
无监督语义相似度(一)
预训练+微调在下游任务上确实取得了很好的效果,但是在没有监督数据微调的情况下,使用预训练模型表征文本语义时效果却很差,不如直接使用词向量来表征文本。记得在BERT刚出来的时候,使用BERT做无监督语义相似度的任务时,计算出来的句子之间的余弦相似度值都很高,导致正负样本之间的区分度不高,当时并不明白是什么原因导致的,只知道不微调BERT,直接拿来用的效果不行。直到今天已经有不少工作对这个问题给出了解释,原因是BERT的句子向量空间是不平滑的、各向异性的,如何理解”各向异性“这个词?一个好的向量空间应该是均匀分布的,这样表征出来的句子就会呈现出差异化,而”各向异性“的向量空间中,是非均匀的,可能会聚簇在一个狭小的地方,表征出来的句子会很相近。知道了原因,就会有相应的解决方案,接下来介绍几个相关的工作。
论文一:On the Sentence Embeddings from Pre-trained Language Models
BERT向量空间的”各向异性“概念早在这篇论文之前就有人提出,但却是在这篇论文中被大家熟知。并且通过理论和实验进一步认证了这个问题,论文中使用词向量来论证这个问题(因为在语言模型中词向量和上下文向量是相关的,如果词向量存在问题,那上下文向量也存在问题),作者通过计算词向量和原点之间的欧式距离以及词向量和K近邻之间的欧氏距离,发现高频词离原点近且分布集中,低频词离原点远且分布离散。
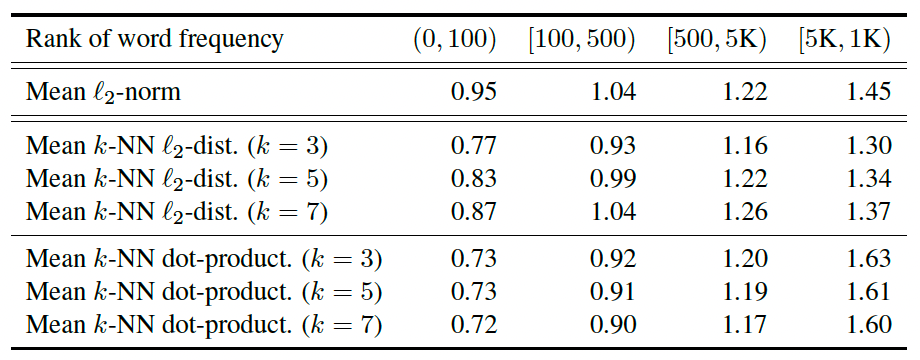
这样的结果会导致语义不同的高频词相近,而语义相同的高频词和低频词却相隔很远,这也就是为什么用BERT直接得到句向量时,句向量之间的余弦相似值都很高,因为大部分句子主要都是由高频词组成,而高频词无论语义是否相同,在向量空间中都相隔的很近。
