Greenplum/Deepgreen(集群/分布式)安装文档
Deepgreen分布式安装文档
环境准备
1、安装VMware虚拟机软件,然后在VMware安装三台Linux虚拟机(使用centos7版本)
2、使用的虚拟机如下:
192.168.136.155 mdw
192.168.136.156 sdw1
192.168.136.157 sdw2
2.1三台虚拟机分别修改主机名为:mdw/sdw1/sdw2
[root@localhost ~]# hostnamectl set-hostname mdw
2.2三台虚拟机分别添加主机名和ip对应关系
[root@sdw1 ~]# vi /etc/hosts
2.3三台虚拟机进行时间同步操作
[root@sdw1 ~]# yum install ntp
[root@sdw1 ~]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
[root@sdw1 ~]# ntpdate pool.ntp.org
[root@sdw1 ~]# systemctl start ntpd
[root@sdw1 ~]# systemctl enable ntpd
2.4三台虚拟机安装工具(可选)
[root@mdw ~]# yum install net-tools –y
[root@mdw ~]# yum install perl
2.5三台虚拟机关闭防火墙
[root@mdw ~]# systemctl stop firewalld
[root@mdw ~]# systemctl disable firewalld
2.6三台虚拟机修改selinux的值为disabled
[root@sdw1 ~]# vi /etc/selinux/config
2.7三台虚拟机修改关于linux系统推荐配置
[root@mdw ~]# vi /etc/sysctl.conf
kernel.shmmax = 2000000000
kernel.shmmni = 4096
kernel.shmall = 16000000000
kernel.sem = 1000 2048000 400 8192
xfs_mount_options = rw,noatime,inode64,allocsize=16m
kernel.sysrq = 1
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.msgmni = 2048
net.ipv4.tcp_syncookies = 1
net.ipv4.ip_forward = 0
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.conf.all.arp_filter = 1
net.ipv4.ip_local_port_range = 1025 65535
net.core.netdev_max_backlog = 10000
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
vm.overcommit_memory = 2
sysctl -p生效
2.8三台虚拟机更改文件限制
[root@mdw ~]# vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
2.9磁盘io调度算法有多种:CFQ,AS,deadline推荐deadline
[root@mdw ~]# grubby --update-kernel=ALL --args="elevator=deadline"
[root@mdw ~]#/sbin/blockdev --getra /dev/sda预读块默认大小为8192
[root@mdw ~]#/sbin/blockdev --setra 16384 /dev/sda设置预读块大小16G
上述完成之后,三台机器均需重启系统,然后再开始进入数据库安装操作
3、数据库安装
3.1数据库文件deepgreendb.16.32.rh6.x86_64.180912.bin下载并上传到mdw主机上
http://vitessedata.com/deepgreen-db https://www.centos.org/download/
mdw主机创建gpadmin用户
[root@mdw local]# useradd gpadmin
[root@mdw local]# passwd gpadmin
mdw主机赋权限解压bin文件
[root@mdw local]# chmod u+x ./deepgreendb.16.32.rh6.x86_64.180912.bin
[root@mdw local]# ./deepgreendb.16.32.rh6.x86_64.180912.bin
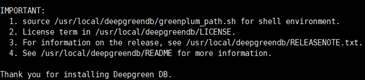
安装后的整体目录如下:
为gpadmin赋安装后的整体目录权限
[root@mdw deepgreendb]# chown -R gpadmin:gpadmin /usr/local/deepgreendb(软连接)
[root@mdw deepgreendb]# source /usr/local/deepgreendb/greenplum_path.sh
3.2创建一个文件:hostfile_exkeys
[root@mdw deepgreendb]# vi hostfile_exkeys
mdw
sdw1
sdw2
里面内容与etc/hosts节点的内容一样
3.3建立节点服务器间的信任
[root@mdw deepgreendb]# gpssh-exkeys -f hostfile_exkeys
