在K8s中: 网络相关(flannel和calico)

K8s 网络插件对比
说到网络插件对比之前、先说一下网络插件的两大功能:
1、实现pod的网络
2、实现网络策略 Network Policy
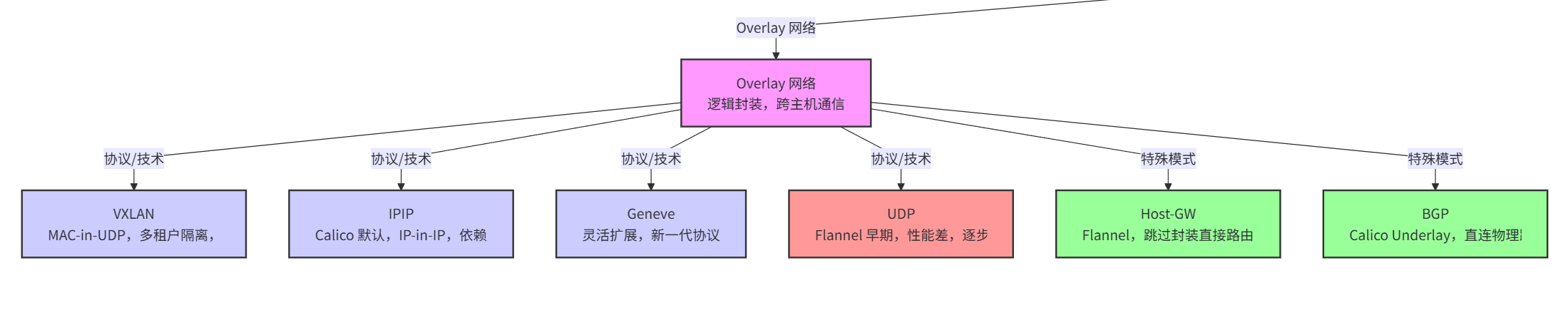
1. Overlay 网络
定义:在现有网络(Underlay)之上构建的逻辑网络,通过封装实现跨主机通信。
核心协议与技术:
- VXLAN(虚拟扩展局域网):最常用,通过 MAC-in-UDP 封装,支持大规模多租户隔离。
- IPIP(IP in IP):Calico 的默认模式,轻量级但依赖底层网络允许 IP 封装。
- GRE(通用路由封装):支持多协议封装,但性能开销较高。
- Geneve(通用网络虚拟化封装):新一代协议,灵活扩展性强(如 OpenStack 中使用)。
- UDP:Flannel 的早期模式,性能较差,已逐渐被 VXLAN 替代。
适用场景:
- 跨云/跨数据中心通信
- 需要灵活隔离的多租户环境
2. Underlay 网络
定义:物理或虚拟化的底层网络基础设施,直接承载数据流量。
核心技术:
- VLAN(虚拟局域网):传统二层隔离,通过 802.1Q 标签划分广播域。
- WLAN(无线局域网):适用于边缘计算或混合部署。
- MPLS(多协议标签交换):运营商级流量工程,低延迟高可靠。
- BGP(边界网关协议):Calico 在 Underlay 模式下直接使用 BGP 路由分发。
适用场景:
- 高性能、低延迟需求(如金融交易系统)
- 物理网络可控的环境(如私有云、裸金属集群)
3、网络模型流程

网络模型
├─ Overlay 网络(逻辑封装,跨主机通信)
│ ├─ 协议/技术:VXLAN(MAC-in-UDP,多租户隔离,性能较高)
│ ├─ 协议/技术:IPIP(Calico 默认,IP-in-IP,依赖底层,性能中等)
│ ├─ 协议/技术:Geneve(灵活扩展,新一代协议)
│ ├─ 协议/技术:UDP(Flannel 早期,性能差,逐步被替代)
│ ├─ 特殊模式:Host-GW(Flannel,跳过封装直接路由,性能最高)
│ └─ 特殊模式:BGP(Calico Underlay,直连物理路由器,性能最高)
└─ Underlay 网络(物理/底层承载)
├─ 技术:VLAN(802.1Q 二层隔离,传统广播域划分)
├─ 技术:MPLS(运营商级流量工程,低延迟高可靠)
├─ 技术:BGP 物理路由器(对接 Calico BGP 模式)
└─ 技术:WLAN(无线场景,边缘计算/混合部署)
%% 性能排序标注:Host-GW/BGP > VXLAN/Geneve > IPIP > UDP
4、Kubernetes 网络插件对比(含支持规模)
| 插件 | 支持模式 | 封装协议 | 支持规模 | 特点 |
|---|---|---|---|---|
| Calico | IPIP、VXLAN、BGP(Underlay) | IPIP / VXLAN | ≤ 10k Pods,≤ 1k Nodes | 高性能、策略驱动,适合大规模集群 |
| Flannel | VXLAN、Host-GW、UDP | VXLAN / UDP | ≤ 1k Pods,≤ 100 Nodes | 简单易用,适合中小规模集群 |
| Cilium | Overlay + eBPF(直接路由) | VXLAN / Geneve | ≤ 50k Pods,≤ 5k Nodes | 基于 eBPF 的高性能网络与安全策略 |
| Weave Net | Overlay | 自有协议(FastDP) | ≤ 500 Pods,≤ 50 Nodes | 无依赖、支持多播,但性能中等 |
重点:BGP是Underlay模式、跨路由的才会使用VXLAN
K8s flannel
