数据分析之pandas模块
Pandas
1.介绍
Pandas使我们进行数据分析的一个主要工具。它是基于Numpy构建的,它所包含的数据结构和数据处理工具的设计使得Python中进行数据清洗和分析非常快捷。pandas一般也是和其他数值计算工具一起使用的,支持大部分Numpy语言风格的数组计算。pandas和numpy最大的区别就是pandas是用来处理表格型或者异质性数据的,而Numpy则刚好相反,它更适合处理同质型的数值类数组数据
2.Pandas的主要功能:
-
具备对其功能的数据结构DataFrame,Series
-
集成时间序列功能
-
提供丰富的数学运算和操作
-
灵活处理缺失数据
安装方法:
pip install pandas
引用方法:
import pandas as pd
2.1. Series数据结构
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
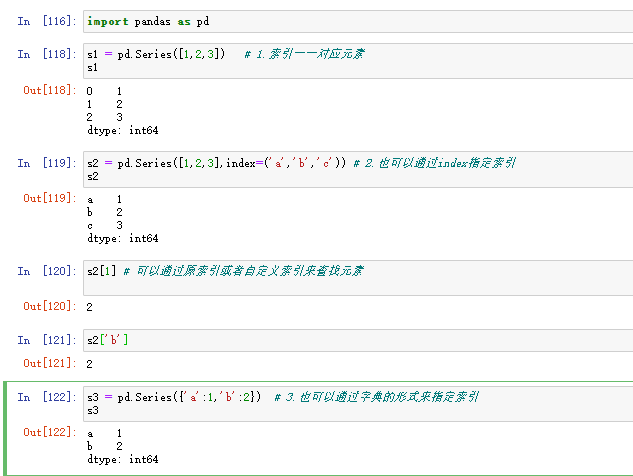
第四种:创建一个值都是0的数组
pd.Series(0,index=['a','b','c'])
执行结果: a 0
b 0
c 0
dtype: int64
缺失数据
为什么会出现数据缺少的现象呢,看下面的例子
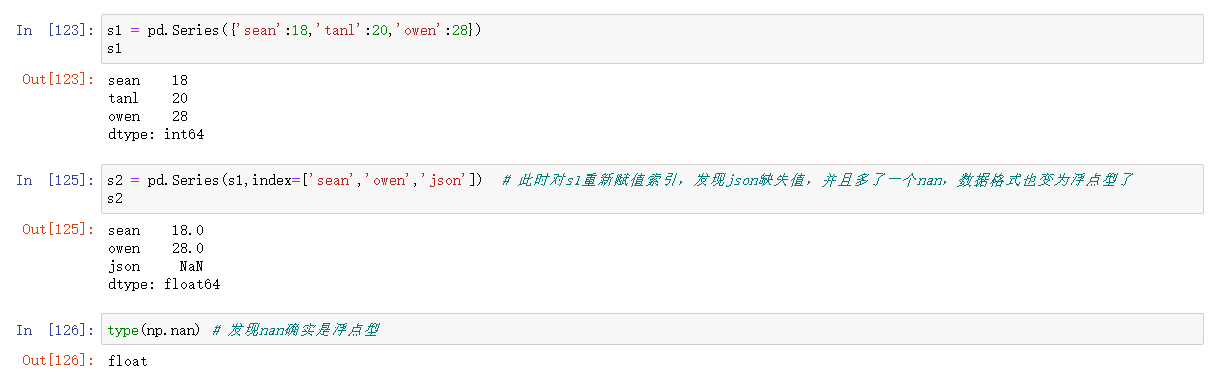