按照提示输入root密码,记住这一步不能输入gpadmin的密码,因为批量安装时需要在/usr/local下创建目录,需要root权限
3.4批量安装
[root@mdw deepgreendb]# gpseginstall -f hostfile_exkeys -u gpadmin -p 123456
这一步其实就是将master上的greenplum打包通过scp命令传到hostfile_exkeys中的主机上,并赋予目录gpadmin的权限
20181031:11:31:26:011120 gpseginstall:mdw:root-[INFO]:-SUCCESS -- Requested commands completed
3.5检查批量安装情况
[root@mdw deepgreendb]# gpssh -f hostfile_exkeys -e ls -l $GPHOME

返回结果中各节点目录一致则代表批量安装成功
3.6上述步骤完成后,创建Master主数据的存储区域
[root@mdw deepgreendb]# mkdir -p /data/master
[root@mdw deepgreendb]# chown gpadmin:gpadmin /data/master
[root@mdw deepgreendb]# vi hostfile_gpssh_segonly
sdw1
sdw2
只含有segment节点
vi hostfile_gpssh_segonly这步主要是为了使用gpssh工具创建数据目录,单机安装一般手动
3.7创建segment主机上创建主数据和镜像数据目录并赋权限
[root@mdw deepgreendb]# source greenplum_path.sh
[root@mdw deepgreendb]# gpssh -f hostfile_gpssh_segonly -e 'mkdir -p /data1/primary'
[sdw1] mkdir -p /data1/primary
[sdw2] mkdir -p /data1/primary
[root@mdw deepgreendb]# gpssh -f hostfile_gpssh_segonly -e 'mkdir -p /data2/primary'
[sdw1] mkdir -p /data2/primary
[sdw2] mkdir -p /data2/primary
[root@mdw deepgreendb]# gpssh -f hostfile_gpssh_segonly -e 'mkdir -p /data2/mirror'
[sdw1] mkdir -p /data2/mirror
[sdw2] mkdir -p /data2/mirror
[root@mdw deepgreendb]# gpssh -f hostfile_gpssh_segonly -e 'mkdir -p /data1/mirror'
[sdw1] mkdir -p /data1/mirror
[sdw2] mkdir -p /data1/mirror
[root@mdw deepgreendb]# gpssh -f hostfile_gpssh_segonly -e 'chown -R gpadmin:gpadmin /data1'
[sdw1] chown -R gpadmin:gpadmin /data1
[sdw2] chown -R gpadmin:gpadmin /data1
[root@mdw deepgreendb]# gpssh -f hostfile_gpssh_segonly -e 'chown -R gpadmin:gpadmin /data2'
[sdw1] chown -R gpadmin:gpadmin /data2
[sdw2] chown -R gpadmin:gpadmin /data2
[root@mdw deepgreendb]#
3.8创建gp初始化文件
[root@mdw deepgreendb]# su - gpadmin
[gpadmin@mdw deepgreendb]$ vi hostfile_gpinitsystem
sdw1
sdw2
从安装软件的模板中拷贝一份gpinitsystem_config文件到当前目录:
[gpadmin@mdw deepgreendb]$ cp docs/cli_help/gpconfigs/gpinitsystem_config .
修改gpinitsystem_config设置segment个数
declare -a DATA_DIRECTORY=(/data1/primary /data2/primary)
[gpadmin@mdw deepgreendb]$ vi ~/.bashrc
source /usr/local/deepgreendb/greenplum_path.sh
export MASTER_DATA_DIRECTORY=/data/master/gpseg-1
export PGPORT=5432
export PGUSER=gpadmin
export PGDATABASE=test
[gpadmin@mdw deepgreendb]$ source ~/.bashrc
完成上述步骤运行初始化工具初始化数据库
[gpadmin@mdw deepgreendb]$ gpinitsystem -c gpinitsystem_config -h hostfile_gpinitsystem -B 8
注释:由于我是36个segement所以并行开的-B 8
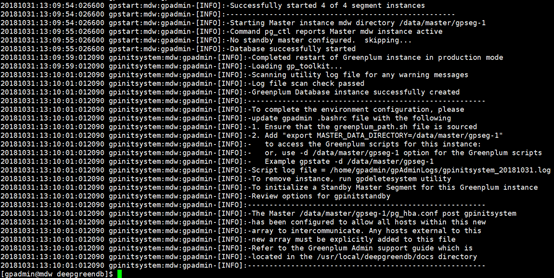
安装成功,进行操作即可!
[gpadmin@mdw deepgreendb]$ psql -d postgres
psql (8.2.15)
Type "help" for help.