Flannel 协议模式详解
重点:VXLAN和host-gateway的不同之处 ?
VXLAN是flanneld内部维护路由表来转发的报文请求(由flanneld转发)
host-gateway是由flanneld进程读取所有节点对应的路由、然后写到该node节点、后续直接转发、不需要flanneld参与
1. VXLAN 模式
原理:
- 封装方式:在原始 L2 帧(Pod 流量)外封装 VXLAN 头 + UDP 头,通过底层网络传输。
- 外层头:源/宿主机 IP + UDP 端口(默认 8472)。
- VXLAN 头:包含 VNI(虚拟网络标识符,Flannel 默认为 1)。
- 工作流程:
- Pod A 发送数据包到 Pod B(跨节点)。
- Flannel 通过 etcd 或 Kubernetes API 查询 Pod B 所在节点的 IP 和 VXLAN 隧道端点(VTEP)。
- 在源节点封装 VXLAN 包,通过底层网络发送到目标节点。
- 目标节点解封装,将原始帧传递给 Pod B。
性能特点:
- 优点:支持跨三层网络通信,隔离性好(通过 VNI)。
- 缺点:封装/解封装有 CPU 开销(约 10-15% 带宽损耗)。
适用场景:
- 节点位于不同子网或云环境。
- 需要多租户隔离的中等规模集群(≤500 节点)。
2. Host-GW 模式(Host Gateway)
原理:
- 无封装:直接利用节点的路由表,将 Pod 流量转发到目标节点。
- 每条路由格式:
<目标 Pod CIDR> via <目标节点 IP> dev <本地网卡>。
- 每条路由格式:
- 工作流程:
- Pod A 发送数据包到 Pod B(跨节点)。
- 源节点根据路由表,将包直接发给目标节点(需二层互通)。
- 目标节点通过本地网卡接收并转发给 Pod B。
性能特点:
- 优点:零封装开销,性能接近裸金属网络(吞吐量 ≈ 底层网络极限)。
- 缺点:要求所有节点在同一二层网络(不支持跨子网)。
适用场景:
- 私有化部署且节点间二层直连(如裸金属或同子网虚拟机)。
- 超低延迟/高吞吐需求(如金融交易系统)。
模式对比总结
| 模式 | 封装开销 | 网络要求 | 性能 | 推荐场景 |
|---|---|---|---|---|
| VXLAN | 中等 | 跨三层网络 | 中等(≈50-70% 带宽利用率) | 云环境/跨子网集群 |
| Host-GW | 无 | 节点间二层互通 | 高(≈95%+ 带宽利用率) | 同子网私有化部署 |
| UDP | 极高 | 无要求 | 极低(≤30% 带宽利用率) | 已弃用,仅测试 |
底层依赖与限制
- VXLAN 模式:
- 要求 Linux 内核 ≥3.7(支持
vxlan模块)。 - 需开放 UDP 8472 端口(可修改)。
- 要求 Linux 内核 ≥3.7(支持
- Host-GW 模式:
- 节点间需直接路由可达(不能有 NAT)。
- 若节点跨子网需手动配置静态路由。
扩展知识:Flannel 的改进方向
- IPVS 替代 iptables:新版本支持 IPVS 提升 Service 性能。
- WireGuard 加密:实验性支持 WireGuard 加密隧道(替代 UDP/VXLAN)。
K8s calico
Calico 协议模式详解
1. IPIP 模式(IP in IP)
原理:
- 封装方式:在原始 Pod IP 包外封装新的 IP 头(协议号 4),源/目标地址为节点 IP。
- 外层头:源节点 IP → 目标节点 IP(协议号 4,标识 IPIP 封装)。
- 内层头:保留原始 Pod A IP → Pod B IP。
- 工作流程:
- Pod A 发送数据包到跨节点 Pod B,目标 IP 为 Pod B。
- Calico 根据路由表(
