CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
本文档主要记录了Hadoop+Hive+Spark集群安装过程,并且对NameNode与ResourceManager进行了HA高可用配置,以及对NameNode的横向扩展(Federation联邦)
1 VM网络配置
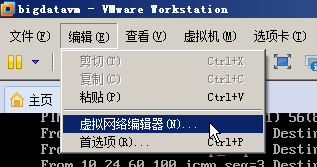
将子网IP设置为192.168.1.0:

将网关设置为192.168.1.2:

并禁止DHCP
当经过上面配置后,虚拟网卡8的IP会变成192.168.1.1:

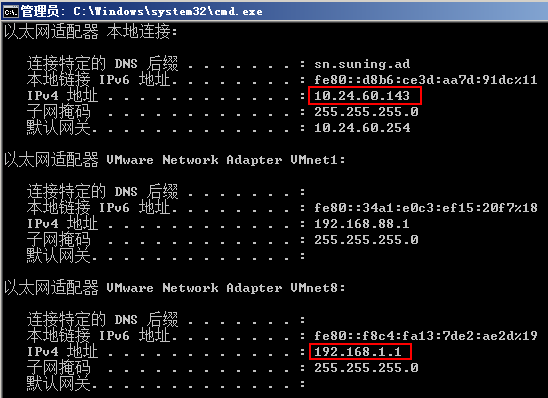
(虚拟机与物理机不在一个网段是没有关系的)
2 CentOS配置
2.1 下载地址
http://mirrors.neusoft.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1511.iso
下载不带桌面的最小安装版本
2.2 激活网卡
激活网卡,并设置相关IP:
![]()
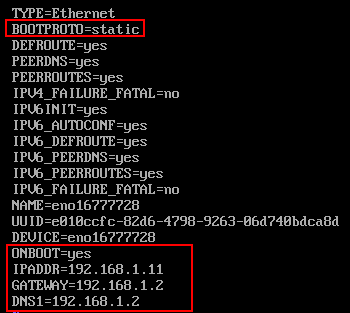
网关与DNS设置为上面虚拟网卡8中设置的网关即可
2.3 SecureCRT
当网卡激活后,就可以使用SecureCRT终端远程连接Linux,这样方便后续操作。如何连接这里省略,
这里连接上后简单的进行下面设置:


2.4 修改主机名
/etc/sysconfig/network
![]()
/etc/hostname
![]()
/etc/hosts

192.168.1.11 node1
192.168.1.12 node2
192.168.1.13 node3
192.168.1.14 node4
2.5 yum代理上网
由于公司内部是代理上网,所以yum无法连网搜索软件包
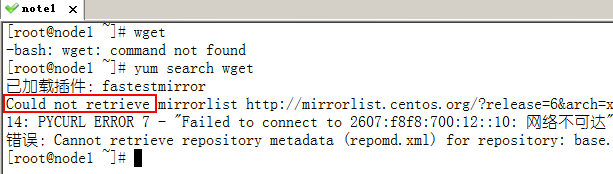
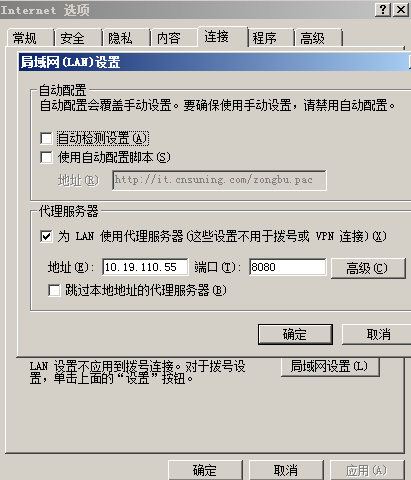
yum代理的设置:vi /etc/yum.conf

再次运行yum,发现可以连网搜索软件包了:
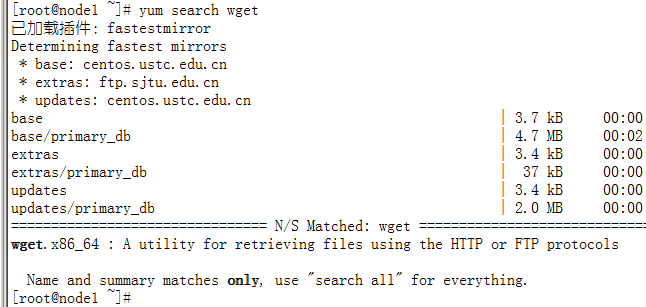
2.6 安装ifconfig

2.7 wget安装与代理
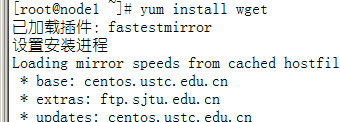
安装好wget后,在/etc目录下就会产生wget配置文件wgetrc,在这里面可以配置wget代理:
[root@node1 ~]# vi /etc/wgetrc

http_proxy = http://10.19.110.55:8080
https_proxy = http://10.19.110.55:8080
ftp_proxy = http://10.19.110.55:8080
2.8 安装VMware Tools
为了虚拟机与主机时间同步,所以需要安装VMWare Tools
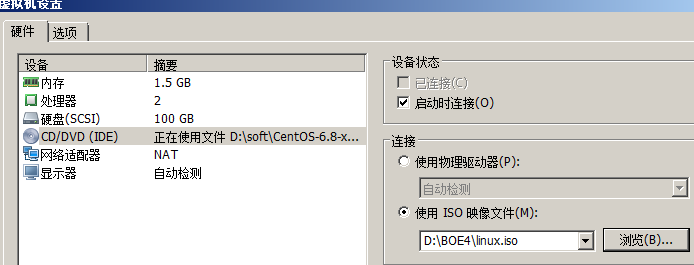
[root@node1 opt]# yum -y install perl
[root@node1 ~]# mount /dev/cdrom /mnt
[root@node1 ~]# tar -zxvf /mnt/VMwareTools-9.6.1-1378637.tar.gz -C /root
[root@node1 ~]# umount /dev/cdrom
[root@node1 ~]# /root/vmware-tools-distrib/vmware-install.pl
[root@node1 ~]# rm -rf /root/vmware-tools-distrib
注:下面文件共享与鼠标拖放功能不要安装,否则安装过程会出问题:

[root@node1 ~]# chkconfig --list | grep vmware
vmware-tools 0:关 1:关 2:开 3:开 4:开 5:开 6:关
vmware-tools-thinprint 0:关 1:关 2:开 3:开 4:开 5:开 6:关
[root@node1 ~]# chkconfig vmware-tools-thinprint off
[root@node1 ~]# find / -name *vmware-tools-thinprint* | xargs rm -rf
2.9 其他
2.9.1 问题
刚启动时会出以下错误提示:

修改虚拟机配置文件node1.vmx可以解决:
vcpu.hotadd = "FALSE"
mem.hotadd = "FALSE"
2.9.2 设置
2.9.2.1去掉开机等待时间
[root@node1 ~]# vim /etc/default/grub
GRUB_TIMEOUT=0 #默认为5秒
[root@node1 ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
2.9.2.2VM调整
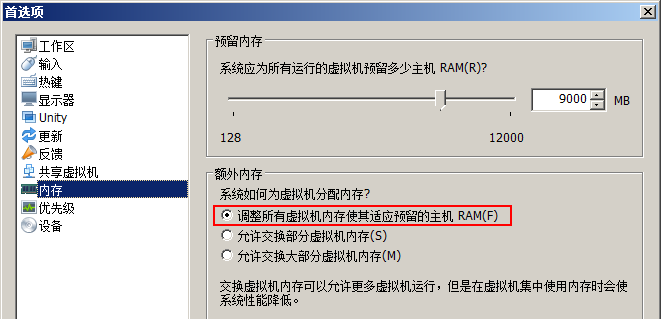
(注:小内存禁用)
修改node1.vmx文件:
mainMem.useNamedFile = "FALSE"
为了全屏显示,方便命令行输入,做以下调整:
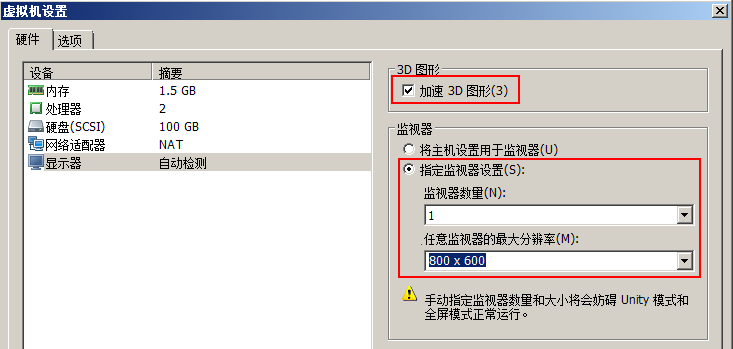
并去掉状态栏显示:

