
注意力机制总结
Encoder-Decoder框架==sequence to sequence 条件生成框架
attention 机制的最典型应用是统计机器翻译。给定任务,输入是“Echt”, “Dicke” and “Kiste”进 encoder,使用 rnn 表示文本为固定长度向量 h3。但问题就在于,当前 decoder 生成 y1 时仅仅依赖于最后一个隐层状态h3,也就是 sentence_embedding。那么这个 h3 必须 encode 输入句子中的全部信息才行。可实际上,传统Encoder-Decoder模型并不能达到这个功能。那 LSTM [3]不就是用来解决长期依赖信息问题的嘛?但事实上,长短期记忆网络仍然存在问题。我们说,RNN在长期信息访问当前处理单元之前,需要按顺序地通过所有之前的单元。这意味着它很容易遭遇梯度消失问题。然后引入 LSTM,使用门控某种程度上解决这个问题。的确,LSTM、GRU 和其变体能学习大量的长期信息,但它们最多只能记住相对长的信息,而不是更大更长。Encoder-Decoder框架,也被称为 sequence to sequence 条件生成框架[1],是一种文本处理领域的研究模式。常规的 encoder-decoder方法,第一步,将输入句子序列 X通过神经网络编码为固定长度的上下文向量C,也就是文本的语义表示;第二步,由另外一个神经网络作为解码器根据当前已经预测出来的词记忆编码后的上下文向量 C,来预测目标词序列,过程中编码器和解码器的 RNN 是联合训练的,但是监督信息只出现在解码器 RNN 一端,梯度随着反向传播到编码器 RNN 一端。使用 LSTM 进行文本建模时当前流行的有效方法[2]。\alpha_{t,i}=\frac{\exp(score(u_i, u_t))}{\sum\limits_{j=1}^{T_x}\exp(score(u_j, u_t))}
\alpha_{t,i}=\frac{\exp(score(u_i, u_t))}{\sum\limits_{j=1}^{T_x}\exp(score(u_j, u_t))}
|
使用 RNN 文本表示与生成
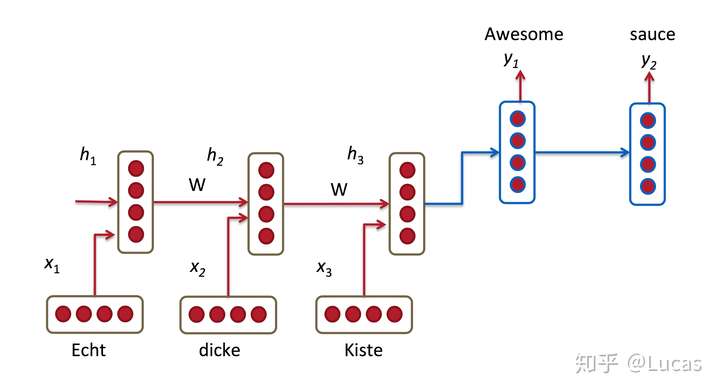
所以,我们来总结一下传统 encoder-decoder的一般范式及其问题:任务是翻译中文“我/爱/赛尔”到英文。传统 encoder-decoder 先把整句话输入进去,编码最后一个词“赛尔”结束之后,使用 RNN生成一个整句话的表示-向量 C,在条件生成时,当翻译到第 2个词“赛尔”的时候,需要退 1 步找到已经预测出来的h_1以及上下文表示 C, 然后 decode 输出。
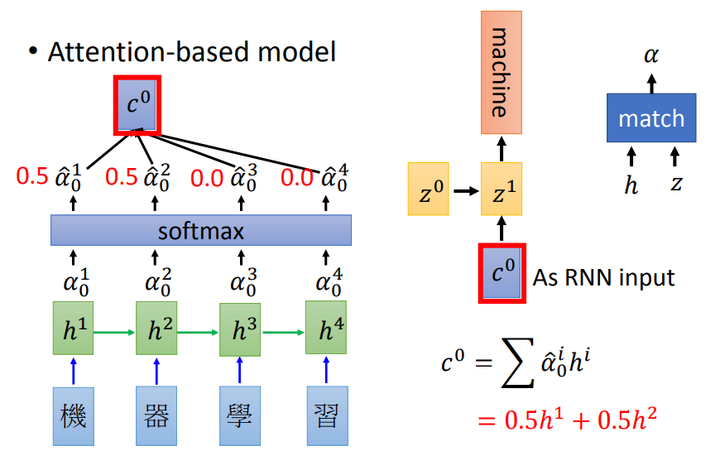
从注意力均等到注意力集中
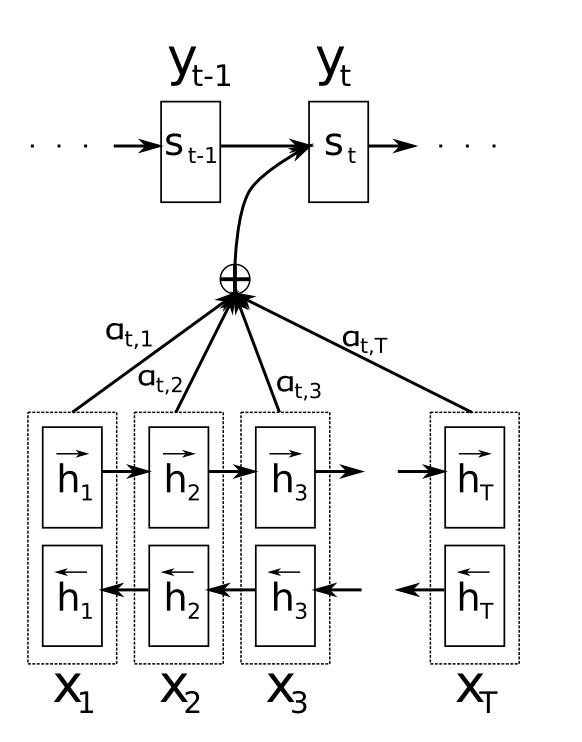
在传统Encoder-Decoder 框架下:由解码器根据当前已经预测出来的词记忆编码后的上下文向量 C,来预测目标词序列。也就是说,不论生成那个词,我们使用的句子编码表示 C 都是一样的。换句话说,句子中任意单词对生成某个目标单词P_yi来说影响力都是相同的,也就是注意力均等。很显然这不符合直觉。直觉应该:我翻译哪个部分,哪个部分就应该把注意力集中于我的翻译的原文,翻译到第一个词,就应该多关注原文中的第一个词是什么意思。详见伪代码和下图:
P_y1 = F(E<start>,C),
P_y2 = F((E<the>,C)
P_y3 = F((E<black>,C)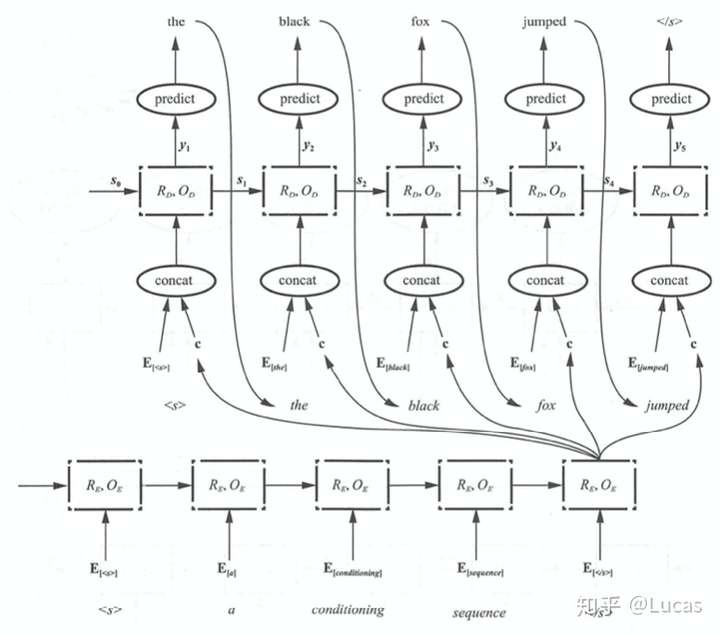 传统 Encoder-Decoder 框架下的 RNN 进行文本翻译,一直使用同一个 c
传统 Encoder-Decoder 框架下的 RNN 进行文本翻译,一直使用同一个 c
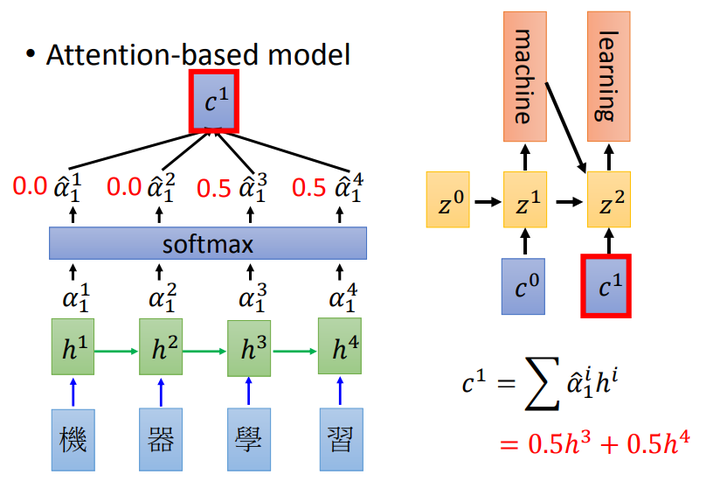
接下来观察上下两个图的区别:相同的上下文表示C会替换成根据当前生成单词而不断变化的Ci。
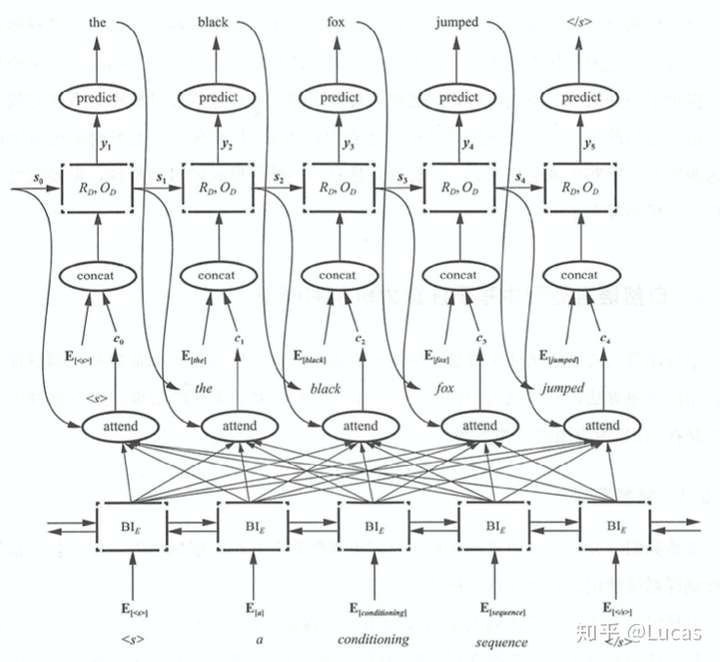 融合 attention 机制的RNN 模型进行文本翻译每个时刻生成不同的 c
融合 attention 机制的RNN 模型进行文本翻译每个时刻生成不同的 c
文本翻译过程变为:
P_y1 = F(E<start>,C_0),
P_y2 = F((E<the>,C_1)
P_y3 = F((E<black>,C_2)Encoder-Decoder框架的代码实现
1 class EncoderDecoder(nn.Module): 2 """ 3 A standard Encoder-Decoder architecture. Base for this and many 4 other models. 5 """ 6 def __init__(self, encoder, decoder, src_embed, tgt_embed, generator): 7 super(EncoderDecoder, self).__init__() 8 self.encoder = encoder 9 self.decoder = decoder 10 self.src_embed = src_embed 11 self.tgt_embed = tgt_embed 12 self.generator = generator 13 14 def forward(self, src, tgt, src_mask, tgt_mask): 15 "Take in and process masked src and target sequences." 16 return self.decode(self.encode(src, src_mask), src_mask, 17 tgt, tgt_mask) 18 19 def encode(self, src, src_mask): 20 return self.encoder(self.src_embed(src), src_mask) 21 22 def decode(self, memory, src_mask, tgt, tgt_mask): 23 return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
考虑可解释性
不含注意力模型的传统encoder-decoder 可解释差:对于编码向量中究竟编码了什么信息,如何利用这些信息以及解码器特定行为的原因是什么我们并没有明确的认识。包含注意力机制的结构提供了一张相对简单的方式让我们了解解码器的推理过程以及模型究竟在学习什么内容,学到那些东西。尽管是一种弱可解释性,但是已经 make sense 了。
直面 attention 的核心公式
在预测目标语言的第i个词时,源语言第j个词的权重为 , 权重的大小可i以j 看做是一种源语言和目标语言的软对齐信息。
总结
使用 attention 方法实际上就在于预测一个目标词 yi 时,自动获取原句中不同位置的语义信息,并给每个位置信息的语义赋予的一个权重,也就是“软”对齐信息,将这些信息整理起来计算对于当前词 yi 的原句向量表示 c_i。
Attention 的 PyTorch应用实现
