
大数据Spark实时处理--实时数据交换2(Kafka)
- Kafka Producer API编程
- 1)工作当中,使用Kafka的场景:和流处理进行关联/对接。也就是通过流处理系统(Spark Streaming\Flink\Storm流处理引擎)对接Kafka的数据,然后获取topic里的数据,进行消费和统计分析。这种场景一般是使用API的方式进行交互的。接下来,讲解使用API的方式来操作Kafka。
- 2)按照之前的传统----->spark-log4j----->new----->Module----->Maven----->next----->Artifactld:log-kafka-api----->Modele name:log-kafka-api----->Finish
- 在项目spark-log4j中,多了一个log-kafka-api的子工程。
- 在主工程的pom.xml中,多了log-kafka-api的配置。
- 3)使用Api进行开发,要将kafka的包导入
- 主工程的pom.xml中,添加kafka版本号:
<properties>
<kafka.version>2.5.0</kafka.version>
</properties>
- 主工程的pom.xml中,导入kafka包:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
- 子工程log-kafka-api的pom.xml中,添加dependency:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
</dependencies>
- 更新Maven,导入依赖包:右键----->Maven----->Reload Project
- 4)创建package及生产者class
- 路径:C:\Users\jieqiong\IdeaProjects\spark-log4j\log-kafka-api\src\main\java
- new package:com.imooc.bigdata.kafka----->new java class:ImoocKafkaProducer
- 记住:程序不需要死记硬背,只需记住入口点KafkaProducer(可以看源码)
package com.imooc.bigdata.kafka; /* * 此API的作用:是一个Kafka客户端向Kafka集群上的一个topic发送记录的 */ import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class ImoocKafkaProducer { public static void main(String args[]){ // ***第2步:new一个properties // 输入new Properties().var Properties props = new Properties(); // ***第7步:放信息put(key,value) // 目前Properties()里还是空的 // 往Properties()放哪些信息呢? // 源码里无示例:KafkaProducer<String, String> producer // 作用:使用producer发送记录record,是使用strings类型和key\value模式。 // ***第8步:kafka服务器地址 props.put("bootstrap.servers","spark000:9092"); // ***第9步:后续讲 props.put("acks","all"); // ***第10步: // key的序列化 props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); // ***第11步: // value的序列化 props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); // 入口点:KafkaProducer<>() // ***第1步:new KafkaProducer<>() // 看源码:构造器KafkaProducer(Properties properties) // ***第3步:将上面new的properties的props放入() // ***第4步:new KafkaProducer<>(properties).var选择producer // 看源码:KafkaProducer<String, String>的KafkaProducer类,很重要:KafkaProducer<K, V> implements Producer<K, V> // KafkaProducer<K, V> implements Producer<K, V>实现了一个Producer接口,有事务的初始化/开始、发送偏移量offset、提交事务等。 // KafkaProducer<K, V> implements Producer<K, V>,是一个Kafka客户端向Kafka集群上的一个topic发送记录的。 // ***第5步:将KafkaProducer<Object, Object>中改为KafkaProducer<String, String> // ***第6步:KafkaProducer<>(props)改为:KafkaProducer<String, String>(props) KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props); // ***第12步 //开始发数据 for (int i = 0; i < 100; i++){ //构建一条记录,通过producer发过去, //send选择record; //在send()中new ProducerRecord<String, String>() //看ProducerRecord源码:在这里选择一个比较简单的ProducerRecord(String topic, K key, V value) producer.send(new ProducerRecord<String, String>("zhang-replicated-topic",i+"",i+"")); } // ***第14步 // 控制台输出信息 System.out.println("消息发送完毕..."); // ***第13步 //关闭producer producer.close(); } }
- 5)虚拟机开启producer和consumer
[hadoop@spark000 ~]$ kafka-console-producer.sh --bootstrap-server spark000:9092 --topic zhang-replicated-topic
>
[hadoop@spark000 ~]$ kafka-console-consumer.sh --bootstrap-server spark000:9092 --topic zhang-replicated-topic
- 6)consumer端成功接收消息