postgres=#
也可以使用如下初始方式:
[gpadmin@mdw deepgreendb]$ gpinitsystem -c gpinitsystem_config -h hostfile_gpinitsystem -s sdw2 -S
会出错,因为没有足够的主机无法形成spread模式,去掉-S
由于选择sdw2为standby,需要在sdw2节点上创建文件夹
[root@sdw2 primary]# mkdir -p /data/master
[root@sdw2 primary]# chown gpadmin:gpadmin /data/master
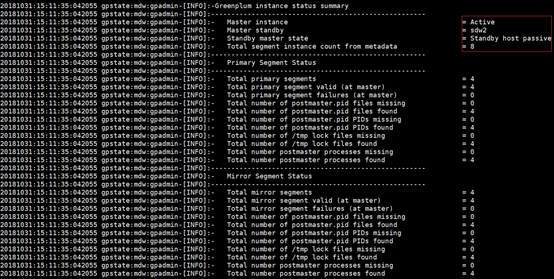
======================================================================
关于镜像,有2种方式开启Mirror:
1. 在GP数据库安装的时候,开启Mirror设置
gpinitsystem -c gpinitsystem_config -h hostfile_segonly -s smdw1 -S
-s 代表standby
-S代表spread模式
2. 在已建好的数据库中,使用命令gpaddmirrors和gpinitstandby来开启Mirror
=======================关于节点分布模式:grouped、spread==============================
1.greenplum的两种节点分布模式
①grouped mirror模式:
(grouped模式,主机的mirror节点全部放在下一个主机上)
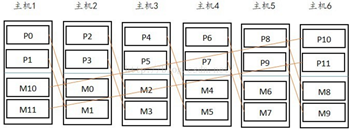
②spread mirror模式:
(spread模式,主机的第一个mirror在下个主机,第二个mirror在次下个主机,第三mirror在次次下个主机....)
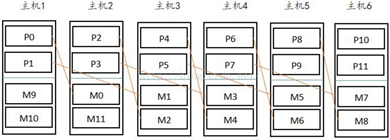
2.初始化的mirror模式:
1)初始化为grouped模式
在部署配置gp的过程中
执行初始化命令:gpinitsystem ,默认的节点分布方式为grouped
[gpadmin@master ~]$gpinitsystem -c gpinitsystem_config -h seg_hosts -s standby
2)在初始化时改为spread模式
在部署配置gp的过程中
执行初始化命令:gpinitsystem加上–S,节点分布方式为spread
[gpadmin@master ~]$gpinitsystem -c gpinitsystem_config -h seg_hosts -s standby –S
3)主机数量少的情况(无法改设spread)
假设segment主机为两台,节点数为2;执行初始化命令gpinitsystem加上–S是无法形成spread模式,并且会在执行初始化命令之后报错,原因由于主机个数没有比primary节点数大1。
3.对于两种模式,添加segment主机节点的情况:
(排除自行修改gpexpand_inputfile_xxxxx_xxxx文件的情况,可以自行添加主机或节点)
1)grouped模式
新增的主机数必须大于等于2,确保新增primary和mirror在不同的机器上。
2)spread模式
新增主机数至少比每台主机上的primary数大1,确保mirror平均分配在其他主机上(参照图例理解)。
4.两种模式的优缺:
①grouped mirror:
如果其中一台挂掉,那么拥有该主机mirror的机器负载加重一倍;在segment主机数非常多的情况下,至少允许两台主机挂掉
②spread mirror:
如果其中一台挂掉,那么拥有该主机mirror的机器负载均衡,没有grouped的压力大;在segment主机数非常多的情况下,只可以挂掉一台主机
(一般情况,greenplum同时死机两台概率很低,死机一台概率较高,建议spread)
==================================================================================
Rebalancing a Table重新平衡一张表