作者在这里也提出了一种方法来解决”各向异性“的问题,就是将”各向异性“的向量空间转换到一个”各向同性“的高斯分布空间。
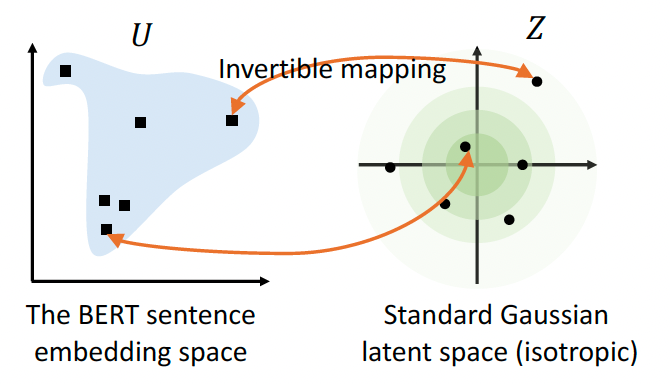
基于流式生成模型,将BERT的向量表征可逆的映射到高斯分布空间,作者将这个命名为BERT-flow,学习一个可逆的映射$f$,把服从高斯分布的变量$z$映射到BERT的向量分布$u$,则$f^{-1}$就可以把$u$映射到高斯分布。在训练过程中,只训练$f$,不更新BERT的权重。最终的实验结果如下:
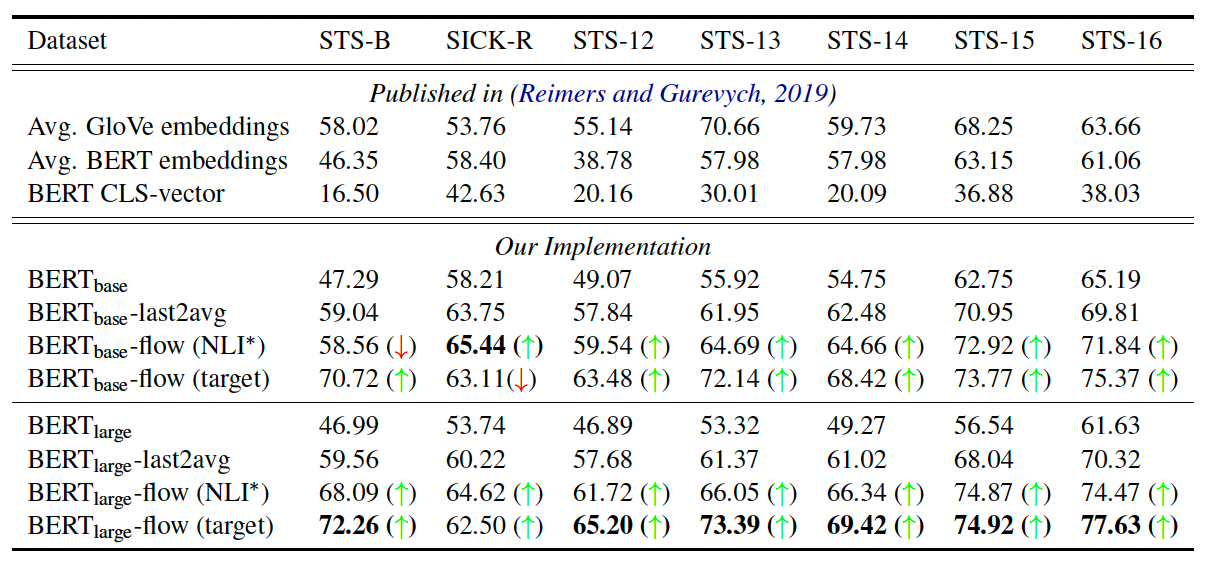
直接使用BERT的得到句向量的效果是不如Glove词向量的平均,使用BERT-flow后效果提升还是挺明显的。
论文二:SimCSE: Simple Contrastive Learning of Sentence Embeddings
对比学习是提升无监督语义相似度的又一有力手段,对比学习的特点是使得正样本相近,负样本远离。对比学习有两个相关指标: $Alignment$ 和 $Uniformity$ ,可以用来衡量句子表征的质量。$Alignment$ 用来度量两个正样本之间的距离,$Uniformity$ 用来度量表征是否分布均匀:
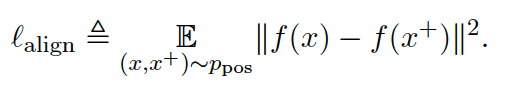
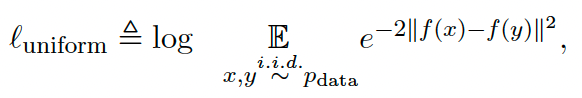
