多表连接查询详解
1.笛卡尔积形式------无条件
select * from tb_a,tb_b
tb_a和tb_b表中的所有记录相互匹配成新的记录
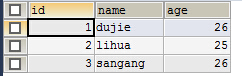

tb_a tb_b
结果:
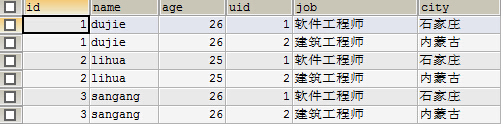
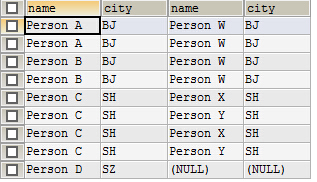
2.左连接
查询步骤:从左表读出一条,选出所有与on匹配的右表纪录(n条)进行连接,形成n条纪录(包括重复的行),如果右边没有与on条件匹配的表,那连接的字段都是null.然后继续读下一条。
SELECT * FROM tb_a a LEFT JOIN tb_b b ON a.city=b.city
左边的(tb_a)表为主表,主表中的所有记录均会被列出
@1.对于tb_a 中的每一条记录对应的城市如果在tb_b中也恰好存在而且刚好只有一条,那么就会在返回的结果中形成一条新的记录
@2.对于tb_a 中的每一条记录对应的城市如果在tb_b中也恰好存在而且有N条,那么就会在返回的结果中形成N条新的记录(做项目时忽视了此点,使得人员记录出现重复)
@3.对于tb_a 中的每一条记录对应的城市如果在tb_b中不存在,那么就会在返回的结果中形成一条新的记录,且该记录的右边全部NULL
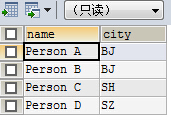
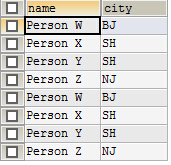
tb_a tb_b
结果:
引申:我们可以用右表没有on匹配则显示null的规律, 来找出所有在左表,不在右表的纪录, 注意用来判断的那列必须声明为not null的
select id, name, action from user as u
left join user_action a on u.id = a.user_id
where a.user_id is NULL (user_id必须类型必须设置为not null)
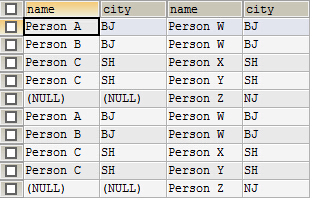
3.右连接
SELECT * FROM tb_a a RIGHT JOIN tb_b b ON a.city=b.city
左边的(tb_b)表为主表,主表中的所有记录均会被列出
@1.对于tb_b 中的每一条记录对应的城市如果在tb_a中也恰好存在而且刚好只有一条,那么就会在返回的结果中形成一条新的记录
@2.对于tb_b 中的每一条记录对应的城市如果在tb_a中也恰好存在而且有N条,那么就会在返回的结果中形成N条新的记录(做项目时忽视了此点,使得人员记录出现重复)
@3.对于tb_b 中的每一条记录对应的城市如果在tb_a中不存在,那么就会在返回的结果中形成一条新的记录,且该记录的右边全部NULL
查询结果:
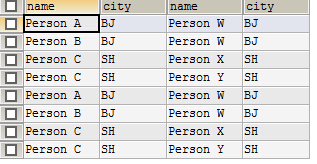
4.内连接---等值连接
MySQL内连接的数据记录中,不会存在字段为NULL的情况。
可以简单地认为,内链接的结果就是在左连接或者右连接的结果中剔除存在字段为NULL的记录后所得到的结果
即:保留两个表中都有的记录值(可能有重复记录)
标准写法: SELECT * FROM tb_a a INNER JOIN tb_b b ON a.city=b.city
缺省写法: SELECT * FROM tb_a a JOIN tb_b b ON a.city=b.city
常用写法: SELECT * FROM tb_a a,tb_b b WHERE a.city=b.city INNER JOIN 和 , (逗号) 在语义上是等同的
结果:
5@.自连接
车站表: stops(id, name)
公交线路表: route(num, company, pos, stop)
一、对公交线路表route进行自连接。
SELECT * FROM route R1, route R2 WHERE R1.num=R2.num AND R1.company=R2.company
查询结果:每条公交线路的任意两个可联通的车站。
二、用stop字段来对route(公交线路表)进行自连接。
SELECT * FROM route R1, route R2 WHERE R1.stop=R2.stop
查询结果:共用同一车站的所有公交线。
从这两个例子我们能看出,自连接的语法结构非常简单,但语意结果往往不是那么容易理解。就我们这里所列出的两个表,如果运用得当,能解决非常多实际问题,例如,任意两个站点之间怎么换乘。
SELECT R1.company, R1.num FROM route R1, route R2, stops S1, stops S2WHERE R1.num=R2.num AND R1.company=R2.company AND R1.stop=S1.id AND R2.stop=S2.idAND S1.name=’Craiglockhart’ AND S2.name=’Tollcross’6@.补充:
@1.连接关键字使用:
USING (column_list):其作用是为了方便书写联结的多对应关系,大部分情况下USING语句可以用ON语句来代替,如下面例子:
a LEFT JOIN b USING (c1,c2,c3),其作用相当于下面语句 on a.c1 = b.c1 等同于 using(c1)
a LEFT JOIN b ON a.c1=b.c1 AND a.c2=b.c2 AND a.c3=b.c3
只是用ON来代替会书写比较麻烦而已。
@2.查询顺序
