Hadoop(6)hdfs的写入流程和读取流程 (重点!!!)
🌈hdfs写入流程(面试重点)
一个文件上传到hdfs文件系统的简略过程
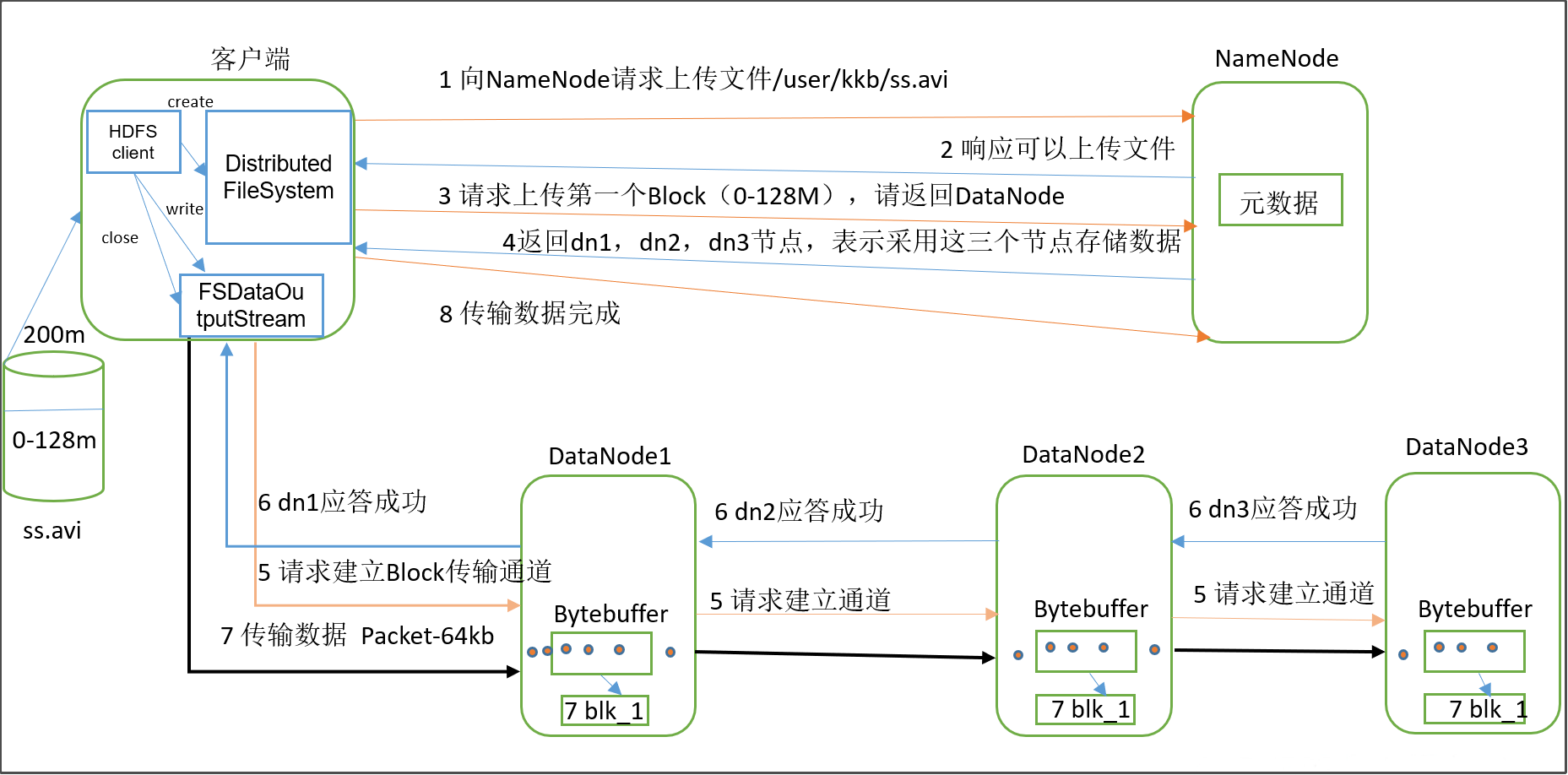
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block到服务器。(重复执行3-7步)。
一个文件上传到hdfs文件系统的详细过程
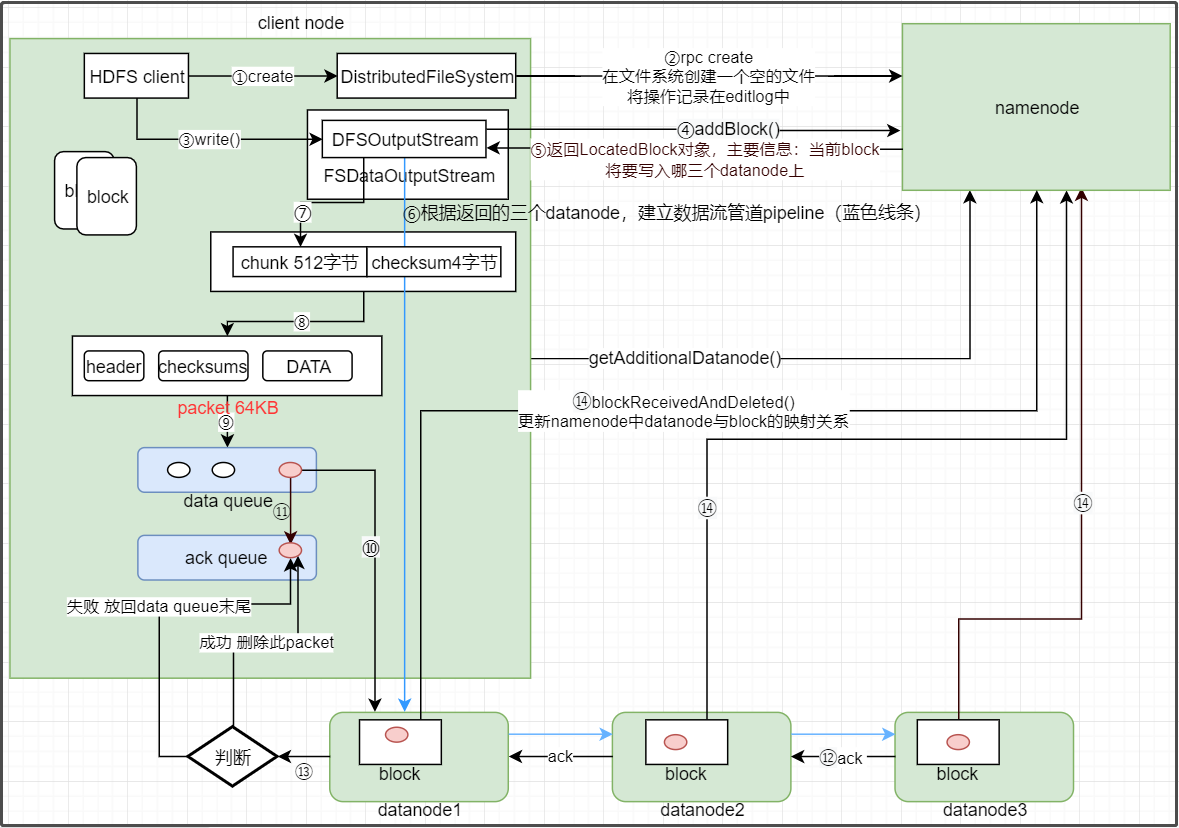
- hdfs client客户端调用DistributedFileSystem.create()方法,这个方法会通过RPC(远程过程调用)的方式调用namenode的create()方法
- namenode在hdfs文件系统创建一个空文件,并将这一个操作记录在edits.log文件中(因为创建空文件产生了新的元数据)。
- 如果namenode.create()方法没有抛出异常,就会返回给客户端一个FSDataInputStream输出流对象,FSDataInputStream类是对DFSOutputStream类的一个包装。
- 有了DFSOutputStream输出流对象后,客户端就调用方法DFSOutputStream.write()方法,这个方法会通过RPC的方式调用namenode的addBlock()方法,向namenode申请上传一个数据块。
- 调用addBlock()方法无异常后,namenode就会返回给客户端一个LocatedBlock对象,这个对象包含的主要信息是:这个block要存储在哪三个datanode节点上。
(每次启动hdfs集群,每个datanode就会通过心跳方式向namenode汇报节点磁盘使用率,然后namenode就可以通过使用情况来决定block存在哪里) - 客户端根据namenode返回的块将要存放的位置信息,建立数据流管道pipeline。
- 输出流DFSOutputSream开始读取block的数据,然后把数据写到一个叫做chunk的文件,当chunk文件写满512字节后,就会调用关于crc32的校验方法来进行数据校验,生成一个4字节的checksum校验文件。(这就是为什么JavaApi操作hdfs文件系统会生成一个.crc文件)(为什么做校验?)