ip route)发现目标需通过 IPIP 隧道到达。 - 内核自动封装 IPIP 包,通过物理网络发送到目标节点。
- 目标节点解封装,将原始包传递给 Pod B。
性能特点:
- 优点:比 VXLAN 轻量(少 UDP 头),适合节点间跨子网通信。
- 缺点:
- 部分云厂商禁止 IPIP 封装(如 AWS 需手动启用)。
- MTU 需减少 20 字节(外层 IP 头),可能影响大包性能。
适用场景:
- 私有云或允许 IPIP 的云环境(如 OpenStack)。
- 中等规模集群(≤1k 节点),需平衡性能与灵活性。
2. VXLAN 模式
原理:
- 封装方式:类似 Flannel VXLAN,但由 Calico 控制平面管理 VTEP。
- 外层头:源/目标节点 IP + UDP 头(端口 4789)。
- VXLAN 头:VNI 默认 4096(可配置),隔离租户流量。
- 工作流程:
- Pod A 发送数据包,Calico 通过 BGP 或静态配置确定目标节点 VTEP。
- 内核封装 VXLAN 包,通过底层网络发送。
- 目标节点解封装,根据 VNI 和 MAC 表转发到 Pod B。
性能特点:
- 优点:支持跨云/数据中心,隔离性好(通过 VNI)。
- 缺点:封装开销大于 IPIP(多 UDP + VXLAN 头,约 50 字节额外开销)。
适用场景:
- 多租户或云环境需网络隔离(如混合云部署)。
- 节点位于不同三层网络且 IPIP 不可用。
3. BGP 模式(纯三层路由)
原理:
- 无封装:节点通过 BGP 协议交换路由信息,直接路由 Pod IP。
- 每个节点向邻居(物理路由器或其他节点)宣告其 Pod CIDR。
- 路由表条目示例:
10.244.1.0/24 via 192.168.1.2 dev eth0。
- 工作流程:
- Pod A 发送数据包到 Pod B,目标 IP 为 Pod B。
- 源节点查询路由表,直接通过物理网络发送到目标节点(无封装)。
- 目标节点接收并转发给 Pod B。
性能特点:
- 优点:零封装开销,性能最佳(吞吐量 ≈ 物理网络极限)。
- 缺点:
- 要求节点间二层或三层直连(需 BGP 邻居可达)。
- 大规模集群需 BGP 路由优化(如 RR 路由反射器)。
适用场景:
- 裸金属或私有云环境,网络设备支持 BGP。
- 超大规模集群(≥1k 节点),如互联网公司数据中心。
模式对比总结
| 模式 | 封装开销 | 网络要求 | 延迟 | 吞吐量 | 适用场景 |
|---|---|---|---|---|---|
| IPIP | 20 字节(IP 头) | 允许 IPIP 封装的跨子网 | 中 | 中高 | 私有云/跨子网中等集群 |
| VXLAN | 50 字节(UDP+VXLAN) | 跨三层网络,开放 UDP 4789 | 中高 | 中 | 多租户/云隔离环境 |
| BGP | 无封装 | 节点/路由器支持 BGP | 最低 | 最高 | 裸金属/超大规模集群 |
底层依赖与限制
- IPIP/VXLAN 模式:
- 要求 Linux 内核支持
ipip或vxlan模块。 - MTU 需调整(IPIP:MTU-20,VXLAN:MTU-50)。
- 要求 Linux 内核支持
- BGP 模式:
- 需部署 BGP 路由反射器(大规模集群)。
- 云厂商限制(如 AWS 不支持节点与外部 BGP 对等)。
高级功能扩展
- eBPF 数据平面:
- 替代 iptables,提升 Service 性能(类似 Cilium),支持 DSR(直接服务器返回)。
- WireGuard 加密:
- 所有模式均可叠加 WireGuard,实现加密隧道(性能损失约 10-15%)。
配置示例(BGP 模式)
# calico-config.yaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-pool
spec:
cidr: 10.244.0.0/16
ipipMode: Never # 禁用 IPIP
natOutgoing: true
nodeSelector: all()
---
# 启用 BGP 对等
calicoctl apply -f - <<EOF
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: peer-to-router
spec:
peerIP: 192.168.1.1 # 物理路由器 IP
asNumber: 64512 # 本地 AS 号
EOF
问题 ?
1、flannel和calico的默认网络模型 ?这两种插件都支持什么网络模型 ? 为什么 ?
首先:这两种网络插件使用的都不是BGP、都会认为所在的网络不支持BGP、假设任务节点是跨路由器、所以就不支持BGP
flannel:默认VXLAN(Overlay 作为网络模型)
支持什么网络模型:BGP三层路由、
还支持三层路由+VXLAN(跨路由器就转成VXLAN、不跨路由就自动使用BGP)
calico:默认IP-in-IP(隧道模式)
支持什么网络模型:IP-in-IP和 BGP协议+VXLAN
2、flannel插件的host-gateway网络模式的工作逻辑 ?(节点必须工作在二层网络)
1、host-gateway工作时候、是需要创建路由表、创建当前节点、到每个节点pod网络的路由规则、都会创建出来、是每个节点都会启动一个flanneld的pod、这个pod相当于一个守护进程、会把当前node对应的路由表写到etcd、每搁一段时间就刷新自己的信息、然后时不时的watch数据库etcd、获取信息、如果不刷新、就说明此node节点挂了,etcd就把记录给删除了、其它节点就watch到此节点挂了、就把关于挂机的node路由表删除。
优缺点:
1、这种模式的优点是简单且性能较高,但缺点是需要所有节点在同一个二层网络中,因为它是基于主机网关的直接路由。
2、实现方法都需要依赖网络来实现、依赖查询数据库、还需要依赖一个进程。
host-gateway模式的路由表规则:比如我们的k8s集群有三个节点
主节点(10.0.0.31):10.244.0.0/24
从节点 1(10.0.0.32):10.244.1.0/24
从节点 2(10.0.0.33):10.244.2.0/24
主节点(10.0.0.31)
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 flannel.1
10.244.1.0 10.0.0.32 255.255.255.0 UG 0 0 0 eth0
10.244.2.0 10.0.0.33 255.255.255.0 UG 0 0 0 eth0
从节点 1(10.0.0.32)
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.244.0.0 10.0.0.31 255.255.255.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 flannel.1
10.244.2.0 10.0.0.33 255.255.255.0 UG 0 0 0 eth0
从节点 2(10.0.0.33)
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.244.0.0 10.0.0.31 255.255.255.0 UG 0 0 0 eth0
10.244.1.0 10.0.0.32 255.255.255.0 UG 0 0 0 eth0
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 flannel.1
3、BGP和 host-gw有什么区别 ?