2.9.3 命令
2.9.3.1关机与重启
[root@node1 ~]# reboot
[root@node1 ~]# shutdown -h now
2.9.3.2服务停止与禁用
#查看开机自启动服务
[root@node1 ~]# systemctl list-unit-files | grep enabled | sort
auditd.service enabled
crond.service enabled
dbus-org.freedesktop.NetworkManager.service enabled
dbus-org.freedesktop.nm-dispatcher.service enabled
default.target enabled
dm-event.socket enabled
getty@.service enabled
irqbalance.service enabled
lvm2-lvmetad.socket enabled
lvm2-lvmpolld.socket enabled
lvm2-monitor.service enabled
microcode.service enabled
multi-user.target enabled
NetworkManager-dispatcher.service enabled
NetworkManager.service enabled
postfix.service enabled
remote-fs.target enabled
rsyslog.service enabled
sshd.service enabled
systemd-readahead-collect.service enabled
systemd-readahead-drop.service enabled
systemd-readahead-replay.service enabled
tuned.service enabled
[root@node1 ~]# systemctl | grep running | sort
crond.service loaded active running Command Scheduler
dbus.service loaded active running D-Bus System Message Bus
dbus.socket loaded active running D-Bus System Message Bus Socket
getty@tty1.service loaded active running Getty on tty1
irqbalance.service loaded active running irqbalance daemon
lvm2-lvmetad.service loaded active running LVM2 metadata daemon
lvm2-lvmetad.socket loaded active running LVM2 metadata daemon socket
NetworkManager.service loaded active running Network Manager
polkit.service loaded active running Authorization Manager
postfix.service loaded active running Postfix Mail Transport Agent
rsyslog.service loaded active running System Logging Service
session-1.scope loaded active running Session 1 of user root
session-2.scope loaded active running Session 2 of user root
session-3.scope loaded active running Session 3 of user root
sshd.service loaded active running OpenSSH server daemon
systemd-journald.service loaded active running Journal Service
systemd-journald.socket loaded active running Journal Socket
systemd-logind.service loaded active running Login Service
systemd-udevd-control.socket loaded active running udev Control Socket
systemd-udevd-kernel.socket loaded active running udev Kernel Socket
systemd-udevd.service loaded active running udev Kernel Device Manager
tuned.service loaded active running Dynamic System Tuning Daemon
vmware-tools.service loaded active running SYSV: Manages the services needed to run VMware software
wpa_supplicant.service loaded active running WPA Supplicant daemon
#查看一个服务的状态
systemctl status auditd.service
#开机时启用一个服务
systemctl enable auditd.service
#开机时关闭一个服务
systemctl disable auditd.service
systemctl disable postfix.service
systemctl disable rsyslog.service
systemctl disable wpa_supplicant.service
#查看服务是否开机启动
systemctl is-enabled auditd.service
2.9.3.3查大文件目录
find . -type f -size +10M -print0 | xargs -0 du -h | sort -nr
将前最大的前20目录列出来,--max-depth表示目录深度,如果去掉,则遍历所有子目录:
du -hm --max-depth=5 / | sort -nr | head -20
find /etc -name '*srm*' #表示在/etc目录下查找文件名中含有字符
2.9.3.4查看磁盘使用情况
[root@node1 dev]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 50G 1.5G 49G 3% /
devtmpfs 721M 0 721M 0% /dev
tmpfs 731M 0 731M 0% /dev/shm
tmpfs 731M 8.5M 723M 2% /run
tmpfs 731M 0 731M 0% /sys/fs/cgroup
/dev/mapper/centos-home 47G 33M 47G 1% /home
/dev/sda1 497M 106M 391M 22% /boot
tmpfs 147M 0 147M 0% /run/user/0
2.9.3.5查看内存使用情况
[root@node1 dev]# top
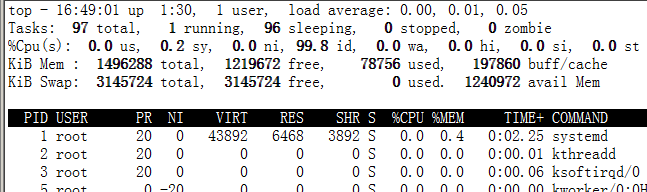
3 安装JDK
JDK所有旧版本在官网中的下载地址:http://www.oracle.com/technetwork/java/archive-139210.html
在线下载jdk-8u72-linux-x64.tar.gz,并存放在/root下:
wget -O /root/jdk-8u92-linux-x64.tar.gz http://120.52.72.24/download.oracle.com/c3pr90ntc0td/otn/java/jdk/8u92-b14/jdk-8u92-linux-x64.tar.gz
[root@node1 ~]# tar -zxvf /root/jdk-8u92-linux-x64.tar.gz -C /root
[root@node1 ~]# vi /etc/profile
在/etc/profile文件的最末加上如下内容:
export JAVA_HOME=/root/jdk1.8.0_92
export PATH=.:$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@node1 ~]# source /etc/profile
[root@node1 ~]# java -version
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build 1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
使用env命令查看当前设置的环境变量是否正确:
[root@node1 ~]# env | grep CLASSPATH
CLASSPATH=.:/root/jdk1.8.0_92/jre/lib/rt.jar:/root/jdk1.8.0_92/lib/dt.jar:/root/jdk1.8.0_92/lib/tools.jar
4 复制虚拟机
前面只安装一台node1的物理机,现从node1复制出node2\node3\node3
|
node1 |
192.168.1.11 |
|
node2 |
192.168.1.12 |
|
node3 |
192.168.1.13 |
|
node4 |
192.168.1.14 |
修改相应虚拟机显示名:

开机时选择复制:

![]()
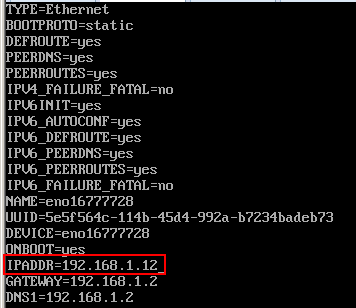
修改主机名:
[root@node1 ~]# vi /etc/sysconfig/network

[root@node1 ~]# vi /etc/hostname
![]()
5 SSH 免密码登录
RSA加密算法是一种典型的非对称加密算法
RSA算法可以用于数据加密(公钥加密,私钥解密)和数字签名或认证(私钥加密,公钥解密)
5.1 一般的ssh原理(需要密码)
客户端向服务器端发出连接请求
服务器端向客户端发出自己的公钥
客户端使用服务器端的公钥加密通讯登录密码然后发给服务器端
如果通讯过程被截获,由于窃听者即使获知公钥和经过公钥加密的内容,但不拥有私钥依然无法解密(RSA算法)
服务器端接收到密文后,用私钥解密,获知通讯密码
5.2 免密码原理
先在客户端创建一对密匙,并把公用密匙放在需要访问的服务器上
客户端向服务器发出请求,请求用你的密匙进行安全验证
服务器收到请求之后, 先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致, 服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端
客户端收到“质询”之后就可以用自己的私人密匙解密再把它发送给服务器
服务器比较发来的“质询”和原先的是否一致,如果一致则进行授权,完成建立会话的操作
5.3 SSH免密码
先删除以前生成的:
rm -rf /root/.ssh
生成密钥:
[root@node1 ~]# ssh-keygen -t rsa
[root@node2 ~]# ssh-keygen -t rsa
[root@node3 ~]# ssh-keygen -t rsa
[root@node4 ~]# ssh-keygen -t rsa
命令“ssh-keygen -t rsa”表示使用 rsa 加密方式生成密钥, 回车后,会提示三次输入信息,我们直接回车即可。
查看生成的密钥:

其中id_rsa.pub为公钥,id_rsa为私钥
服务器之间公钥拷贝:
ssh-copy-id -i /root/.ssh/id_rsa.pub <主机名>
表示将本机的公钥拷贝到hadoop-slave1主机上去,并自动追加到authorized_keys文件中去,如果不存在则会自动创建一个。如果是自己远程自己时,主机就填自己
[root@node1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node1
[root@node1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node2
[root@node1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node3
[root@node1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node4
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node1
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node2
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node3
[root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node4
[root@node3 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node1
[root@node3 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node2
[root@node3 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node3
[root@node3 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node4
[root@node4 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node1
[root@node4 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node2
[root@node4 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node3
[root@node4 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub node4
注:如果发现三台虚拟机上生成的公钥都是一个时,请先删除/etc/udev/rules.d/70-persistent-net.rules 文件,再删除 /root/.ssh文件夹后,重新生成
6 HA+Federation服务器规划
|
|
|
node1 |
node2 |
node3 |
node4 |
|
NameNode |
Hadoop |
Y(属于cluster1 |
Y集群1) |
Y(属于cluster2 |
Y集群2) |
|
DateNode |
|
Y |
Y |
Y |
|
|
NodeManager |
|
Y |
Y |
Y |
|
|
JournalNodes |
Y |
Y |
Y |
|
|
|
zkfc(DFSZKFailoverController) |
Y(有namenode的地方 |
Y就有zkfc) |
Y |
Y |
|
|
ResourceManager |
Y |
Y |
|
|
|
|
ZooKeeper(QuorumPeerMain) |
Zookeeper |
Y |
Y |
Y |
|
|
MySQL |
HIVE |
|
|
|
Y |
|
metastore(RunJar) |
|
|
Y |
|
|
|
HIVE(RunJar) |
Y |
|
|
|
|
|
Scala |
Spark |
Y |
Y |
Y |
Y |
|
Spark-master |
Y |
|
|
|
|
|
Spark-worker |
|
Y |
Y |
Y |
不同的NameNode通过同一ClusterID来共用同一套DataNode:
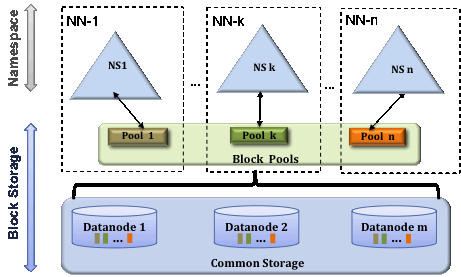
NS-n单元:
7 zookeeper
[root@node1 ~]# wget -O /root/zookeeper-3.4.9.tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
[root@node1 ~]# tar -zxvf /root/zookeeper-3.4.9.tar.gz -C /root
[root@node1 conf]# cp /root/zookeeper-3.4.9/conf/zoo_sample.cfg /root/zookeeper-3.4.9/conf/zoo.cfg
[root@node1 conf]# vi /root/zookeeper-3.4.9/conf/zoo.cfg


[root@node1 conf]# mkdir /root/zookeeper-3.4.9/zkData
[root@node1 conf]# touch /root/zookeeper-3.4.9/zkData/myid
[root@node1 conf]# echo 1 > /root/zookeeper-3.4.9/zkData/myid
[root@node1 conf]# scp -r /root/zookeeper-3.4.9 node2:/root
[root@node1 conf]# scp -r /root/zookeeper-3.4.9 node3:/root
[root@node2 conf]# echo 2 > /root/zookeeper-3.4.9/zkData/myid
[root@node3 conf]# echo 3 > /root/zookeeper-3.4.9/zkData/myid
7.1 超级权限
[root@node1 ~]# vi /root/zookeeper-3.4.9/bin/zkServer.sh
在下面启动Java的地方加上启动参数"-Dzookeeper.DigestAuthenticationProvider.superDigest=super:Q9YtF+3h9Ko5UNT8apBWr8hovH4=",super后面是密码(AAAaaa111):

[root@node1 ~]# /root/zookeeper-3.4.9/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 11] addauth digest super:AAAaaa111
现在就可以任意删除节点数据了:
[zk: localhost:2181(CONNECTED) 15] rmr /rmstore/ZKRMStateRoot
7.2 问题
zookeeper无法启动"Unable to load database on disk"
[root@node3 ~]# more zookeeper.out
2017-01-24 11:31:31,827 [myid:3] - ERROR [main:QuorumPeer@557] - Unable to load database on disk
java.io.IOException: The accepted epoch, d is less than the current epoch, 17
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:554)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
[root@node3 ~]# more /root/zookeeper-3.4.9/conf/zoo.cfg | grep dataDir
dataDir=/root/zookeeper-3.4.9/zkData
[root@node3 ~]# ls /root/zookeeper-3.4.9/zkData
myid version-2 zookeeper_server.pid
清空version-2下的所有文件:
[root@node3 ~]# rm -f /root/zookeeper-3.4.9/zkData/version-2/*.*
[root@node3 ~]# rm -rf /root/zookeeper-3.4.9/zkData/version-2/acceptedEpoch
[root@node3 ~]# rm -rf /root/zookeeper-3.4.9/zkData/version-2/currentEpoch
8 Hadoop
[root@node1 ~]# wget -O /root/hadoop-2.7.2.tar.gz http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
[root@node1 ~]# tar -zxvf /root/hadoop-2.7.2.tar.gz -C /root
8.1 hadoop-env.sh
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/hadoop-env.sh

下面这个存放PID进程号的位置一定要修改,否则可能会出现:XXX running as process 1609. Stop it first.

