
第二次作业 Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现





2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。

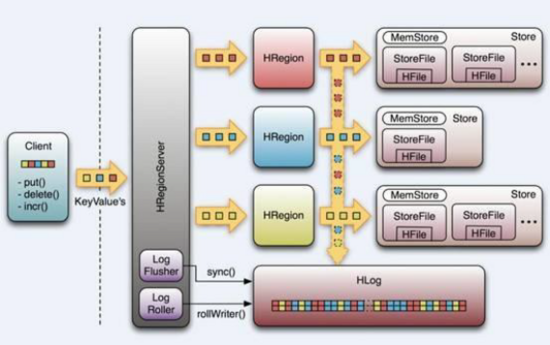
①HBase
Google Bigtable的开源实现
列式数据库
可集群化
可以使用shell、web、api等多种方式访问
适合高读写(insert)的场景
HQL查询语言
NoSQL的典型代表产品
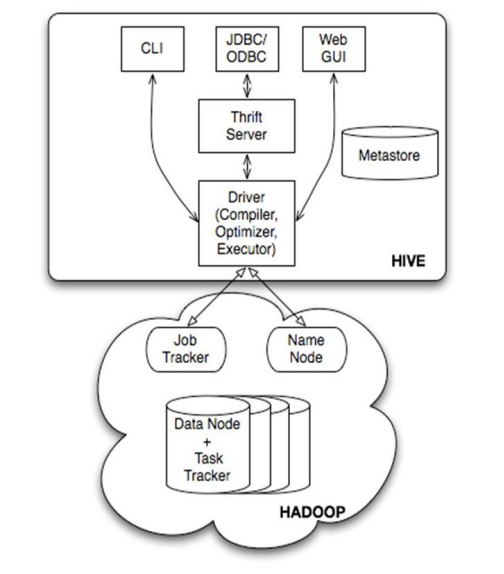
②Hive
数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持
可以看成是从SQL到Map-Reduce的映射器
提供shell、JDBC/ODBC、Thrift、Web等接口
③Zookeeper
Google Chubby的开源实现
用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等
应用场景:Hbase,实现Namenode自动切换
工作原理:领导者,跟随者以及选举过程
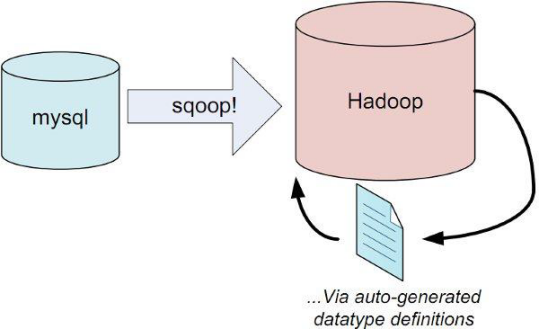
④Sqoop
用于在Hadoop和关系型数据库之间交换数据
通过JDBC接口连入关系型数据库
⑤Chukwa
架构在Hadoop之上的数据采集与分析框架
主要进行日志采集和分析
通过安装在收集节点的“代理”采集最原始的日志数据
代理将数据发给收集器
收集器定时将数据写入Hadoop集群
指定定时启动的Map-Reduce作业队数据进行加工处理和分析

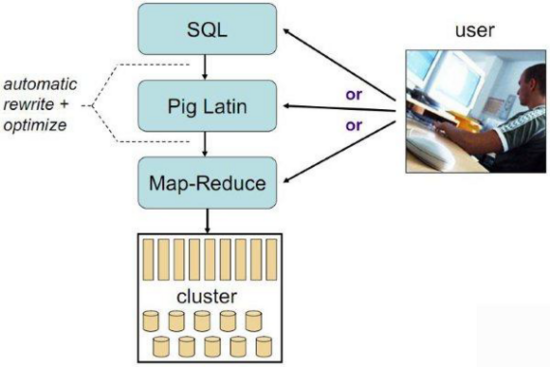
⑥Pig
Hadoop客户端
使用类似于SQL的面向数据流的语言Pig Latin
Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
⑦Avro
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Thrift接口

⑧Cassandra
NoSQL,分布式的Key-Value型数据库,由Facebook贡献
与Hbase类似,也是借鉴Google Bigtable的思想体系
只有顺序写,没有随机写的设计,满足高负荷情形的性能需求

