kafka备忘录
ODPS优化:https://developer.aliyun.com/article/1491341?spm=a2c6h.12883283.index.78.5f1f4307BJr7k3
https://help.aliyun.com/zh/maxcompute/user-guide/use-logview-v2-0-to-view-job-information?spm=a2c4g.11186623.0.0.34bc2ec38fYGds
https://developer.aliyun.com/article/1517196?spm=a2c6h.14164896.0.0.3eda47c5M2fbp2&scm=20140722.S_community@@%E6%96%87%E7%AB%A0@@1517196._.ID_1517196-RL_maxcompute%E4%BC%98%E5%8C%96-LOC_search~UND~community~UND~item-OR_ser-V_3-P0_0
生产者:
package org.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.HashMap;
import java.util.Map;
public class KafkaP {
public static void main(String[] args) {
// 创建一个hashmap作为生产者的配置对象
Map<String,Object> configMap = new HashMap<>();
configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建一个kafka生产者,泛型是对k,v定义和限制
KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);
// 把数据发送到kafka
for (int i = 0; i < 10; i++){
// 创建一个消息对象
ProducerRecord<String, String> record = new ProducerRecord<>("test", "key"+i,"hello kafka"+i);
producer.send(record);
}
// 关闭生产者
producer.close();
}
}
消费者:
