


【CV知识学习】神经网络梯度与归一化问题总结+highway network、ResNet的思考
这是一篇水货写的笔记,希望路过的大牛可以指出其中的错误,带蒟蒻飞啊~
一、 梯度消失/梯度爆炸的问题
首先来说说梯度消失问题产生的原因吧,虽然是已经被各大牛说烂的东西。不如先看一个简单的网络结构,
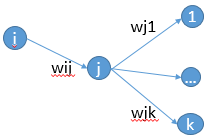
可以看到,如果输出层的值仅是输入层的值与权值矩阵W的线性组合,那么最终网络最终的输出会变成输入数据的线性组合。这样很明显没有办法模拟出非线性的情况。记得神经网络是可以拟合任意函数的。好了,既然需要非线性函数,那干脆加上非线性变换就好了。一般会使用sigmoid函数,得到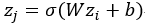 ,这个函数会把数据压缩到开区间(0,1),函数的图像如下
,这个函数会把数据压缩到开区间(0,1),函数的图像如下

可以看到,函数的两侧非常平滑,而且无限的接近0和1,仅仅是中间部分函数接近一条直线,顺便说一下,这个函数的导数最值竟然真的是1啊,也就是x=0的位置,因而称这个函数是双端饱和的,而且它是处处可导。那么,为什么要选用它呢?看到有资料说是模拟神经学科的,但我不太懂这个,个人认为是因为(1)可以引入非线性(2)容易求导(3)可以把数据压缩,这样数据不容易发散。
另外,有一个函数与sigmoid函数很类似,就是tanh()函数,它可以把数据压缩到(-1,1)之间。
但是,我们要讲的是梯度的消失问题哦,要知道,神经网络训练的方法是BP算法(不知道还有没有其他的训练方法。。。)。BP算法的基础其实就是导数的链式法则,这个估计不需要细说了,就是有很多乘法会连接在一起。在看看sigmoid函数的图像就知道了,导数最大是1,而且大多数值都被推向两侧饱和的区域,这些区域的导数可是很小的呀~~~~可以预见到,随着网络的加深,梯度后向传播到浅层网络时,就呵呵了,基本不能引起数值的扰动,这样浅层的网络就学习不到新的特征了。
那么怎么办?我暂时看到了四种解决问题的办法,仅仅是根据我自己看的论文总结的,并非权威的说法。第一种很明显,可以通过使用别的激活函数;第二种可以使用层归一化;第三种是在权重的初始化上下功夫,第四种是构建新的网络结构~。但暂时不写,我还想记录一下看到的梯度消失/爆炸问题在另一个经典网络的出现。
======================
噔噔噔噔,对的,就是RNN。
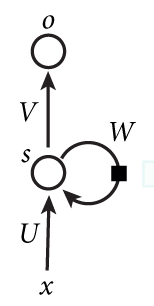
RNN网络简单来说,就是把上层的hidden state与输入数据一同输入到神经元中进行处理(如左图),它是与序列相关的。如果把网络按照时间序列展开,可以得到右图
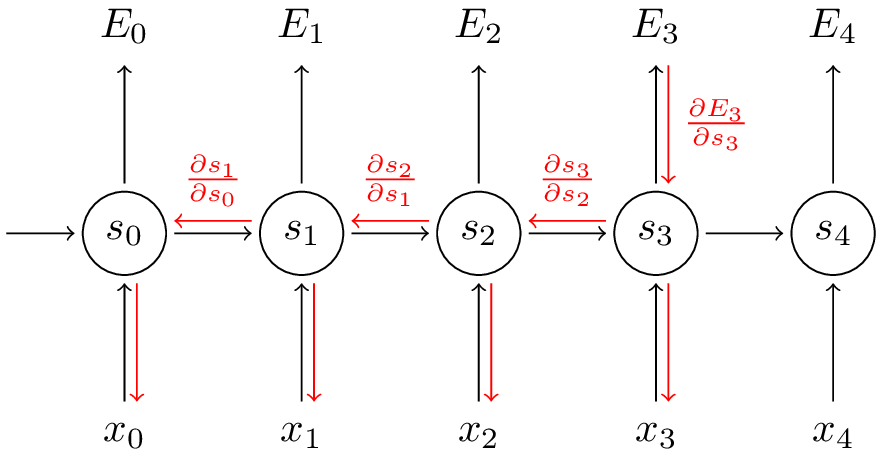
假如要求偏导数![]() ,可以看到一个连乘的式子,元素是
,可以看到一个连乘的式子,元素是![]() ,假如
,假如![]() 大于1,经过k个乘法后会变得异常巨大,毕竟是指数级的,如果小于1,又会变得十分小。这就是RNN中梯度爆炸与消失的问题了。
大于1,经过k个乘法后会变得异常巨大,毕竟是指数级的,如果小于1,又会变得十分小。这就是RNN中梯度爆炸与消失的问题了。
贴一个RNN的代码,有注释,很容易看明白,来自这里


1 import copy, numpy as np 2 np.random.seed(0) 3 4 # compute sigmoid nonlinearity 5 def sigmoid(x): 6 output = 1/(1+np.exp(-x)) 7 return output 8 9 # convert output of sigmoid function to its derivative 10 def sigmoid_output_to_derivative(output): 11 return output*(1-output) 12 13 14 # training dataset generation 15 int2binary = {} 16 binary_dim = 8 17 18 largest_number = pow(2,binary_dim) 19 binary = np.unpackbits( 20 np.array([range(largest_number)],dtype=np.uint8).T,axis=1) 21 for i in range(largest_number): 22 int2binary[i] = binary[i] 23 24 25 # input variables 26 alpha = 0.1 27 input_dim = 2 28 hidden_dim = 16 