- 校验后,客户端就将chunk+chumksum两个文件共516字节存放到一个有64KB容量的package里。package包括三部分(header、checksums、DATA),checksums专门用来存放校验文件,DATA专门用来存放数据。
- 当package存满64KB时,就会将package传到一个data queue数据队列(可以看成一个个package的队列)里,
- 然后将数据队列里的每个package按顺序沿着建立的数据流管道传到第1个datanode节点,再从第1个节点传到第2个节点,再从第2个节点传到第3个节点。
- 每个datanode节点接受到package之后,就会对package进行数据校验,根据数据产生新的校验值,判断新的校验值和传过来的校验值是否匹配。校验正确的结果ACK是反着pipeline方向 返回来的,datanode3--->datanode2-->datanode1。如果校验通过的话,传输就成功了。(每个datanode传输情况都正常,ACK才能返回给客户端)
- 当前正在发送的package不只是沿着数据流管道传到datanode节点,还会被存放到一个ack queue队列里。如果package传输成功的话,就会删除ack queue队列里的该package。如果不成功的话就将ack queue里的package取出来放到data queue的末尾,等待重新传输到datanode。
- 如果这个文件还有其它的块block,则重新执行上面的4-11步骤,直到文件传输完成。
- 文件传输完成后,datanode就会通过RPC远程调用namenode的blockReceivedAndDelete(),然后namenode就会更新内存中block和datanode的映射关系,更新文件和block的映射关系。
- 最后关闭pipeline数据流管道,关闭数据流DFSOutputStream.close(),客户端远程调用namenode的complete()方法,告知上传完成。
补充:
为什么做校验?因为是网络传输,可能数据传输会出现异常什么的,需要保证数据的完整和正确性。
循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种信道编码基技术,主要用来检测或校验数据传输或者保存后可能出现的错误。
CRC32: CRC本身是“冗余校验码”的意思,CRC32则表示会产生一个32bit(4字节)的校验值。由于CRC32产生校验值时源数据块的每一个bit(位)都参与了计算,所以数据块中即使只有1bit的数据发生了变化,也会得到不同的CRC32值.
什么是ACK?
ACK (Acknowledge character)即是确认字符,在数据通信中,接收站发给发送站的一种传输类控制字符。表示发来的数据已确认接收无误。
block沿着数据流管道传输的好处在哪?为什么不将块的数据分3个方向分别同时传输到不同的datanode节点?
因为沿着数据流管道传输可以将传数据的压力分配到不同的datanode节点,减少客户端负荷,效率更高。
校验失败后,package重写放到data queue的末尾,并不会打乱文件的写入,每个package都有一个seqno序号,对号入座即可。
容错机制(重新传输机制)
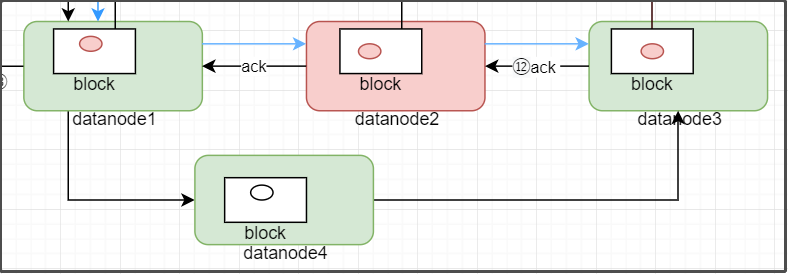
在上面的详细过程中,我们说,如果数据传输出错的话要重新传输,那重新传输的机制是怎样的?比如说,一个package通过一个数据流管道:datanode1--->datanode2--->datanode3来进行传输,如果datanode1和datanode3数据都没问题,就只有datanode2的数据传输有问题(如dn2挂了或者通信不畅了等问题),要怎么解决?
