(阿里训练营)flink——Stream Processing With Flink
一、并行处理和编程规范
1.并行计算
并行计算的核心思想:分而治之,将节点变成有向无环图,路径为Source Trans Sink
二、DataStream API
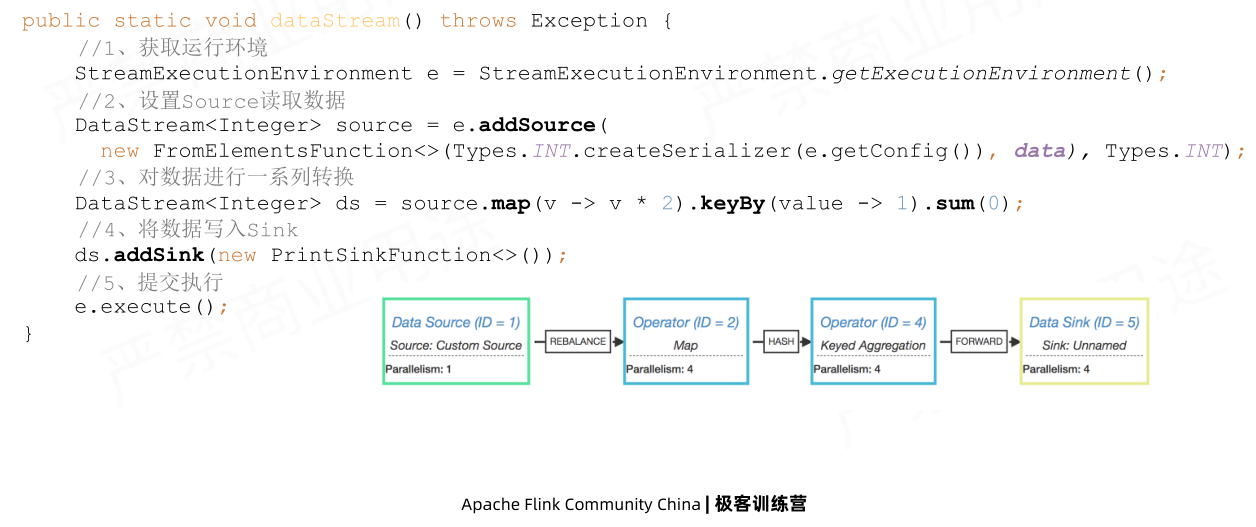
1.大致运行流程:

代码示例:
flink的source从哪里来?——flink连接器
更多的DataStream API,参考:https://blog.csdn.net/xyzkenan/article/details/103802762
三、核心特点:状态和时间
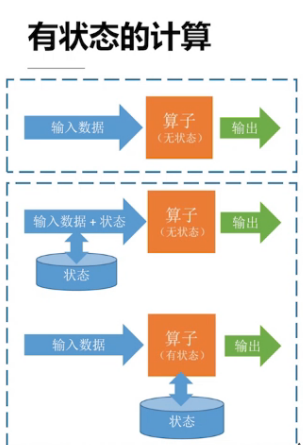
1.有状态的计算
有状态计算是指在程序计算过程中,在Flink程序内部存储计算产生的中间结果,并提供给后续Function或算子计算结果使用。状态数据可以维系在本地存储中,这里的存储可以是Flink的堆内存或者堆外内存,也可以借助第三方的存储介质,例如Flink中已经实现的RocksDB,当然用户也可以自己实现相应的缓存系统去存储状态信息,以完成更加复杂的计算逻辑。
2.flink状态原语
参考:https://blog.csdn.net/xorxos/article/details/80877266
3.flink中时间的概念
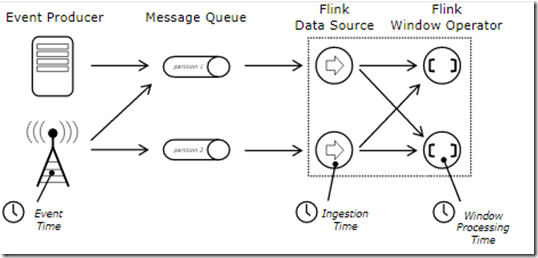
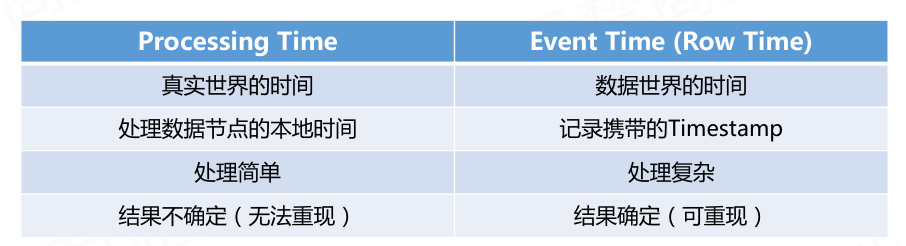
两种时间区别:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号