29 output_dim = 1 30 31 32 # initialize neural network weights 33 synapse_0 = 2*np.random.random((input_dim,hidden_dim)) - 1 34 synapse_1 = 2*np.random.random((hidden_dim,output_dim)) - 1 35 synapse_h = 2*np.random.random((hidden_dim,hidden_dim)) - 1 36 37 synapse_0_update = np.zeros_like(synapse_0) 38 synapse_1_update = np.zeros_like(synapse_1) 39 synapse_h_update = np.zeros_like(synapse_h) 40 41 # training logic 42 for j in range(10000): 43 44 # generate a simple addition problem (a + b = c) 45 a_int = np.random.randint(largest_number/2) # int version 46 a = int2binary[a_int] # binary encoding 47 48 b_int = np.random.randint(largest_number/2) # int version 49 b = int2binary[b_int] # binary encoding 50 51 # true answer 52 c_int = a_int + b_int 53 c = int2binary[c_int] 54 55 # where we'll store our best guess (binary encoded) 56 d = np.zeros_like(c) 57 58 overallError = 0 59 60 layer_2_deltas = list() 61 layer_1_values = list() 62 layer_1_values.append(np.zeros(hidden_dim)) 63 64 # moving along the positions in the binary encoding 65 for position in range(binary_dim): 66 67 # generate input and output 68 X = np.array([[a[binary_dim - position - 1],b[binary_dim - position - 1]]]) 69 y = np.array([[c[binary_dim - position - 1]]]).T 70 71 # hidden layer (input ~+ prev_hidden) 72 layer_1 = sigmoid(np.dot(X,synapse_0) + np.dot(layer_1_values[-1],synapse_h)) 73 74 # output layer (new binary representation) 75 layer_2 = sigmoid(np.dot(layer_1,synapse_1)) 76 77 # did we miss?... if so, by how much? 78 layer_2_error = y - layer_2 79 layer_2_deltas.append((layer_2_error)*sigmoid_output_to_derivative(layer_2)) 80 overallError += np.abs(layer_2_error[0]) 81 82 # decode estimate so we can print it out 83 d[binary_dim - position - 1] = np.round(layer_2[0][0]) 84 85 # store hidden layer so we can use it in the next timestep 86 layer_1_values.append(copy.deepcopy(layer_1)) 87 88 future_layer_1_delta = np.zeros(hidden_dim) 89 90 for position in range(binary_dim): 91 92 X = np.array([[a[position],b[position]]]) 93 layer_1 = layer_1_values[-position-1] 94 