对比学习的目的就是让正样本相互靠近,负样本相互远离。所以对比学习的 loss 可以表达成下面的形式,其中$sim(h_i, h_i^+)$是余弦距离:
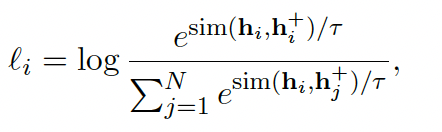
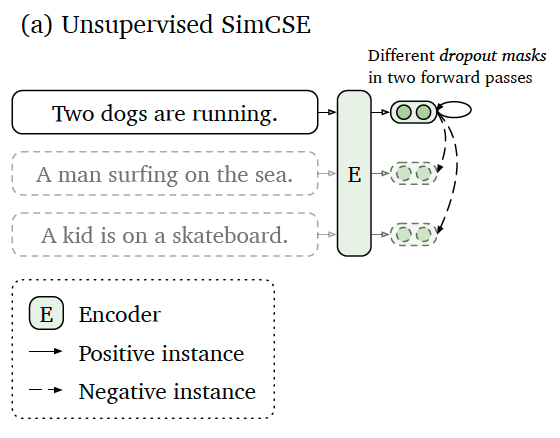
对比学习的核心是如何构造正负样本对,在无监督的对比学习中,通常通过数据增强(增、删、改、换等)来获得正样本对,负样本对则使用 in-batch 中不同的样本对作为负样本。而在SimCSE中,作者没有显示地通过数据增强来构造正样本对,而是通过同一样本经两次不同的 Dropout 得到正样本对。如下图所示,
对应的 loss 如下,其中$z_i$ 和 $z_i^{\prime}$ 是同一样本经不同的 dropout 的正样本对:
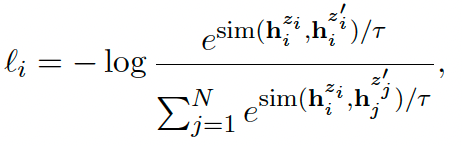
基于 dropout 生成正样本对已经成为了NLP中对比学习常用的正样本生成手段。
论文三:ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
ESimCSE 是在 SimCSE 的基础上改进的模型,主要是从正负样本构造上进行了优化。作者认为在 SimCSE 中因为正样本是同一个样本,在Transformer的架构中,同一个样本的长度一致,这点信息在位置向量中会被突显出来,有了这点信息,模型就可以更容易地判断哪些是正样本,哪些是负样本,导致模型没学到深层的语义信息就收敛了;二是对比学习中负样本的空间是非常大的,in-batch 的负样本构造不一定能代表整个负样本的分布,换句话说 in-batch 的负样本采样受batch size 的影响,导致负样本的数量不够多,困难负样本涵盖不够,负样本容易被识别,因此作者采用了计算机视觉中常用的动量对比的方法,用一个队列来存储历史 batch 作为负样本,来扩大负样本的数量。
