特征值与特征向量及其应用
大学学习线性代数的时候,特征值(eigenvalue)和特征向量(eigenvector)一直不甚理解,尽管课本上说特征值和特征向量在工程技术领域有着广泛的应用,但是除了知道怎么求解特征值和特征向量之外,对其包含的现实意义知之甚少。研究生之后学习统计学,在进行主成分分析过程中,需要求解变量的协方差矩阵的特征值和特征向量,并根据特征值的大小确定主成分,似乎知道了特征值和特征向量的一点点现实意义,但是本着考试为主的态度,没有深入进去理解特征值和特征向量。最近看机器学习的一些方法,如特征降维方法如SVD和PCA,线性判别法(Linear Discriminant Analysis,LDA)等方法的时候都涉及到特征值和特征向量,发现如果不深入理解特征值和特征向量,对这些方法的学习只能浮于表面,难以透彻理解。痛定思痛,决定由表及里好好的学习一下特征值和特征向量,本文的关于特征值和特征向量的理解和表述大量参考了网上的资料,仅作为本人学习笔记,谢绝转载。
一、特征值和特征向量的概念和计算
先看一下教科书上的定义:设A是n阶方阵,如果存在常数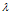 及非零n向量x,使得
及非零n向量x,使得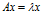 ,则称
,则称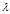 是矩阵A的特征值,x是A属于特征值
是矩阵A的特征值,x是A属于特征值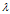 的特征向量。给定n阶矩阵A,行列式
的特征向量。给定n阶矩阵A,行列式
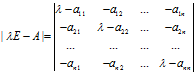
的结果是关于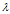 的一个多项式,成为矩阵A的特征多项式,该特征多项式构成的方程
的一个多项式,成为矩阵A的特征多项式,该特征多项式构成的方程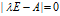 称为矩阵A的特征方程。
称为矩阵A的特征方程。
定理:n阶矩阵A的n个特征值就是其特征方程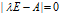 的n个跟
的n个跟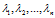 ;而A的属于特征值
;而A的属于特征值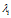 的特征向量就是其次线性方程
的特征向量就是其次线性方程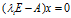 的非零解。
的非零解。
例:求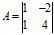 的特征根和特征向量
的特征根和特征向量
解: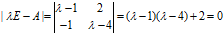 ,解一元二次方程可得
,解一元二次方程可得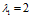 ,
,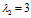 ;
;
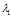 对应的特征向量为x满足
对应的特征向量为x满足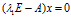 ,求得
,求得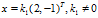
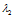 对应的特征向量为x满足
对应的特征向量为x满足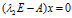 ,求得
,求得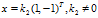
二、特征值和特征向量的几何意义
1、矩阵、向量、向量的矩阵变换
在进行特征和特征向量的几何意义解释之前,我们先回顾一下向量、矩阵、向量矩阵变换的等相关知识。
向量有行向量和列向量,向量在几何上被解释成一系列与轴平行的位移,一般说来,任意向量v都能写成"扩展"形式:
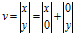
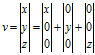
以3维向量为例,定义p、q、r为指向+x,+y和+z方向的单位向量,则有v=xp+yq+zr。现在向量v就被表示成p、q、r的线性变换了。这里的基向量是笛卡尔积坐标轴,但事实上这个一个坐标系可以由任意的3个基向量定义,只要这3个基向量线性无关就行(不在同一平面上)。因此,用一个矩阵乘以向量,如Ax,表述如下:
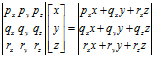
如果把矩阵的行解释为坐标系的基向量,矩阵与向量相乘(或向量与矩阵相乘)相当于执行一次坐标转换,Ax=y可表述为x经矩阵A变换后变为y。因此,追溯矩阵的由来,与向量的关系,我们会觉得矩阵并不神秘,它只是用一种紧凑的方式来表达坐标转换所需的数学运算。
2、矩阵的特征值和特征向量
矩阵A的特征值和特征向量分别为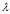 和x,记为
和x,记为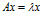 ,该式子可理解为向量x在几何空间中经过矩阵A的变换后得到向量
,该式子可理解为向量x在几何空间中经过矩阵A的变换后得到向量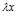 。由此可知,向量x经过矩阵A变换后,方向并无改变(反方向不算方向改变),只是伸缩了
。由此可知,向量x经过矩阵A变换后,方向并无改变(反方向不算方向改变),只是伸缩了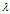 倍。
倍。
以矩阵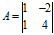 为例,其特征向值分别为
为例,其特征向值分别为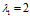 ,
,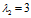 ,对应的特征向量为
,对应的特征向量为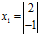 ,
,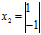 ,那么
,那么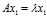 (
(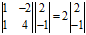 )表示向量
)表示向量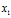 经过矩阵A变换后,得到
经过矩阵A变换后,得到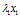 ,向量变换变为改变
,向量变换变为改变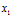 方向,知识将
方向,知识将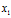 在原方向上扩充了2倍。特征值
在原方向上扩充了2倍。特征值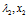 也是同样道理,经过矩阵A变换后特征向量
也是同样道理,经过矩阵A变换后特征向量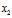 在原方向上扩充了3倍。