3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
准备启动Hadoop集群
解压缩下载的Hadoop发行版。在发行版中,编辑文件etc / hadoop / hadoop-env.sh以定义一些参数,如下所示:
#设置为Java安装的根目录 导出JAVA_HOME = / usr / java / latest
尝试以下命令:
$ bin / hadoop
这将显示hadoop脚本的用法文档。
现在,您可以以三种支持的模式之一启动Hadoop集群:
独立运行
默认情况下,Hadoop被配置为在非分布式模式下作为单个Java进程运行。这对于调试很有用。
下面的示例复制解压缩的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
$ mkdir输入 $ cp etc / hadoop / *。xml输入 $ bin / hadoop jar share / hadoop / mapreduce / hadoop-mapreduce-examples-2.10.0.jar grep输入输出'dfs [az。] +' $ cat输出/ *
伪分布式操作
Hadoop也可以以伪分布式模式在单节点上运行,其中每个Hadoop守护程序都在单独的Java进程中运行。
组态
使用以下内容:
等/hadoop/core-site.xml:
<配置>
<属性>
<名称> fs.defaultFS </名称>
<value> hdfs:// localhost:9000 </ value>
</ property>
</ configuration>
等/hadoop/hdfs-site.xml:
<配置>
<属性>
<name> dfs.replication </ name>
<value> 1 </ value>
</ property>
</ configuration>
设置无密码SSH
现在检查您是否可以在不使用密码的情况下SSH到本地主机:
$ ssh本地主机
如果没有密码就无法SSH到本地主机,请执行以下命令:
$ ssh-keygen -t rsa -P''-f〜/ .ssh / id_rsa $ cat〜/ .ssh / id_rsa.pub >>〜/ .ssh / authorized_keys $ chmod 0600〜/ .ssh / authorized_keys
执行
以下说明是在本地运行MapReduce作业。如果要在YARN上执行作业,请参阅YARN在单节点上。
-
格式化文件系统:
$ bin / hdfs namenode-格式
-
启动NameNode守护程序和DataNode守护程序:
$ sbin / start-dfs.sh
hadoop守护程序日志输出将写入$ HADOOP_LOG_DIR目录(默认为$ HADOOP_HOME / logs)。
-
浏览Web界面的NameNode;默认情况下,它在以下位置可用:
- NameNode- http:// localhost:50070 /
-
设置执行MapReduce作业所需的HDFS目录:
$ bin / hdfs dfs -mkdir / user $ bin / hdfs dfs -mkdir / user / <用户名>
-
将输入文件复制到分布式文件系统中:
$ bin / hdfs dfs -put etc / hadoop输入
-
运行提供的一些示例:
$ bin / hadoop jar share / hadoop / mapreduce / hadoop-mapreduce-examples-2.10.0.jar grep输入输出'dfs [az。] +'
-
检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们:
$ bin / hdfs dfs-获取输出输出 $ cat输出/ *
要么
查看分布式文件系统上的输出文件:
$ bin / hdfs dfs -cat输出/ *
-
完成后,使用以下命令停止守护进程:
$ sbin / stop-dfs.sh
在单个节点上的YARN
您可以通过设置一些参数并另外运行ResourceManager守护程序和NodeManager守护程序,以伪分布式模式在YARN上运行MapReduce作业。
以下指令假定上述指令的1.〜4. 步骤已经执行。
-
如下配置参数:etc / hadoop / mapred-site.xml:
<配置> <属性> <name> mapreduce.framework.name </ name> <value>纱线</ value> </ property> </ configuration>etc / hadoop / yarn-site.xml:
<配置> <属性> <name> yarn.nodemanager.aux-services </ name> <value> mapreduce_shuffle </ value> </ property> </ configuration> -
启动ResourceManager守护程序和NodeManager守护程序:
$ sbin / start-yarn.sh
-
浏览Web界面以找到ResourceManager;默认情况下,它在以下位置可用:
- ResourceManager- http:// localhost:8088 /
-
运行MapReduce作业。
完成后,使用以下命令停止守护进程:
$ sbin / stop-yarn.sh
4.评估华为hadoop发行版本的特点与可用性。
华为FusionInsight HD发行版紧随开源社区的最新技术,快速集成最新组件,并在可靠性、安全性、管理性等方面做企业级的增强,持续改进,持续保持技术领先。
FusionInsight HD的企业级增强主要表现在以下几个方面。
安全
- 架构安全
FusionInsight HD基于开源组件实现功能增强,保持100%的开放性,不使用私有架构和组件。
- 认证安全
- 基于用户和角色的认证统一体系,遵从帐户/角色RBAC(Role-Based Access Control)模型,实现通过角色进行权限管理,对用户进行批量授权管理。
- 支持安全协议Kerberos,FusionInsight HD使用LDAP作为帐户管理系统,并通过Kerberos对帐户信息进行安全认证。
- 提供单点登录,统一了Manager系统用户和组件用户的管理及认证。
- 对登录FusionInsight Manager的用户进行审计。
- 文件系统层加密
Hive、HBase可以对表、字段加密,集群内部用户信息禁止明文存储。
- 加密灵活:加密算法插件化,可进行扩充,亦可自行开发。非敏感数据可不加密,不影响性能(加密约有5%性能开销)。
- 业务透明:上层业务只需指定敏感数据(Hive表级、HBase列族级加密),加解密过程业务完全不感知。
可靠
- 所有管理节点组件均实现HA(High Availability)
业界第一个实现所有组件HA的产品,确保数据的可靠性、一致性。NameNode、Hive Server、HMaster、Resources Manager等管理节点均实现HA。
- 集群异地灾备
业界第一个支持超过1000公里异地容灾的大数据平台,为日志详单类存储提供了迄今为止可靠性最佳实践。
- 数据备份恢复
表级别全量备份、增量备份,数据恢复(对本地存储的业务数据进行完整性校验,在发现数据遭破坏或丢失时进行自恢复)。
易用
- 统一运维管理
Manager作为FusionInsight HD的运维管理系统,提供界面化的统一安装、告警、监控和集群管理。
- 易集成
提供北向接口,实现与企业现有网管系统集成;当前支持Syslog接口,接口消息可通过配置适配现有系统;整个集群采用统一的集中管理,未来北向接口可根据需求灵活扩展。
- 易开发
提供自动化的二次开发助手和开发样例,帮助软件开发人员快速上手。
