
Hadoop学习笔记
1 气象数据导入
上ftp://ftp.ncdc.noaa.gov下载,下载下来的目录结构:
每下个文件夹存放了每一年所有气象台的气象数据:
每一个文件就是一个气象站一年的数据
将上面目录上传到Linux中:
编写以下Shell脚本,将每一年的所有不现气象站所产生的文件合并成一个文件,即每年只有一个文件,并上传到Hadoop系统中:
#!/bin/bash
#将Hadoop权威指南气像数据按每一年合并成一个文件,并上传到Hadoop系统中
rm -rf /root/ncdc/all/*
/root/hadoop-1.2.1/bin/hadoop fs -rm -r /ncdc/all/*
#这里的/*/*中第一个*表示年份文件夹,其下面存放的就是每年不同气象站的气象文件
for file in /root/ncdc/raw/*/*
do
echo "追加$file.."
path=`dirname $file`
target=${path##*/}
gunzip -c $file >> /root/ncdc/all/$target.all
done
for file in /root/ncdc/all/*
do
echo "上传$file.."
/root/hadoop-1.2.1/bin/hadoop fs -put $file /ncdc/all
done
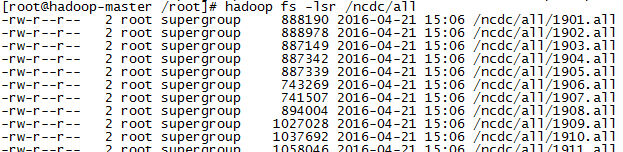
脚本运行完后,HDFS上的文件如下:
2 Mapper、Reducer类
每个Mapper都需要继承org.apache.hadoop.mapreduce.Mapper类,需重写其map方法:
protectedvoid map(KEYIN key, VALUEIN value, Context context)
每个Reducer都需要继承org.apache.hadoop.mapreduce.Reducer类,需重写其
protectedvoid reduce(KEYIN key, Iterable<VALUEIN> values, Context context )
publicclassMapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT//Map父类中的方法定义如下
/**
* Called once at the beginning of the task.在任务开始执行前会执行一次
*/
protectedvoid setup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.会被run()方法循环调用,每对键值都会被调用一次
*/
@SuppressWarnings("unchecked")
protectedvoid map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);//map()方法提供了默认实现,即直接输出,不做处理
}
/**
* Called once at the end of the task.任务结束后会调用一次
*/
protectedvoid cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.map()方法实质上就是被run()循环调用的,我们可以重写这个方法,加一些处理逻辑
*/
publicvoid run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {//每对键值对都会调用一次map()方法
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
}
publicclassReducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
/**
* Called once at the start of the task.在任务开始执行前会执行一次
*/
protectedvoid setup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* This method is called once for each key. Most applications will define
* their reduce class by overriding this method. The default implementation
* is an identity function.reduce()方法会被run()循环调用
*/
@SuppressWarnings("unchecked")
protectedvoid reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);//提供了默认实现,不做处理直接输出
}
}
/**
* Called once at the end of the task.任务结束后会调用一次
*/
protectedvoid cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Advanced application writers can use the
* {@link #run(org.apache.hadoop.mapreduce.Reducer.Context)} method to
* control how the reduce task works.
*/
publicvoid run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKey()) {//每键值对都会调用一次reduce()
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iterinstanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
}
Reducer的reduce方法每执行完一次,就会产生一个结果文件
reduce方法的输入类型必须匹配map方法的输出类型
map的输出文件名为 part-m-nnnnn ,而reduce的输出文件名为 part-r-nnnnn (nnnnn为分区号,即该文件存放的是哪个分区的数据,从0开始),其中part文件名可以修改
publicclass Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {,Mapper类有4个范型参数:
KEYIN:Map Key输入类型,如果输入是文本文件,固定为LongWritable,表示每一行文本所在文件的起始位置,从0开始(即第一行起始为位置为0)
publicvoid map(Object key, Text value, Context context)
throws IOException, InterruptedException {
System.out.println("key=" + key + "; value=" + value);
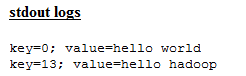
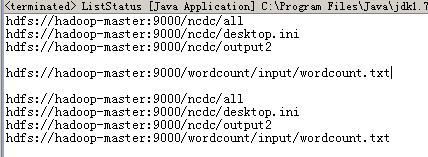
[root@hadoop-master /root]# hadoop fs -get /wordcount/input/wordcount /root/wordcount
换行显示 $('\n'),Tab字符显示^I,^M 是'\r', 回车符
[root@hadoop-master /root]# cat -A /root/wordcount
hello world^M$
hello hadoop
VALUEIN:Map value输入类型,如果输入是文本文件,则一般为Text,表示文本文件中读取到的一行内容(注:Map是以行为单位进行处理的,即每跑一次Map,即处理一行文本,即输入也是以行为单位进行输入的)
KEYOUT, VALUEOUT:为Reduce输出Key与输出Value的类型
3 找最高气温

//文本文件是按照一行一行传输到Mapper中的
publicclass MaxTemperatureMapper
extends Mapper<LongWritable/*输入键类型:行的起始位置,从0开始*/, Text/*输入值类型:为文本的一行内容*/, Text/*输出键类型:年份*/, IntWritable/*输出值类型:气温*/> {
privatestaticfinalintMISSING = 9999;
@Override
publicvoid map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);//取年份
int airTemperature;
if (line.charAt(87) == '+') { //如果温度值前有加号时,去掉,因为parseInt不支持加号
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);//空气质量
//如果是有效天气,则输出
if (airTemperature != MISSING && quality.matches("[01459]")) {
//每执行一次map方法,可能会输出多个键值对,但这里只输出一次,这些输出合并后传递给reduce作用输入
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
publicclass MaxTemperatureReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
//reduce的输入即为Map的输出,这里的输入值为一个集合,Map输出后会将相同Key的值合并成一个数组后
//再传递给reduce,所以值类型为Iterable
publicvoid reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
//write出去的结果会写入到输出结果文件
context.write(key, new IntWritable(maxValue));
}
}
publicclass MaxTemperature {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "weather");
// 根据设置的calss找到它所在的JAR任务包,而不需要明确指定JAR文件名
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
//设置map与reduce的输出类型,一般它们的输出类型都相同,如果不同,则map可以使用setMapOutputKeyClass、setMapOutputValueClass来设置
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// addInputPath除了支持文件、目录,还可以使用文件通匹符?
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all/1901.all"));
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all/1902.all"));
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all/1903.all"));
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all/1904.all"));
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all/1905.all"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/output2"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
MapReduce逻辑数据流:

4 JOB JAR运行
./hadoop jar /root/ncdc/weather.jar ch02.MaxTemperature
如果weather.jar包里的MANIFEST.MF 文件里指定了Main Class:
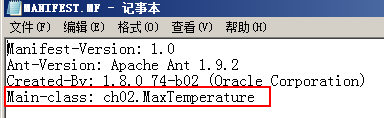
则运行时可以不用指定主类:
./hadoop jar /root/ncdc/weather.jar
hadoop2里可以这样执行:
./yarn jar /root/ncdc/weather.jar
如果在运行前指定了export HADOOP_CLASSPATH=/root/ncdc/weather.jar,如果设置了HADOOP_CLASSPATH应用程序类路径环境变量,则可以直接运行:
./hadoop MaxTemperature
./yarn MaxTemperature
以上都没有写输入输出文件夹,因为应用程序启动类里写了
5 数据流
map是移动算法而不是数据。在集群上,map任务(算法代码)会移动到数据节点Datanode(计算数据在哪就移动到哪台数据节点上),但reduce过程一般不能避免数据的移动(即不具备本地化数据的优势),单个reduce任务的输入通常来自于所有mapper的输出,因此map的输出会传输到运行reduce任务的节点上,数据在reduce端合并,然后执行用户自定义的reduce方法
reduce任务的完整数据流:
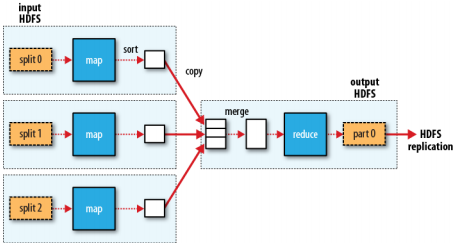
虚线表示节点,虚线箭头表示节点内部数据传输,实线箭头表示不同节点间的数据传输
有时,map任务(程序)所需要的三台机(假设配置的副本数据为3)正在处理其他的任务时,则Jobtracker就会在这三份副本所在机器的同一机架上找一台空亲的机器,这样数据只会在同一机架上的不同机器上进行传输,这样比起在不同机架之间的传输效率要高
数据与map程序可能在同一机器上,可能在同一机架上的不同机器上,还有可能是在不同机架上的不同机器上,即数据与map程序分布情况有以下三种:
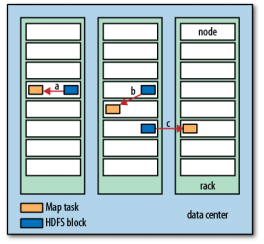
a(本地数据):同一机器,b(本地机架):同一机架上不同机器,c(跨机架):不同机架上不同机器。显然a这种情况下,执行效率是最高的
从上图来看,应该尽量让数据与map任务程序在一机器上,这就是为什么分片最大的大小与HDFS块大小相同,因为如果分片跨越多个数据块时,而这些块又不在同一机器上时,就需要将其他的块传输到map任务所在节点上,这本地数据相比,这种效率低
为了避免计算时不移动数据,TaskTracker是跑在DataName上的
reduce的数量并不是由输入数据大小决定的,而是可以单独指定的
如果一个任务有很多个reduce任务,则每个map任务就需要对输出数据进行分区partition处理,即输入数据交给哪个reduce进行处理。每个reduce需要建立一个分区,每个分区就对应一个reduce,默认的分区算法是根据输出的键哈希法:Key的哈希值 MOD Reduce数量),等到分区号,分区号 小于等于 Reduce数量的整数,从0开始。比如有3个reduce任务,则会分成三个分区。
分区算法也是可以自定义的
在map与reduce之间,还有一个shuffle过程:包括分区、排序、合并
多reduce任务数据流:
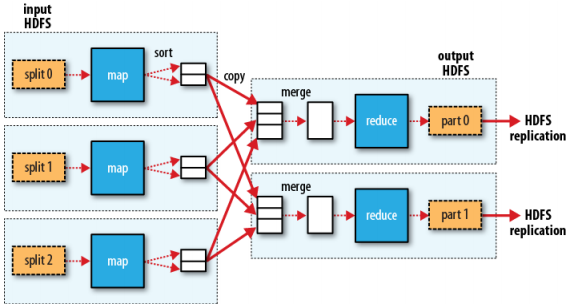
一个Map输出数据可能输出到不同的reduce,一个reduce的输入也可能来自不同的map输出
一个作业可以没有reduce任务,即无shuffle过程
Hadoop将作业分成若干个小任务进行执行,其中包括两类任务:map任务与reduce任务。
有两类节点控制着任务的执行:一个JobTracker,与若干TaskTracker,JobTracker相当于NameNode的,是用来管理、调度TaskTracker,TaskTracker相当于DataName,需要将任务执行状态报告给JobTracker。
Hadoop将MapReduce的输入数据划分成等长的小数据块,称为输入分片——input split。
每个分片构建一个map任务,一个map任务就是我们继承Mapper并重写的map方法
数据分片,可以多个map任务进行并发处理,这样就会缩短整个计算时间,并且分片可以很好的解决负载均衡问题,分片越细(小),则负载均衡越高,但分片太小需要建造很多的小的任务,这样可能会影响整个执行时间,所以,一个合理的分片大小为HDFS块的大小,默认为64M
map任务将其输出结果直接写到本地硬盘上,而不是HDFS中,这是因为map任务输出的是中间结果,该输出传递给reduce任务处理后,就可以删除了,所以没有必要存储在HDFS上
6 combiner
可以为map输出指定一个combiner(就像map通过分区输出到reduce一样),combiner函数的输出作为reduce的输入。
combiner属于优化,无法确定map输出要调用combiner多少次,有可能是0、1、多次,但不管调用多少次,reduce的输出结果都是一样的
假设1950年的气象数据很大,map前被分成了两片,这样1950的数据就会由两个map任务去执行,假设第一个map输出为:
(1950, 0)
(1950, 20)
(1950, 10)
第二个map任务输出为:
(1950, 25)
(1950, 15)
如果在没有使用combiner时,reducer的输入会是这样的:(1950, [0, 20, 10, 25, 15]),最后输入结果为:(1950, 25);为了减少map的数据输出,这里可以使用combiner函数对每个map的输出结果进行查找最高气温(第一个map任务最高为20,第二个map任务最高为25),这样一来,最后传递给reducer的输入数据为:(1950, [20, 25]),最后的计算结果也是(1950, 25),这一过程即为:
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
上面是找最高气温,并不是所有业务需求都具有此特性,如求平均气温时,就不适用combiner,如:
mean(0, 20, 10, 25, 15) = 14
但:
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15
combiner与reducer的计算逻辑是一样的,所以不需要重定义combiner类(如果输入类型与reducer不同,则需要重定义一个,但输入类型一定相同),而是在Job启动内中通过job.setCombinerClass(MaxTemperatureReducer.class);即可,即combiner与reducer是同一实现类
publicclass MaxTemperatureWithCombiner {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "weather");
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all/1950.all"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/output2"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在Map端,用户自定义实现的Combine优化机制类Combiner在执行Map端任务的节点本身运行,相当于对map函数的输出做了一次reduce。使用Combine机制的意义就在于使Map端输出更紧凑,使得写到本地磁盘和传给Reduce端的数据更少
Combiner通常被看作是一个Map端的本地reduce函数的实现类Reducer
选用Combine机制下的Combiner虽然减少了IO,但是等于多做了一次reduce,所以应该查看作业日志来判断combine函数的输出记录数是否明显少于输入记录的数量,以确定这种减少和花费额外的时间来运行Combiner相比是否值得
Combine优化机制执行时机
⑴ Map端spill的时候
在Map端内存缓冲区进行溢写的时候,数据会被划分成相应分区,后台线程在每个partition内按键进行内排序。这时如果指定了Combiner,并且溢写次数最少为 3(min.num.spills.for.combine属性的取值)时,Combiner就会在排序后输出文件写到磁盘之前运行。 ⑵ Map端merge的时候
在Map端写磁盘完毕前,这些中间的输出文件会合并成一个已分区且已排序的输出文件,按partition循环处理所有文件,合并会分多次,这个过程也会伴随着Combiner的运行。
⑶ Reduce端merge的时候
从Map端复制过来数据后,Reduce端在进行merge合并数据时也会调用Combiner来压缩数据。
Combine优化机制运行条件
⑴ 满足交换和结合律[10]
结合律:
(1)+(2+3)+(4+5+6)==(1+2)+(3+4)+(5)+(6)== ...
交换律:
1+2+3+4+5+6==2+4+6+1+2+3== ...
应用程序在满足如上的交换律和结合律的情况下,combine函数的执行才是正确的,因为求平均值问题是不满足结合律和交换律的,所以这类问题不能运用Combine优化机制来求解。
例如:mean(10,20,30,40,50)=30
但mean(mean(10,20),mean(30,40,50))=22.5
这时在求平均气温等类似问题的应用程序中使用Combine优化机制就会出错。
6.1 Hadoop2 NameNode元数据相关文件目录解析
下面所有的内容是针对Hadoop 2.x版本进行说明的,Hadoop 1.x和这里有点不一样。
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
[wyp@wyp hadoop-2.2.0]$ $HADOOP_HOME/bin/hdfs namenode -format
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构
current/
|-- VERSION
|-- edits_*
|-- fsimage_0000000000008547077
|-- fsimage_0000000000008547077.md5
|-- seen_txid
其中的dfs.namenode.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
hadoop.tmp.dir是在core-site.xml中配置的,默认值如下
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
dfs.namenode.name.dir属性可以配置多个目录,如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。
1、 VERSION文件是Java属性文件,内容大致如下:
#Fri Nov 15 19:47:46 CST 2013
namespaceID=934548976
clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196
cTime=0
storageType=NAME_NODE
blockpoolID=BP-893790215-192.168.24.72-1383809616115
layoutVersion=-47
其中
(1)、namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
(2)、storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
(3)、cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
(4)、layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
(5)、clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;如下说明
a、使用如下命令格式化一个Namenode:
$ $HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b、使用如下命令格式化其他Namenode:
$ $HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
c、升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$ $HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID。
(6)、blockpoolID:是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-893790215-192.168.24.72-1383809616115就是在我的ns1(NameNode节点)的namespace下的存储块池的ID,这个ID包括了 其对应的NameNode节点的ip地址。
2、 $dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、 $dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。fsimage和edits是Hadoop元数据相关的重要文件,请参考Hadoop文件系统元数据fsimage和编辑日志edits。
7 MapReduce输入输出类型
一般来说,map函数输入的健/值类型(K1和V1)不同于输出类型(K2和V2),虽然reduce函数的输入类型必须与map函数的输出类型相同,但reduce函数的输出类型(K3和V3)可以不同于输入类型
如果使用combine函数,它与reduce函数的形式相同(它也是Reducer的一个实现),不同之处是它的输出类型是中间的键/值对类型(K2和V2),这些中间值可以输入到reduce函数:
map: (K1, V1) → list(K2, V2)
combine: (K2, list(V2)) → list(K2, V2)
partition(K2, V2) → integer //将中间键值对分区,返回分区索引号。分区内的键会排序,相同的键的所有值会合并
reduce: (K2, list(V2)) → list(K3, V3)
上面是map、combine、reduce的输入输出格式,如map输入的是单独的一对key/value(值也是值);而combine与reduce的输入也是键值对,只不过它们的值不是单值,而是一个列表即多值;它们的输出都是一样,键值对列表;另外,reduce函数的输入类型必须与map函数的输出类型相同,所以都是K2与V2类型

job.setOutputKeyClass和job.setOutputValueClas在默认情况下是同时设置map阶段和reduce阶段的输出(包括Key与Value输出),也就是说只有map和reduce输出是一样的时候才会这样设置;当map和reduce输出类型不一样的时候就需要通过job.setMapOutputKeyClass和job.setMapOutputValueClas来单独对map阶段的输出进行设置,当使用job.setMapOutputKeyClass和job.setMapOutputValueClas后,setOutputKeyClass()与setOutputValueClas()此时则只对reduce输出设置有效了。
8 新旧API
1、新API倾向于使用抽像类,而不是接口,这样更容易扩展。在旧API中使用Mapper和Reducer接口,而在新API中使用抽像类
2、新API放在org.apache.hadoop.mapreduce包或其子包中,而旧API则是放在org.apache.hadoop.mapred中
3、新API充分使用上下文对象,使用户很好的与MapReduce交互。如,新的Context基本统一了旧API中的JobConf OutputCollector Reporter的功能,使用一个Context就可以搞定,易使用
4、新API允许mapper和reducer通过重写run()方法控制执行流程。如,即可以批处理键值对记录,也可以在处理完所有的记录之前停止。这在旧API中可以通过写MapRunnable类在mapper中实现上述功能,但在reducer中无法实现
5、新的API中作业是Job类实现,而非旧API中的JobClient类,新的API中删除了JobClient类
6、新API实现了配置的统一。旧API中的作业配置是通过JobConf完成的,它是Configuration的子类。在新API中,作业的配置由Configuration,或通过Job类中的一些辅助方法来完成配置
输出的文件命名方法稍有不同。在旧的API中map和reduce的输出被统一命名为 part-nnmm,但在新API中map的输出文件名为 part-m-nnnnn,而reduce的输出文件名为 part-r-nnnnn(nnnnn为分区号,即该文件存放的是哪个分区的数据,从0开始)其中part文件名可以修改
7、
8、新API中的可重写的用户方法抛出ava.lang.InterruptedException异常,这意味着可以使用代码来实现中断响应,从而可以中断那些长时间运行的作业
9、新API中,reduce()传递的值是java.lang.Iterable类型的,而非旧API中使用java.lang.Iterator类型,这就可以很容易的使用for-each循环结构来迭代这些值:for (VALUEIN value : values) { ... }
9 hadoop目录结构
9.1 hadoop1
存放的本地目录是可以通过hdfs-site.xml配置的:
hadoop1:
<property>
<name>dfs.name.dir</name>
<value>${hadoop.tmp.dir}/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
9.2 Hadoop文件系统元数据fsimage和编辑日志edits
在《Hadoop NameNode元数据相关文件目录解析》文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件:
current/
|-- VERSION
|-- edits_*
|-- fsimage_0000000000008547077
|-- fsimage_0000000000008547077.md5
`-- seen_txid
其中存在大量的以edits开头的文件和少量的以fsimage开头的文件。那么这两种文件到底是什么,有什么用?下面对这两中类型的文件进行详解。在进入下面的主题之前先来搞清楚edits和fsimage文件的概念:
(1)、fsimage文件其实是Hadoop文件系统元数据的一个永久性的检查点,其中包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;
(2)、edits文件存放的是Hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
fsimage和edits文件都是经过序列化的,在NameNode启动的时候,它会将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
NameNode起来之后,HDFS中的更新操作会重新写到edits文件中,因为fsimage文件一般都很大(GB级别的很常见),如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行的十分缓慢,但是如果往edits文件里面写就不会这样,每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。如果一个文件比较大,使得写操作需要向多台机器进行操作,只有当所有的写操作都执行完成之后,写操作才会返回成功,这样的好处是任何的操作都不会因为机器的故障而导致元数据的不同步。
fsimage包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;对于文件来说,包含的信息有修改时间、访问时间、块大小和组成一个文件块信息等;而对于目录来说,包含的信息主要有修改时间、访问控制权限等信息。fsimage并不包含DataNode的信息,而是包含DataNode上块的映射信息,并存放到内存中,当一个新的DataNode加入到集群中,DataNode都会向NameNode提供块的信息,而NameNode会定期的“索取”块的信息,以使得NameNode拥有最新的块映射。因为fsimage包含Hadoop文件系统中的所有目录和文件idnode的序列化信息,所以如果fsimage丢失或者损坏了,那么即使DataNode上有块的数据,但是我们没有文件到块的映射关系,我们也无法用DataNode上的数据!所以定期及时的备份fsimage和edits文件非常重要!
在前面我们也提到,文件系统客户端执行的所以写操作首先会被记录到edits文件中,那么久而久之,edits会非常的大,而NameNode在重启的时候需要执行edits文件中的各项操作,那么这样会导致NameNode启动的时候非常长!在下篇文章中我会谈到在Hadoop 1.x版本和Hadoop 2.x版本是怎么处理edits文件和fsimage文件的。
9.3 Hadoop 1.x中fsimage和edits合并实现
在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大;虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时候,NameNode先将fsimage里面的所有内容映像到内存中,然后再一条一条地执行edits中的记录,当edits文件非常大的时候,会导致NameNode启动操作非常地慢,而在这段时间内HDFS系统处于安全模式,这显然不是用户要求的。能不能在NameNode运行的时候使得edits文件变小一些呢?其实是可以的,本文主要是针对Hadoop 1.x版本,说明其是怎么将edits和fsimage文件合并的,Hadoop 2.x版本edits和fsimage文件合并是不同的。
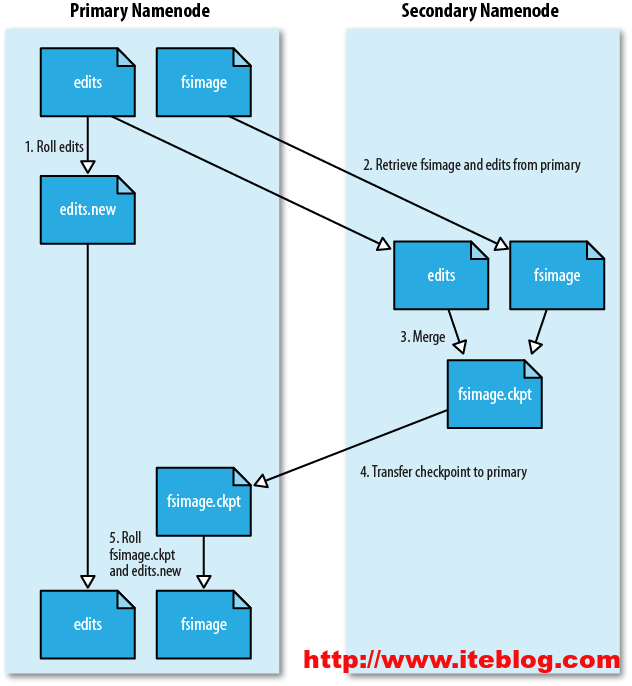
用过Hadoop的用户应该都知道在Hadoop里面有个SecondaryNamenode进程,从名字看来大家很容易将它当作NameNode的热备进程。其实真实的情况不是这样的。SecondaryNamenode是HDFS架构中的一个组成部分,它是用来保存namenode中对HDFS metadata的信息的备份,并减少namenode重启的时间而设定的!一般都是将SecondaryNamenode单独运行在一台机器上,那么SecondaryNamenode是如何减少namenode重启的时间的呢?来看看SecondaryNamenode的工作情况:
(1)、SecondaryNamenode会定期的和NameNode通信,请求其停止使用edits文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)、SecondaryNamenode通过HTTP GET方式从NameNode上获取到fsimage和edits文件,并下载到本地的相应目录下;
(3)、SecondaryNamenode将下载下来的fsimage载入到内存,然后一条一条地执行edits文件中的各项更新操作,使得内存中的fsimage保存最新;这个过程就是edits和fsimage文件合并;
(4)、SecondaryNamenode执行完(3)操作之后,会通过post方式将新的fsimage文件发送到NameNode节点上
(5)、NameNode将从SecondaryNamenode接收到的新的fsimage替换旧的fsimage文件,同时将edit.new替换edits文件,通过这个过程edits就变小了!整个过程的执行可以通过下面的图说明:


在(1)步骤中,我们谈到SecondaryNamenode会定期的和NameNode通信,这个是需要配置的,可以通过core-site.xml进行配置,下面是默认的配置:
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
其实如果当fs.checkpoint.period配置的时间还没有到期,我们也可以通过判断当前的edits大小来触发一次合并的操作,可以通过下面配置:
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>
当edits文件大小超过以上配置,即使fs.checkpoint.period还没到,也会进行一次合并。顺便说说SecondaryNamenode下载下来的fsimage和edits暂时存放的路径可以通过下面的属性进行配置:
<property>
<name>fs.checkpoint.dir</name>
<value>${hadoop.tmp.dir}/dfs/namesecondary</value>
<description>Determines where on the local filesystem the DFS secondary
name node should store the temporary images to merge.
If this is a comma-delimited list of directories then the image is
replicated in all of the directories for redundancy.
</description>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>${fs.checkpoint.dir}</value>
<description>Determines where on the local filesystem the DFS secondary
name node should store the temporary edits to merge.
If this is a comma-delimited list of directoires then teh edits is
replicated in all of the directoires for redundancy.
Default value is same as fs.checkpoint.dir
</description>
</property>
从上面的描述我们可以看出,SecondaryNamenode根本就不是Namenode的一个热备,其只是将fsimage和edits合并。其拥有的fsimage不是最新的,因为在他从NameNode下载fsimage和edits文件时候,新的更新操作已经写到edit.new文件中去了。而这些更新在SecondaryNamenode是没有同步到的!当然,如果NameNode中的fsimage真的出问题了,还是可以用SecondaryNamenode中的fsimage替换一下NameNode上的fsimage,虽然已经不是最新的fsimage,但是我们可以将损失减小到最少!
在Hadoop 2.x通过配置JournalNode来实现Hadoop的高可用性,可以参见《Hadoop2.2.0中HDFS的高可用性实现原理》,这样主被NameNode上的fsimage和edits都是最新的,任何时候只要有一台NameNode挂了,也可以使得集群中的fsimage是最新状态!关于Hadoop 2.x是如何合并fsimage和edits的,可以参考《Hadoop 2.x中fsimage和edits合并实现》
9.4 Hadoop 2.x中fsimage和edits合并实现
在《Hadoop 1.x中fsimage和edits合并实现》文章中,我们谈到了Hadoop 1.x上的fsimage和edits合并实现,里面也提到了Hadoop 2.x版本的fsimage和edits合并实现和Hadoop 1.x完全不一样,今天就来谈谈Hadoop 2.x中fsimage和edits合并的实现。
我们知道,在Hadoop 2.x中解决了NameNode的单点故障问题;同时SecondaryName已经不用了,而之前的Hadoop 1.x中是通过SecondaryName来合并fsimage和edits以此来减小edits文件的大小,从而减少NameNode重启的时间。而在Hadoop 2.x中已经不用SecondaryName,那它是怎么来实现fsimage和edits合并的呢?首先我们得知道,在Hadoop 2.x中提供了HA机制(解决NameNode单点故障),可以通过配置奇数个JournalNode来实现HA,如何配置今天就不谈了!HA机制通过在同一个集群中运行两个NN(active NN & standby NN)来解决NameNode的单点故障,在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改(如增删文件),它需要持久化到一半(由于JournalNode最少为三台奇数台,所以最少要存储到其中两台上)以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态(更多的关于Hadoop 2.x的HA相关知识,可以参考本博客的《Hadoop2.2.0中HDFS的高可用性实现原理》)。
那么这种机制是如何实现fsimage和edits的合并?在standby NameNode节点上会一直运行一个叫做CheckpointerThread的线程,这个线程调用StandbyCheckpointer类的doWork()函数,而doWork函数会每隔Math.min(checkpointCheckPeriod, checkpointPeriod)秒来做一次合并操作,相关代码如下:
try {
Thread.sleep(1000 * checkpointConf.getCheckPeriod());
} catch (InterruptedException ie) {}
publiclong getCheckPeriod() {
return Math.min(checkpointCheckPeriod, checkpointPeriod);
}
checkpointCheckPeriod = conf.getLong(DFS_NAMENODE_CHECKPOINT_CHECK_PERIOD_KEY,
DFS_NAMENODE_CHECKPOINT_CHECK_PERIOD_DEFAULT);
checkpointPeriod = conf.getLong(DFS_NAMENODE_CHECKPOINT_PERIOD_KEY,
DFS_NAMENODE_CHECKPOINT_PERIOD_DEFAULT);
上面的checkpointCheckPeriod和checkpointPeriod变量是通过获取hdfs-site.xml以下两个属性的值得到:
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>The SecondaryNameNode and CheckpointNode will poll the NameNode
every 'dfs.namenode.checkpoint.check.period' seconds to query the number
of uncheckpointed transactions.
</description>
</property>
当达到下面两个条件的情况下,将会执行一次checkpoint:
boolean needCheckpoint = false;
if (uncheckpointed >= checkpointConf.getTxnCount()) {
LOG.info("Triggering checkpoint because there have been " +
uncheckpointed + " txns since the last checkpoint, which " +
"exceeds the configured threshold " +
checkpointConf.getTxnCount());
needCheckpoint = true;
} else if (secsSinceLast >= checkpointConf.getPeriod()) {
LOG.info("Triggering checkpoint because it has been " +
secsSinceLast + " seconds since the last checkpoint, which " +
"exceeds the configured interval " + checkpointConf.getPeriod());
needCheckpoint = true;
}
当上述needCheckpoint被设置成true的时候,StandbyCheckpointer类的doWork()函数将会调用doCheckpoint()函数正式处理checkpoint。当fsimage和edits的合并完成之后,它将会把合并后的fsimage上传到Active NameNode节点上,Active NameNode节点下载完合并后的fsimage,再将旧的fsimage删掉(Active NameNode上的)同时清除旧的edits文件。步骤可以归类如下:
(1)、配置好HA后,客户端所有的更新操作将会写到JournalNodes节点的共享目录中,可以通过下面配置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://XXXX/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export1/hadoop2x/dfs/journal</value>
</property>
(2)、Active
Namenode和Standby
NameNode从JournalNodes的edits共享目录中同步edits到自己edits目录中;
(3)、Standby NameNode中的StandbyCheckpointer类会定期的检查合并的条件是否成立,如果成立会合并fsimage和edits文件;
(4)、Standby NameNode中的StandbyCheckpointer类合并完之后,将合并之后的fsimage上传到Active NameNode相应目录中;
(5)、Active NameNode接到最新的fsimage文件之后,将旧的fsimage和edits文件清理掉;
(6)、通过上面的几步,fsimage和edits文件就完成了合并,由于HA机制,会使得Standby NameNode和Active NameNode都拥有最新的fsimage和edits文件(之前Hadoop 1.x的SecondaryNameNode中的fsimage和edits不是最新的)
9.5 Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
(1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
(2)、在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个NN(active NN & standby NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集群中,通常有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半(奇数个,一般为3,所以需要持久到2台)以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,Standby NN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的DataNode将配置好Active NN和Standby NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
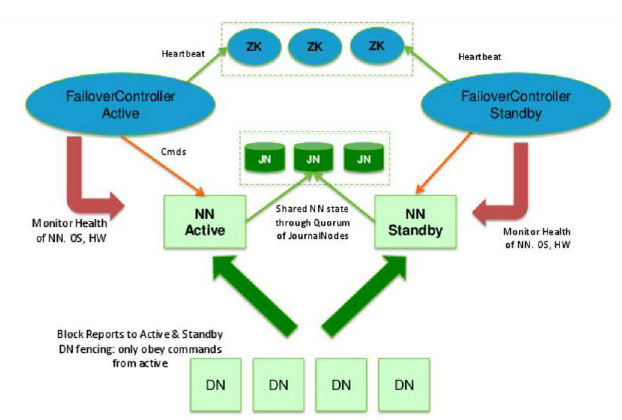
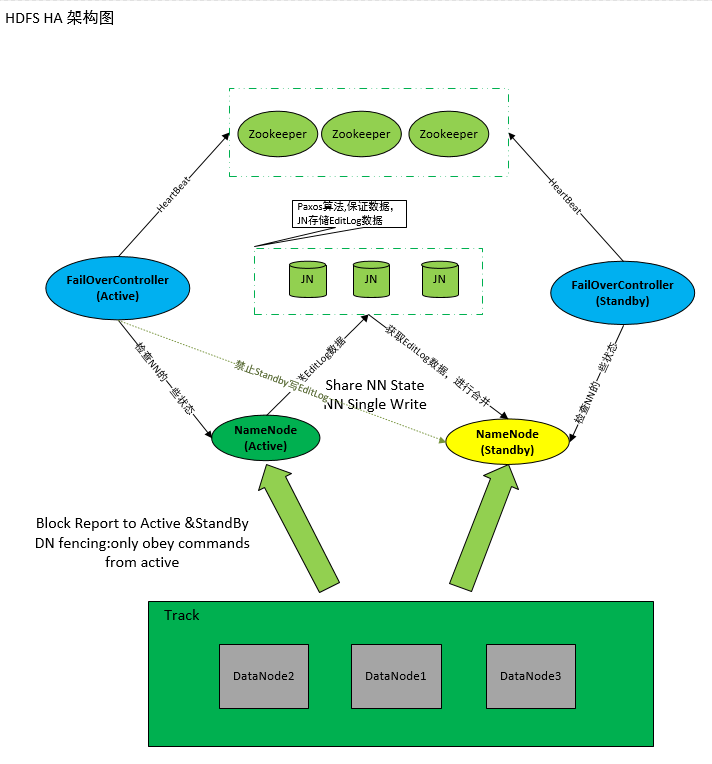
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态。
为了部署HA集群,你需要准备以下事项:
(1)、NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以与其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
10 命令
hadoop fs –help
% hadoop fs -copyFromLocal /input/docs/quangle.txt quangle.txt 将本地文件复制到HDFS中,目的地为相对地址,相对的是HDFS上的/user/root目录,root为用户,不同的用户执行,则不同
hadoop fs -copyToLocal quangle.txt quangle.copy.txt 从HDFS中下载文件到本地
% hadoop fs -mkdir books
% hadoop fs -ls .
Found 2 items
drwxr-xr-x - tom supergroup 0 2009-04-02 22:41 /user/tom/books
-rw-r--r-- 1 tom supergroup 118 2009-04-02 22:29 /user/tom/quangle.txt
第一列为文件模式,第二列文件的副本数,如果目录则没有;第三、四列表示文件的所属用户和用户组;第五列为文件大小,目录没有。
一个文件的执行权限X没有什么意义,因为你不可能在HDFS系统时执行一个文件,但它对目录是有用的,因为在访问一个目录的子项时是不需要此种权限的
11 HDFS:Hadoop Distributed Filesystem
处理超大的文件:一个文件可以是几百M,甚至是TB级文件
流式数据访问:一次写入,多次读取
廉价的机器
不适用于低延迟数据访问,如果需要可以使用Hbase
不适用于大量的小文件,因为每个文件存储在DFS中时,都会在NameNode上保存文件的元数据信息,这会会急速加太NameNode节点的内存占用,目前每个文件的元数据信息大概占用150字节,如果有一百万个文件,则要占用300MB的内存
不支持并发写,并且也不支持文件任意位置的写入,只能一个用户写在文件最末
11.1 块
默认块大小为64M,如果某个文件不足64,则不会占64,而是文件本身文件大小,这与操作系统文件最小存储单元块不同
分块存储的好处:
一个文件的大小可以大于网络中的任意一个硬盘的容量,如果不分块,则不能存储在硬盘中,当分块后,就可以将这个大文件分块存储到集群中的不同硬盘中
分块后适合多副本数据备份,保证了数据的安全
可以通过以下命令查看块信息:
hadoop fsck / -files -blocks
11.2 namenode、datanode
一个namenode(管理者),多个datanode(工作者,存放数据)
namenode管理文件系统的命名空间,它维护着文件系统树及整个树里的文件和目录,这些系统以两个文件持久化硬盘上永久保存着:命名空间镜像文件fsimage和编辑日志文件edits
namenode记录了每个文件中各个块所在的datanode信息,但它并不将这些位置信息持久化硬盘上,因为这些信息会在系统启动时由datanode上报给namenode节点后重建
如果在没有任何备份,namenode如果坏了,则整个文件系统将无法使用,所以就有了secondnamenode辅助节点:
secondnamenode除了备份namenode上的元数据持久信息外,最主要的作用是定期的将namenode上的fsimage、edits两个文件拷贝过来进行合并后,将传回给namenode。secondnamenode的备份并非namenode上所有信息的完全备份,它所保存的信息就是滞后于namenode的,所以namenode坏掉后,尽管可以手动从secondnamenode恢复,但也难免丢失部分数据(最近一次合并到当前时间内所做的数据操作)
11.3 联邦HDFS
由于1.X只能有一个namenode,随着文件越来越多,namenode的内存就会受到限制,到某个时候肯定是存放不了更多的文件了(虽然datanode可以加入新的datanode可以解决存储容量问题),不可以无限在一台机器上加内存。在2.X版本中,引入了联邦HDFS允许系统通过添加namenode进行扩展,这样每个namenode管理着文件系统命名空间的一部分元数据信息
11.4 HDFS高可用性
联邦HDFS只解决了内存数据扩展的问题,但并没有解决namenode单节点问题,即当某个namenode坏掉所,由于namenode没有备用,所以一旦毁坏后还是会导致文件系统无法使用。
HDFS高可用性包括:水平扩展namenode以实现内存扩展、高安全(坏掉还有其他备用的节点)及热切换(坏掉后无需手动切换到备用节点)到备用机
在2.x中增加了高可用性支持,通过活动、备用两台namenode来实现,当活动namenode失效后,备用namenode就会接管安的任务并开始服务于来自客户端的请求,不会有任何明显中断服务,这需要架构如下:
n Namenode之间(活动的与备用的两个节点)之间需要通过共享存储编辑日志文件edits,即这edits文件放在一个两台机器都能访问得到的地方存储,当活动的namenode毁坏后,备用namenode自动切换为活动时,备用机将edits文件恢复备用机内存
n Datanode需要现时向两个namenode发送数据块处理报告
n 客户端不能直接访问某个namenode了,因为一旦某个出问题后,就需要通过另一备用节点来访问,这需要用户对namenode访问是透明的,不能直接访问namenode,而是通过管理这些namenode集群入口地址透明访问
在活动namenode失效后,备用namenode能够快速(几十秒的时间)实现任务接管,因为最新的状态存储在内存中:包括最新的编辑日志和最新的数据块映射信息
备用切换是通过failover_controller故障转移控制器来完成的,故障转移控制器是基于ZooKeeper实现的;每个namenode节点上都运行着一个轻量级的故障转移控制器,它的工作就是监视宿主namenode是否失效(通过一个简单的心跳机制实现)并在namenode失效时进行故障切换;用户也可以在namenode没有失效的情况下手动发起切换,例如在进行日常维护时;另外,有时无法确切知道失效的namenode是否已经停止运行,例如在网络异常情况下,同样也可能激发故障转换,但先前的活动着的namenode依然运行着并且依旧是活动的namenode,这会出现其他问题,但高可用实现做了“规避”措施,如杀死行前的namenode进程,收回访问共享存储目录的权限等
伪分布式: fs.default.name=hdfs://localhost:8020;dfs.replication=1,如果设置为3,将会持续收到块副本不中的警告,设置这个属性后就不会再有问题了
11.5 Hadoop文件系统JAVA接口
Hadoop本身是由Java编写的
11.5.1 FileSystem继承图
org.apache.hadoop.fs.FileSystem是文件系统的抽象类,常见有以下实现类:
|
文件系统 |
URI scheme |
Java实现类 |
描述 |
|
Local |
file |
org.apache.hadoop.fs.LocalFileSystem |
使用了客户端校验和的本地文件系统(未使用校验和的本地文件系统请使用RawLocalFileSystem) |
|
HDFS |
hdfs |
org.apache.hadoop.hdfs.DistributedFileSystem |
Hadoop分布式文件系统 |
|
HFTP |
hftp |
org.apache.hadoop.hdfs.HftpFileSystem |
通过Http对Hdfs进行只读访问的文件系统,用于实现不同版本HDFS集群间的数据复制 |
|
HSFTP |
hsftp |
org.apache.hadoop.hdfs.HsftpFileSystem |
同上,只是https协议 |
|
|
|
org.apache.hadoop. |
|
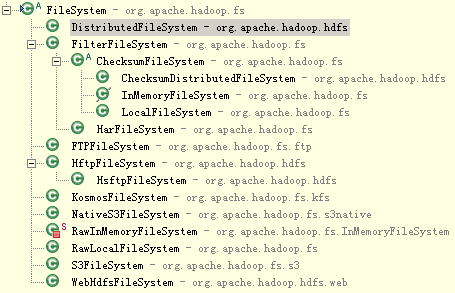
11.5.2 读取数据
获取FileSystem实例有以下几个静态方法:
publicstatic FileSystem get(Configuration conf) throws IOException//获取core-sit.xml中fs.default.name配置属性所配置的URI来返回相应的文件系统,由于core-sit.xml已配置,所以一般调用这个方法即可
publicstatic FileSystem get(URI uri, Configuration conf) throws IOException//根据uri参数里提供scheme信息返回相应的文件系统,即hdfs://hadoop-master:9000,则返回的是hdfs文件系统
publicstatic FileSystem get(URI uri, Configuration conf, String user) throws IOException
有了FileSystem后,就可以调用open()方法获取文件输入流:
public FSDataInputStream open(Path f) throws IOException //默认缓冲4K
publicabstract FSDataInputStream open(Path f, int bufferSize) throws IOException
示例:将hdfs文件系统中的文件内容在标准输出显示
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
publicclass FileSystemCat {
publicstaticvoid main(String[] args) throws Exception {
// 如果为默认端口8020,则可以省略端口
String uri = "hdfs://hadoop-master:9000/wordcount/input/wordcount.txt";
Configuration conf = new Configuration();
// FileSystem fs = FileSystem.get(URI.create(uri), conf);
// 因为get方法的URI参数只需要URI scheme,所以只需指定服务地址即可,无需同具体到某个文件
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
//或者这样使用
// conf.set("fs.default.name", "hdfs://hadoop-master:9000");
// FileSystem fs = FileSystem.get(conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false); //无需使用循环对流进行拷贝,借助于工具类IOUtils即可
} finally {
IOUtils.closeStream(in);//不直接调用输入输出流的close方法,而是使用IOUtils工具类
}
}
}
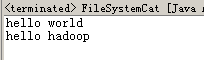
实际上,FileSystem的open方法返回的是FSDataInputStream类型的对象,而非Java标准输入流,这个类继承了标准输入流DataInputStream:
publicclassFSDataInputStreamextends DataInputStream
implements Seekable, PositionedReadable, Closeable, HasFileDescriptor {
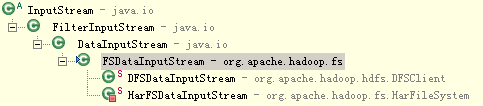
并且FSDataInputStream类实现了Seekable接口,支持随机访问,因此可以从流的任意位置读取数据。
Seekable接口支持在文件中找到指定的位置,并提供了一个查询当前位置相当于文件起始位置偏移量的方法getPos():
publicinterfaceSeekable {
// 定位到文件指定的位置,与标准输入流的InputStream.skip不同的是,seek可以定位到文件中的任意绝对位置,而
// skip只能相对于当前位置才能定位到新的位置。这里会传递的是相对于文件开头的绝对位置,不能超过文件长度。注:seek开销很高,谨慎调用
void seek(long pos) throws IOException;
// 返回当前相对于文件开头的偏移量
long getPos() throws IOException;
boolean seekToNewSource(long targetPos) throws IOException;
}
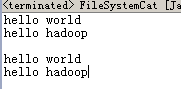
示例:改写上面实例,让它输出两次
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
publicclass FileSystemCat {
publicstaticvoid main(String[] args) throws Exception {
String uri = "hdfs://hadoop-master:9000/wordcount/input/wordcount.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
System.out.println("\n");
in.seek(0);//跳到文件的开头
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
FSDataInputStream类还实现了PositionedReadable接口,这可以从一个指定的偏移量处读取文件的一部分:
publicinterfacePositionedReadable {
// 从文件指定的position处读取最多length字节的数据并存入缓冲区buffer的指定偏移量offset处,返回的值是
// 实际读取到的字节数:调用者需要检查这个值,有可能小于参数length
publicint read(long position, byte[] buffer, int offset, int length) throws IOException;
// 与上面方法相当,只是如果读取到文件最末时,被读取的字节数可能不满length,此时则会抛异常
publicvoid readFully(long position, byte[] buffer, int offset, int length) throws IOException;
// 与上面方法相当,只是每次读取的字节数为buffer.length
publicvoid readFully(long position, byte[] buffer) throws IOException;
}
注:上面这些方法都不会修改当前所在文件偏移量
11.5.3 写入数据
FileSystem类有一系列参数不同的create创建文件方法,最简单的方法:
publicFSDataOutputStreamcreate(Path f) throws IOException {
还有一系列不同参数的重载方法,他们最终都是调用下面这个抽象方法实现的:
publicabstract FSDataOutputStream create(Path f,
FsPermission permission, //权限
boolean overwrite, //如果文件存在,传false时会抛异常,否则覆盖已存在的文件
int bufferSize, //缓冲区的大小
short replication, //副本数量
long blockSize, //块大小
Progressable progress) throws IOException; //处理进度的回调接口
一般调用简单方法时,如果文件存在,则是会覆盖,如果不想覆盖,可以指定overwrite参数为false,或者使用FileSystem类的exists(Path f)方法进行判断:
publicbooleanexists(Path f) throws IOException {//可以用来测试文件或文件夹是否存在
进度回调接口,当数据每次写完缓冲数据后,就会回调该接口显示进度信息:
package org.apache.hadoop.util;
publicinterface Progressable {
publicvoid progress();//返回处理进度给Hadoop应用框架
}
另一种新建文件的方法是使用append方法在一个已有文件末尾追加数据(该方法也有一些重载版本):
public FSDataOutputStream append(Path f) throws IOException {
示例:带进度的文件上传
publicclass FileCopyWithProgress {
publicstaticvoid main(String[] args) throws Exception {
InputStream in = new BufferedInputStream(new FileInputStream("d://1901.all"));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
OutputStream out = fs.create(new Path("hdfs://hadoop-master:9000/ncdc/all/1901.all"), new Progressable() {
publicvoid progress() {
System.out.print(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}
像FSDataInputStream 一样,FSDataOutputStream类也有一个getPos方法,用来查询当前位置,但与FSDataInputStream不同的是,不允许在文件中定位,这是因为HDFS只允许对一个已打开的文件顺序写入,或在现有文件的末尾追加数据,安不支持在除文件末尾之外的其他位置进行写入,所以就没有seek定位方法了
11.5.4 上传本地文件
publicvoid copyFromLocalFile(Path src, Path dst)
publicvoid copyFromLocalFile(boolean delSrc, Path src, Path dst)
publicvoid copyFromLocalFile(boolean delSrc, boolean overwrite,Path[] srcs, Path dst)
publicvoid copyFromLocalFile(boolean delSrc, boolean overwrite,Path src, Path dst)
delSrc - whether to delete the src是否删除源文件
overwrite - whether to overwrite an existing file是否覆盖已存在的文件
srcs - array of paths which are source 可以上传多个文件数组方式
dst – path 目标路径,如果存在,且都是目录的话,会将文件存入它下面,并且上传文件名不变;如果不存在,则会创建并认为它是文件,即上传的文件名最终会成为dst指定的文件名
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://hadoop-master:9000");
FileSystem fs = FileSystem.get(conf);
fs.copyFromLocalFile(new Path("c:/t_stud.txt"), new Path("hdfs://hadoop-master:9000/db1/output1"));
11.5.5 重命名或移动文件
fileSystem.rename(src, dst);
形为重命名,实际上该方法还可以移动文件,与上传目的地dst参数一样:如果dst为存在的目录,则会放在它下面;如果不存在,则会创建并认为它是文件,即上传的文件名最终会成为dst指定的文件名
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://hadoop-master:9000");
FileSystem fs = FileSystem.get(conf);
fs.rename(new Path("hdfs://hadoop-master:9000/db1/output2"), new Path("hdfs://hadoop-master:9000/db3/output2"));
11.5.6 删除文件目录
FileSystem的delete()方法可以用来删除文件或目录
publicabstractboolean delete(Path f, boolean recursive) throws IOException;
如果f是一个文件或空目录,那么recursive的值就会被忽略。只有在recursive值为true时,非空目录及其内容才会被删除(如果删除非空目录时recursive为false,则会抛IOException异常?)
11.5.7 创建目录
FileSystem提供了创建目录的方法:
publicbooleanmkdirs(Path f) throws IOException {
如果父目录不存在,则也会自动创建,并返回是否成功
通常情况下,我们不需要调用这个方法创建目录,因为调用create方法创建文件时,如果父目录不存在,则会自动创建
11.5.8 查看目录及文件信息
FileStatus类封装了文件系统中的文件和目录的元数据,包括文件长度、大小、副本数、修改时间、所有者、权限等
FileSystem的getFileStatus方法可以获取FileStatus对象:
publicabstract FileStatus getFileStatus(Path f) throws IOException;
示例:获取文件(夹)状态信息
publicclass ShowFileStatus {
publicstaticvoid main(String[] args) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
OutputStream out = fs.create(new Path("/dir/file"));
out.write("content".getBytes("UTF-8"));
//out.close();
IOUtils.closeStream(out);
// 文件的状态信息
Path file = new Path("/dir/file");
FileStatus stat = fs.getFileStatus(file);
System.out.println(stat.getPath().toUri().getPath());
System.out.println(stat.isDir());//是否文件夹
System.out.println(stat.getLen());//文件大小
System.out.println(stat.getModificationTime());//文件修改时间
System.out.println(stat.getReplication());//副本数
System.out.println(stat.getBlockSize());//文件系统所使用的块大小
System.out.println(stat.getOwner());//文件所有者
System.out.println(stat.getGroup());//文件所有者所在组
System.out.println(stat.getPermission().toString());//文件权限
System.out.println();
// 目录的状态信息
Path dir = new Path("/dir");
stat = fs.getFileStatus(dir);
System.out.println(stat.getPath().toUri().getPath());
System.out.println(stat.isDir());
System.out.println(stat.getLen());//文件夹为0
System.out.println(stat.getModificationTime());
System.out.println(stat.getReplication());//文件夹为0
System.out.println(stat.getBlockSize());//文件夹为0
System.out.println(stat.getOwner());
System.out.println(stat.getGroup());
System.out.println(stat.getPermission().toString());
}
}

11.5.9 列出文件(状态)
除了上面FileSystem的getFileStatus一次只能获取一个文件或目录的状态信息外,FileSystem还可以一次获取多个文件的FileStatus或目录下的所有文件的FileStatus,这可以调用FileSystem的listStatus方法,该方法有以下重载版本:
publicabstract FileStatus[] listStatus(Path f) throws IOException;
public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException {
public FileStatus[] listStatus(Path[] files) throws IOException {
public FileStatus[] listStatus(Path[] files, PathFilter filter) throws IOException {
当传入的参数是一个文件时,它会简单转成以数组方式返回长度为1的FileStatus对象。当传入的是一个目录时,则返回0或多个FileStatus对象,包括此目录中包括的所有文件和目录
listStatus方法可以列出目录下所有文件的文件状态,所以就可以借助于这个特点列出某个目录下的所有文件(包括子目录):
publicclass ListStatus {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
Path[] paths = new Path[2];
// 目录
paths[0] = new Path("hdfs://hadoop-master:9000/ncdc");
// 文件
paths[1] = new Path("hdfs://hadoop-master:9000/wordcount/input/wordcount.txt");
// 只传一个目录进去。注:listStatus方法只会将直接子目录或子文件列出来,
// 而不会递归将所有层级子目录文件列出
FileStatus[] status = fs.listStatus(paths[0]);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
// 输出输入目录下的所有文件及目录的路径
System.out.println(p);
}
System.out.println();
// 只传一个文件进去
status = fs.listStatus(paths[1]);
listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
// 输出输入文件的路径
System.out.println(p);
}
System.out.println();
//传入的为一个数组:包括文件与目录
status = fs.listStatus(paths);
// 将FileStatus数组转换为Path数组
listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
// 输出所有输入的文件的路径,以及输入目录下所有文件或子目录的路径
System.out.println(p);
}
}
}
11.5.10 获取Datanode信息
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://hadoop-master:9000");
FileSystem fs = FileSystem.get(conf);
DistributedFileSystem hdfs = (DistributedFileSystem) fs;
DatanodeInfo[] dns = hdfs.getDataNodeStats();
for (int i = 0, h = dns.length; i < h; i++) {
System.out.println("datanode_" + i + "_name: " + dns[i].getHostName());
}

通过DatanodeInfo可以获得datanode更多的消息
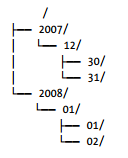
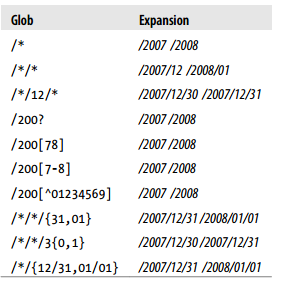
11.5.11 文件通配
FileSystem提供了两个通配的方法:
public FileStatus[] globStatus(Path pathPattern) throws IOException {
public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws IOException {
pathPattern参数是通配,filter是进一步骤过滤

注:根据通配表达式,匹配到的可能是目录,也可能是文件,这要看通配表达式是只到目录,还是到文件。具体示例请参考下面的PathFilter
11.5.12 过滤文件
有时通配模式并不总能多精确匹配到我们想要的文件,此时此要使用PathFilter参数进行过滤。FileSystem的listStatus() 和 globStatus()方法就提供了此过滤参数
publicinterfacePathFilter {
boolean accept(Path path);
}
示例:排除匹配指定正则表达式的路径
publicclass RegexExcludePathFilter implements PathFilter {
privatefinal String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
publicboolean accept(Path path) {
return !path.toString().matches(regex);
}
}
publicstaticvoid main(String[] args) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
FileStatus[] status = fs.globStatus(new Path("/2007/*/*"));//匹配到文件夹
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
![]()
publicstaticvoid main(String[] args) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
FileStatus[] status = fs.globStatus(new Path("/2007/*/*/*30.txt"));//匹配到文件
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
![]()
publicstaticvoid main(String[] args) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
FileStatus[] status = fs.globStatus(new Path("/2007/*/*"), new RegexExcludePathFilter(
"^.*/2007/12/31$"));//过滤掉31号的目录
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
![]()
11.6 数据流
11.6.1 文件读取过程
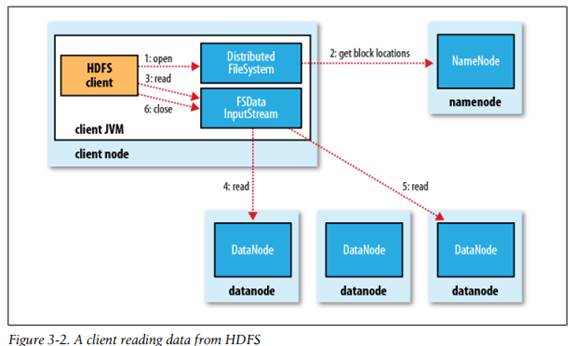
1、 客户端调用DistributedFileSystem(在编程时我们一般直接调用的是其抽像父类FileSystem的open方法,对于HDFS文件系统来说,实质上调用的还是DistributedFileSystem的open方法)的open()方法来打开要读取的文件,并返回FSDataInputStream类对象(该类实质上是对DFSInputStream的封装,由它来处理与datanode和namenode的通信,管理I/O)
2、 DistributedFileSystem通过使用RPC来调用namenode,查看文件在哪些datanode上,并返回这些datanode的地址(注:由于同一文件块副本的存放在很多不同的datanode节点上,返回的都是网络拓扑中距离客户端最近的datanode节点地址,距离算法请参考后面)
3、 客户端调用FSDataInputStream对象的read()方法
4、 FSDataInputStream去相应datanode上读取第一个数据块(这一过程并不需要namenode的参与,该过程是客户端直接访问datanote)
5、 FSDataInputStream去相应datanode上读取第二个数据块…如此读完所有数据块(注:数据块读取应该是同时并发读取,即在读取第一块时,也同时在读取第二块,只是在拼接文件时需要按块顺序组织成文件)
6、 客户端调用FSDataInputStream的close()方法关闭文件输入流
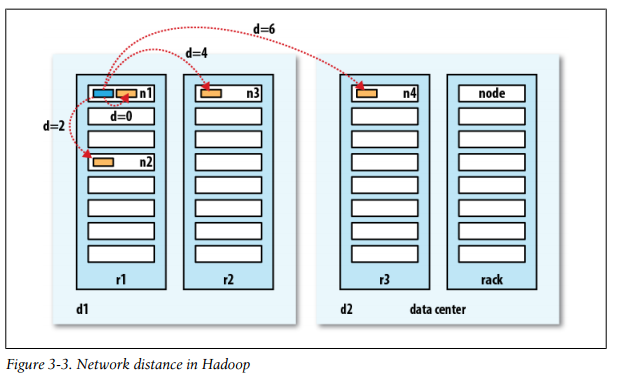
假设有数据中心d1机架r1中的n1节点表示为 /d1/r1/n1。
• distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node)同一节点
• distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)同一机架上不同节点
• distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center)同一数据中心不同机架上不同节点
• distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)不同数据中心
哪些节点是哪些机架上是通过配置实现的,具体请参考后面的章节
11.6.2 文件写入过程

1、 客户端调用DistributedFileSystem的create()创建文件,并向客户端返回FSDataOutputStream类对象(该类实质上是对DFSOutputStream的封装,由它来处理与datanode和namenode的通信,管理I/O)
2、 DistributedFileSystem向namenode发出创建文件的RPC调用请求,namenode会告诉客户端该文件会写到哪些datanode上
3、 客户端调用FSDataOutputStream的write方法写入数据
4、 FSDataOutputStream向datanode写数据
5、 当数据块写完(要达到dfs.replication.min副本数)后,会返回确认写完的信息给FSDataOutputStream。在返回写完信息的后,后台系统还要拷贝数据副本要求达到dfs.replication设置的副本数,这一过程是在后台自动异步复制完成的,并不需要等所有副本都拷贝完成后才返回确认信息到FSDataOutputStream
6、 客户端调用FSDataOutputStream的close方法关闭流
7、 DistributedFileSystem发送文件写入完成的信息给namenode
数据存储在哪些datanode上,这是有默认布局策略的:
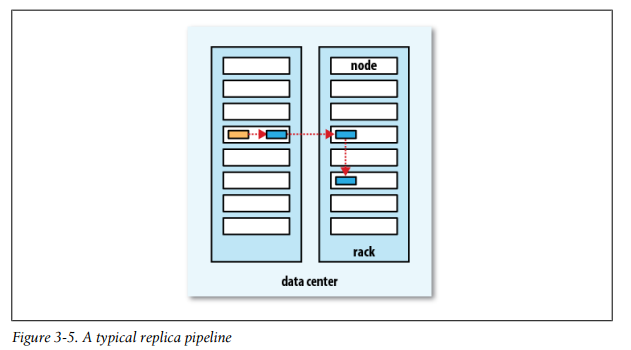
在客户端运行的datanode节点上放第一个副本(如果客户端是在集群外的机器上运行的话,会随机选择一个空闲的机器),第二个副本则放在与第一个副本不在同一机架的节点上,第三个副本则放在与第二个节点同一机架上的不同节点上,超过3个副本的,后继会随机选择一台空闲机器放后继其他副本。这样做的目的兼顾了安全与效率问题
11.6.3 缓存同步
当新建一个文件后,在文件系统命名空间立即可见,但数据不一定能立即可见,即使数据流已刷新:
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
assertThat(fs.getFileStatus(p).getLen(), is(0L));
当写入数据超过一个块后,第一个数据块对新的reader就是可见的,之后的块也是一样,当后面的块写入后,前面的块才能可见。总之,当前正在写入的块对其他reader是不可见的
FSDataOutputStream提供了一个方法sync()来使所有缓存与数据节点强行同步,当sync()方法调用成功后,对所有新的reader而言都可见:
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
out.sync();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
注:如果调用了FSDataOutputStream的close()方法,该方法也会调用sync()
12 压缩
文件压缩有两大好处:减少存储文件所需要的磁盘空间,并加速数据在网络和磁盘上的传输

所有的压缩算法要权衡时间与空间,压缩时间越短,压缩率超低,压缩时间越长,压缩率超高。上表时每个工具都有9个不同的压缩级别:-1为优化压缩速度,-9为优化压缩空间。如下面命令通过最快的压缩方法创建一个名为file.gz的压缩文件:
gzip -1 file
不同压缩工具有不同的压缩特性。gzip是一个通用的压缩工具,在空间与时间比较均衡。bzip2压缩能力强于gzip,但速度会慢一些。另外,LZO、LZ4和Snappy都优化了压缩速度,比gzip快一个数量级,但压缩率会差一些(LZ4和Snappy的解压速度比LZO高很多)
上表中的“是否可切分”表示数据流是否可以搜索定位(seek)。

上面这些算法类都实现了CompressionCodec接口。
CompressionCodec接口包含两个方法,可以用于压缩和解压。如果要对数据流进行压缩,可以调用createOutputStream(OutputStream out)方法得到CompressionOutputStream输出流;如果要对数据流进行解压,可以调用createInputStream(InputStream in)方法得到CompressionInputStream输入流
CompressionOutputStream与CompressionInputStream类似java.util.zip.DeflaterOutputStream和java.util.zip.DeflaterInputStream,只不过前两者能够重置其底层的压缩与解压算法
12.1 使用CompressionCodec对数据流进行压缩与解压
示例:压缩从标准输入读取的数据,然后将其写到标准输出
publicstaticvoid main(String[] args) throws Exception {
ByteArrayInputStream bais = new ByteArrayInputStream("测试".getBytes("GBK"));
Class<?> codecClass = Class.forName("org.apache.hadoop.io.compress.GzipCodec");
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);// 压缩流,构造时会输出三字节的头信息:31-117 8
 //1F=16+15=31;负数是以补码形势存储的,8B的二进制为10001011,先减一得到10001010,再除符号位各们取反得到原码11110101,即得到 -117
//1F=16+15=31;负数是以补码形势存储的,8B的二进制为10001011,先减一得到10001010,再除符号位各们取反得到原码11110101,即得到 -117
System.out.println();
IOUtils.copyBytes(bais, out, 4096, false);// 将压缩流输出到标准输出
out.finish();
System.out.println();
bais = new ByteArrayInputStream("测试".getBytes("GBK"));
ByteArrayOutputStream baos = new ByteArrayOutputStream(4);
out = codec.createOutputStream(baos);
IOUtils.copyBytes(bais, out, 4096, false);// 将压缩流输出到缓冲
out.finish();
bais = new ByteArrayInputStream(baos.toByteArray());
CompressionInputStream in = codec.createInputStream(bais);// 解压缩流
IOUtils.copyBytes(in, System.out, 4096, false);// 将压缩流输出到标准输出
// ---------将压缩文件上传到Hadoop中
// 注:hadoop默认使用的是UTF-8编码,如果使用GBK上传,使用 hadoop fs -text /gzip_test 命令
// 在Hadoop系统中查看时显示不出来,但Down下来后可以
bais = new ByteArrayInputStream("测试".getBytes("UTF-8"));
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop-master:9000"), conf);
out = codec.createOutputStream(fs.create(new Path("/gzip_test.gz")));
IOUtils.copyBytes(bais, out, 4096);
IOUtils.closeStream(out);
IOUtils.closeStream(in);
IOUtils.closeStream(fsout);
}
![]()

12.2通过CompressionCodecFactory自动获取CompressionCodec
在读取一个压缩文件时,可以通过文件扩展名推断需要使用哪个codec,如以.gz结尾,则使用GzipCodec来读取。可以通过调用CompressionCodecFactory的getCodec()方法根据扩展名来得到一个CompressionCodec
示例:根据文件扩展名自动选取codec解压文件
publicclass FileDecompressor {
publicstaticvoid main(String[] args) throws Exception {
String uri = "hdfs://hadoop-master:9000/gzip_test.gz";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
// 根据文件的扩展名自动找到对应的codec
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
String outputUri = CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
// 将解压出的文件放在hdoop上的同一目录下
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}
CompressionCodecFactory从io.compression.codecs(core-site.xml配置文件里)配置属性里定义的列表中找到codec:

<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>A list of the compression codec classes that can be used for compression/decompression.</description>
</property>
12.3 本地native压缩库
运行上面示例时,会报以下警告:
WARN [main] org.apache.hadoop.io.compress.snappy.LoadSnappy - Snappy native library not loaded
hdfs://hadoop-master:9000/gzip_test
WARN [main] org.apache.hadoop.io.compress.zlib.ZlibFactory - Failed to load/initialize native-zlib library
这是因为程序是在Windows上运行的,在本地没有搜索到native类库,而使用Java实现来进行压缩与解压。如果将程序打包上传到Linux上运行时,第二个警告会消失:
[root@hadoop-master /root/tmp]# hadoop jar /root/tmp/FileDecompressor.jar
16/04/26 11:13:31 INFO util.NativeCodeLoader: Loaded the native-hadoop library
16/04/26 11:13:31 WARN snappy.LoadSnappy: Snappy native library not loaded
16/04/26 11:13:31 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
但第一个警告还是有,原因是Linux系统上没有安装snappy,下面安装:
一、安装snappy
yum install snappy snappy-devel
二、使得Snappy类库对Hadoop可用
ln -sf /usr/lib64/libsnappy.so /root/hadoop-1.2.1/lib/native/Linux-amd64-64
再次运行:
[root@hadoop-master /root/hadoop-1.2.1/lib/native/Linux-amd64-64]# hadoop jar /root/tmp/FileDecompressor.jar
16/04/26 11:42:19 WARN snappy.LoadSnappy: Snappy native library is available
16/04/26 11:42:19 INFO util.NativeCodeLoader: Loaded the native-hadoop library
16/04/26 11:42:19 INFO snappy.LoadSnappy: Snappy native library loaded
16/04/26 11:42:19 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
与内置的Java实现相比,原生的gzip类库可以减少约束一半的解压时间与约10%的压缩时间,下表列出了哪些算法有Java实现,哪些有本地实现:

默认情况下,Hadoop会根据自身运行的平台搜索原生代码库,如果找到则自加载,所以无需为了使用原生代码库而修改任何设置,但是,如果不想使用原生类型,则可以修改hadoop.native.lib配置属性(core-site.xml)为false:
<property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
12.4 CodecPool压缩池
如何使用的是代码库,并且需要在应用中执行大量压缩与解压操作,可以考虑使用CodecPool,它支持反复使用压缩秘解压,减少创建对应的开销
publicstaticvoid main(String[] args) throws Exception {
//注:这里使用GBK,如果使用UTF-8,则输出到标准时会乱码,原因操作系统标准输出为GBK解码
ByteArrayInputStream bais = new ByteArrayInputStream("测试".getBytes("GBK"));
ByteArrayOutputStream bois = new ByteArrayOutputStream();
Class<?> codecClass = Class.forName("org.apache.hadoop.io.compress.GzipCodec");
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = null;
CompressionInputStream in = null;
Compressor cmpressor = null;// 压缩实例
Decompressor decompressor = null;// 解压实例
try {
// 从池中获取或新建一个Compressor压缩实例
cmpressor = CodecPool.getCompressor(codec);
// 从池中获取或新建一个Compressor解压缩实例
decompressor = CodecPool.getDecompressor(codec);
out = codec.createOutputStream(bois, cmpressor);
System.out.println();
IOUtils.copyBytes(bais, out, 4096, false);// 将压缩流输出到缓冲
out.finish();
bais = new ByteArrayInputStream(bois.toByteArray());
in = codec.createInputStream(bais, decompressor);// 解压压缩流
IOUtils.copyBytes(in, System.out, 4096, false);// 解压后标准输出
} finally {
IOUtils.closeStream(out);
CodecPool.returnCompressor(cmpressor);// 用完之后返回池中
CodecPool.returnDecompressor(decompressor);
}
}

12.5 压缩数据分片问题
如果压缩数据超过块大小后,会被分成多块,如果每个片断数据单独作传递给不同的Map任务,由于gzip数据是不能单独片断进行解压的,所以会出问题。但实际上Mapreduce任务还是可以处理gzip文件的,只是如果发现(根据扩展名)是gz,就不会进行文件任务切分(其他算法也一样,只要不支持单独片断解压的,都会交给同一Map进行处理),而将这个文件块都交个同一个Map任务进行处理,这样会影响性能问题。
只有bzip2压缩格式的文件支持数据任务的切分,哪些压缩能切分请参考这里
12.6 在Mapreduce中使用压缩
要想压缩mapreduce作业的输出(即这里讲的是对reduce输出压缩),应该在mapred-site.xml配置文件的配置项mapred.output.compress设置为true,mapred.output.compression.code设置为要使用的压缩算法:
<property>
<name>mapred.output.compress</name>
<value>false</value>
<description>Should the job outputs be compressed?
</description>
</property>
<property>
<name>mapred.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
<description>If the job outputs are compressed, how should they be compressed?
</description>
</property>
也可以直接在作业启动程序里通过FileOutputFormat进行设置:
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "MaxTemperatureWithCompression");
job.setJarByClass(MaxTemperatureWithCompression.class);
//map的输入可以是压缩格式的,也可直接是未压缩的文本文件,输入map前会自动根据文件后缀来判断是否需要解压,不需要特殊处理或配置
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/1901_1902.txt.gz"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/MaxTemperatureWithCompression"));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//与mapred-site.xml配置文件里的mapred.output.compress配置属性等效:job输出是否压缩,即对reduce输出是否采用压缩
FileOutputFormat.setCompressOutput(job, true);
//与mapred-site.xml配置文件里的mapred.output.compression.codec配置属性等效
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
如果Job输出生成的是顺序文件(sequence file),则可以设置mapred.output.compression.type(mapred-site.xml)来控制限制使用压缩格式,默认值为RECORD,表示针对每一条记录进行压缩。如果将其必为BLOCK,将针对一组记录进行压缩,这也是推荐的压缩策略,因为它的压缩效率更高
<property>
<name>mapred.output.compression.type</name>
<value>RECORD</value>
<description>If the job outputs are to compressed as SequenceFiles, how should
they be compressed? Should be one of NONE, RECORD or BLOCK.
</description>
</property>
该属性还可以直接在JOB启动任务程序里通过SequenceFileOutputFormat的setOutputCompressionType()来设定
mapred-site.xml配置文件里可以对Job作业输出压缩进行配置的三个配置项:

12.6.1 对Map任务输出进行压缩
如果对map阶段的中间输出进行压缩,可以获得不少好处。由于map任务的输出需要写到磁盘并通过网络传输到reducer节点,所以如果使用LZO、LZ4或者Snappy这样的快速压缩方式,是可以获得性能提升的,因为要传输的数据减少了。
启用map任务输出压缩和设置压缩格式的三个配置属性如下(mapred-site.xml):

