
RabbitMQ 延时消息设计
问题背景
- 所谓"延时消息"是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
- 场景一:客户A在十二点下了一个订单,我想半个小时后来检查一下这个订单的付款状态,根据付款状态来作下一步的处理。 a. 针对场景一,建议采用方案数据库保存+schedule的方式也许更合适。
- 场景二:mdc系统更新了一个A信息,我要通知给A门店信息发生了变化,通知他们回调API来读取最新的值。
如果拿到消息后立即回调,可能因为mdc事务、缓存、从库延迟等原因,拿到变化前的信息,所以mdc希望能延迟一段时间再来消费此消息。
目标
- 可以实现消息按照自定义的时间延迟发送。
- 最好做到对消息生产者和消费者透明,不修改现有应用程序。
总体方案
3.1. 实现原理
- AMQP和RabbitMQ本身没有直接支持延迟队列功能,但是可以通过以下特性模拟出延迟队列的功能。
- RabbitMQ可以针对Queue和Message设置 x-message-ttl,来控制消息的生存时间,如果超时,则消息变为dead letter
- RabbitMQ的Queue可以配置x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了dead letter,则按照这两个参数重新路由。
结合以上两个特性,就可以模拟出延迟消息的功能
参考资料:
- https://www.cloudamqp.com/docs/delayed-messages.html
- http://www.rabbitmq.com/ttl.html
- http://www.rabbitmq.com/dlx.html
- http://www.rabbitmq.com/maxlength.html
3.2. 技术方案
|
|
方案一:针对Queue设置延迟时间 |
方案二:针对Message设置延迟时间 |
|
|
|
|
|
|
|
方案关键点 |
针对需要延迟的Queue配置ttl参数 |
针对Queue设置最大延迟时间 |
|
|
|
1. 优点: |
发送方对每个Message设置有效延迟时间 |
|
|
|
a. 维护简单 |
|
|
|
|
b. 客户端完全透明 |
1. 优点 |
|
|
|
c. 针对每个延迟时间建立一个延迟队 |
a. 发送时可以自定义延迟时间 |