package org.example;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.HashMap;
import java.util.Map;
public class KafkaC {
public static void main(String[] args) {
Map<String,Object> configMap = new HashMap<>();
configMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
configMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configMap.put(ConsumerConfig.GROUP_ID_CONFIG,"test_group");
// 创建kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configMap);
// 订阅主题
consumer.subscribe(java.util.Arrays.asList("test"));
// 消费数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
// 关闭消费者
// consumer.close();
}
}
先启动消费者等待着
再启动生产者即可得到测试数据
如果是windows可以使用kafkatool可以便利操作
核心概念补充:
Kafka的topic分区是一个核心概念,它允许Kafka将数据分散到多个broker上,以实现更高的吞吐量和容错性。以下是关于Kafka topic分区的详细解释:
Kafka Topic分区
定义:
Kafka的topic是一个记录流,可以看作是一个消息队列。而每个topic都可以被划分为一个或多个分区(partition)。
作用:
分区的主要目的是提高Kafka的吞吐量和容错性。通过将topic划分为多个分区,Kafka可以实现数据的并行处理,因为不同的分区可以部署在不同的broker上,并由这些broker独立处理。
同时,分区也是Kafka实现数据冗余和容错的关键。通过将同一个topic的多个分区复制到不同的broker上,Kafka可以确保即使某个broker出现故障,数据也不会丢失,因为其他broker上的副本仍然可用。