如何处理缺失值
-
dropna:过滤掉值为nan的
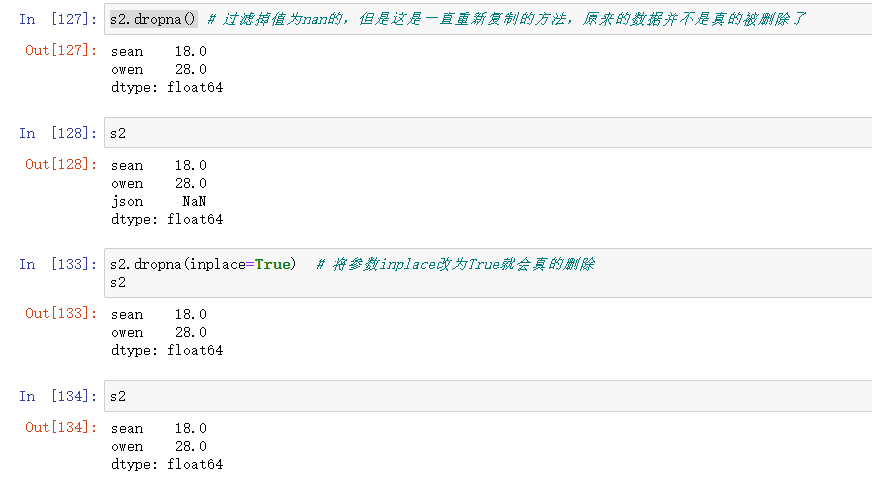
-
fillna:将nan进行填充

-
isnull() : 返回布尔数组,缺失值对应为True
-
notnull() :返回布尔数组,缺失值对应为False
2.2 Series特性(和numpy基本一样)
-
从ndarray创建Series:Series(arr)
-
与标量(数字):sr * 2
-
两个Series运算
-
通用函数:np.ads(sr)
-
布尔值过滤:sr[sr>0]
-
统计函数:mean()、sum()、cumsum()
支持字典的特性:
-
从字典创建Series:Series(dic),
-
In运算:'a'in sr、for x in sr
-
键索引:sr['a'],sr[['a','b','d']]
-
键切片:sr['a':'c']
-
其他函数:get('a',default=0)等
整数索引
pandas当中的整数索引对象可能会让初次接触它的人很懵逼,接下来通过代码演示:
sr = pd.Series(np.arange(10))
sr1 = sr[3:].copy()
sr1
运行结果:
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int32