- 运行ImoocKafkaProducer.java程序,consumer自动接收1-99消息。
- Kafka Consumer API编程
- 1)创建消费者class
- 路径:C:\Users\jieqiong\IdeaProjects\spark-log4j\log-kafka-api\src\main\java\com\imooc\bigdata\kafka
- new java class ----->ImoocKafkaConsumer.java
- 2)同理,这样的开发只需要记住入口点。
package com.imooc.bigdata.kafka; /* * 此API作用:一个客户端从kafka集群消费/记录数据 */ import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Arrays; import java.util.Properties; public class ImoocKafkaConsumer { public static void main(String args[]){ // ***第2步 // new Properties().var Properties properties = new Properties(); // ***第5步 // 作用:kafka consumer api 自动提交偏移量offset // 源码里无示例:KafkaProducer<String, String> consumer // ***第6步:kafka服务器地址 properties.put("bootstrap.servers","spark000:9092"); // ***第7步:consumer group.id properties.put("group.id","jieqiong-group"); // ***第8步:自动提交偏移量 properties.put("enable.auto.commit","true"); // ***第9步:key的反序列化 // 因为在producer有一个序列化,所以在consumer有一个反序列化 properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); // ***第10步:value的反序列化 properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); // 入口点 // ***第1步:new KafkaConsumer<>() // 看源码:无参构造public KafkaConsumer(Properties properties) // ***第3步:将properties放入new KafkaConsumer<>(properties) // ***第4步:new KafkaConsumer<>(properties).var选择consumer // 看源码:KafkaConsumer<K, V> implements Consumer<K, V>,一个客户端从kafka集群消费/记录数据 // Consumer要比Producer复杂 // 第19步:将KafkaConsumer<Object, Object>改为KafkaConsumer<String, String> KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties); // ***第11步:开始consumer // 具体消费spark000上的哪一个topic // 选择consumer.subscribe(Collection<String> topics) void // ***第12步:往consumer.subscribe();中放一个集合Arrays.asList() // 若有多个集合,使用逗号隔开即可。 // consumer去订阅zhang-replicated-topic这个topic consumer.subscribe(Arrays.asList("zhang-replicated-topic")); // ***第13步: // 对consumer来说,是源源不断的,只要producer产生数据传递到consumer,都要消费/记录到。 while (true) { // ***第14步:如何记录/消费数据的? // consumer.选择poll(Duration) // 看源码:ConsumerRecords<K, V> poll(Duration var1); 这是Duration的一个时长。 // ***第15步:选择毫秒consumer.poll(Duration.ofMillis(1000)) // 在Duration的一个时长里,不要超时即可。 // ***第16步:consumer.poll(Duration.ofMillis(1000)).var // ***第17步:将poll改为records // ***第18步:将ConsumerRecords<Object, Object>改为ConsumerRecords<String, String> ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); // ***第20步:有了records,做输出 // 使用ConsumerRecord做增强的for循环 // ConsumerRecords是一个集合,是一堆的List<ConsumerRecord<K, V> // 注意循环里是单数的ConsumerRecord for (ConsumerRecord record : records ){ // ***第21步:记录输出 // 在控制台输出结果 // key值为空,是一般我们不关注key值 // value值,即在producer端输入的值 // topic值,即默认的zhang-replicated-topic // 偏移量值,即从215开始 // 我们看一下有没有分区信息,我们是单节点的,在这个topic里只有一个分区,分区副本系数也为1,所以这里的值为1. System.out.println(record.key() + "\t" + record.value() + "\t" + record.topic() + "\t" + record.offset() + "\t" + record.partition() ); } } } }
- 3)在producer处,输入数据,并在控制台接收
[hadoop@spark000 ~]$ kafka-console-producer.sh --bootstrap-server spark000:9092 --topic zhang-replicated-topic >zhang >jie >qiong >1 >2 >3
- Kafka对接Flume收集的数据
- 1)即将Kafka和Flume,这一链路打通。
- 也就是说,在整个流处理的过程中,数据产生之后,通过Flume收集数据,将数据交给Kafka的。再由后续的流处理对接Kafka。
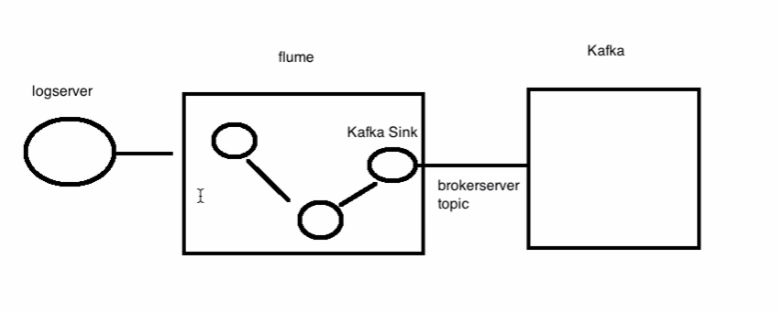