分区与数据:
不同分区存储不同数据:在Kafka中,每个分区都是一个有序的消息序列。不同的分区之间不会存储相同的数据。这意味着,当生产者向topic发送消息时,这些消息会被分配到该topic的一个或多个分区中,但同一消息不会出现在多个分区中。
分区与消费者:消费者组(consumer group)中的消费者可以并行地从不同的分区中读取数据。但是,对于同一个消费者组内的消费者,Kafka会确保每个分区只被一个消费者读取,以避免数据重复消费。不过,不同的消费者组可以独立地读取同一个分区的数据。
分区数与性能:
分区数过多或过少都可能影响Kafka的性能。过多的分区会导致过多的文件句柄打开,增加系统的I/O压力;而过少的分区则可能导致单个broker的负载过高,无法充分利用集群的资源。
因此,在选择分区数时需要根据实际场景进行权衡。一般来说,可以根据topic的数据量、消费者的并发量以及集群的规模来确定合适的分区数。
总结
Kafka的topic分区是Kafka实现高性能、高吞吐量和容错性的关键。通过将topic划分为多个分区,Kafka可以实现数据的并行处理和冗余存储,从而满足各种实际场景的需求。同时,不同的分区之间存储的是不同的数据,确保了数据的一致性和正确性。
Kafka中的消费者组(Consumer Group)是一个非常重要的概念,它允许多个消费者实例共同消费一个或多个Kafka topic的数据,同时保证每条消息只被消费一次。以下是关于消费者组的详细解释:
消费者组(Consumer Group)
定义:
消费者组是一个或多个消费者的集合,它们共享一个共同的消费逻辑(通常是一个应用程序)。消费者组内的消费者实例可以并行地消费数据,但每个分区内的数据只能被组内的一个消费者实例消费。
作用:
水平扩展:通过增加消费者组内的消费者实例数量,可以水平扩展应用程序的吞吐量,从而处理更多的数据。
容错性:如果消费者组内的某个消费者实例失败,其他消费者实例可以继续消费数据,确保数据不会丢失。
数据隔离:不同的消费者组可以独立地消费同一个topic的数据,实现数据的隔离和独立处理。
分区与消费者组:
Kafka保证每个分区只能被消费者组内的一个消费者实例消费。这意味着,如果消费者组内的消费者实例数量少于分区的数量,那么一些消费者实例将消费多个分区的数据;如果消费者实例数量多于分区的数量,那么一些消费者实例将处于空闲状态。