在原方向上扩充了3倍。
因此,将特征向量看成基向量,矩阵就是这些基向量向对应的特征值伸展所需的数学运算。给定一个矩阵,就可以找出对应的基(特征向量),及透过向量变换(矩阵),这些基的伸展(特征值)。
三、特征值和特征向量的应用实例
1、主成分分析(Principle Component Analysis, PCA)
(1)方差、协方差、相关系数、协方差矩阵
方差: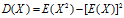
协方差: 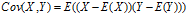 ,
, 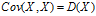 ,
, 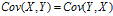
**方差是衡量单变量的离散程度,协方差是衡量两个变量的相关程度(亲疏),协方差越大表明两个变量越相似(亲密),协方差越小表明两个变量之间相互独立的程度越大。
相关系数: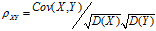 ,
,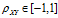
**协方差和相关系数都可以衡量两个表明的相关程度,协方差未消除量纲,不同变量之间的协方差大小不能直接比较,而相关系数消除了量纲,可以比较不同变量之间的相关程度。
协方差矩阵:如果有两个变量X,Y,那么协方差矩阵为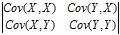 ,协方差阵说明了样本中变量间的亲疏关系。
,协方差阵说明了样本中变量间的亲疏关系。
(2)主成分分析的思想和算法
主成分分析是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。它是一个线性变换,这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。
假设用p个变量来描述研究对象,分别用X1,X2…Xp来表示,这p个变量构成的p维随机向量为X=(X1,X2…Xp),n个样本构成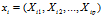 组成了n行p列的矩阵A。主成分求解过程如下:
组成了n行p列的矩阵A。主成分求解过程如下:
第一步,求解得到矩阵A的协方差阵B;
第二步,求解协方差阵B,得到按大小顺序排列的特征值向量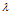 ,
,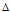 为特征值向量
为特征值向量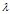 中每个特征值组成的对角矩阵,U为所有特征值对应的特征向量构成的矩阵U,因此有
中每个特征值组成的对角矩阵,U为所有特征值对应的特征向量构成的矩阵U,因此有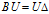 。重点来了,U是有特征向量构成的正定阵,向量的每一行可以视为一个的基向量,这些基向量经过矩阵B转换后,得到了在各个基向量上的伸缩,伸缩的大小即为特征向量。
。重点来了,U是有特征向量构成的正定阵,向量的每一行可以视为一个的基向量,这些基向量经过矩阵B转换后,得到了在各个基向量上的伸缩,伸缩的大小即为特征向量。
第三步,主成分个数选择,根据特征值的大小,将特征值较大的作为主成分,其对应的特征向量就为基向量,特征值的筛选根据实际情况而定,一般大于1即可考虑作为主成分。
(3)实例分析——机器学习中的分类问题
机器学习中的分类问题,给出178个葡萄酒样本,每个样本含有13个参数,比如酒精度、酸度、镁含量等,这些样本属于3个不同种类的葡萄酒。任务是提取3种葡萄酒的特征,以便下一次给出一个新的葡萄酒样本的时候,能根据已有数据判断出新样本是哪一种葡萄酒。
问题详细描述:http://archive.ics.uci.edu/ml/datasets/Wine
训练样本数据:http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
把数据集赋给一个178行13列的矩阵R,它的协方差矩阵C是13行13列的矩阵,对C进行特征分解,对角化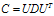 ,其中U是特征向量组成的矩阵,D是特征之组成的对角矩阵,并按由大到小排列。然后,令
,其中U是特征向量组成的矩阵,D是特征之组成的对角矩阵,并按由大到小排列。然后,令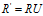 ,就实现了数据集在特征向量这组正交基上的投影。嗯,重点来了,
,就实现了数据集在特征向量这组正交基上的投影。嗯,重点来了,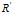 中的数据列是按照对应特征值的大小排列的,后面的列对应小特征值,去掉以后对整个数据集的影响比较小。比如,现在我们直接去掉后面的7列,只保留前6列,就完成了降维。
中的数据列是按照对应特征值的大小排列的,后面的列对应小特征值,去掉以后对整个数据集的影响比较小。比如,现在我们直接去掉后面的7列,只保留前6列,就完成了降维。
下面我们看一下降维前和降维后的使用svm分类结果,本部分采用实现SVM的R语言包e1071,代码如下表所示。分类结果显示,使用主成分分析后的样本和未进行主成分分析样本的分类结果一样。因此,主成分分析提取的6个主成分能较好的表达原样本的13个变量。
library("e1071") #读取数据 wineData=read.table("E:\\research in progress\\百度云同步盘\\blog\\特征值和特征向量\\data.csv",header=T,sep=","); #计算协方差阵 covariance = cov(wineData[2:14]) #计算特征值和特征向量 eigenResult=eigen(covariance) #选取6个主成分,并计算这6个主成分解释的方差总和 PC_NUM = 6 varSum=sum(eigenResult$values[1:PC_NUM])/sum(eigenResult$values) #降维后的样本 ruduceData= data.matrix(wineData[2:14])%*%eigenResult$vectors[,1:PC_NUM] #加入分类标签 #finalData=cbind(wineData$class,ruduceData) #给finalData添加列名 #colnames(finalDat) =c("calss","pc1","pc2","pc3","pc4","pc5","pc6") #训练样本--主成分分析后的样本作为训练样本 y=wineData$class; x1=ruduceData; model1 <- svm(x1, y,cross=10) pred1 <- predict(model1, x1) #pred1 <- fitted(model1) table(pred1, y) #使用table来查看预测结果 #训练样本--原数据作为训练样本 x2=wineData[2:14] model2 <- svm(x2, y,cross=10) #pred2 <- predict(model2, x2) pred2 <- fitted(model2) table(pred2, y) #使用table来查看预测结果
posted on 2014-07-14 17:01 Jiahua Jin 阅读(24710) 评论(2) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号