1 import torch 2 import torch.nn as nn 3 4 class BiLSTM_Attention(nn.Module): 5 def __init__(self): 6 super(BiLSTM_Attention, self).__init__() 7 8 self.embedding = nn.Embedding(vocab_size, embedding_dim) 9 self.lstm = nn.LSTM(embedding_dim, n_hidden, bidirectional=True) 10 self.out = nn.Linear(n_hidden * 2, num_classes) 11 12 # lstm_output : [batch_size, n_step, n_hidden * num_directions(=2)], F matrix 13 def attention_net(self, lstm_output, final_state): 14 hidden = final_state.view(-1, n_hidden * 2, 1) # hidden : [batch_size, n_hidden * num_directions(=2), 1(=n_layer)] 15 attn_weights = torch.bmm(lstm_output, hidden).squeeze(2) # attn_weights : [batch_size, n_step] 16 soft_attn_weights = F.softmax(attn_weights, 1) 17 # [batch_size, n_hidden * num_directions(=2), n_step] * [batch_size, n_step, 1] = [batch_size, n_hidden * num_directions(=2), 1] 18 context = torch.bmm(lstm_output.transpose(1, 2), soft_attn_weights.unsqueeze(2)).squeeze(2) 19 return context, soft_attn_weights.data.numpy() # context : [batch_size, n_hidden * num_directions(=2)] 20 21 def forward(self, X): 22 input = self.embedding(X) # input : [batch_size, len_seq, embedding_dim] 23 input = input.permute(1, 0, 2) # input : [len_seq, batch_size, embedding_dim] 24 25 hidden_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden] 26 cell_state = Variable(torch.zeros(1*2, len(X), n_hidden)) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden] 27 28 # final_hidden_state, final_cell_state : [num_layers(=1) * num_directions(=2), batch_size, n_hidden] 29 output, (final_hidden_state, final_cell_state) = self.lstm(input, (hidden_state, cell_state)) 30 output = output.permute(1, 0, 2) # output : [batch_size, len_seq, n_hidden] 31 attn_output, attention = self.attention_net(output, final_hidden_state) 32 return self.out(attn_output), attention # model : [batch_size, num_classes], attention : [batch_size, n_step]
注意力机制是一种在编码器-解码器结构中使用到的机制, 现在已经在多种任务中使用:
- 机器翻译(Neural Machine Translation, NMT)
- 图像描述(Image Captioning (translating an image to a sentence))
- 文本摘要(Summarization(translating to a more compact language))
而且也不再局限于编码器-解码器结构, 多种变体的注意力结构, 应用在各种任务中.
总的来说, 注意力机制应用在:
- 允许解码器在序列中的多个向量中, 关注它所需要的信息, 是传统的注意力机制的用法. 由于使用了编码器多步输出, 而不是使用对应步的单一定长向量, 因此保留了更多的信息.
- 作用于编码器, 解决表征问题(例如Encoding Vector再作为其他模型的输入), 一般使用自注意力(self-attention)
1. 编码器-解码器注意力机制
1.1 编码器-解码器结构
如上图, 编码器将输入嵌入为一个向量, 解码器根据这个向量得到输出. 由于这种结构一般的应用场景(机器翻译等), 其输入输出都是序列, 因此也被称为序列到序列的模型Seq2Seq.
对于编码器-解码器结构的训练, 由于这种结构处处可微, 因此模型的参数θθ可以通过训练数据和最大似然估计得到最优解, 最大化对数似然函数以获得最优模型的参数, 即:
这是一种端到端的训练方法.
1.2 编码器
原输入通过一个网络模型(CNN, RNN, DNN), 编码为一个向量. 由于这里研究的是注意力, 就以双向RNN作为示例模型.
对于每个时间步tt, 双向RNN编码得到的向量htht可以如下表示:
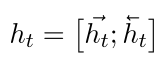
1.3 解码器
这里的解码器是单向RNN结构, 以便在每个时间点上产生输出, 行程序列. 由于解码器仅使用最后时间步TT对应的编码器的隐藏向量hTxhTx, TxTx指的是当前样本的时间步长度(对于NLP问题, 经常将所有样本处理成等长的). 这就迫使编码器将更多的信息整合到最后的隐藏向量hTxhTx中.
但由于hTxhTx是单个长度一定的向量, 这个单一向量的表征能力有限, 包含的信息量有限, 很多信息都会损失掉.
注意力机制允许解码器在每一个时间步tt处考虑整个编码器输出的隐藏状态序列(h1,h2,⋯,hTx)(h1,h2,⋯,hTx), 从而编码器将更多的信息分散地保存在所有隐藏状态向量中, 而解码器在使用这些隐藏向量时, 就能决定对哪些向量更关心.
具体来说, 解码器生产的目标序列(y1,⋯,yTx)(y1,⋯,yTx)中的每一个输出(如单词)ytyt, 都是基于如下的条件分布:
其中h~th~t是引入注意力的隐藏状态向量(attentional hidden state), 如下得到:
htht为编码器顶层的隐藏状态, ctct是上下文向量, 是通过当前时间步上下文的隐藏向量计算得到的, 主要有全局和局部两种计算方法, 下午中提到. WcWc和WsWs参数矩阵训练得到. 为了式子的简化没有展示偏置项.
1.4 全局注意力
通过全局注意力计算上下文向量ctct时, 使用整个序列的隐藏向量htht, 通过加权和的方式获得. 假设对于样本xx的序列长度为TxTx, ctct如下计算得到:
其中长度为TxTx的校准向量alignment vector αtαt的作用是在tt时间步, 隐藏状态序列中的所有向量的重要程度. 其中每个元素αt,iαt,i的使用softmax方法计算:
值的大小指明了序列中哪个时间步对预测当前时间步tt的作用大小.
score函数可以是任意的比对向量的函数, 一般常用:
-
点积: score(ht,hi)=hTthiscore(ht,hi)=htThi
这在使用全局注意力时有更好的效果
-
使用参数矩阵:
score(ht,hi)=hTtWαhiscore(ht,hi)=htTWαhi
这就相当于使用了一个全连接层, 这种方法在使用局部注意力时有更好的效果.
