内存一致性模型和内存屏障的学习
起因
在芯片设计的领域,在单芯主频提高慢慢地越来越难,然后某一刻走向了多核时代(😹这段可以自己Google去)。这样,CPU里有多于个1个核心,在同一时间CPU能够同时运行多个线程,那么系统的处理能力就得到大大的提升。也带来了一些副作用,那就是内存一致性的问题。
对CPU而言,主存实在太慢了,所以芯片设计者为CPU设计了高速缓存(高速缓存技术早就出现了)。而起初只有一个高速缓存,后来CPU越跑越快,核心数越来越多,芯片设计者为CPU分级缓存,😹后来更复杂了多级缓存了,带来的性能提升也是丧心病狂的,哈哈,但是基本模型就是这样 独立的cache(L1) -> 核心共享的cache(L2) -> 主存(RAM)。我们就在这个基本的模型上展开吧。
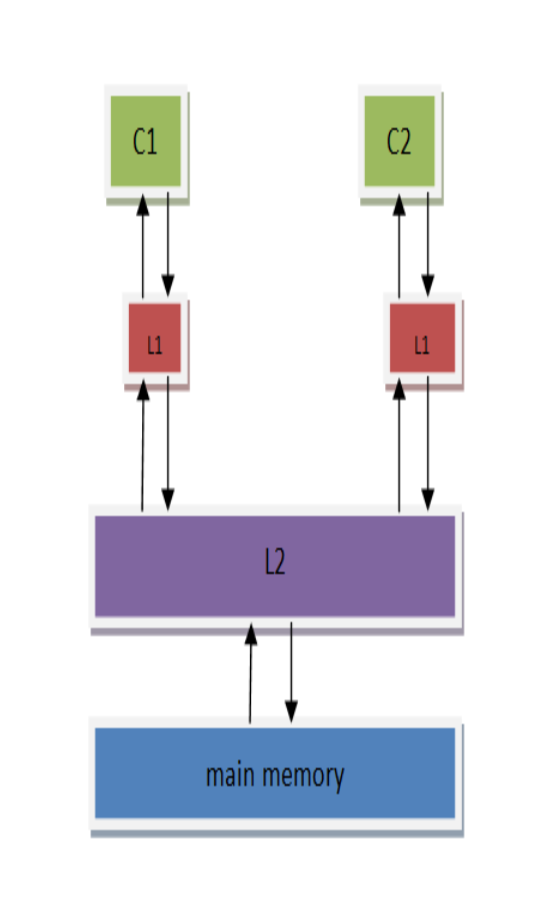
但是同时也引入了一些问题。因为而处理核心承载的线程并不是老死不相来往的,现实中很可能他们在处理同一份相关的数据基本的模型。
演进
内存一致性模型和面临情况
- 下面就从最严格的的模型开始一步一步放开约束,变得越来越宽松。
a.) 顺序存储模型 SC(sequential consistency model)
-
顺序存储模型是最基本的存储模型,也是最符合人脑思维的模型。CPU会按照程序中顺序依次执行store和load指令,(为了方便理解,这里假设cache是完美一致的,没有缓存间的同步问题)
分析一下代码
core1 core2 S1: store data=NEW S2: store flag=SET L1: load r1=flag B1: if (r1≠SET) goto L1 L2: load r2=data 在顺序存储器模型里,会严格按照代码指令流来执行代码,上面代码在主存里的访问顺序是:
S1 S2 L1 L2其访问行为与UP(单核)上是一致的。我们能得到期望的数据状态,即r2的值为NEW。
b.) 完全存储定序 TSO(total store order)
-
(这里开始烧脑了哦)
按照上面那个两级告诉缓存和主存的模型,假设最初的变量data仅仅存在主存里,那么core1执行
store data=NEW这个cpu指令时,就要先将他从主存加载到缓存(以缓存行的形式),而这个过程很可能过了几个时钟周期了,所以芯片设计人员为这个耗时的过程设计了一个store buffer,它的作用是为store指令提供缓冲,使得CPU不用等待存储器的响应。只要store buffer里还有空间,写就只需要1个时钟周期。但这里也引入了另一个问题---访问乱序。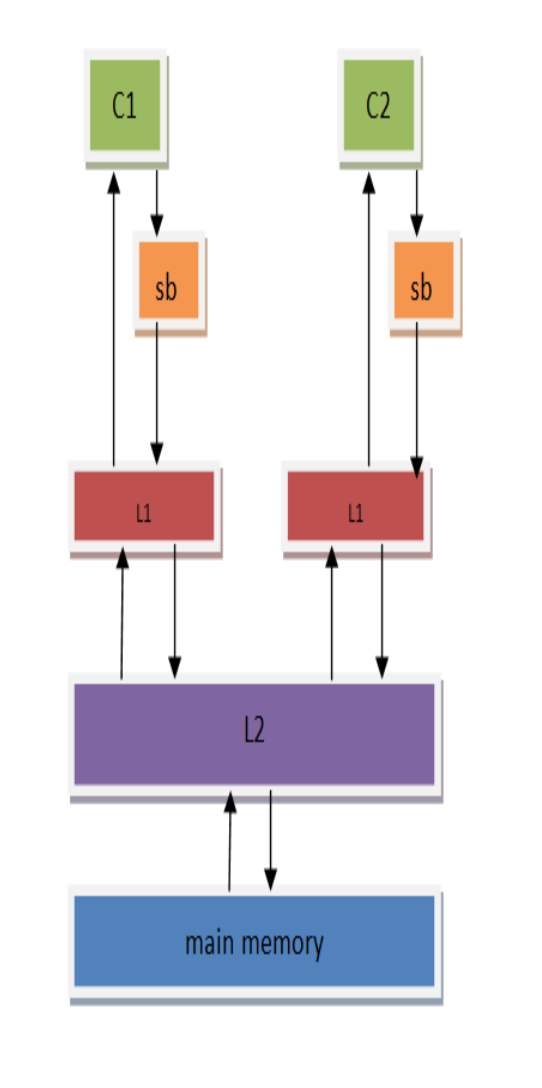
相比于以前的内存模型而言,store的时候数据会先被放到store buffer里面,然后再被写到L1 cache里。
core1 - S1: store flag=SET S2: load r1=data S3: store b=SET 如果按照顺序存储模型,S1肯定会比S2先执行。S1将指令放到了store buffer后会立刻返回,这个时候会立刻执行S2。S2是read指令,CPU必须等到数据读取到r1后才会继续执行。这样很可能S1的