|
|
|
列 |
2. 缺点 |
|
|
|
2. 缺点: |
a. 需要升级客户端,对客户端不透明 |
|
|
|
a. 发送方无法自定义延迟时间 |
b. 需要针对每个队列建立不同的延迟 |
|
|
|
b. 延迟时间在建Queue时确定,修改 |
队列 |
|
|
|
不便 |
c. 带延迟参数的send方法容易误用, |
|
|
|
c. 修改延迟时间需要在MQ集群重新进 |
很难发现 |
|
|
|
行配置 |
|
|
|
选择结果 |
最终选择了方案一 |
|
|
3.3. 消息发送流程
3.3.1. 原有业务流程

3.3.2. 自产自消的延迟消息流程

3.3.3. 普通的延迟消息流程
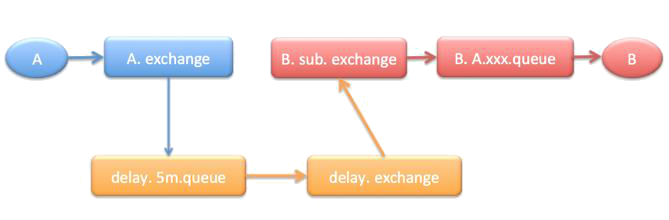
4. 操作步骤
4.1. 建立 delay.exchange
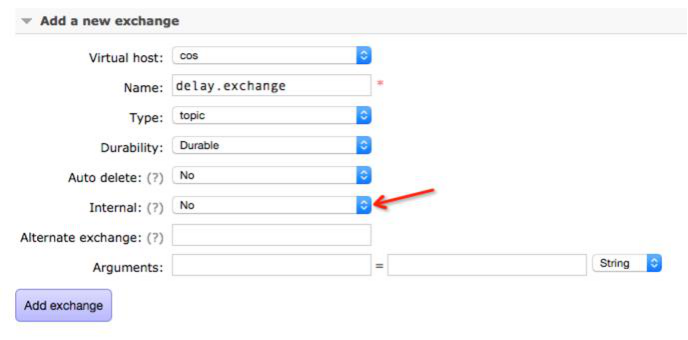
注意事项:
1. 不要设置为Internal,否则将无法接受dead letter
4.2. 建立延时队列(delay queue)
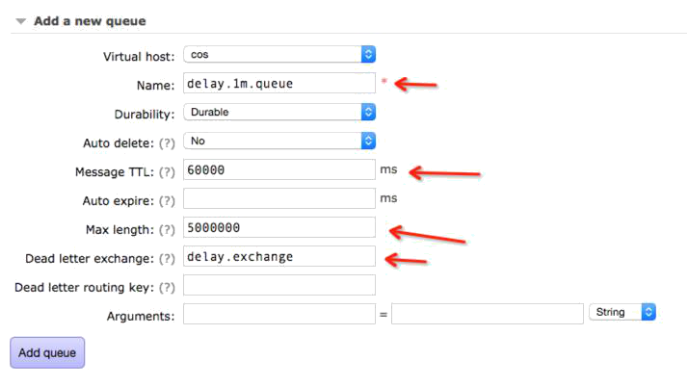
注意事项:
- 按照延期时间配置queue的名字,建议命名规则为delay.{time}.queue,使用delay前缀方便排序和做一些权限控制
- cos线上集群默认配置了delay.1m.queue、delay.5m.queue、delay.15m.queue三个队列
- 通过TTL设置队列的延期时间,对应不同的Queue
- MAX length为最大的积压的消息个数,推荐设置为100w~500w之间,推测方法见积压测试结果,
- 超过MAX length限制以后,队列头部的消息会立即转到delay.exchange进行投递,不会造成消息丢失
- 设置dead letter exchange为刚才配置的 delay.exchange
注意不要配置"dead letter routing key"否则会覆盖掉消息发送时携带的routingkey,导致后面无法路由
4.3. 配置延时路由规则
4.3.1. 需要延时的消息到exchange后先路由到指定的延时队列

4.3.2. delay.exchange 再重新把消息路由到正常的queue或exchang中
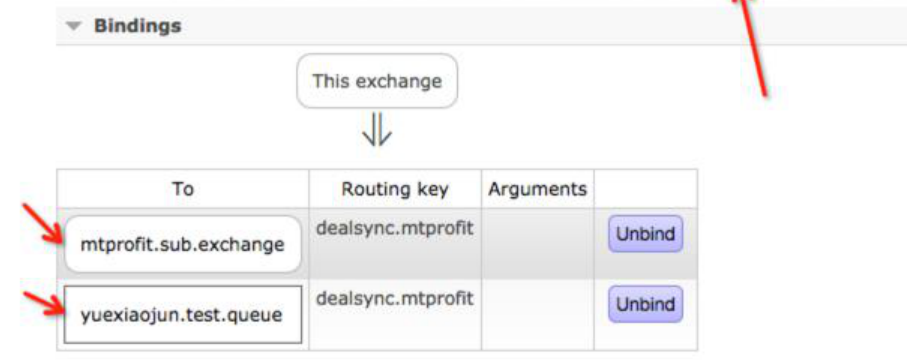