也可在程序里设定(新的API设置方式):
Configuration conf = new Configuration();
conf.setBoolean("mapred.compress.map.output", true);
conf.setClass("mapred.map.output.compression.codec", GzipCodec.class,
CompressionCodec.class);
Job job = new Job(conf);
旧API设置方式,通过conf对象的方法设置:
conf.setCompressMapOutput(true);
conf.setMapOutputCompressorClass(GzipCodec.class);
13 序列化
13.1 Writable接口
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
publicinterface Writable {
void write(DataOutput out) throws IOException;//序列化:即将实例写入到out输出流中
void readFields(DataInput in) throws IOException;//反序列化:即从in输出流中读取实例
}
Hadoop中可序列化的类都实现了Writable这个接口,比如数据类型类BooleanWritable、ByteWritable、DoubleWritable、FloatWritable、IntWritable、LongWritable、Text
publicstaticvoid main(String[] args) throws IOException {
IntWritable iw = new IntWritable(163);
// 序列化
byte[] bytes = serialize(iw);
// Java里整型占两个字节
System.out.println(StringUtils.byteToHexString(bytes).equals("000000a3"));//true
// 反序列化
IntWritable niw = new IntWritable();
deserialize(niw, bytes);
System.out.println(niw.get() == 163);//true
}
// 序列化
publicstaticbyte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);//最终还是借助于Java API中的ByteArrayOutputStream 与 DataOutputStream 来完成序列化:即将基本类型的值(这里为整数)转换为二进制的过程
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}
// 反序列化
publicstaticvoid deserialize(Writable writable, byte[] bytes) throws IOException {
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
DataInputStream dataIn = new DataInputStream(in); //最终还是借助于Java API中的ByteArrayInputStream与 DataInputStream来完成反序列化:即将二进制转换为基本类型的值(这里为整数)的过程
writable.readFields(dataIn);
dataIn.close();
}
IntWritable类的序列化与反序列化实现:
publicclass IntWritable implements WritableComparable<IntWritable> {
privateintvalue;
@Override
publicvoidreadFields(DataInput in) throws IOException {
value = in.readInt();
}
@Override
publicvoidwrite(DataOutput out) throws IOException {
out.writeInt(value); //实质上最后就是将整型值以二进制存储起来了
}
...
}
13.2 WritableComparable接口、WritableComparator 类
IntWritable实现了WritableComparable接口,而WritableComparable接口继承了Writable接口与java.lang.Comparable接口
publicclassIntWritableimplements WritableComparable {
publicinterfaceWritableComparable<T> extendsWritable, Comparable<T> {
publicinterface Comparable<T> {
publicintcompareTo(T o);
}
IntWritable实现了Comparable的compareTo方法,具体实现:
/** Compares two IntWritables. */
publicint compareTo(Object o) {
int thisValue = this.value;
int thatValue = ((IntWritable)o).value;
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
除了实现了Comparable比较能力接口,Hadoop提供了一个优化接口是继承自java.util.Comparator比较接口的RawComparator接口:
publicinterfaceRawComparator<T> extendsComparator<T> {
publicint compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
RawComparator:原生比较,即基于字节的比较
publicinterface Comparator<T> {
intcompare(T o1, T o2);
boolean equals(Object obj);
}
为什么说是优化接口呢?因为该接口中的比较方法可以直接对字节进行比较,而不需要先反序列化后再比(因为是静态内部类实现:
/** A WritableComparable for ints. */
publicclass IntWritable implements WritableComparable {
...
/** A Comparator optimized for IntWritable. */
publicstaticclass Comparator extends WritableComparator {
publicint compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
...
}
}
...
}
),这样就避免了新建对象(即不需要通过反序列化重构Writable对象后,才能调用该对象的compareTo()比较方法)的额外开销,而Comparable接口比较时是基于对象本身的(属于非静态实现):
/** A WritableComparable for ints. */
publicclass IntWritable implements WritableComparable {
...
/** Compares two IntWritables. */
publicint compareTo(Object o) {
...
}
...
}
),所以比较前需要对输入流进行反序列重构成Writable对象后再比较,所以性能不高。如IntWritable的内部类IntWritable.Comparator就实现了RawComparator原生比较接口,性能比IntWritable.compareTo()比较方法高:
publicstaticclassComparatorextends WritableComparator {
public Comparator() {
super(IntWritable.class);
}
//这里实现的实际上是重写WritableComparator里的方法。注:虽然WritableComparator已经提供了该方法的默认实现,但不要直接使用,因为父类WritableComparator提供的默认实现也是先反序列化后,再通过回调IntWritable里的compareTo()来完成比较的,所以我们在为自定义Key时,一定要自己重写WritableComparator里提供的默认实现
@Override
publicint compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
int thisValue = readInt(b1, s1);// readInt为父类WritableComparator中的方法,将字节数组转换为整型(具体请参考后面),这样不需要将字节数组反序列化成IntWritable后再进行大小比对,而是直接对IntWritable里封装的int value进行比对
int thatValue = readInt(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
而WritableComparator又是实现了RawComparator接口中的compare()方法,同时还实现了Comparator类中的:
publicclass WritableComparator implements RawComparator{
publicint compare(byte[] b1, ints1, intl1, byte[] b2, ints2, intl2) {//该方法实现的是RawComparator接口里的方法
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
thrownew RuntimeException(e);
}
return compare(key1, key2); // compare them
}
@SuppressWarnings("unchecked")//该方法被上下两个方法调用,是WritableComparator里自己定义的方法,不是重写或实现
publicint compare(WritableComparable a, WritableComparable b) {
returna.compareTo(b);
}
@Override//该方法实现的是Comparator的compare(T o1, T o2)方法
publicint compare(Object a, Object b) {
return compare((WritableComparable)a, (WritableComparable)b);
}
}
WritableComparable是一个接口;而WritableComparator 是一个类。WritableComparator提供一个默认的基于对象(非字节)的比较方法compare(如上面所贴),这与实现Comparable接口的比较方法是一样的:都是基于对象的,所以性能也不高
获取IntWritable的内部类Comparator的实例:
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
这样可以取到RawComparator实例,原因是在IntWritable实现里注册过
static { // register this comparator
WritableComparator.define(IntWritable.class, newComparator());
}
这个comparator实例可以用于比较两个IntWritable对象:
IntWritable w1 = new IntWritable(163);
IntWritable w2 = new IntWritable(67);
assertThat(comparator.compare(w1, w2), greaterThan(0));// comparator.compare(w1, w2)会回调IntWritable.compareTo方法
或是IntWritable对象序列化的字节数组:
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
assertThat(comparator.compare(b1, 0, b1.length, b2, 0, b2.length),greaterThan(0));//这里才真正调用IntWritable.Comparator.compare()方法进行原生比较
上面分析的是IntWritable类型,其他类型基本上也是这样
13.2.1 比较方式优先级(WritableComparable、WritableComparator)
Key在Map的shuffle过程中是需要进行排序的,这就要求Key是实现WritableComparable的类,或者如果不实现WritableComparable接口时,需要通过Job指定比较类,他们的优先选择顺序如下:
1、 如果配置了mapred.output.key.comparator.class比较类,或明确地通过job的setSortComparatorClass(Class<? extends RawComparator> cls)方法(旧API为setOutputKeyComparatorClass() on JobConf)指定过,则使用指定类(一般从WritableComparator继承)的实例进行排序(这种情况要不需要WritableComparable,而只需实现Writable即可)
2、 否则,Key必须是实现了WritableComparable的类(因为在实现内部静态比较器继承时需要继承WritableComparator,其构造函数需要传进一个实现了WritableComparable的Key,并在WritableComparator类里提供的默认比较会回调Key类所实现的compareTo()方法,所以需要实现WritableComparable类),并且如果该Key类内部通过静态块(WritableComparator.define(Class c, WritableComparator comparator))注册过基于字节比较的类WritableComparator(实现RawComparator的抽象类,RawComparator又继承了Comparator接口),则使用字节比较方式进行排序(一般使用这种)
3、 否则,如果没有使用静态注册过内部实现WritableComparator,则使用WritableComparable的compareTo()进行对象比较(这需要先反序列化成对象之后)(注:此情况下Key也必须是实现WritableComparable类)
13.3 Writable实现类
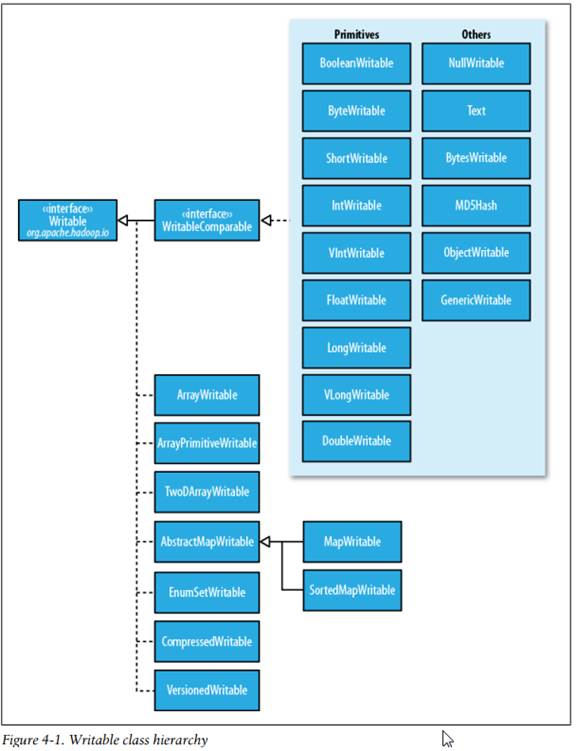
13.3.1 Java基本类型对应的Writable实现类
Writable很多的实现类实质上是对Java基本类型(但除char没有对应的Writable实现类外,char可以存放在IntWritable中)的再一次封装,get()、set()方法就是对这些封装的基本值的读取与设定:
![]()
![]()
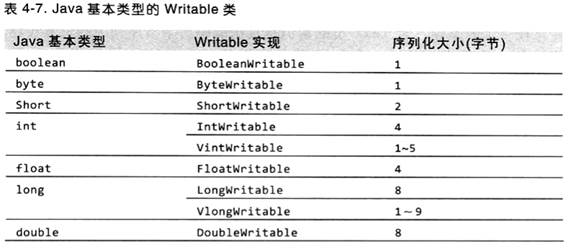
13.3.2 可变长类型VIntWritable 、VLongWritable
从上表可以看出,VIntWritable(1~5)与 VLongWritable(1~9)为变长。如果数字在-112~127之间时,变长格式就只用一个字节进行编码;否则,使用第一个字节来存放正负号,其他字节就存放值(究竟需要多少字节来存放,则是看数字的大小,如int类型的值需要1~4个字节不等)。如 值为163需要两个字节,而不是4个字节:第一个字节存符号为(不同长度的数这个字节存储的不太一样),第二个字节存放的是值;而257则需要三个字节来存放了;
可变长度类型有点像UTF-8一样,编码是变长的,如果传输内容中的数字都是比较小的数时(如果内容都是英文的字符,UTF-8就会大大缩短编码长度),用可变长度则可以减少数据量,这些数的范围:-65536 =< VIntWritable =< 65535此范围最多只占3字节,包括符号位;-281474976710656L =< VLongWritable =< 28147497671065L此范围最多只占7字节,包括符号位,如果超过了这些数,建议使用定长的,因为此时定长的所占字节还少,因为在接近最大Int或Long时,变长的VintWritable达到5个字节(如2147483647就占5字节),VlongWritable达到9个字节(如9223372036854775807L就占9字节),而定长的最多只有4字节与8字节
另外,同一个数用VintWritable或VlongWritable最后所占有字节数是一样的,比如2147483647这个数,都是8c7fffffff,占5字节,既然同一数字的编码长度都一样,所以优先推荐使用 VlongWritable,因为他存储的数比VintWritable更大,有更好的扩展
虽然VintWritable与VlongWritable所占最大字节可能分别达到5或9位,但它们允许的最大数的范围也 基本类型 int、long是一样的,即VintWritable允许的数字范围:-2147483648 =< VintWritable =< 2147483647;VlongWritable允许的数字范围:-9223372036854775808L =< VlongWritable =< 9223372036854775807L,因为它们的构造函数参数的类型就是基本类型int、long:
public VIntWritable(int value) { set(value); }
public VLongWritable(long value) { set(value); }
13.3.3 Text
提供了序列化、反序列化和在字节级别上比较文本的方法。它的长度类型是整型,采用0压缩序列化格式。另外,它还支持在不将字符数组转换为字符串的情况下进行字符串遍历
相当于Java中的String类型,采用UTF-8编解码,它是对 byte[] 字节数组的封装,而不直接是String:
![]()
length存储了字符串所占的字节数,为int类型,所以最大可达2GB。
getLength():返回的是字节数组bytes的所存储内容的有效长度,而非字符串个数,取长度时不要直接通过getBytes().length来获取,因为在通过set()方法重置Text后,有时数组整个长度会大于所存内容的长度
getBytes():返回字符串原生字节数组,但数据的有效长度到getLength()
与String不同的是,Text是可变的,可以通过set()方法重用它
Text索引位置都是以字节为单位进行索引的,并不像String那样是以字符为单位进行索引的
Text与IntWritable一样,也是可序列化与可比较的
由于Text在内存中使用的是UTF-8编码的字节码,而Java中的String则是Unicode编码,所以是有区别的
Text t = new Text("江正军");
//字符所占字节数,而非字符个数
System.out.println(t.getLength());// 9 UTF-8编码下每个中文占三字节
//取单个字符,charAt()返回的是Unicode编码
System.out.println((char) t.charAt(0));
System.out.println((char) t.charAt(3));// 第二个字符,注意:传入的是byte数组中的索引,不是字符位置索引
System.out.println((char) t.charAt(6));
//转换成String
System.out.println(t.toString());// 江正军
ByteBuffer buffer = ByteBuffer.wrap(t.getBytes(), 0, t.getLength());
int cp;
// 遍历每个字符
while (buffer.hasRemaining() && (cp = Text.bytesToCodePoint(buffer)) != -1) {
System.out.println((char) cp);
}
// 在末尾附加字符
t.append("江".getBytes("UTF-8"), 0, "江".getBytes("UTF-8").length);
System.out.println(t.toString());// 江正军江
// 查找字符:返回第一次出现的字符位置(也是在字节数组中的偏移量,而非字符位置),类似String的indexOf,注:这个位置指字符在UTF-8字节数组的索引位置,而不是指定字符所在位置
System.out.println(t.find("江"));// 0
System.out.println(t.find("江", 1));// 9 从第2个字符开始向后查找
Text t2 = new Text("江正军江");
//比较Text:如果相等,返回0
System.out.println(t.compareTo(t2));// 0
System.out.println(t.compareTo(t2.getBytes(), 0, t2.getLength()));//0
下表列出Text字符(实为UTF-8字符)与String(实为Unicode字符)所占字节:如果是拉丁字符如大写字母A,则存放在Text中只占一个字节,而String占用两字节;大于127的都占有两字节;汉字时Text占有三字节,String占两字节;后面的U+10400不知道是什么扩展字符?反正表示一个字符,但都占用了4个字节:

@Test
publicvoid string() throws UnsupportedEncodingException {
String s = "\u0041\u00DF\u6771\uD801\uDC00";
assertThat(s.length(), is(5));
assertThat(s.getBytes("UTF-8").length, is(10));
assertThat(s.indexOf("\u0041"), is(0));
assertThat(s.indexOf("\u00DF"), is(1));
assertThat(s.indexOf("\u6771"), is(2));
assertThat(s.indexOf("\uD801\uDC00"), is(3));
assertThat(s.charAt(0), is('\u0041'));
assertThat(s.charAt(1), is('\u00DF'));
assertThat(s.charAt(2), is('\u6771'));
assertThat(s.charAt(3), is('\uD801'));
assertThat(s.charAt(4), is('\uDC00'));
assertThat(s.codePointAt(0), is(0x0041));
assertThat(s.codePointAt(1), is(0x00DF));
assertThat(s.codePointAt(2), is(0x6771));
assertThat(s.codePointAt(3), is(0x10400));
}
@Test
publicvoid text() {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
assertThat(t.getLength(), is(10));
assertThat(t.find("\u0041"), is(0));
assertThat(t.find("\u00DF"), is(1));
assertThat(t.find("\u6771"), is(3));
assertThat(t.find("\uD801\uDC00"), is(6));
assertThat(t.charAt(0), is(0x0041));
assertThat(t.charAt(1), is(0x00DF));
assertThat(t.charAt(3), is(0x6771));
assertThat(t.charAt(6), is(0x10400));
}
13.3.4 BytesWritable
与Text一样,BytesWritable是对二进制数据的封装
![]()
序列化时,前4个字节存储了字节数组的长度:
publicstaticvoid main(String[] args) throws IOException {
BytesWritable b = new BytesWritable(newbyte[] { 3, 5 });
byte[] bytes = serialize(b);
System.out.println((StringUtils.byteToHexString(bytes)));//000000020305
}
// 序列化
publicstaticbyte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}
BytesWritable也是可变的,可以通过set()方法进行修改。与Text一样,BytesWritable的getBytes()返回的是字节数组长——容量——也可以无法体现所存储的实际大小,可以通过getLength()来确定实际大小,可以通过 setCapacity(int new_cap) 方法重置缓冲大小
13.3.5 NullWritable
它是一个Writable特殊类,它序列化长度为0,即不从数据流中读取数据,也不写入数据,充当占位符。如在MapReduce中,如果你不需要使用键或值,你就可以将键或值声明为NullWritable
它是一个单例,可以通过NullWritable.get()方法获取实例
13.3.6 ObjectWritable、GenericWritable
ObjectWritable是对Java基本类型、String、enum、Writable、null或这些类型组成的一个通用封装:
![]()
当一个字段中包含多个类型时(比如在map输出多种类型时),ObjectWritable非常有用,例如:如果SequenceFile中的值包含多个类型,就可以将值类型声明为ObjectWritable。
可以通过getDeclaredClass()获取ObjectWritable封装的类型
ObjectWritable在序列会时会将封装的类型名一并输出,这会浪费空间,我们可以使用GenericWritable来解决这个问题:如果封装的类型数量比较少并且能够提交知道需要封装哪些类型,那么就可以继承GenericWritable抽象类,并实现这个类将要对哪些类型进行封装的抽象方法:
abstractprotected Class<? extends Writable>[] getTypes();
这们在序列化时,就不必直接输出封装类型名称,而是这些类型的名称的索引(在GenericWritable内部会它他们分配编号),这样就减少空间来提高性能
class MyWritable extendsGenericWritable{
MyWritable(Writable writable) {
set(writable);
}
publicstatic Class<? extends Writable>[] CLASSES = new Class[] { Text.class };
@Override
protected Class<? extends Writable>[] getTypes() {
returnCLASSES;
}
publicstaticvoid main(String[] args) throws IOException {
Text text = new Text("\u0041\u0071");
MyWritable myWritable = new MyWritable(text);
System.out.println(StringUtils.byteToHexString(serialize(text)));// 024171
System.out.println(StringUtils.byteToHexString(serialize(myWritable)));// 00024171
ObjectWritable ow = new ObjectWritable(text); //00196f72672e6170616368652e6861646f6f702e696f2e5465787400196f72672e6170616368652e6861646f6f702e696f2e54657874024171 红色前面都是类型名序列化出来的结果,占用了很大的空间
System.out.println(StringUtils.byteToHexString(serialize(ow)));
}
publicstaticbyte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}
}
GenericWritable的序列化只是把类型在type数组里的索引放在了前面,这样就比ObjectWritable节省了很多空间,所以推荐大家使用GenericWritable
13.3.7 Writable集合
6种集合类:ArrayWritable, ArrayPrimitiveWritable, TwoDArrayWritable, MapWritable,SortedMapWritable, EnumSetWritable.
ArrayWritable与TwoDArrayWritable是对Writable的数组和二维数据(数组的数组)的实现:
![]()

ArrayWritable与TwoDArrayWritable中所有元素必须是同一类型的实例(在构造函数中指定):
ArrayWritable writable = new ArrayWritable(Text.class);
TwoDArrayWritable writable = new TwoDArrayWritable(Text.class);
ArrayWritable与TwoDArrayWritable都有get、set、toArray方法,注:toArray方法是获取的数组(或二维数组)的副本(浅复制,虽然数组壳是复制了一份,只里面存放的元素未深度复制)
publicvoid set(Writable[] values) { this.values = values; }
publicWritable[] get() { returnvalues; }
publicvoid set(Writable[][] values) { this.values = values; }
publicWritable[][] get() { returnvalues; }
ArrayPrimitiveWritable是对Java基本数组类型的一个封装,调用set()方法时可以识别相应组件类型,因此无需通过继承来设置类型
MapWritable 与 SortedMapWritable分别实现了java.util.Map<Writable,Writable> 与 java.util.SortedMap<WritableComparable, Writable>接口。它们在序列化时,类型名称也是使用索引来替代一起输出,如果存入的是自定义Writable内,则不要超过127个,因它这两个类里面是使用一个byte来存放自定义Writable类型名称索引的,而那些标准的Writable则使用-127~0之间的数字来编号索引
对集合的枚举类型可以采用EnumSetWritable。对于单类型的Writable列表,使用ArrayWritable就足够了。但如果需要把不同的Writable类型存放在单个列表中,可以使用GenericWritable将元素封装在一个ArrayWritable中
13.4 自定义Writable
Hadoop中提供的现有的一套标准Writable是可以满足我们决大多数需求的。但在某些业务下需我们定义具有自己数据结构的Writable。
定制的Writable可以完全控制二进制表示和排序顺序。由于Writable是MapReduce数据路径的核心,所以调整二进制表示能对性能产生显著效果。虽然Hadoop自带的Writable实现已经过很好的性能调优,但如果希望将结构调整得更好,更好的做法就是新建一个Writable类型
示例:存储一对Text对象的自定义Writable,如果是Int整型,可以参考后面示例IntPair,如果复合键如果由整型与字符型组成,则可能同时参考这两个类来定义:
publicclassTextPairimplements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
publicvoid set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
returnfirst;
}
public Text getSecond() {
returnsecond;
}
@Override
publicvoid write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
publicvoid readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
/*
* HashPartitioner(MapReuce中的默认分区类)通常用hashcode()方法来选择reduce分区,所
* 以应该确保有一个比较好的哈希函数来保证每个reduce数据分区大小相似
*/
@Override
publicint hashCode() {
returnfirst.hashCode() * 163 + second.hashCode();
}
@Override
publicboolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
returnfirst.equals(tp.first) && second.equals(tp.second);
}
returnfalse;
}
/*
* TextOutputFormat将键或值输出时,会调用此方法,所以也需重写
*/
@Override
public String toString() {
returnfirst + "\t" + second;
}
/*
* 除VIntWritable、VLongWritable这两个Writable外,大多数的Writable类本身都实现了
* Comparable比较能力的接口compareTo()方法,并且又还在Writable类静态的实了Comparator
* 比较接口的compare()方法,这两个方法在Writable中的实现的性能是不一样的:Comparable.
* compareTo()方法在比较前,需要将字节码反序列化成相应的Writable实例后,才能调用;而
* Comparator.compare()比较前是不需要反序列化,它可以直接对字节码(数组)进行比较,所
* 以这个方法的性能比较高,属于原生比较
*
* VIntWritable、VLongWritable这两个类里没有静态的实现Comparator接口,可能是因为
* 变长的原因,
*
*/
@Override//WritableComparator里自定义比较方法 compare(WritableComparable a, WritableComparable b) 会回调此方法
publicintcompareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {//先按第一个字段比,如果相等,再比较第二个字段
return cmp;
}
returnsecond.compareTo(tp.second);
}
//(整型类型IntWritable基于字节数组原生比较请参考这里)
publicstaticclassComparatorextends WritableComparator {
privatestaticfinal Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
//或者这样来获取Text.Comparator实例?
// RawComparator<IntWritable> comparator = WritableComparator.get(Text.class);
public Comparator() {
super(TextPair.class);
}
/*
* 这个方法(下面注释掉的方法)从Text.Comparator.compare()方法拷过来的 l1、l2表示字节数有效的长度
*
* 由于Text在序列化时(这一序列化过程可参照Text的序列化方法write()源码来了解):首先是将Text的有效字节数 length
* 以VIntWritable方式序列化(即length在序列化时所在字节为 1~5), 然后再将整个字节数组序列化
* (字节数组序列化时也是先将字节有效长度输出,不过此时为Int,而非VInt,请参考后面贴出的源码)
* 下面是Text的序列化方法源码:
* public void write(DataOutput out) throws IOException {
* WritableUtils.writeVInt(out, length);
* out.write(bytes,0, length);
* }
*
* 下面是BytesWritable的序列化方法源码:
* public void write(DataOutput out) throws IOException {
* out.writeInt(size);
* out.write(bytes, 0, size);
* }
*
* WritableUtils.decodeVIntSize(b1[s1]):读出Text序列化出的串前面多少个字节是用來表示Text的长度的,
* 这样在取Text字節內容時要跳過長度信息串。传入时只需传入字节数组的第一个字节即可
*
* compareBytes(b1, s1 + n1, l1 - n1, b2, s2 + n2, l2 - n2):此方法才是真正按一個個字節進行大小比較
* b1从s1 + n1开始l1 - n1个字节才是Text真正字节内容
*
*/
// public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {//此方法是从Text.Comparator中拷出来的
// int n1 = WritableUtils.decodeVIntSize(b1[s1]);//序列化串中前面多少个字节是长度信息
// int n2 = WritableUtils.decodeVIntSize(b2[s2]);
// return compareBytes(b1, s1 + n1, l1 - n1, b2, s2 + n2, l2 - n2);
// }
@Override
publicintcompare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
//WritableUtils.decodeVIntSize(b1[s1])表示Text有效长度序列化输出占几个字节
//readVInt(b1, s1):将Text有效字节长度是多少读取出来。
//最后firstL1 表示的就是第一个Text属性成员序列化输出的有效字节所占长度
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
//比较第一个Text:即first属性。本身Text里就有Comparator的实现,这里只需要将first
//与second所对应的字节截取出来,再调用Text.Comparator.compare()即根据字节进行比较
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
return cmp;
}//如果第一个Text first 不等,则比较第二个Test:即second属性
//s1 + firstL1为第二个Text second的起始位置,l1 - firstL1为第二个Text second的字节数
returnTEXT_COMPARATOR
.compare(b1, s1 + firstL1, l1 - firstL1, b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
thrownew IllegalArgumentException(e);
}
}
}
static {
WritableComparator.define(TextPair.class, new Comparator());
}
}
14 顺序文件结构
14.1 SequenceFile
SequenceFile:顺序文件、或叫序列文件。它是一种具有一定存储结构的文件,数据以在内存中的二进制写入。Hadoop在读取与写入这类文件时效率会高
顺序文件——相对于MapFile只能顺序读取,所以称顺序文件
序列文件——写入文件时,直接将数据在内存中存储的二进写入到文件,所以写入后使用记事本无法直接阅读,但使用程序反序列化后或通过Hadoop命令可以正常阅读显示:hadoop fs -text /sequence/seq1
SequenceFile类提供了Writer,Reader 和 SequenceFile.Sorter 三个类用于完成写,读,和排序
14.1.1 写
publicclass SequenceFileWriteDemo {
privatestaticfinal String[] DATA = { "One, 一", "Three, 三", "Five, 五", "Seven, 七", "Nine, 九" };
publicstaticvoid main(String[] args) throws IOException {
String uri = "hdfs://hadoop-master:9000/sequence/seq1";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
/*
* 该方法有很多的重载版本,但都需要指定FileSystem+Configuration(或FSDataOutputStream+Configuration)
* 、键的class、值的class;另外,其他可选参数包括压缩类型CompressionType以及相应的CompressionCodec
* 、 用于回调通知写入进度的Progressable、以及在Sequence文件头存储的Metadata实例
*
* 存储在SequenceFile中的键和值并不一定需要Writable类型,只要能被Serialization序列化和反序列化
* ,任何类型都可以
*/
// 通过静态方法获取顺序文件SequenceFile写实例SequenceFile.Writer
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 10; i++) {
key.set(10 - i);
value.set(DATA[i % DATA.length]);
// getLength()返回文件当前位置,后继将从此位置接着写入(注:当SequenceFile刚创建时,就已
// 写入元数据信息,所以刚创建后getLength()也是非零的
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
/*
* 同步点:用来快速定位记录(键值对)的边界的一个特殊标识,在读取SequenceFile文件时,可以通过
* SequenceFile.Reader.sync()方法来搜索这个同步点,即可快速找到记录的起始偏移量
*
* 加入同步点的顺序文件可以作为MapReduce的输入,由于访类顺序文件允许切分,所以该文件的不同部分可以
* 由不同的map任务单独处理
*
* 在每条记录(键值对)写入前,插入一个同步点,这样是方便读取时,快速定位每记录的起始边界(如果读取的
* 起始位置不是记录边界,则会抛异常SequenceFile.Reader.next()方法会抛异常)
*
* 在真正项目中,可能不是在每条记录写入前都加上这个边界同步标识,而是以业务数据为单位(多条记录)加入
* ,这里只是为了测试,所以每条记录前都加上了
*/
writer.sync();
// 只能在文件末尾附加健值对
writer.append(key, value);
}
} finally {
// SequenceFile.Writer实现了java.io.Closeable,可以关闭流
IOUtils.closeStream(writer);
}
}
}

写入后在操作系统中打开显示乱的:
从上面可以看出这种文件的前面会写入一些元数据信息:键的Class、值的Class,以及压缩等信息
如果使用Hadoop来看,则还是可以正常显示的,因为该命令会给我们反序列化后再展示出来:
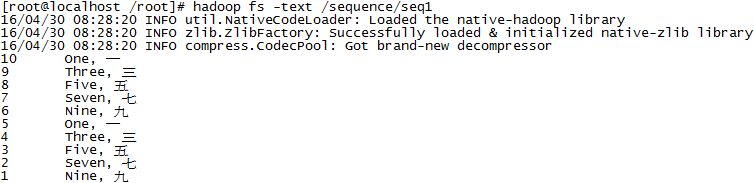
14.1.2 读
publicclass SequenceFileReadDemo {
publicstaticvoid main(String[] args) throws IOException {
String uri = "hdfs://hadoop-master:9000/sequence/seq1";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
// 通过SequenceFile.Reader实例进行读
reader = new SequenceFile.Reader(fs, path, conf);
/*
* 通过reader.getKeyClass()方法从SequenceFile文件头的元信息中读取键的class类型
* 通过reader.getValueClass()方法从SequenceFile文件头的元信息中读取值的class类型
* 然后通过ReflectionUtils工具反射得到Key与Value类型实例
*/
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
// 返回当前位置,从此位置读取下一健值对
long position = reader.getPosition();
// 读取下一健值对,并分别存入key与value变量中,如果到文件尾,则返回false
while (reader.next(key, value)) {
// 如果读取的记录(键值对)前有边界同步特殊标识时,则打上*
String syncSeen = reader.syncSeen() ? "*" : "";
// position为当前输入键值对的起始偏移量
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next
// record下一对健值对起始偏移量
}
System.out.println();
//设置读取的位置,注:一定要是键值对起始偏移量,即记录的边界位置,否则抛异常
reader.seek(228);
System.out.print("[" + reader.getPosition() + "]");
reader.next(key, value);
System.out.println(key + " " + value + " [" + reader.getPosition() + "]");
//这个方法与上面seek不同,传入的位置参数不需要是记录的边界起始偏移的准确位置,根据边界同步特殊标记可以自动定位到记录边界,这里从223位置开始向后搜索第一个同步点
reader.sync(223);
System.out.print("[" + reader.getPosition() + "]");
reader.next(key, value);
System.out.println(key + " " + value + " [" + reader.getPosition() + "]");
} finally {
IOUtils.closeStream(reader);
}
}
}