prev_layer_1 = layer_1_values[-position-2] 95 96 # error at output layer 97 layer_2_delta = layer_2_deltas[-position-1] 98 # error at hidden layer 99 layer_1_delta = (future_layer_1_delta.dot(synapse_h.T) + layer_2_delta.dot(synapse_1.T)) * sigmoid_output_to_derivative(layer_1) 100 101 # let's update all our weights so we can try again 102 synapse_1_update += np.atleast_2d(layer_1).T.dot(layer_2_delta) 103 synapse_h_update += np.atleast_2d(prev_layer_1).T.dot(layer_1_delta) 104 synapse_0_update += X.T.dot(layer_1_delta) 105 106 future_layer_1_delta = layer_1_delta 107 108 109 synapse_0 += synapse_0_update * alpha 110 synapse_1 += synapse_1_update * alpha 111 synapse_h += synapse_h_update * alpha 112 113 synapse_0_update *= 0 114 synapse_1_update *= 0 115 synapse_h_update *= 0 116 117 # print out progress 118 if(j % 1000 == 0): 119 print "Error:" + str(overallError) 120 print "Pred:" + str(d) 121 print "True:" + str(c) 122 out = 0 123 for index,x in enumerate(reversed(d)): 124 out += x*pow(2,index) 125 print str(a_int) + " + " + str(b_int) + " = " + str(out) 126 print "------------" 127 128
二、 选择其他激活函数
激活函数有很多其他的选择,常看见的有ReLU、Leaky ReLU函数。下面就说一说这两个函数,对于ReLU,函数为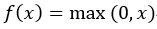 ,观察一下它的函数图像
,观察一下它的函数图像
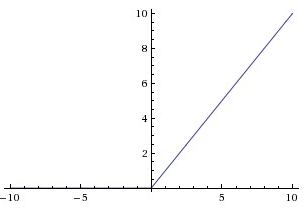
可以看到,它在负数的一段永远是0啊。为什么要使用这个函数呢?据说它是与神经学科有关的,这是因为稀疏激活的,这表现在负数端是抑制状态,正数兴奋激活。而且有理论也表明,稀疏的网络更准确,在googLeNet的实现中就是利用了神经网络的稀疏性。而且,在正数端导数永远为1,这就很好地解决了梯度消失的问题了。可是,它没有把数据压缩,这会使得数据的范围可能很大。
此外还有Leaky ReLU函数,这个我是在YOLO看到的,其实和ReLU差不多,就是在负数端不完全抑制了。图像如下:

三、 层归一化
这里记录的是Batch Normalization。主要参考(1)(2)(3)写的总结,可怜我只是个搬运工啊。
先说一说BN解决的问题,论文说要解决 Internal covariate shift 的问题,covariate shift 是指源空间与目标空间中条件概率一致,但是边缘概率不同。在深度网络中,越深的网络对特征的扭曲就越厉害(应该是这样说吧……),但是特征本身对于类别的标记是不变的,所以符合这样的定义。BN通过把输出层的数据归一化到mean = 0, var = 1的分布中,可以让边缘概率大致相同吧(知乎魏大牛说不可以完全解决,因为均值方差相同不代表分布相同~~他应该是对的),所以题目说是reducing。
那么BN是怎么实现的呢?它是通过计算min batch 的均值与方差,然后使用公式归一化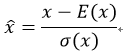 。例如激活函数是sigmoid,那么输出归一化后的图像就是
。例如激活函数是sigmoid,那么输出归一化后的图像就是
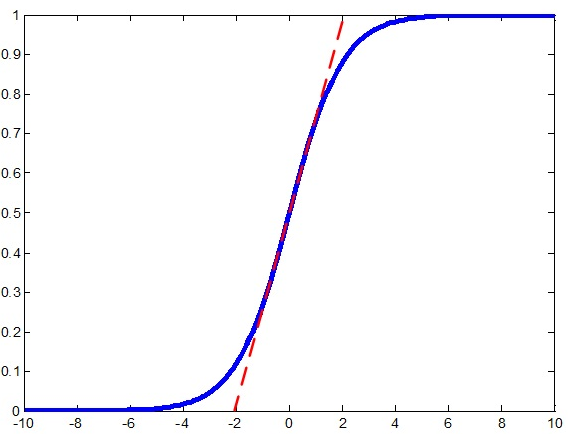
中间就是接近线性了,这样,导数几乎为常数1,这样不就可以解决梯度消失的问题了吗?
