

| desc | |
| 神经网络问题的解决 |
1. 网络调不了
1) init 的工作
2) 想办法找pre train 去 fine tuning
3) batch normalization 减小依赖度
4) 别用 sigmoid
2. 准确率上不去 或者 早停止 了,即:validate 或者 交叉验证集 上的loss 不再下降,但是 train 上可能还会下降,此时是一个瓶颈,即 还有办法做
1) 调 lr,halved the α步长
即 准确率上不去 有哪些method
|
| 关于 tensorFlow |
1. caffe model zoo 可以转化为 TF 的
2. 可视化中间的过程,然后可以实时监控
|
| CNN 的几个层 |
data
conv
pooling 下采样
激励层
全连接
softmax
|
| SGD 与 全局梯度下降的对比 |
SGD
优点:可以跳过局部最优点
缺点:但是loss 曲线会震荡,即不是每次都是 loss 下降的(上一个data 按照其梯度下降了,但是 next data 可能loss 还是很大,甚至比原来上升了)
全局GD:
优点:每次loss 都在稳定的下降
缺点:很可能收敛到局部极值
因此两者 balance 就是 mini-batch
多个batch随机,可能收敛到全局最优
多个batch,每次全局 loss 降低 速度加快
单次看不一定是下降的,长期看是下降的
|
| 现在工业界的激活函数 | 一般都是 RELU 了 |
| RNN 很多是全连接的 |
· 数据维度变更也是全连接
· LSTM 的参数是 全连接相乘
· 对于 RNN 的参数也是全连接
所以可能用到 Batch Normalizaiton
|
|
两个对神经网络工程化的理解
【important】
|
1. 关于初始化的重要性,但是你从没有考虑过:
受这个伤了,重要性占 整个网络的 60%!!!
2. 因为有这种 layer input 成为全 0的现象 或者 ±1 震荡
所以才会有:监控可视化,作为一个模块单独引入在 TF 中
|
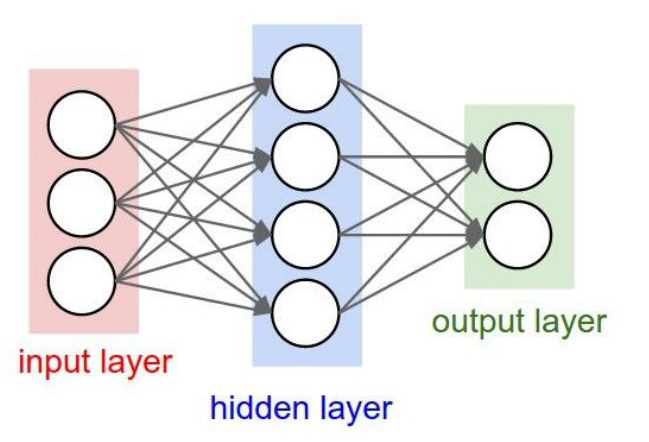
| 全零初始化 |
如果全部的w都是0,那么这里:
四个input都是一模一样的 ,下一层的两个input 也是一模一样的了
传回来的梯度也一模一样,再传入也是一模一样
即:所有的 cell 在学习同一个东西
但是希望:希望参数非对称,分化出不同的权重 ,从而学习不同的角度
结论:不可取
 |
|
小值的正态随机初始化
|
层次不深,可行;层次深,不可行
因为传到后面,input layer X 也都成了全0
|
| 大值的正态随机初始化 |
节点容易饱和
即:每次的输出 sigmiod(wx+b) 后的输出是 ±1,相当于 wx+b 这个值很大
此时的 梯度接近于 消失
|
|
理论求证
对于 非ReLU 的层
|
让初始化的范围与 input 与 output 的节点的个数相关
这样初始化,可以保证:
输入层序列的方差和输出层序列的方差是一致的
因为经过推到这个可以看出是 与 神经元个数相关的
|
|
理论求证
对于 ReLU 的层
|
或者
这样的初始化,其实就是在原基础上 把 根号n 变为
|
| batch normalization |
中心极限定理:不管X 服从什么分布,只要 Xi 独立同分布
那么 这几个 Xi 的和就服从 正态分布
这里相当于 n 为1,那么 处理过的 X' 服从 N(0,1) 的标准正态分布
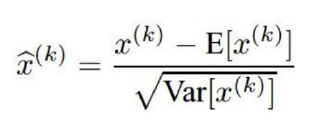 然后因为正态分布化以后,这个对原始信息的表征是有损失的
还要使用r 和 β通过线性组合来进行信息的还原,
用这个 Y 作为新的next layer 的输入【important】
|
| BN 层的位置 |
一般 BN 接在FC 后面的 ,是因为FC 的输出的波动状况会更大
conv 层 后面其实还是没那么大波动
现在的CNN 已经开始有多个FC层
这是有可能的,只要计算力够,然后再需要BN
|
| batch normalization的好处 |
1. 降低对init 的敏感度,因为降低了 全0 或者 ±1饱和的情况,因此传导计算也流畅