- 2)Flume----->Kafka sink:Flume 1.9.0 User Guide — Apache Flume
- 作用是,将flume中的数据输出至Kafka的topic里。
- sink.type = org.apache.flume.sink.kafka.KafkaSink
- kafka.bootstrap.servers = spark000:9020 若是多个,则用comma分隔即可。
- kafka.topic = zhang-replicated-topic
- kafka.producer.acks = 1 确保数据是否能够接收,是否有反馈。
- 3)配置Flume的agent
[hadoop@spark000 config]$ pwd /home/hadoop/app/apache-flume-1.6.0-cdh5.16.2-bin/config [hadoop@spark000 config]$ vi flume-kafka.conf # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 44444 # Use a channel which buffers events in memory a1.channels.c1.type = memory # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = zhang-replicated-topic a1.sinks.k1.kafka.bootstrap.servers = spark000:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- 4)执行flume脚本
- 在路径下:/home/hadoop/app/apache-flume-1.6.0-cdh5.16.2-bin/config
- agent的名字是a1
- 默认FLUME_HOME/conf
- 写入配置文件所在路径:$FLUME_HOME/config/flume-kafka.conf
- 在控制台输出数据:Dflume.root.logger=INFO,console
flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/flume-kafka.conf \ -Dflume.root.logger=INFO,console
- 5)连接
[hadoop@spark000 ~]$ telnet spark000 44444 Trying 192.168.131.66... Connected to spark000. Escape character is '^]'. testflume01 OK tes OK testflume02 OK
- 6)在consumer端查看结果
[hadoop@spark000 ~]$ kafka-console-consumer.sh --bootstrap-server spark000:9092 --topic zhang-replicated-topic
testflume01
tes
testflume02
- 对接项目数据到Kafka
- 1)Flume对应Kafka的producer,然后数据sink到Kafka的topic中,最后consumer到topic取数据并消费掉。
- 2)配置Flume的agent。
[hadoop@spark000 config]$ pwd /home/hadoop/app/apache-flume-1.6.0-cdh5.16.2-bin/config [hadoop@spark000 config]$ vi access-kafka.conf
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.channels = c1 a1.sources.r1.positionFile = /home/hadoop/tmp/position/taildir_position.json a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /home/hadoop/logs/access.log a1.sources.r1.headers.f1.headerKey1 = zhang a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = zhang-replicated-topic a1.sinks.k1.kafka.bootstrap.servers = spark000:9092,spark000:9093,spark000:9094 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- 3)开始对接项目数据
- 4)一定要记得开启zookeeper、Kafka服务器
[hadoop@spark000 ~]$ jps -m 7186 Kafka /home/hadoop/app/kafka_2.12-2.5.0/config/server-zhang0.properties6823 QuorumPeerMain /home/hadoop/app/zookeeper-3.4.5-cdh5.16.2/bin/../conf/zoo.cfg 7591 Kafka /home/hadoop/app/kafka_2.12-2.5.0/config/server-zhang1.properties 7999 Kafka /home/hadoop/app/kafka_2.12-2.5.0/config/server-zhang2.properties
- 5)启动consumer
[hadoop@spark000 ~]$ kafka-console-consumer.sh --bootstrap-server spark000:9092,spark000:9093,spark000:9094 --topic zhang-replicated-topic
- 6)启动Flume脚本
- 路径:/home/hadoop/app/apache-flume-1.6.0-cdh5.16.2-bin/config
flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/config/access-kafka.conf \ -Dflume.root.logger=INFO,console
- 7)开始对接数据
- 先打开consumer终端,目前展示为空
- run本地IDEA的C:\Users\jieqiong\IdeaProjects\spark-log4j\log-service\src\main\java\com\imooc\bigdata\log\utils\Test.java
- 然后会发现kafka的consumer终端加载access.log中的数据。
- 8)即:完成了从数据的落地,然后通过Flume把落地的数据收集过来,其次sink到Kafka.。现在是在Kafka的consumer终端来消费/记录数据的。
- Kafka数据/文件存储是什么样的呢?