但是,对于ReLU函数,这个是否起作用呢?好像未必吧,不过我觉得这个归一化可以解决ReLU不能把数据压缩的问题,这样可以使得每层的数据的规模基本一致了。上述(3)中写到一个BN的优点,我觉得和我的想法是一致的,就是可以使用更高的学习率。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale保持一致,那么我们就可以直接使用较高的学习率进行优化。这样就可以加快收敛了。我觉得还是主要用来减少covariate shift 的。
但是,上述归一化会带来一个问题,就是破坏原本学习的特征的分布。那怎么办?论文加入了两个参数,来恢复它本来的分布![]() 这个带入归一化的式子看一下就可以知道恢复原来分布的条件了。但是,如果恢复了原来的分布,那还需要归一化?我开始也没想明白这个问题,后来看看别人的解释,注意到新添加的两个参数,实际上是通过训练学习的,就是说,最后可能恢复,也可能没有恢复。这样可以增加网络的capicity,网络中就存在多种不同的分布了。最后抄一下BP的公式:
这个带入归一化的式子看一下就可以知道恢复原来分布的条件了。但是,如果恢复了原来的分布,那还需要归一化?我开始也没想明白这个问题,后来看看别人的解释,注意到新添加的两个参数,实际上是通过训练学习的,就是说,最后可能恢复,也可能没有恢复。这样可以增加网络的capicity,网络中就存在多种不同的分布了。最后抄一下BP的公式:
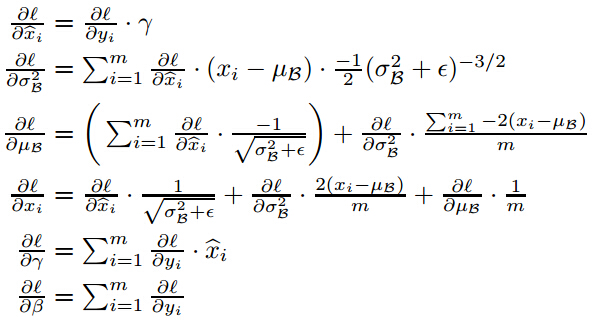
那么在哪里可以使用这个BN?很明显,它应该使用在激活函数之前。而在此处还提到一个优点就是加入BN可以不使用dropout,为什么呢?dropout它是用来正则化增强网络的泛化能力的,减少过拟合,而BN是用来提升精度的,之所以说有这样的作用,可能有两方面的原因(1)过拟合一般发生在数据边缘的噪声位置,而BN把它归一化了(2)归一化的数据引入了噪声,这在训练时一定程度有正则化的效果。对于大的数据集,BN的提升精度会显得更重要,这两者是可以结合起来使用的。
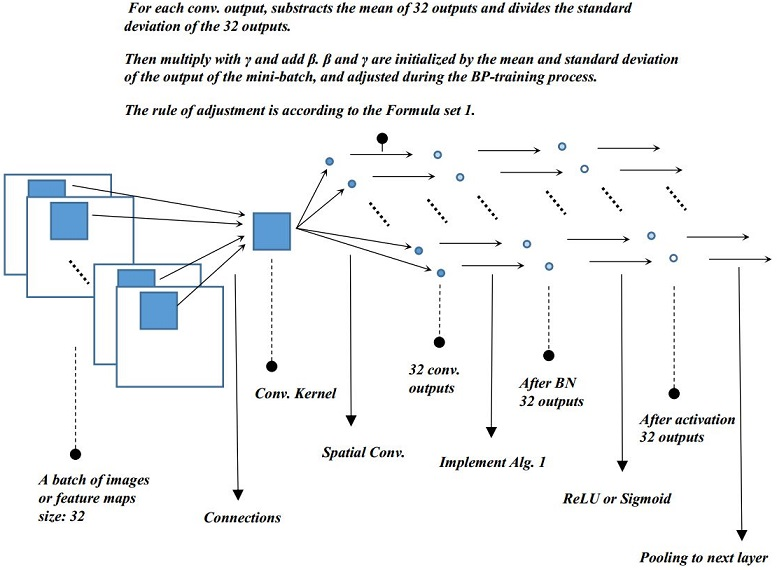
最后贴一个算法的流程,以及结构图,结构图是来自 http://yeephycho.github.io/2016/08/03/Normalizations-in-neural-networks/

四、 权值初始化
为了让信息可以更好的在网络中流动(不一定是梯度消失的问题),可以使用xavier的初始化方法。主要可以看知乎专栏。为了不重复别人的工作,我简单总结一下算了。注意一个问题,xavier的初始化方法的前提假设是,激活函数是线性的(其实归一化后,可能把数据集中在了一处,就好像将BN的那张图一样)。
如果输入数据x和权值w都满足均值为0,标准差为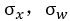 ,(x可以通过归一化、白化实现)而且各数据是独立同分布的。这样,输出为
,(x可以通过归一化、白化实现)而且各数据是独立同分布的。这样,输出为 ,根据概率公式,z 的均值依然为0,方差为
,根据概率公式,z 的均值依然为0,方差为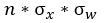 。
。
通过递推公式可以得到 ,则
,则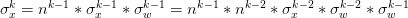 。于是,方差的计算公式为
