

句子对关系预测——交互式模型
句子对关系是NLP中非常常见的任务,例如句子相似度计算,自然语言推断等。句子对关系判断一般都两种模型:一是表示式模型,例如孪生网络,DSSM,这类模型的特点是将句子编码成向量,在编码时两个句子可以共享或不共享模型参数,之后再通过余弦,欧式距离等计算两个向量的距离,从而来表示两个句子的相关性;二是交互式模型,交互式模型比表示式模型要复杂,但在预测两个句子的相关性时不仅仅只使用了句子的信息,还使用了词,短语这一类更细粒度的信息,简单说就是在模型构造时会将两个句子中的词和短语做交互。
虽说预训练模型在各种基准任务上都取得当前最优的结果,但对于复杂的交互式模型还是有必要了解一些,因为这些模型的交互层在做句子对任务时是值得借鉴的,也许在一些数据集上用预训练模型做encoder,再配合这些交互层,可能能取得更好的效果,所以接下来我们来看看一些经典的交互式模型。
一,MatchPyramid
论文:Text Matching as Image Recognition
本论文比较早,在attention还没有在NLP中广泛的应用下,将文本匹配问题转换成图像识别的问题,想法还是比较新奇的。但文本和图像有一个很明显的区别就是,文本是一维的,而图像是二维的,如何将一维的文本转换成二维的图像是本文的一个重点,此外在图像识别中通常是通过多层CNN去提取不同粒度的特征,作者也是利用了这种思想,通过多层的CNN去提取不同粒度的交互特征。
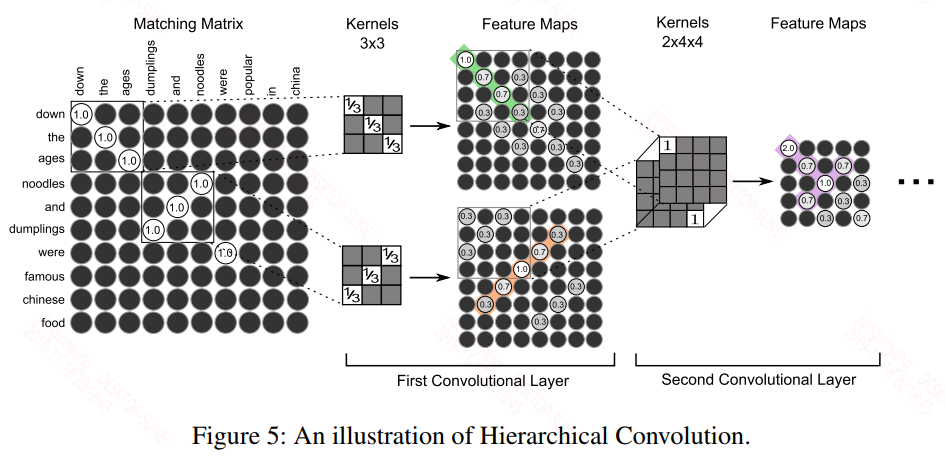
首先我们为什么需要交互式模型,看个具体的例子:

如上图所示,两个语义相同的句子,在词级别上就有很多相同或相似对应的词,例如down-down,famous-popular等等。在短语级别上也是noodles and dumplings - dumplings and noodls等等。在更细粒度上做交互可以获得更多的信息。来看看具体的模型实现,模型结构图如下:

整个模型可以分为匹配矩阵层,卷积层,MLP层。
匹配矩阵层:为了将一维的文本转换成二维,在这里作者构建了一个匹配矩阵,具体的来说就是两个句子中的词两两计算相似度得到一个矩阵,矩阵中的元素$M_{ij}$表示句子1中的第$i$个词和第2个句子中的第$j$个词的相似度值,具体表达式如下:
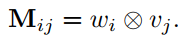
在这里作者提供了三种相似度计算的方法:Indicator Function(当两个词相同则为1,否则为0,感觉这种方法跟词袋模型类似,效果应该一般,而且是离散计算的) ,cosine,dot。