14.1.3 使用命令查看文件
hadoop fs –text命令除可以显示纯文本文件,还可以以文本形式显示SequenceFile文件、MapFile文件、gzip压缩文件,该命令可以自动力检测出文件的类型,根据检测出的类型将其转换为相应的文本。
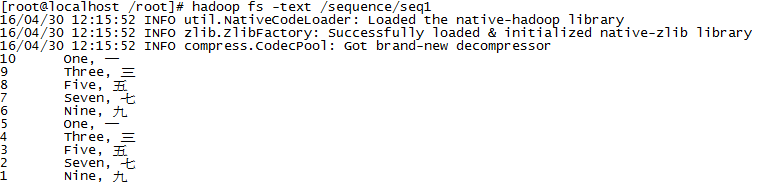
对于SequenceFile文件、MapFile文件,会调用Key与Value的toString方法来显示成文本,所以要重写好自定义的Writable类的toString()方法
14.1.4 将多个顺序文件排序合并
MapReduce是对一个或多个顺序文件进行排序(或合并)最好的方法。MapReduce本身是并行的,并就可以指定reducer的数量(即分区数),如指定1个reducer,则只会输出一个文件,这样就可以将多个文件合并成一个排序文件了。
除了自己写这样一个简单的排序合并MapReduce外,我们可以直接使用Haddop提供的官方实例来完成排序合并,如将前面写章节中产生的顺序文件重新升级排序(原输出为降序):
[root@hadoop-master /root/hadoop-2.7.2/share/hadoop/mapreduce]# hadoop jar ./hadoop-mapreduce-examples-2.7.2.jar sort-r 1 -inFormat org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat -outFormat org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat -outKey org.apache.hadoop.io.IntWritable -outValue org.apache.hadoop.io.Text /sequence/seq1 /sequence/seq1_sorted
[root@hadoop-master /root/hadoop-2.7.2/share/hadoop/mapreduce]# hadoop fs -text /sequence/seq1_sorted/part-r-00000
1 Nine, 九
2 Seven, 七
3 Five, 五
4 Three, 三
5 One, 一
6 Nine, 九
7 Seven, 七
8 Five, 五
9 Three, 三
10 One, 一
System.out.println("sort [-r <reduces>] " + //reduces的数量
"[-inFormat <input format class>] " +
"[-outFormat <output format class>] " +
"[-outKey <output key class>] " +
"[-outValue <output value class>] " +
"[-totalOrder <pcnt> <num samples> <max splits>] " +
"<input> <output>");
注:官方提供的Sort示例除了排序合并顺序文件外,还可以合并普通的文本文件,下面是它的部分源码:
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
job.setNumReduceTasks(num_reduces);
job.setInputFormatClass(inputFormatClass);
job.setOutputFormatClass(outputFormatClass);
job.setOutputKeyClass(outputKeyClass);
job.setOutputValueClass(outputValueClass);
14.1.5 SequenceFile文件格式
顺序文件由文件头Header、随后的一条或多条记录Record、以及记录间边界同步点特殊标识符Sync(可选):
此图为压缩前和记录压缩Record compression后的顺序文件的内部结构
顺序文件的前三个字节为SEQ(顺序文件代码),紧随其后的一个字节表示顺序文件的版本号,文件头还包括其他字段,例如键和值的名称、数据压缩细节、用户定义的元数据,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每个文件都有一个随机生成的同步标识,存储在文件头中。同步标识位于顺序文件中的记录与记录之间,同步标识的额外存储开销要求小于1%,所以没有必要在每条记录末尾添加该标识,特别是比较短的记录
记录的内部结构取决于是否启用压缩,SeqeunceFile支持两种格式的数据压缩,分别是:记录压缩record compression和块压缩block compression。
record compression如上图所示,是对每条记录的value进行压缩
默认情况是不启用压缩,每条记录则由记录长度(字节数)Record length、健长度Key length、键Key和值Value组成,长度字段占4字节
记录压缩(Record compression)格式与无压缩情况基本相同,只不过记录的值是用文件头中定义的codec压缩的,注,键没有被压缩(指记录压缩方式的Key是不会被压缩的,而如果是块压缩方式的话,整个记录的各个部分信息都会被压缩,请看下面块压缩)
块压缩(Block compression)是指一次性压缩多条记录,因为它可以利用记录间的相似性进行压缩,所以比单条记录压缩方式要好,块压缩效率更高。block compression是将一连串的record组织到一起,统一压缩成一个block:
上图:采用块压缩方式之后,顺序文件的内部结构,记录的各个部分都会被压缩,不只是Value部分
可以不断向数据块中压缩记录,直到块的字节数不小于io.seqfile.compress.blocksize(core-site.xml)属性中设置的字节数,默认为1MB:
<property>
<name>io.seqfile.compress.blocksize</name>
<value>1000000</value>
<description>The minimum block size for compression in block compressed SequenceFiles.
</description>
</property>
每一个新块的开始处都需要插入同步标识,block数据块的存储格式:块所包含的记录数(vint,1~5个字节,不压缩)、每条记录Key长度的集合(Key长度集合表示将所有Key长度信息是放在一起进行压缩)、每条记录Key值的集合(所有Key放在一起再起压缩)、每条记录Value长度的集合(所有Value长度信息放在一起再进行压缩)和每条记录Value值的集合(所有值放在一起再进行压缩)
14.2 MapFile
MapFile是已经排过序的SequenceFile,它有索引,索引存储在另一单独的index文件中,所以可以按键进行查找,注:MapFile并未实现java.util.Map接口
MapFile是对SequenceFile的再次封装,分为索引与数据两部分:
publicclass MapFile {
/** The name of the index file. */
publicstaticfinal String INDEX_FILE_NAME = "index";
/** The name of the data file. */
publicstaticfinal String DATA_FILE_NAME = "data";
publicstaticclass Writer implements java.io.Closeable {
private SequenceFile.Writer data;
private SequenceFile.Writer index;
/** Append a key/value pair to the map. The key must be greater or equal
* to the previous key added to the map. 在Append时,Key的值一定要大于或等于前面的已加入的值,即升序,否则抛异常*/
publicsynchronizedvoid append(WritableComparable key, Writable val)
throws IOException {
...
publicstaticclass Reader implements java.io.Closeable {
// the data, on disk
private SequenceFile.Reader data;
private SequenceFile.Reader index;
...
14.2.1 写
与SequenceFile一样,也是使用append方法在文件末写入,而且键要是WritableComparable类型的具有比较能力的Writable,值与SequenceFile一样也是Writable类型即可
privatestaticfinal String[] DATA = { "One, 一", "Three, 三", "Five, 五", "Seven, 七", "Nine, 九" };
publicstaticvoid main(String[] args) throws IOException {
String uri = "hdfs://hadoop-master:9000/map";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
IntWritable key = new IntWritable();
Text value = new Text();
MapFile.Writer writer = null;
try {
/*
* 注:在创建writer时与SequenceFile不太一样,这里传进去的是URI,而不是具体文件的Path,
* 这是因为MapFile会生成两个文件,一个是data文件,一个是index文件,可以查看MapFile源码:
* //The name of the index file.
* public static final String INDEX_FILE_NAME = "index";
* //The name of the data file.
* public static final String DATA_FILE_NAME = "data";
*
* 所以不需要具体的文件路径,只传入URI即可,且传入的URI只到目录级别,即使包含文件名也会看作目录
*/
writer = new MapFile.Writer(conf, fs, uri, key.getClass(), value.getClass());
for (int i = 0; i < 1024; i++) {
key.set(i);
value.set(DATA[i % DATA.length]);
// 注:append时,key的值要大于等前面已加入的键值对
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
[root@localhost /root]# hadoop fs -ls /map
Found 2 items
-rw-r--r-- 3 Administrator supergroup 430 2016-05-01 10:24 /map/data
-rw-r--r-- 3 Administrator supergroup 203 2016-05-01 10:24 /map/index
会在map目录下创建两个文件data与index文件,这两个文件都是SequenceFile
[root@localhost /root]# hadoop fs -text /map/data | head
0 One, 一
1 Three, 三
2 Five, 五
3 Seven, 七
4 Nine, 九
5 One, 一
6 Three, 三
7 Five, 五
8 Seven, 七
9 Nine, 九
[root@localhost /root]# hadoop fs -text /map/index
0 128
128 4013
256 7918
384 11825
512 15730
640 19636
768 23541
896 27446
Index文件存储了部分键(上面显示的第一列)及在data文件中的起使偏移量(上面显示的第二列)。从index输出可以看到,默认情况下只有每隔128个键才有一个包含在index文件中,当然这个间隔是可以调整的,可调用MapFile.Writer实例的setIndexInterval()方法来设置(或者通过io.map.index.interval属性配置也可)。增加索引间隔大小可以有效减少MapFile存储索引所需要的内存,相反,如果减小间隔则可以提高查询效率。因为索引index文件只保留一部分键,所以MapFile不能够提供枚举或计算所有的键的方法,唯一的办法是读取整个data文件
下面可以根据index的索引seek定位到相应位置后读取相应记录:
publicstaticvoid main(String[] args) throws IOException {
String uri = "hdfs://hadoop-master:9000/map/data";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
reader.seek(4013);
System.out.print("[" + reader.getPosition() + "]");
reader.next(key, value);
System.out.println(key + " " + value + " [" + reader.getPosition() + "]");
} finally {
IOUtils.closeStream(reader);
}
}
[4013]128 Seven, 七 [4044]
14.2.2 读
MapFile遍历文件中所有记录与SequenceFile一样:先建一个MapFile.Reader实例,然后调用next()方法,直到返回为false到文件尾:
/** Read the next key/value pair in the map into <code>key</code> and
* <code>val</code>. Returns true if such a pair exists and false when at
* the end of the map */
publicsynchronizedboolean next(WritableComparable key, Writable val)
throws IOException {
通过调用get()方法可以随机访问文件中的数据:
/** Return the value for the named key, or null if none exists. */
publicsynchronized Writable get(WritableComparable key, Writable val)
throws IOException {
根据指定的key查找记录,如果返回null,说明没有相应的条目,如果找到相应的key,则将该键对应的值存入val参变量中
publicstaticvoid main(String[] args) throws IOException {
String uri = "hdfs://hadoop-master:9000/map/data";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
MapFile.Reader reader = null;
try {
//构造时,路径只需要传入目录即可,不能到data文件
reader = new MapFile.Reader(fs, "hdfs://hadoop-master:9000/map", conf);
IntWritable key = (IntWritable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
key.set(255);
//根据给定的key查找相应的记录
reader.get(key, value);
System.out.println(key + " " + value);// 255 One, 一
} finally {
IOUtils.closeStream(reader);
}
}
get()时,MapFile.Reader首先将index文件读入内存,接着对内存中的索引进行二分查找,最后在index中找到小于或等于搜索索引的键255,这里即为128,对应的data文件中的偏移量为4013,然后从这个位置顺序读取每条记录,拿出Key一个个与255进行对比,这里很不幸运,需要比较128(由io.map.index.interval决定)次直到找到键255为止。
getClosest()方法与get()方法类似,只不过它返回的是与指定键匹配的最接近的键,而不是在不匹配的返回null,更准确地说,如果MapFile包含指定的键,则返回对应的条目;否则,返回MapFile中的第一个大于(或小于,由相应的boolean参数指定)指定键的键
大型MapFile的索引全加载到内存会占据大量内存,如果不想将整个index加载到内存,不需要修改索引间隔之后再重建索引,而是在读取索引时设置io.map.index.skip属性(编程时可通过Configuration来设定)来加载一定比例的索引键,该属性通常设置为0,意味着加载index时不跳过索引键全部加载;如果设置为1,则表示加载index时每次跳过索引键中的一个,这样索引会减半;如果设置为2,则表示加载index时每次读取索引时跳过2个键,这样只加载索引的三分一的键,以此类推,设置的值越大,节省大量内存,但增加搜索时间
14.2.3 特殊的MapFile
l SetFile是一个特殊的MapFile,用于只存储Writable键的集合,键必须升序添加:
publicclass SetFile extends MapFile {
publicstaticclass Writer extends MapFile.Writer {
/** Append a key to a set. The key must be strictly greater than the
* previous key added to the set. */
publicvoid append(WritableComparable key) throws IOException{
append(key, NullWritable.get());//只存键。由于调用MapFile.Writer.append()方法实现,所以键也只能升序添加
}
. . .
/** Provide access to an existing set file. */
publicstaticclass Reader extends MapFile.Reader {
/** Read the next key in a set into <code>key</code>. Returns
* true if such a key exists and false when at the end of the set. */
publicboolean next(WritableComparable key)
throws IOException {
return next(key, NullWritable.get());//也只读取键
}
l ArrayFile也是一个特殊的MapFile,键是一个整型,表示数组中的元素索引,而值是一个Writable值
publicclass ArrayFile extends MapFile {
/** Write a new array file. */
publicstaticclass Writer extends MapFile.Writer {
private LongWritable count = new LongWritable(0);
/** Append a value to the file. */
publicsynchronizedvoid append(Writable value) throws IOException {
super.append(count, value); // add to map 键是元素索引
count.set(count.get()+1); // increment count 每添加一个元素后,索引加1
}
. . .
/** Provide access to an existing array file. */
publicstaticclass Reader extends MapFile.Reader {
private LongWritable key = new LongWritable();
/** Read and return the next value in the file. */
publicsynchronized Writable next(Writable value) throws IOException {
return next(key, value) ? value : null;//只返回值
}
/** Returns the key associated with the most recent call to {@link
* #seek(long)}, {@link #next(Writable)}, or {@link
* #get(long,Writable)}. */
publicsynchronizedlong key() throws IOException {//如果知道是第几个元素,则是可以调用此方法
returnkey.get();
}
/** Return the <code>n</code>th value in the file. */
publicsynchronized Writable get(long n, Writable value)//根据数组元素索引取值
throws IOException {
key.set(n);
return get(key, value);
}
l BloomMapFile文件构建在MapFile的基础之上:
publicclass BloomMapFile {
publicstaticfinal String BLOOM_FILE_NAME = "bloom";
publicstaticclass Writer extends MapFile.Writer {
唯一不同之处就是,除了data与index两个文件外,还增加了一个bloom文件,该bloom文件主要包含一张二进制的过滤表,该过滤表可以提高key-value的查询效率。在每一次写操作完成时,会更新这个过滤表,其实现源代码如下:
publicclass BloomMapFile {
publicstaticclass Writer extends MapFile.Writer {
publicsynchronizedvoid append(WritableComparable key, Writable val)
throws IOException {
super.append(key, val);
buf.reset();
key.write(buf);
bloomKey.set(byteArrayForBloomKey(buf), 1.0);
bloomFilter.add(bloomKey);
}
它有两个调优参数,一个是io.mapfile.bloom.size,指出map文件中大概有多少个条目;另一个是io.mapfile.bloom.error.rate , BloomMapFile中使用布隆过滤器失败比率. 如果减少这个值,使用的内存会成指数增长。
VERSION: 过滤器的版本号;
nbHash: 哈希函数的数量;
hashType: 哈希函数的类型;
vectorSize: 过滤表的大小;
nr: 该BloomFilter可记录key的最大数量;
currentNbRecord: 最后一个BloomFilter记录key的数量;
numer: BloomFilter的数量;
vectorSet: 过滤表;
14.2.4 将SequenceFile转换为MapFile
前提是SequenceFile里是按键升序存放的,这样才可以为它创建index文件
publicclass MapFileFixer {
publicstaticvoid main(String[] args) throws Exception {
String mapUri = "hdfs://hadoop-master:9000/sequence2map";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(mapUri), conf);
Path map = new Path(mapUri);
//如果data文件名不是data也是可以的,但这里为默认的data,所以指定MapFile.DATA_FILE_NAME即可
Path mapData = new Path(map, MapFile.DATA_FILE_NAME);
// Get key and value types from data sequence file
SequenceFile.Reader reader = new SequenceFile.Reader(fs, mapData, conf);
Class keyClass = reader.getKeyClass();
Class valueClass = reader.getValueClass();
reader.close();
// Create the map file index file
long entries = MapFile.fix(fs, map, keyClass, valueClass, false, conf);
System.out.printf("Created MapFile %s with %d entries\n", map, entries);
}
}
fix()方法通常用于重建已损坏的索引,如果要将某个SequenceFile转换为MapFile,则一般经过以下几步:
1、 保证SequenceFile里的数据是按键升序存放的,否则使用MapReduce任务对文件进行一次输入输出,就会自动排序合并,如:
//创建两个SequenceFile
publicclass SequenceFileCreate {
privatestaticfinal String[] DATA = { "One, 一", "Three, 三", "Five, 五", "Seven, 七", "Nine, 九" };
publicstaticvoid main(String[] args) throws IOException {
String uri = "hdfs://hadoop-master:9000/sequence/seq1";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
Path path2 = new Path("hdfs://hadoop-master:9000/sequence/seq2");
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null, writer2 = null;
try {
//创建第一个SequenceFile
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 10; i++) {
key.set(10 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
//创建第二个SequenceFile
writer2 = SequenceFile.createWriter(fs, conf, path2, key.getClass(), value.getClass());
for (int i = 10; i < 20; i++) {
key.set(30 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer2.getLength(), key, value);
writer2.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
IOUtils.closeStream(writer2);
}
}
}

//将前面生成的两个SequenceFile排序合并成一个SequenceFile文件
publicclass SequenceFileCovertMapFile {
publicstaticclass Mapper extends
org.apache.hadoop.mapreduce.Mapper<IntWritable, Text, IntWritable, Text> {
@Override
publicvoid map(IntWritable key, Text value, Context context) throws IOException,
InterruptedException {
context.write(key, value);
System.out.println("key=" + key + " value=" + value);
}
}
publicstaticclass Reducer extends
org.apache.hadoop.mapreduce.Reducer<IntWritable, Text, IntWritable, Text> {
@Override
publicvoid reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException,
InterruptedException {
for (Text value : values) {
context.write(key, value);
}
}
}
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "SequenceFileCovert");
job.setJarByClass(SequenceFileCovertMapFile.class);
job.setJobName("SequenceFileCovert");
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
// 注意这里要设置输入输出文件格式为SequenceFile
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(1);//默认就是1,一个Reduce就只输出一个文件,这样就将多个输入文件合并成一个文件了
SequenceFileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/sequence"));
SequenceFileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/sequence2map"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

2、 将SequenceFile文件名修改为data(hadoop fs -mv /sequence2map/part-r-00000 /sequence2map/data)
3、 使用最前面的MapFileFixer程序创建index
15 MapReduce应用开发
15.1 Configuration类
org.apache.hadoop.conf.Configuration类是用来读取特定格式XML配置文件的
<?xml version="1.0"?>
<configuration>
<property>
<name>color</name>
<value>yellow</value>
<description>Color</description>
</property>
<property>
<name>size</name>
<value>10</value>
<description>Size</description>
</property>
<property>
<name>weight</name>
<value>heavy</value>
<final>true</final> <!--该属性不能被后面加进来的同名属性覆盖-->
<description>Weight</description>
</property>
<property>
<name>size-weight</name>
<value>${size},${weight}</value><!—配置属性可以引用其他属性或系统属性-->
<description>Size and weight</description>
</property>
</configuration>
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");//如有多个XML,可以多添调用此方法添加,相同属性后面会覆盖前面的,除非前面是final属性
System.out.println(conf.get("color"));//yellow
System.out.println(conf.get("size"));//10
System.out.println(conf.get("breadth", "wide"));//wide 如果不存在breadth配置项,则返回后面给定的wide默认值
System.out.println(conf.get("size-weight"));//10,heavy
系统属性的优先级高于XML配置文件中定义的属性,但还是不能覆盖final为true的属性:
System.setProperty("size", "14");//系统属性
System.out.println(conf.get("size-weight"));//14,heavy
系统属性还可以通过JVM参数 -Dproperty=value 来设置
虽然可以通过系统属性来覆盖XML配置文件中非final属性,但如果XML中不存在该属性,则仅配置系统属性后,通过Configuration是获取不到的:
System.setProperty("length", "2");
System.out.println(conf.get("length"));//null 由于XML中未配置length这个属性,所以为null
15.2 作业调用


16 MapReduce工作原理
在1.X及以前版本中,mapred.job.tracker决定了执行MapReuce程序的方式。如果这个配置属性被设置为local(默认值),则使用本地的作业运行器。
如果mapred.job.tracker被设置为用冒号分开的主机和端口,那么该配置属性就被解释为一个jobtracker地址,运行器则将作业提交该地址的jobtracker
Hadoop2.0引入了一种新的执行机制,即Yarn资源管理运行框架,是否使用此执行框架,则由mapreduce.framework.name属性来决定,它有三种取值:
1、 local,表示本地的作业运行器
2、 classic表示不使用Yarn执行框架,而是经典的MapReduce框架,也称MapReduce1,它使用一个jobtracker和多个tasktracker,
3、 yarn表示使用新的框架
16.1 经典的mapreduce(MapReduce 1)
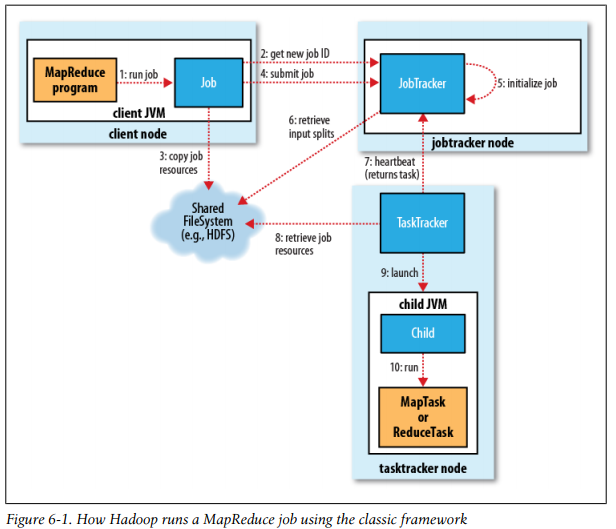
提交作业后,waitForCompletion()每秒轮询作业的进度,如果发现自上次报告后有改变,则把进度报告到控制台
将作业资源JAR包拷贝到 HDFS中(步骤3),并且有多个副本,这个副本数由mapred.submit.replication决定,默认为10。因此,运行作业时,集群中有很多个副本可供tasktracker访问
当JobTracker接收到对其submitJob()方法调用后,把此调用放入一个内部队列中,交由作业调度器(job scheduler)进行调度(步骤4)
为了创建任务运行列表,Jobtracker上的作业调度器首先从共享文件系统中获取客户端已经计算好的输入分片(步骤6),然后为每个分片创建一个map任务;创建的reduce任务的数量是由Job的mapred.reduce.tasks属性决定,也可用setNumReduceTasks()方法来设置,然后调度器创建相应数量的reduce任务
tasktracker运行一个简的循环来定期发送心跳给jobtracket
对于map任务,jobtracker会考虑tasktracker的网络位置,并选取一个距离其输入分片文件最近的tasktracker。在最理想的情况下,任务是数据本地化的(data-local),也就是任务运行在输入分片所在的节点上;同样,任务也可能是机架本地化的(rack-local):任务和输入分片在同一个机架,但不在同一节点上;另外,一些任务即不是数据本地化,也不是机架本地化,数据是来自于不同机器上的节点,此情况是最差的一种
被分配任务的tasktracker会从共享文件系统把任务的JAR文件复制到tasktracker所在的节点中,同时,tasktracker将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。然后,tasktracker为任务新建一个本地工作目录,并把JAR文件中的内容解压到这个文件夹下,最后tasktracker新建一个TaskRunner实例来运行该任务
作业状态更新:
16.2 YARN(MapReduce 2)
如果要使用YARN(MapReduce 2)来运行MapReduce任务的话,需要将mapreduce.framework.name设置为yarn
与经典MapReduce 1一样,也会将作业资源打包成JAR并上传到HDFS系统中,也是多个副本存放(步骤3),最后并通过调用资源管理器resourcemanager的submitApplication()方法提交作用(步骤4);resourcemanager收到调用它的submitApplication()消息后,便将请求传递给调度器(scheduler)。调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动应用程序的master进程(步骤5a和5b)
MapReduce作业的application master是一个Java应用程序,它的主类是MRAppMaster。它对每个分片创建一个map任务,以及创建mapreduce.job.reduces个reduce任务
如果作用很小,application master就选择MapReduce作业在与它同一个JVM上运行任务,这样的作业称为uberized,或者作为uber任务运行。但MapReduce 1从不在单个tasktracker上运行小作业
小作业就是map任务小于10,只有一个reduce且输入小于一个HDFS块大小(可以通过修改mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces, and mapreduce.job.ubertask.maxbytes的值来改变uber的限制范围),然后也可以单独设置mapreduce.job.ubertask.enable为false来关闭作为uber任务来运行
如果作业不适合作用为uber任务运行,那么application master就会为该作业中的所有map任务和reduce任务向资源管理器resourcemanager请求容器(步骤8),然后根据心跳信息里的数据分片所在位置信息,以最优的方式将任务分配到离数据最近的节点上执行
默认情况下,map任务与reduce任务都分配1024MB内存,但可以通过mapreduce.map.memory.mb 与 mapreduce.reduce.memory.mb来修改。在MapReduce 1中,tasktrackers在集群配置时设置了固定的“slots槽”,每个任务在一个slots里运行,每个slots的内存也是固定分配的,导致任务占用较小内存时无法充分利用内存以及大任务内存不足的问题;在YARN中,资源分配更细,所以可以避免上述问题。应用程序可以请求最小到最大限制范围内的任意最小值位数的内存容量,默认值最小值是1024MB(由yarn.scheduler.capacity.minimum-allocation-mb设定),默认的最大值是10240MB(由yarn.scheduler.capacity.maximum-allocation-mb设置),因此,任务可以通过适当设置mapreduce.map.memory.mb 与 mapreduce.reduce.memory.mb来请求1GB到10GB间的任意1GB倍数的内存容量
一量资源管理器的调度器为任务分配了容器,application master就通过与节点管理器通信来启动容器(步骤9a,9b),该任务由主类为YarnChild的Java应用程序执行。在它运行任务前,首先将任务需要的资源本地化,包括作业的配置、JAR文件和所有来自分布式缓存的文件(步骤10)。最后,运行map任务或reduce任务(步骤11)
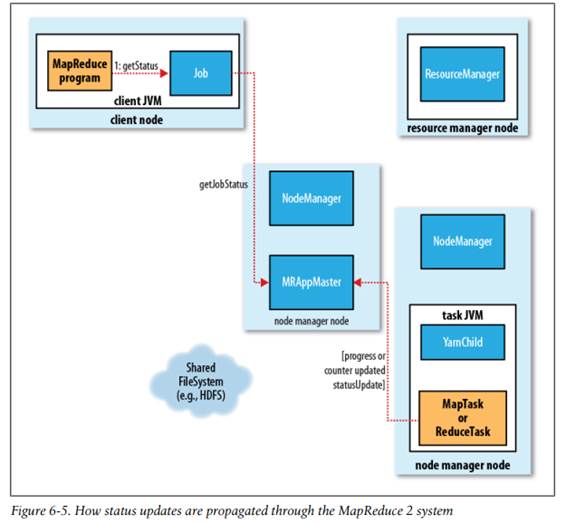
16.3 Shuffle and Sort
MapReduce要求每个reducer的输入都是按键排序的。
Shuffle描述着数据从map task输出到reduce task输入的这段过程
16.3.1 Shuffle详解
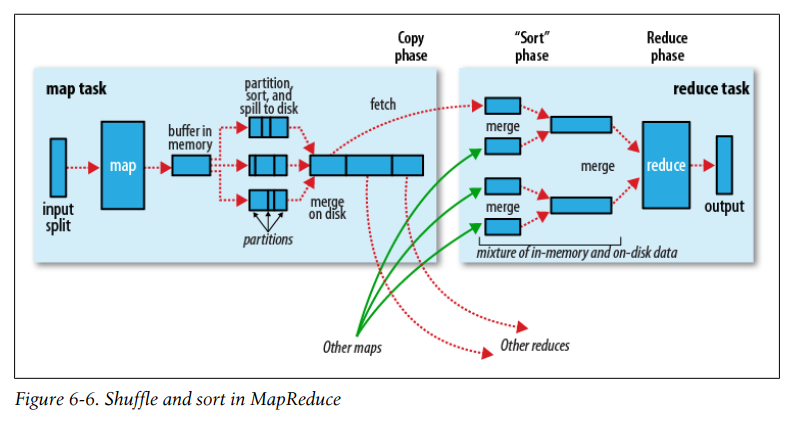
以WordCount为例,并假设它有8个map task和3个reduce task。从上图看出,Shuffle过程横跨map与reduce两端,所以下面我也会分两部分来展开。
先看看map端的情况,如下图:
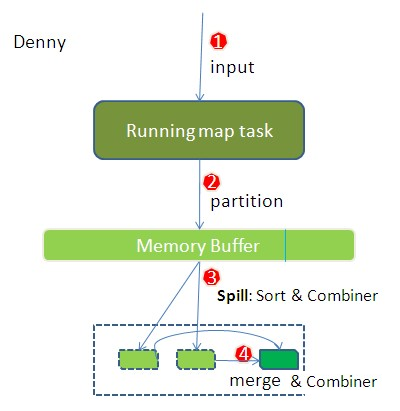
上图可能是某个map task的运行情况。拿它与官方图的左半边比较,会发现很多不一致。官方图没有清楚地说明partition, sort与combiner到底作用在哪个阶段。我画了这张图,希望让大家清晰地了解从map数据输入到map端所有数据准备好的全过程。
整个流程我分了四步。简单些可以这样说,每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
当然这里的每一步都可能包含着多个步骤与细节,下面我对细节来一一说明:
① 在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。在WordCount例子里,假设map的输入数据都是像“aaa”这样的字符串。
② 在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“aaa”, value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。前面我们知道这个job有3个reduce task,到底当前的“aaa”应该交由哪个reduce去做呢,这就是分区,是需要现在(Map输出结果写入到缓冲时)决定的。疑问:分区到底是在map输出写入缓冲前完成的还是溢写磁盘前完成的?这与官方图矛盾!!!
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
在我们的例子中,“aaa”经过Partitioner后返回0,也就是这对值应当交由第一个reducer来处理。接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
整个内存缓冲区就是一个字节数组,它的字节索引及key/value存储结构我没有研究过。如果有朋友对它有研究,那么请大致描述下它的细节吧。
③ 这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要在溢写前(生成溢写文件时)对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
在这里我们可以想想,因为map task的输出是需要发送到不同的reduce端去,而内存缓冲区没有对将发送到相同reduce端的数据做合并(但会做分区),那么这种合并应该是体现是磁盘文件中的。从官方图上也可以看到写到磁盘中的溢写文件是对不同的reduce端的数值做过合并。所以溢写过程一个很重要的细节在于,如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录。
在针对每个reduce端而合并数据时,有些数据可能像这样:“aaa”/1, “aaa”/1。对于WordCount例子,就是简单地统计单词出现的次数,如果在同一个map task的结果中有很多个像“aaa”一样出现多次的key,我们就应该把它们的值合并到一块,这个过程叫reduce也叫combiner。但MapReduce的术语中,reduce只指reduce端执行从多个map task取数据做计算的过程,除reduce外,非正式地合并数据只能算做combine了。其实大家知道的,MapReduce中将Combiner等同于Reducer,所以其输出结果与Reducer输出是一样的,只是部分reduce过程提前到map端来完成。
如果client设置过Combiner,那么现在(溢写时)就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等,但不适用于求平均值。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
④ 每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。Merge是怎样的?如前面的例子,“aaa”从某个溢写文件中读取过来时值是5,从另外一个溢写文件读取来的值是8,因为它们有相同的key,所以得merge成group。什么是group。对于“aaa”就是像这样的:{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。请注意,因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中(合并时)如果client设置过Combiner,也会使用Combiner来合并相同的key。
至此,map端的所有工作都已结束,最终生成的这个文件也存放在TaskTracker够得着的某个本地目录内。每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息,如果reduce task得到通知,获知某台TaskTracker上的map task执行完成,Shuffle的后半段过程开始启动。
简单地说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。见下图:
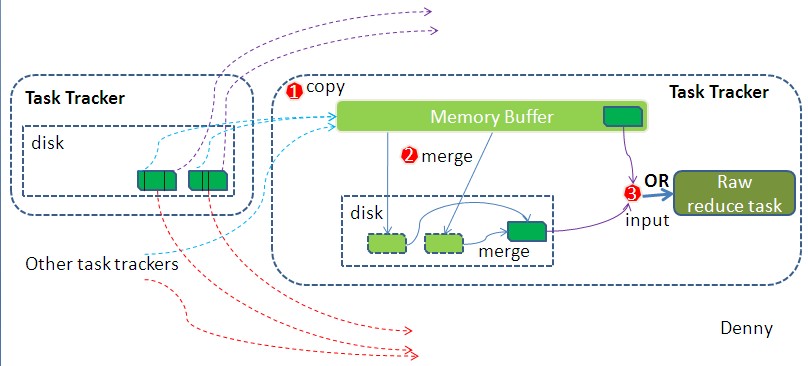
如map 端的细节图,Shuffle在reduce端的过程也能用图上标明的三点来概括。当前reduce copy数据的前提是它要从JobTracker获得有哪些map task已执行结束,这段过程不表,有兴趣的朋友可以关注下。Reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地在做。如前面的方式一样,下面我也分段地描述reduce 端的Shuffle细节:
① Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
② Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式(内存到磁盘)一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
③ Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,之后的性能优化篇我再说。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
16.3.2 map端
当map task开始运算,并产生中间数据时,其产生的中间结果并非直接就简单的写入磁盘。这中间的过程比较复杂,并且利用到了内存buffer来进行已经产生的部分结果的缓存,并在内存buffer中进行一些预排序来优化整个map的性能。每一个map都会对应存在一个内存buffer(MapOutputBuffer,即上图的buffer in memory),map会将已经产生的部分结果先写入到该buffer中,这个buffer默认是100MB大小,此值可以通过修改io.sort.mb(mapred-default.xml)配置项一调整。当map的产生数据非常大时,并且把io.sort.mb调大,那么map在整个计算过程中spill的次数就势必会降低,map task对磁盘的操作就会变少,如果map tasks的瓶颈在磁盘上,这样调整就会大大提高map的计算性能。map做sort和spill的内存结构如下如所示:
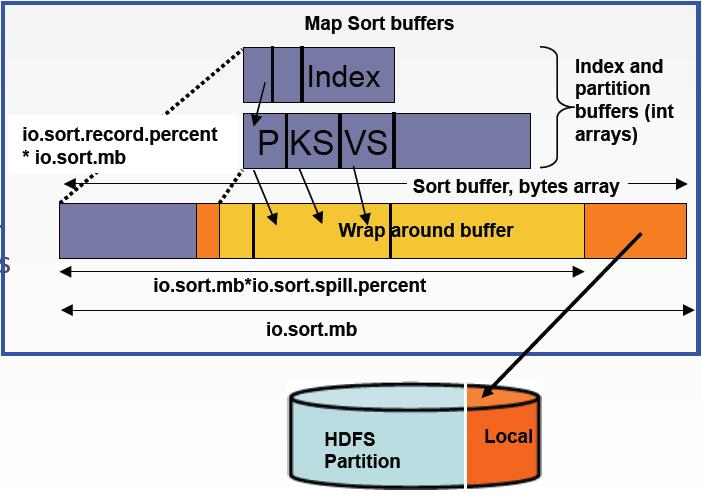
map在运行过程中,不停的向该buffer中写入已有的计算结果,但是该buffer并不一定能将全部的map输出缓存下来,当map输出超出一定阈值(比如100M),那么map就必须将该buffer中的数据写入到磁盘中去,这个过程在mapreduce中叫做spill,在溢写时,map的输出继续写到缓冲区(那剩下的20%空闲空间),但如果在此期间缓冲区被填满(指那剩下的20%空闲也被使用完了),则map会被阻塞直到写磁盘过程完成。map并不是要等到将该buffer全部写满时才进行spill,因为如果全部写满了再去写spill,势必会造成map的计算部分等待buffer释放空间的情况。所以,map其实是当buffer被写满到一定程度(比如80%)时,就开始进行spill。这个阈值也是由一个job的配置参数来控制,即io.sort.spill.percent,默认为0.80或80%。这个参数同样也是影响spill频繁程度,进而影响map task运行周期对磁盘的读写频率的。但非特殊情况下,通常不需要人为的调整。调整io.sort.mb对用户来说更加方便。
当map task的计算部分全部完成后,就会生成一个或者多个spill文件,这些文件就是map的输出结果。map在正常退出之前,需要将这些spill合并(merge)成一个,所以map在结束之前还有一个merge的过程。merge的过程中,有一个参数可以调整这个过程的行为,该参数为:io.sort.factor。该参数默认为10。它表示当merge spill文件时,最多能有多少并行的stream(即可以同时打开多少个文件进行读取)向merge文件中写入。比如如果map产生的数据非常的大,产生的spill文件大于10,而io.sort.factor使用的是默认的10,那么当map计算完成做merge时,就没有办法一次将所有的spill文件merge成一个,而是会分多次,每次最多10个stream。这也就是说,当map的中间结果非常大,调大io.sort.factor,有利于减少merge次数,进而减少map对磁盘的读写频率,有可能达到优化作业的目的。
当job指定了combiner的时候,我们都知道map介绍后会在map端根据combiner定义的函数将map结果进行合并。运行combiner函数的时机有可能会是merge完成之前,或者之后,这个时机可以由一个参数控制,即min.num.spills.for.combine(default 3),当job中设定了combiner,并且spill数最少有3个的时候,那么combiner函数就会在merge产生结果文件之前运行。通过这样的方式,就可以在spill非常多需要merge,并且很多数据需要做conbine的时候,减少写入到磁盘文件的数据数量,同样是为了减少对磁盘的读写频率,有可能达到优化作业的目的。
减少中间结果读写进出磁盘的方法不止这些,还有就是压缩。也就是说map的中间,无论是spill的时候,还是最后merge产生的结果文件,都是可以压缩的。压缩的好处在于,通过压缩减少写入读出磁盘的数据量。对中间结果非常大,磁盘速度成为map执行瓶颈的job,尤其有用。控制map中间结果是否使用压缩的参数为:mapred.compress.map.output(true/false)。将这个参数设置为true时,那么map在写中间结果时,就会将数据压缩后再写入磁盘,读结果时也会采用先解压后读取数据。这样做的后果就是:写入磁盘的中间结果数据量会变少,但是cpu会消耗一些用来压缩和解压。所以这种方式通常适合job中间结果非常大,瓶颈不在cpu,而是在磁盘的读写的情况。说的直白一些就是用cpu换IO。根据观察,通常大部分的作业cpu都不是瓶颈,除非运算逻辑异常复杂。所以对中间结果采用压缩通常来说是有收益的。以下是一个wordcount中间结果采用压缩和不采用压缩产生的map中间结果本地磁盘读写的数据量对比:
map中间结果不压缩:
map中间结果压缩:
可以看出,同样的job,同样的数据,在采用压缩的情况下,map中间结果能缩小将近10倍,如果map的瓶颈在磁盘,那么job的性能提升将会非常可观。
当采用map中间结果压缩的情况下,用户还可以选择压缩时采用哪种压缩格式进行压缩,现在hadoop支持的压缩格式有:GzipCodec,LzoCodec,BZip2Codec,LzmaCodec等压缩格式。通常来说,想要达到比较平衡的cpu和磁盘压缩比,LzoCodec比较适合。但也要取决于job的具体情况。用户若想要自行选择中间结果的压缩算法,可以设置配置参数:mapred.map.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec或者其他用户自行选择的压缩方式。
-------------------------------------------------------------------------------------------------------------------------------
溢写文件存放目录由mapred.local.dir配置项指定
在写磁盘之前,线程首先根据reducer的数量把数据划分成相应数据的分区(partition)。每个分区中的数据都会按键在内存中进行排序,如果指定了combiner,则对排序输出再次运行combiner方法。运行combiner可以减少map的输出,这样就减少写到磁盘的数据和传递给reducer的数据
每次溢写都会产生一个文件,所以同一个map任务的输出是有可能会产生多个文件,在Map任务完成后,会将这些溢写文件再次分区排序写入到一个总的文件中,每次可以合并多少个文件由io.sort.factor(默认值为10,即可打开10 I/O同时进行文件操作)控制;如果至少存在3(由min.num.spills.for.combine设置)个及以上的溢写文件合并时,在输出到文件时前会再次调用combiner对数据进行合并计算(如果设置了combiner,在写spill文件的时候也会调用)。combiner可以反复调用而不会影响输出结果。如果只有一两个溢写文件需要合并,是不会(不值得)调用combiner
如果将写到磁盘的map输出数据进行压缩,将会节约磁盘空间,写减少写磁盘时间,且还可以减少传递给reducer的时间。默认情况下是不开启Map输出压缩的,但可以通过配置mapred.compress.map.output属性为true,则可以自动开启,并且压缩方法由mapred.map.output.compression.codec属性指定
map输出的分区文件是通过HTTP方式传递给reducer端的,map端上(每个tasktracker)默认开40个(可由tasktracker.http.threads配置)HTTP服务线程来为文件传输工作。在MapReduce 2中,该配置属性不适用,因为使用最大线程数是由机器处理器数量自动设定的,默认情况下允许值为处理数量的两倍
16.3.3 reduce端
reduce的运行是分成三个阶段的。分别为copy->sort->reduce。由于job的每一个map都会根据reduce数n将数据分成n个partition,所以map的中间结果中是有可能包含多个reduce需要处理的部分数据的。所以,为了优化reduce的执行时间,hadoop中是等job的第一个map结束后,所有的reduce就开始尝试从完成的map中下载该reduce对应的partition部分数据(而不是等到所有map任务都完成后才开始copy)。这个过程就是通常所说的shuffle,也就是copy过程。
Reduce task在做shuffle时,实际上就是从不同的已经完成的map上去下载属于自己这个reduce的部分数据,由于map通常有许多个,所以对一个reduce来说,下载也可以是并行的从多个map下载,这个并行度是可以调整的,调整参数为:mapred.reduce.parallel.copies(default 5)。默认情况下,每个只会有5个并行的下载线程在从map下数据,如果一个时间段内job完成的map有100个或者更多,那么reduce也最多只能同时下载5个map的数据,所以这个参数比较适合map很多并且完成的比较快的job的情况下调大,有利于reduce更快的获取属于自己部分的数据。
reduce的每一个下载线程在下载某个map数据的时候,有可能因为那个map中间结果所在机器发生错误,或者中间结果的文件丢失,或者网络瞬断等等情 况,这样reduce的下载就有可能失败,所以reduce的下载线程并不会无休止的等待下去,当一定时间后下载仍然失败,那么下载线程就会放弃这次下载,并在随后尝试从另外的地方下载(因为这段时间map可能重跑)。所以reduce下载线程的这个最大的下载时间段是可以调整的,调整参数为:mapred.reduce.copy.backoff(default 300秒)。如果集群环境的网络本身是瓶颈,那么用户可以通过调大这个参数来避免reduce下载线程被误判为失败的情况。不过在网络环境比较好的情况下,没有必要调整。通常来说专业的集群网络不应该有太大问题,所以这个参数需要调整的情况不多。
Reduce将map结果下载到本地时,同样也是需要进行merge的,所以io.sort.factor的配置选项同样会影响reduce进行merge时的行为,该参数的详细介绍上文已经提到,当发现reduce在shuffle阶段io wait非常的高的时候,就有可能通过调大这个参数来加大一次merge时的并发吞吐,优化reduce效率。
Reduce在shuffle阶段对下载来的map数据,并不是立刻就写入磁盘的,而是会先缓存在内存中,然后当使用内存达到一定量的时候才刷入磁盘。这个内存大小的控制就不像map一样可以通过io.sort.mb来设定了,而是通过另外一个参数来设置:mapred.job.shuffle.input.buffer.percent(default 0.7),这个参数其实是一个百分比,意思是说,shuffile在reduce内存中的数据最多使用内存量为:0.7 * maxHeap of reduce task。也就是说,如果该reduce task的最大heap使用量(通常通过mapred.child.java.opts来设置,比如设置为-Xmx1024m)的一定比例用来缓存数据。默认情况下,reduce会使用其heap size的70%来在内存中缓存数据。如果reduce的heap由于业务原因调整的比较大,相应的缓存大小也会变大,这也是为什么reduce用来做缓存的参数是一个百分比,而不是一个固定的值了。
假设mapred.job.shuffle.input.buffer.percent为0.7,reduce task的max heapsize为1G,那么用来做下载数据缓存的内存就为大概700MB左右,这700M的内存,跟map端一样,也不是要等到全部写满才会往磁盘刷的,而是当这700M中被使用到了一定的限度(通常是一个百分比),就会开始往磁盘刷。这个限度阈值也是可以通过job参数来设定的,设定参数为:mapred.job.shuffle.merge.percent(default 0.66)。如果下载速度很快,很容易就把内存缓存撑满,那么调整一下这个参数有可能会对reduce的性能有所帮助。
当reduce将所有的map上对应自己partition的数据下载完成后,就会开始真正的reduce计算阶段(中间有个sort阶段通常时间非常短,几秒钟就完成了,因为整个下载阶段就已经是边下载边sort,然后边merge的)。当reduce task真正进入reduce函数的计算阶段的时候,有一个参数也是可以调整reduce的计算行为。也就是:mapred.job.reduce.input.buffer.percent(default 0.0)。由于reduce计算时肯定也是需要消耗内存的,而在读取reduce需要的数据时,同样是需要内存作为buffer,这个参数是控制,需要多少的内存百分比来作为reduce读已经sort好的数据的buffer百分比。默认情况下为0,也就是说,默认情况下,reduce是全部从磁盘开始读处理数据。如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,反正reduce的内存闲着也是闲着。
----------------------------------------------------------------------------------------------------------------------------------------------
map输出文件位于运行map任务机器的本地磁盘上(注:reduce输出不是这样的)
每一个分区数据都会启动一个reduce任务,同一分区数据可能来自于不同机器上的好几个不同的文件。所以一个reduce任务需所要的数据可能来自于好几个不同机器上的map 任务输出文件。
每个map任务完成的时间不相同,但只要有一个任务完成输出,reduce就会使用复制线程(默认为5个,可以修改mapred.reduce.parallel.copies)将map任务输出复制过来
如果从map任务复制到reducer端的数据能足够存放在JVM里的缓存(这个内存是通过mapred.job.shuffle.input.buffer.percent来配置,值是一个百分比,默认为0.7,即划出70%的JVM heap堆内存用来在shuffle过程中存放复制过来的map输出)中时,就不直接复制到reducer所在机器上的磁盘中,而是直接放在其内存中;当缓冲达到阈值大小(可由mapred.job.shuffle.merge.percent属性设定),或者存放的文件数达到阈值(由mapred.inmem.merge.threshold指定,默认为1000)时,就开始合并,并溢写到reducer磁盘中;如果指定了combiner,则还会在合并期间运行以减少写入硬盘的数据量
当不断有文件溢写到磁盘时,后台线程就开合并,而不是等到所有map输出都复制过来时才开始,这样可以为后面的合并节约时间
合并时,如果复制过来的数据是压缩的,会先解压
如果某个redue所需的map任务输出全部复制过来后,reduce task就会进入排序阶段,该阶段进行map输出合并,并维护其排序顺序。合并是循环进行的,假如有50个map输出,而且合并因子为10(即可同时打开10 I/O进行文件操作,可由io.sort.factor配置,默认为10),则合并将进行5趟,每趟将10个文件合并成一个文件,因此最后有5个中间文件。为了避免再次写磁盘,这5个文件并不会再次合并成一个文件,而是直接将这些文件输入到reduce函数。
当所有map任务输出数据都复制到reducer端并合并完成后,就进入了reduce阶段,对于每个输入的键值对就会调用一次reduce函数,并且reduce阶段的输出会直接写入到HDFS中,由于tasktracker node(或MapReduce 2 中的node manager)与data node在同一机器上,所以reduce输出第一个副本会放tasktracker node所在的data node中存储
每趟(round)合并的文件数与前面提供的实例可能有所不同,为了最终产生的文件个数最少为目的(这样可以减少写入到磁盘上的数据量,因为文件数越少,合并力度越大),例如40个文件,就会采用如下图合并的方式,第1趟只合并4个文件,第2、3、4趟合并10个文件,这样经过4趟后合并后,就会合并成4个文件,还剩6个文件,这样最后一趟(第5趟)将这最后10 = 4 + 6个文件合并成一个文件,这样总比经过4趟,每趟10个文件的要好,因为这最终会生成4个文件,不是最优合并法:

16.3.4 shuffle配置调优
通过调整shuffle过程的配置,可以提高MapReduce的性能,下面两个表总结了相应配置与默认值,这些设置都是以作业为单位的(除非特别说明)
|
配置项 |
类型 |
默认值 |
说明 |
|
io.sort.mb |
int |
100 |
Map任务输出内存缓冲区,单位M |
|
io.sort.record.percent |
float |
0.05 |
io.sort.mb中用来保存map output记录边界(即索引数据部分)的百分比,其他缓存用来保存数据。1.X版本后不在使用 |
|
io.sort.spill.percent |
float |
0.80 |
缓冲区存储达到这个百分比时,开始溢写 |
|
io.sort.factor |
int |
10 |
排序合并文件时,一次可合并处理的文件数,即同时可以打开10文件流,该配置项还用于reduce端 |
|
min.num.spills.for.combine |
int |
3 |
运行combiner所需最小spill溢写文件 |
|
mapred.compress.map.output |
boolean |
false |
压缩map输出 |
|
mapred.map.output.compression.codec |
Class name |
org.apache.hadoop.io.compress.DefaultCodec |
map输出压缩算法 |
|
tasktracker.http.threads |
int |
40 |
每个tasktracker上所开的http线程数,该HTTP服务线程用于将map输出传输到reduce端。该配置项是针对整个集群的,不是单个作业。在MapReduce 2中已不适用 |
总的原则是给shuffle过程尽量多提供内存空间。然而,有一个平衡问题,也就是要确保map函数和reduce函数能得到足够的内存来运行。这就是为什么编写map函数和reduce函数时尽量少用内存原因,它们不应该无限使用内存,例如应避免在map中堆积数据
运行map任务和reduce任务的JVM,其大小由mapred.child.java.opts属性设置,任务节点上的内存大小应该尽量大
在map端,可以通过避免多次溢写磁盘来获得最佳性能;一次是最佳的情况。如果估算map输出大小,就可以合理地设置ip.sort.*.属性来尽可能减少溢写的次数,具体而言,如增加io.sort.mb的值。MapReduce计数器(“Spilled records”)计算在作业运行整个阶段中溢定磁盘的记录数,这对于调优很有帮助,注:这个计数器包括map和reduce两端的溢写
在reduce端,中间数据全部驻留在内存时,就能获得最佳性能。在默认情况下,这是不可能发生的,因为所有内存一般都预留给reduce函数。但如果reduce函数的内存需求不大,把mapred.inmem.merge.threshold设置为0,把mapred.job.reduce.input.buffer.percent设置为1(或更低的值)就可以提升性能
|
配置项 |
类型 |
默认值 |
说明 |
|
mapred.reduce.parallel.copies |
int |
5 |
用于把map输出复制到reducer的线程数 |
|
mapred.reduce.copy.backoff |
int |
300 |
map输出复制到reducer过程中,由于种种原因可能失败,失败后reducer会自动重试,直到超过这个时间 |
|
io.sort.factor |
int |
10 |
这个参数也在map端使用,请参数map端 |
|
mapred.job.shuffle.input.buffer.percent |
float |
0.70 |
reduce端的shuffle阶段,将堆内存的百分之多少用来缓存从map端复制过来的数据 |
|
mapred.job.shuffle.merge.percent |
float |
0.66 |
reducer端用来接收map输出的缓冲(由mapred.job.shuffle.input.buffer.percent配置)使用空间达到此百分比时,就会将缓冲的内容合并溢写到磁盘 |
|
mapred.inmem.merge.threshold |
int |
1000 |
与前面mapred.job.shuffle.merge.percent参数一样,也是用来控制合并溢写的,如果从map节点取过来的map输出数,当达到这个数之后,也会进行合并溢写。如果为0,则不会生效,则合并溢写触发只能上面参数来控制了 |
|
mapred.job.reduce.input.buffer.percent |
float |
0.0 |
在reduce时,用来存储map输出缓冲所占堆内存的最大百分比。在reduce阶段,内存缓冲存放map输出不会大于此大小。在默认情况下,为了reducer有更多可用的内存,reduce开始前所有map输出都会被merge到磁盘。但是,如果reducer需要较少内存时可以增加该值来减少写磁盘的次数 |
Hadoop读取文件时使用默认为4KB的缓冲区,这是很低的,因此应该在集群中增加这个值(通过设置io.file.buffer.size)
16.4 hadoop 配置项的调优
l dfs.block.size
文件块大小,由它决定HDFS文件block数量的多少(文件个数,块越大,文件个数越小),它会间接的影响Job Tracker的调度和内存的占用(更影响内存的使用)
l mapred.map.tasks.speculative.execution
l mapred.reduce.tasks.speculative.execution
这是两个推测式执行的配置项,默认是true
所谓的推测执行,就是当所有task都开始运行之后,Job Tracker会统计所有任务的平均进度,如果某个task所在的task node机器配
置比较低或者CPU load很高(原因很多),导致任务执行比总体任务的平均执行要慢,此时Job Tracker会启动一个新的任务(duplicate task),原有任务和新任务哪个先执行完就把另外一个kill掉,这也是我们经常在Job Tracker页面看到任务执行成功,但是总有些任务被kill,就是这个原因。
l mapred.child.java.opts
默认值-Xmx200m
运行map任务和reduce任务的JVM,其大小由mapred.child.java.opts属性设置,任务节点上的内存大小应该尽量大
l mapred.compress.map.output
压缩Map的输出,这样做有两个好处:
a)压缩是在内存中进行,所以写入map本地磁盘的数据就会变小,大大减少了本地IO次数
b) Reduce从每个map节点copy数据,也会明显降低网络传输的时间
l io.sort.mb
以MB为单位,默认100M,这个值比较小
map节点没运行完时,内存的数据过多,要将内存中的内容写入磁盘,这个设置就是设置内存缓冲的大小,在suffle之前这个选项定义了map输出结果在内存里占用buffer的大小,当buffer达到某个阈值(后面那条配置),会启动一个后台线程来对buffer的内容进行排序,然后写入本地磁盘(一个spill文件)
根据map输出数据量的大小,可以适当的调整buffer的大小,注意是适当的调整,并不是越大越好,假设内存无限大,
io.sort.mb=1024(1G), 和io.sort.mb=300 (300M),前者未必比后者快:
(1)1G的数据排序一次
(2)排序3次,每次300MB
一定是后者快(归并排序)
l io.sort.spill.percent
这个值就是上面提到的buffer的阈值,默认是0.8,既80%,当buffer中的数据达到这个阈值,后台线程会起来对buffer中已有的数
据进行排序,然后写入磁盘,此时map输出的数据继续往剩余的20% buffer写数据,如果buffer的剩余20%写满,排序还没结束,
map task被block等待。
如果你确认map输出的数据基本有序,排序时间很短,可以将这个阈值适当调高,更理想的,如果你的map输出是有序的数据,那
么可以把buffer设的更大,阈值设置为1.
l io.sort.factor
同时打开的文件句柄的数量,默认是10
当一个map task执行完之后,本地磁盘上(mapred.local.dir)有若干个spill文件,map task最后做的一件事就是执行merge sort,把这些spill文件合成一个文件(partition,combine阶段)。
执行merge sort的时候,每次同时打开多少个spill文件,就是由io.sort.factor决定的。打开的文件越多,不一定merge sort就越快,也要根据数据情况适当的调整。
注:merge排序的结果是两个文件,一个是index,另一个是数据文件,index文件记录了每个不同的key在数据文件中的偏移量(即partition)。
在map节点上,如果发现map所在的子节点的机器io比较重,原因可能是io.sort.factor这个设置的比较小,io.sort.factor设置小的话,如果spill文件比较多,merge成一个文件要很多轮读取操作,这样就提升了io的负载。io.sort.mb小了,也会增加io的负载。
如果设置了执行combine的话,combine只是在merge的时候,增加了一步操作,不会改变merge的流程,所以combine不会减少或者增加文件个数。另外有个min.num.spills.for.combine的参数,表示执行一个merge操作时,如果输入文件数小于这个数字,就不调用combiner。如果设置了combiner,在写spill文件的时候也会调用,这样加上merge时候的调用,就会执行两次combine。
提高Reduce的执行效率,除了在Hadoop框架方面的优化,重点还是在代码逻辑上的优化.比如:对Reduce接受到的value可能有重
复的,此时如果用Java的Set或者STL的Set来达到去重的目的,那么这个程序不是扩展良好的(non-scalable),受到数据量的限制,当数据膨胀,内存势必会溢出
l mapred.reduce.parallel.copies
Reduce copy数据的线程数量,默认值是5
Reduce到每个完成的Map Task 拷贝数据(通过RPC调用),默认同时启动5个线程到map节点取数据。这个配置还是很关键的,如果你的map输出数据很大,有时候会发现map早就100%了,reduce却在缓慢的变化,那就是copy数据太慢了,比如5个线程copy 10G的数据,确实会很慢,这时就要调整这个参数,但是调整的太大,容易造成集群拥堵,所以 Job tuning(调优)的同时,也是个权衡的过程,要熟悉所用的数据!
l mapred.job.shuffle.input.buffer.percent
当指定了JVM的堆内存最大值以后,上面这个配置项就是Reduce用来存放从Map节点复制过来的数据所用的内存占堆内存的比例,默认是0.7,既70%,通常这个比例是够了,但是对于大数据的情况,这个比例还是小了一些,0.8-0.9之间比较合适。(前提是你的reduce函数不会疯狂的吃掉内存)
l mapred.job.shuffle.merge.percent(默认值0.66)
l mapred.inmem.merge.threshold(默认值1000)
第一个指的是从Map节点取数据过来,放到内存,当达到这个阈值之后,后台启动线程(通常是Linux native process)把内存中的
数据merge sort,写到reduce节点的本地磁盘;
第二个指的是从map节点取过来的文件个数,当达到这个个数之后,也进行merger sort,然后写到reduce节点的本地磁盘;这两个配置项第一个优先判断,其次才判断第二个thresh-hold。
从实际经验来看,mapred.job.shuffle.merge.percent默认值偏小,完全可以设置到0.8左右;第二个默认值1000,完全取决于map输出数据的大小,如果map输出的数据很大,默认值1000反倒不好,应该小一些,如果map输出的数据不大(light weight),可以设置2000或者以上。
l mapred.reduce.slowstart.completed.maps
map完成多少百分比时,开始shuffle
当map运行慢,reduce运行很快时,如果不设置mapred.reduce.slowstart.completed.maps会使job的shuffle时间变的很长,map运行完很早就开始了reduce,导致reduce的slot一直处于被占用状态。mapred.reduce.slowstart.completed.maps 这个值是和“运行完的map数除以总map数”做判断的,当后者大于等于设定的值时,开始reduce的shuffle。所以当map比reduce的执行时间多很多时,可以调整这个值(0.75,0.80,0.85及以上),默认为0.05
16.5 MapReduce作业的默认配置
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
publicclass T {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "XXX");
job.setJarByClass(T.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/all/1901.all"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/output2"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
上面这个示例什么与没有指定,就指定了输入也输出位置,输入结果:
每一行以整数开始,表示每行中Value所在原输入文件的行起始偏移量,值就是原输入文件的每行内容。虽然这个程序不是很有用的程序,但对于理解它如何产生输出是很有用的
上面示例代码没有显示的设置输入输出参数类型以及map、reduce类,那是因为使用了默认设置,下面粗体就是默认设置,只不过通过程序显示指定了:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
publicclass T {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "XXX");
job.setJarByClass(T.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(Mapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setReducerClass(Reducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/all/1901.all"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/output2"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
默认的输入文件格式为TextInputFormat,它产生的键类型是LongWritable(文件中每行起始偏移量),值类型是Text(文本行)
默认的mapper是org.apache.hadoop.mapreduce.Mapper(我们实现的map()方法就是继承这个类然后重写的)类,它将输入的键和值原封不动地写到输出中:
publicclass Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protectedvoid map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
默认的partitioner是HashPartitioner,它对每条记录的键进行哈希操作以决定该记录(键值对)应该属于哪个分区。每个分区对应一个reducer任务,所以分区数等于作业的reducer个数:
publicclass HashPartitioner<K, V> extends Partitioner<K, V> {
publicint getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
键的哈希码被转换为一个非负整数,它由哈希值与最大的整型值做一次按位与操作而获得,然后用分区数进行取模操作,来决定该记录属于哪个分区索引(即该键值对应该复制到哪个reduce任务上去)。
默认情况下,只有一个reducer,因此也就只有一个分区,在这种情况下,由于所有数据都放入同一个分区,partitioner操作将变得无关紧要了。然后,如果有很多reducer,了解HashPartitioner的作用就非常重要了。假设基于键的散列函数足够好,那么记录将被均匀分到若干个reduce任务中,这样,具有相同键的记录将由同一个reduce任务进行处理
注:map任务数据并不能设置,该数量等于输入文件被划分成的分块数,这取决于输入文件的大小以及文件块的大小
默认的reducer是org.apache.hadoop.mapreduce.Reducer(我们实现的reduce()方法就是继承这个类然后重写的)类型,它简单地将所有的输入写到输出中:
publicclass Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
protectedvoid reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
}
默认的输出格式为TextOutputFormat,它将键和值转换成字符串并用制表符分隔开,然后一条记录一行地进行输出。这就是为什么输出文件是用制表符(Tab)分隔的,这是TextOutputFormat的特点
16.6 输入格式
16.6.1 输入分片与记录
一个分片(split)对应一个map任务处理,即每个map只处理一个输入分片。每个分片被划分为若干个记录,每条记录就是一个键值对,map是一个个处理记录的。输入分片和记录都是逻辑概念。
publicabstractclass InputSplit {
/**
* Get the size of the split, so that the input splits can be sorted by size.
* @return the number of bytes in the split
*/
publicabstractlong getLength() throws IOException, InterruptedException;
/**
* Get the list of nodes by name where the data for the split would be local.
* The locations do not need to be serialized.
* @return a new array of the node nodes.
*/
publicabstract String[] getLocations() throws IOException, InterruptedException;
}
InputSplit包括一个以字节为单位的长度和一组存储位置(即一组主机名)。注:分片并不数据本身,而是指向数据的引用(reference)。可以根据存储位置将map任务尽量放在分片数据附近。可以根据分片大小用来排序分片,以便优先处理最大的分片,从而最小化作业运行时间
我们不必直接处理InputSplit,因为它是由InputFormat创建的。InputFormat负责产生输入分片并将它们分割成记录
publicabstractclass InputFormat<K, V> {
/**
* Logically split the set of input files for the job.
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*/
publicabstract
List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException;
/**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
*/
publicabstract RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context ) throws IOException,
InterruptedException;
}
运行作业的客户端通过调用getSplits()获取逻辑分片列表,然后将它们发送到jobtracker,jobtracker使用其存储位置信息来调度map任务从而在tasktracker上处理这些分片数据。在tasktracker上,map任务把输入分片传给InputFormat的createRecordReader()方法获得这个分片的RecordReader。RecordReader就是记录上的迭代器,map任务通用RecordReader来生成记录的键值对,然后再传给map函数。从org.apache.hadoop.mapreduce.Mapper(我们实现的map()方法就是继承这个类然后重写的)的run()方法可以看到这一过程:
/**
* Expert users 专家用户可以重写这个run方法 can overridethis method for more complete control over the execution of the Mapper.
*/
publicvoid run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
运行完setup()方法之后,再循环调用Context上的nextKeyValue()方法,该方法会委托给RecordReader的同名方法来为mapper产生Key和value,如果未讲到stream的尾部时,借助于context委托调用同名方法(getCurrentKey(),getCurrentValue())将读取出来的key和value传给map()方法,这样我们就可以在map()方法里来处理一个个记录(键值对)了
通常情况下我们的mapper是从org.apache.hadoop.mapreduce.Mapper继承过来然后重写map()方法来实现,它有很多的子类:

MultithreadedMapper是Mapper的一个子类,它能以并行的方式来运行mapper,即启动一个线程来运行map()方法,MultithreadedMapper能启动多少个线程是可以通过mapreduce.mapper.multithreadedmapper.threads来配置的。在通常情况下我们继承org.apache.hadoop.mapreduce.Mapper就可以了,但如果map()方法需要花很长一段时间来处理每一条记录时(如需要连接外部服务器),就可以继承这个类,针对一个分片就可以实例化多个Mapper,让记录之间的处理是并行的,而不是串行的
16.6.1.1 FileInputFormat
FileInputFormat是使用文件作为数据源的基类,一切基于文件格式输入的实现都是从此类继承的:

FileInputFormat它有两个功用:一是提供作业输入文件的位置,二是将输入文件分片的实现代码;而将分片分割成记录则是由其子类来实现的
16.6.1.1.1 FileInputFormat文件路径
FileInputFormat提供了四种静态方法来设定Job的输入路径:
publicstaticvoid addInputPath(Job job, Path path)
publicstaticvoid addInputPaths(Job job, String commaSeparatedPaths)
publicstaticvoid setInputPaths(Job job, Path... inputPaths)
publicstaticvoid setInputPaths(Job job, String commaSeparatedPaths)
addInputPath与addInputPaths可以多次调用,它们是附加路径,而setInputPaths则是一次性设置完成的路径列表,并且以前设置的都会被替换掉
路径可以是一个文件、一个目录、或文件通配,如果是目录的话则包含这个目录下所有文件(默认情况下是不包含子目录,并且如果有子目录也会被当作文件看,这样运行时会产生错误,处理这个问题就是使用文件通配或过滤器来选择目录中的文件;但如果将mapred.input.dir.recursive设置为true时,就会递归读取子目录)
add与set方法指定了要包含的文件,如果要排除,可以使用setInputPathFilter()方法来设置一个过滤器:
publicstaticvoid setInputPathFilter(Job job, Class<? extends PathFilter> filter)
PathFilter过滤器的使用请参考前面
即使不使用过滤器,FileInputFormat也会使用一个默认的过滤器来排除隐藏文件(名称中以“.”和“_”开头的文件),如果通过setInputPathFilter方法设置了过滤器,它会在默认过滤器的基础上进行过滤
路径和过滤器也可以通过配置属性来设置:

16.6.1.1.2 InputSplit
InputSplit是指分片,在MapReduce当中作业中,作为map task最小输入单位。分片是基于文件基础上出来的而来的概念,通俗的理解一个文件可以切分为多少个片段(一个分片可包含的多个block,一个分片也可以来自多个文件——如CombineFileInputFormat输入)每个片段包括了“文件名,开始位置,长度,位于哪些主机”等信息。在MapTask拿到这些分片后,会知道从哪开始读取该map任务所处理的数据。注:InputSplit本身并没有存储数据,而只是记录了数据所在的地方
通过调用map()方法参数对象Context上的getInputSplit()方法,返回InputSplit对象,如果输入的文件是FileInputFormat,则是可以将InputSplit强转为FileSplit类型,然后就可以调用以下方法获取相应信息:
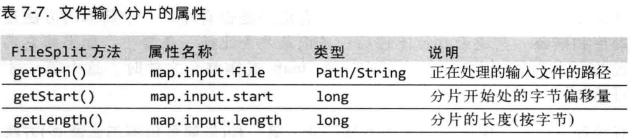
/** Constructs a split with host information
* @param file the file name 文件分片所在的文件路径,从这里来看,不是路径数组,只是单个路径,这说明一个FileSplit文件分片只对应一个文件,即FileSplit文件分片不会跨文件(但可能包含多个数据块),但CombineFileSplit分片是可以跨的文件的
* @param start the position of the first byte in the file to process 分片所在文件中的起始位置
* @param length the number of bytes in the file to process 分片长度
* @param hosts the list of hosts containing the block, possibly null 主机名是一个数组,因为一个文件是分块存放在不同的DataNode上的
*/
public FileSplit(Path file, long start, long length, String[] hosts) {
this.file = file;
this.start = start;
this.length = length;
this.hosts = hosts;
}
publicclass CombineFileSplit extends InputSplit implements Writable {
private Path[] paths;//该分片数据来自哪些文件(CombineFileSplit是跨文件的)。paths[]、startoffset[]、lengths[]这三个数组中的元素是一一对应的,这可以理解 CombineFileSplit是由很多个FileSplit组成的一样
privatelong[] startoffset;
privatelong[] lengths;
private String[] locations;
privatelongtotLength;//分片长度
FileInputFormat输入格式对应的是FileSplit、CombineFileInputFormat输入格式对应的是CombineFileSplit
16.6.1.1.3 FileInputFormat文件分片算法
FileInputFormat的getSplits()方法为逻辑分片算法,即如何将文件分成输入片断,为map任务提供输入数据
FileInputFormat的getSplits()返回的是FileSplit列表
下面三个配置属性可以用来控制分片大小:

mapred.min.split.size与mapred.max.split.size是在mapred-site.xml配置的,dfs.block.size是在hdfs-site.xml中配置的;其中mapred.max.split.size属性在旧API(org.apache.hadoop.mapred包下面的FileInputFormat)中没有使用(新API——org.apache.hadoop.mapreduce包下的FileInputFormat才会使用),所以如果使用的是旧API,则配置了mapred.max.split.size也不管用;如果配置文件中没有配置mapred.min.split.size与mapred.max.split.size这两属性,则它们在程序中会有相应默认值:1与最大的long;除了通过配置文件进行配置外,mapred.min.split.size与mapred.max.split.size还可以通过FileInputFormat的方法:setMinInputSplitSize()、setMaxInputSplitSize()方法分别进行设置。
FileInputFormat文件格式输入的分片大小(splitSize)由以下公式计算:
splitSize = max(minSize, min(maxSize, blockSize))
由于在默认情况下:
minSize < blockSize < maxSize
所以默认分片大小就是blockSize
计算公式可以查看FileInputFormat.computeSplitSize()方法:
protectedlong computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
该方法会被getSplits()方法调用:
longsplitSize= computeSplitSize(blockSize, minSize, maxSize);//splitSize即为分片大小,分片时就会根据此大小进行分片
上面计算公式具体为三步:
1、 minSize取值逻辑:minSize = Math.max(FormatMinSplitSize, MinSplitSize)
1) FormatMinSplitSize,本Format设置的最小Split大小,通过getFormatMinSplitSize()获取,程序里写死的是1个字节
2) MinSplitSize,通过配置文件属性mapred.min.split.size设置或通过程序方法setMinInputSplitSize()设置,通过getMinSplitSize()获取,未设置则为1
3) 取两者较大值。由于FormatMinSplitSize、MinSplitSize都为1,所以最终minSize还是为1
2、 Math.min(maxSize, blockSize)取值逻辑:
1) maxSize,通过配置文件属性mapred.max.split.size设置或通过程序方法setMaxInputSplitSize()设置,通过getMaxSplitSize()获取,无设置则取Long.MAX_VALUE
2) 文件块大小blockSize,由配置文件属性dfs.block.size设置
3) 取两者较小值
3、 再取 minSize、Math.min(maxSize, blockSize)的较大值

从上图可以看出mapred.min.split.size可以改变最小分片大小,如果将该值设置成比HDFS文件系统块大的话,这样就可以强迫分片比HDFS块大。这样做不是很好,因为这样的话,分片中的数据就可能跨不同的机器,这样map任务的数据就不是本地化数据了
16.6.1.1.3.1 Block和Split
1、 block是hdfs存储文件的单位(默认是64M);这是物理的划分,大文件上传到HDFS时,就会切分成若干块后分块存储
2、 InputSplit是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,每个InputSplit并没有对文件实际的切割,只是记录了要处理的数据的位置(包括文件的path和hosts)和长度(由start和length决定)。
Block和Split没有必然的关系,在分片时不是以Block为单位的,即一个Split可能包含了某个Block一部分
两个问题:
1、 Hadoop的一个Block默认是64M,在上传文件到HDFS中存储时,会不会从一行的中间进行切开?即一行会分到两个不同的Block中?
2、 在map任务处理前,会将输入文件进行逻辑分片,这会不会造成一行记录被分成两个InputSplit,如果被分成两个InputSplit,这样一个InputSplit里面就有一行不完整的数据,那么处理这个InputSplit的Mapper会不会得出不正确的结果?
答案:以行记录为输入单位的文本,是可能存在一行记录被划分到不同的Block,甚至不同的DataNode上去;再通过分析FileInputFormat里面的getSplits()方法,可以得出,某一行记录同样也可能被划分到不同的InputSplit:
long bytesRemaining = length;//整个文件大小
while (((double) bytesRemaining) / splitSize > 1.1) {//不是只要文件大小大于了分片大小,这个文件就立马进行分片的,而要求该文件大小超过分片大小的10%以上才会进行分片
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(new FileSplit(path, length - bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts()));//FileSplit即为一个逻辑分片,它记录了数据片断所对应的文件路径、起始偏量(length - bytesRemaining),以及长度(splitSize)等信息;从这里可以看出,一个FileSplit是不可能跨文件的,这可能与CombineFileSplit是不一样的
bytesRemaining -= splitSize; //剩下的部分再次循环分片
}
if (bytesRemaining != 0) {//最后不足一个分片大小时,也会创建一个分片
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
从上面的分片代码可以看出:
1、 一个FileSplit分片不能跨文件
2、 FileInputFormat对文件的切分是严格按照偏移量来的,所以会出现下后两种情况:
3、 一个FileSplit分片可以跨Block,甚至只包含某个Block的一部分(即一个Block可能被分割到几个FileSplit中)
4、 完全可能从行中间进行分片,这会造成同一行被分片到了不同的FileSplit分片中
尽管一行记录可能被拆分到不同的InputSplit,但是与FileInputFormat关联的RecordReader被设计的足够健壮,当一行记录跨InputSplit时,其能够到读取不同的InputSplit,直到把这一行记录读取完成;在Hadoop里,以行形式的输入文本,通常采用默认的TextInputFormat类来进行格式输入,TextInputFormat关联的是LineRecordReader,而LineRecordReader最终又是借助于LineReader来读取行的,而LineReader的readLine()方法解决了跨分片读取整行的问题(因为行是可以跨分片的,即同一行被分片到了不同的FileSplit分片中);另外,行跨分片会带来另一问题:该行数据会不会被重复读取的问题,其实重复读取问题是不会存在的,原因是LineRecordReader的initialize()初始化方法里解决了这个问题——会自动跳过最前面的半行
16.6.1.1.4 CombineFileInputFormat
CombineFileInputFormat适合处理大批量的小文件,它把多个文件打包到一个分片中以便每个mapper可以处理更多的数据,决定哪些文件放入同一分片时,CombineFileInputFormat会考虑到节点和机架因素,将相近的数据尽量打在一个包中
注:这里的小文件是指文件的大小是小于Block的,即每个文件只有一个Block,如果超一个Block,则就不太适用了
CombineFileInputFormat分片即不是以文件为单位,也不是以Block块为单位进行划分的(FileInputFormat切分时与文件及Block都是没关系,它直接是以字节为单位进行的,所以FileInputFormat切分出来的分片都是一样的——除最后一个分片外),而是在真正开始分片之前,预先将每个文件逻辑切分成若干个小的碎片(前提的文件是可切分的,即isSplitable),碎片切分算法如下:
long left = locations[i].getLength();//文件大小
long myOffset = locations[i].getOffset();//初始值固定为0
long myLength = 0;
while (left > 0) {
if (maxSize == 0) {
myLength = left;
} else {
if (left > maxSize && left < 2 * maxSize) {
// if remainder is between max and 2*max - then
// instead of creating splits of size max, left-max we
// create splits of size left/2 and left/2. This is
// a heuristic to avoid creating really really small
// splits.
myLength = left / 2;
} else {
myLength = Math.min(maxSize, left);
}
}
//文件碎片,关键信息为起始位置及碎片长度
OneBlockInfo oneblock = new OneBlockInfo(path, myOffset,
myLength, locations[i].getHosts(), locations[i].getTopologyPaths());
left -= myLength;
myOffset += myLength;
blocksList.add(oneblock);
}
预先将文件分成若干小碎片的好处是便于后面在真正分片时,是以这些小碎片为单位进行分片,这样可以将每个分片的大小分得更接近,但相对于FileInputFormat来说还是粒度粗了很多,所以导致CombineFileInputFormat分出的片断应该只能是大小相近
CombineFileInputFormat涉及到三个重要的属性:
mapreduce.input.fileinputformat.split.maxsize(或通过setMaxSplitSize()方法进行设置):同一节点或同一机架的数据块形成切片时,切片大小的最大值;
mapreduce.input.fileinputformat.split.minsize.per.node(或通过setMinSplitSizeNode()方法进行设置):同一节点的数据块形成切片时,切片大小的最小值;
mapreduce.input.fileinputformat.split.minsize.per.rack(或通过setMinSplitSizeRack()方法进行设置):同一机架的数据块形成切片时,切片大小的最小值。
注:这些属性都有相应的方法进行设置(CombineFileInputFormat.setMaxSplitSize()、CombineFileInputFormat.setMinSplitSizeNode()、CombineFileInputFormat.setMinSplitSizeRack ()),通过方法进行设置要优先于通过配置属性进行的设置
CombineFileInputFormat切片形成过程(具体可参考CombineFileInputFormat的getSplits()方法调用的getMoreSplits()方法):
(1)逐个节点形成切片;
a、遍历并累加这个节点上的数据块,如果累加数据块(这里的数据块就是上面预先分的碎片)大小大于或等于mapred.max.split.size,则将这些数据块形成一个切片,继承该过程,直到剩余数据块累加大小小于mapred.max.split.size,则进行下一步;
b、如果剩余数据块累加大小大于或等于mapred.min.split.size.per.node,则将这些剩余数据块形成一个切片,如果剩余数据块累加大小小于mapred.min.split.size.per.node,则这些数据块留待后续处理。
(2)逐个机架形成切片;
a、遍历并累加这个机架上的数据块(这些数据块即为上一步遗留下来的数据块),如果累加数据块大小大于或等于mapred.max.split.size,则将这些数据块形成一个切片,继承该过程,直到剩余数据块累加大小小于mapred.max.split.size,则进行下一步;
b、如果剩余数据块累加大小大于或等于mapred.min.split.size.per.rack,则将这些剩余数据块形成一个切片,如果剩余数据块累加大小小于mapred.min.split.size.per.rack,则这些数据块留待后续处理。
(3)遍历并累加所有机架上剩余数据块,如果数据块大小大于或等于mapred.max.split.size,则将这些数据块形成一个切片,继承该过程,直到剩余数据块累加大小小于mapred.max.split.size,则进行下一步;
(4)剩余数据块形成一个切片。
注:如果maxSplitSize,minSizeNode,minSizeRack三个都没有设置,那是所有输入整合成一个分片!
总结:
CombineFileInputFormat形成切片过程中考虑数据本地性(同一节点、同一机架),首先处理同一节点的数据块,然后处理同一机架的数据块,最后处理剩余的数据块,可见本地性是逐步减弱的
CombineFileInputFormat是一个抽象类,需要实现createRecordReader()方法
16.6.1.1.4.1 示例
1、实现CombineFileInputFormat:
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.CombineFileRecordReader;
import org.apache.hadoop.mapreduce.lib.input.CombineFileSplit;
publicclass CombineSmallfileInputFormat extendsCombineFileInputFormat<LongWritable, BytesWritable> {
@Override//使用CombineFileInputFormat时,需要实现createRecordReader()方法
public RecordReader<LongWritable, BytesWritable> createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException {
CombineFileSplit combineFileSplit = (CombineFileSplit) split;
//CombineSmallfileRecordReader为自定义的RecordReader
CombineFileRecordReader<LongWritable, BytesWritable> recordReader = new CombineFileRecordReader<LongWritable, BytesWritable>(combineFileSplit, context, CombineSmallfileRecordReader.class);
try {
recordReader.initialize(combineFileSplit, context);
} catch (InterruptedException e) {
new RuntimeException("Error to initialize CombineSmallfileRecordReader.");
}
return recordReader;
}
}
2、自定义RecordReader:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.CombineFileSplit;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.LineRecordReader;
publicclass CombineSmallfileRecordReader extendsRecordReader<LongWritable, BytesWritable> {
private CombineFileSplit combineFileSplit;
/*
* 该自定义的RecordReader实质上借助于LineRecordReader来实现的,免去了实现细节,除了构造与初始化
* 其它操作都可直接委派到相应的方法。但是LineRecordReader返回的Key是LongWritable,即文本的行号,
* 如果Key是自定义键(如复合Key),我们可以将LongWritable拷贝过来,然后修改它的nextKeyValue()方
* 法,将key使用自定义的Key类型即可
*/
private LineRecordReader lineRecordReader = new LineRecordReader();
private Path[] paths;//当前分片所有文件路径
privateinttotalLength;//所有文件数
privateintcurrentIndex;//当前正处理的数据块索引
privatefloatcurrentProgress = 0;//处理进度
private LongWritable currentKey;//键
private BytesWritable currentValue = new BytesWritable();//值
/*
* 该自定义RecordReader类一定要带有如下参数的构造函数,否则运行出错
*/
public CombineSmallfileRecordReader(CombineFileSplit combineFileSplit, TaskAttemptContext context,
Integer index) throws IOException {
super();
this.combineFileSplit = combineFileSplit;
this.currentIndex = index; // 当前要处理的小文件Block在CombineFileSplit中的索引
}
@Override
publicvoid initialize(InputSplit split, TaskAttemptContext context) throws IOException,
InterruptedException {
this.combineFileSplit = (CombineFileSplit) split;
// 处理CombineFileSplit中的一个小文件Block,因为使用LineRecordReader,需要构造一个FileSplit对象,然后才能够读取数据
FileSplit fileSplit = new FileSplit(combineFileSplit.getPath(currentIndex),
combineFileSplit.getOffset(currentIndex), combineFileSplit.getLength(currentIndex),
combineFileSplit.getLocations());
lineRecordReader.initialize(fileSplit, context);
this.paths = combineFileSplit.getPaths();
totalLength = paths.length;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
currentKey = lineRecordReader.getCurrentKey();
returncurrentKey;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
byte[] content = lineRecordReader.getCurrentValue().getBytes();
currentValue.set(content, 0, content.length);
returncurrentValue;
}
@Override
publicboolean nextKeyValue() throws IOException, InterruptedException {
if (currentIndex >= 0 && currentIndex < totalLength) {
returnlineRecordReader.nextKeyValue();
} else {
returnfalse;
}
}
@Override
publicfloat getProgress() throws IOException {
if (currentIndex >= 0 && currentIndex < totalLength) {
currentProgress = (float) currentIndex / totalLength;
returncurrentProgress;
}
returncurrentProgress;
}
@Override
publicvoid close() throws IOException {
lineRecordReader.close();
}
}
3、Job中使用
job.setInputFormatClass(CombineSmallfileInputFormat.class);
16.6.1.1.5 避免文件切分
有些情况下可能不希望文件被切分,而是用一个mapper完整处理每一个输入文件,例如,检查一个文件中所有记录是否有序,这种情况就不能切分,需要以文件为单位进行处理
有两种方法。第一种:增加最小分片大小属性的值,将它设置成大于要处理的最大文件大小,如设置为最大long;第二种方法就是重写FileInputFormat的isSplitable()方法,把返回值设置为false
16.6.1.1.6 示例:将整个文件作为一条记录处理
为了避免在HDFS中产生很多小文件,在产生很多小文件之前,可以使用SequenceFile将它们合成一个大的文件后放在HDFS中:可以将文件名作为键(如果不需要键,可以使用NullWritable代替),文件的内容作为值
先定义一个FileInputFormat:
//由于没有用到Key,所以使用NullWritable 代替,值是BytesWritable,存储整个文件内容
publicclass WholeFileInputFormat extends FileInputFormat<NullWritable, BytesWritable> {
@Override
protectedboolean isSplitable(JobContext context, Path file) {
returnfalse;//不切分文件
}
@Override
public RecordReader<NullWritable, BytesWritable> createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException, InterruptedException {
WholeFileRecordReader reader = new WholeFileRecordReader();
reader.initialize(split, context);
return reader;
}
}
再定义一个RecordReader:负责将FileSplit转换成一条记录
//不使用键,所以为NullWritable;值为BytesWritable类型,存储文件内容
class WholeFileRecordReader extends RecordReader<NullWritable, BytesWritable> {
private FileSplit fileSplit;
private Configuration conf;
private BytesWritable value = new BytesWritable();
privatebooleanprocessed = false;//记录是否已经被处理过
@Override
publicvoid initialize(InputSplit split, TaskAttemptContext context) throws IOException,
InterruptedException {
this.fileSplit = (FileSplit) split;
this.conf = context.getConfiguration();
}
@Override
publicboolean nextKeyValue() throws IOException, InterruptedException {
if (!processed) {
//缓冲用来存放文件内容,长度为分片大小(这里实为整个文件大小,因为isSplitable为false)
byte[] contents = newbyte[(int) fileSplit.getLength()];
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream in = null;
try {
in = fs.open(file);//打开文件
//读取文件
IOUtils.readFully(in, contents, 0, contents.length);
//将读取出来的文件字节数组转换为Writable对象
value.set(contents, 0, contents.length);
} finally {
IOUtils.closeStream(in);
}
processed = true;
returntrue;
}
returnfalse;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
returnvalue;
}
@Override
publicfloat getProgress() throws IOException {
returnprocessed ? 1.0f : 0.0f;
}
@Override
publicvoid close() throws IOException {
// do nothing 由于只有一条记录,读取完后nextKeyValue()方法自己就已将其关闭了,所以这里不需要再关闭
}
}
下面来使用上面自建的FileInputFormat,将多个小文件合并成一个大的序列文件(键为文件名,值为文件内容):
publicclass SmallFilesToSequenceFileConverter {
staticclass SequenceFileMapper extends Mapper<NullWritable, BytesWritable, Text, BytesWritable> {
private Text filenameKey;
@Override
protectedvoid setup(Context context) throws IOException, InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit) split).getPath();
filenameKey = new Text(path.toString());//文件名做为序列文件的Key
}
@Override
protectedvoid map(NullWritable key, BytesWritable value, Context context) throws IOException,
InterruptedException {
context.write(filenameKey, value);//文件名做为序列文件的Key
}
}
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = Job.getInstance(conf, "XXX");
job.setJarByClass(T.class);
//使用前面自定义的FileInputFormat
job.setInputFormatClass(WholeFileInputFormat.class);//使用前面自定义的FileInputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/smallfile"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/smallfile/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
a.txt~f.txt,每个文件中的内容为文件名相应的两字母,除e.txt没有内容,下面是合并成一个序列文件的结果:

至少有一种方法可以改进程序,一个mapper处理一个小文件的方法低效,所以较好的方法是继承CombineFileInputFormat而不是FileInputFormat
16.6.2 文本输入
16.6.2.1 TextInputFormat
在作业中未通过job.setInputFormatClass()方法指定InputFormat时,默认会使用TextInputFormat。
TextInputFormat格式输入文件里的内容:每一行文本就是一条记录键值对,即每行文本都会调用一次map()方法处理一次。键是LongWritable类型,键代表每一行文本在文件中的起始字节偏移量,第一行为0;值的类型是Text,存储的内容为这行的文本内容,不包括任何行终止符(换行和回车符)。所以,包含如下文本的文件被切分为包含4条记录的一个分片:

每条记录以键值对形式出现:
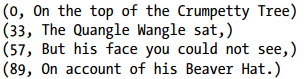
很明显,键并不是行号,因为文件按字节而不是按行切分为分片的,所以很难取得行号,每个分片又是单独不分先后顺序处理的,行号又是一个连续的标记,在分片内知道行号是可能的,但文件分成多个分片后就不可能了,所以Key是行文本的偏移量而不是行号的原因
文本行是完全有可能跨块Block与跨分片Split的,但FileInputFormat实现已解决了行的读取问题
16.6.2.2 KeyValueTextInputFormat
我们知道TextInputFormat的键是每一行在文件中的字节偏移量,通常没有什么用。如果输入文件中的每行都是由 键/值 构造,并且健与值之间使用某个分界符进行分隔,比如Tab,则可以使用KeyValueTextInputFormat进行输入,以下为例,其中 --> 表示制表符:

则使用KeyValueTextInputFormat格式化输入后,后形成的输入分片数据如下:

此时的键为每一行Tab制表符前在的字符串,而非行字节偏移量
可以通过mapreduce.input.keyvaluelinerecordreader.key.value.separator 属性 (旧API中为 key.value.separator.in.input.line)来指定分隔符,它默认为一个制表符
16.6.2.3 NLineInputFormat
NLineInputFormat与TextInputFormat是相似:健也是行字节偏移量,只是在分片时,根据N值来划分,即每个mapper会收到固定行数N的输入。N的默认值为1。
可以通过mapreduce.input.lineinputformat.linespermap属性(旧API中为mapred.line.input.format.linespermap)对N进行设置
如果有以下四行的文本:
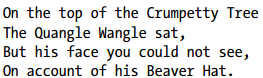
当N为2时,则每个输入分片包含两行,其中一个mapper收到的输入分片为:
![]()
另一个mapper眉目到的输入分片则为:
![]()
键和值与TextInputFormat生成的一样,不同的是输入分片的构造方式
16.6.2.4 XML
如果要处理XML类型的文件,则可以把输入格式设置为StreamInputFormat,把stream.recordreader.class属性设置为org.apache.hadoop.streaming.StreamXmlRecordReader
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapred.lib.MultipleInputs;
import org.apache.hadoop.streaming.StreamInputFormat;
import org.apache.hadoop.streaming.StreamXmlRecordReader;
publicclass XmlMR {
publicstaticclass MyMap extends MapReduceBase implements Mapper<Text, Text, Text, Text> {
@Override
publicvoid map(Text key, Text value, OutputCollector<Text, Text> ctx, Reporter r) throws IOException {
System.out.println("map :::::: " + key.toString() + " value = " + value); //注:value一直是空的
ctx.collect(key, key);
}
}
publicstaticclass MyReduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
@Override
publicvoid reduce(Text key, Iterator<Text> value, OutputCollector<Text, Text> ctx, Reporter r)
throws IOException {
StringBuffer sb = new StringBuffer();
while (value.hasNext()) {
Text v = value.next();
System.out.println("reduce :::::: " + v.toString() + " key = " + key);
sb.append(v.toString());
}
ctx.collect(new Text(key.getLength() + ""), new Text(sb.toString()));
}
}
//自定义StreamInputFormat,不让切分文件,因为经测试分片后,输入有重复,是因为分片造成的
publicstaticclass MyStreamInputFormat extends StreamInputFormat {
@Override
protectedboolean isSplitable(FileSystem fs, Path file) {
returnfalse;
}
}
publicstaticvoid main(String[] args) throws Exception {
String begin = "<property>";
String end = "</property>";
JobConf conf = new JobConf(XmlMR.class);
conf.setJobName("xmlMR");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(MyMap.class);
conf.setReducerClass(MyReduce.class);
conf.setInputFormat(MyStreamInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
conf.setJarByClass(XmlMR.class);
MyStreamInputFormat.addInputPath(conf, new Path("hdfs://hadoop-master:9000/xml/core-site.xml")); FileOutputFormat.setOutputPath(conf, new Path("hdfs://hadoop-master:9000/xml/output"));
conf.set("stream.recordreader.class", StreamXmlRecordReader.class.getName());
// hadoop会把包含起始结束标签之间的内容(包括起始标签)作为一个record传给map函数
conf.set("stream.recordreader.begin", begin);
conf.set("stream.recordreader.end", end);
conf.set("mapred.job.tracker", "hadoop-master:9001");
JobClient.runJob(conf);
}
}
目前好像只支持旧API
由于要使用hadoop-streaming-1.2.1.jar包,所以需要将它加入到类路中,修改hadoop-env.sh:
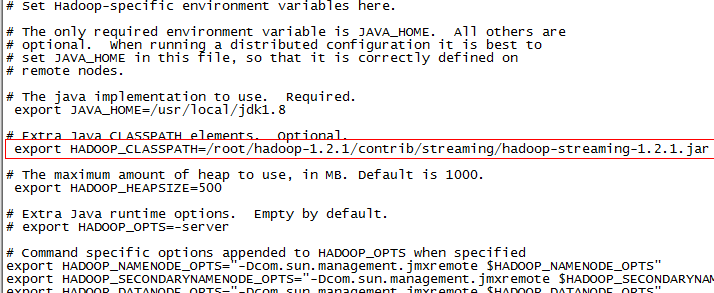
解析出的XML如下:

16.6.3 二进制输入
16.6.3.1 SequenceFileInputFormat
MapReduce除了可以处理文本文件外,还可以处理二进制的SequenceFile数据文件,sequence file格式的文件里存储的就是 二进制的键值对记录,sequence file相关详细信息请参考前面章节的SequenceFile。由于SequenceFile文件里存储了一定量的同步特殊标记点,该标记能快速定义到下一个记录的边界,所以这类文件也是可分片的(splittable),这类文件很适合MapReduce来处理,并且它还支持压缩,它还可以使用序列化技术存储任意类型的数据
如果要用顺序文件SequenceFile作为MapReduce的输入,应该使用SequenceFileInputFormat,键和值的类型由顺序文件决定
注:SequenceFileInputFormat除了可以读取SequenceFile外,还可以读取MapFiles,因为在处理顺序文件时如果遇到目录,SequenceFileInputFormat类会认为自己正在读取MapFile,此时则会读取其数据文件,所以这也就是为什么没有MapFileInputFormat类的原因
16.6.3.2 SequenceFileAsTextInputFormat
SequenceFileAsTextInputFormat是SequenceFileInputFormat的子类,它将顺序文件的键和值都转换为Text对象,即在键和值上调toString()方法来实现的
16.6.3.3 SequenceFileAsBinaryInputFormat
SequenceFileAsBinaryInputFormat也是SequenceFileInputFormat的子类,它将获取顺序文件的键和值作为二进制对象,它们被封装为BytesWritable对象。这些顺序文件可以由SequenceFile.Writer的appendRaw()或者是SequenceFileAsBinaryOutputFormat来生成
16.6.4 多个输入
MultipleInputs可以为每个输入路径指定个InputFormat和Mapper,如果输入是多个路径且数据格式不相同时,则不能使用同一个Mapper来解析输入,这时可以使用MultipleInputs来设定每个各自路径所对应的Mapper:
/**
* Add a {@link Path} with a custom {@link InputFormat} and
* {@link Mapper} to the list of inputs for the map-reduce job.
*
* @param job The {@link Job}
* @param path {@link Path} to be added to the list of inputs for the job
* @param inputFormatClass {@link InputFormat} class to use for this path
* @param mapperClass {@link Mapper} class to use for this path
*/
@SuppressWarnings("unchecked")
publicstaticvoid addInputPath(Job job, Path path,
Class<? extendsInputFormat> inputFormatClass,
Class<? extendsMapper> mapperClass) {
比英国Met Office与NCDC的气象数据放在一起来分析最高气温,则可以通过以下方式来设置输入路径:
MultipleInputs.addInputPath(job, ncdcInputPath,TextInputFormat.class, MaxTemperatureMapper.class);
MultipleInputs.addInputPath(job, metOfficeInputPath,TextInputFormat.class, MetOfficeMaxTemperatureMapper.class);
这段代码取代了对以前对FileInputFormat.addInputPath()与job.setMapperClass()调用,Met Office与NCDC都是文本数据,所以两者都使用TextInputFormat数据类型,但这两个数据源的行格式不同,所以我们使用了两个不一样的mapper。MaxTemperatureMapper读取NCDC的输入数据并抽取年份和气温了字段的值;MetOfficeMaxTemperatureMapper读取Met Office的输入数据,抽取年份和气温字段的值。
MultipleInputs类有一个重载版的addInputPath(),它没有mapper参数:
publicstaticvoid addInputPath(Job job, Path path, Class<? extends InputFormat> inputFormatClass)
如果有多种输入格式而只有一个mapper,则通过Job的setMapperClass()方法来统一设定mapper
16.6.5 数据库输入
DBInputFormat输入格式用于使用JDBC从关系数据库中读取数据。
注意:DBInputFormat内部实现机制没使用连接池,所以使用时要小心,不建议将Mapper任务数(mapred.map.tasks,如果不设置,默认Mapper任务数会是1)设置过多,因为每一个Mapper产生一个物理数据库连接;但如果查询的数据条数很多,可以设置适当设置Mapper任务个数,这样多个Mapper并行去取部分数据最后整合起来,这样查询速度快。如果不设置mapred.map.tasks,默认就是1,数据量大时也要注意!
在关系数据库和HDFS之间抽取数据的另一个方法是:使用Sqoop
另外,MapReduce可以通过HBase的TableInputFormat读取HBase(非关系性数据库)表中的数据,MapReduce通过TableOutputFormat把数据输出到HBase表中
为了方便MapReduce直接访问关系型数据库(MySQL,Oracle),Hadoop提供了DBInputFormat和DBOutputFormat两个类,通过DBInputFormat类把数据库表数据读入到HDFS,根据DBOutputFormat类把MapReduce产生的结果集导入到数据库表中。
16.6.5.1 MySql安装
1、在 /etc/yum.repos.d/ 下建立 MariaDB.repo,内容如下:
$ cd /etc/yum.repos.d
$ vi MariaDB.repo
输入以下内容保存:
# MariaDB 5.5 CentOS repository list - created 2016-05-19 11:18 UTC
# http://mariadb.org/mariadb/repositories/
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/5.5/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
其它各版本及各操作系统下载源配置见https://downloads.mariadb.org/mariadb/repositories/#mirror=neusoft
查看是否已安装过MySQL:
rpm -qa|grep MySQL -----以前版本MySQL
rpm -qa|grep mysql
rpm -qa|grep MariaDB ----新版本MySQL

rpm -e --nodeps MariaDB-common-5.5.49-1.el7.centos.x86_64 ---上面查出什么包就卸载什么包
2、使用YUM安装MariaDB
[root@hadoop-slave2 /etc/yum.repos.d]# yum install MariaDB-server MariaDB-client
3、启动数据库
$ service mysql start
4、修改Root的密码
$ mysqladmin -u root password 'AAAaaa111'
5、配置远程访问,MariaDB为了安全起见,默认情况下绑定ip( 127.0.0.1),限制其他IP远程访问。
$ mysql -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 4
Server version: 10.0.4-MariaDB MariaDB Server
Copyright (c) 2000, 2013, Oracle, Monty Program Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'AAAaaa111' WITH GRANT OPTION;
MariaDB [(none)]>flush privileges;
并可以使用 mysql -h localhost -u root -p 验证是否能远程登录到本地
grant权限1,权限2,…权n ON 数据库名称.表名称 TO用户名@用户地址 IDENTIFIED BY '连接口令';
权限1,权限2,…权限n代表select,insert,update,delete,create,drop,index,alter,grant,references,reload,shutdown,process,file等14个权限。
当权限1,权限2,…权限n被ALL PRIVILEGES或者ALL代替,表示赋予用户全部权限。
当数据库名称.表名称被 *.*代替,表示赋予用户操作服务器上所有数据库所有表的权限。
用户地址可以是localhost,也可以是ip地址、机器名字、域名。也可以用 '%'表示从任何地址连接。"%"表示任何主机都可以远程登录到该服务器上访问
'连接口令'不能为空,否则创建失败。
flush privileges:第二句表示从mysql数据库的grant表中重新加载权限数据。因为MySQL把权限都放在了cache中,所以在做完更改后需要重新加载。
5、 禁止防火墙
7、大小写敏感配置
用root帐号登录后,在/etc/my.cnf 中的[mysqld]后添加添加lower_case_table_names=1,重启MYSQL服务,这时已设置成功:不区分表名的大小写;
[mysqld]
lower_case_table_names = 1
其中 0:区分大小写,1:不区分大小写
8、 重启服务
# service mysql stop
$ service mysql start
9、 查看数据库字符集
MariaDB [(none)]> show variables like 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
10、 修改字符集
注:请在创建数据库之前修改,否则以前创建的库不会随之修改
#vi /etc/my.cnf
[client]
default-character-set=utf8
[mysqld]
character-set-server=utf8
[mysql]
default-character-set=utf8
MariaDB [hadoopdb]> show variables like 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
11、 创建库
$ mysql -u root -p
输入登录密码
MariaDB [(none)]> create database hadoopdb;
12、 显示数据库
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hadoopdb |
| mysql |
| performance_schema |
| test |
+----------------------------------+
13、 连接数据库
MariaDB [(none)]> use hadoopdb;
Database changed
14、 创建数据表
MariaDB [hadoopdb]> CREATE TABLE t_stud (
-> id INTEGER NOT NULL PRIMARY KEY,
-> name VARCHAR(32) NOT NULL);
15、 查看库中有哪些表
MariaDB [hadoopdb]> show tables;
+--------------------+
| Tables_in_hadoopdb |
+--------------------+
| t_stud |
+--------------------+
16、 退出:
MariaDB [hadoopdb]> exit
Bye
下载驱动并上传到hadoop-master主机上:/root/hadoop-1.2.1/lib/mysql-connector-java-5.1.22-bin.jar
配置hadoop-env.sh:

注:多路径Linux中使用冒号分隔,而不是分号
再将配置及驱动复制到其他主机上
连接异常:
com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Communication link failure, message from server: "Can't get hostname for your address"
修改配置文件:vi /etc/my.cnf
[mysqld]
skip-name-resolve
16.6.5.2 从数据库中读写数据
如果要将文本文件中的数据数据导入到数据库中,则这个文本文件格式要是不带BOM头信息的UTF-8格式,否则三个字节的BOM头也会被读入,Hadoop好像没有考虑BOM:
下面将Hadoop中的数据插入到MySql数据库中,并从MySql中读取数据到Hadoop中:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
/*
* 键值对应记录,出入库都通过它
*/
publicclass StudentinfoRecord implements Writable, DBWritable {
intid;
String name;
// 反序列化:从文件读取时调用
publicvoid readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = Text.readString(in);
// 或直接读取
// this.name = in.readUTF();
}
// 序列化:写入文件时调用
publicvoid write(DataOutput out) throws IOException {
out.writeInt(this.id);
// Text.writeString(out, this.name);
// 或直接写
out.writeUTF(this.name);
}
// 反序列化:从数据库中读取时调用
publicvoid readFields(ResultSet result) throws SQLException {
this.id = result.getInt(1);
this.name = result.getString(2);
}
// 序列化:写入数据库时调用
publicvoid write(PreparedStatement stmt) throws SQLException {
stmt.setInt(1, this.id);
stmt.setString(2, this.name);
}
public String toString() {
returnthis.id + " " + this.name;
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
/*
* 将数据写入数据库
*/
publicclass DBOutput {
/*
* 如果输入文件是GBK,可以使用此方法将GBK转换为UTF-8的字符串
* 即使从文本行中某个字符中间被split也没关系,因为TextInputFormat是以行为单位进行读取的,
* 所以这里也是以行为单位进行编解码,所以没有问题
*/
publicstatic Text transformTextToUTF8(Text text, String encoding) {
String value = null;
try {
value = new String(text.getBytes(), 0, text.getLength(), encoding);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
returnnew Text(value);
}
/*
* 注:需要定义成静态的内部类,否则框架在利用反射实例化时会抛异常: java.lang.RuntimeException:
* java.lang.NoSuchMethodException: DBOutput$MyReducer.<init>()
*/
publicstaticclass MyReducer extends Reducer<LongWritable, Text, StudentinfoRecord, NullWritable> {
protectedvoid reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException,
InterruptedException {
// 如果是GBK,则可以重新编码成UTF8
// Text t = transformTextToUTF8(values.iterator().next(), "GBK");
// String[] splits = t.toString().split("\t");
String[] splits = values.iterator().next().toString().split("\t");
StudentinfoRecord studt = new StudentinfoRecord();
studt.id = Integer.parseInt(splits[0]);
studt.name = splits[1];
// 好像只会将Key写入数据库,即Value会忽略
context.write(studt, NullWritable.get());
// context.write(studt, new Text(studt.name));
};
}
publicstaticvoid main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver",
"jdbc:mysql://hadoop-slave1:3306/hadoopdb", "root", "AAAaaa111");
Job job = Job.getInstance(conf, "DBOutput");
job.setJarByClass(DBOutput.class);
job.setOutputFormatClass(DBOutputFormat.class);
DBOutputFormat.setOutput(job, "t_stud", "id", "name");
job.setReducerClass(MyReducer.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop-master:9000/db/input"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/*
* 从数据库中读取数据
*/
publicclass DBInput {
/*
* 注:需要定义成静态的内部类,否则框架在利用反射实例化时会抛异常: java.lang.RuntimeException:
* java.lang.NoSuchMethodException: DBInput$DBInputMapper.<init>()
*/
publicstaticclass DBInputMapper extends Mapper<LongWritable, StudentinfoRecord, LongWritable, Text> {
protectedvoid map(LongWritable key, StudentinfoRecord value, Context context) throws IOException,
InterruptedException {
//这里的key为数据库记录索引,从0开始
context.write(key, new Text(value.toString()));
};
}
publicstaticvoid main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver",
"jdbc:mysql://hadoop-slave1:3306/hadoopdb", "root", "AAAaaa111");
Job job = Job.getInstance(conf, "DBInput");
job.setJarByClass(DBInput.class);
// 默认是TextInputFormat,所以需要修改
job.setInputFormatClass(DBInputFormat.class);
String tableName = "t_stud";
String conditions = "";
String orderBy = "id";
String[] fieldNames = { "id", "name" };
/**
* @param job The map-reduce job
* @param inputClass the class object implementing DBWritable, which is the Java object holding tuple fields.
* @param tableName The table to read data from
* @param conditions The condition which to select data with, eg. '(updated > 20070101 AND length > 0)'
* @param orderBy the fieldNames in the orderBy clause.
* @param fieldNames The field names in the table
*/
DBInputFormat.setInput(job, StudentinfoRecord.class, tableName, conditions, orderBy, fieldNames);
// String inputQuery = "select id, name from t_stud";
// String inputCountQuery = "select count(*) from t_stud";
// DBInputFormat.setInput(job, StudentinfoRecord.class, inputQuery, inputCountQuery);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/db/output"));
job.setMapperClass(DBInputMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
16.7 输出格式
16.7.1 文本输出
在Job没有指定输出格式时,默认就是TextOutputFormat,它把每条记录写为文本行,它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。每个键值对默认使用Tab进行分隔,当然也可以通过设置mapreduce.output.textoutputformat.separator属性(旧API为mapred.textoutputformat.separator)来改变默认的分隔符
与TextOutputFormat对应的输入格式是KeyValueTextInputFormat,它也是通过可配置的分隔符将键值对文本行分隔
如果不想输出键或值,则可以将键或值的类型设定为NullWritable(如果键和值都不需要输出,则等效于NullOutputFormat),当只有键或者值某一个输出时,就不会有键与值分隔符输出,则输出的这样类型的文件适合用TextInputFormat读取
16.7.2 二进制输出
16.7.2.1 SequenceFileOutputFormat
如果要以SequenceFile顺序文件来存储reduce的输出,则使用SequenceFileOutputFormat。SequenceFile顺序文件支持压缩,存储了键值对类型,其结构更适合于MapReduce的输入,具体请参考前面章节SequenceFile顺序文件的特性
16.7.2.2 SequenceFileAsBinaryOutputFormat
SequenceFileAsBinaryOutputFormat与SequenceFileAsBinaryInputFormat相对应,它把键值对作为二进制格式写到SequenceFile顺序文件
16.7.2.3 MapFileOutputFormat
MapFileOutputFormat把MapFile作为输出。MapFile中的键必须是顺序添加,所以必须确保reducer输出的键是已经排好序
reduce输入的键一定是有序的,但输出的键由reduce函数控制,MapReduce框架中没有硬性规定reduce输出键必须是有序的。所以要使用MapFileOutputFormat,就需要额外的限制来保证reduce输出的键是有序的
16.7.3 多个输出
一般情况下,每个reducer只会输出一个文件,名称格式如下:part-r-00000, part-r-00001等,是以分区号(00000、00001)来区分(part是可以通过MultipleOutputs修改的,即多文件输出时才可修改)。
如果一个reducer需要输出多个文件,则需要MultipleOutputs类
一个reducer对应一个分区,使用MultipleOutputs要以将属于同一分区的数据可以输出到不同的文件中
16.7.3.1 示例:分区数据
每个气象站单独输出一个文件
第一种方法:每个气象站对应一个reducer。这需要两步:第一步,写一个partitioner,把同一个气象站的数据放到同一个分区;第二步骤,把作业的reducer数据设为气象站的个数。partitioner如下:
publicclass StationPartitioner extends Partitioner<LongWritable, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
publicint getPartition(LongWritable key, Text value, int numPartitions) {
String stationId = value.toString().substring(4, 10) + "-" + value.toString().substring(10, 15);
return getPartition(stationId);
}
privateint getPartition(String stationId) {//将气象ID转换为相应的分区号
...
}
}
上面这种方式有两个缺点:第一,需要在作业运行前知道气象站的个数;第二,如果每个气象站对应一个reducer任务,如果任务处理数据量差别很大,少量的数据也要开启一个reducer,整体完成时间不能平衡,而且reducer任务开启也会需要开销的。
第二方法:由于第一种方法的明显缺陷,最好的作法是让集群决定分区数据,这样每个分区就可能包括多个气象站的数据,由于默认情况下同一分区的数据只会输出一个文件,因此,如果要实现同一分区的每个气象站一个输出文件的话,这就需要MultipleOutputs
16.7.3.1.1 NcdcRecordParser气温数据解析器
publicclass NcdcRecordParser {
privatestaticfinalintMISSING_TEMPERATURE = 9999;
privatestaticfinal DateFormat DATE_FORMAT = new SimpleDateFormat( "yyyyMMddHHmm");
private String stationId;//气象站ID
private String observationDateString;//观测日期字符串
private String year;//年
private String airTemperatureString;//温度字符串
privateintairTemperature;//温度
privatebooleanairTemperatureMalformed;//
private String quality;//空气质量
// 传入的为一行气象数据文本
publicvoid parse(String record) {
stationId = record.substring(4, 10) + "-" + record.substring(10, 15);
observationDateString = record.substring(15, 27);
year = record.substring(15, 19);
airTemperatureMalformed = false;
// Remove leading plus sign as parseInt doesn't like them
if (record.charAt(87) == '+') {
airTemperatureString = record.substring(88, 92);
airTemperature = Integer.parseInt(airTemperatureString);
} elseif (record.charAt(87) == '-') {
airTemperatureString = record.substring(87, 92);
airTemperature = Integer.parseInt(airTemperatureString);
} else {//温度字符串前不带正负号
airTemperatureMalformed = true;
}
airTemperature = Integer.parseInt(airTemperatureString);
quality = record.substring(92, 93);
}
publicvoid parse(Text record) {
parse(record.toString());
}
publicboolean isValidTemperature() {
return !airTemperatureMalformed
&& airTemperature != MISSING_TEMPERATURE
&& quality.matches("[01459]");
}
publicboolean isMalformedTemperature() {
returnairTemperatureMalformed;
}
publicboolean isMissingTemperature() {
returnairTemperature == MISSING_TEMPERATURE;
}
public String getStationId() {
returnstationId;
}
public Date getObservationDate() {
try {
returnDATE_FORMAT.parse(observationDateString);
} catch (ParseException e) {
thrownew IllegalArgumentException(e);
}
}
public String getYear() {
return year;
}
publicint getYearInt() {
return Integer.parseInt(year);
}
publicint getAirTemperature() {
returnairTemperature;
}
public String getAirTemperatureString() {
returnairTemperatureString;
}
public String getQuality() {
returnquality;
}
}
16.7.3.2 MultipleOutputs
MultipleOutputs类可以将同一分区的数据写到多个文件(即每个reducer可以产生多个输出文件),并且还可以设置输出文件的名称
使用MultipleOutputs将同一分区的数据输出到不同的文件(同一气象站数据输出到时同一文件中):
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
publicclass PartitionByStationUsingMultipleOutputs {
staticclass StationMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String stationId = value.toString().substring(4, 10) + "-" + value.toString().substring(10, 15);
// Key为气象站ID
context.write(new Text(stationId), value);
}
}
staticclass MultipleOutputsReducer extends Reducer<Text, Text, NullWritable, Text> {
private MultipleOutputs<NullWritable, Text> multipleOutputs;
@Override
protectedvoid setup(Context context) throws IOException, InterruptedException {
// 初始化,不输出Key,只输出值
multipleOutputs = new MultipleOutputs<NullWritable, Text>(context);
}
@Override
protectedvoid reduce(Text key, Iterable<Text> values, Context context) throws IOException,
InterruptedException {
for (Text value : values) {
/*
* Key不输出,所以Key为NullWritable的实例:这里NullWritable.get()
* 获取就是NullWritable的单例
*
* 第三个参数是输出文件名,文件名相同的自然就会输出到同一文件,这里为 key.toString(),
* Key为气象站ID。这个文件名可以包含路径,但不要以 / 开头,文件名(以及带路径的文件名)都是相对于
* 作业设置的输出路径: FileOutputFormat.setOutputPath(),即这里都会输出到
* hdfs://hadoop-master:9000/ncdc/output1(或2)这个目录下
*
* 在这里是通过MultipleOutputs实例来输出的,而不再是是Context.write()
*
* 输出的文件名形式为:name-r-nnnnn,name就是这里的 key.toString(),即气象站ID,输出文件名形式为
* station_identifier-r-nnnnn
* 1/ 2/ 为子路径,相对于hdfs://hadoop-master:9000/ncdc/output1(或2)这个目录
*/
// multipleOutputs.write(NullWritable.get(), value, "1/" + key.toString());
multipleOutputs.write(NullWritable.get(), value, "2/" + key.toString());
}
}
@Override
protectedvoid cleanup(Context context) throws IOException, InterruptedException {
multipleOutputs.close();
}
}
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
Job job = new Job(conf);
job.setJarByClass(PartitionByStationUsingMultipleOutputs.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/all/1901.all"));
// FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/output1"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/output2"));
job.setMapperClass(StationMapper.class);
job.setOutputKeyClass(NullWritable.class);
// 由于Mapper的输出与Reducer的输出类型不同,所以这里单设置mapper的输出类型
job.setMapOutputKeyClass(Text.class);
// 由于前面使用了job.setMapOutputKeyClass()设置了mapper输出类型,所以这里只是设置reducer的输出类型
job.setReducerClass(MultipleOutputsReducer.class);
// job.setNumReduceTasks(1);// 将reducer数量设置为1
job.setNumReduceTasks(2);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
下面分下是将reduce数量设为1与2时的输出文件情况,当reducer数据为2时,有5个气象站的数据都分到的1区,只有1个气象站分到了0区,在通常情况下(未使用MultipleOutputs情况下),那5个气象站会输出到一个文件中,但这里因为使用了MultipleOutputs,让每个气象站输出到单独一个文件中(文件名为气象站ID):

图中有3个空文件(注:只有在使用MultipleOutputs时出现),是因为名为 part-r-xxxxx 的文件没有数据(如果在没有使用MultipleOutputs情况下,数据才会输出到这3个文件)
16.7.4 禁止空文件输出
FileOutputFormat子类会输出文件名格式为part-r-nnnnn的文件,即使是空的(如上面的多文件输出示例中就会产生)。如果不想要这些空文件,则可以使用LazyOutputFormat,它是对所有的OutputFormat(如TextOutputFormat,SequenceFileOutputFormat等)的一个wrapper,使用了LazyOutputFormat的job,在输出output的时候,会在第一条记录输出时才创建文件,如果没有输出就不会被创建;它不像现在所有outputFormat的机制一样,task以开始运行不管有没有输出先把输出文件给创建了再说。这种延迟创建的方式有利于避免job创建过多的空输出文件而占据过多的namendoe内存。
LazyOutputFormat.setOutputFormatClass(job,TextOutputFormat.class);
注:由于reducer默认输出是TextOutputFormat,所以这里为TextOutputFormat,但不能是FileOutputFormat,因为是抽象类,不能被实例化。另外,如果有job.setOutputFormatClass(TextOutputFormat.class);,则要注掉
将上面的代码加到上面示例中,就不会输出空文件了
16.7.5 数据库输出
请参考前面章节数据库输入
16.8 Counters计数器
计数器即作业执行后的一些统计信息,根据这些信息可反应出作业的执行情况

16.8.1 任务计数器
任务计数器:该类计数器在任务处理过程中不断更新,同一作业里的所有任务上统计
作业计数器:该类计数器在作业处理过程中不断更新,所有不同作业上统计
任务计数器由其相应的任务自己维护,并定期的发送给tasktracker,再由tasktracker发送给jobtracker,最后在jobtracker上合计
任务计数器的值每次都是完整传输,即不只是传输增加值,而是完成可以覆盖以前的传输过来的值,这样避免了某一次由于传输计数器值失败而引起计数器值最终不准的问题。
另外,如果一个任务在作业执行期间失败,则相关的计数器的值也会随之减小
每个任务运行完后,可以通过http://hadoop-master:50030来查看这些计数器统计值,若任务是直接前台运行,则在任务包括完后,即可看到各计数器统计值,粗体为计数器的组名,其下方列出的就是各个计数器统计值:
16/05/23 09:55:59 INFO mapred.JobClient: Running job: job_201605201002_0044
16/05/23 09:56:00 INFO mapred.JobClient: map 0% reduce 0%
16/05/23 09:56:07 INFO mapred.JobClient: map 40% reduce 0%
16/05/23 09:56:09 INFO mapred.JobClient: map 60% reduce 0%
16/05/23 09:56:10 INFO mapred.JobClient: map 100% reduce 0%
16/05/23 09:56:15 INFO mapred.JobClient: map 100% reduce 33%
16/05/23 09:56:17 INFO mapred.JobClient: map 100% reduce 100%
16/05/23 09:56:17 INFO mapred.JobClient: Job complete: job_201605201002_0044
16/05/23 09:56:17 INFO mapred.JobClient: Counters: 29
16/05/23 09:56:17 INFO mapred.JobClient: Job Counters
16/05/23 09:56:17 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=27746
16/05/23 09:56:17 INFO mapred.JobClient: Launched reduce tasks=1
16/05/23 09:56:17 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
16/05/23 09:56:17 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
16/05/23 09:56:17 INFO mapred.JobClient: Launched map tasks=5
16/05/23 09:56:17 INFO mapred.JobClient: Data-local map tasks=5
16/05/23 09:56:17 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=10157
16/05/23 09:56:17 INFO mapred.JobClient: File Output Format Counters
16/05/23 09:56:17 INFO mapred.JobClient: Bytes Written=45
16/05/23 09:56:17 INFO mapred.JobClient: FileSystemCounters
16/05/23 09:56:17 INFO mapred.JobClient: FILE_BYTES_READ=360619
16/05/23 09:56:17 INFO mapred.JobClient: HDFS_BYTES_READ=4439538
16/05/23 09:56:17 INFO mapred.JobClient: FILE_BYTES_WRITTEN=1078053
16/05/23 09:56:17 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=45
16/05/23 09:56:17 INFO mapred.JobClient: File Input Format Counters
16/05/23 09:56:17 INFO mapred.JobClient: Bytes Read=4438998
16/05/23 09:56:17 INFO mapred.JobClient: Map-Reduce Framework
16/05/23 09:56:17 INFO mapred.JobClient: Map output materialized bytes=360643
16/05/23 09:56:17 INFO mapred.JobClient: Map input records=32827
16/05/23 09:56:17 INFO mapred.JobClient: Reduce shuffle bytes=360643
16/05/23 09:56:17 INFO mapred.JobClient: Spilled Records=65566
16/05/23 09:56:17 INFO mapred.JobClient: Map output bytes=295047
16/05/23 09:56:17 INFO mapred.JobClient: Total committed heap usage (bytes)=644698112
16/05/23 09:56:17 INFO mapred.JobClient: CPU time spent (ms)=7960
16/05/23 09:56:17 INFO mapred.JobClient: Combine input records=0
16/05/23 09:56:17 INFO mapred.JobClient: SPLIT_RAW_BYTES=540
16/05/23 09:56:17 INFO mapred.JobClient: Reduce input records=32783
16/05/23 09:56:17 INFO mapred.JobClient: Reduce input groups=5
16/05/23 09:56:17 INFO mapred.JobClient: Combine output records=0
16/05/23 09:56:17 INFO mapred.JobClient: Physical memory (bytes) snapshot=958246912
16/05/23 09:56:17 INFO mapred.JobClient: Reduce output records=5
16/05/23 09:56:17 INFO mapred.JobClient: Virtual memory (bytes) snapshot=11630010368
16/05/23 09:56:17 INFO mapred.JobClient: Map output records=32783
16.8.1.1 MapReduce任务计数器