。于是,方差的计算公式为![]() 。这里又出现了连乘,还是按照之前与1比较的讨论,那么,最好是可以让方差保持一致啦,这样数值的幅度就不会相差太大,就好像上面BN说的那样,可以收敛的更快。那么就是让连乘内的每一项都为1了,则可以推出权值的初始化为
。这里又出现了连乘,还是按照之前与1比较的讨论,那么,最好是可以让方差保持一致啦,这样数值的幅度就不会相差太大,就好像上面BN说的那样,可以收敛的更快。那么就是让连乘内的每一项都为1了,则可以推出权值的初始化为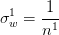 。
。
上面说的是前向的,那么后向呢?后向传播时,如果可以让方差保持一致,同样地会有前向传播的效果,梯度可以更好地在网络中流动。由于假设是线性的,那么回流的梯度公式是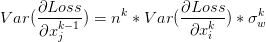 ,可以写成
,可以写成 。令回流的方差不变,那么权值又可以初始化成
。令回流的方差不变,那么权值又可以初始化成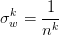 。注意一个是前向,一个是后向的,两者的n 是不同的。取平均
。注意一个是前向,一个是后向的,两者的n 是不同的。取平均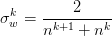 。
。
最后,是使用均匀分布来初始化权值的,得到初始化的范围 。
。
另外一种MSRA的初始化的方法,可以学习http://blog.csdn.net/shuzfan/article/details/51347572,实验效果表现要好一些,但貌似xavier用的要多一些。
五、 调整网络的结构
解决RNN的问题,提出了一种LSTM的结构,但我对LSTM还不是太熟悉,就不装逼了。主要是总结最近看的两篇文章《Training Very Deep Networks》和《Deep Residual Learning for Image Recognition》。
Highway Network
Highway Network主要解决的问题是,网络深度加深,梯度信息回流受阻造成网络训练困难的问题。先看下面的一张对比图片,分别是没有highway 和有highway的。
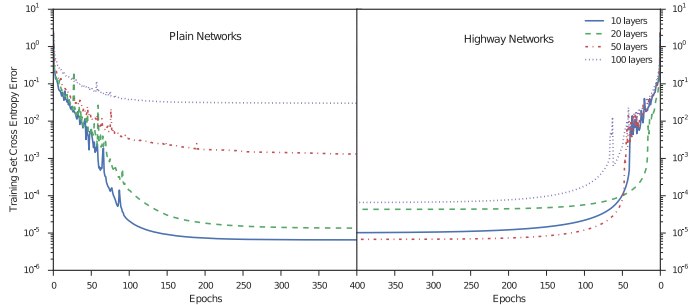
可以看到,当网络加深,训练的误差反而上升了,而加入了highway之后,这个问题得到了缓解。一般来说,深度网络训练困难是由于梯度回流受阻的问题,可能浅层网络没有办法得到调整,或者我自己YY的一个原因是(回流的信息经过网络之后已经变形了,很可能就出现了internal covariate shift类似的问题了)。Highway Network 受LSTM启发,增加了一个门函数,让网络的输出由两部分组成,分别是网络的直接输入以及输入变形后的部分。
假设定义一个非线性变换为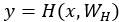 ,定义门函数
,定义门函数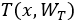 ,携带函数
,携带函数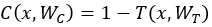 。对于门函数取极端的情况0/1会有
。对于门函数取极端的情况0/1会有 ,而对应的门函数使用sigmoid函数
,而对应的门函数使用sigmoid函数 ,则极端的情况不会出现。
,则极端的情况不会出现。
一个网络的输出最终变为![]() ,注意这里的乘法是element-wise multiplication。