在MySQL5.0以后,运算顺序得到了重视,所以对多表的联结查询可能会错误以子联结查询的方式进行。譬如你需要进行多表联结,因此你输入了下面的联结查询:
SELECT t1.id,t2.id,t3.id
FROM t1,t2
LEFT JOIN t3 ON (t3.id=t1.id)
WHERE t1.id=t2.id;
但是MySQL并不是这样执行的,其后台的真正执行方式是下面的语句:
SELECT t1.id,t2.id,t3.id
FROM t1,( t2 LEFT JOIN t3 ON (t3.id=t1.id) )
WHERE t1.id=t2.id;
这并不是我们想要的效果,所以我们需要这样输入:
SELECT t1.id,t2.id,t3.id
FROM (t1,t2)
LEFT JOIN t3 ON (t3.id=t1.id)
WHERE t1.id=t2.id;
在这里括号是相当重要的,因此以后在写这样的查询的时候我们不要忘记了多写几个括号,至少这样能避免很多错误(因为这样的错误是很难被开发人员发现的)
@3. MySQL如何优化LEFT JOIN和RIGHT JOIN
当 MySQL 在从一个表中检索信息时,你可以提示它选择了哪一个索引。
如果 EXPLAIN 显示 MySQL 使用了可能的索引列表中错误的索引,这个特性将是很有用的。
通过指定 USE INDEX (key_list),你可以告诉 MySQL 使用可能的索引中最合适的一个索引在表中查找记录行。
可选的二选一句法 IGNORE INDEX (key_list) 可被用于告诉 MySQL 不使用特定的索引。
4. 一些例子:
代码:
1. MySQL> SELECT * FROM table1,table2 WHERE table1.id=table2.id;
2. MySQL> SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id;
3. MySQL> SELECT * FROM table1 LEFT JOIN table2 USING (id);
4. MySQL> SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id
5. -> LEFT JOIN table3 ON table2.id=table3.id;
6. MySQL> SELECT * FROM table1 USE INDEX (key1,key2)
7. -> WHERE key1=1 AND key2=2 AND key3=3;
8. MySQL> SELECT * FROM table1 IGNORE INDEX (key3)
9. -> WHERE key1=1 AND key2=2 AND key3=3;
7.2.9. MySQL如何优化LEFT JOIN和RIGHT JOIN
在MySQL中,A LEFT JOIN B join_condition执行过程如下:
根据表A和A依赖的所有表设置表B。
根据MySQL LEFT JOIN条件中使用的所有表(除了B)设置表A。
LEFT JOIN条件用于确定如何从表B搜索行。(换句话说,不使用WHERE子句中的任何条件)。
可以对所有标准联接进行优化,只是只有从它所依赖的所有表读取的表例外。如果出现循环依赖关系,MySQL提示出现一个错误。
进行所有标准WHERE优化。
如果A中有一行匹配WHERE子句,但B中没有一行匹配ON条件,则生成另一个B行,其中所有列设置为NULL。
如果使用LEFT JOIN找出在某些表中不存在的行,并且进行了下面的测试:WHERE部分的col_name IS NULL,其中col_name是一个声明为 NOT NULL的列,MySQL找到匹配LEFT JOIN条件的一个行后停止(为具体的关键字组合)搜索其它行。
RIGHT JOIN的执行类似LEFT JOIN,只是表的角色反过来。
联接优化器计算表应联接的顺序。LEFT JOIN和STRAIGHT_JOIN强制的表读顺序可以帮助联接优化器更快地工作,因为检查的表交换更少。请注意这说明如果执行下面类型的查询,MySQL进行全扫描b,因为LEFT JOIN强制它在d之前读取:
代码:
1. SELECT *
2. FROM a,b LEFT JOIN c ON (c.key=a.key) LEFT JOIN d ON (d.key=a.key)
3. WHERE b.key=d.key;
在这种情况下修复时用a的相反顺序,b列于FROM子句中:
代码:
1. SELECT *
2. FROM b,a LEFT JOIN c ON (c.key=a.key) LEFT JOIN d ON (d.key=a.key)
3. WHERE b.key=d.key;
MySQL可以进行下面的LEFT JOIN优化:如果对于产生的NULL行,WHERE条件总为假,LEFT JOIN变为普通联接。
例如,在下面的查询中如果t2.column1为NULL,WHERE 子句将为false:
代码:
1. SELECT * FROM t1 LEFT JOIN t2 ON (column1) WHERE t2.column2=5;
因此,可以安全地将查询转换为普通联接:
1. SELECT * FROM t1, t2 WHERE t2.column2=5 AND t1.column1=t2.column1;
这样可以更快,因为如果可以使查询更佳,MySQL可以在表t1之前使用表t2。为了强制使用表顺序,使用STRAIGHT_JOIN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号