全局注意力的总结如下图:
1.5 局部注意力
全局注意力需要在序列中所有的时间步上进行计算, 计算的代价是比较高的, 可以使用固定窗口大小的局部注意力机制, 窗口的大小为2D+12D+1. DD为超参数, 为窗口边缘距离中心的单方向距离. 上下文向量ctct的计算方法如下:
可以看到, 只是考虑的时间步范围的区别, 其他完全相同. ptpt作为窗口的中心, 可以直接使其等于当前时间步tt, 也可以设置为一个变量, 通过训练获得, 即:
其中σσ为sigmoid函数, vpvp和WpWp均为可训练参数. 因此这样计算得到的ptpt是一个浮点数, 但这并没有影响, 因为计算校准权重向量αtαt时, 增加了一个均值为ptpt, 标准差为D2D2的正态分布项:
当然, 这里有pt∈R∩[0,Tx]pt∈R∩[0,Tx], i∈N∩[pt−D,pt+D]i∈N∩[pt−D,pt+D]. 由于正态项的存在, 此时的注意力机制认为窗口中心附近的时间步对应的向量更重要, 且与全局注意力相比, 除了正态项还增加了一个截断, 即一个截断的正态分布.
局部注意力机制总结如下图:
2. 自注意力
2.1 与编码器-解码器注意力机制的不同
最大的区别是自注意力模型没有解码器. 因此有两个最直接的区别:
- 上下文向量ctct在seq2seq模型中, ct=∑i=1Txαt,ihict=∑i=1Txαt,ihi, 用来组成解码器的输入
h~t=tanh(Wc[ct;ht])h~t=tanh(Wc[ct;ht]), 但由于自注意力机制没有解码器, 所以这里就直接是模型的输出, 即为stst
- 在计算校准向量αtαt时, seq2seq模型使用的是各个位置的隐藏向量与当前隐藏向量的比较值. 在自注意力机制中, 校准向量中的每个元素由每个位置的隐藏向量与当前时间步tt的平均最优向量计算得到的, 而这个平均最优向量是通过训练得到的
2.2 自注意力机制实现
首先将隐藏向量hihi输入至全连接层(权重矩阵为WW), 得到uiui:
使用这个向量计算校正向量αtαt, 通过softmax归一化得到:
这里的utut是当前时间步tt对应的平均最优向量, 每个时间步不同, 这个向量是通过训练得到的.
最后计算最后的输出:
一般来说, 在序列问题中, 只关心最后时间步的输出, 前面时间步不进行输出, 即最后的输出为s=sTs=sT
2.3 层级注意力
如下图, 对于一个NLP问题, 在整个架构中, 使用了两个自注意力机制: 词层面和句子层面. 符合文档的自然层级结构:
词->句子->文档. 在每个句子中, 确定每个单词的重要性, 在整片文档中, 确定不同句子的重要性.
参考:
https://zhuanlan.zhihu.com/p/88376673
https://www.cnblogs.com/databingo/p/9769928.html
Attention 的本质是什么
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。

Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。大家看一下下面这张图:

我们一定会看清「锦江饭店」4个字,如下图:

但是我相信没人会意识到「锦江饭店」上面还有一串「电话号码」,也不会意识到「喜运来大酒家」,如下图:

所以,当我们看一张图片的时候,其实是这样的:

上面所说的,我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
AI 领域的 Attention 机制
Attention 机制最早是在计算机视觉里应用的,随后在 NLP 领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年 BERT 和 GPT 的效果出奇的好,进而走红。而 Transformer 和 Attention 这些核心开始被大家重点关注。
如果用图来表达 Attention 的位置大致是下面的样子:

这里先让大家对 Attention 有一个宏观的概念,下文会对 Attention 机制做更详细的讲解。在这之前,我们先说说为什么要用 Attention。
Attention 的3大优点
之所以要引入 Attention 机制,主要是3个原因:
- 参数少
- 速度快
- 效果好
参数少
模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
速度快
Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
效果好
在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的预期就是被挑出来的重点。

Attention 的原理
Attention 经常会和 Encoder–Decoder 一起说,之前的文章《一文看懂 NLP 里的模型框架 Encoder-Decoder 和 Seq2Seq》 也提到了 Attention。
下面的动图演示了attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。
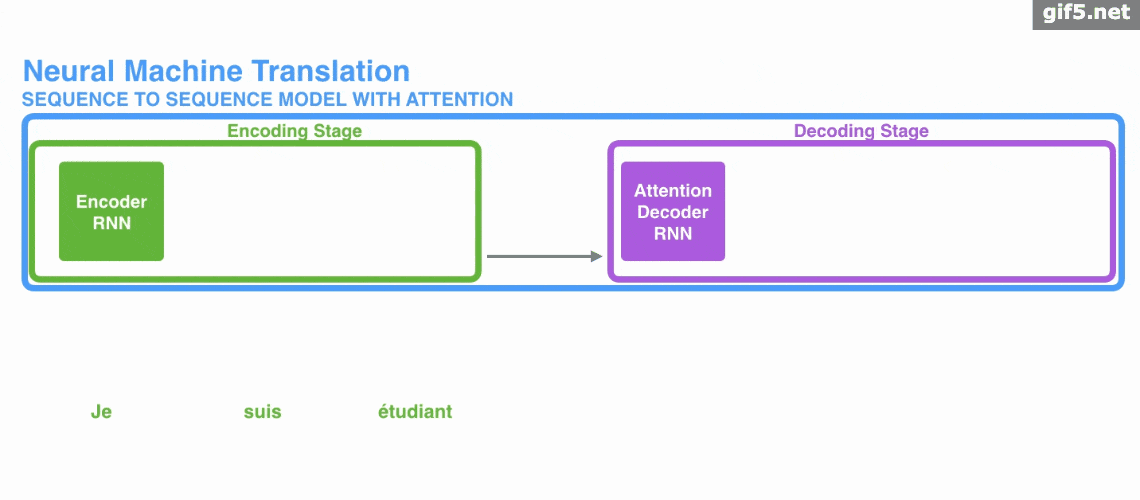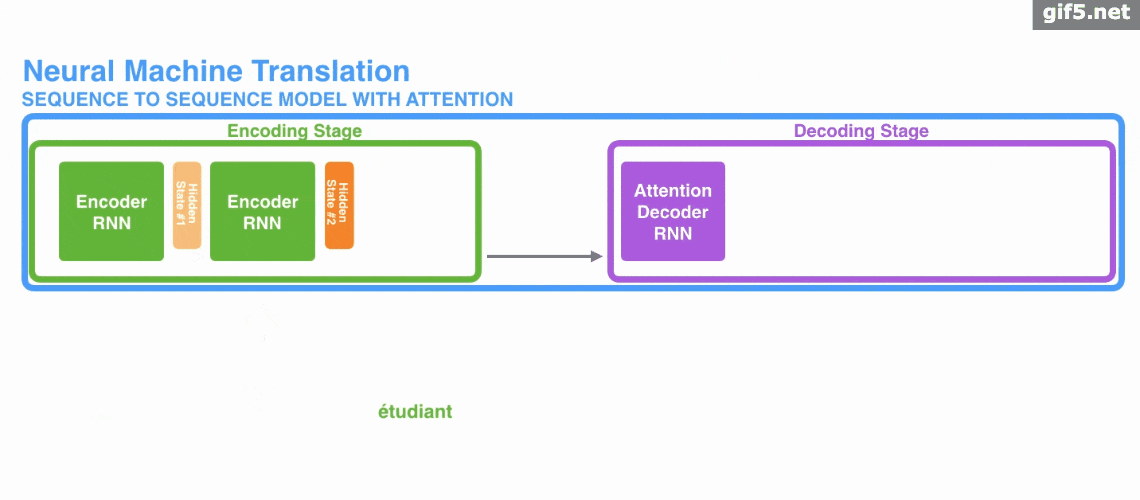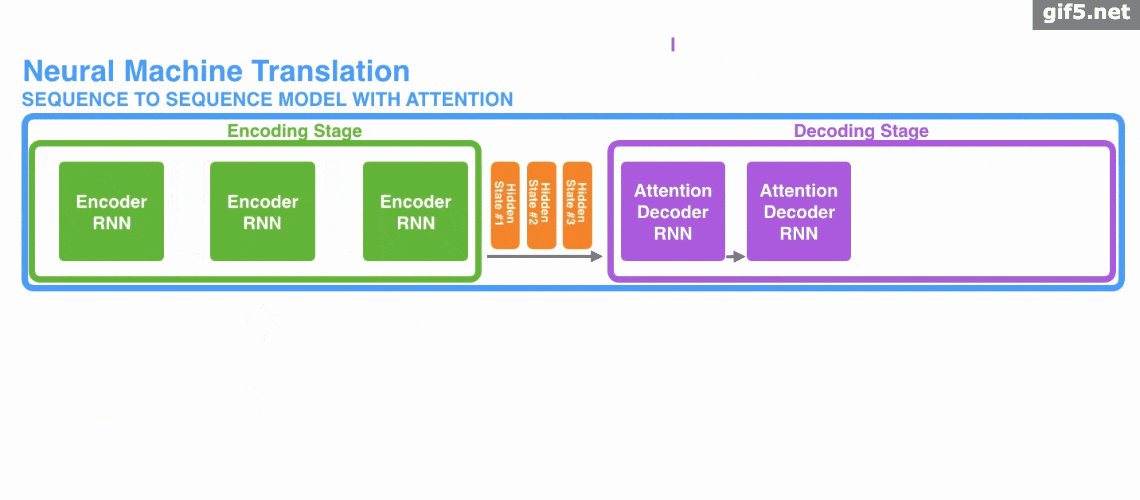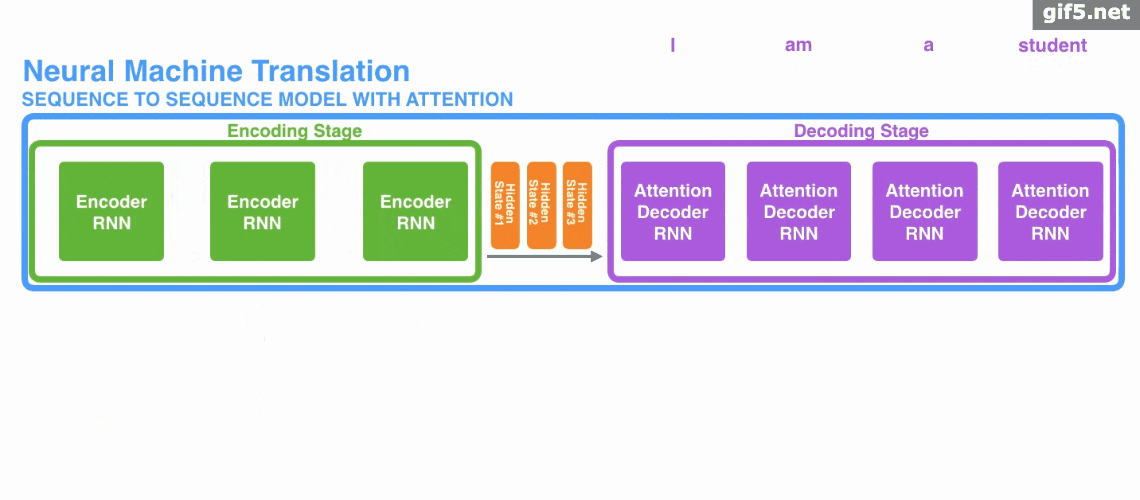
但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。
下面的图片则是脱离 Encoder-Decoder 框架后的原理图解。
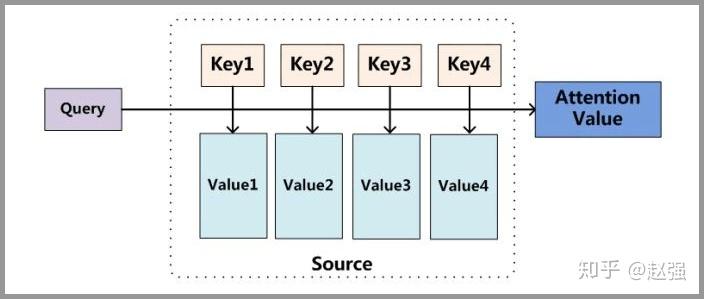
小故事讲解
上面的图看起来比较抽象,下面用一个例子来解释 attention 的原理:
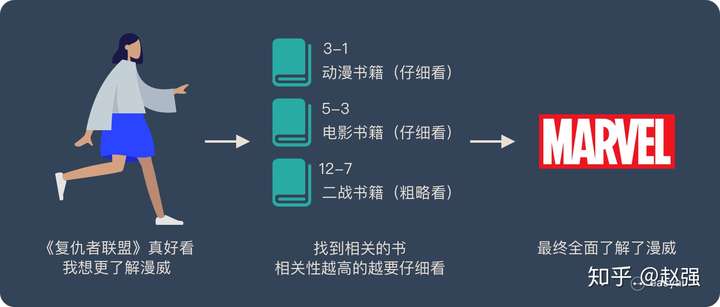
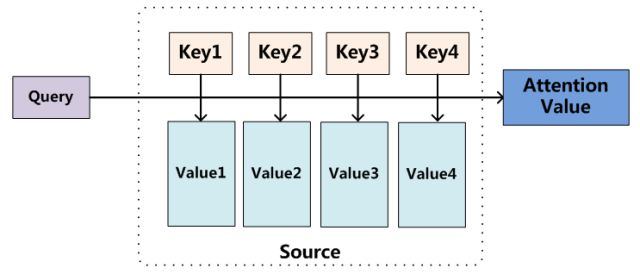
图书管(source)里有很多书(value),为了方便查找,我们给书做了编号(key)。当我们想要了解漫威(query)的时候,我们就可以看看那些动漫、电影、甚至二战(美国队长)相关的书籍。
为了提高效率,并不是所有的书都会仔细看,针对漫威来说,动漫,电影相关的会看的仔细一些(权重高),但是二战的就只需要简单扫一下即可(权重低)。