8.2 hdfs-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>
The default block size for new files, in bytes.
You can use the following suffix (case insensitive):
k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.),
Or provide complete size in bytes (such as 134217728 for 128 MB).
注:1.X及以前版本默认是64M,而且配置项名为dfs.block.size
</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>注:如果还有权限问题,请执行下“/root/hadoop-2.7.2/bin/hdfs dfs -chmod -R 777 /”命令</description>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster1,cluster2</value>
<description>使用federation时,使用了2个HDFS集群。这里抽象出两个NameService实际上就是给这2个HDFS集群起了个别名。名字可以随便起,相互不重复即可。多个集群时使用逗号分开。注:这里的命名只是个逻辑空间的概念,不是集群1、集群2两集群,应该是 cluster1+cluster2 才组成一个集群,cluster1、cluster2只是集群的一部分,从逻辑上将整个集群分成了两部分(当然还要以加一个高可用NameNode进来,组成第三部分),cluster1、cluster2是否属于同一集群,则是是clusterID决定的,clusterID这个值是在格式化NameNode时指定的,请参照namenode格式化和启动</description>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
<description>集群1里面NameNode的逻辑名,注:只是随便命的逻辑名,这里不是真实的NameNode主机名,后面配置才指定到主机</description>
</property>
<property>
<name>dfs.ha.namenodes.cluster2</name>
<value>nn3,nn4</value>
<description>集群2里的NameNode逻辑名</description>
</property>
<!-- 下面配置实现逻辑名与物理主机绑定-->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>node1:8020</value>
<description>8020为HDFS 客户端接入地址(包括命令行与程序),有的使用9000</description>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.nn3</name>
<value>node3:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.nn4</name>
<value>node4:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>node1:50070</value>
<description> namenode web的接入地址</description>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster2.nn3</name>
<value>node3:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster3.nn4</name>
<value>node4:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/cluster1</value>
<description>指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息。
node1\node2主机中使用这个配置</description>
</property>
<!--
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/cluster2</value>
<description>指定cluster2的两个NameNode共享edits文件目录时,使用的JournalNode集群信息。
node3\node4主机中使用这个配置</description>
</property>
-->
<property>
<name>dfs.ha.automatic-failover.enabled.cluster1</name>
<value>true</value>
<description>指定cluster1是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.cluster2</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>指定cluster1出故障时,哪个Java类负责执行故障切换</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop-2.7.2/tmp/journal</value>
<description>指定JournalNode自身存储数据的磁盘路径</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>NameNode使用SSH进行主备切换</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>如果使用ssh进行故障切换,使用ssh通信时用的密钥存储的位置</description>
</property>
</configuration>
8.3 core-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1:8020</value>
<description>在使用客户端(或程序)时,如果不指定具体的接入地址?该值来自于hdfs-site.xml中的配置。注:所有主机上配置都一样。</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.7.2/tmp</value>
<description>这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
<description>这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点</description>
</property>
<!-- 下面的配置可解决NameNode连接JournalNode超时异常问题-->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
</description>
</property>
</configuration>
8.4 slaves
指定DataNode所在主机:
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/slaves
8.5 yarn-env.sh
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-env.sh

8.6 mapred-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce运行在Yarn框架下</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如node2:10020、node3:10020、node4:10020,,拷贝过去后请做相应修改</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如node2:19888、node3:19888、node4:19888,拷贝过去后请做相应修改</description>
</property>
</configuration>
8.7 yarn-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>RM的数据默认存放在ZK上的/rmstore中,可通过yarn.resourcemanager.zk-state-store.parent-path 设定</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志收集,这样会将每台执行任务的机上产生的本地日志文件集中拷贝到HDFS的某个地方,这样就可以在任何一台集群中的机器上集中查看作业日志了</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如http://node2:19888/jobhistory/logs、http://node3:19888/jobhistory/logs、http://node4:19888/jobhistory/logs,拷贝过去后请做相应修改</description>
</property>
</configuration>
8.8 复制与修改
[root@node1 ~]# scp -r /root/hadoop-2.7.2/ node2:/root
[root@node1 ~]# scp -r /root/hadoop-2.7.2/ node3:/root
[root@node1 ~]# scp -r /root/hadoop-2.7.2/ node4:/root
[root@node3 ~]# vi /root/hadoop-2.7.2/etc/hadoop/hdfs-site.xml

[root@node3 ~]# scp /root/hadoop-2.7.2/etc/hadoop/hdfs-site.xml node4:/root/hadoop-2.7.2/etc/hadoop
[root@node2 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[root@node3 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[root@node4 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[root@node2 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
[root@node3 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
[root@node4 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
8.9 启动ZK
[root@node1 bin]# /root/zookeeper-3.4.9/bin/zkServer.sh start
[root@node2 bin]# /root/zookeeper-3.4.9/bin/zkServer.sh start
[root@node3 bin]# /root/zookeeper-3.4.9/bin/zkServer.sh start
[root@node1 bin]# jps
1622 QuorumPeerMain
查看状态:
[root@node1 ~]# /root/zookeeper-3.4.9/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
[root@node2 ~]# /root/zookeeper-3.4.9/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
查看数据节点:
[root@node1 hadoop-2.7.2]# /root/zookeeper-3.4.9/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
8.10格式化zkfc
在每个集群上的任意一节点上进行操作,目的是在Zookeeper集群上建立HA的相应Znode节点数据
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs zkfc -formatZK
[root@node3 ~]# /root/hadoop-2.7.2/bin/hdfs zkfc -formatZK
格式化后,会在ZK上创建hadoop-ha名称的Znode数据节点:
[root@node1 ~]# /root/zookeeper-3.4.9/bin/zkCli.sh

8.11启动journalnode
[root@node1 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start journalnode
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start journalnode
[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start journalnode
[root@node1 ~]# jps
1810 JournalNode
8.12namenode格式化和启动
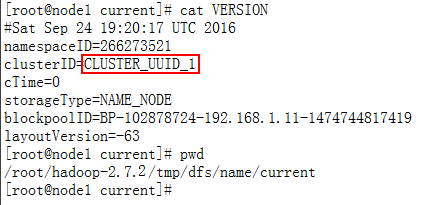
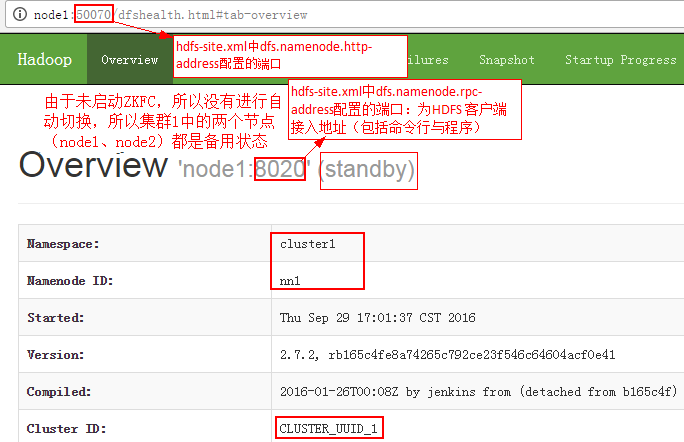
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs namenode -format -clusterId CLUSTER_UUID_1
[root@node1 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode
[root@node1 ~]# jps
1613 NameNode
同一集群中的所有集群ID必须相同(包括NameNode、DataNode等):
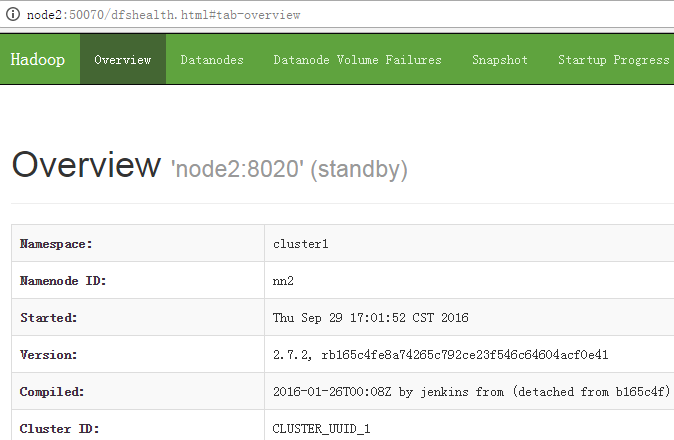
[root@node2 ~]# /root/hadoop-2.7.2/bin/hdfs namenode -bootstrapStandby
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode
[root@node3 ~]# /root/hadoop-2.7.2/bin/hdfs namenode -format -clusterId CLUSTER_UUID_1
[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode
[root@node4 ~]# /root/hadoop-2.7.2/bin/hdfs namenode -bootstrapStandby
[root@node4 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode

8.13启动zkfc
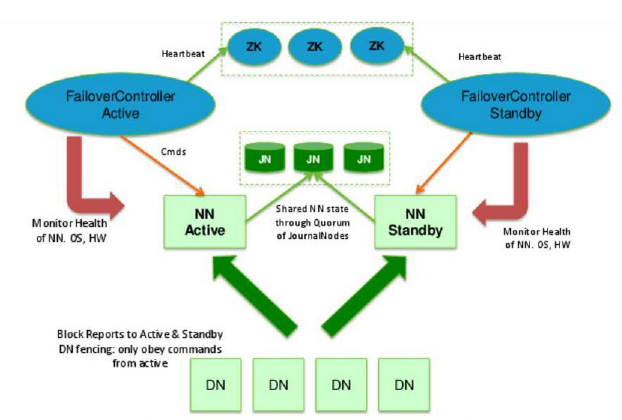
ZKFC(zookeeper Failover Controller)是用来监控NameNode状态的,协助实现主备NameNode切换的,在所有NameNode上执行
[root@node1 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc
[root@node1 ~]# jps
5280 DFSZKFailoverController
自动切换成功:
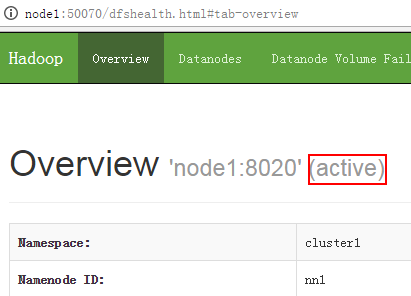
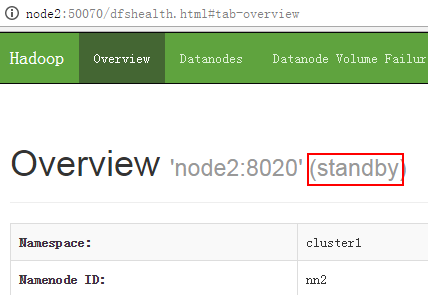
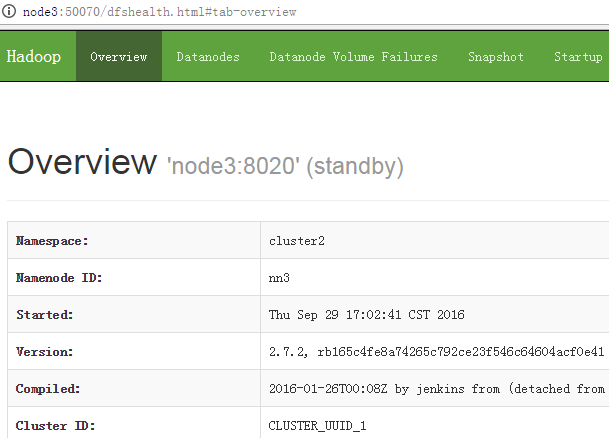
[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc
[root@node4 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc
8.14启动datanode
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start datanode
[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start datanode
[root@node4 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.sh start datanode
8.15HDFS验证
上传到指定的集群2中:
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2.tar.gz hdfs://cluster2/
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs dfs -put /root/test_upload.tar hdfs://cluster1:8020/
上传时如果未明确指定路径,则会默认使用core-site.xml配置文本中的fs.defaultFS配置项:
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2.tar.gz /
也可以具体到某台主机(但要是处于激活状态):
/root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2.tar hdfs://node3:8020/
/root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2.tar hdfs://node3/
8.16HA验证
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster1 -getServiceState nn1
active
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster1 -getServiceState nn2
standby
[root@node1 ~]# jps
2448 NameNode
3041 DFSZKFailoverController
3553 Jps
2647 JournalNode
2954 QuorumPeerMain
[root@node1 ~]# kill 2448
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster1 -getServiceState nn2
active
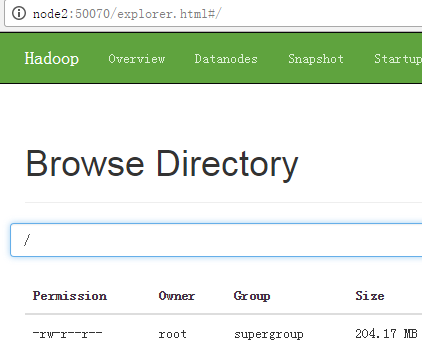
8.16.1 手动切换
/root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster1 -failover nn2 nn1
/root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster2 -failover nn4 nn3
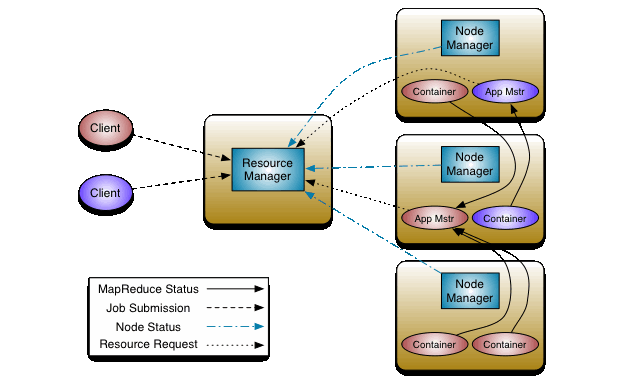
8.17启动yarn
[root@node1 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.sh start resourcemanager
[root@node2 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.sh start resourcemanager
[root@node2 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.sh start nodemanager
[root@node3 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.sh start nodemanager
[root@node4 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.sh start nodemanager
http://node1:8088/cluster/cluster
注:输入地址为http://XXXXX/cluster/cluster形式,否则如果是备用的则会自动跳转到激活主机上面去
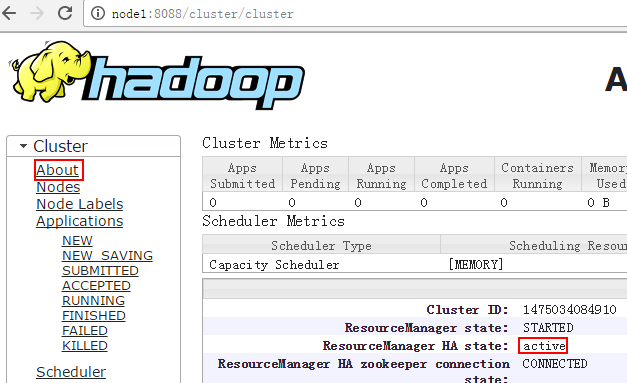
http://node2:8088/cluster/cluster
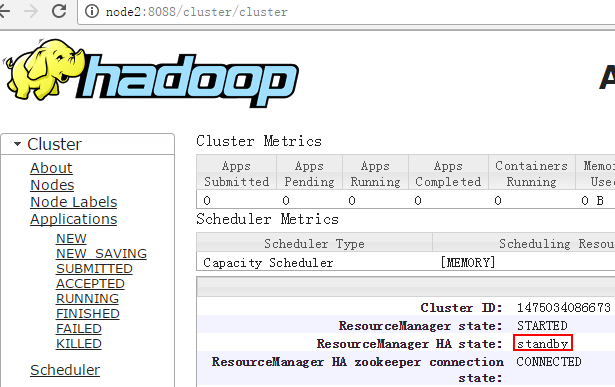
查看状态命令:
[root@node4 logs]# /root/hadoop-2.7.2/bin/yarn rmadmin -getServiceState rm2
8.18MapReduce测试
[root@node4 ~]# /root/hadoop-2.7.2/bin/hdfs dfs -mkdir hdfs://cluster1/hadoop
[root@node4 ~]# /root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2/etc/hadoop/*xml* hdfs://cluster1/hadoop
[root@node4 ~]# /root/hadoop-2.7.2/bin/hadoop jar /root/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount hdfs://cluster1:8020/hadoop/h* hdfs://cluster1:8020/hadoop/m* hdfs://cluster1/wordcountOutput
注:MapReduce的输出要与其输入在同一集群。虽然可以放在另一集群时也要执行成功,但通过Web查看输出结果文件时,会找不到
8.19脚本
以下脚本放在node1上运行
8.19.1 启动与停用脚本
自动交互
在通过脚本进行RM手动切换时使用
[root@node1 ~]# yum install expect
[root@node1 ~]# vi /root/starthadoop.sh
#rm -rf /root/hadoop-2.7.2/logs/*.*
#ssh root@node2 'export BASH_ENV=/etc/profile;rm -rf /root/hadoop-2.7.2/logs/*.*'
#ssh root@node3 'export BASH_ENV=/etc/profile;rm -rf /root/hadoop-2.7.2/logs/*.*'
#ssh root@node4 'export BASH_ENV=/etc/profile;rm -rf /root/hadoop-2.7.2/logs/*.*'
/root/zookeeper-3.4.9/bin/zkServer.sh start
ssh root@node2 'export BASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh start'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh start'
/root/hadoop-2.7.2/sbin/start-all.sh
ssh root@node2 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/yarn-daemon.sh start resourcemanager'
/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc
ssh root@node2 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc'
ssh root@node4 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc'
#ret=`/root/hadoop-2.7.2/bin/hdfs dfsadmin -safemode get | grep ON | head -1`
#while [ -n "$ret" ]
#do
#echo '等待离开安全模式'
#sleep 1s
#ret=`/root/hadoop-2.7.2/bin/hdfs dfsadmin -safemode get | grep ON | head -1`
#done
/root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster1 -failover nn2 nn1
/root/hadoop-2.7.2/bin/hdfs haadmin -ns cluster2 -failover nn4 nn3
echo 'Y' | ssh root@node1 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/bin/yarn rmadmin -transitionToActive --forcemanual rm1'
/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver
ssh root@node2 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver'
ssh root@node4 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver'
#此命令行启动Spark,只安装Hadoop时去掉
/root/spark-2.1.0-bin-hadoop2.7/sbin/start-all.sh
echo '--------------node1---------------'
jps | grep -v Jps | sort -k 2 -t ' '
echo '--------------node2---------------'
ssh root@node2 "export PATH=/usr/bin:$PATH;jps | grep -v Jps | sort -k 2 -t ' '"
echo '--------------node3---------------'
ssh root@node3 "export PATH=/usr/bin:$PATH;jps | grep -v Jps | sort -k 2 -t ' '"
echo '--------------node4---------------'
ssh root@node4 "export PATH=/usr/bin:$PATH;jps | grep -v Jps | sort -k 2 -t ' '"
#下面两行命令用来启动Hive,没有安装时请去掉
ssh root@node4 'export BASH_ENV=/etc/profile;service mysql start'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/hive-1.2.1/bin/hive --service metastore&'
[root@node1 ~]# vi /root/stophadoop.sh
#此命令行用来停止Spark,未安装时去掉
/root/spark-2.1.0-bin-hadoop2.7/sbin/stop-all.sh
#下面两行用来停止HIVE,未安装时去掉
ssh root@node4 'export BASH_ENV=/etc/profile;service mysql stop'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/jdk1.8.0_92/bin/jps | grep RunJar | head -1 |cut -f1 -d " "| xargs kill'
ssh root@node2 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/yarn-daemon.sh stop resourcemanager'
/root/hadoop-2.7.2/sbin/stop-all.sh
/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc
ssh root@node2 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc'
ssh root@node4 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc'
/root/zookeeper-3.4.9/bin/zkServer.sh stop
ssh root@node2 'export BASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh stop'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh stop'
/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver
ssh root@node2 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver'
ssh root@node3 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver'
ssh root@node4 'export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver'
[root@node1 ~]# chmod 777 starthadoop.sh stophadoop.sh
8.19.2 重启、关机
[root@node1 ~]# vi /root/reboot.sh
ssh root@node2 "export PATH=/usr/bin:$PATH;reboot"
ssh root@node3 "export PATH=/usr/bin:$PATH;reboot"
ssh root@node4 "export PATH=/usr/bin:$PATH;reboot"
reboot
[root@node1 ~]# vi /root/shutdown.sh
ssh root@node2 "export PATH=/usr/bin:$PATH;shutdown -h now"
ssh root@node3 "export PATH=/usr/bin:$PATH;shutdown -h now"
ssh root@node4 "export PATH=/usr/bin:$PATH;shutdown -h now"
shutdown -h now
[root@node1 ~]# chmod 777 /root/shutdown.sh /root/reboot.sh
8.20Eclipse插件
8.20.1 插件安装
1、 将hadoop-2.7.2.tar.gz(前面自己编译的CentOS版本)解压到D:\hadoop下,并将winutil.exe.hadoop.dll等文件到hadoop安装目录bin文件夹下,再将hadoop.dll放到C:\Windows及C:\Windows\System32下。
2、 添加HADOOP_HOME环境变量,值为D:\hadoop\hadoop-2.7.2,并将%HADOOP_HOME%\bin添加到Path环境变量中
3、 双击winutils.exe,如果出现“缺失MSVCR120.dll”的提示,则安装VC++2013相关组件
4、 将hadoop-eclipse-plugin-2.7.2.jar(该插件包也是要在Windows上进行编译,非常麻烦,也找现成的吧!)插件包拷贝到Eclipse plugins目录下
5、 运行Eclipse,进行配置:

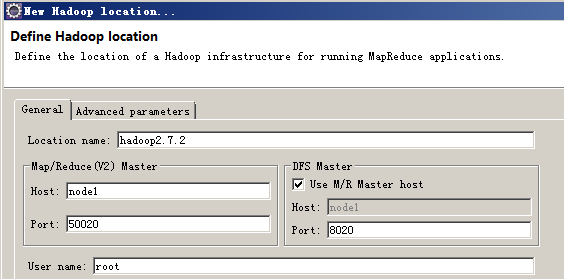
- Map/Reduce(V2) Master :这个端口不用管,不影响任务远程提交与执行。如果配置正确,下面这个就可以在Eclips直接监视任务执行情况了(这个捣鼓了很久,还是没出来,在hadoop1.2.1倒是搞出来过):