卷积层:在这里作者采用了两层卷积核池化来抽取匹配矩阵中的细粒度特征。卷积核可以看作类似于n-gram,因此卷积核可以捕获短语与短语之间的相似度信息。
MLP层:在这里作者同样采用了两层的全连接层来进一步提取句子特征。
最后的损失函数为交叉熵损失函数,经典的分类损失函数。
二,ESIM
论文:Enhanced LSTM for Natural Language Inference
首先这篇论文本质上是给出了两个模型——ESIM和HIM,看下具体的模型结构图,再来说这两者的区别
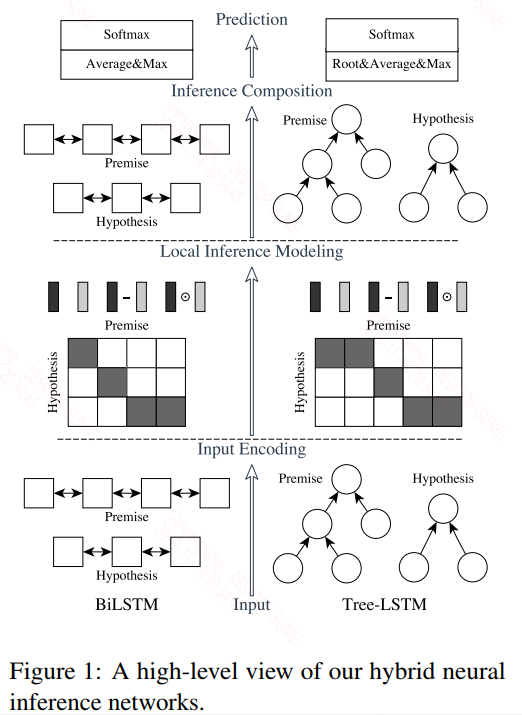
横向来看,上面的图中既有BiLSTM,还有Tree-LSTM,作者将只使用BiLSTM的模型称为ESIM,同时使用BiLSTM和Tree-LSTM的模型称为HIM,从结果来看HIM的效果是要优于ESIM,但是能输入到Tree-LSTM的数据是比较难以获得的,你需要给出类似依存树这样的信息才行,因此适用性很窄,所以我们只关注ESIM。
整个模型可以分为4层:输入层,局部推断层,推断合成层,预测层。
输入层:词向量嵌入,BiLSTM编码,两个句子共享参数
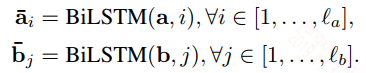
局部推断层:在这里attention已经在NLP中被广泛使用,而基于attention的交互模式也非常直接,因此后面的模型交互层基本都是基于attention的,首先计算两个句子中词与词之间的点积,得到一个相似度矩阵,然后通过attention机制求得每个词对应的一个新的向量:

上面式子中$\tilde{a_i}$是$\bar{a_i}$对所有的词$b$ attention的结果,个人认为这个能提取句子B中的和$\bar{a_i}$相关的信息,用句子B中所有的词来表示$\bar{a_i}$。在这个基础上,作者还做了增强推断,具体的就是对$\tilde{a_i}$和$\bar{a_i}$之间进行交互,得到更多的局部信息,说实话这里我是没看懂为什么要这么做的。
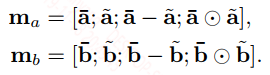
将得到的$\bar{a}, \tilde{a}, \bar{a}-\tilde{a}, \bar{a} \odot \tilde{a}$四个在词的维度上拼接
推断合成层:将推断的结果组合起来。将上面得到的$m_a, m_b$再经过BiLSTM,然后通过最大池化或平均池化得到句子的向量:
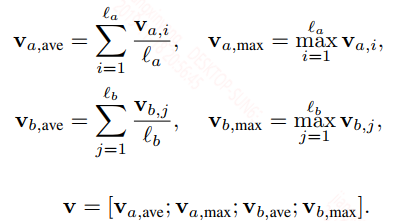
最后将向量$V$输入到全连接层中经softmax分类。
三,BiMPM
论文:Bilateral Multi-Perspective Matching for Natural Language Sentences
本论文将交互式模型分为五个典型的部分:词表示层(嵌入层),上下文表示层(编码层),句子匹配层,聚合层,预测层。
词表示层:显而易见就是用词向量来表征词
上下文表示层:在这里使用BiLSTM来捕捉上下文信息
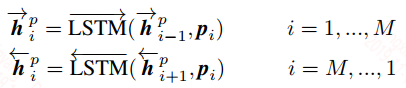
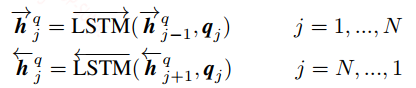
句子匹配层:这一层是本文的核心,这一层提供了四种匹配策略,并且对于每种匹配策略都从不同的视角出发,我们来看看具体的含义,首先什么是不同的视角?我们在计算两个向量的余弦值时引入一个矩阵$W$,表达式如下:

这个矩阵$W$中的每个向量都会对向量$v_1, v_2$做element-wise的映射,表达式如下:
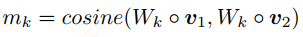
上面式子中的$W_k$是矩阵$W$中的第$k$个向量,本来两个向量的余弦值是一个标量,通过引入矩阵$W$,我们会得到一个向量$m$,这个向量就是从不同视角下计算得到的余弦值。
本论文还提供了四种匹配策略,如下图所示:
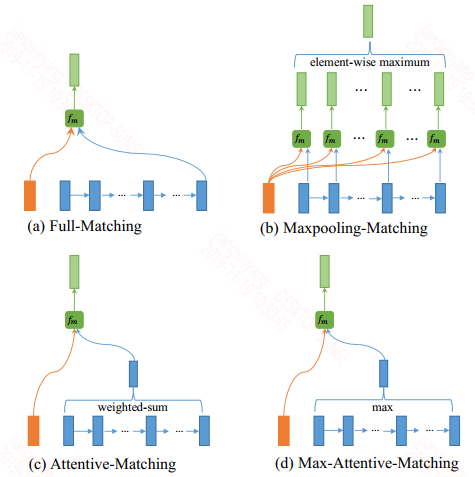
四种策略分别为:Full-Matching,Maxpooling-Matching,Attentive-Matching,Max-Attentive-Matching。这里提供的四种策略并没有做词与词的交互,而是直接做的词与句子向量的交互。这样感觉很像是将一个句子拆分来,来计算该句子的每个部分和句子的余弦值,此外每个分布的权重可能不一样,然后按照对应的权重加权和。上面提供的四种策略的不同之处只在于如何表征句子向量
Full-Matching:该策略就是将最后时刻的输出作为句子向量的表征,然后计算词和句子向量之间的相似度,在这里只显示了句子p中的词对句子q的句向量的余弦值,公式如下:
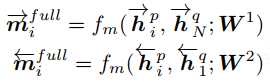
Maxpooling-Matching:该策略采用max pooling的方式输出句子向量
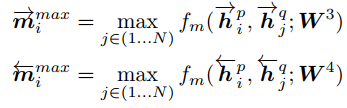
Attentive-Matching:该策略采用attention的方式输出句子向量