16.8.1.2 文件系统任务计数器

BYTES_READ:map与reduce任务读取的每一种文件系统的字节数,每一个文件系统都有一个计数器,文件系统可以是:Local、HDFS、S3、KFS等
BYTES_WRITTEN:map与reduce任务往每一种文件系统写的字节数
16.8.1.3 FileInputFormat任务计数器

map任务通过FileInputFormat读取的字节数
16.8.1.4 FileOutputFormat任务计数器

map任务(针对仅含map的作业)或者reduce任务通过FileOutputFormat写出的字节数
16.8.2 作业计数器
作业计数器由jobtracker(或Yarn中的application master)维护,不需要在网络上传送,这与其他(包括用户自定义的计数器)不一样
这些计数器都是在作业级别统计得到的,其值不会随着任务运行而改变



16.8.3 自定义计数器
一般用户使用枚举(enum)来自定一组相关的计数器,枚举类型名即为计数器组名,枚举类型里定义的成员字段就是计数器名称
这里计数器是全局的,即在所有map和reduce中进行计数累加,并在作业结束时产生一个最终的结果
publicclass MaxTemperatureWithCounters extends Configured implements Tool {
// 定义了两个计数器。一般会将自定义枚举计数器定义成内部类
enum Temperature {
MISSING, MALFORMED
}
staticclass MaxTemperatureMapperWithCounters extends Mapper<LongWritable, Text, Text, IntWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {//如果是有效气温,则输出
int airTemperature = parser.getAirTemperature();
context.write(new Text(parser.getYear()), new IntWritable(airTemperature));
} elseif (parser.isMalformedTemperature()) {//如果数据问题,MALFORMED计数器累加
context.getCounter(Temperature.MALFORMED).increment(1);
} elseif (parser.isMissingTemperature()) {//如果没有气温值,MISSING计数器累加
context.getCounter(Temperature.MISSING).increment(1);
}
// dynamic counter动态计数器:即未使用枚举来定义计数器,而是在程序中直接指定计数器组名以及计数器名
//下面 TemperatureQuality 即组名,parser.getQuality()即计数器名。与枚举静态计数器定义不同的时,在获取时
//需要明确的指定计数器组名
context.getCounter("TemperatureQuality", parser.getQuality()).increment(1);
}
}
. . . . . .
如果计数器是采用枚举类型来定义的,则计数器默认名称就是枚举类型的完全限定类名,如这里的默认计数器组名为:MaxTemperatureWithCounters$Temperature(注:由于上面示例类在默认包括里,所以没有包前缀信息),而每个成员的名称就是默认计数器名称,如这里的MISSING与 MALFORMED,下面是上面作业运行后输出的计数器统计信息:
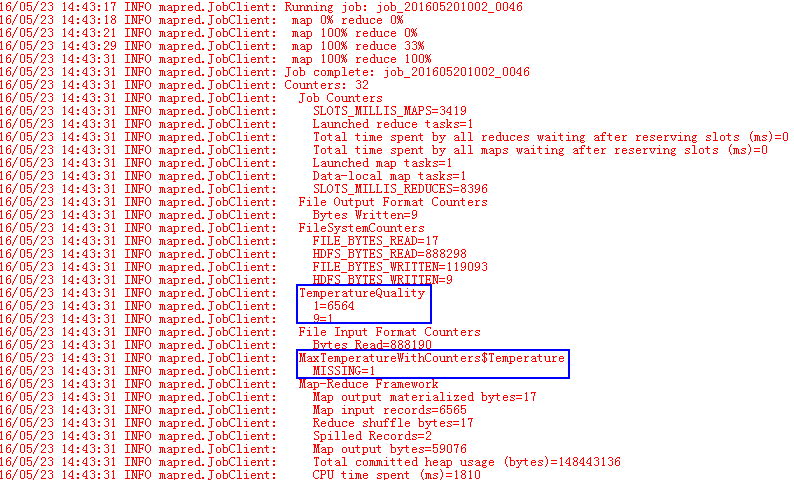
枚举类型定义的计数器的默认名称不易读,可以为这个枚举定义相应的属性资源文件,如果枚举是内部类,则属性文件名中使用下画线分隔:MaxTemperatureWithCounters_Temperature.properties:

属性文件中内容:
CounterGroupName配置的是计数器组名称
成功字段名.name配置的是具体某个计数器名称
如果是中文翻译,则对应的属性资源文件名为:
MaxTemperatureWithCounters_Temperature_zh_CN.properties
16.8.4 获取计数器
除了通过Web界面和命令行(hadoop job -counter),还可以通过Java API来获取计数器的值
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapred.Counters;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.JobID;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.Task;
publicclass MissingTemperatureFields {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop-master:9001");
JobClient jobClient = new JobClient(new JobConf(conf));
// 根据作业ID来获取作业,一般jobtracker上默认保存最近100个作业,可以通过
// mapred.jobtracker.completeuserjobs.maximum 配置属性配置,所以有可能找不到作业
RunningJob job = jobClient.getJob(JobID.forName("job_201605201002_0046"));
// 获取作业上所有的计数器
Counters counters = job.getCounters();
// 获取具体某个计数器
long missing = counters.getCounter(MaxTemperatureWithCounters.Temperature.MISSING);
long total = counters.getCounter(Task.Counter.MAP_INPUT_RECORDS);
System.out.printf("Records with missing temperature fields: %.2f%%\n", 100.0 * missing / total);
}
}
上面示例代码片断使用的是旧版API,通过新版API获取计数器的方法并不适用于Hadoop 1.X版本(但使用旧版编写的获取计数器的代码可以运行在新版API上)。新旧版本API主要差别是在于是新版本API中使用Cluster对象来获取一个Job对象(而非一个RunningJob对象),然后再调用它的getCounters()方法:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Cluster;
import org.apache.hadoop.mapreduce.Counters;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobID;
import org.apache.hadoop.mapreduce.TaskCounter;
Cluster cluster = new Cluster(conf);
Job job = cluster.getJob(JobID.forName("job_201605201002_0046"));
Counters counters = job.getCounters();
longmissing = counters.findCounter(MaxTemperatureWithCounters.Temperature.MISSING).getValue();
longtotal = counters.findCounter(TaskCounter.MAP_INPUT_RECORDS).getValue();
另外一个区别,新API使用org.apache.hadoop.mapreduce.TaskCounter枚举类型,则旧API里使用org.apache.hadoop.mapred.Task.Counter枚举类型
16.9 排序
16.9.1 气象数据转换为顺序文件
为了按气温对天气数据进行排序,需要以天气为Key写进sequence 文(在Map输出时就会自动按Key进行排序),所以在排序之前,需要先将天气数据文件转换为SequenceFile格式的文件:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
publicclass SortDataPreprocessor {
staticclass CleanerMapper extends Mapper<LongWritable, Text, IntWritable, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override//这里只有map,没有reduce
protectedvoid map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
context.write(new IntWritable(parser.getAirTemperature()), value);
}
}
}
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");// 指定使用yarn框架
conf.set("yarn.resourcemanager.address", "hadoop-master:8032"); // 远程提交任务需要用到
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");// 指定namenode
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath()
+ "\\SortDataPreprocessor.jar");
Job job = Job.getInstance(conf, "weather");
job.setJarByClass(SortDataPreprocessor.class);
job.setMapperClass(CleanerMapper.class);
// 由于气温是按带符号的,所以不能简单以字符串来比,所以要转换为数字后才能比,所以Key为整型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);// 值就是行文本
// 不需要 reducer 任务,所以可设置为0。由于reducer任务个数设置为0,每个文件(还是 每数据块?)
// 输出一个Map输出,输出文件名形式为part-m-xxxxx,没有reduce输出。注:由于没有Reduce任务,
//所以这里的Map输出数据是未分区的,只是简单的将普通的Text输入文件转换为SequenceFile文件
job.setNumReduceTasks(0);
job.setOutputFormatClass(SequenceFileOutputFormat.class);// 以键值对顺序文件格式输出
SequenceFileOutputFormat.setCompressOutput(job, true);// 启用压缩
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);// 压缩方法
SequenceFileOutputFormat.setOutputCompressionType(job,
CompressionType.BLOCK);// 压缩类型:块级别的压缩
FileInputFormat.addInputPath(job, new Path( "hdfs://hadoop-master:9000/ncdc/all"));
FileOutputFormat.setOutputPath(job, new Path( "hdfs://hadoop-master:9000/ncdc/all-seq/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
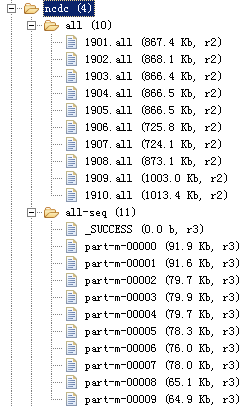
16.9.2 部分排序
将顺序文件按温度排序,由于采用是默认Hash分区,每个分区输出到一个文件,这个文件里的数据是按温度排序的,但是分区(文件)之间不是排序的,即一个文件里的所以数据不一定全部大于或小于另一文件里的数据,所以这是部分排序。
下面这个程序是对前面无序的顺序文件进行默认排序(采用默认分区、并使用默认的map与reduce),此作业输出的单个文件里的数据是有序的,但文件之间是无序的,所以是部分排序:
publicclass SortByTemperatureUsingHashPartitioner {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath()
+ "\\SortByTemperatureUsingHashPartitioner.jar");
Job job = Job.getInstance(conf, "weather");
job.setJarByClass(SortByTemperatureUsingHashPartitioner.class);
/*
* 该类没有指定Map与Reducer,所以使用默认的map与reducer,由于在shuffle过程中,
* 默认就会对分区中的数据里进行排序,所以每个输出文件中的数据是按Key(温度)排序的
*/
job.setInputFormatClass(SequenceFileInputFormat.class);//输入的为顺序文件
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);//还是以顺序文件格式输出
job.setNumReduceTasks(5);//会输出5个已排序的输出文件
//输出还是会使用块级别的压缩
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job, CompressionType.BLOCK);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/all-seq/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/output-hashsort/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
上面产生的文件是部分排序的顺序文件SequenceFile(文件里是排序的,但文件之间无序),为了根据温度Key在文件中进行查找,需要这些文件为MapFile,哪怕这些文件是之间是无序的。下面程序与上面示例一样,唯一不同的是上面输出格式为SequenceFileOutputFormat,而这个为MapFileOutputFormat:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MapFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
publicclass SortByTemperatureToMapFile {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath()
+ "\\SortByTemperatureToMapFile.jar");
Job job = Job.getInstance(conf, "weather");
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(MapFileOutputFormat.class);
job.setNumReduceTasks(5);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job, CompressionType.BLOCK);
FileInputFormat.addInputPath(job, new Path( "hdfs://hadoop-master:9000/ncdc/all-seq"));
FileOutputFormat.setOutputPath(job, new Path( "hdfs://hadoop-master:9000/ncdc/output-hashmapsort"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
如果按默认reduce输出,则会产生一个 _SUCCESS 空的标记文件,但这个文件会导致
Reader[] readers = MapFileOutputFormat.getReaders(path, conf);获取MapFile.Reader出错(请看后面示例):
Exception in thread "main" java.io.FileNotFoundException: File does not exist: hdfs://hadoop-master:9000/ncdc/output-hashmapsort/_SUCCESS/data
原因是该方法的path参数输入的要求输入的路径是分区文件夹的上一级目录,这里即为output-hashmapsort, MapFile.Reader的特点会自动定位到data与index文件,所以如果读取MapFile时,只需到目录即可。所以设以下这个配置属性,不让其输出:
conf.setBoolean("mapreduce.fileoutputcommitter.marksuccessfuljobs", false);
设置后输入结果文件中就不会产生_SUCCESS 空的标记文件了:
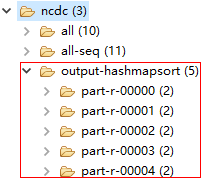
16.9.2.1 在部分排序的MapFile文件集中查找
MapFileOutputFormat类提供了两个便利的静态方法,用来在mapreduce输入为MapFileOutputFormat格式的文件集中进行查找:
publicstatic MapFile.Reader[]getReaders(Path dir, Configuration conf) throws IOException {
FileSystem fs = dir.getFileSystem(conf);
Path[] names = FileUtil.stat2Paths(fs.listStatus(dir));
// sort names, so that hash partitioning works
Arrays.sort(names);
MapFile.Reader[] parts = new MapFile.Reader[names.length];
for (inti = 0; i < names.length; i++) {
parts[i] = new MapFile.Reader(fs, names[i].toString(), conf);
}
returnparts;
}
该方法读取mapreduce作业输出的MapFileOutputFormat格式的MapFile文件,由于作业输出的mapfile为多个(如上面的output-hashmapsort输出文件夹),返回的为数组MapFile.Reader[],Mapreducer会为每个Mapfile输出文件打开一个MapFile.Reader,MapFile.Reader可以参考前面章节
publicstatic <K extends WritableComparable<?>, V extends Writable> WritablegetEntry(MapFile.Reader[] readers, Partitioner<K, V> partitioner, K key, V value) throws IOException {
intpart = partitioner.getPartition(key, value, readers.length);
returnreaders[part].get(key, value);
}
根据指定的key及分区算法,找到该key所对应的value。实现过程:为了得到键值key在readers数组中的哪一个Reader对象中,我们需要构建一个HashPartitioner类的对象partitioner。在创建了对象partitioner后,我们可以根据要查找的键key(如果存在时)该所在分区的索引(readers数组的下标)。得到数组的下标后,我们就可以得到要查找的键Key所在的输出reader,通过reader的get方法,就可以得到指定key所对应的value
下面基于上面产生的MapFile,在文件中查找指定温度的气象数据,注:这些文件之间是无序的,文件里是有序的,即这些文件是部分排序的。
示例:从MapFile文件集中查找第一条符合指定温度的气象数据
publicclass LookupRecordByTemperature {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
Path path = new Path("hdfs://hadoop-master:9000/ncdc/output-hashmapsort");
IntWritable key = new IntWritable(Integer.parseInt("-39"));
Reader[] readers = MapFileOutputFormat.getReaders(path, conf);
Partitioner<IntWritable, Text> partitioner = new HashPartitioner<IntWritable, Text>();
Text val = new Text();
//根据分区方式,在readers数组中找到指定的第一个key所对应的val,返回的值entry实质上也是val
Writable entry = MapFileOutputFormat.getEntry(readers, partitioner, key, val);
if (entry == null) {
System.err.println("Key not found: " + key);
System.exit(0);
}
NcdcRecordParser parser = new NcdcRecordParser();
parser.parse(val.toString());
//entry与val是一样的
//parser.parse(entry.toString());
System.out.printf("%s\t%s\n", parser.getStationId(), parser.getYear());
}
}
028690-99999 1909
示例:从MapFile文件集中查找所有符合指定温度的气象数据
publicclass LookupRecordsByTemperature {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
Path path = new Path("hdfs://hadoop-master:9000/ncdc/output-hashmapsort");
IntWritable key = new IntWritable(Integer.parseInt("-39"));
Reader[] readers = MapFileOutputFormat.getReaders(path, conf);
Partitioner<IntWritable, Text> partitioner = new HashPartitioner<IntWritable, Text>();
Text val = new Text();
//找到指定Key所对应的MapFile.Reader
Reader reader = readers[partitioner.getPartition(key, val, readers.length)];
Writable entry = reader.get(key, val);
if (entry == null) {
System.err.println("Key not found: " + key);
System.exit(0);
}
NcdcRecordParser parser = new NcdcRecordParser();
IntWritable nextKey = new IntWritable();
do {
parser.parse(val.toString());
System.out.printf("%s\t%s\t%s\n", key, parser.getStationId(), parser.getYear());
} while (reader.next(nextKey, val) && key.equals(nextKey));//如果还未到文件尾,且键为指定的键时
}
}
-39 029600-99999 1905
-39 029600-99999 1905
-39 029810-99999 1905
-39 029810-99999 1905
-39 029810-99999 1905
-39 029600-99999 1905
-39 029440-99999 1907
-39 228920-99999 1907
16.9.3 全排序
如何让mapreducer作业产生一个全局排序的文件?最简单方法就是使用一个分区,即只输出一个文件,这样的方法跟单机没什么区别,完全没有利用分布式计算的优势,数据量稍大时,一个reduce的处理效率极低;如果是多个分区,则会输出的是多个文件,多文件输出的情况下要是全排序的话,除了文件内部是排序外(Map默认就是按Key升序输出给Reducer,所以Reducer输出默认也是升序的,所以文件内部排序默认情况下不需要我们去编码实现),文件之间也是排序的,即前一分区里的所有Key全大于或小于或等于后一分区里的所有Key。
默认情况下,会使用HashPartitioner类对Map输出进行Hash分区,但是, Hash分区算法可能会导致分区之间的记录分配不均,如可能会出现下面分配不均的问题:
这时我们可以使用TotalOrderPartitioner全排序分区算法,对Map输出数据进行均衡分区。使用该类进行分区前,需要先对数据进行采样得到一系列的采样数据,并能这些采样数据进行排序,然后通过一定的算法并将这些排序过的采样数据划分为多个范围(数量为Reducer个数减一),然后取这些范围的起始Key作为抽样点,最后TotalOrderPartitioner类会根据这些分区范围对数据进行分区。
所以现在使用TotalOrderPartitioner进行全排序分区的问题,转换为如何对数据进行采样生成分区范围抽样点的问题
如果我们预先就知道所有温度数据,则可以通过自定义分区算法,将所有记录很好的均匀分配到各分区中,但对于大数据量输入来说遍历整个数据集是不可取的,这时我们只能通过对键分布空间进行采样,才可能较为均匀的划分数据集。采样的思想就是针对一部分的数据获得其分布情况,由此来构建分区,并且Hadoop已提供了这样内置的采样器,无需自己编写
16.9.3.1 数据抽样
为什么要使用采样器?
简单的来说就是解决"How to automatically find good partitioning function",即创建大小近似相等的分区
采样的目的是为了创建大小近似相等的一系统分区
如何对大数据进行高效地全局排序且排序过程中reducer要数据均衡?首先,创建一系列排序好的文件;其次,串联这些文件;最后生成一个全局排序的文件。
主要思路是使用一个partitioner来描述全局排序的输出。
由此我们可以归纳出这样一个用hadoop对大量数据排序的步骤:
1) 对待排序数据进行抽样;
2) 对抽样数据进行排序,产生标尺;
3) Map对输入的每条数据计算其处于哪两个标尺之间;将数据发给对应区间ID的reduce
4) Reduce将获得数据直接输出。
InputSampler类内部实现了三种采样方法:SplitSampler、RandomSampler和IntervalSampler(RandomSampler最耗时),它们都实现了InputSampler的内部接口Sampler接口:
publicinterface Sampler<K,V> {
//根据job的配置信息以及输入获取抽样数据
K[] getSample(InputFormat<K,V> inf, Job job) throws IOException, InterruptedException;
}
这个接口通常不直接由客户端调用,而是由InputSampler类的静态方法writePartitionFile() 调用,目的是创建一个顺序文件SequenceFile(该文件即为分区文件,根据该文件对Map输出数据进行分区)来存储抽样点数据,根据这些抽样点(即具体某个key)就可以知道每个分区所存储的数据范围(区间),抽样点的个数为分区数减一,即如果分区数为n,则该顺序文件会记入 n - 1 个抽样点,就靠这 n - 1 个分隔点(抽样点)将mapreduce输出数据均衡分成n个分区,这样多个reducer任务最终产生的多个输出文件之间的数据就是有序并且均衡。具体如何从抽样数据中获取抽样点,可以参考publicstatic <K,V> void writePartitionFile(Job job, Sampler<K,V> sampler)这个方法,访方法是将采样的结果数据进行排序,然后从这份样本数据中取出 n - 1(n为分区数)个抽样点(key)写入到顺序文件中,具体抽样点的取法如下:
NullWritable nullValue = NullWritable.get();
// numPartitions:分区数,samples:样本数据数组。stepSize即为将样本数据分成numPartitions份,每份约多少个(可能为小数)?即步长
float stepSize = samples.length / (float) numPartitions;
int last = -1;//上一次被抽中样本元素索引,即最近一次写入到顺序文件的样本数据所在samples样本数组里的索引
//注:如果分区数为1,则是不会对抽样数据进行抽样取点,即下面循环不会执行
for(int i = 1; i < numPartitions; ++i) {//执行 numPartitions - 1次,即需要抽取的样本元素个数为numPartitions - 1
int k = Math.round(stepSize * i);//四舍五入,如 k = 4.3则取samples[4], 如 k = 4.5则取samples[5]
//防止上一次元素再次被抽中,按理的话k不太可能小于last,最多只能相等
while (last >= k && comparator.compare(samples[last], samples[k]) == 0) {
++k;
}
writer.append(samples[k], nullValue);//将抽样点写入SequenceFile,NullWritable表示值不写入
last = k;
}
1、 SplitSampler只采样分片中的前N条记录,并且只对随机几个分片中抽取(而不是所有分片),所以该采样器并不适合于已经排好序的数据,这样会造成取样太偏。SplitSampler类有两个属性:
publicstaticclass SplitSampler<K,V> implements Sampler<K,V> {
privatefinalintnumSamples;//从所有选中的分片中获取的最大抽样数
privatefinalintmaxSplitsSampled;//用来选作抽样的最大分片数。只要 numSamples与maxSplitsSampled任一条件满足,即停止抽样
通过其构造函数对这两属性进行设置:
public SplitSampler(int numSamples, int maxSplitsSampled) {
2、 IntervalSampler根据一定的间隔从分片中采样数据,非常适合对排好序的数据采样。SplitSampler类有两个属性也有两个属性:
publicstaticclass IntervalSampler<K,V> implements Sampler<K,V> {
privatefinaldoublefreq;
privatefinalintmaxSplitsSampled;
通过其构造函数对这两属性进行设置:
public IntervalSampler(double freq, int maxSplitsSampled) {
如果当前样本数与已经读取的记录数的比值小于freq,则将这条记录添加到样本集合,否则读取下一条记录
3、 RandomSampler随机地从输入数据中抽取Key,是一个优秀的通用采样器。RandomSampler类有三个属性:
publicstaticclass RandomSampler<K,V> implements Sampler<K,V> {
privatedoublefreq;// Key被选中的概率
privatefinalintnumSamples;//从所有选中的分片中获取的最大抽样数
privatefinalintmaxSplitsSampled;//用来选作抽样的最大分片数
通过其构造函数对这三个属性进行设置:
public RandomSampler(double freq, int numSamples, int maxSplitsSampled) {
取出一条记录,判断得到的随机浮点数是否小于等于采样频率freq,如果大于则放弃这条记录
采样方式对比表:
|
类名称 |
采样方式 |
构造方法 |
效率 |
特点 |
|
SplitSampler<K,V> |
对前n个记录进行采样 |
采样总数,取样最大分片数 |
最高 |
|
|
RandomSampler<K,V> |
遍历所有数据,随机采样 |
采样频率,采样总数,取样最大分片数 |
最低 |
|
|
IntervalSampler<K,V> |
固定间隔采样 |
采样频率,取样最大分片数 |
中 |
对有序的数据十分适用 |
16.9.3.2 根据抽样数据进行全排序,并让数据均衡分布
默认的Hash分区算法类HashPartitioner可能会导致分区数据不均,可以使用全排序分区算法TotalOrderPartitioner并接合随机抽样RandomSampler一起使用,可以输出数据均衡的全排序文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner;
publicclass SortByTemperatureUsingTotalOrderPartitioner {
publicstaticvoid main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath()
+ "\\SortByTemperatureUsingTotalOrderPartitioner.jar");
Job job = Job.getInstance(conf, "weather");
job.setJarByClass(SortByTemperatureUsingTotalOrderPartitioner.class);
// 该程序将输入5个内部已排好序的分区,且分区i中所有的键都小于i+1中的键
job.setNumReduceTasks(5);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job,
CompressionType.BLOCK);
FileInputFormat.addInputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/all-seq"));
FileOutputFormat.setOutputPath(job, new Path(
"hdfs://hadoop-master:9000/ncdc/output-totalsort2"));
// 指定分区方式为全排序的分区类TotalOrderPartitioner,而非默认的Hash分区类HashPartitioner
// 即分区i(i为分区编号,即part-r-nnnnn中的nnnnn)中所有的键都小于i+1中的键
//注:使用TotalOrderPartitioner的场景中,不要让分区数(reducer数)比采样得到的非重复Key还要多,否则可能会出问题
job.setPartitionerClass(TotalOrderPartitioner.class);
// 注:一定要再次通过job来获取conf,而不能直接使用上面定义的conf,否则会找不到分布式缓存文件路径
conf = job.getConfiguration();
// 分区文件需要存放到分布式缓存中与其他任务共享,TotalOrderPartitioner需要用到抽样文件
String partitionFile = TotalOrderPartitioner.getPartitionFile(conf);
URI partitionUri = new URI(partitionFile + "#" + TotalOrderPartitioner.DEFAULT_PATH);
DistributedCache.addCacheFile(partitionUri, conf);//注:使用job.addCacheFile(partitionUri);来代替
DistributedCache.createSymlink(conf);//老版本中使用的,现在不用了,可以注掉
// 使用RandomSampler采样器抽样。采样概率为0.1;10000为最大抽样数,即最多抽取10000个;10为选作抽样的
// 最大分片数只要最大抽样数与选作抽样的最大分片数任一条件满足,即停止抽样
InputSampler.Sampler<IntWritable, Text> sampler = new InputSampler.RandomSampler<IntWritable, Text>(
0.1, 10000, 10);
//访方法是将采样的结果数据进行排序,然后从这份样本数据中取出 n - 1(n为分区数)个抽样点(key)写入到顺序文件中(根据该文件中的 n - 1 个 Key对Map输出进行分区),生成的该分区文件会被TotalOrderPartitioner全排序分区类使用。
// 这里输出文件会存放到分布式缓存中,具体路径是通过上面DistributedCache配置的
InputSampler.writePartitionFile(job, sampler);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
最终产生的抽样分区文件如下,由于要分成5个分区,所以分区文件中存放了4个抽样点(key),将所有数据划分为5个范围([-∞,-33)、[-33,11)、[11,61)、[61,122)、[122,+∞)),同一范围内的数据会输出到同一reducer中:

下面是使用默认HashPartitioner分区与TotalOrderPartitioner分区结果对比,发现采用TotalOrderPartitioner类进行分区的输出文件数据分布是比较均衡的:
上面output-hashsort文件夹里的是通过HashPartitioner分区出来的数据,而output-totalsort是通过TotalOrderPartitioner分区出来的数据,可以看出output-totalsort里的文件大小比较均衡一致,即数据分布均衡,并且分区i(i为分区编号,即part-r-nnnnn中的nnnnn)中所有的键都小于i+1中的键:
如果都将reducer任务数调为10,更明显:

16.9.3.3 分区Partitioner
分区算法都从Partitioner继续:
publicabstractclass Partitioner<KEY, VALUE> {
/**
* 根据指定的Key,返回它所在的分区的分区号
* @param numPartitions 总共分区数.
*/
publicabstractint getPartition(KEY key, VALUE value, int numPartitions);
}
Partition主要作用就是将map的结果发送到相应的reduce。这就对partition有两个要求:
1)均衡负载,尽量的将工作均匀的分配给不同的reduce。
2)效率,分配速度一定要快。
Mapreduce提供的Partitioner:

1、HashPartitioner<k,v>是mapreduce的默认partitioner。源代码如下:
publicint getPartition(K key, V value, int numReduceTasks) {
// numReduceTasks 为reducer任务数。(key.hashCode() & Integer.MAX_VALUE)作用是去掉负号
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
2、BinaryPartitioner:仅对键值K的二进制值的[rightOffset,leftOffset]这个区间的二进制数据取hash:
一个数组的元素索引偏移两的两种表达方式:leftOffset从前往后来标记,第一个元素为0;rightOffset从后向前标记,第一个元素为-1
* +---+---+---+---+---+
* | B | B | B | B | B |
* +---+---+---+---+---+
* 0 1 2 3 4
* -5 -4 -3 -2 -1
// lef:Hash开始的起始索引,采用从前往后标记,索引号为正,即通常的数组元素编号;
// right:Hash终止的结束索引,采用从后向前标记,索引号为负
publicstaticvoid setOffsets(Configuration conf, int left, int right) {
conf.setInt("mapred.binary.partitioner.left.offset", left);
conf.setInt("mapred.binary.partitioner.right.offset", right);
}
privateintleftOffset, rightOffset;
publicvoid setConf(Configuration conf) {
this.conf = conf;
//如果left.offset与right.offset都未设置,则将会对整个Key所对应的二进制数组进行Hash运算
leftOffset = conf.getInt("mapred.binary.partitioner.left.offset", 0);//如果未设置,则取0
rightOffset = conf.getInt("mapred.binary.partitioner.right.offset", -1); //如果未设置,则取-1
}
publicint getPartition(BinaryComparable key, V value, int numPartitions) {
int length = key.getLength();//Key所对应的二进制数数据字节长度
int leftIndex = (leftOffset + length) % length;//起始索引
int rightIndex = (rightOffset + length) % length;//结束索引
// leftIndex :开始Hash的起始偏移量,rightIndex - leftIndex + 1为需要Hash的二进制数据长度
int hash = WritableComparator.hashBytes(key.getBytes(), leftIndex, rightIndex - leftIndex + 1);
return (hash & Integer.MAX_VALUE) % numPartitions;
}
3、KeyFieldBasedPartitioner也是基于hash的个partitioner。和BinaryPatitioner不同,它提供了多个区间用于计算hash。当区间数为0时KeyFieldBasedPartitioner退化成HashPartitioner。
4、TotalOrderPartitioner这个类可以实现输出的全排序。不同于以上3个partitioner,这个类并不是基于hash的。
16.9.4 第二排序(复合Key)
前面的示例都是找最高或最低气温,都是以温度来作为Key的,如果是以年为维度,找每年的最高最低气温呢?这可以先按年排序,然后按温度进行排序来实现,但是,由于只能按Key进行排序,所以需要进行排序的字段都要做为Key的一部分,所以这时需要将Key设置成复合Key:年+温度,而不是年或者温度作为Key了。
初看起来,复合键是可以解决这种混排的问题,但是,要注意的是,由于是复合键(键中除年外,还有温度信息)会导致同一年的数据会被分区到不同Reducer,这样输出还是会有问题的(同一年找出的最高或最低温度就会有多个,并且分布在不同的Reducer输出文件中)。为了使同一年的数据送往同一Reducer,这需要设计一个只按年进行分区的partitioner,由它来确保同一年的数据发送到同一Reducer中。但这样还是有一个问题就是,虽然通过自定义的分区算法,可以将同一年的数据发送到同一Reducer中,但是,由于Key是由 年+温度 的复合键,这会导致同一年的数据还是不能合并在一起(即分组到一起):

),如会出下现在的问题(以整个复合键来分组,即使年相同但温度不同时,还是会分成多个组,这样会导致每年的最高气温不只一个):
其实这个问题也可以像自定义分区那样,也可以自定义分组的,我们可以按年来分组,这样同一年的数据在发送Reducer后,就会自分在一组(即只按年来分组,温度不参与分组——默认情况下是参与的,所以还需要自定义分组算法):
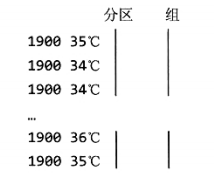
所以,总之,对于复合Key,一般需要自定义分区与自定义分组才能很好的工作
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import ch02.NcdcRecordParser;
publicclass MaxTemperatureUsingSecondarySort extends Configured implements Tool {
//如果是字符类型,则可以参考前面的TextPair 注:该Int整型Key并未实现原生比较,如果要实现请参考这里IntWritable.Comparator来实现
publicstaticclass IntPair implements WritableComparable<IntPair> {
privateintfirst;// 年
privateintsecond;// 温度
public IntPair() {
}
public IntPair(intfirst, intsecond) {
set(first, second);
}
publicvoid set(intfirst, intsecond) {
this.first = first;
this.second = second;
}
publicint getFirst() {
returnfirst;
}
publicint getSecond() {
returnsecond;
}
@Override
publicvoid write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
@Override
publicvoid readFields(DataInput in) throws IOException {
first = in.readInt();
second = in.readInt();
}
@Override
publicint hashCode() {
returnfirst * 163 + second;
}
@Override
publicboolean equals(Object o) {
if (oinstanceof IntPair) {
IntPair ip = (IntPair) o;
returnfirst == ip.first && second == ip.second;
}
returnfalse;
}
@Override
public String toString() {
returnfirst + "\t" + second;
}
@Override//WritableComparator里自定义比较方法 compare(WritableComparable a, WritableComparable b) 会回调此方法
publicintcompareTo(IntPair ip) {
intcmp = compare(first, ip.first);
if (cmp != 0) {
returncmp;
}
return compare(second, ip.second);
}
/**
* Convenience method for comparing two ints.
*/
publicstaticint compare(inta, intb) {
return (a < b ? -1 : (a == b ? 0 : 1));
}
}
staticclass MaxTemperatureMapper extends Mapper<LongWritable, Text, IntPair, NullWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
// 键为复合主键,值为空
context.write(new IntPair(parser.getYearInt(), parser.getAirTemperature()), NullWritable.get());
}
}
}
staticclass MaxTemperatureReducer extends Reducer<IntPair, NullWritable, IntPair, NullWritable> {
@Override
protectedvoid reduce(IntPair key, Iterable<NullWritable> values, Context context) throws IOException,
InterruptedException {
context.write(key, NullWritable.get());
}
}
// 自定义分区算法,
publicstaticclass FirstPartitioner extends Partitioner<IntPair, NullWritable> {
@Override
publicint getPartition(IntPair key, NullWritable value, intnumPartitions) {
// 只让年参与计算。这里乘127后再Hash会更好的打散分区,防止数据倾斜
return Math.abs(key.getFirst() * 127) % numPartitions;
}
}
//自定排序比较器
publicstaticclass KeyComparator extends WritableComparator {
protected KeyComparator() {
super(IntPair.class, true);
}
@Override //重写父类WritableComparator中的compare(WritableComparable a, WritableComparable b)方法
publicint compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
intcmp = IntPair.compare(ip1.getFirst(), ip2.getFirst());
if (cmp != 0) {//先按年升序排,如果不同则不再需要比较温度
returncmp;
}
//在年相同的情况下,降序排序温度,这样同一年第一行温度即为最高温度
return -IntPair.compare(ip1.getSecond(), ip2.getSecond()); // reverse
}
}
// 自定义分组比较器
publicstaticclass GroupComparator extends WritableComparator {
protected GroupComparator() {
super(IntPair.class, true);
}
@Override
publicint compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
// 只按年来进行比较分组,只要年份相同就会分为一组,虽然Key是年+温度
//由于Job设置了自定义排序(先按年升序,再按温度降序),所以最后分组
//只取温度最高的复合Key,即数据发送到Reducer前,每一年只有一记录,该
//记录就是温度最高的记录,其他都会因为分组给忽略掉
return IntPair.compare(ip1.getFirst(), ip2.getFirst());
}
}
@Override
publicint run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath()
+ "\\MaxTemperatureUsingSecondarySort.jar");
Job job = Job.getInstance(conf, "weather");
job.setJarByClass(SortByTemperatureUsingHashPartitioner.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/all"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/ncdc/output-secondarysort"));
job.setMapperClass(MaxTemperatureMapper.class);
// 1、先分区:设置自定义分区算法
job.setPartitionerClass(FirstPartitioner.class);
//2、再排序:设置自定义排序比较器,用于Map输出分区后,发往Reducer前,在分区类进行排序进调用
job.setSortComparatorClass(KeyComparator.class);
//3、最后分组:设置自定义分组器,在数据分区且排序完成发送Reducer前,会调用此算法进行分组:同一年分到同一组
job.setGroupingComparatorClass(GroupComparator.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
returnjob.waitForCompletion(true) ? 0 : 1;
}
publicstaticvoid main(String[] args) throws Exception {
intexitCode = ToolRunner.run(new MaxTemperatureUsingSecondarySort(), args);
System.exit(exitCode);
}
}
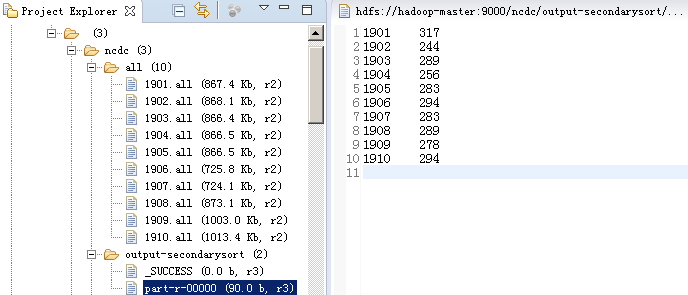