- 1)在单机器部署多个broker时候,我们创建了一个分区(多副本的)。看一下是存储在哪里的:
- topic下面的数据,会拆分成partition,partition是存储在broker上的。
- kafka-logs-0是1broker, kafka-logs-1是2broker, kafka-logs-2是3broker。
- zhang-replicated-topic-0:zhang-replicated-topic是topic的名称,0是分区
- zhang-replicated-topic-0是一个分区:0
- zhang-replicated-topic-0是三个副本,分别在kafka-logs-0 kafka-logs-1 kafka-logs-2中。
[hadoop@spark000 ~]$ cd app/tmp [hadoop@spark000 tmp]$ ls kafka-logs-0 kafka-logs-1 kafka-logs-2 [hadoop@spark000 tmp]$ cd kafka-logs-0 [hadoop@spark000 kafka-logs-0]$ ls zhang-replicated-topic-0 [hadoop@spark000 tmp]$ cd kafka-logs-1 [hadoop@spark000 kafka-logs-1]$ ls zhang-replicated-topic-0 [hadoop@spark000 tmp]$ cd kafka-logs-2 [hadoop@spark000 kafka-logs-2]$ ls zhang-replicated-topic-0
- 2)总结1:
- 在kafka文件存储时,同一个topic下会有多个不同的partition
- 每个partition都是一个文件夹/目录
- partition的命名规则是:topic的名称-序号(zhang-replicated-topic-0)
- 第一个partition序号就是0
- 序号最大值应该是partition数量-1
- 3)总结2:
- 每个partition相当于是,一个非常大的文件被平均分配到多个大小(不一定相等)的文件中。
- 每个partition相当于是,一个非常大的文件分配到segment文件中。
- 什么是segment文件?
[hadoop@spark000 kafka-logs-2]$ cd zhang-replicated-topic-0 [hadoop@spark000 zhang-replicated-topic-0]$ ls 00000000000000000000.index //索引文件
00000000000000000000.log //数据文件
00000000000000000000.timeindex
00000000000000000215.snapshot
leader-epoch-checkpoint
- 假设一个topic分成了三个分区,那我们的数据都会落在这三个分区里面,数据会大批量的进来。所以在这里zhang-replicated-topic-0设计的时候:里面的一个log文件就相当于是一个segment文件。
- segment file,每个segment file是可以设定大小的。只要数据量超过了segment file大小,就会生成新的segment file。
- 举例:一个partition是100G的数据大小,然后划分第一个500M的segment file,第二个500M的segment file....
- 4)总结3:
- segment file由两部分组成:索引文件index file(00000000000000000000.index)做存储和记录的、数据文件data/log file(00000000000000000000.log)。
- 00000000000000000000.index和00000000000000000000.log是一组segment文件。名称列位一共是20位。
- 5)segment的命名规则:
- partition全局的第一个segment从0开始
- 后续的每个segment文件名为上一个segment文件最后一条消息的offset值。所以第二组消息是从+1开头开始记录的。
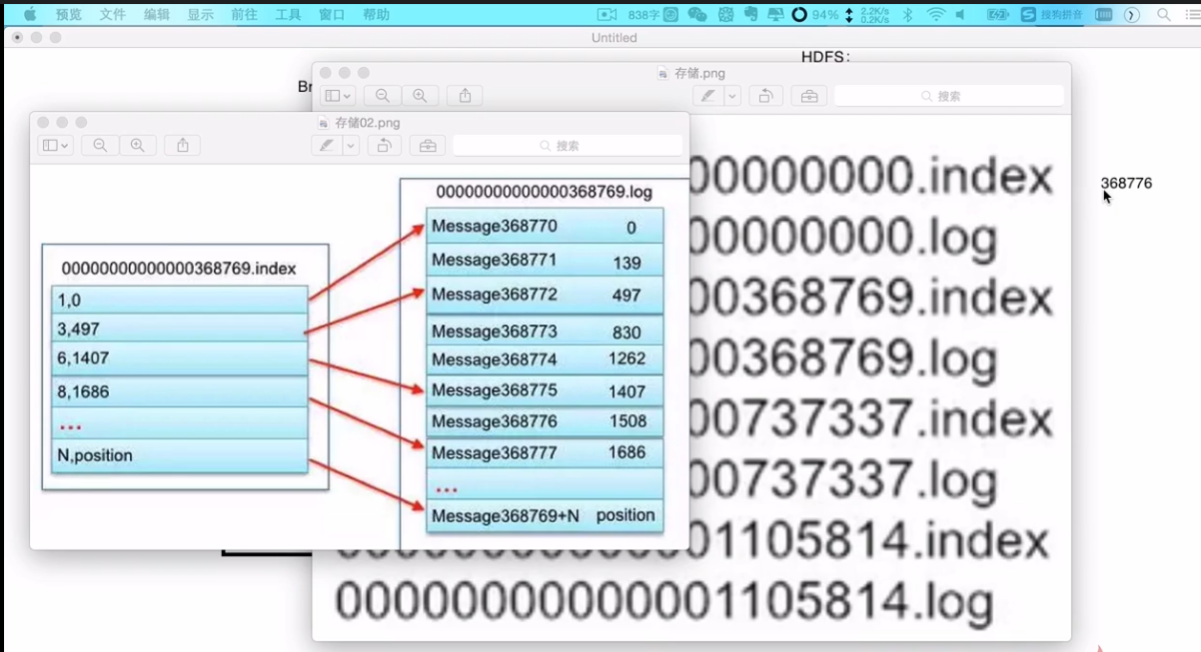
- 6)需求:offset=368776的消息/数据是什么?