# 到这里会发现很正常,一点问题都没有,可是当使用整数索引取值的时候就会出现问题了。因为在pandas当中使用整数索引取值是优先以标签解释的,而不是下标
sr1[1]
解决方法:
-
loc属性 # 以标签解释
-
iloc属性 # 以下标解释
sr1.iloc[1] # index+location 以自定义index索引解释
sr1.loc[3] # location 以原索引解释
Series数据对齐
pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr2 = pd.Series([11,20,10], index=['d','c','a',])
sr1 + sr2
运行结果:
a 33
c 32
d 45
dtype: int64
# 可以通过这种索引对齐直接将两个Series对象进行运算
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1 + sr3
运行结果:
a 33.0
b NaN
c 32.0
d 45.0
dtype: float64
# sr1 和 sr3的索引不一致,所以最终的运行会发现b索引对应的值无法运算,就返回了NaN,一个缺失值
将两个Series对象相加时将缺失值设为0:
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1.add(sr3,fill_value=0)
运行结果:
a 33.0
b 14.0
c 32.0
d 45.0
dtype: float64
# 将缺失值设为0,所以最后算出来b索引对应的结果为14
灵活的算术方法:add,sub,div,mul
2.3 DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
创建方式:
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来形成DataFrame:
第一种

第二种通过Series来创建

获取数据信息
read方法
-
read_csv
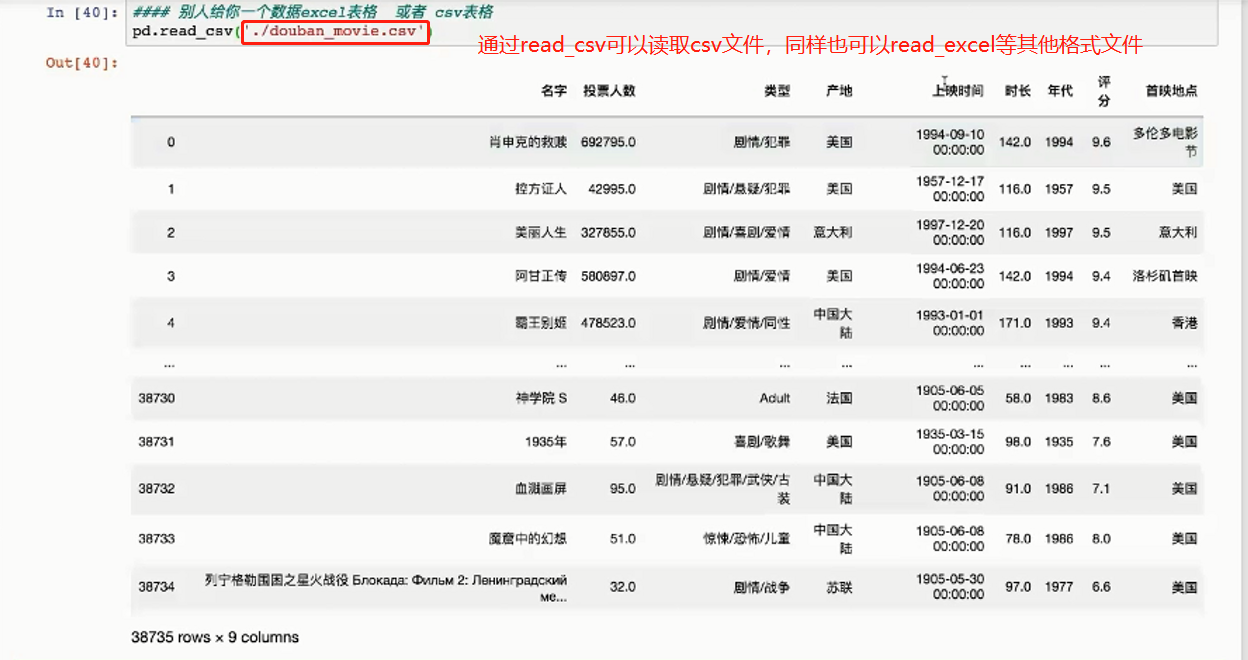
-
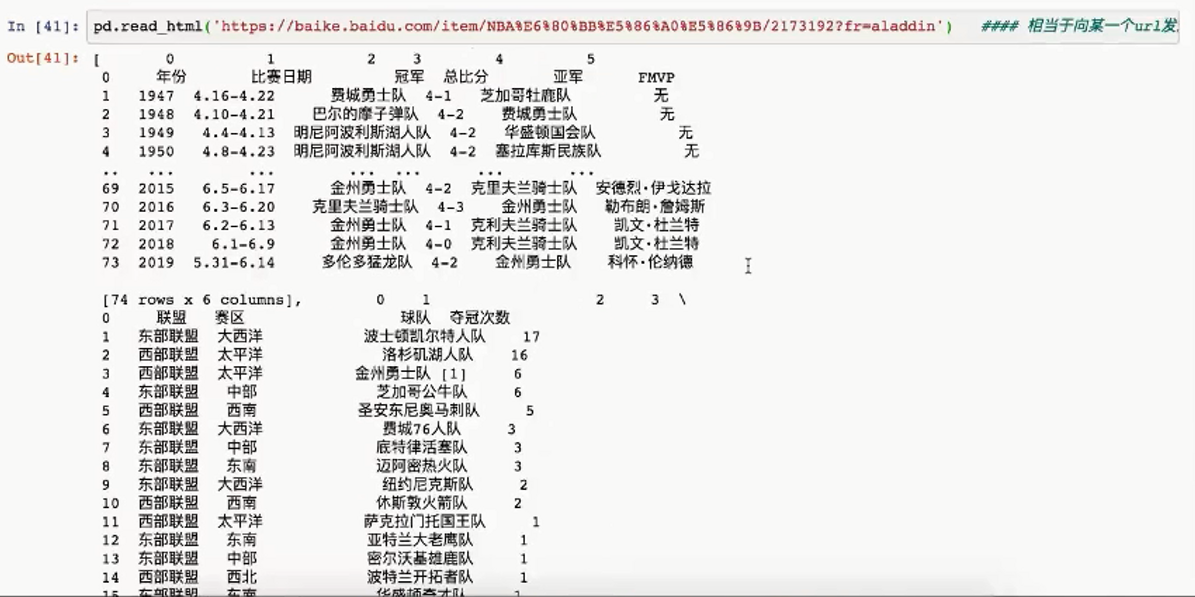
read_html
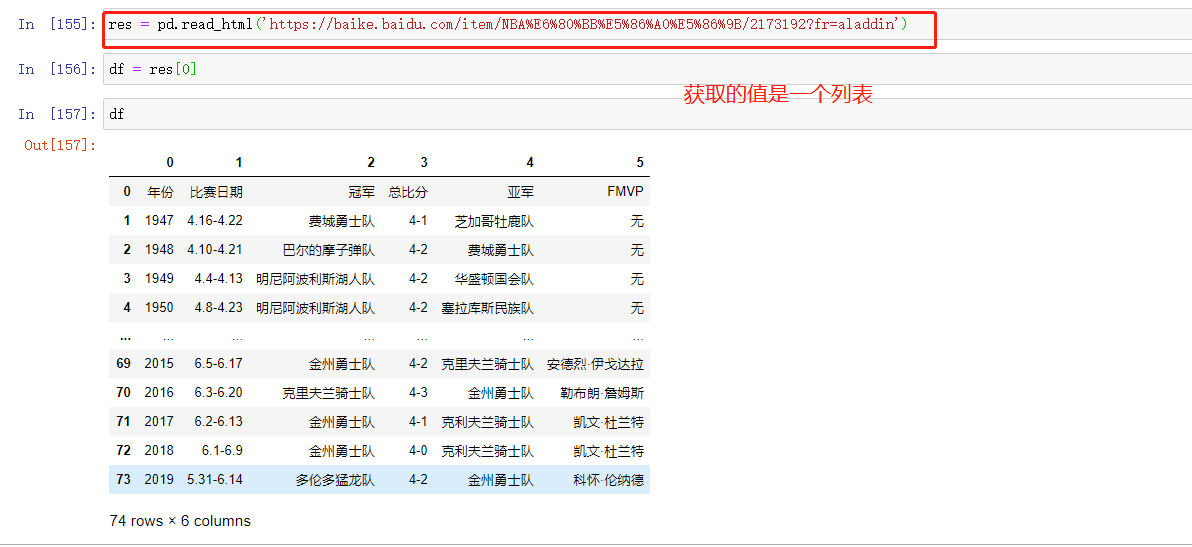
通过索引获取需要的信息
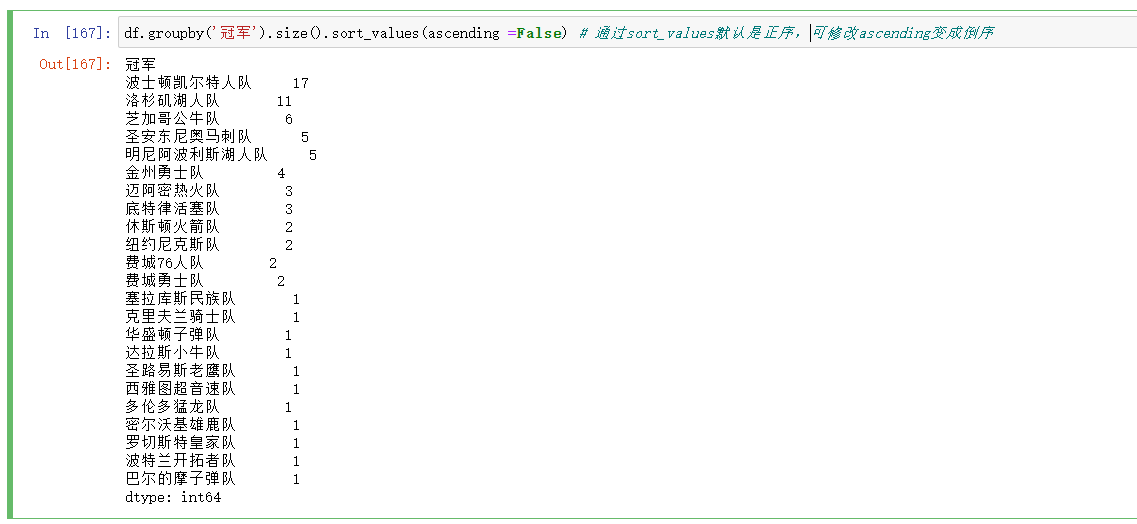
将表格修改一下





 浙公网安备 33010602011771号
浙公网安备 33010602011771号