

centos7下MHA+keepalived高可用集群环境搭建
未经允许不得转载
一、安装前准备
1、设置DNS及配置静态IP
(1)如果是用vmware创建的虚拟机,想配置静态IP的话,需要注意IP要和VMnet8在同一网段
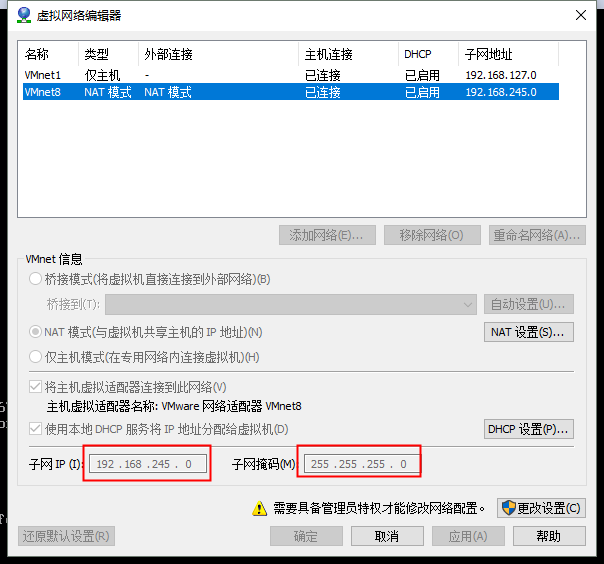
(2)编辑/etc/sysconfig/network-scripts/ifc-xxxx(网卡名称),可用ip addr看到网卡名称
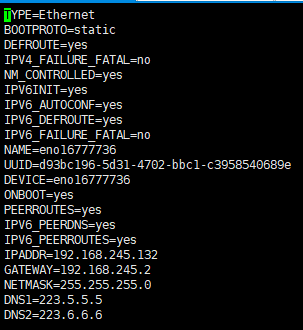
然后systemctl restart network
2、关闭selinux,防火墙放行mariadb端口
systemctl start firewalld
systemctl enable firewalld
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --reload
setenforce 0
3、各节点时间同步(HA集群的前提)
各节点上执行:
yum install -y ntp #``安装ntp服务器
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime #``时区设置为中国上海时区
hwclock -w #``用系统时间同步硬件时间
二、 安装MariaDB
1 、安装MariaDB
yum install -y mariadb*
2、启动MariaDB
systemctl start mariadb.service
systemctl enable mariadb.service
3、设置MariaDB
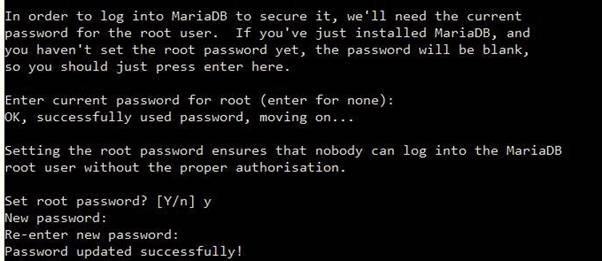
执行命令:mysql_secure_installation,先敲回车,会首先提示root用户设置密码,选Y,然后设置密码。接着会有多次询问,如果没有特殊要求一律选Y就可以,
使用命令登陆测试:mysql -u root -p,然后输入自己设定的密码。
三、配置MariaDB主从复制
背景:主数据库在192.168.245.132,从数据库在192.168.245.128和192.168.245.129上
1、主节点下操作步骤
(1)vim /etc/my.cnf,在[mysqld]字段下添加:
server-id = 1 #``复制集群中的各节点的id均必须唯一;
log-bin = master-log #``开启二进制日志,因为每一台slave都可能会变成master;
relay-log = relay-log #``开启中继日志;
skip_name_resolve = ON #``不进行域名解析
(2)systemctl restart mariadb
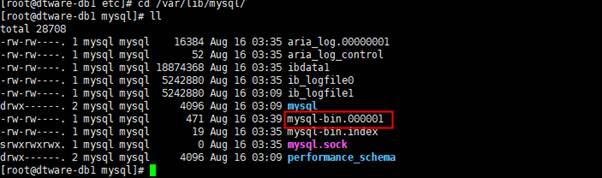
可以看到在mariadb的默认数据存放路径(/var/lib/mysql)下有该binlog日志``
(3)登录mariadb:mysql -u root -p
(4)主服务器上授权一个有所有权限的账号,用于复制,to:将权限授予哪个用户。格式:”用户名”@”登录IP或域名”。 %表示没有限制,在任何主机都可以登录
grant replication slave on *.* to 'cpuser'@'192.168.245.%' identified by 'cppass';
FLUSH PRIVILEGES;
2、从节点操作步骤
从节点1下:
(1) ``vim /etc/my.cnf``,在[mysqld]字段下添加:
server-id = 2 #``复制集群中的各节点的id均必须唯一;
relay-log = relay-log #``开启中继日志;
log-bin = master-log #``开启二进制日志,因为每台slave都可能会变成master;
read_only = ON #``开启只读权限;
relay_log_purge = 0 #``是否自动清空不再需要的中继日志;