16.10 连接
如果要像关系数据库那样,可以对两张表进行关联操作,在MapReducer里是可以实现的,但很麻烦的,可以考虑使用Pig、Hive
前面气象记录数据中只有气象站的ID,如果有一份文件存放了气象站更多信息:如气象站名,如何将气象记录数据与气象站数据通过ID进行关联,输出温度时也输出气象站名称呢?
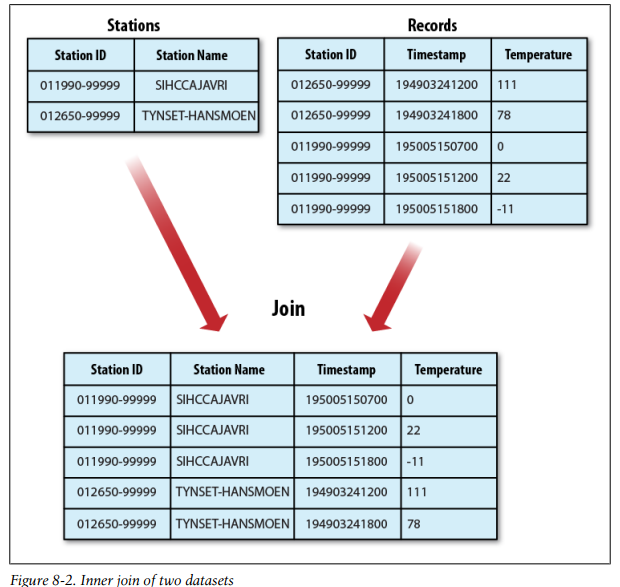
将数据录入到测试文本文件中:
![]()

JOIN操作可以在Map端,也可以在Reducer端完成,至于采用哪种,则要看数据的组织方式。
16.10.1 Map端连接
之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中,如两个表进行关联,表数据来自于不同的数据文件中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。
Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,这样小表可以直接存放到内存中,这样就可以将该小表缓存到读取大表的Map任务中,在Map中就可以完成联接。这样,我们可以将小表复制多份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
(1) 在Job的main()方法中使用静态方法DistributedCache.addCacheFile()指定要复制的文件(一般是主数据文件,如用户、商品等数据量小的主数据文件),它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
(2) 在map()方法中使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件,然后与业务数据文件(一般是大文件,如订单业务交易数据文件,这类文件通过map方法去分布读取)进行关联。
具体查看后面的分布式缓存
16.10.2 Reducer端连接
reduce side join是一种最简单的join方式,其主要思想如下:
在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag),比如:tag=0表示来自文件File1,tag=2表示来自文件File2。即:map阶段的主要任务是对不同文件中的数据打标签。
在reduce阶段,reduce函数获取key相同的来自File1和File2文件的value list, 然后对于同一个key,对File1和File2中的数据进行join(笛卡尔乘积)。即:reduce阶段进行实际的连接操作。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.io.WritableUtils;
publicclassTextPairimplements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
publicvoid set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
returnfirst;
}
public Text getSecond() {
returnsecond;
}
@Override
publicvoid write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
publicvoid readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
publicint hashCode() {
returnfirst.hashCode() * 163 + second.hashCode();
}
@Override
publicboolean equals(Object o) {
if (oinstanceof TextPair) {
TextPair tp = (TextPair) o;
returnfirst.equals(tp.first) && second.equals(tp.second);
}
returnfalse;
}
@Override
public String toString() {
returnfirst + "\t" + second;
}
@Override
publicint compareTo(TextPair tp) {
intcmp = first.compareTo(tp.first);
if (cmp != 0) {
returncmp;
}
returnsecond.compareTo(tp.second);
}
// 自定义排序:用来对分区里的数据进行排序,除了按第一主键气象站ID来排序外,第二辅助标记键也参与排序
publicstaticclass Comparator extends WritableComparator {
privatestaticfinal Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
// 也可以这样获取比较实例
privatestaticfinal WritableComparator TEXT_COMPARATOR2 = WritableComparator.get(Text.class);
public Comparator() {
super(TextPair.class);
}
@Override//具体实现过程请参考前面的TextPair
publicint compare(byte[] b1, ints1, intl1, byte[] b2, ints2, intl2) {
try {
intfirstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
intfirstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
intcmp = TEXT_COMPARATOR2.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
returncmp;
}
// 当第一主键相同时,对第二辅助键进行排序
returnTEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1, b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
thrownew IllegalArgumentException(e);
}
}
}
static {
// 注:这里静态注册的是分区数据排序算法,而不是下面分组排序。该排序类使用不需在JOB里特别设置,会自动使用
WritableComparator.define(TextPair.class, new Comparator());
}
// 自定义排序:用来分组,只根据第一个主键进行分组,即同一气象站数据(气象站元数据与气温数据)
// 传给Reducer前会分在一组里,而忽略第二辅助标记键
publicstaticclass FirstComparator extends WritableComparator {
privatestaticfinal Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
publicint compare(byte[] b1, ints1, intl1, byte[] b2, ints2, intl2) {
try {
// 只根据气象站ID进行排序
intfirstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
intfirstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
returnTEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
thrownew IllegalArgumentException(e);
}
}
@Override
@SuppressWarnings("rawtypes")
publicint compare(WritableComparable a, WritableComparable b) {
if (ainstanceof TextPair && binstanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
returnsuper.compare(a, b);
}
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//该Mapper读取气象站元数据并标记
publicclassJoinStationMapperextends Mapper<LongWritable, Text, TextPair, Text> {
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/*
* 辅助键为0,用来在Reducer中标记数据是来自于气象站数据文件stations.txt,
* 当辅助键为1时表示数据来自于气温数据文件records.txt。 不管数据是气象站还是气温数据,
* Key都是 气象站ID + 数据来源标记
* 组成,将气象站 标记为0,而气温数据标记为1是为了按辅助键升序排序时,让气象数据排在分区的第一条,
* 除第一条外,后面的数据都是来自于气温文件
*/
context.write(new TextPair(value.toString().split("\t")[0], "0"),// 键=气象站ID+标记
new Text(value.toString().split("\t")[1]));// 值=气象站名
}
}
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//该Mapper读取气温数据并标记
publicclassJoinRecordMapperextends Mapper<LongWritable, Text, TextPair, Text> {
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 辅助键为1,用来在Reducer中标记数据是来自于气温数据文件records.txt
context.write(new TextPair(value.toString().split("\t")[0], "1"), // 键=气象站ID+标记
value);// 值为气温记录
}
}
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//该Reducer用来完成数据的Join操作,数据来自于气象站与气温两个数据文件
publicclassJoinReducerextends Reducer<TextPair, Text, Text, Text> {
@Override
protectedvoid reduce(TextPair key, Iterable<Text> values, Context context) throws IOException,
InterruptedException {
Iterator<Text> iter = values.iterator();
// 从map传过来的分区文件中的第一行为气象站元数据,这是由于特定的排序来决定的
// (这里假设每条气温都有一条气象点元数据,否则这里第一条数据需要特殊处理一下)
Text stationName = new Text(iter.next());
// 从分区数据的第二条开始往后就都是气温数据了
while (iter.hasNext()) {
Text record = iter.next();
Text outValue = new Text(stationName.toString() + "\t" + record.toString().split("\t", 2)[1]);
context.write(key.getFirst(), outValue);
}
}
}
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
publicclassJoinRecordWithStationNameextends Configured implements Tool {
// 自定义分区类
publicstaticclass KeyPartitioner extends Partitioner<TextPair, Text> {
@Override
publicint getPartition(TextPair key, Text value, intnumPartitions) {
//只根据第气象ID进行分区,即同一气象站数据会放到同一分区中,&是为了去掉负号
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
@Override
publicint run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath() + "\\JoinRecordWithStationName.jar");
Job job = Job.getInstance(conf, "weather");
job.setJarByClass(JoinRecordWithStationName.class);
Path stationInputPath = new Path("hdfs://hadoop-master:9000/join/stations.txt");
Path ncdcInputPath = new Path("hdfs://hadoop-master:9000/join/records.txt");
Path outputPath = new Path("hdfs://hadoop-master:9000/join/output");
//使用MultipleInputs类来添加多文件源输入
MultipleInputs.addInputPath(job, ncdcInputPath, TextInputFormat.class, JoinRecordMapper.class);
MultipleInputs.addInputPath(job, stationInputPath, TextInputFormat.class, JoinStationMapper.class);
FileOutputFormat.setOutputPath(job, outputPath);
job.setReducerClass(JoinReducer.class);
//设置自定义分区类:只根据第一主键:气象站ID进行分区
job.setPartitionerClass(KeyPartitioner.class);
//设置自定义分组:只根据第一主键:气象站ID进行分组
job.setGroupingComparatorClass(TextPair.FirstComparator.class);
//由于Map的输出与Reducer的输出类型不一样,所以需要使用下面两行分别指定
job.setMapOutputKeyClass(TextPair.class);//设置Map输出类型
job.setOutputKeyClass(Text.class);//设置Reducer输出类型
returnjob.waitForCompletion(true) ? 0 : 1;
}
publicstaticvoid main(String[] args) throws Exception {
intexitCode = ToolRunner.run(new JoinRecordWithStationName(), args);
System.exit(exitCode);
}
}
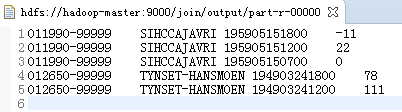
16.10.3 自连接
有以下父子关系:
child parent
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma

要求找出子孙关系。设计思路:将左表的parent与右表的child进行关联。在Map中将上面输出两次,第一次输出为左表,以parent为Key,值为1表示数据来自于左表;第二次输出为右表,以child为Key,值为2表示数据来自于右表。这当数据传到Reducer后,由于相同的Key会分组合并,这样可以在Reducer中取出每个分组,然后取出值列表,将自来左表的数据与来自右表的数据进行笛卡尔积输出即可
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
publicclass ValueText implements Writable {
private Text personName;//人名
private Text from;//数据来自左表还是右表:1—左,2—右
public ValueText() {
set(new Text(), new Text());
}
public ValueText(String personName, String from) {
set(new Text(personName), new Text(from));
}
public ValueText(Text personName, Text from) {
set(personName, from);
}
publicvoid set(Text personName, Text from) {
this.personName = personName;
this.from = from;
}
public Text getPersonName() {
returnpersonName;
}
public Text getFrom() {
returnfrom;
}
@Override
publicvoid write(DataOutput out) throws IOException {
personName.write(out);
from.write(out);
}
@Override
publicvoid readFields(DataInput in) throws IOException {
personName.readFields(in);
from.readFields(in);
}
@Override
public String toString() {
returnpersonName + "\t" + from;
}
}
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
publicclass JoinSelf extends Configured implements Tool {
staticclass SelfMapper extends Mapper<LongWritable, Text, Text, ValueText> {
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (value.toString().length() != 0) {
// 输出左表数据
context.write(new Text(value.toString().split("\t")[1]),// Key为parent
new ValueText(value.toString().split("\t")[0], "1"));// 值为child,使用1来标记,表示是左表
// 输出右表数据
context.write(new Text(value.toString().split("\t")[0]),// Key为child
new ValueText(value.toString().split("\t")[1], "2"));// 值为parent,用2来标记,表示是右表
}
}
}
staticclass SelfReducer extends Reducer<Text, ValueText, ValueText, Text> {
@Override
protectedvoid reduce(Text key, Iterable<ValueText> values, Context context) throws IOException,
InterruptedException {
ArrayList<Text> lefTab = new ArrayList<Text>();
ArrayList<Text> rightTab = new ArrayList<Text>();
for (ValueText vt : values) {
if (vt.getFrom().toString().equals("1")) {
/*
* 但key和value相关的对象只有两个,reduce会反复重用这两个对象(每次清除里面的内容,然后重用
* Key与Value对象本身)所以如果要保存key或者value的结果,只能将其中的值取出另存或者重新clone
* 一个对象(例如Text store = new Text(value) 或者String a = value.toString()),而不能
* 直接赋引用,否则集合中存储的将是最后一次Key与Value
*/
lefTab.add(new Text(vt.getPersonName()));
} elseif (vt.getFrom().toString().equals("2")) {
rightTab.add(new Text(vt.getPersonName()));
}
}
for (Text textL : lefTab) {
for (Text textR : rightTab) {
context.write(new ValueText(textL,key), textR);
}
}
}
}
@Override
publicint run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("mapred.remote.os", "Linux");
conf.set("mapred.jar", new File("").getAbsolutePath() + "\\JoinSelf.jar");
Job job = Job.getInstance(conf, "selfjoin");
job.setJarByClass(JoinSelf.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop-master:9000/join/self/self.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/join/self/output"));
job.setMapperClass(SelfMapper.class);
job.setReducerClass(SelfReducer.class);
// 由于Map与Reducer的输出值类型不一样,所在需要以下两行设置
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(ValueText.class);
// 由于Map与Rducer的输出健类型不一样,所在需要以下两行设置
job.setMapOutputKeyClass(Text.class);
job.setOutputKeyClass(ValueText.class);
returnjob.waitForCompletion(true) ? 0 : 1;
}
publicstaticvoid main(String[] args) throws Exception {
intexitCode = ToolRunner.run(new JoinSelf(), args);
System.exit(exitCode);
}
}
16.11 map、reduce函数参数传递
写MapReduce程序通常要传递各种各样的参数到map()与reduce()方法中,最直接的方式就是使用Configuration的各种set(String name, String value)方法,但这要求值为字符串类型,即如果传递的是某个对象,此时需要将对象先转换为字符串才能传递,一般我们是调用其对象的toString()进行转换,但这可能会出问题:如果数字对象的精度丢失与字节内容的膨胀,这就要用到org.apache.hadoop.io.DefaultStringifier这个类,通过这个类,将对象的反序列化的出来的字节内容通过Base64进行编码成字符串,然后再进行传递,这种方法的好处是保证了原始的内容,内容也不会膨胀
下面是不通过Configuration进行传递时,由于任务跑在不同的JVM上,所以很多时候会出问题,如下面:
1. Java编写MapReduce程序时,如何向map、reduce函数传递参数
先做个实验:
在主类中声明两个静态变量, 然后在 main 函数中给变量赋值, 试图在 map和reduce函数中获得变量的值。
代码结构类似如下:
![说明: [MapReduce] <wbr>如何向map和reduce脚本传递参数,加载文件和目录《转载》](https://images2015.cnblogs.com/blog/717614/201701/717614-20170125113052503-208652598.png)
提交到集群运行发现在 map 和 reduce函数中, 静态变量MaxScore的值始终是初值1。
于是试图在主类的静态区(图中的2)中给变量赋值 (因为静态区中的代码比main中的代码要先执行), 仍是不成功, MaxScore的值始终是初值1。
将上述代码在 单机hadoop上运行, 结果正常, map 函数中能获得变量的值。
思考是这个原因: 在提交作业到hadoop集群后,mapper类和reducer类就到各个 tasktracker上去运行了, 与主类独立, 不能交互。
因此,上述往 map 和 reduce 函数传参数的方法实在太天真。
于是想到其它一些方法: 例如将参数写入hdfs文件中, 然后在 mapper 和 reducer 类的 run方法中读取文件, 并将值读到相应变量,这是可行的,但是方法较复杂,代码如下:
![说明: [MapReduce] <wbr>如何向map和reduce脚本传递参数,加载文件和目录《转载》](https://images2015.cnblogs.com/blog/717614/201701/717614-20170125113052831-445127654.png)
上述方法尽管可用, 但是不是常规方法, 下面介绍常用的方法:
16.11.1 通过 Configuration 传递
在main函数中调用set方法设置参数, 例如:
![说明: [MapReduce] <wbr>如何向map和reduce脚本传递参数,加载文件和目录《转载》](https://images2015.cnblogs.com/blog/717614/201701/717614-20170125113053128-1418625849.png)
在mapper中通过上下文context来获取当前作业的配置, 并获取参数, 例如:
![说明: [MapReduce] <wbr>如何向map和reduce脚本传递参数,加载文件和目录《转载》](https://images2015.cnblogs.com/blog/717614/201701/717614-20170125113053362-1642493042.png)
注: context 很有用, 能获取当前作业的大量信息,例如上面就获取了任务ID.
16.11.2 通过DefaultStringifier类
直接将对象转换为字符串(调用其toString())方法,然后使用Configuration.set(String name, String value)传递这个字符串到map、reduce方法中进行解析,这种方法有些缺点:如将对象变成字符串会有精度上的损失,如 double类型转换成字符串,不仅精度有损失,而且8字节的空间用字符串来表示可能会变成几十字节。正确的方法是,让这个对象实现Writable接口,使它具有序列化的能力,然后使用org.apache.hadoop.io.DefaultStringifier的store(Configuration conf, K item, String keyName)和load(Configuration conf, String keyName, Class<K> itemClass)静态方法设置和获取这个对象。他的主要思想就是将这个对象序列化成一个字节数组后,用Base64编码成一个字符串,然后传递给 conf, 解析的时候与之类似。
Configuration conf = new Configuration();
Text maxscore = new Text("12989");
DefaultStringifier.store(conf, maxscore, "maxscore");
在Job中这样设置后,Text对象maxscore就以“maxscore”作为key存储在conf对象中了,然后在map和reduce方法中调用load的方法便可以把对象读出:
Configuration conf = context.getConfiguration();
Text out = DefaultStringifier.load(conf, "maxscore", Text.class);
需要说明的是,这个需要传递的对象必须要先实现序列化的接口Writable
下面看看DefaultStringifier的store()方法原型:
/**
* Stores the item in the configuration with the given keyName.
*
* @param<K> the class of the item
* @param conf the configuration to store
* @param item the object to be stored
* @param keyName the name of the key to use
*/ publicstatic <K> void store(Configuration conf, K item, String keyName) throws IOException {
DefaultStringifier<K> stringifier = new DefaultStringifier<K>(conf, GenericsUtil.getClass(item));
conf.set(keyName, stringifier.toString(item));//存储到conf对象中的类型最后是字符串,但这是如何将对象转换为字符串,请看后面DefaultStringifier的toString()方法
stringifier.close();
}
DefaultStringifier的toString()方法原型:
@Override
public String toString(T obj) throws IOException {
outBuf.reset();
serializer.serialize(obj);//最终调用了writable.write(dataOut);方法来完成序列化
byte[] buf = newbyte[outBuf.getLength()];
System.arraycopy(outBuf.getData(), 0, buf, 0, buf.length);
returnnew String(Base64.encodeBase64(buf), Charsets.UTF_8);//将序列化出来的二进制转换为Base64编码格式的字符串,所以最终存储到conf对象中的就是这个Base64格式的字符串
}
再看看DefaultStringifier的load ()方法:
/**
* Restores the object from the configuration.
*
* @param<K> the class of the item
* @param conf the configuration to use
* @param keyName the name of the key to use
* @param itemClass the class of the item
* @return restored object
*/
publicstatic <K> K load(Configuration conf, String keyName, Class<K> itemClass) throws IOException {
DefaultStringifier<K> stringifier = new DefaultStringifier<K>(conf, itemClass);
try {
String itemStr = conf.get(keyName);
returnstringifier.fromString(itemStr);//先调用fromString()(具体实现请看下面)方法将Base64编码格式的字符串转换成二进制字节数组,最后将该二进制字节数组反序列化成原始对象
} finally {
stringifier.close();
}
}
@Override
public T fromString(String str) throws IOException {
try {
byte[] bytes = Base64.decodeBase64(str.getBytes("UTF-8"));//将Base64编码格式的字符串转换成二进制字节数组
inBuf.reset(bytes, bytes.length);
T restored = deserializer.deserialize(null);//最终通过writable.readFields(dataIn);进行反序列化
returnrestored;
} catch (UnsupportedCharsetException ex) {
thrownew IOException(ex.toString());
}
}
16.11.2.1 第三方JavaBean
此方法需要注意一点是obj这个对象需要实现Writable接口,使它具有序列化的能力。此对象的Writable接口可以自己实现也可以将此obj转化为BytesWritable类型的(因为DefaultStringifier的set与load方法参数需要的类型要是Writable,BytesWritable就像InteWritable一样,是实现了Writable接口的),这样在从conf中取出的时候还得进行反转,转化方法可以这样写:
privatestatic BytesWritable transfer(Object patterns) {
ByteArrayOutputStream baos = null;
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(newByteArrayOutputStream());//借助于Java标准的序列化来实现
oos.writeObject(patterns);
oos.flush();
returnnew BytesWritable(baos.toByteArray());//最后再将这个BytesWritable对应传递给DefaultStringifier即可,这样这个patterns类就不需要实现Writable接口了,因为这个类可能是第三方提供的JavaBean,我们没法让去实现Writable
} catch (Exception e) {
} finally {
IoUtils.close(baos);
IoUtils.close(oos);
}
returnnull;
}
反转方法为:
privatestatic Object transferMRC(byte[] bytes) {
ObjectInputStream is = null;
try {
is = new ObjectInputStream(new ByteArrayInputStream(bytes));
returnis.readObject();
} catch (Exception e) {
} finally {
IoUtils.close(is);
}
returnnull;
}
但是如果遇到更大的参数呢?比如分词用的语料库等等,这时就应该用到Hadoop的缓存机制Distributed Cache了。
16.12 Distributed Cache分布式缓存
如果传递的参数数据量比较大,就不适合通过conf对象来传递了,因为这些参数是直接放在内存中的,这时可以考虑Distributed Cache,比如前面的抽样分区示例。
DistributedCache是Hadoop提供的文件缓存工具,它能够自动将指定的文件分发到各个节点上,缓存到任务执行节点的本地磁盘中,供用户程序(多为map()与reduce()方法)读取使用。它具有以下几个特点:缓存的文件是只读的,修改这些文件内容没有意义;用户可以调整文件可见范围(比如只能用户自己使用,所有用户都可以使用等),进而防止重复拷贝现象;按需拷贝,文件是通过HDFS作为共享数据中心分发到各节点的,且只发给任务被调度到的节点。本文将介绍DistributedCache在Hadoop 1.0和2.0中的使用方法及实现原理。
Hadoop DistributedCache有以下几种典型的应用场景:
1)分发字典文件,一些情况下Mapper或者Reducer需要用到一些外部字典,比如黑白名单、词表等;
2)map-side join:当多表连接时,一种场景是一个表很大,一个表很小,小到足以加载到内存中,这时可以使用DistributedCache将小表分发到各个节点上,以供Mapper加载使用;
3)分发第三方库(jar,so等)
注:需要分发的文件,必须提前放到hdfs上,默认的路径前缀是hdfs://的,不是file://
Hadoop提供了两种DistributedCache使用方式,一种是通过API,在程序中设置文件路径,另外一种是通过命令行(-files,-archives或-libjars)参数告诉Hadoop,个人建议使用第二种方式,该方式可使用以下三个参数设置文件:
(1)-files:将指定的本地/hdfs文件分发到各个Task的工作目录(hadoop jar ... .jar包所在的目录?)下,不对文件进行任何处理;
(2)-archives:将指定文件分发到各个Task的工作目录下,并对名称后缀为“.jar”、“.zip”,“.tar.gz”、“.tgz”的文件自动解压,比如压缩包为dict.zip,则解压后内容存放到目录dict.zip中。为此,你可以给文件起个别名(软链接),比如dict.zip#dict,这样,压缩包会被解压到目录dict中。
(3)-libjars:指定待分发的jar包,Hadoop将这些jar包分发到各个节点上后,会将其自动添加到任务的CLASSPATH环境变量中。
前面提到,DistributedCache分发的文件是有可见范围的,有的文件可以只对当前程序可见,程序运行完后,直接删除;有的文件只对当前用户可见(该用户所有程序都可以访问);有的文件对所有用户可见。DistributedCache会为每种资源(文件)计算一个唯一ID,以识别每个资源,从而防止资源重复下载,举个例子,如果文件可见范围是所有用户,则在每个节点上,第一个使用该文件的用户负责缓存该文件,之后的用户直接使用即可,无需重复下载。那么,Hadoop是怎样区分文件可见范围的呢?
在Hadoop 1.0版本中,Hadoop是以HDFS文件的属性作为标识判断文件可见性的,需要注意的是,待缓存的文件即使是在Hadoop提交作业的客户端(Linux服务器,安装了Hadoop)上,也会首先上传到HDFS的某一目录下,再分发到各个节点上的,因此,HDFS是缓存文件的必经之路。对于经常使用的文件或者字典,建议放到HDFS上,这样可以防止每次重复下载,做法如下:
比如将数据保存在HDFS的/dict/public目录下,并将/dict和/dict/public两层目录的可执行权限全部打开(在Hadoop中,可执行权限的含义与linux中的不同,该权限只对目录有意义,表示可以查看该目录中的子目录),这样,里面所有的资源(文件)便是所有用户可用的,并且第一个用到的应用程序会将之缓存到各个节点上,之后所有的应用程序无需重复下载,可以在提交作业时通过以下命令指定:
-files hdfs:///dict/public/blacklist.txt, hdfs:///dict/public/whilelist.txt
如果有多个HDFS集群可以指定namenode的对外rpc地址:
-files hdfs://host:port/dict/public/blacklist.txt, hdfs://host:port/dict/public/whilelist.txt
DistributedCache会将blacklist.txt和whilelist.txt两个文件缓存到各个节点的一个公共目录下,并在需要时,在任务的工作目录下建立一个指向这两个文件的软连接。
如果可执行权限没有打开,则默认只对该应用程序的拥有者可见,该用户所有应用程序可共享这些文件。
一旦你对/dict/public下的某个文件进行了修改,则下次有作业用到对应文件时,会发现文件被修改过了,进而自动重新缓存文件。
对于一些频繁使用的字典,不建议存放在客户端,每次通过-files指定这样的文件,每次都要经历以下流程:上传到HDFS上—》缓存到各个节点上—》之后不再使用这些文件,直到被清除,也就是说,这样的文件,只会被这次运行的应用程序使用,如果再次运行同样的应用程序,即使文件没有被修改,也会重新经历以上流程,非常耗费时间,尤其是字典非常多,非常大时。
DistributedCache内置缓存置换算法,一旦缓存(文件数目达到一定上限或者文件总大小超过某一上限)满了之后,会踢除最久没有使用的文件。
在Hadopo 2.0中,自带的MapReduce框架仍支持1.0的这种DistributedCache使用方式,但DistributedCache本身是由YARN实现的,不再集成到MapReduce中。YARN还提供了很多相关编程接口供用户调用,有兴趣的可以阅读源代码。
下面介绍Hadoop 2.0中,DistributedCache通过命令行分发文件的基本使用方式:
(1)运行Hadoop自带的example例子, dict.txt会被缓存到各个Task的工作目录下,因此,直接像读取本地文件一样,在Mapper和Reducer中,读取dict.txt即可:
bin/Hadoop jar \
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar \
wordcount \
-files hdfs:///dict/public/dict.txt \
/test/input \
/test/output
(3)接下给出一个缓存压缩文件的例子,假设压缩文件为dict.zip,里面存的数据为:
data/1.txt
data/2.txt
mapper.list
reducer.list
通过-archives参数指定dict.zip后,该文件被解压后,将被缓存(实际上是软连接)到各个Task的工作目录下的dict.zip目录下,组织结构如下:
dict.zip/
data/
1.txt
2.txt
mapper.list
reducer.list
你可以在Mapper或Reducer程序中,使用类似下面的代码读取解压后的文件:
File file2 = read(“dict.zip/data/1.txt”, “r”);
…….
File file3 = read(“dict.zip/mapper.list”, “r”);
疑问:为什么MapReduce不直接通过API读取HDFS中的文件呢?为什么一定得用DistributedCache分发到Task所在的节点本地呢?
因为Map或Reduce依赖的外部资源大部分是本地资源,比如jar包,可执行文件等,这些资源,必须在本地才能使用,比如jar包必须加到环境变量CLASSPATH中,而CLASSPATH是不能识别HDFS文件的,JVM不支持;另外,HDFS上的文件是不可以直接执行的,必须放到本地,这个除非支持远程执行或者远程调用,这个在默认情况下,操作系统是不支持的。 除了上面这些原因,还有一个是,文件放到本地后程序读取数据更快,因为数据不需要在网络中传输了。
16.12.1 MR1
1、通过配置
可以配置这三个属性值:
mapred.cache.files,
mapred.cache.archives,
mapred.create.symlink (值设为yes 如果要建link的话)注:在由于在2.X版本后,没有该类设置,如连接中有#,则会自动创建,所以2.0后不再使用
也可以通过设置配置文档里的属性 mapred.job.classpath.{files|archives}
如果要分发的文件有多个的话,要以逗号分隔(貌似在建link的时候,逗号分隔前后还不能有空,,否则会报错)
2、使用命令行
在pipes和streaming里面可能会用到
-files Specify comma-separated files to be copied to the Map/Reduce cluster
-libjars Specify comma-separated jar files to include in the classpath
-archives Specify comma-separated archives to be unarchived on the compute machines
例如:
-files hdfs://host:fs_port/user/testfile.txt
-files hdfs://host:fs_port/user/testfile.txt#testfile
-files hdfs://host:fs_port/user/testfile1.txt,hdfs://host:fs_port/user/testfile2.txt
-archives hdfs://host:fs_port/user/testfile.jar
-archives hdfs://host:fs_port/user/testfile.tgz#tgzdir
注:只要命令行中(hadoo jar ...)运行Job时指定了上面某个参数,则就会将指定的文件分发到Task任务节点的本地,如下面命令:
% hadoop jar hadoop-examples.jar MaxTemperatureByStationNameUsingDistributedCacheFile \
-files input/ncdc/metadata/stations-fixed-width.txt input/ncdc/all output
上面运行MaxTemperatureByStationNameUsingDistributedCacheFile作业时,会先将input/ncdc/metadata/stations-fixed-width.txt文件分发到任务执行节点的本地input/ncdc/all output分别为输入输出目录
上面的命令将本地文件stations-fixed-width.txt(未指定文件系统,从而被自动解析为本地文件)复制到任务节点,从而可以查找气象站名称,下面是在reducer中使用这个分发的缓存文件代码:
protectedvoid setup(Context context) throws IOException, InterruptedException {
metadata = new NcdcStationMetadata();
//使用命令方式运行Job时会自动创建symlink符号软连接,软连接名默认就是文件名自身,除非使用#在URI里指定
metadata.initialize(new File("stations-fixed-width.txt"));
}
命令工作机制:
当用户启动一个作业,Hadoop会把由-files、-archives、-libjars等选项所指定的文件复制到分布式文件系统(一般是HDFS)之中,接着会在任务运行前,tasktracker将文件从HDFS系统复制到本地磁盘缓存起来使任务能够访问文件。此外,由-libjars指定的文件会在任务启动前添加到任务的类路径(classpath)中
3、代码调用
DistributedCache.addCacheFile(URI,conf) / DistributedCache.addCacheArchive(URI,conf)
DistributedCache.setCacheFiles(URIs,conf) / DistributedCache.setCacheArchives(URIs,conf)
DistributedCache.addArchiveToClassPath(Path, Configuration, FileSystem) //将文件加载到jvm的classpath
DistributedCache.addFileToClassPath //将文件加载到jvm的classpath
如果要建link,需要增加DistributedCache.createSymlink(Configuration),注:在由于在2.X版本后,不需要手动来创建,如连接中有#,则会自动创建,所以2.0后不再使用
其中URI的形式是 hdfs://host:port/absolute-path#link-name。
hdfs://namenode:port/lib.so.1#lib.so,则在task当前工作目录会有名为lib.so的连接文件, 它指向了本地缓存目录(${hadoop.tmp.dir}/mapred/local)下的lib.so.1。

获取cache文件可以使用
DistributedCache.getLocalCacheFiles(Configuration conf)
DistributedCache.getLocalCacheArchives(Configuration conf)
public Path[] getLocalCacheFiles() throws IOException;
public Path[] getLocalCacheArchives() throws IOException;
public Path[] getFileClassPaths();
public Path[] getArchiveClassPaths();
代码调用常常会有各样的问题,一般我比较倾向于通过createSymlink的方式来使用,就把cache当做当前目录的文件来操作,简单很多。常见的通过代码来读取cache文件的问题如下:
DistributedCache.getLocalCacheFiles在伪分布式情况下,常常返回null.
DistributedCache.getLocalCacheFiles其实是把DistributedCache中的所有文件都返回(可以使用软连接解决,参考下面符号连接)。需要自己筛选出所需的文件.archives也有类似的问题
DistributedCache.getLocalCacheFiles返回的是tt机器本地文件系统的路径,使用的时候要注意,因为很多地方默认的都是hdfs://,可以自己加上file://来避免这个问题
4、symlink符号连接
给分发的文件,在task运行的当前工作目录建立软连接(如同Linux下的ln -s命令),在使用起来的时候会更方便,没有上面的各种麻烦
conf.set("mapred.cache.files", "/data/data#mData");
conf.set("mapred.cache.archives", "/data/data.zip#mDataZip");//会在Task工作目录创建名为mDataZip的软连接指向本地缓存目录(${hadoop.tmp.dir}/mapred/local)下的data.zip文件
@Override
protectedvoid setup(Context context) throws IOException,InterruptedException {
super.setup(context);
FileReader reader = new FileReader(new File("mData"));
BufferedReader bReader = new BufferedReader(reader);
// TODO
}
在使用symlink之前,需要告知hadoop,如下:
conf.set("mapred.create.symlink", "yes"); // 通过配置设置。是yes,不是true
DistributedCache.createSymlink(Configuration)//通过API设置。注:在由于在2.X版本后,不需要手动来创建,如连接中有#,则会自动创建,所以2.0后不再使用
5、缓存在本地的存储目录:
<property>
<name>mapreduce.cluster.local.dir</name>
<value>${hadoop.tmp.dir}/mapred/local</value>
<description>The local directory where MapReduce stores intermediate
data files. May be a comma-separated list of
directories on different devices in order to spread disk i/o.
Directories that do not exist are ignored.
</description>
</property>
在Job的main()方法中,将HDFS文件添加到distributed cache中:
Configuration conf = job.getConfiguration();
DistributedCache.addCacheFile(new
URI(inputFileOnHDFS), conf); // add file to
distributed cache
其中,inputFileOnHDFS是一个HDFS文件的路径。在mapper的setup()方法中使用:
Configuration conf = context.getConfiguration();
Path[] localCacheFiles = DistributedCache.getLocalCacheFiles(conf);
readCacheFile(localCacheFiles[0]);
其中,readCacheFile()是我们自己的读取cache文件的方法,可能是这样做的(仅举个例子):
privatestaticvoid readCacheFile(Path cacheFilePath) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(cacheFilePath.toUri().getPath()));
String line;
while ((line = reader.readLine()) != null) {
//TODO: your code here
}
reader.close();
}
要获得cache数据,就得在map/reduce task中的setup方法中取得cache数据,再进行相应操作:
protectedvoid setup(Context context) throws IOException, InterruptedException {
super.setup(context);
URI[] uris = DistributedCache.getCacheFiles(context.getConfiguration());
Path[] paths = DistributedCache.getLocalCacheFiles(context.getConfiguration());
// TODO
}
而三方库的使用稍微简单,只需要将库上传至hdfs,再用代码添加至classpath即可:
DistributedCache.addArchiveToClassPath(new Path("/data/test.jar"), conf);
16.12.2 MR2
上面的代码中,addCacheFile() 方法和 getLocalCacheFiles() 都已经被Hadoop 2.x标记为 @Deprecated 了。
因此,有一套新的API来实现同样的功能,如下面将HDFS文件添加到distributed cache中:
job.addCacheFile(new Path(inputFileOnHDFS).toUri());
在mapper的setup()方法中:
Configuration conf = context.getConfiguration();
URI[] localCacheFiles = context.getCacheFiles();
readCacheFile(localCacheFiles[0]);
其中,readCacheFile()是我们自己的读取cache文件的方法,参考上面
我用的是Hadoop 2.5.1版,这一版里面DistributedCache已经被Deprecated了。最好是用标准命令行参数-files <file1>,<file2>...来上传DistributedCache文件。上传的文件会被自动拷贝到data node的本地文件系统中,并被强制建立符号链接,符号链接的文件名就是#号后面的部分,缺省是上传前本地文件名。
指定-files参数时估计可以带#号指定符号链接文件名,不过我没试过。
16.12.3 相关配置
16.12.3.1 MR1
|
属性名 |
默认值 |
备注 |
|
${hadoop.tmp.dir}/mapred/local |
The local directory where MapReduce stores intermediate data files. May be a comma-separated list of directories on different devices in order to spread disk i/o. Directories that do not exist are ignored. |
|
|
10737418240(10G) |
The number of bytes to allocate in each local TaskTracker directory for holding Distributed Cache data. |
|
|
10000 |
The maximum number of subdirectories that should be created in any particular distributed cache store. After this many directories have been created, cache items will be expunged regardless of whether the total size threshold has been exceeded. |
|
|
mapreduce.tasktracker.cache.local.keep.pct |
0.95(作用于上面2个参数) |
It is the target percentage of the local distributed cache that should be kept in between garbage collection runs. In practice it will delete unused distributed cache entries in LRU order until the size of the cache is less than mapreduce.tasktracker.cache.local.keep.pct of the maximum cache size. This is a floating point value between 0.0 and 1.0. The default is 0.95. |
16.12.3.2 MR2
yarn.nodemanager.delete.debug-delay-sec
yarn.nodemanager.local-cache.max-files-per-directory
yarn.nodemanager.localizer.cache.cleanup.interval-ms
yarn.nodemanager.localizer.cache.target-size-mb
附件列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号