具体的技术方案如下图所示:
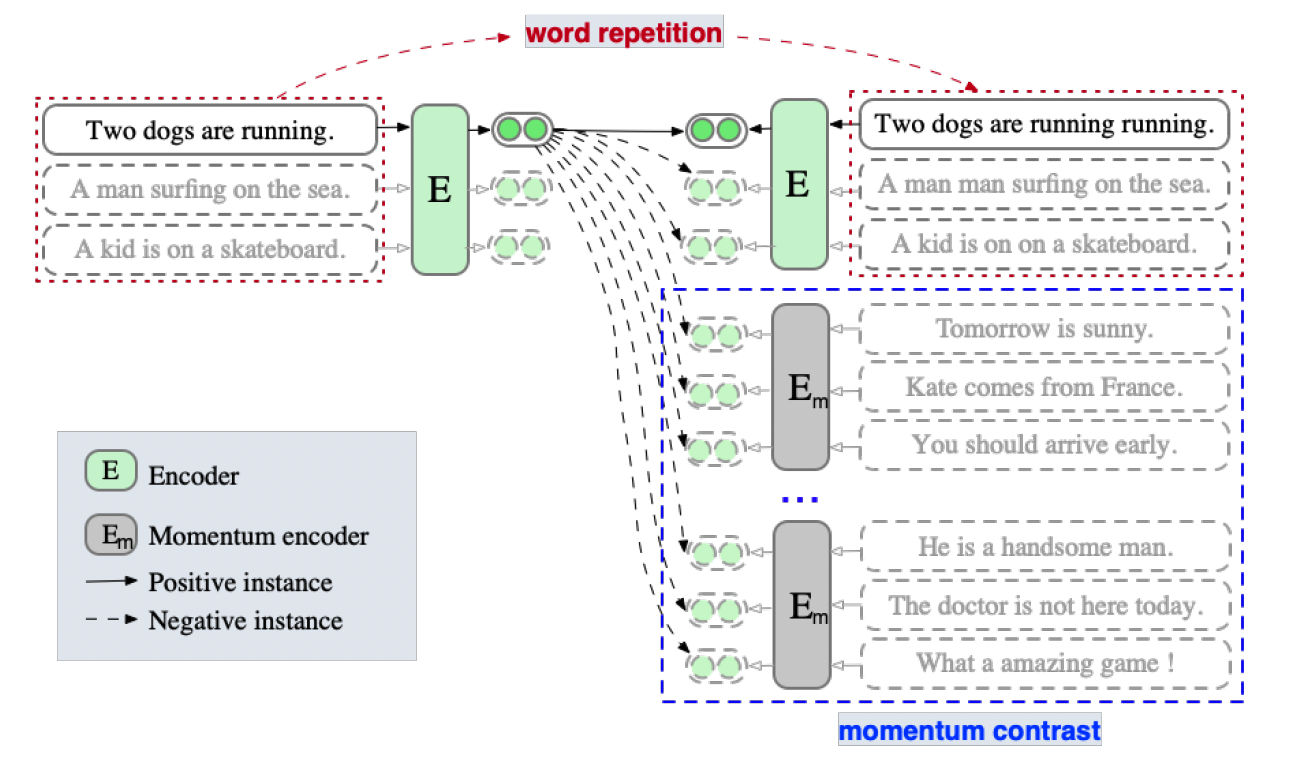
1)正样本构造
作者认为增删改等都有可能改变句子的语义,但是对词做复制的话不太可能会影响句子的语义。作者通过对句子中的子词进行复制来构造正样本对,这样得到的正样本对长度也不一致,如上图所示 ”Two dogs are running“ 和 ”Two dogs are running running“就是通过复制构造的正样本对,通过均匀采样复制哪个子词,且复制子词的比例也是一个可设置的超参数。
2)动量对比
用一个队列将历史 batch 缓存起来,队列的大小是固定的,遵循这新batch 入队列,老batch 出队列。队列中的样本用一个新的 Momentum Encoder来编码,Momentum Encoder只做前向计算,不过反向传播更新参数,它的参数由Encoder的参数来辅助更新,更新机制如下,通过滑动的方式更新:
![]()
由于引入了动量对比,loss 也要将这部分负样本加进来,loss 表达式如下:
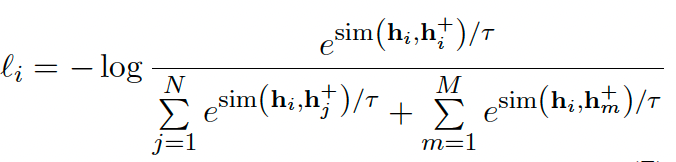
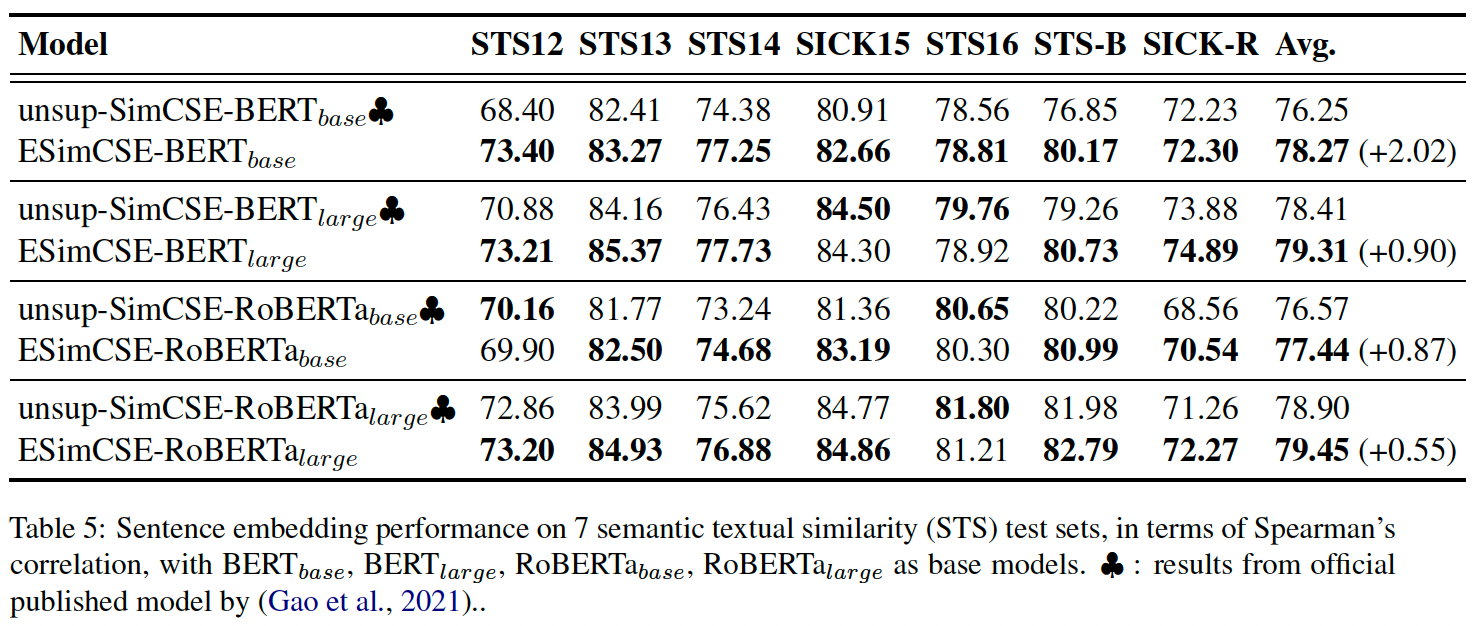
经过这两点优化后,相比SimCSE还是有不小的提升:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号