- 因为datanode2的package有问题,导致校验结果失败,客户端会将ack queue队列中的所有package放回到data queue末尾,准备重新传输该package
- 放回到data queue末尾后,客户端会RPC远程调用namenode的updataBlockForPipeline()方法,从而为当前block生成新的版本(实际上就是生成新的时间戳)。会从pipeline管道中删除datanode2。
- 客户端再RPC调用namenode的getAdditionalDatanode()方法,namenode返回给客户端一个新的datanode,比如说datanode4。
- 输出流将datanode1、datanode3、datanode4形成新的pipeline管道,并更新datanode1和datanode2中的block版本,把DN1或者DN3中更新后的block复制到DN4中,管道就重新建立好了。
- DFSOutputStream远程调用namenode的updatePipeline()方法更新元数据。
- 开始沿着新管道重新传输未完成的package。
datanode2的故障排除并重启后,会通过心跳与namenode进行通信,namenode发现datanode2上有些block的间戳是老的,datanode2就会将对应的这些block删除。
🌈hdfs读取流程(面试重点)
大致过程
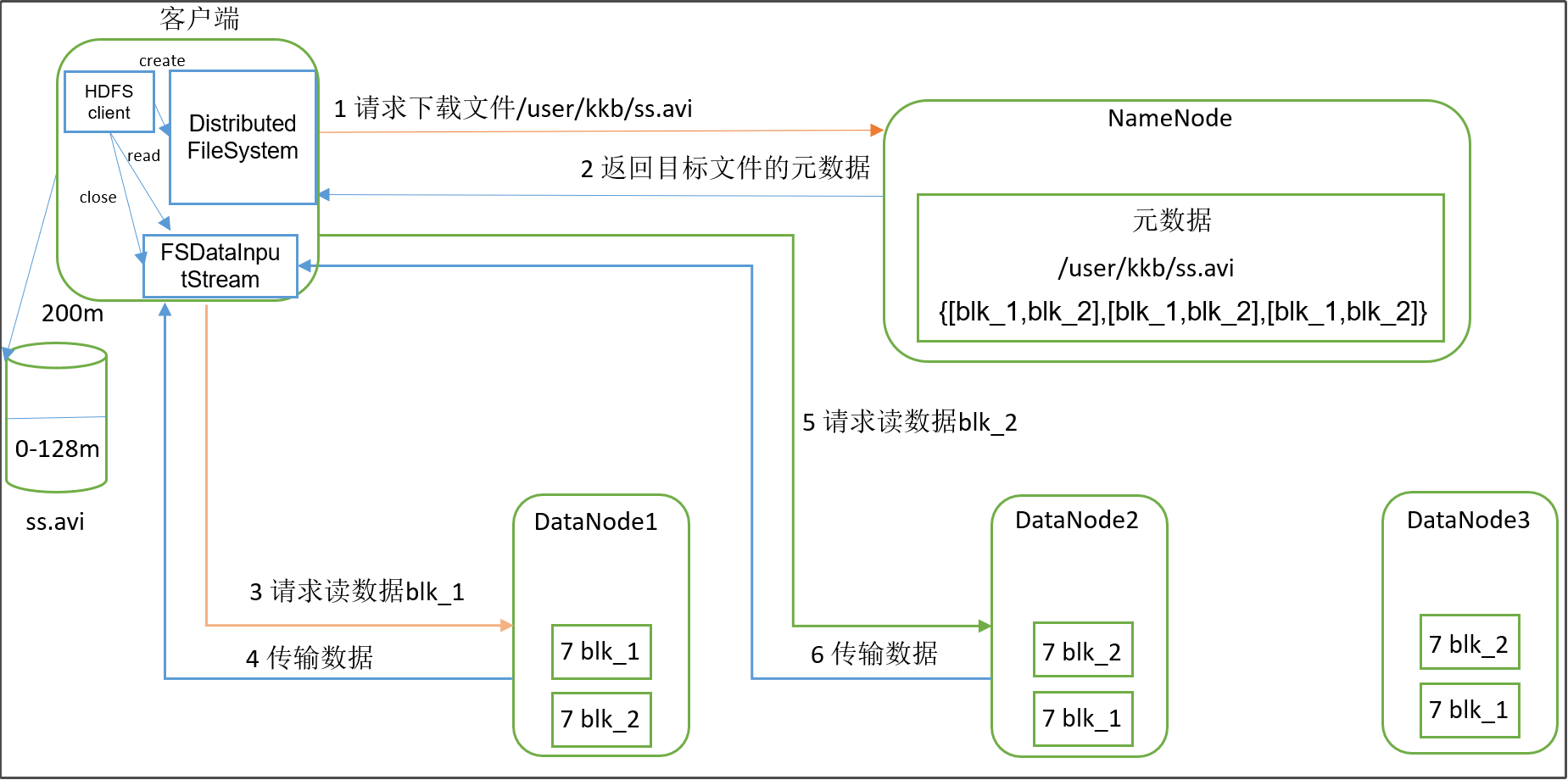