当我们全部看完后就对漫威有一个全面的了解了。
Attention 原理的3步分解:
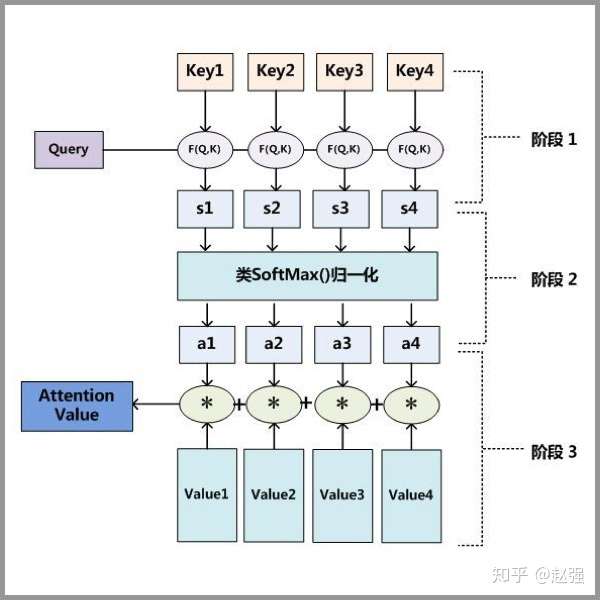
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
从上面的建模,我们可以大致感受到 Attention 的思路简单,四个字“带权求和”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感)->提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)->融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)->登峰造极(沉浸地大量练习)。
这也如同attention的发展脉络,RNN 时代是死记硬背的时期,attention 的模型学会了提纲挈领,进化到 transformer,融汇贯通,具备优秀的表达学习能力,再到 GPT、BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。
要回答为什么 attention 这么优秀?是因为它让模型开窍了,懂得了提纲挈领,学会了融会贯通。
——阿里技术
想要了解更多技术细节,可以看看下面的文章或者视频:
「文章」深度学习中的注意力机制
「文章」探索 NLP 中的 Attention 注意力机制及 Transformer 详解
Attention 的 N 种类型
Attention 有很多种不同的类型:Soft Attention、Hard Attention、静态Attention、动态Attention、Self Attention 等等。下面就跟大家解释一下这些不同的 Attention 都有哪些差别。
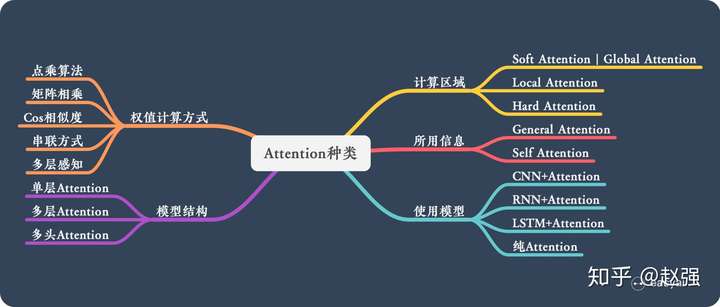
由于这篇文章《Attention用于NLP的一些小结》已经总结的很好的,下面就直接引用了:
本节从计算区域、所用信息、结构层次和模型等方面对Attention的形式进行归类。
1. 计算区域
根据Attention的计算区域,可以分成以下几种:
1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
2. 所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算attention,这里问题属于原文,文章词向量就属于外部信息。
2)Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
3. 结构层次
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
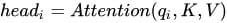
最后再把这些结果拼接起来:
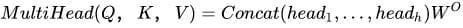
4. 模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
1)CNN+Attention
CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
a. 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
2)LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有:
a. 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
3)纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
5. 相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
1)点乘:最简单的方法,
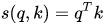
2)矩阵相乘:
3)cos相似度:
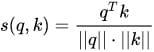
4)串联方式:把q和k拼接起来,
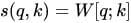
5)用多层感知机也可以:
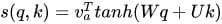
参考:
https://zhuanlan.zhihu.com/p/91839581
【NLP】Attention原理和源码解析
对attention一直停留在浅层的理解,看了几篇介绍思想及原理的文章,也没实践过,今天立个Flag,一天深入原理和源码!如果你也是处于attention model level one的状态,那不妨好好看一下啦。
内容:
- 核心思想
- 原理解析(图解+公式)
- 模型分类
- 优缺点
- TF源码解析
P.S. 拒绝长篇大论,适合有基础的同学快速深入attention,不明白的地方请留言咨询~
1. 核心思想
Attention的思想理解起来比较容易,就是在decoding阶段对input中的信息赋予不同权重。在nlp中就是针对sequence的每个time step input,在cv中就是针对每个pixel。
2. 原理解析
针对Seq2seq翻译来说,rnn-based model差不多是图1的样子:
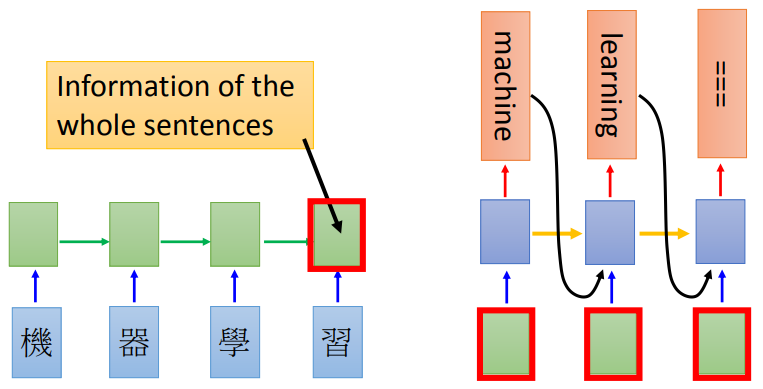 图1 传统rnn-based model
图1 传统rnn-based model
而比较基础的加入attention与rnn结合的model是下面的样子(也叫soft attention):
其中 是
对应的权重,算出所有权重后会进行softmax和加权,得到
。
可以看到Encoding和decoding阶段仍然是rnn,但是decoding阶使用attention的输出结果 作为rnn的输入。
那么重点来了, 权重 是怎么来的呢?常见有三种方法:
思想就是根据当前解码“状态”判断输入序列的权重分布。
如果把attention剥离出来去看的话,其实是以下的机制:
输入是query(Q), key(K), value(V),输出是attention value。如果与之前的模型对应起来的话,query就是 ,key就是