共同点:
都是物理网络、基于Underlay、直接利用物理网络路由,无封装开销(性能优于 VXLAN/IPIP)。
均需 节点间路由可达(BGP 动态学习,Host-GW 静态配置)。
不同点:
BGP: 是动态协议,自动同步路由,适合复杂网络。
host-gw:是静态配置,依赖手动维护路由表,仅适合简单环境。
本质区别
| 特性 | BGP(Border Gateway Protocol) | Host-GW(Host Gateway) |
|---|---|---|
| 协议类型 | 动态路由协议(标准化,跨设备交互) | 静态路由(手工配置,节点间直连) |
| 工作原理 | 节点自动向物理路由器/其他节点宣告 Pod 网段 | 节点手动写入其他节点的 Pod 网段路由 |
| 封装开销 | 无封装(纯三层路由) | 无封装(纯三层路由) |
| 网络要求 | 需支持 BGP 的网络设备(如路由器/交换机) | 节点间需二层互通(同一子网) |
| 扩展性 | 支持超大规模集群(通过路由反射器) | 仅适合中小规模集群(≤100 节点) |
4、calico插件的工作逻辑 ?(三层网络:三层路由BGP功能)
工作流程:需要部署一个进程、把当前node配置成BGP路由器、来通告路由表、这样不需要像flannel依赖etcd查询数据库的方式。
1、直接把节点本身的内核之上运行一个进程、这个进程可以把节点自身配置成BGP协议的路由器、通过BGP协议对外广播、(通告:通告自己所接入的子网是什么、通告自身有几个pod、每个pod的ip地址)
2、这个每个节点都互相通告出去、节点互相学习生成路由表、这样就形成了路由表。
5、BGP如何跨路由器学习 ?
(1)数据流示例
假设:
- Node1(Pod CIDR:
10.244.1.0/24) ↔ 物理路由器A ↔ 物理路由器B ↔ Node2(Pod CIDR:10.244.2.0/24)。
路由同步流程:
- Node1 向 路由器A 宣告路由:
10.244.1.0/24(下一跳Node1-IP)。 - 路由器A 通过 BGP 将路由传递给 路由器B。
- 路由器B 学习到路由后,将
10.244.1.0/24的下一跳指向Node1-IP。 - Node2 向 路由器B 宣告路由:
10.244.2.0/24(反向同理)。
结果:
- 所有路由器均知道如何转发 Pod 流量,实现跨节点、跨路由器的直接通信。
6、calico和flannel的区别 ?
从哪几个角度去说:
1、两种插件的核心定位(默认网络模型和底层使用进程的逻辑)
2、使用网络模型和协议对比
3、支持使用规模、应用场景
扩展:谁支持公有云场景、谁支持网络策略
白话总结:(无非就是Underlay和Overlay的区别)
1、先说Underlay吧:(第一种方案、私有云、物理裸机环境)
如果使用flannel的话、host-gw直接路由模式、就必须在二层子网之间工作、不能跨路由、性能最强的、适合小规模集群的场景、(此时pod和node就会受到限制)不支持网络策略。
如果使用calico的话、BGP直接路由通告模式、工作在三层网络、相互学习、能跨路由器、支持网络策略。支持超大规模集群场景。(calico会在节点内核上启动一个进程、由这个进程动态管理路由表)
2、如果使用Overlay的话
flannel:VXLAN 隧道封装、性能没有calico的IPIP强 缺点:解封装性能消耗
优点:可以使用host-gw + VXLAN(同一子网就走host-gw)
calico:IPIP 隧道封装IP头、支持大规模pod、 缺点:解封装需要性能开销、
calico:VXLAN 隧道封装比IPIP封装多、 缺点:解封装需要性能开销、没有IPIP性能强。
3、打个比喻去选择、如果1000pod或以上的集群、如果是私有云环境、想要用网络策略功能、直接使用calico的BGP、性能会更好、如果使用公有云部署、建议使用IPIP方式。
4、如果是100-300pod的业务场景、对安全要求不高、不使用网络策略的话、并且不夸路由的话、建议使用flannel的host-gw模式。
5、公有云有自己研发的更适配的网络插件、建议使用云厂商提供的专属网络插件。
7、其它网络插件有什么、有什么了解的吗 ?