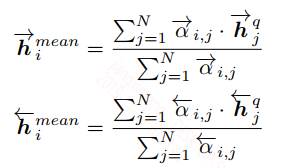
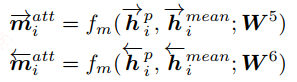
Max-Attentive-Matching:该策略就是将上面的策略中的加权和求句向量改成权重最大的方式求句向量。
对于采用多少个不同视角,也就是矩阵$W$中应该含有多少个映射向量,作者也做了实验:
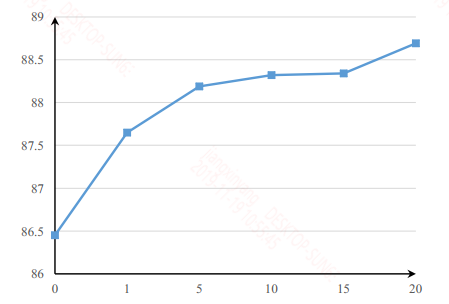
随着视角数的增加,模型的性能还是会上升的。
聚合层:将上述不同策略得到句子(此时的词向量长度等于矩阵$M$的向量数)再经过Bi-LSTM,之后将最后时刻的向量拼接再一起(不同策略的拼接在一起,再把两个句子的拼接在一起)。
预测层:将聚合层的输出输入到softmax中进行分类。
四,MWAN
论文:Multiway Attention Networks for Modeling Sentence Pairs
看完这篇论文后,有一种想法,也不只是针对这篇论文,而是很多论文中的交互式模型都非常复杂,这些复杂的模型到底是怎么想出来的,还是说是不断的尝试得到的,不懂为什么要这么设计,以及这样设计后会什么会有效。说了这么多来看看这篇论文吧,这篇论文用了很多attention机制,并且也对比了不同attention机制的结果,这个还是挺不错的。
模型结构如下:
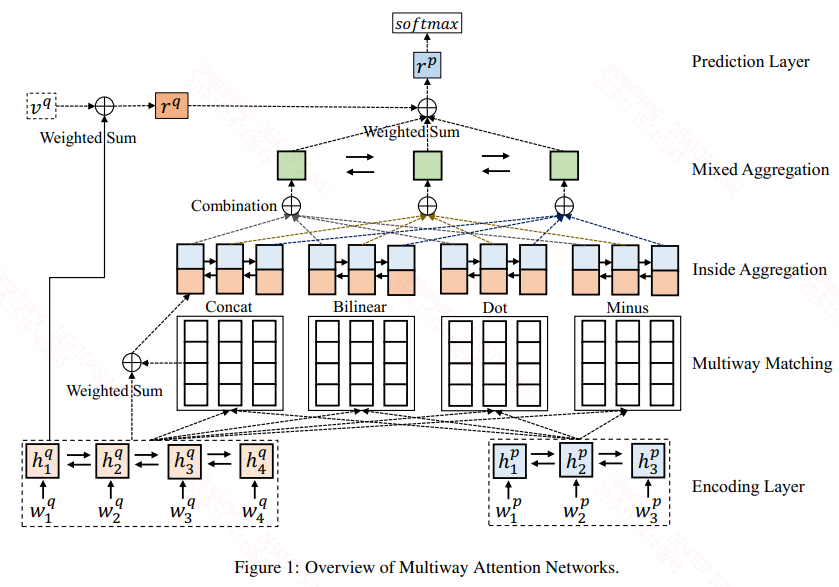
整个模型同样可以分为5层:嵌入层,编码层,匹配层,聚合层,预测层。本文的重点都在匹配层和聚合层。
嵌入层:在这里作者采用了GLOVE词向量嵌入。
编码层:采用了BiGRU进行编码。
匹配层:作者采用了4种attention机制来做词对词的匹配,4种attention机制分别为:Concat Attention,Bilinear Attention,Dot Attention,Minus Attention。

对于句子Q种的词隐层向量$h_j^q$,通过4种对句子P做的attention机制后,可以得到4种对应的attention后的向量$q_t^c, q_t^b, q_t^d, q_t^m$。
聚合层:这一层就是对上面4种attention后的向量和原隐层向量的聚合,首先分别对4种attention后的向量和原隐层向量单独聚合,通过门机制来控制信息的流出:
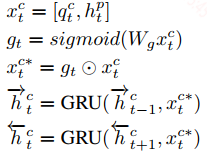
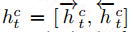
上面就是对attention向量$q_t^c$和原隐层向量$h_t^p$的聚合,这样聚合完之后,在每个词的位置还是有4个向量,在这里作者再次采用attention机制对这4个向量做加权和:
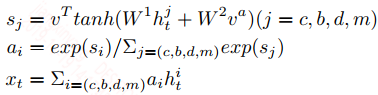
通过这样一系列的操作折后,对句子Q和P种的每个词就是一个单独的向量,这样整个句子的维度和encoder后的维度一致。然后再进入到一个BiGRU层去捕获聚合后的上下文信息。
预测层:这一层会将两个句子合并成一个向量,然后输出到分类器中,在这里作者依然用了attention来获得最终的向量,先随机初始化一个向量对句子Q做attention,得到句子向量$r^q$:
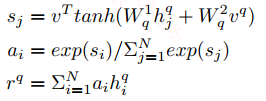
利用$r^q$对句子P做attention,得到句子向量$r^p$,又因为$r^p$是由$r^q$attention出来的结果,因此作者直接将$r^p$作为最终两个句子语义交互的向量,再进入到softmax分类。
另外在作者的实验中表明Dot Attention的结果是要优于另外3种的,当你只采用一种attention机制时,可以首选Dot,其实在大多数论文种采用的attention都是Dot。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号