,value也是
。模型通过Q和K的匹配计算出权重,再结合V得到输出:
再深入理解下去,这种机制其实做的是寻址(addressing),也就是模仿中央处理器与存储交互的方式将存储的内容读出来,可以看一下李宏毅老师的课程。
3. 模型分类
3.1 Soft/Hard Attention
soft attention:传统attention,可被嵌入到模型中去进行训练并传播梯度
hard attention:不计算所有输出,依据概率对encoder的输出采样,在反向传播时需采用蒙特卡洛进行梯度估计
3.2 Global/Local Attention
global attention:传统attention,对所有encoder输出进行计算
local attention:介于soft和hard之间,会预测一个位置并选取一个窗口进行计算
3.3 Self Attention
传统attention是计算Q和K之间的依赖关系,而self attention则分别计算Q和K自身的依赖关系。具体的详解会在下篇文章给出~
4. 优缺点
优点:
- 在输出序列与输入序列“顺序”不同的情况下表现较好,如翻译、阅读理解
- 相比RNN可以编码更长的序列信息
缺点:
- 对序列顺序不敏感
- 通常和RNN结合使用,不能并行化
5. TF源码解析
发现已经有人解析得很明白了,即使TF代码有更新,原理应该还是差不多的,直接放上来吧:
顾秀森:Tensorflow源码解读(一):AttentionSeq2Seq模型Attention机制详解(一)——Seq2Seq中的Attention
Attention模型在机器学习领域越来越得到广泛的应用,准备写一个关于Attention模型的专题,主要分为三个部分:(一)在Seq2Seq 问题中RNN与Attention的结合。 (二)抛除RNN的Self-Attention模型以及谷歌的Transformer架构。 (三)Attention及Transformer在自然语言处理及图像处理等方面的应用。主要参考资料是Yoshua Bengio组的论文、谷歌研究组的论文及Tensor2Tensor的官方文档、斯坦福自然语言处理相关部分讲义等。
这一篇先来介绍早期的在Machine Translation(机器翻译)中Attention机制与RNN的结合。
RNN结构的局限
机器翻译解决的是输入是一串在某种语言中的一句话,输出是目标语言相对应的话的问题,如将德语中的一段话翻译成合适的英语。之前的Neural Machine Translation(一下简称NMT)模型中,通常的配置是encoder-decoder结构,即encoder读取输入的句子将其转换为定长的一个向量,然后decoder再将这个向量翻译成对应的目标语言的文字。通常encoder及decoder均采用RNN结构如LSTM或GRU等(RNN基础知识可参考循环神经网络RNN——深度学习第十章),如下图所示,我们利用encoder RNN将输入语句信息总结到最后一个hidden vector中,并将其作为decoder初始的hidden vector,利用decoder解码成对应的其他语言中的文字。
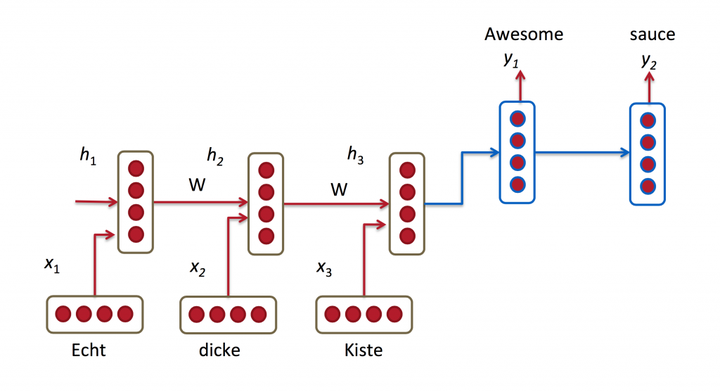
但是这个结构有些问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
Attention机制的引入
为了解决这一由长序列到定长向量转化而造成的信息损失的瓶颈,Attention注意力机制被引入了。Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。同样的,Attention模型中,当我们翻译当前词语时,我们会寻找源语句中相对应的几个词语,并结合之前的已经翻译的部分作出相应的翻译,如下图所示,当我们翻译“knowledge”时,只需将注意力放在源句中“知识”的部分,当翻译“power”时,只需将注意力集中在"力量“。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。

以上是直观理解,我们来详细的解释一下数学上对应哪些运算。
- 首先我们利用RNN结构得到encoder中的hidden state
,
- 假设当前decoder的hidden state 是
,我们可以计算每一个输入位置j与当前输出位置的关联性,
,写成相应的向量形式即为
,其中
是一种相关性的算符,例如常见的有点乘形式
,加权点乘
,加和
等等。
- 对于
进行softmax操作将其normalize得到attention的分布,
,展开形式为
- 利用
我们可以进行加权求和得到相应的context vector
- 由此,我们可以计算decoder的下一个hidden state
以及该位置的输出
。
这里关键的操作是计算encoder与decoder state之间的关联性的权重,得到Attention分布,从而对于当前输出位置得到比较重要的输入位置的权重,在预测输出时相应的会占较大的比重。
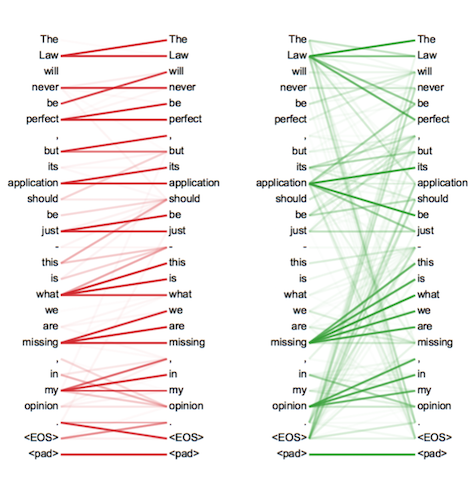
通过Attention机制的引入,我们打破了只能利用encoder最终单一向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。还有一个优点是,我们通过观察attention 权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,有助于更好的理解模型工作机制,如下图所示。

当然,一个自然的疑问是,Attention机制如此有效,那么我们可不可以去掉模型中的RNN部分,仅仅利用Attention呢?下一篇会详细解释谷歌在Attention is All you need中提出的self-attention机制及Transformer
Attention机制详解(二)——Self-Attention与Transformer
上一篇Attention机制详解(一)——Seq2Seq中的Attention回顾了早期Attention机制与RNN结合在机器翻译中的效果,RNN由于其顺序结构训练速度常常受到限制,既然Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型呢,这样我们可以使训练并行化,同时拥有全局信息?