Kafka通过消费者组的协调器(coordinator)来管理消费者与分区之间的映射关系。当消费者加入或离开消费者组时,协调器会重新分配分区给消费者实例,以确保每个分区都有且仅有一个消费者实例在消费。
偏移量(Offset):
Kafka使用偏移量来跟踪消费者已经消费的数据位置。每个消费者实例都会维护一个偏移量,表示它已经消费到了分区中的哪个位置。当消费者实例消费数据时,它会更新自己的偏移量,并将新的偏移量提交给Kafka服务器。这样,即使消费者实例失败或重启,它也可以从上次提交的偏移量位置继续消费数据。
消费者组ID:
每个消费者组都有一个唯一的ID,用于标识该消费者组。在创建消费者实例时,需要指定消费者组ID,以便Kafka服务器将其加入到相应的消费者组中。
消费者组配置:
Kafka提供了许多与消费者组相关的配置选项,如session.timeout.ms(消费者与协调器之间的会话超时时间)、max.poll.interval.ms(消费者两次轮询之间的最大时间间隔)等。这些配置选项可以根据实际场景进行调整,以优化消费者组的性能和容错性。
总结
消费者组是Kafka实现水平扩展、容错性和数据隔离的关键。通过合理地配置和管理消费者组,可以确保Kafka系统的高效运行和数据的可靠处理。
生产者(Producer):负责将数据发送到Kafka服务中。
消费者(Consumer):从Kafka中提取数据进行消费。
Broker(集群实例):Kafka支持集群分布式部署,每个服务器上的Kafka服务即为一个Broker。
Topic(主题):Kafka中的关键词,单个Topic代表一种类型的消息。
Partition(分区):Topic下的更小元素,每个Topic可以有多个Partition,每个Partition在磁盘上对应一个文件。
Offset(偏移量):用于标记消息在Partition中的位置。
架构图:
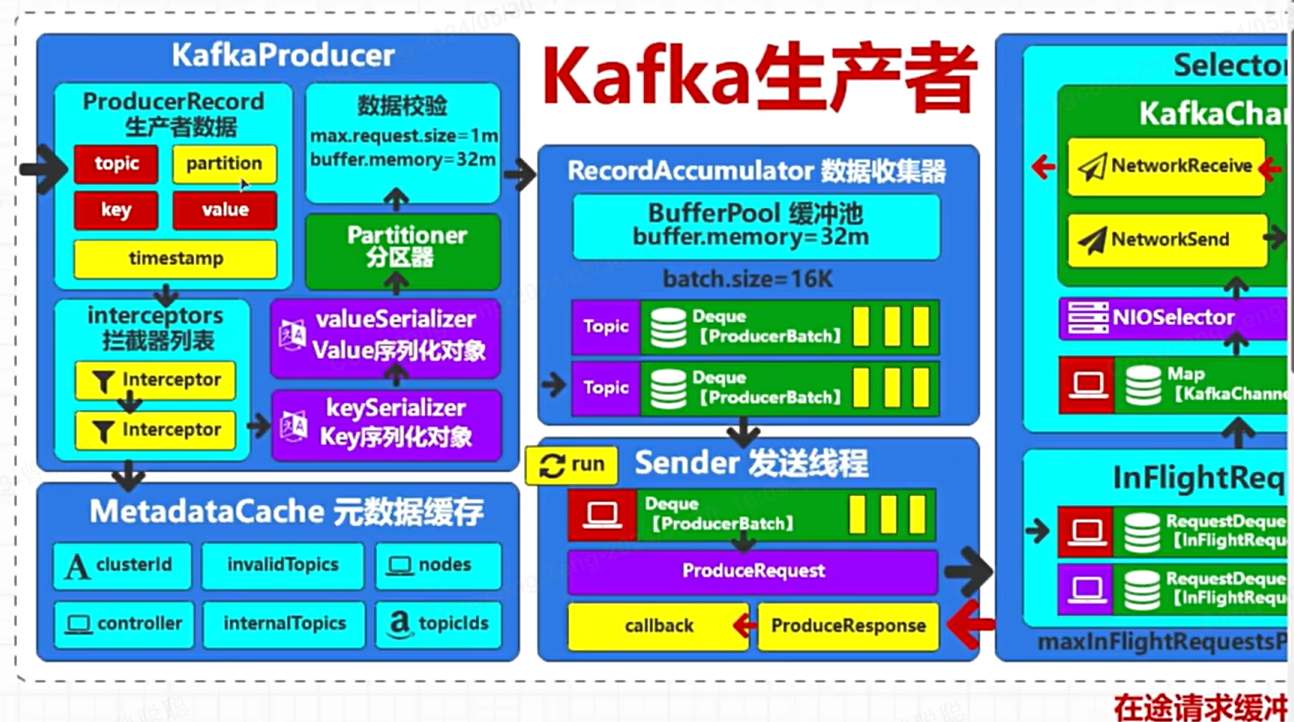
主要流程:
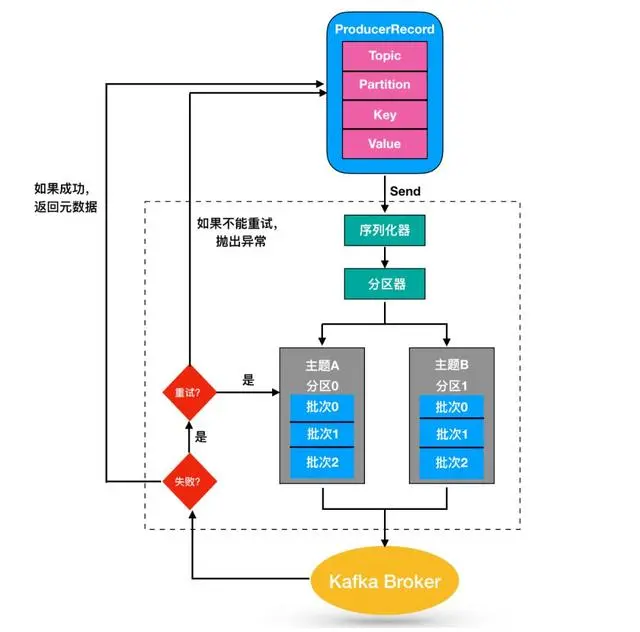
同步和异步发送都各有优劣,可以通过配置应答配置ACKS进行应答级别控制:(在生产者处配置)
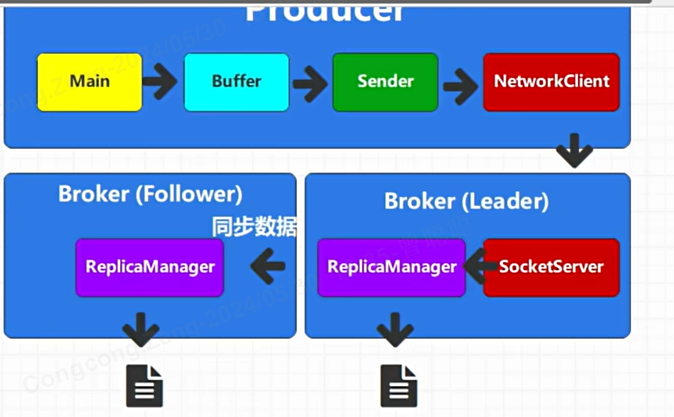
acks=0:生产者发送消息后,不等待任何Broker的确认就认为消息已成功写入。这种情况下,如果Broker在收到消息但尚未持久化到磁盘之前宕机,那么消息将会丢失。虽然吞吐量最高,但数据可靠性最低。