store flag=set指令还在store buffer上,而S2的load指令可能已经执行完(特别是data在cache上存在,而flag没在cache中的时候。这个时候CPU往往会先执行S2,这样可以减少等待时间)。这里就可以看出再加入了store buffer之后,内存一致性模型就发生了改变。如果我们定义store buffer必须严格按照FIFO的次序将数据发送到主存(所谓的FIFO表示先进入store buffer的指令数据必须先于后面的指令数据写到存储器中),这样S3必须要在S1之后执行,CPU能够保证store指令的存储顺序,这种内存模型就叫做完全存储定序(TSO)。
core1 core2 S1: store data=NEW L1: store flag=NEW S2: load r1=flag L2: load r1=data -
按照SC模型,可能发生如下顺序
S1 S2 L1 L2 S1 L1 S2 L2 S1 L1 L2 S2 L1 L2 S1 S2 L1 S1 S2 L2 L1 S1 L2 S2最终我们看到的结果是至少有一个CORE的r1值为
NEW,或者都为NEW(所有store指令均先于load指令发生)。 -
按照TSO模型,由于store buffer的存在,L1和S1的store指令会被先放到store buffer里面,然后CPU会继续执行后面的load指令。Store buffer中的数据可能还没有来得及往存储器中写,这个时候我们可能看到C1和C2的r1都为0的情况。
所以,我们可以看到,在store buffer被引入之后,内存一致性模型已经发生了变化(从SC模型变为了TSO模型),会出现store-load乱序的情况,这就造成了代码执行逻辑与我们预先设想不相同的情况。而且随着内存一致性模型越宽松(通过允许更多形式的乱序读写访问),这种情况会越剧烈,会给多线程编程带来很大的挑战。
-
c.) 部分存储定序 PSO(part store order)
-
芯片设计人员并不满足TSO带来的性能提升,于是他们在TSO模型的基础上继续放宽内存访问限制,允许CPU以非FIFO来处理store buffer缓冲区中的指令。
CPU只保证地址相关指令在store buffer中才会以FIFO的形式进行处理,而其他的则可以乱序处理,所以这被称为部分存储定序(PSO)。core1 core2 S1: store data=NEW S2: store flag=SET L1: load r1=flag B1: if (r1≠SET) goto L1 L2: load r2=data S1与S2是地址无关的store指令,cpu执行的时候都会将其推到store buffer中。如果这个时候flag在C1的cahe中存在,那么CPU会优先将S2的store执行完,然后等data缓存到C1的cache之后,再执行store data=NEW指令。
这个时候可能的执行顺序:
S2 L1 L2 S1这样在C1将data设置为NEW之前,C2已经执行完,r2最终的结果会为0,而不是我们期望的NEW,这样PSO带来的store-store乱序将会对我们的代码逻辑造成致命影响。从这里可以看到,store-store乱序的时候就会将我们的多线程代码完全击溃。所以在PSO内存模型的架构上编程的时候,要特别注意这些问题。
d.) 宽松存储模型 RMO(relax memory order)
-