- 也就是说kafka可以指定一个偏移量,是快速从一个点拉取数据的原因。
- 以下展示了一个segment里面,index和log的对应关系。
- 3,497:表示第3个消息的偏移量是497,kafka去找的话会很方便。
- Kafka面试题:谈谈对acks的看法(分层次来分析)
- acks是kafka的一个参数。
- 1)如何保证宕机时数据的不丢失
- 首先在kafka里面,数据是分topic来存放的。在这个topic里面,是可以分成多个分区的。那每个分区呢,就是负责存储topic中的一部分数据的。
- 在kafka cluster集群(由Brokers构成)中:每个broker上存储一些partition的数据。
- 这样多个机器构成的集群,我们的一个topic的数据,分布式的存储在kafka的集群/(brokers)
- 2)多副本冗余机制
- 假设有一个topic是三个partition(1、2、3)的,此时三个broker上各存放一个partition,当一个broker挂掉,则一个partition的数据丢失,则数据不完整了。这种情况是不允许的。
- 一个partition可以有多个副本
- leader、follower副本概念
- 现在假设2个replication副本的机制,则一个broker上存在两个partition(交叉存储),这个就叫冗余的分布式存储。这样就能解决任何一台机器挂掉数据彻底丢失的问题,起码这个副本在别的机器上是有的。
- 3)多副本如何进行数据同步问题。
- 因为我们有leader、follower的副本
- leader:是对外提供读写服务的
- producer往一个partition中写入数据,一般都是写入leader副本中的。
- leader副本接收到数据之后,follower副本会不停的发送请求尝试拉取最新的数据,拉取到本地磁盘。(kafka数据写入的流程)
- 4)Isr
- 在查看kafka状态时,会显示Isr这一字段值:In-Sync Replication 保持同步的副本
- 跟leader始终保持同步的follower有哪些副本。
- 5)ack
- 在我们ImoocKafkaProducer api接口编程的时候,涉及到了props.put("acks","all");
- 这个操作的意思:是否需要producer接收leader信息的反馈消息
- ack有三个值:0、1、all
- 0:表示producer只负责发送数据,不会等待任何的反馈信息。(默认消息一发送,就落盘成功,即不关心),这种延时性是最低的。(不关心leader、follower是否同步数据ok)
- 1:意味着leader需要记录本地的日志。而且只负责leader是否成功写入消息,不管follower是否同步成功。(只关心leader是否同步数据ok)
- all:意味着leader会等待所有的Isr中副本数据写入成功,才是真正的成功。(关心leader和follower是否同步数据ok)
- 延时性逐层递增。
课后问题
1、谈谈Kafka分区分配策略的看法,并举例说明
2、Kafka消息数据积压,Kafka消费能力不足怎处理
3、Kafka为什么有如此搞笑的数据读写能力
4、Kafka有哪些数据是存放在ZK上的?
5、你使用过哪些Kafka的参数调优?
6、Kafka是实时处理中非常受欢迎的一个框架,是一个分布式消息队列,具有很高的吞吐量,谈谈你对Kafka的认识?
(1)Kafka是什么?
(2)Kafka读写数据为什么性能高
(3)Kafka分区分配策略有哪些?各自的特点是什么?
(4)Kafka幂等性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号