hash_wildcard_init初始化成功的散列表,需要将它赋到
* combinedHash.wc_tail后置通配符散列表指针中 */
combinedHash.wc_tail = (ngx_hash_wildcard_t *) hash.hash;
}
此时,临时内存池已经没有存在意义了,即ngx_hash_keys_arrays_t中的这些数组、简易散列表都可以销毁了。这里只需要
简单地把temp_pool内存池销毁即可:
ngx_destroy_pool(ha.temp_pool);
下面检查一下散列表是否工作正常。首先,查询关键字www.test.org,实际上,它应该匹配后置通配符散列表中的元素
www.text.*:
/* 首先定义待查询的关键字符串findServer */
ngx_str_t findServer;
findServer.len = ngx_strlen("www.test.org");
/* 为什么必须要在内存池中分配空间以保存关键字呢?因为我们使用的散列方法是 ngx_hash_key_l,它会试着把
* 关键字全小写 */
findServer.data = ngx_pcalloc(cf->pool, ngx_strlen("www.test.org"));
ngx_memcpy(findServer.data, "www.test.org", ngx_strlen("www.test.org"));
/* ngx_hash_find_combined方法会查找出www.test.*对应的散列表元素,返回其指向的用户数据
* ngx_hash_find_combined, 也就是testHashNode[1] */
TestWildcardHashNode *findHashNode = ngx_hash_find_combined(&combinedHash,
ngx_hash_key_lc(findServer.data, findServer.len), findServer.data, findServer.len);
如果没有查询到的话,那么findHashNode值为NULL。
接着查询www.test.com,实际上,testHashNode[0]、testHashNode[1]、testHashNode[2]这 3 个节点都是匹配的,因为
.test.com、www.test.、www.test.com都是匹配的。但按照完全匹配最优先的规则,ngx_hash_find_combined方法会返回
testHashNode[2]的地址,也就是www.test.com对应的元素。
findServer.len = ngx_strlen("www.test.com");
findServer.data = ngx_pcalloc(cf->pool, ngx_strlen("www.test.com"));
ngx_memcpy(findServer.data, "www.test.com", ngx_strlen("www.test.com");
findHashNode = ngx_hash_find_combined(&combinedHash,
ngx_hash_key_lc(findServer.data, findServer.len),
findServer.data, findServer.len);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号