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
注意:读取一个文件不能并发读写(不能一次性读多个该文件的block),但是可以一次性读多个文件。
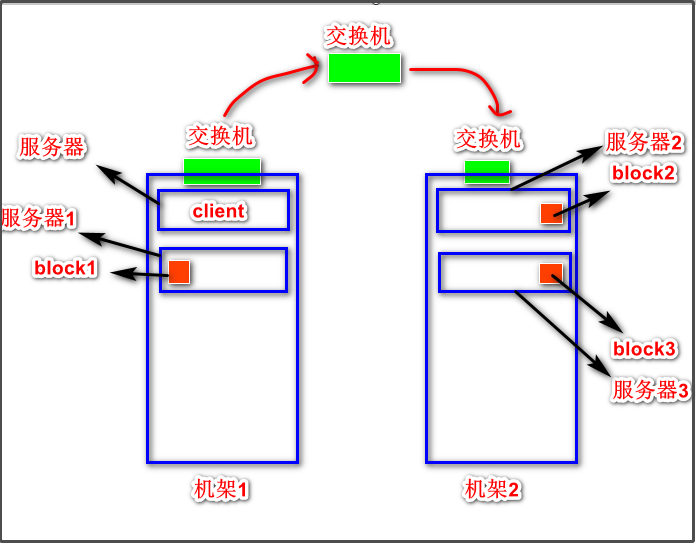
补充:如何判断客户端距离文件的某个block存放的datanode最近是谁?
从上图可以看到,文件的某个块的三个副本存放在了两个不同的机架上,其中有一个block的datanode节点服务器和客户端所在服务器是在同一台机架上的,很明显block1离客户端最近,因为如果读取block2和block3需要经过层层交换机。
容错机制
- 情况1,假如客户端从datanode1下载文件过程中,dn1挂掉了,客户端就会告知namenode:dn1挂掉了,然后客户端尝试从文件的block存放的另一个datanode节点下载数据。
- 情况2,假如客户端从datanode1下载文件过程中,dn1出现了位衰减的问题,客户端收到package后也是需要进行校验,若校验不通过,也会告知namenode:dn1有问题了,然后客户端尝试从文件的block存放的另一个datanode节点下载数据。
- 情况3,package校验不通过不一定是位衰减等问题,有可能是网络传输的问题。因此,package校验不通过不会直接换节点传输,而是首先进行重试(重新传输),如果校验结果再次不通过,客户端才会告诉namenode,节点出问题了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号