这一篇就主要根据谷歌的这篇Attention is All you need论文来回顾一下仅依赖于Attention机制的Transformer架构,并结合Tensor2Tensor源代码进行解释。
直观理解与模型整体结构
先来看一个翻译的例子“I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。如下图所示,encoder读入输入数据,利用层层叠加的Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。Decoder也利用类似的Self-Attention机制,但它不仅仅看之前产生的输出的文字,而且还要attend encoder的输出。以上步骤如下动图所示:

Transformer模型的整体结构如下图所示
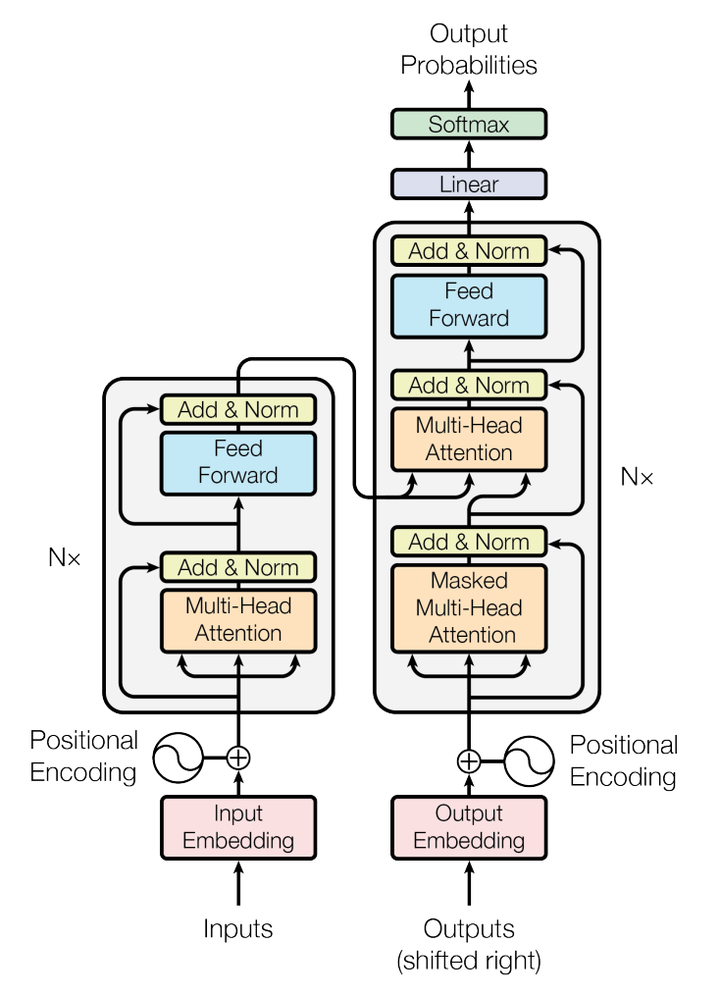
这里面Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,如下图所示,两个head学习到的Attention侧重点可能略有不同,这样给了模型更大的容量。
Self-Attention详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
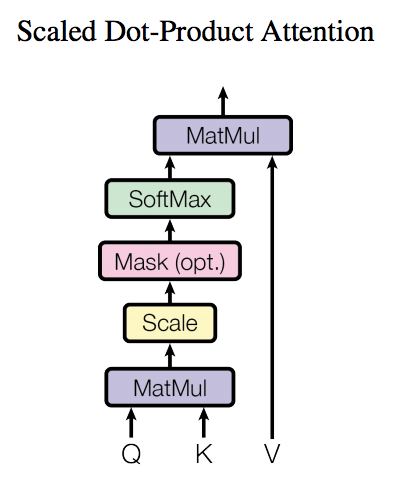
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度 ,其中
为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为
这里可能比较抽象,我们来看一个具体的例子(图片来源于https://jalammar.github.io/illustrated-transformer/,该博客讲解的极其清晰,强烈推荐),假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用 表示,Machines的embedding vector用
表示。
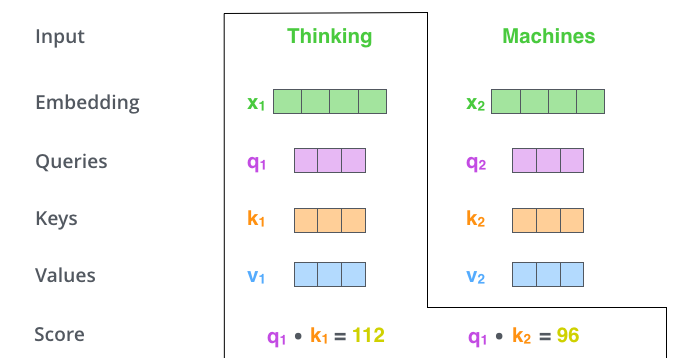
当我们处理Thinking这个词时,我们需要计算句子中所有词与它的Attention Score,这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。我们用 代表Thinking对应的query vector,
及
分别代表Thinking以及Machines对应的key vector,则计算Thinking的attention score的时候我们需要计算
与
的点乘,同理,我们计算Machines的attention score的时候需要计算
与
的点乘。如上图中所示我们分别得到了
与
的点乘积,然后我们进行尺度缩放与softmax归一化,如下图所示:
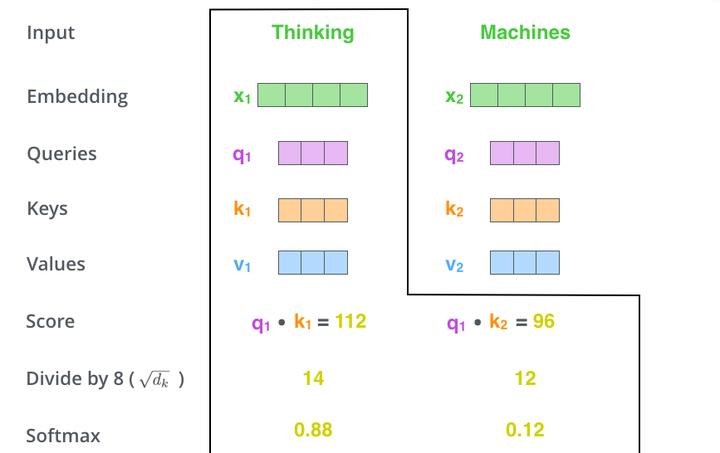
显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。然后我们在用这些attention score与value vector相乘,得到加权的向量。
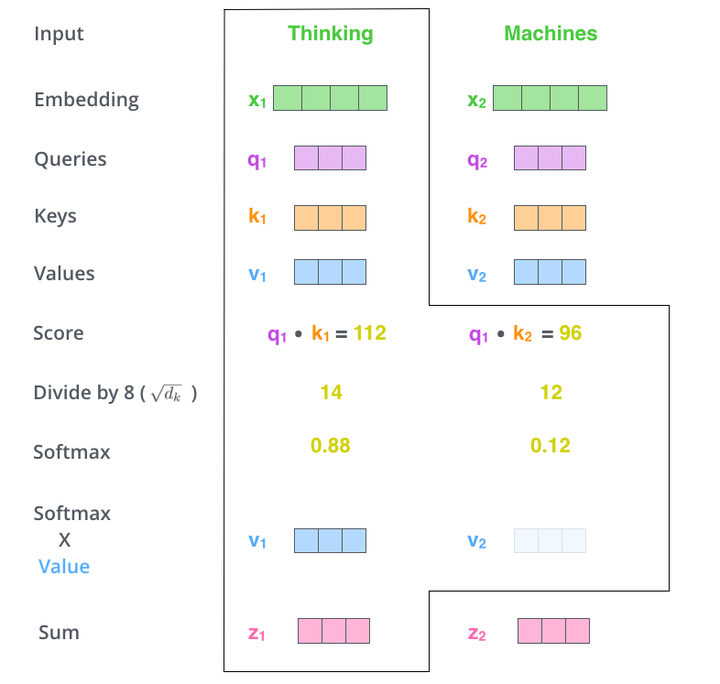
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
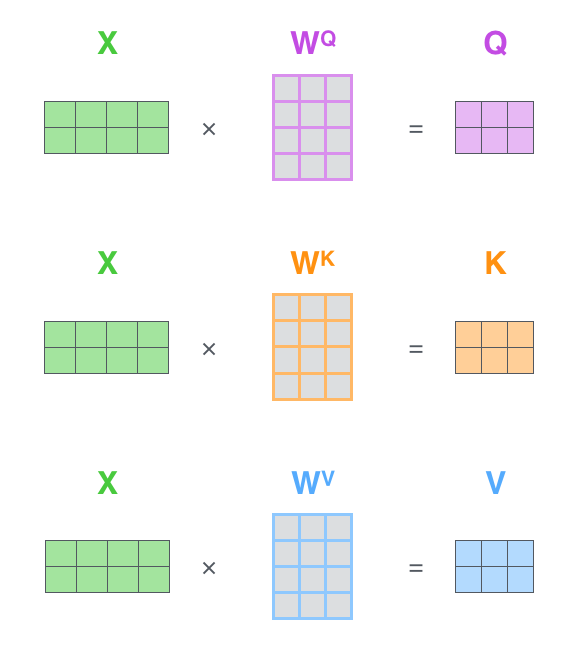
其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
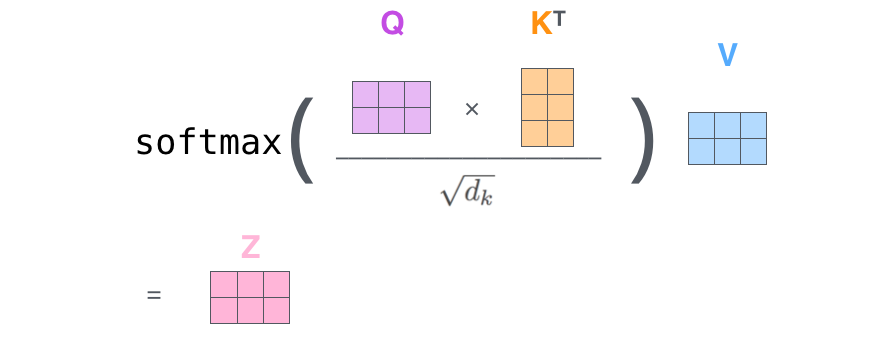
而multihead就是我们可以有不同的Q,K,V表示,最后再将其结果结合起来,如下图所示:
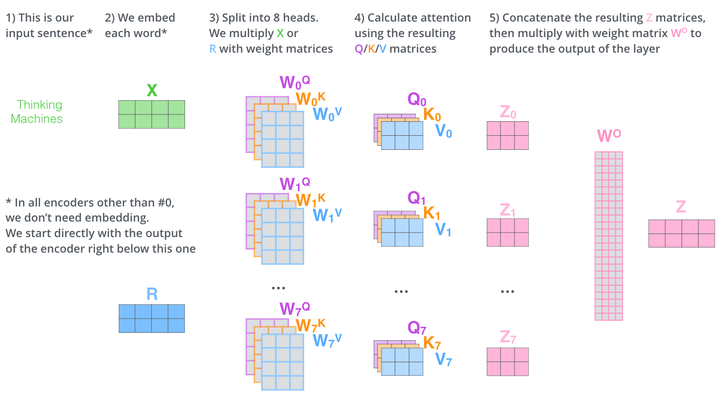
这就是基本的Multihead Attention单元,对于encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层encoder的输出,即encoder的每个位置都可以注意到之前一层encoder的所有位置。
对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出,下面分别解释一下是什么原理。
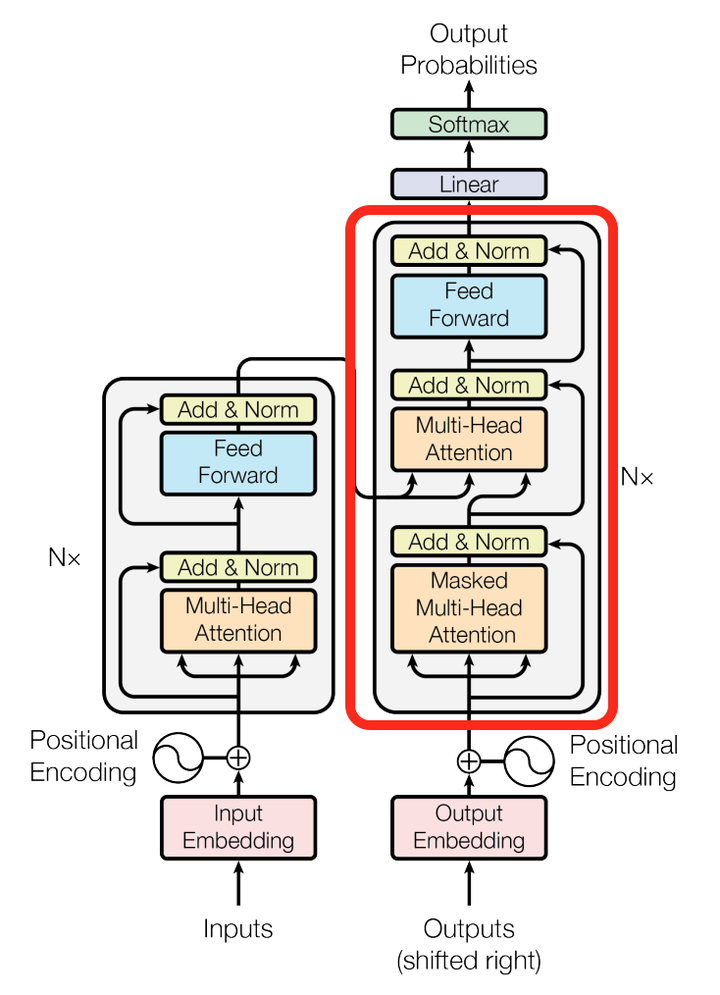
第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
而第二级decoder也被称作encoder-decoder attention layer,即它的query来自于之前一级的decoder层的输出,但其key和value来自于encoder的输出,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。