,注意这里的乘法是element-wise multiplication。
注意,门函数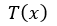 ,转换
,转换 ,
,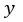 与
与 的维度应该是相同的。如果不足,可以用0补或者用一个卷积层去变化。
的维度应该是相同的。如果不足,可以用0补或者用一个卷积层去变化。
在初始化的时候,论文是把偏置 b 初始化为负数,这样可以让携带函数 C 偏大,这样做的好处是什么呢?可以让更多的信息直接回流到输入,而不需要经过一个非线性转化。我的理解是,在BP算法时,这一定程度上增大了梯度的回流,而不会被阻隔;在前向流动的时候,把允许原始的信息直接流过,增加了容量,就好像LSTM那样,可以有long - term temporal dependencies。
Residual Network
ResNet的结构与Highway很类似,如果把Highway的网络变一下形会得到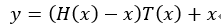 ,而在ResNet中,直接把门函数T(x)去掉,就得到一个残差函数
,而在ResNet中,直接把门函数T(x)去掉,就得到一个残差函数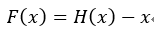 ,而且会得到一个恒等的映射 x ,对的,这叫残差网络,它解决的问题与Highway一样,都是网络加深导致的训练困难且精度下降的问题。残差网络的一个block如下:
,而且会得到一个恒等的映射 x ,对的,这叫残差网络,它解决的问题与Highway一样,都是网络加深导致的训练困难且精度下降的问题。残差网络的一个block如下:

是的,就是这么简单,但是,网络很强大呀。而且实验证明,在网络加深的时候,依然很强大。那为什么这么强大呢?我觉得是因为identity map是的梯度可以直接回流到了输入层。至于是否去掉门函数会更好呢,这个并不知道。在作者的另一篇论文《Identity Mappings in Deep Residual Networks》中,实验证明了使用identity map会比加入卷积更优。而且通过调整激活函数和归一化层的位置到weight layer之前,称为 pre-activation,会得到更优的结果。
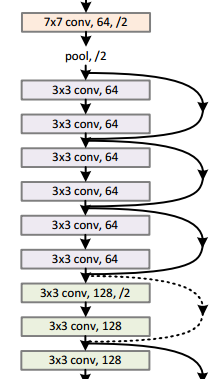
对于网络中的一些虚线层,他们的shortcut就连接了两个维度不同的feature,这时,有两种解决办法(1)在维度减少的部分直接使用 identity 映射,同时对于feature map增加部分用0补齐。(2)通过1*1的卷积变形得到。对于这个1*1的投影是怎么做的,可以参考VGG-16。我开始也很纳闷,例如上面的虚线,输入有64个Feature,输出是128个Feature,如果是用128个kernel做卷积,应该有64*128个feature啊。纠结很久,看了看VGG的参数个数就明白了,如下图

例如第一、二行,输入3个Feature,有64个卷积核但却有64个输出,是怎么做到的呢?看它的权值的个数的计算时(3*3*3)*64,也就是说,实际上这64个卷积核其实是有3维的通道的。对应于ResNet的64个输入,同样卷积核也是有64个channel的。
结语
还请大牛可以指正不足以及思考不周的地方,指点学习的方向啊!!!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号