- DFS Master: Name Node的IP和端口,hdfs-site.xml中dfs.namenode.rpc-address配置端口,这个配置决定了左边树是否可以连上Hadoop的dfs:
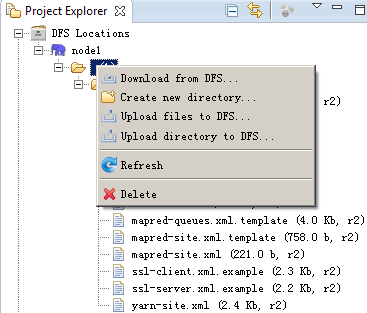
8.20.2 WordCount工程

8.20.2.1 WordCount.java
package jzj;
import java.io.IOException;
import java.net.URI;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
publicclass WordCount {
publicstaticclass TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
privatefinalstatic IntWritable one = new IntWritable(1);
private Text word = new Text();
private Logger log = Logger.getLogger(TokenizerMapper.class);
publicvoid map(Object key, Text value, Context context) throws IOException, InterruptedException {
log.debug("[Thread=" + Thread.currentThread().hashCode() + "] map任务:log4j输出:wordcount,key=" + key + ",value=" + value);
System.out.println("[Thread=" + Thread.currentThread().hashCode() + "] map任务:System.out输出:wordcount,key=" + key + ",value="
+ value);
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
publicstaticclass IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private Logger log = Logger.getLogger(IntSumReducer.class);
publicvoid reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
log.debug("[Thread=" + Thread.currentThread().hashCode() + "] reduce任务:log4j输出:wordcount,key=" + key + ",count=" + sum);
System.out.println("[Thread=" + Thread.currentThread().hashCode() + "] reduce任务:System.out输出:wordcount,key=" + key + ",count="
+ sum);
}
}
publicstaticvoid main(String[] args) throws Exception {
Logger log = Logger.getLogger(WordCount.class);
log.debug("JOB Main方法:log4j输出:wordcount");
System.out.println("JOB Main方法:System.out输出:wordcount");
Configuration conf = new Configuration();
// 注:xxx.jar任务包中需要一个空的yarn-default.xml配置文件,否则任务远程提交后会一直等待,Why?
conf.set("mapreduce.framework.name", "yarn");// 指定使用yarn框架
conf.set("yarn.resourcemanager.address", "node1:8032"); // 提交任务到哪台机器上
// 需要加上,否则抛异常:java.io.IOException: The ownership on the staging
// directory /tmp/hadoop-yarn/staging/15040078/.staging
// is not as expected. It is owned by . The directory must be owned by
// the submitter 15040078 or by 15040078
conf.set("fs.defaultFS", "hdfs://node1:8020");// 指定namenode
// 加上该配置,否则抛异常:Stack trace: ExitCodeException exitCode=1: /bin/bash: 第 0
// 行:fg: 无任务控制
conf.set("mapreduce.app-submission.cross-platform", "true");
// 此处Key值mapred.jar不要修改,值为本项目导出的Jar包,如果不设置,则报找不到类
conf.set("mapred.jar", "wordcount.jar");
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
// 如果这里设置了Combiner,则Map端与会有reduce日志,原因设置了Combiner后,Map端做完Map后,会继续运行reduce任务,所以在Map端也会看到reduce任务日志就不奇怪了
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(4);
FileInputFormat.addInputPath(job, new Path("hdfs://node1/hadoop/core-site.xml"));
FileInputFormat.addInputPath(job, new Path("hdfs://node1/hadoop/m*"));
FileSystem fs = FileSystem.get(URI.create("hdfs://node1"), conf);
fs.delete(new Path("/wordcountOutput"), true);
FileOutputFormat.setOutputPath(job, new Path("hdfs://node1/wordcountOutput"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
System.out.println(job.getStatus().getJobID());
}
}
8.20.2.2 yarn-default.xml
注:工程中的yarn-default.xml为空文件,但经测式一定需要
8.20.2.3 build.xml
<projectdefault="jar"name="Acid">
<propertyname="lib.dir"value="D:/hadoop/hadoop-2.7.2/share/hadoop"/>
<propertyname="src.dir"value="../src"/>
<propertyname="classes.dir"value="../bin"/>
<propertyname="output.dir"value=".."/>
<propertyname="jarname"value="wordcount.jar"/>
<propertyname="mainclass"value="jzj.WordCount"/>
<!-- 第三方jar包的路径 -->
<pathid="lib-classpath">
<filesetdir="${lib.dir}">
<includename="**/*.jar"/>
</fileset>
</path>
<!-- 1. 初始化工作,如创建目录等 -->
<targetname="init">
<mkdirdir="${classes.dir}"/>
<mkdirdir="${output.dir}"/>
<deletefile="${output.dir}/wordcount.jar"/>
<deleteverbose="true"includeemptydirs="true">
<filesetdir="${classes.dir}">
<includename="**/*"/>
</fileset>
</delete>
</target>
<!-- 2. 编译 -->
<targetname="compile"depends="init">
<javacsrcdir="${src.dir}"destdir="${classes.dir}"includeantruntime="on">
<compilerargline="-encoding GBK"/>
<classpathrefid="lib-classpath"/>
</javac>
</target>
<!-- 3. 打包jar文件 -->
<targetname="jar"depends="compile">
<copytodir="${classes.dir}">
<filesetdir="${src.dir}">
<includename="**"/>
<excludename="build.xml"/>
<!--注:不能排除掉log4j.properties文件,该文件也要一起打包,否则运行时不会显示日志
该日志配置文件仅作用于JOB,即会在作业提交的客户端上产生日志,而TASK(MapReduce任务)
则是由/root/hadoop-2.7.2/etc/hadoop/log4j.properties配置文件来决定-->
<!--exclude name="log4j.properties" / -->
</fileset>
</copy>
<!-- jar文件的输出路径 -->
<jardestfile="${output.dir}/${jarname}"basedir="${classes.dir}">
<manifest>
<attributename="Main-class"value="${mainclass}"/>
</manifest>
</jar>
</target>
</project>
8.20.2.4 log4j.properties
log4j.rootLogger=info,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p-%m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p%t%c-%m%n
log4j.logger.jzj =DEBUG
8.20.3 打包执行
打开工程中的build.xml构件文件,按 SHIFT+ALT+X,Q,即可在工程下打成作业jar包:
![]() 包结构如下:
包结构如下:
然后打开工程中的WordCount.java源码文件,点击:
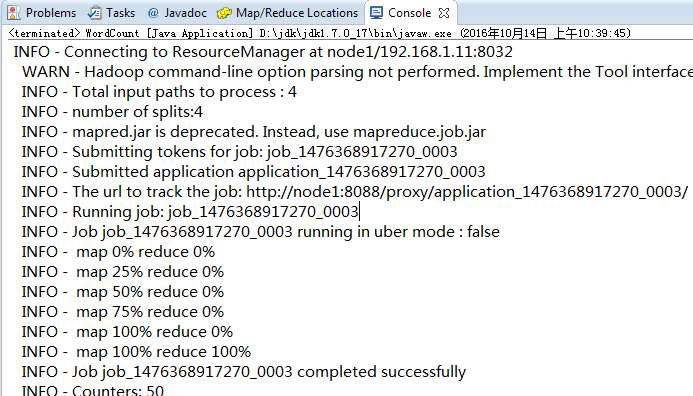
8.20.4 权限访问
运行时如果报以下异常:
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=15040078, access=EXECUTE, inode="/tmp/hadoop-yarn/staging/15040078/.staging/job_1484039063795_0001":root:supergroup:drwxrwx---
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:319)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:259)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:205)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:190)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1720)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1704)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkOwner(FSDirectory.java:1673)
at org.apache.hadoop.hdfs.server.namenode.FSDirAttrOp.setPermission(FSDirAttrOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermission(FSNamesystem.java:1653)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setPermission(NameNodeRpcServer.java:695)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setPermission(ClientNamenodeProtocolServerSideTranslatorPB.java:453)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043)
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfs dfs -chmod -R 777 /
8.21杀任务
如果发现任务提交后,停止不前,则可以杀掉该任务:
[root@node1 ~]# /root/hadoop-2.7.2/bin/hadoop job -list
[root@node1 ~]# /root/hadoop-2.7.2/bin/hadoop job -kill job_1475762778825_0008
8.22日志
8.22.1 Hadoop系统服务日志
如NameNode、secondarynamenode、historyserver、ResourceManage、DataNode、nodemanager等系统自带的服务输出来的日志默认是存放 在${HADOOP_HOME}/logs目录下,也可以通过Web页面这样查看:
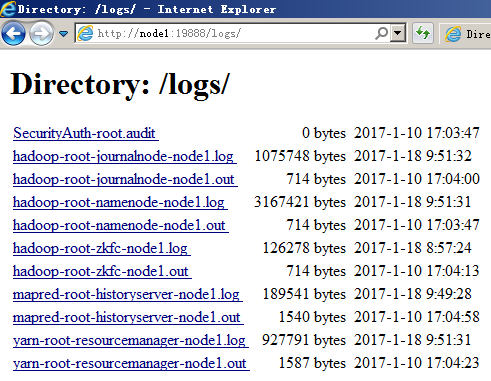
这些日志实际上对应每台主机上的本地日志文件,进入相应主机可以看到原始文件:
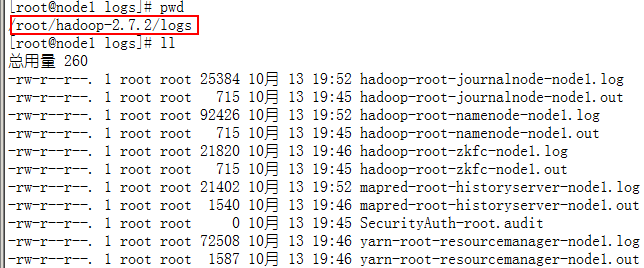
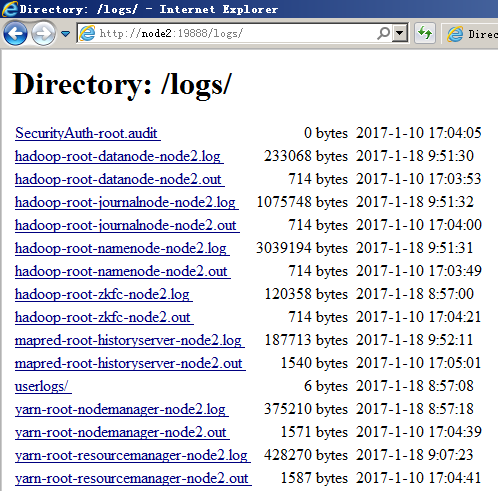
当日志到达一定的大小将会被切割出一个新的文件,后面的数字越大,代表日志越旧。在默认情况 下,只保存前20个日志文件。系统日志位置及大小都是可以在 在${HADOOP_HOME}/etc/hadoop/log4j.properties文件中配置的,配置文件中的环境变量由${HADOOP_HOME}/etc/hadoop/目录下相关配置文件来设定
*.out文件,标准输出会重定向到这里
也可以这样点进来:
8.22.2 Mapreduce日志
Mapreduce日志可以分为历史作业日志和Container日志。
(1)、历史作业的记录里面包含了一个作业用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息;这些信息对分析作业是很有帮助的,我们可以通过这些历史作业记录得到每天有多少个作业运行成功、有多少个作业运行失败、每个队列作业运行了多少个作业等很有用的信息。这些历史作业的信息是通过下面的信息配置的:

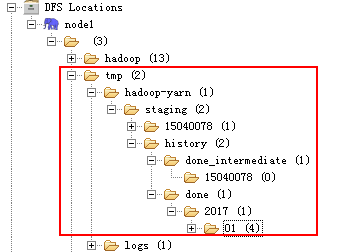
注:这一类日志文件是放在HDFS上面的
(2)、Container日志:包含ApplicationMaster日志和普通Task日志等信息。
YARN提供了两种存放容器(container)日志的方式:
1) 本地:如果日志聚合服务被开启的话(通过yarn.log-aggregation-enable来配置),容器日志将会被拷贝到HDFS中并且删除本机上的日志文件,位置由yarn-site.xml中的yarn.nodemanager.remote-app-log-dir来配置,默认在hdfs://tmp/logs目录中:
<property>
<description>Where to aggregate logs to.</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
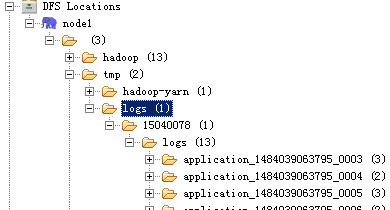
/tmp/logs下的子目录默认配置:
<property>
<description>The remote log dir will be created at {yarn.nodemanager.remote-app-log-dir}/${user}/{thisParam}
</description>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
默认情况下,这些日志信息是存放在${HADOOP_HOME}/logs/userlogs目录下:
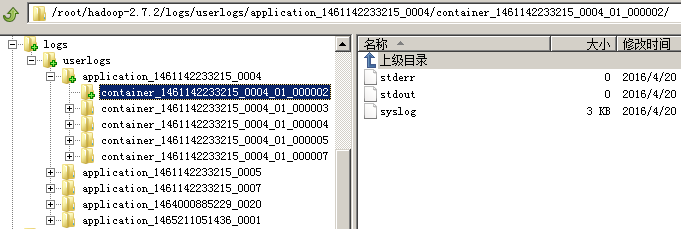
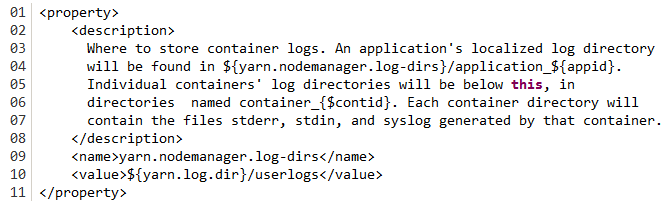
我们可以通过下面的配置进行修改:
2) HDFS:当日志聚合服务关闭时(yarn.log-aggregation-enable为false),日志被保留在任务执行的机器本地的$HADOOP_HOME/logs/userlogs,作业执行完后不会被移到HDFS系统中
通过http://node1:8088/cluster/apps进去点击即可查看正在运行与已经完成的作业的日志信息:

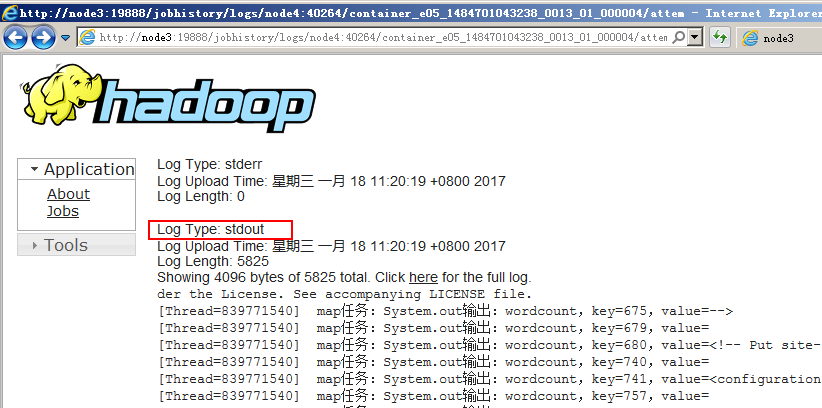
点击相应链接可以查看到每个Map或Reduce任务的日志:

8.22.3 System.out
JOB启动类main方法中的System.out:会在 Job作业提交节点的终端上输出。如果在是Eclipse上远程提交的,会在Eclipse中输出:

如果作业提交到远程服务器上运行,在哪个节点(jobtracker)上启动作业,就在哪个节点终端上显示输出:
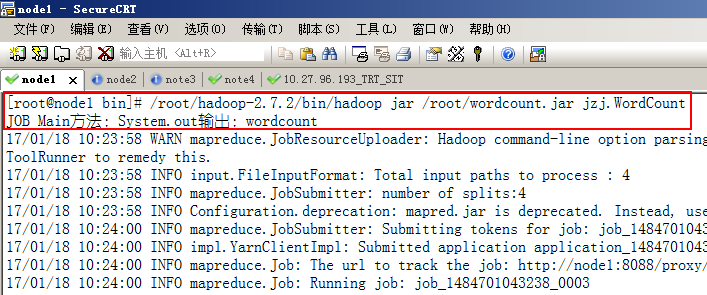
如果是Map或者是reduce类里输出的,则会将日志输出到 ${HADOOP_HOME}/logs/userlogs目录下的文件中(如果日志聚合服务被开启的话,则任务执行完后会移到HDFS中去存储,所以在试验时要在任务运行完之前查看):
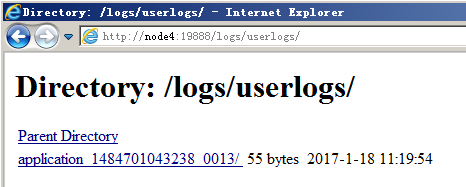

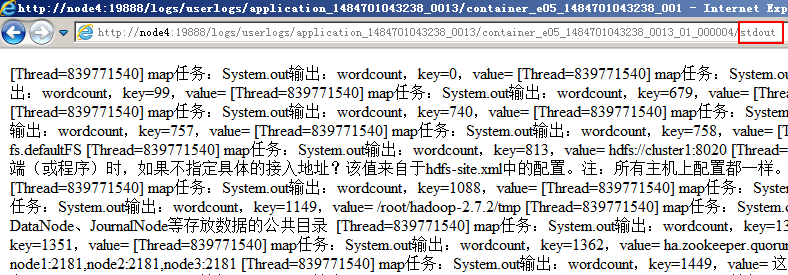
这些日志还可以通过http://node1:8088/cluster/apps页面查看的
8.22.4 log4j
在Eclipse中启动运行:
作业提交代码(即Main方法)中的日志、以及作业运行过程中Eclipse控制台输出,是由作业jar打包中的log4j.properties配置文件来决定:

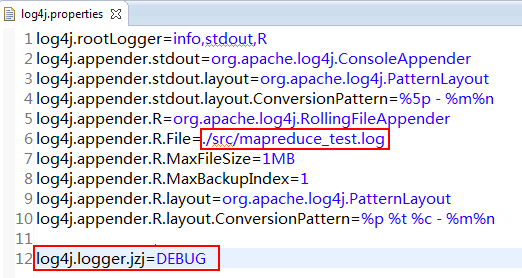
由于在log4j.properties文件中配置了Console标准输出,所以在Eclipse控制台会直接打印出来:
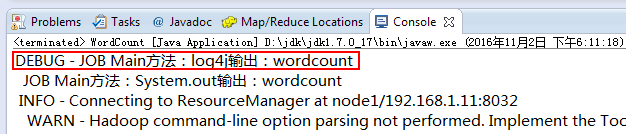
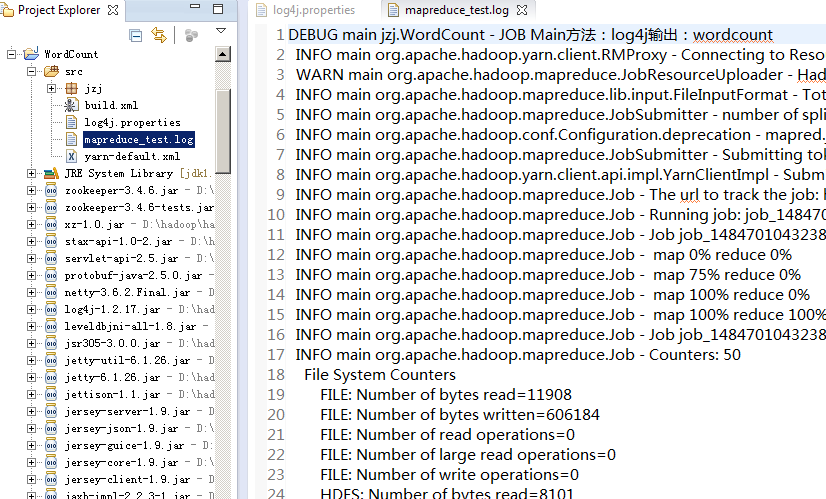
从输出来看,除了Main方法中的日志输出外,还有大量的作业运行过程中产生的日志记录,这些也是log4j输出的,这所有日志记录(Main中的输出、作业系统框架输出)都会记录到mapreduce_test.log文件中去:
提交到服务上运行时:此时的配置文件为/root/hadoop-2.7.2/etc/hadoop/log4j.properties
而MapReduce任务中的日志级别是由mapred-site.xml中配置,下面是默认配置:
<property>
<name>mapreduce.map.log.level</name>
<value>INFO</value>
<description>The logging level for the map task. The allowed levels are:
OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE and ALL.
The setting here could be overridden if "mapreduce.job.log4j-properties-file"
is set.
</description>
</property>
<property>
<name>mapreduce.reduce.log.level</name>
<value>INFO</value>
<description>The logging level for the reduce task. The allowed levels are:
OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE and ALL.
The setting here could be overridden if "mapreduce.job.log4j-properties-file"
is set.
</description>
</property>
Map、Reduce类中的log4j输出日志会直接输入到${HADOOP_HOME}/logs/userlogs目录下的相应文件中(如果日志聚合服务被开启的话,则任务执行完后会移到HDFS中去存储),而不是/root/hadoop-2.7.2/etc/hadoop/log4j.properties中配的日志文件(该配置文件所指定的默认名为hadoop.log,但一直都没找到过!?):
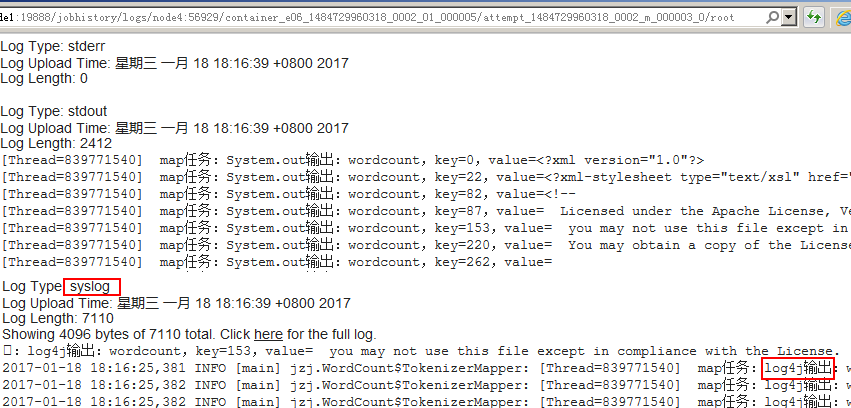
注:如果这里设置了Combiner,则Map端与会有reduce日志,原因设置了Combiner后,Map端做完Map后,会继续运行reduce任务,所以在Map端也会看到reduce任务日志就不奇怪了
9 MySQL
1、下载mysql的repo源
[root@node4 ~]# wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
2、安装mysql-community-release-el7-5.noarch.rpm包
[root@node4 ~]# rpm -ivh mysql-community-release-el7-5.noarch.rpm
安装这个包后,会获得两个mysql的yum repo源:/etc/yum.repos.d/mysql-community.repo,/etc/yum.repos.d/mysql-community-source.repo
3、安装mysql
[root@node4 ~]# yum install mysql-server
4、启动数据库
[root@node4 /root]# service mysql start
5、修改root的密码
[root@node4 /root]# mysqladmin -u root password 'AAAaaa111'
6、配置远程访问,为了安全,默认情况只允许本地登录,限制其他IP远程访问
[root@node4 /root]# mysql -h localhost -u root -p
Enter password: AAAaaa111
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'AAAaaa111' WITH GRANT OPTION;
mysql> flush privileges;
7、查看数据库字符集
mysql> show variables like 'character%';