总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
论文其他细节解读
我们再来看看论文其他方面的细节,一个使position encoding,这个目的是什么呢?注意由于该模型没有recurrence或convolution操作,所以没有明确的关于单词在源句子中位置的相对或绝对的信息,为了更好的让模型学习位置信息,所以添加了position encoding并将其叠加在word embedding上。该论文中选取了三角函数的encoding方式,其他方式也可以,该研究组最近还有relation-aware self-attention机制,可参考这篇论文[1803.02155] Self-Attention with Relative Position Representations。
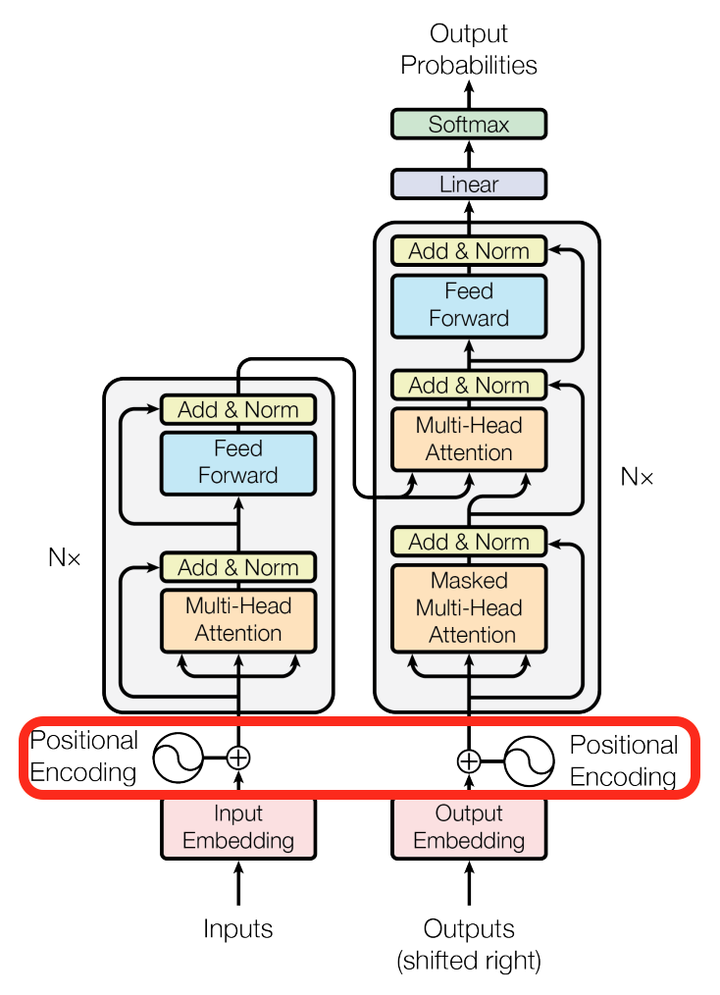
再来看看模型中这些Add & Norm模块的作用。
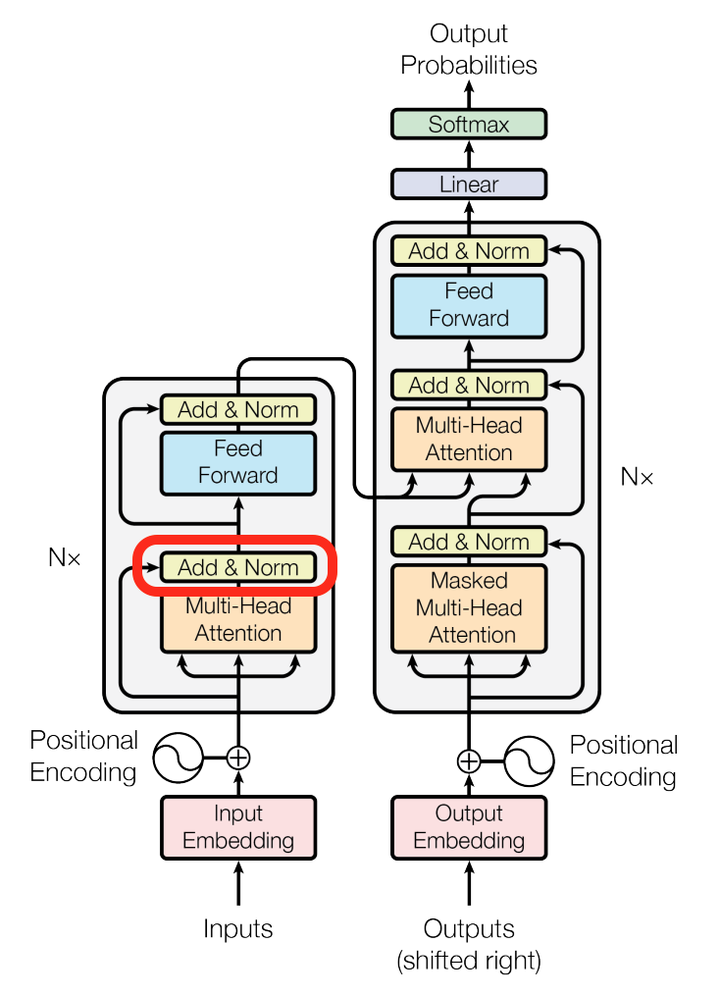
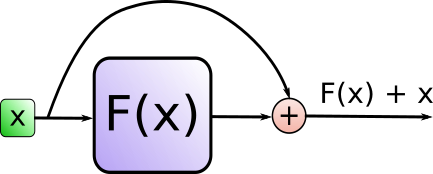
其中Add代表了Residual Connection,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分,这一方法之前在图像处理结构如ResNet等中常常用到。
而Norm则代表了Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛,可参考这篇论文Layer Normalization。
源码解读
我们可以通过阅读源码加深理解,主要的部分是common_attention library以及调用该library的Transformer模型。
我们先来看看common_attention library 中的multihead-attention method(为简化省去很多argument及logic,集中于主要的logic,而且以单一head为例并加入了自己的一些comment,感兴趣的可以详细查阅源码):
def multihead_attention(query_antecedent,
memory_antecedent,
...):
"""Multihead scaled-dot-product attention with input/output transformations.
Args:
query_antecedent: a Tensor with shape [batch, length_q, channels]
memory_antecedent: a Tensor with shape [batch, length_m, channels] or None
...
Returns:
The result of the attention transformation. The output shape is
[batch_size, length_q, hidden_dim]
"""
#计算q, k, v矩阵
q, k, v = compute_qkv(query_antecedent, memory_antecedent, ...)
#计算dot_product的attention
x = dot_product_attention(q, k, v, ...)
x = common_layers.dense(x, ...)
return x其中compute_qkv定义为
def compute_qkv(query_antecedent,
memory_antecedent,
...):
"""Computes query, key and value.
Args:
query_antecedent: a Tensor with shape [batch, length_q, channels]
memory_antecedent: a Tensor with shape [batch, length_m, channels]
...
Returns:
q, k, v : [batch, length, depth] tensors
"""
# 注意这里如果memory_antecedent是None,它就会设置成和query_antecedent一样,encoder的
# self-attention调用时memory_antecedent 传进去的就是None。
if memory_antecedent is None:
memory_antecedent = query_antecedent
q = compute_attention_component(
query_antecedent,
...)