skip_name_resolve = ON #``不进行域名解析
从节点2下
(2) ``vim /etc/my.cnf``,在[mysqld]字段下添加:
server-id = 3 #``复制集群中的各节点的id均必须唯一;
relay-log = relay-log #``开启中继日志;
log-bin = master-log #``开启二进制日志,因为每台slave都可能会变成master;
read_only = ON #``开启只读权限;
relay_log_purge = 0 #``是否自动清空不再需要的中继日志;
skip_name_resolve = ON #``不进行域名解析
(3)所有从节点执行:systemctl restart mariadb
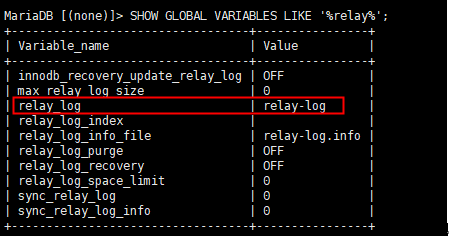
(4)所有从节点登录数据库`,`查看中继日志是否是启动状态
SHOW GLOBAL VARIABLES LIKE '%relay%';
(5)配置主从复制参数
主数据库上执行SHOW MASTER STATUS;

从数据库上:
CHANGE MASTER TO
MASTER_HOST='192.168.245.132',MASTER_USER='cpuser',MASTER_PASSWORD='cppass',MASTER_LOG_FILE='master-log.000002',MASTER_LOG_POS=486;
START SLAVE;
SHOW SLAVE STATUS\G

注释:
MASTER_HOST='192.168.245.132' --``主服务器的IP地址
MASTER_USER='cpuser' --``主服务器上授权复制的用户名
MASTER_PASSWORD='cppass' --``主服务器上授权用名的密码
MASTER_LOG_FILE=' master-log.000002 ' --``主服务器上的日志文件
MASTER_LOG_POS=486 --``主服务器上日志文件的位置
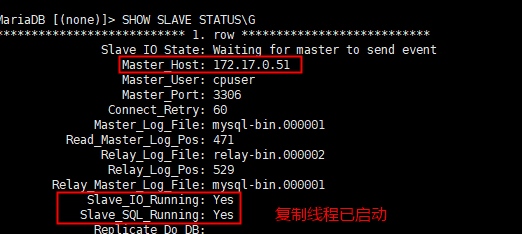
如果Slave_IO_Running的状态是connecting,则等待几秒钟再查看是否变为Yes
(6)测试:在主服务器上建立、删除数据库,可以看到从服务器上立刻同步了
注意:从数据库理论上是只读的,不要在从数据库上执行查询以外的任何操作(如增删操作),否则会导致数据库异常。
四、keepalived安装配置
1、安装keepalived(所有节点)
yum install -y keepalived
2、配置keepalived(所有节点)
(1)主数据库节点上配置keepalived
vi /etc/keepalived/keepalived.conf
global_defs {
notification_email { ######定义接受邮件的邮箱
wangjj@hrloo.com
}
notification_email_from jiankong@staff.tuge.com ######定义发送邮件的邮箱
smtp_server mail.tuge.com
smtp_connect_timeout 10
}
vrrp_instance vrrptest { ######定义vrrptest实例
state BACKUP ######服务器状态
interface eno16777736 ######使用的接口
virtual_router_id 51 ######虚拟路由的标志,一组lvs的虚拟路由标识必须相同,这样才能切换
priority 100 ######服务启动优先级,值越大,优先级越高,BACKUP 不能大于MASTER
advert_int 1 ######服务器之间的存活检查时间
nopreempt
authentication {
auth_type PASS ######认证类型
auth_pass 1111 ######认证密码,一组lvs 服务器的认证密码必须一致
}