8、修改字符集
[root@node4 /root]# vi /etc/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
9、大小写敏感配置
不区分表名的大小写;
[root@node4 /root]# vi /etc/my.cnf
[mysqld]
lower_case_table_names = 1
其中 0:区分大小写,1:不区分大小写
10、 重启服务
[root@node4 /root]# service mysql stop
[root@node4 /root]# service mysql start
11、 [root@node4 /root]# mysql -h localhost -u root -p
12、 字符集修改后再次查看
mysql> show variables like 'character%';

13、 创建库
mysql> create database hive;
14、 显示数据库
mysql> show databases;
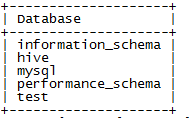
15、 连接数据库
mysql> use hive;
16、 查看库中有哪些表
mysql> show tables;
17、 退出:
mysql> exit;
10 HIVE安装
10.1三种安装模式
基本概念:metastore包括两部分,服务进程和数据的存储。
《hadoop权威指南 第二版》374页这张图:
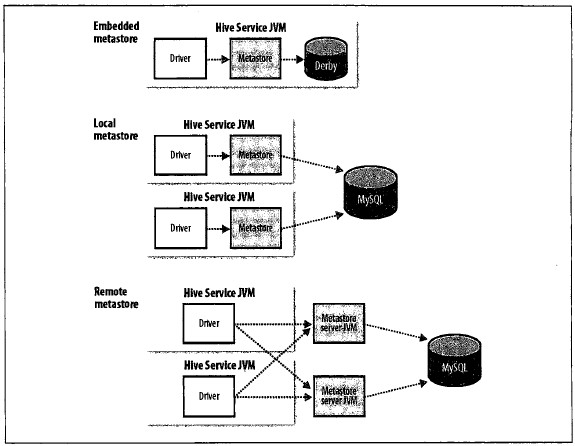
1.上方描述的是内嵌模式,特点是:hive服务和metastore服务运行在同一个进程中,derby服务也运行在该进程中。
该模式无需特殊配置
2.中间是本地模式,特点是:hive服务和metastore服务运行在同一个进程中,mysql是单独的进程,可以在同一台机器上,也可以在远程机器上。
该模式只需将hive-site.xml中的ConnectionURL指向mysql,并配置好驱动名、数据库连接账号即可:

3.下方是远程模式,特点是:hive服务和metastore在不同的进程内,可能是不同的机器。
该模式需要将hive.metastore.local设置为false,并将hive.metastore.uris设置为metastore服务器URI,如有多个metastore服务器,URI之间用逗号分隔。metastore服务器URI的格式为thrift://host:port,Thrift:是hive的通信协议
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083</value>
</property>
把这些理解后,大家就会明白,其实仅连接远程的mysql并不能称之为“远程模式”,是否远程指的是metastore和hive服务是否在同一进程内,换句话说,“远”指的是metastore和hive服务离得“远”。
10.2远程模式安装
在node1上安装hive,在node3上安装metastore服务:
1、 下载地址:http://apache.fayea.com/hive
Hadoop版本为2.7.2,这里下载apache-hive-1.2.1-bin.tar.gz包
[root@node1 ~]# wget http://apache.fayea.com/hive/stable/apache-hive-1.2.1-bin.tar.gz
2、 [root@node1 ~]# tar -zxvf apache-hive-1.2.1-bin.tar.gz
3、 [root@node1 ~]# mv apache-hive-1.2.1-bin hive-1.2.1
4、 [root@node1 ~]# vi /etc/profile
export HIVE_HOME=/root/hive-1.2.1
export PATH=.:$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin
5、 [root@node1 ~]# source /etc/profile
6、 将mysql-connector-java-5.6-bin.jar驱动放在 /root/hive-1.2.1/lib/ 目录下面
7、 [root@node1 ~]# cp /root/hive-1.2.1/conf/hive-env.sh.template /root/hive-1.2.1/conf/hive-env.sh
8、 [root@node1 ~]# vi /root/hive-1.2.1/conf/hive-env.sh
![]()
经过上面这些操作后,应该可以启动默认配置(数据库用的是内嵌数据库derby)的HIVE了(注:运行Hive之前要启动Hadoop):
[root@node1 ~]# hive
Logging initialized using configuration in jar:file:/root/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
9、 将node1上的Hive拷贝到node3上
[root@node1 ~]# scp -r /root/hive-1.2.1 node3:/root
[root@node1 ~]# scp /etc/profile node3:/etc/profile
[root@node3 ~]# source /etc/profile
10、 [root@node1 ~]# vi /root/hive-1.2.1/conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
</configuration>
11、 [root@node3 ~]# vi /root/hive-1.2.1/conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node4:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>AAAaaa111</value>
</property>
</configuration>
12、 启动metastore 服务:
[root@node3 ~]# hive --service metastore&
[1] 2561
Starting Hive Metastore Server
[root@hadoop-slave1 /root]# jps
2561 RunJar
&表示让metastore服务在后台运行
13、 启动Hive Server:
[root@node1 ~]# hive --service hiveserver2 &
[1] 3310
[root@hadoop-master /root]# jps
3310 RunJar
进程号名也是RunJar
注:不要使用 hive --service hiveserver 来启动服务,否则会抛异常:
Exception in thread "main" java.lang.ClassNotFoundException: org.apache.hadoop.hive.service.HiveServer
注:直接使用hive命令启动shell环境时,其实已经顺带启动了hiveserver,所以远程模式下其实只需要单独启动metastore,然后就可以进入shell环境正常使用,所以这一步实际上可以省掉,直接运行hive进入shell环境
14、 启动hive命令行
[root@hadoop-master /root]# hive
Logging initialized using configuration in jar:file:/root/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
注:启运hive时会顺带启动了hiveserver,所以没有必要运行hive --service hiveserver2 & 命令了
15、 验证hive:
[root@hadoop-master /root]# hive
Logging initialized using configuration in jar:file:/root/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> show tables;
OK
Time taken: 1.011 seconds
hive> create table test(id int,name string);
可能会出现以下两种之一的异常:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:For direct MetaStore DB connections, we don't support retries at the client level.)
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:javax.jdo.JDODataStoreException: An exception was thrown while adding/validating class(es) : Specified key was too long; max key length is 767 bytes
com.mysql.jdbc.exceptions.MySQLSyntaxErrorException: Specified key was too long; max key length is 767 bytes
这是由于数据库字符集引起的,进入mysql修改:
[root@node4 /root]# mysql -h localhost -u root -p
mysql> alter database hive character set latin1;
16、 登录mySQL查看meta信息
mysql> use hive;

3)登录hadoop查看
[root@node1 ~]# hadoop-2.7.2/bin/hdfs dfs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - root supergroup 0 2017-01-22 23:45 /user/hive/warehouse/test
11 Scala安装
1、 [root@node1 ~]# wget -O /root/scala-2.12.1.tgz http://downloads.lightbend.com/scala/2.12.1/scala-2.12.1.tgz
2、 [root@node1 ~]# tar -zxvf /root/scala-2.12.1.tgz
3、 [root@node1 ~]# vi /etc/profile
export SCALA_HOME=/root/scala-2.12.1
export PATH=.:$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin
4、 [root@node1 ~]# source /etc/profile
5、 [root@node1 ~]# scala -version
Scala code runner version 2.12.1 -- Copyright 2002-2016, LAMP/EPFL and Lightbend, Inc.
[root@node1 ~]# scala
Welcome to Scala 2.12.1 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_92).
Type in expressions for evaluation. Or try :help.
scala> 9*9;
res0: Int = 81
scala>
6、 [root@node1 ~]# scp -r /root/scala-2.12.1 node2:/root
[root@node1 ~]# scp -r /root/scala-2.12.1 node3:/root
[root@node1 ~]# scp -r /root/scala-2.12.1 node4:/root
[root@node1 ~]# scp /etc/profile node2:/etc
[root@node1 ~]# scp /etc/profile node3:/etc
[root@node1 ~]# scp /etc/profile node4:/etc
[root@node2 ~]# source /etc/profile
[root@node3 ~]# source /etc/profile
[root@node4 ~]# source /etc/profile
12 Spark安装
1、 [root@node1 ~]# wget -O /root/spark-2.1.0-bin-hadoop2.7.tgz http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.7.tgz
2、 [root@node1 ~]# tar -zxvf /root/spark-2.1.0-bin-hadoop2.7.tgz
3、 [root@node1 ~]# vi /etc/profile
export SPARK_HOME=/root/spark-2.1.0-bin-hadoop2.7
export PATH=.:$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
4、 [root@node1 ~]# source /etc/profile
5、 [root@node1 ~]# cp /root/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh.template /root/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh
6、 [root@node1 ~]# vi /root/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh
export SCALA_HOME=/root/scala-2.12.1
export JAVA_HOME=//root/jdk1.8.0_92
export HADOOP_CONF_DIR=/root/hadoop-2.7.2/etc/hadoop
7、 [root@node1 ~]# cp /root/spark-2.1.0-bin-hadoop2.7/conf/slaves.template /root/spark-2.1.0-bin-hadoop2.7/conf/slaves
8、 [root@node1 ~]# vi /root/spark-2.1.0-bin-hadoop2.7/conf/slaves

