概述机器学习中的偏差与方差
在这篇博文中主要介绍下机器学习中的偏差和方差。在实际运用机器学习(或深度学习)模型的过程当中,总是会难免碰到一个问题,就是常说的偏差(Bias)与方差(Variance),及其之间的权衡(Bias-Variance Tradeoff),理解了机器学习中的方差和偏差有助于进一步理解机器学习算法的运作并且怎么样利用其他方式来更好的提高机器学习算法的表现,在介绍偏差和方差的过程中会一并讨论泛化误差,也就是机器学习模型基于测试数据集(未曾见过的数据:unseen data)做预测时所产生的误差,因为泛化误差和偏差及方差有着内在的数学联系。
机器学习算法的目的就是旨在从带有标记(labels)的数据(data)中学习(learning/training from)到某种匹配模式(需要符合普适原理-Generalization),从而对未曾见过或者未知的类似数据利用学习好或者训练好的模型进行预测,这种学习算法我们一般也叫监督学习(supervised learning)。通常情况下,我们会对数据进行划分,一部分用于训练机器学习模型,一部分用于用训练完成之后的模型进行预测。当用训练完成后的模型对测试数据集进行预测时,预测误差(prediction errors)的结果通常就会存在以下几种情况:
- 偏差(Bias Error)
- 方差(Variance Error)
- 不可避免的误差(Irreducible Error)
对上述三类型错误的分析通常也是我们衡量一个机器学习算法是否好坏的标准之一。本文仅详述前两类预测误差,第三种不可避免的误差很直白:也就是不论你使用何种机器学习算法对数据进行训练和预测,该误差必然存在,存在的原因可能有数据本身导致的,也可能由某些变量产生的。
1、方差、偏差的图形表示
首先,我们先来直观的了解一下方差和偏差存在的情况基于图片描述是如何的。通过图1我们可以看到最左边的图标注了高方差,并且我们可以得知蓝色曲线极度拟合图片上的数据,而最右边标注了高偏差,从图我们可以看出一条直线貌似很好的从两组数据的中间穿插而过,但是其实有很多数据并没有很好的被划分,而中间图我们可以看出这条曲线比较好的划分了两类数据,允许了一定的误差。这是一个比较直观的展示,高方差存在主要是因为数据过拟合了,在训练模型的时候模型相当于记忆住了标记与训练数据之间的关系,这样子的模型最终的预测精准度是非常低的。而高偏差则主要是欠拟合导致的,模型并无很好的被训练出来区分数据和找到一条比较好的线来划分数据之间的差异。
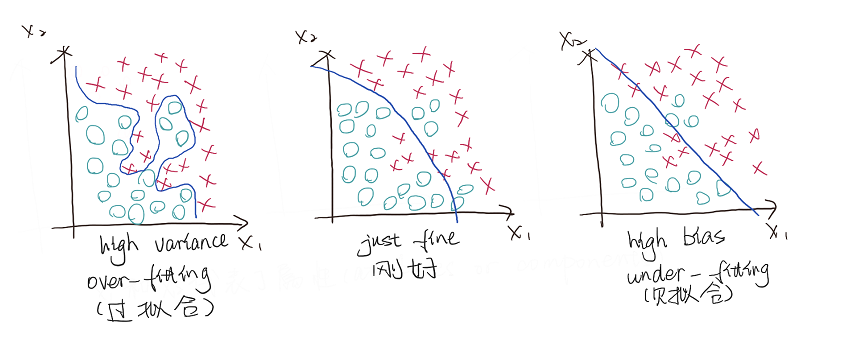
图1 方差与偏差的图片展示
2、偏差、方差和泛化误差的关系
由偏差产生的误差:偏差度量的是用训练好的模型做预测时的期望预测(expected prediction)与真实值(实际标记: ground truth)之间的偏离程度。
由方差产生的误差:方差度量的则是训练集波动(data variability)对模型学习的性能影像。
偏差、方差与泛化误差之间的数学表达式(mathematical expression):

3、解决办法
下面的流程图提供在机器学习或者深度学习中用来解决偏差和方差的方法,但是在机器学习领域中,偏差和方差是没有办法完全避免的,因为他们本身之间存在着如下的关系:
- 提高偏差可以降低方差
- 提高方差可以降低方差
一个鲁棒性比较好的模型是兼顾两者,并没有办法完全把两个带来的误差完全消除掉,这个是不现实的,同样也不可能仅仅为了提升其中一方,降低另外一方。

其他延申阅读:
Understanding the Bias-Variance Tradeoff: http://scott.fortmann-roe.com/docs/BiasVariance.html
Gentle Introduction to the Bias-Variance Trade-Off in Machine Learning:https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning/
《机器学习》,周志华著,清华大学出版社,2018年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号