cilium:使用eBPF网络模型
1、内核级的、增强版的更强大的netfilter(把内核定义成为了高级的更强大的可编程的接口)
当我们想要实现许多功能时候:
1、假如想要把内核当作防火墙使用时候、直接通过网络插件修改接口去送iptables规则。
2、把linux主机当负载均衡器时候、直接去送ipVS规则。
3、eBPG增强了接口的可编程性、过去在名称空间中实现的功能、都可以在内核中实现。
4、它能提供网络、相当于直接从内核去配置svc到pod的映射、不需要iptables或ipvs了、想当于把kube-proxy给废了
8、如何选择网络插件 ?
1、部署公有云环境(共有云不支持Underlay、公有云环境自身就是基于Overlay开发的)
flannel的VXLAN模式
calico的IPIP模式
2、部署私有云环境
calico的BGP
flannel的host-gateway
注意:Underlay没有隧道、无性能开销、性能取决于宿主机的网络性能。
(Underlay使用IPVLAN和MACVLAN时候瞬间拉起大量pod的时候比较慢)
Overlay需要性能开销、创建大量pod时候才会有优势、比如集群崩了、重新拉起所有pod
9、如何配置网络插件、设置使用的网络模型 ?
使用configmap来配置
10、VXLAN模型的跨节点之间的pod访问流程及抓包验证 ?
#flannel模式:pod-A访问pod-B的流程
数据流:
Pod A(Node 1)发送数据 → Flannel 封装成 VXLAN 包 → 通过 Node 1 的网卡发送。
Node 2 接收 VXLAN 包 → Flannel 解封装 → 转发给 Pod B。
pod-A
cni0(路由器)
flannel.1(隧道接口)
eth0----->到达对端eth0
eth0(到达物理接口)
flannel.1(再到达隧道接口)
cni0(再到达路由器)
pod-B(到达目标pod)
如何抓包进行验证 ?
host-gw:
1、在源pod抓包、在源节点抓包(抓取出去的包)
抓cni0的包:tcpdump -i cni0 -nn tcp src port 80
抓eth0的包:tcpdump -i eth0 -nn tcp src port 80
2、在目标节点抓包、在目标pod抓包(抓取收到的包)
抓eth0的包:tcpdump -i eth0 -nn tcp dst port 80
抓cni0的包:tcpdump -i cni0 -nn tcp dst port 80
如果使用VXLAN封装、隧道会使用UDP进行传输、目的协议、出口网络使用的是UDP的8472端口、就需要抓UDP的8472目标端口 ?
在node1抓取到node2的8472端口的报文
抓UDP出口到目标网络:tcpdump -i eth0 -nn udp dst port 8472
K8s 网络策略
网络策略:Network Policy(必须依赖网络插件才能实现)
1、实现多租户之间的隔离、限制跨名称空间、跨节点、跨pod之间的访问
网络策略实现方法:
1、标签选择器
原因:
pod可能在同一个节点之上
pod跨节点
pod跨名称空间
网络策略有2种
ingress 入口
egress 出口
本章相关命令
#修改物理插件的configmap命令
#导出修改或者直接edit修改
[root@k8s-31:~]# kubectl edit configmap -n kube-system calico-config
#抓包命令
tcpdump -i eth0 -nn tcp dst port 80
#查看节点子网命令、节点路由信息命令
route -n
#查看物理插件信息、然后重启
kubectl get ds -n kube-flannel
kubectl rollout restart daemonset -n kube-system calico-node

 浙公网安备 33010602011771号
浙公网安备 33010602011771号