acks=1(默认值):生产者发送消息后,等待leader replica成功写入消息后就认为消息已成功写入(存盘成功)。这种情况下,如果leader replica在收到消息但尚未复制到follower replicas之前宕机,并且其他follower replicas也未能成为新的leader,那么消息将会丢失。它提供了较好的吞吐量和数据可靠性之间的平衡。
acks=all(或称为acks=-1):生产者发送消息后,等待所有同步副本(in-sync replicas, ISR)都成功写入消息后才认为消息已成功写入。这种配置提供了最强的数据持久性保证,但也会牺牲一些吞吐量,因为需要等待多个副本的写入操作。
数据重复和乱序:
没有接收到ACK确认消息时,会重试retry,重试次数可以配置,如果数据在接收到并且持久化后,返回ack过程中挂掉节点,此时retry可能造成重复
如果发送1 2 3三条数据,如果1挂掉重试,则重发后1这个数据会导致乱序
幂等性操作:
可以在生产者配置一个幂等性参数,幂等性并不能解决消息乱序的问题,即如果消息A和消息B先后发送,但由于网络等原因导致消息B先到达,那么即使使用了幂等性,消息B仍然可能先被处理。
幂等性智能保证一个分区数据是幂等的。
数据存储:
数据先到内存,再定期转储为文件。log.flush的参数。数据文件是三个一组:文件名其实代表了偏移量
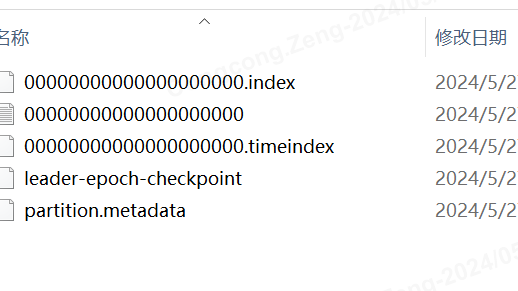
数据topic是一个逻辑结构,具体物理文件是分区parttion:
字段详细说明
- Offset(偏移量):每个Partition中的消息都有一个唯一的、递增的ID,即Offset。它表示消息在Partition中的位置。
- Key:消息的键,用于在Kafka中唯一标识消息。它通常用于路由消息到特定的Partition。key通常用于决定消息应该被写入到哪个partition。Kafka使用key的哈希值来对partition进行选择,以实现消息的分区和有序性。
- Value:消息的实际内容。
- Timestamp(时间戳):消息的时间戳,用于表示消息的创建时间
数据消费流程:
Kafka消费数据的基本流程包括配置消费者、订阅Topic、消费消息、消息处理、消息确认等步骤
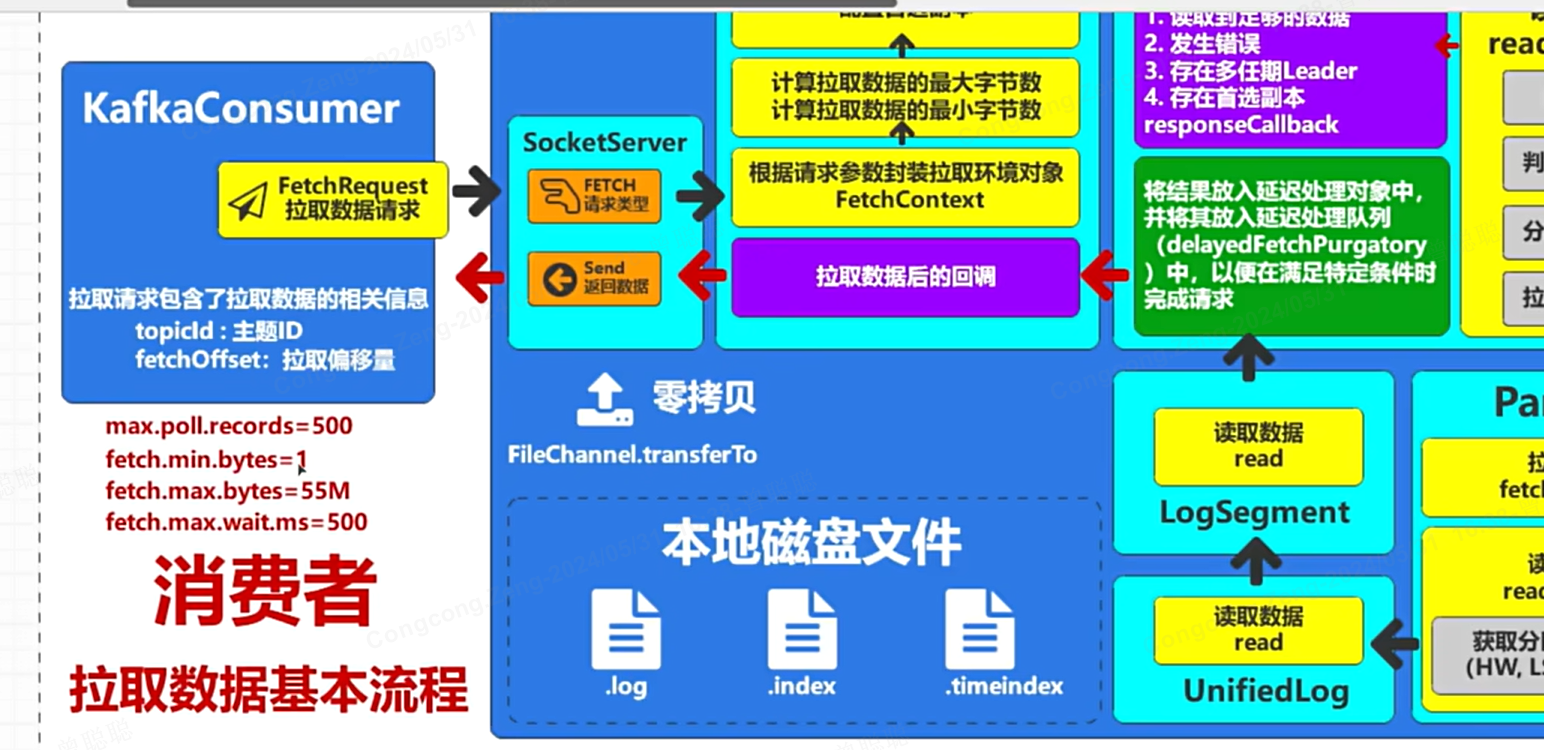
消费者会保存维护偏移量