丧心病狂的芯片研发人员为了榨取更多的性能,在PSO的模型的基础上进一步放宽内存模型,进一步允许load-load,load-store乱序,只要是地址无关的指令,在读写访问的时候都可以打乱所有load/store的顺序,这就是宽松内存模型(RMO)。
core1 core2 S1: store data=NEW S2: store flag=SET L1: load r1=flag B1: if (r1≠SET) goto L1 L2: load r2=data 还是上面的代码。按照PSO模型,由于S2可能会比S1先执行,从而会导致C2的r2寄存器获取到的data值为0。在RMO模型里,不仅会出现PSO的store-store乱序,C2本身执行指令的时候,由于L1与L2是地址无关的,所以L2可能先比L1执行,这样即使C1没有出现store-store乱序,C2本身的load-load乱序也会导致我们看到的r2为0。从上面的分析可以看出,RMO内存模型里乱序出现的可能性会非常大,这是一种乱序随可见的内存一致性模型。
内存屏障 (memory barrier)
-
芯片设计者在提高性能放宽内存模型的同时,也引入了多线程情况下的软件逻辑问题,为此芯片设计者也提供了内存屏障来应对这些问题。
到这里,回归到JMM中看,JMM为不同的内存一致性模型使用了相应的内存屏障。(这图很多说java内存模型的文章都有贴上)
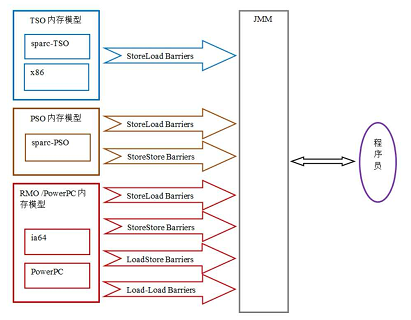
不同内存屏障的解读如图:
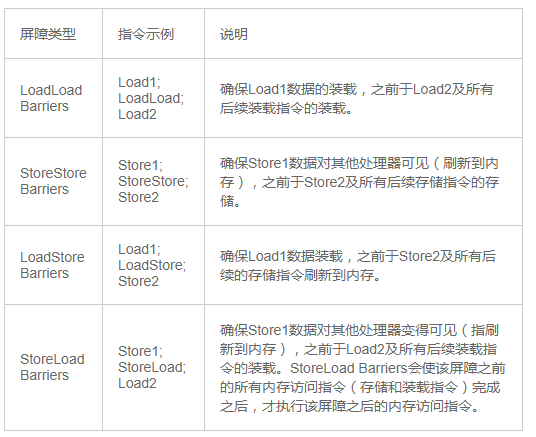
其中StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
结合上面的例子,能很好掌握内存一致性模型和内存屏障哦(不管他也无所谓,毕竟JMM已经管理好了)
JMM和JSR-133
大部分关于java内存模型的规范都在JSR-133中定义了。其中就有happens-before规则。
java的专家们以经为我们准备了更简单的happens-before规则,一经搜索,就能发现很多文章有写,不做展开了。
happens-before概述一下就是:
第n指令 happens-before 第n+1指令
第n+1指令 happens-before 第n+2指令
同时根据传递性可推导出
第n指令 happens-before 第n+2指令
而JMM会在happens-before规则中根据指令的变量相关性适当的安排内存屏障或不做安排(允许重排)。
总结
JMM为我们屏蔽了大量细节,我们只需要合理运用好final、volatile、synchornize关键字,以及正确的CAS就能很好地应对并发安全问题了(JUC包中的核心类AQS就是一个volatile修饰的state变量以及相关的cas操作写成的)。
了解内存一直性模型可能对编写java没啥帮助,用好JUC就能好地写成并发安全的代码了,可是我很可能跑回C++哦,要学的要学的,哈哈。
出处:http://www.cnblogs.com/jiefzz/
微信公众号:冇
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
本文链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号