2. 属于一种正则化,即 input 被约束在一定范围内
FC 的学习能力是强的,在尽可能记录原始信息, 所以在一个幅度大的范围内进行信息表征,所以输出的vector 的波动大,目的是:能记录所有的信息
现在的约束是 在一定的空间范围内进行学习,只能在这个范围内将信息表示出来,所以可以视为一种正则化
|
| batch normalization 解决的问题不是 梯度相关的,而是 input 相关的 |
所以其实最大的问题就是 input 全都成了0,那么输出也都是 0 了
这可能使得网络训练不下去,此时的梯度很大
而 batch normalization 就是解决这个 input layer X 分布不均与的问题
如果 input 很大——> 梯度消失
如果 input 全0 ——> 梯度很大
|
| Alex 的地位 |
就是给后面的网络一个很好的初始化
其它的往往使得网络训练不下去,你不知道考虑这个init,即太脆弱了
三大网络:
Alex net,GoogleLeNet,VGG,resNet
都是给后面提供了 fine tuning 的借鉴
而 VGG 都是在 Alex 的基础上训练出来的
|
| 去均值的两种情况 |
1. 按:像素点:
32 * 32 个像素点,按照 element wise 的求均值,
即一共有:32*32*3 个均值
2. 按通道:
只有三个均值,即便是同一张图片内的所有像素点,同一个通道的都要相加,
这个方法比较粗暴
|
| 如何理解加入 noise | 加一些noise,使得学习这些 noise,从而更健壮 |
| 对牛顿法的观点 | 可以理解为2阶的SGD,会更快,但是对内存要求大 |
| 对深度学习的认识 | 深度学习极强,如果技巧得当 讲一个 task 做好,其实不是 理论上多么强,而是 工程能力好,而 普通的 model,是没有这么强的灵活性的 |
| 对 dropout 的认识 |
神经网络中 倾向于 不使用 L2 norm
因为神经网络的参数量太大,而 L2 norm 这个量级的计算太大
所以使用的是 dropout
|
| 预测过程的dropout |
预测的时候怎么做?
1. 所有的 x 乘以 概率值p, 而不是再0-1化的开关损失了,此时是连续化的
2. 训练的时候所有有dropout 的layer 都 x'=x/p
那么预测的时候什么都不用做,即学的时候就是 x/p的参数
|
| 为什么dropout 能防止过拟合 |
1. 别开启所有的学习单元,遗忘一定的细节
2. 每次训练过程中都随机关掉一部分感知器,每次得到一个新模型
那么调参的方向将会是 多个模型的综合,不至于听一家所言
|
| 多类别分类 |
损失函数使用:互熵损失最好
对于多类别,其实是 两个序列,尤其是看做两个 概率分布
|
| caffe 的使用步骤 |
· 图像转数据库
· 定义层次结构
· 定义solver # 训练时候的参数
使用 caffe 可以规范化 你的很多 tech
即:如果你搞懂每个参数的含义的化
使用caffe 的时候,可以将前面的学习率为指定为 0,即不调整前面,只训练后面的一个分类器
|
|
对于超参数的一个角度
不是静止的而是触发式调整
|
即:learning rate 和 weight decay 都是超参数,
是可以动态调整出来的
一开始肯定 欠拟合,所以不必weight decay ,然后再去 decay
这个就是精细化 过程
其实:欠拟合 与 过拟合 是时间轴上的关系
|
| 一个跑前的技巧 |
首先是小数据集(100张图片等) ,准确率应该收敛到100%
如果到不了 100%,那么网络是有问题的
# 注:这个是没有的正则化 和 dropout 的情况,因为正则化是其到不了100%的
|
| tensor flow |
比 caffe 强在:即 多机器上的GPU 它也可以用, 即分布式训练
而这个 caffe 是不能用到多服务器上的GPU的 ,它可以用一台机器上的多个GPU
|
| 关于中间过程可视化 |
1. 对于隐层的可视化
 2. 对于 每一个 epoch 的可视化
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号