CREATE TABLE sales_temp (LIKE sales) DISTRIBUTED BY (date, total, customer);
INSERT INTO sales_temp SELECT * FROM sales;
DROP sales;
ALTER TABLE sales_temp RENAME TO sales;
============================================================================
https://yq.aliyun.com/articles/177
该链接是关于如何扩展segment的文档写的非常详细,个人也是根据此链接操作成功的。
扩容回滚
如果在扩容过程中,报错,需先启动GP master node,然后rollback再启动GP
gpstart -m
gpexpand –r –D dw
gpstart
==============================================================================
linux nmon的安装及使用:该软件可以监控linux系统
参考:https://blog.csdn.net/u010798968/article/details/74932124
1.下载nmon压缩包:
http://nmon.sourceforge.net/pmwiki.php?n=Site.Download
根据系统的发型版本及CPU位数选择相应的压缩包下载,如笔者的系统发行版本为:红帽子7.3.1611,64位:

所以选择的版本为:nmon16g_x86.tar.gz,
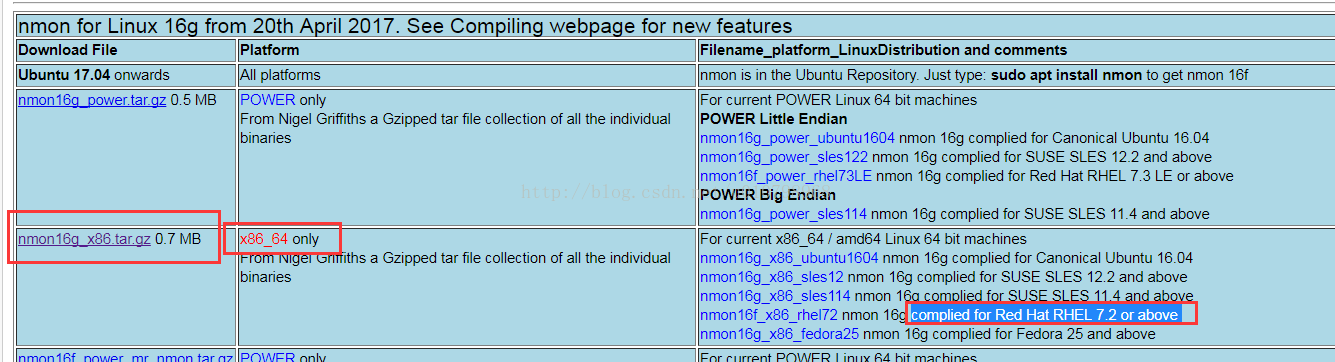
可以下载到本地,再ftp传到linux服务器上,也可以直接在linux服务器上wget 下载链接。
2.下载后解压缩,有适用于不同linux发行版本的文件,根据自身系统选择不同文件,这里笔者选择的是nmon16g_x86_rhel72:
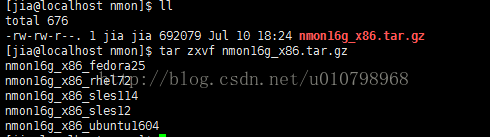
根据自身需求重命名及赋权,这里笔者重命名为nmon,赋755权限:

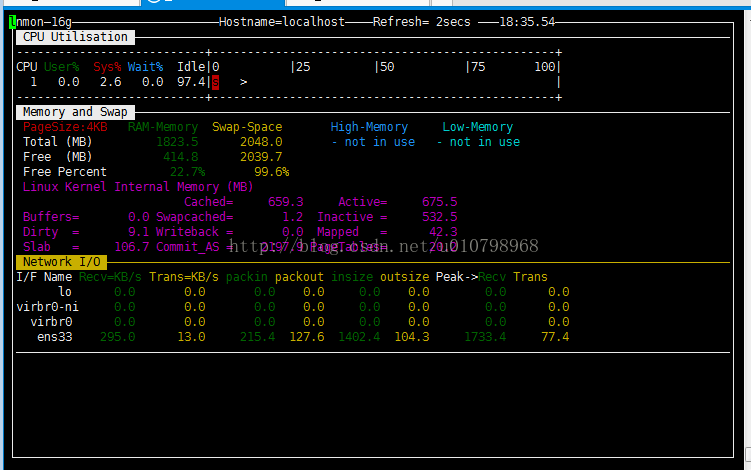
执行nmon:./nmon,进入nmon实时监控页,按c查看CPU使用信息,按m查看内存使用信息,按n查看网络使用信息,如下图:
更多命令按h查看帮助信息。
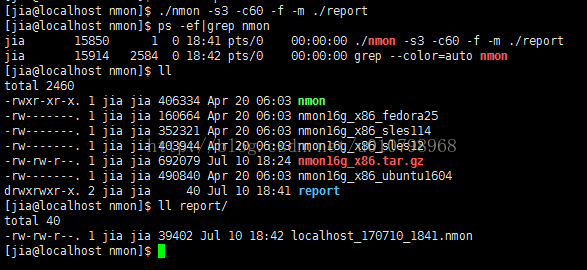
3.采集系统性能信息,并生成报告
a.执行./nmon -s3 -c60 -f -m ./report,-s3为每3s收集一次性能信息,-c60为收集60次,-f为生成的文件名包含该文件创建时间,-m ./report为指定测试报告存储路径,如下图:
执行完收集信息的命令后,生成了以hostname+创建年月+创建时间的文件,并且可以看到有个nmon的后台进程,即为收集服务器性能信息的进程,直到60次收集执行完之后,该进程才会结束。
b.下载 nmon analyser分析工具,该工具可以将上面生成的.nmon文件转化为图表,更为直观。
下载地址:https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/Power%20Systems/page/nmon_analyser
下载完解压可以看到有两个文件:
打开 nmon analyser v51_2.xlsm文件:

将linux服务器上的报告.nmon文件down下来,点击上图中的Analyze nmon data按钮,选择刚刚down下来的文件,生成可视化图表,如下图:

另外,如果有同学点击Analyze nmon data按钮后弹出“宏不可用”的提示,Excel可自行百度如何开启宏,wps个人版则需要下载一个插件,笔者放到了网盘里面:
http://pan.baidu.com/s/1o8iFk6m,可自行下载,下载之后解压,双击vba6chs.msi安装即可,安装好之后重启wps,即可正常使用宏,并生成可视化图表。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号