7、 [root@node1 ~]# scp -r /root/spark-2.1.0-bin-hadoop2.7 node2:/root
[root@node1 ~]# scp -r /root/spark-2.1.0-bin-hadoop2.7 node3:/root
[root@node1 ~]# scp -r /root/spark-2.1.0-bin-hadoop2.7 node4:/root
[root@node1 ~]# scp /etc/profile node2:/etc
[root@node1 ~]# scp /etc/profile node3:/etc
[root@node1 ~]# scp /etc/profile node4:/etc
[root@node2 ~]# source /etc/profile
[root@node3 ~]# source /etc/profile
[root@node4 ~]# source /etc/profile
8、 [root@node1 conf]# /root/spark-2.1.0-bin-hadoop2.7/sbin/stop-all.sh
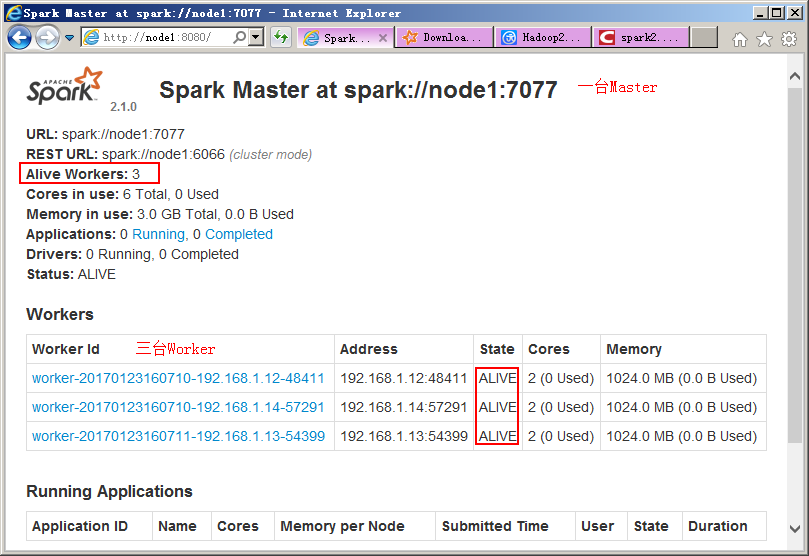
[root@node1 ~]# jps
2569 Master
[root@node2 ~]# jps
2120 Worker
[root@node3 ~]# jps
2121 Worker
[root@node4 ~]# jps
2198 Worker
12.1测试
直接在Spark Shell中进行测试:
[root@node1 conf]# spark-shell
val file=sc.textFile("hdfs://node1/hadoop/core-site.xml")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
使用Spark将Hadoop提供的WordCount示例提交测试:
[root@node1 ~]# spark-submit --master spark://node1:7077 --class org.apache.hadoop.examples.WordCount --name wordcount /root/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar hdfs://node1/hadoop/core-site.xml hdfs://node1/output
不过此种情况还是提交成MapReduce任务,而不是Spark任务,该示例包jar由Java语开发的,并且程序中未使用到Spark包
使用Spark提供的WordCount示例进行测试:
spark-submit --master spark://node1:7077 --class org.apache.spark.examples.JavaWordCount --name wordcount /root/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar hdfs://node1/hadoop/core-site.xml hdfs://node1/output
该示例也是Java语句实现,但程序是通过Spark包实现的,所以产生了Spark任务:
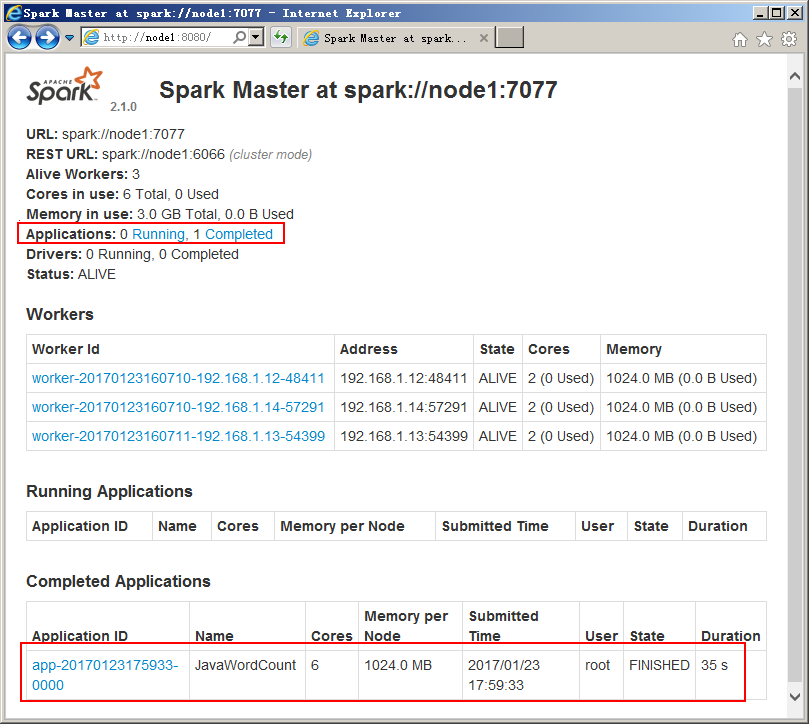
12.2Hive启动问题
Hive在spark2.0.0启动时无法访问../lib/spark-assembly-*.jar: 没有那个文件或目录的解决办法

[root@node1 ~]# vi /root/hive-1.2.1/bin/hive
#sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`
sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`
[root@node1 ~]# scp /root/hive-1.2.1/bin/hive node3:/root/hive-1.2.1/bin
13 清理与压缩
yum 会把下载的软件包和header存储在cache中,而不会自动删除。清除YUM缓存:
[root@node1 ~]# yum clean all
[root@node1 ~]# dd if=/dev/zero of=/0bits bs=20M //将碎片空间填充上0,结束的时候会提示磁盘空间不足,忽略即可
[root@node1 ~]# rm /0bits //删除上面的填充
关闭虚拟机,然后打开cmd ,用cd命令进入到你的vmware安装文件夹,如D:\BOE4 然后执行:
vmware-vdiskmanager -k D:\hadoop\spark\VM\node1\node1.vmdk //注:这个vmdk文件为总文件,而不是子的
14 hadoop2.x常用端口
|
组件 |
节点 |
默认端口 |
配置 |
用途说明 |
|
HDFS |
DataNode |
50010 |
dfs.datanode.address |
datanode服务端口,用于数据传输 |
|
HDFS |
DataNode |
50075 |
dfs.datanode.http.address |
http服务的端口 |
|
HDFS |
DataNode |
50475 |
dfs.datanode.https.address |
https服务的端口 |
|
HDFS |
DataNode |
50020 |
dfs.datanode.ipc.address |
ipc服务的端口 |
|
HDFS |
NameNode |
50070 |
dfs.namenode.http-address |
http服务的端口 |
|
HDFS |
NameNode |
50470 |
dfs.namenode.https-address |
https服务的端口 |
|
HDFS |
NameNode |
8020 |
fs.defaultFS |
接收Client连接的RPC端口,用于获取文件系统metadata信息。 |
|
HDFS |
journalnode |
8485 |
dfs.journalnode.rpc-address |
RPC服务 |
|
HDFS |
journalnode |
8480 |
dfs.journalnode.http-address |
HTTP服务 |
|
HDFS |
ZKFC |
8019 |
dfs.ha.zkfc.port |
ZooKeeper FailoverController,用于NN HA |
|
YARN |
ResourceManager |
8032 |
yarn.resourcemanager.address |
RM的applications manager(ASM)端口 |
|
YARN |
ResourceManager |
8030 |
yarn.resourcemanager.scheduler.address |
scheduler组件的IPC端口 |
|
YARN |
ResourceManager |
8031 |
yarn.resourcemanager.resource-tracker.address |
IPC |
|
YARN |
ResourceManager |
8033 |
yarn.resourcemanager.admin.address |
IPC |
|
YARN |
ResourceManager |
8088 |
yarn.resourcemanager.webapp.address |
http服务端口 |
|
YARN |
NodeManager |
8040 |
yarn.nodemanager.localizer.address |
localizer IPC |
|
YARN |
NodeManager |
8042 |
yarn.nodemanager.webapp.address |
http服务端口 |
|
YARN |
NodeManager |
8041 |
yarn.nodemanager.address |
NM中container manager的端口 |
|
YARN |
JobHistory Server |
10020 |
mapreduce.jobhistory.address |
IPC |
|
YARN |
JobHistory Server |
19888 |
mapreduce.jobhistory.webapp.address |
http服务端口 |
|
HBase |
Master |
60000 |
hbase.master.port |
IPC |
|
HBase |
Master |
60010 |
hbase.master.info.port |
http服务端口 |
|
HBase |
RegionServer |
60020 |
hbase.regionserver.port |
IPC |
|
HBase |
RegionServer |
60030 |
hbase.regionserver.info.port |
http服务端口 |
|
HBase |
HQuorumPeer |
2181 |
hbase.zookeeper.property.clientPort |
HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
|
HBase |
HQuorumPeer |
2888 |
hbase.zookeeper.peerport |
HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
|
HBase |
HQuorumPeer |
3888 |
hbase.zookeeper.leaderport |
HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
|
Hive |
Metastore |
9083 |
/etc/default/hive-metastore中export PORT=<port>来更新默认端口 |
|
|
Hive |
HiveServer |
10000 |
/etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT=<port>来更新默认端口 |
|
|
ZooKeeper |
Server |
2181 |
/etc/zookeeper/conf/zoo.cfg中clientPort=<port> |
对客户端提供服务的端口 |
|
ZooKeeper |
Server |
2888 |
/etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 |
follower用来连接到leader,只在leader上监听该端口。 |
|
ZooKeeper |
Server |
3888 |
/etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 |
用于leader选举的。只在electionAlg是1,2或3(默认)时需要。 |
15 Linux命令
查超出10M的文件:
find . -type f -size +10M -print0 | xargs -0 du -h | sort -nr
将前最大的前20目录列出来,--max-depth表示目录深度,如果去掉,则遍历所有子目录:
du -hm --max-depth=5 / | sort -nr | head -20
find /etc -name '*srm*' #表示在/etc目录下查找文件名中含有srm字符的所有文件
清除YUM缓存
yum 会把下载的软件包和header存储在cache中,而不会自动删除。假如我们觉得他们占用了磁盘空间,能够使用yum clean指令进行清除,更精确 的用法是yum clean headers清除header,yum clean packages清除下载的rpm包,yum clean all一股脑儿端 .
更改所有者
chown -R -v 15040078 /tmp
16 hadoop文件系统命令
[root@node1 ~/hadoop-2.6.0/bin]# ./hdfs dfs -chmod -R 700 /tmp
附件列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号