4.3.3. 消费者和以前一样从正常queue中接收消费消息
5. 积压消息测试结果
5.1. 积压测试结论
从实现原理上看,对于持久化消息,内存主要保存的是消息的索引数据,从测试结果也可以验证,可以得出以下数据:
- 内存占用方面估算
- 消息占用内存的大小确实和消息体本身大小无关,和消息个数直接相关。
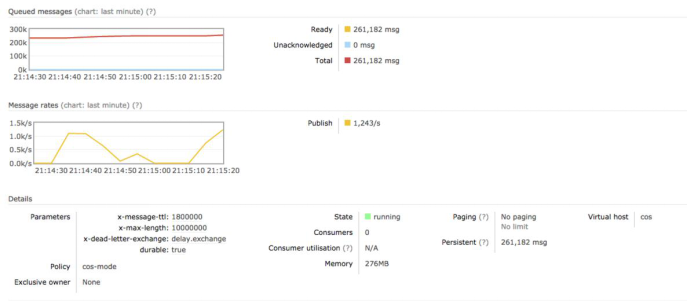
- 消息体为40字节的字符串,积压10万消息,占用101MB内存,23万消息,占用230MB内存
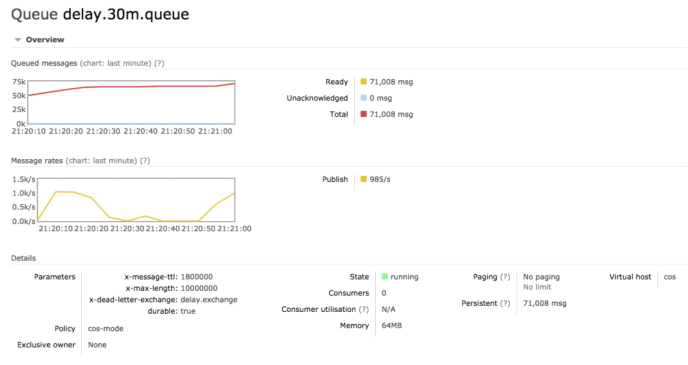
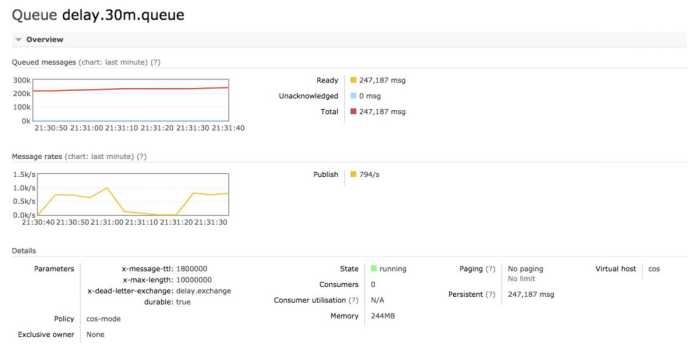
- 消息体为一个整数,积压7万消息,占用64MB内存,24万消息,占用240MB内存
- 一个消息约占1KB的内存,以10GB内存,留一半余量:5GB/1K=500 0000
- 线上单个queue推荐线上的max length不要超过500万,根据延迟时间和消息量来调整此值的大小。
- 消息占用内存的大小确实和消息体本身大小无关,和消息个数直接相关。
- 消息量估算
- 以30分钟延迟,每秒发送1000个消息为例,则最大值为:30*60*1000=180 0000
- 倒推:以500万,30分钟延迟为例,则每秒最多发送的消息个数为:5000000/30/60=2777
- 消息积压数超过max length以后,消息不会丢失,只会导致消息会被提前消费。
结论:1. MAX length推荐这个值设置为100万~500万,既可以满足业务需求,又不超过内存限制
5.2. 40字节消息积压26万
5.3. 4字节消息积压7万
5.4. 4字节消息积压24万
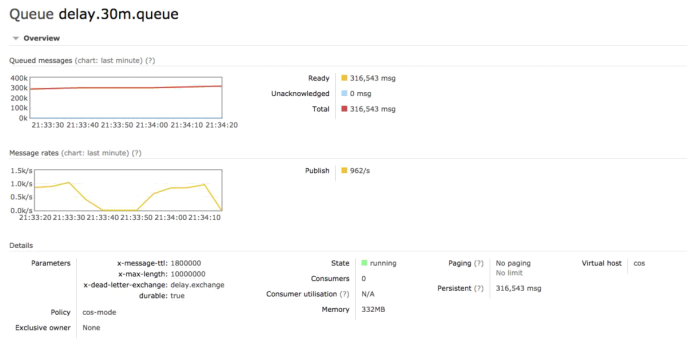
5.5. 4字节消息积压31万
5.6. 4字节消息积压64万
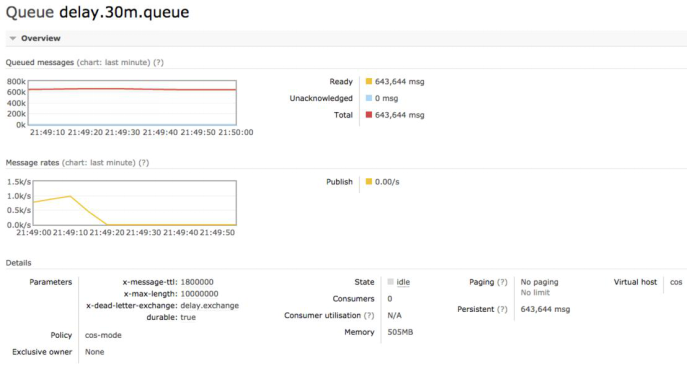
总结:经过压测及基础配置,延时消息可以满足目前的需求,实现消息的延迟处理。
不知道延迟队列加上惰性队列的组合,即可以减小内存占用,又可以实现消息的延迟处理,也是一个非常好的方案。蛋糕和咖啡真的很配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号