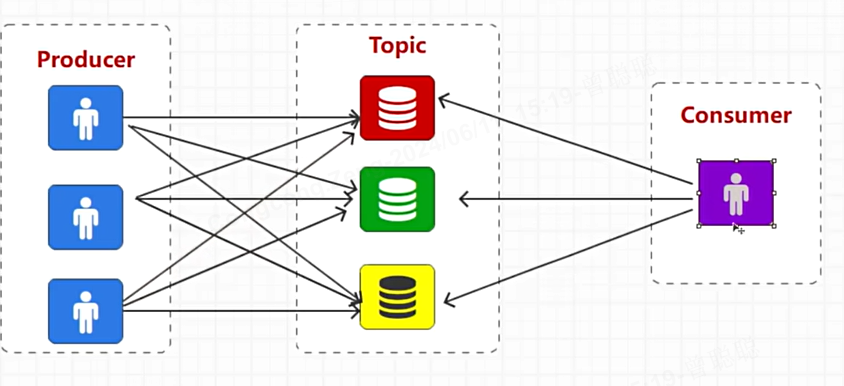
消费者组的概念:
默认情况下,消费者要去自己拉数据,每个分区都得去扫,所以多生产单消费的时候,消费者会特别累
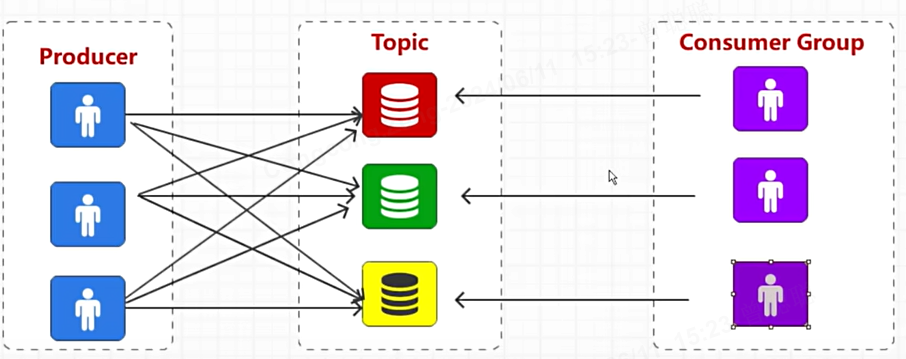
改造后,可以多消费者组成消费者组:一个消费者组是一个逻辑上的消费者,每个组内消费者只消费一个分区,这样效率高。当然也无法组内多个消费者消费一个分区,否则重复消费
基本概念补充:
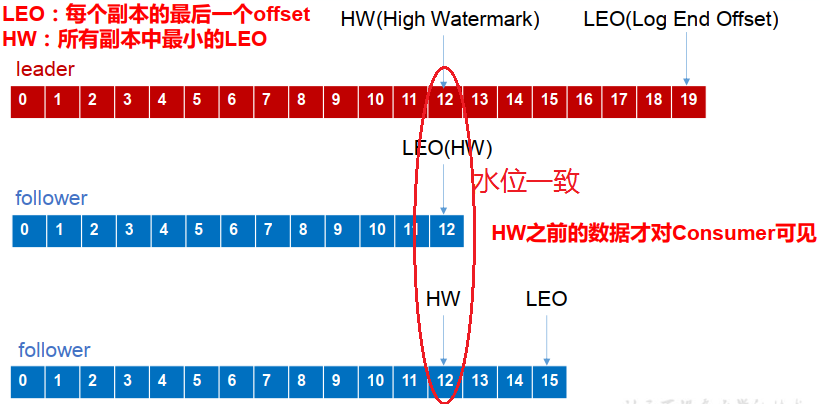
偏移量:
除了 earliest 和 latest,Kafka 的 auto.offset.reset 配置还有一个值 none。此外,在某些版本中或特定的使用场景下,可能会有其他配置选项或行为,但官方文档主要描述了这三个值。下面是更详细的说明:
1. earliest
含义:当消费者组首次订阅一个主题(topic)或者某个分区(partition)没有已保存的偏移量时,消费者将从最早的可用消息开始读取。
适用场景:处理所有历史数据,包括以前产生的消息。
2. latest
含义:当消费者组首次订阅一个主题或某个分区没有已保存的偏移量时,消费者将只从最新的消息开始读取,即只会接收从它开始订阅之后新到达的消息。
适用场景:只关心实时数据流,并且不想处理任何过去的数据。
3. none
含义:如果消费者在启动时找不到之前的偏移量,它不会自动选择从头或尾开始读取消息,而是抛出异常 (OffsetOutOfRangeException)。这意味着用户必须明确指定要消费的具体偏移量。
适用场景:当你希望对偏移量有完全控制权,不希望 Kafka 自动生成偏移量策略时。这种设置可以防止意外地消费到不必要的旧消息或新消息。
注意!
默认值:auto.offset.reset 的默认值通常是 latest,这意味着如果没有明确指定的话,默认情况下消费者只会接收从它开始订阅之后新到达的消息。
已有偏移量的情况:如果消费者组已经有了之前保存的偏移量,那么 auto.offset.reset 的设置不会影响现有偏移量的行为;它只会在没有找到已保存偏移量的情况下生效。
幂等性和重复消费:选择 earliest 可能会导致重复消费已经处理过的消息,所以在设计应用逻辑时需要考虑如何处理重复消息的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号