# 注意这里k,v均来自于memory_antecedent。
k = compute_attention_component(
memory_antecedent,
...)
v = compute_attention_component(
memory_antecedent,
...)
return q, k, v
def compute_attention_component(antecedent,
...):
"""Computes attention compoenent (query, key or value).
Args:
antecedent: a Tensor with shape [batch, length, channels]
name: a string specifying scope name.
...
Returns:
c : [batch, length, depth] tensor
"""
return common_layers.dense(antecedent, ...)其中dot_product_attention定义为
def dot_product_attention(q,
k,
v,
...):
"""Dot-product attention.
Args:
q: Tensor with shape [..., length_q, depth_k].
k: Tensor with shape [..., length_kv, depth_k]. Leading dimensions must
match with q.
v: Tensor with shape [..., length_kv, depth_v] Leading dimensions must
match with q.
Returns:
Tensor with shape [..., length_q, depth_v].
"""
# 计算Q, K的矩阵乘积。
logits = tf.matmul(q, k, transpose_b=True)
# 利用softmax将结果归一化。
weights = tf.nn.softmax(logits, name="attention_weights")
# 与V相乘得到加权表示。
return tf.matmul(weights, v)我们再来看看Transformer模型中是如何调用的,对于encoder
def transformer_encoder(encoder_input,
hparams,
...):
"""A stack of transformer layers.
Args:
encoder_input: a Tensor
hparams: hyperparameters for model
...
Returns:
y: a Tensors
"""
x = encoder_input
with tf.variable_scope(name):
for layer in range(hparams.num_encoder_layers or hparams.num_hidden_layers):
with tf.variable_scope("layer_%d" % layer):
with tf.variable_scope("self_attention"):
# layer_preprocess及layer_postprocess包含了一些layer normalization
# 及residual connection, dropout等操作。
y = common_attention.multihead_attention(
common_layers.layer_preprocess(x, hparams),
#这里注意encoder memory_antecedent设置为None
None,
...)
x = common_layers.layer_postprocess(x, y, hparams)
with tf.variable_scope("ffn"):
# 前馈神经网络部分。
y = transformer_ffn_layer(
common_layers.layer_preprocess(x, hparams),
hparams,
...)
x = common_layers.layer_postprocess(x, y, hparams)
return common_layers.layer_preprocess(x, hparams)对于decoder
def transformer_decoder(decoder_input,
encoder_output,
hparams,
...):
"""A stack of transformer layers.
Args:
decoder_input: a Tensor
encoder_output: a Tensor
hparams: hyperparameters for model
...
Returns:
y: a Tensors
"""
x = decoder_input
with tf.variable_scope(name):
for layer in range(hparams.num_decoder_layers or hparams.num_hidden_layers):
layer_name = "layer_%d" % layer
with tf.variable_scope(layer_name):
with tf.variable_scope("self_attention"):
# decoder一级memory_antecedent设置为None
y = common_attention.multihead_attention(
common_layers.layer_preprocess(x, hparams),
None,
...)
x = common_layers.layer_postprocess(x, y, hparams)
if encoder_output is not None:
with tf.variable_scope("encdec_attention"):
# decoder二级memory_antecedent设置为encoder_output
y = common_attention.multihead_attention(
common_layers.layer_preprocess(x, hparams),
encoder_output,
...)
x = common_layers.layer_postprocess(x, y, hparams)
with tf.variable_scope("ffn"):
y = transformer_ffn_layer(
common_layers.layer_preprocess(x, hparams),
hparams,
...)
x = common_layers.layer_postprocess(x, y, hparams)
return common_layers.layer_preprocess(x, hparams)这些代码验证了我们之前在self-attention详解中的理解是正确的。
总结
完全的不依赖于RNN结构仅利用Attention机制的Transformer由于其并行性和对全局信息的有效处理使其获得了较之前方法更好的翻译结果,在这基础上,Attention和Transformer架构逐步被应用在自然语言处理及图像处理等领域,下一篇将会介绍这些方面的应用。
Attention机制详解(三)——Attention模型的应用
上两篇Attention机制详解(一)——Seq2Seq中的Attention, Attention机制详解(二)——Self-Attention与Transformer主要回顾了Attention与RNN结合在机器翻译中的原理以及self-attention模型,这一篇准备分类整理一下Attention模型的各种应用场景,主要参考资料为谷歌研究组和Yoshua Bengio组的论文。
自然语言处理
之前已经见过Attention模型对于机器翻译(Attention is All you need)有非常很好的效果,那么在自然语言处理方面Attention模型还有哪些其他应用呢?我们通过总结以下几篇论文来了解以下:
这篇文章主要是结合了Transformer结构与RNN中循环归纳的优点,使得Transformer结构能够适用更多自然语言理解的问题。其改进的结构如下
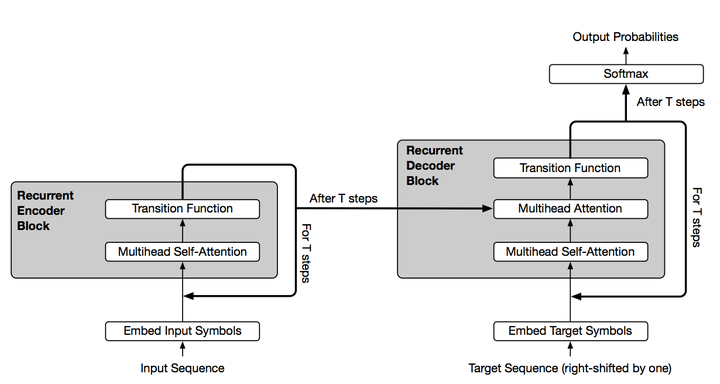
可以看到,通过引入Transition Function,我们对Attention可以进行多次循环。这一机制被有效的应用到诸如问答,根据主语推测谓语,根据上下填充缺失的单词,数字字符串运算处理,简易程序执行,机器翻译等场景。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
这也是最近自然语言处理领域比较火的文章,打破了多项benchmark,主要是利用双向Transformer进行预处理,得到包含有上下文信息的表示,这一表示可进一步用来fine-tune很多种自然语言处理任务。下图是BERT模型(双向Tansformer结构)与OpenAI GPT(单向Transformer结构)与ElMo(双向独立LSTM最终组合的结构)的对比。
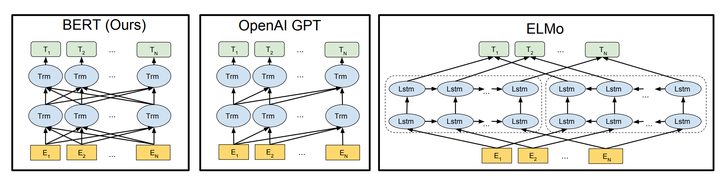
BERT的表示进行fine-tuning后,对于GLUE Benchmark(主要包含MNLI,RTE:比较两个句子的语义关系,QQP:判别Quora上两个问题相似度,QNLI:问答,SST-2:情感分析,CoLA:语句合理性判别,STS-B, MRPC:句子相似度判别),SQuAD(问答),NER(命名实体识别)等都有极大的提高。将来,可能BERT pre-train在自然语言处理领域就会像VGG, ResNet, Inception等在图像识别里的作用而成为预处理的标配。
Generating Wikipedia by Summarizing Long Sequences
文章生成:通过处理若干篇源文章,提取有效信息,再用Transformer Decoder合成一篇类似于Wikipedia风格的文章,这个模型以后加以改善可以极大的方便人们获取有效信息。
图像处理及合成
其实最早Attention模型是先在图像处理领域得到应用,后来拓展到自然语言处理领域,例如这一篇
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
就是利用Attention机制进行Image Caption(将图像翻译为文字表述)

利用Attention机制进行图像合成,如将局部图像补全:

通过低分辨率的图像还原高分辨率图像

由于Image Transformer模型训练的稳定性,很有可能代替GAN成为图像生成任务的首选。
其他
这里再列出一些综合或其他方面的应用
采用多适应性的模型架构希望一个模型可以处理多领域的问题。其模型结构如下所示
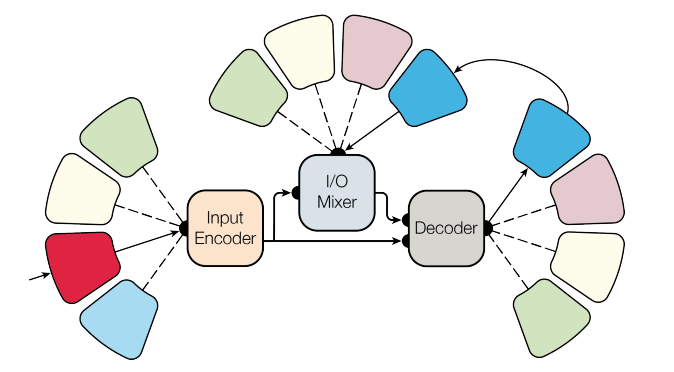
该论文中处理了语言文字、图像、声音和分类数据,虽然和state-of-the-art还不能相比,但也不失为一种泛机器学习的有意思的尝试。
Neural Attentive Session-based Recommendation
利用Attention模型处理用户session中的序列信息进行相关推荐,值得参考。
Generating Long-Term Structure in Songs and Stories
来自谷歌Magenta项目,利用Attention RNN创作乐曲,很有意思。
Attention模型由于其并行性,高效性及可解释性,逐渐会用在越来越多的有意思的应用场景中,值得期待。
链接:https://zhuanlan.zhihu.com/p/47613793

 浙公网安备 33010602011771号
浙公网安备 33010602011771号