为什么 Mysql 用 B + 树做索引而不用 B 树或红黑树
为什么 Mysql 用 B + 树做索引而不用 B 树或红黑树
B + 树只有叶节点存放数据,其余节点用来索引,而 B -树是每个索引节点都会有 Data 域。所以从 Mysql(Inoodb)的角度来看,B + 树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。
那么 Mysql 如何衡量查询效率呢?– 磁盘 IO 次数。 B - 树 / B + 树 的特点就是每层节点数目非常多,层数很少,目的就是为了就少磁盘 IO 次数,但是 B - 树的每个节点都有 data 域(指针),这无疑增大了节点大小,说白了增加了磁盘 IO 次数(磁盘 IO 一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO 次数增多,一次 IO 多耗时),而 B + 树除了叶子节点其它节点并不存储数据,节点小,磁盘 IO 次数就少。这是优点之一。
另一个优点是: B + 树所有的 Data 域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。在数据库中基于范围的查询是非常频繁的,而 B 树不支持这样的遍历操作。
B 树相对于红黑树的区别
AVL 树和红黑树基本都是存储在内存中才会使用的数据结构。在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘 IO 读写过于频繁,进而导致效率低下的情况。为什么会出现这样的情况,我们知道要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘 IO 代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘 IO 频繁读写。根据磁盘查找存取的次数往往由树的高度所决定,所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B 树可以有多个子女,从几十到上千,可以降低树的高度。
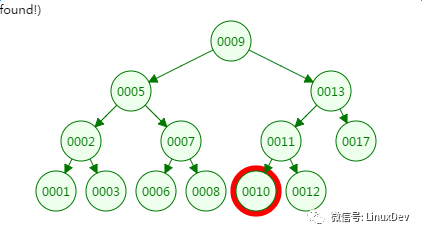
我们先来看二叉树查找时磁盘IO的次:定义一个树高为4的二叉树,查找值为10:
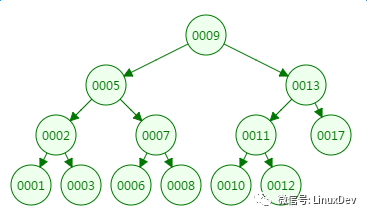
第一次磁盘IO:
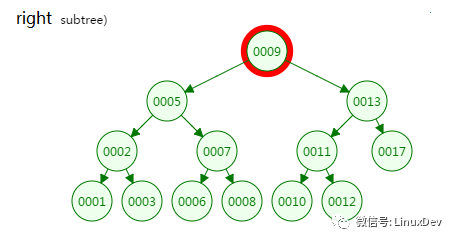
第二次磁盘IO
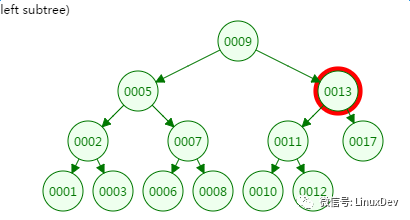
第三次磁盘IO:
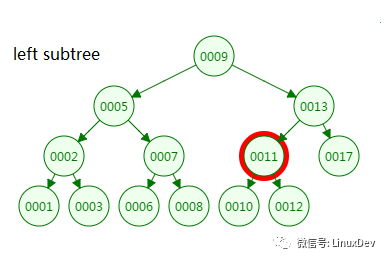
第四次磁盘IO:
而对于B树:
如下有一个3阶的B树,观察查找元素21的过程:
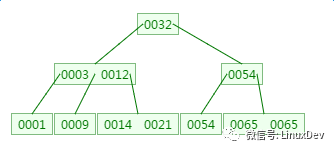
第一次磁盘IO:
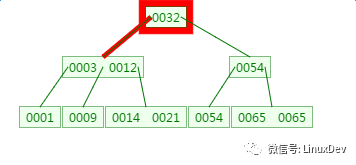
第二次磁盘IO:
这里有一次内存比对:分别跟3与12比对
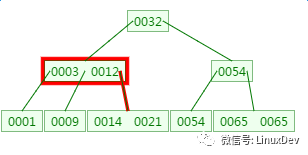
第三次磁盘IO:
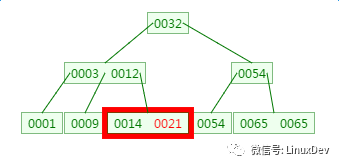
这里有一次内存比对,分别跟14与21比对
从查找过程中发现,B树的比对次数和磁盘IO的次数与二叉树相差不了多少,所以这样看来并没有什么优势。
但是仔细一看会发现,比对是在内存中完成中,不涉及到磁盘IO,耗时可以忽略不计。另外B树中一个节点中可以存放很多的key(个数由树阶决定)。
相同数量的key在B树中生成的节点要远远少于二叉树中的节点,相差的节点数量就等同于磁盘IO的次数。这样到达一定数量后,性能的差异就显现出来了。
数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次 I/O 就可以完全载入。为了达到这个目的,在实际实现 B-Tree 还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个 node 只需一次 I/O。
好的,我总结一下:
- 使用B+树而不是B数的原因
- B+树节点大小更小,一次IO读入的节点数更多
- B+树的数据都在叶子节点中,遍历和区间访问性能大幅提高
- B+树查询效率稳定
- 使用B+树而不是AVL树、红黑树的原因
- B+树的树高比AVL树、红黑树低,IO次数少

 浙公网安备 33010602011771号
浙公网安备 33010602011771号