virtual_ipaddress { ######虚拟IP地址
192.168.245.150
}
}
(2)两台从节点配置大致和上面相同,只需要改动:
①:priority(优先级),从节点的优先级需要低于主节点,并且所有节点的优先级不能相同。
②:interface(网卡名称),每个节点都需要执行ip addr去查看自己的网卡名称。
③在keepalived中2种模式,分别是master->backup模式和backup->backup模式。
在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来。
在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。
为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
backup->backup模式配置方法:keepalived配置文件里改动2个地方:
3、所有节点的防火墙上放行VRRP协议(解决脑裂问题)
(1)firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface eno16777736 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
(2)firewall-cmd --reload
注释:
①interface后面接的参数是每个节点各自的网卡名
②VRRP是一种可以实现IP地址漂移的容错协议,主备节点轮流在对外发布vrrp通告(vrrp官方的通告地址为224.0.0.18),理论上备节点如果收到主节点的通告,通告中优先级高于自己,就不会主动对外发送通告;
③firewalld若不允许vrrp或者组播流量,则备节点收不到主节点的通告,认为主节点故障,切换状态,发布VIP,从而导致主备节点都有VIP,即发生了所谓的脑裂现象。
4、启动keepalived(先在master上启动,再在从节点上启动)
systemctl start keepalived
systemctl enable keepalived
5、验证keepalived是否生效
(1)关闭主节点上的keepalived服务
systemctl stop keepalived
systemctl status keepalived
(2)在每台从节点上执行ip addr,看VIP是否漂移到优先级第二高的节点上了
(3)手动启动原主节点上的keepalived服务
systemctl start keepalived
systemctl status keepalived
五、MHA安装配置
注意:由于是数据库的MHA,因此虚拟机不需要公网,要练手的话可以本地创建足够数量的虚拟机。
本次实验环境:
node1:MariaDB master 192.168.245.132
node2:MariaDB slave1 192.168.245.128
node3:MariaDB slave2、MHA Manager 192.168.245.129
1、权限设置
(1)在所有节点授权拥有管理(监控)权限的用户,可远程访问其他节点。
此时仅需要在****master****节点运行类似如下****SQL****语句即可**:
GRANT ALL PRIVILEGES ON *.* TO 'mhaadmin'@'192.168.245.%' IDENTIFIED BY 'mhapass';
FLUSH PRIVILEGES;
(3) 在所有节点授权拥有复制权限的用户,
此时仅需要在****master****节点运行类似如下****SQL****语句即可**:
登录数据库,然后
grant replication slave on *.* to 'cpuser'@'192.168.245.%' identified by 'cppass';
FLUSH PRIVILEGES;
因为这个架构,任何一个从节点,将有可能成为主节点,所以slave节点也需要创建账号;
2、master节点与node节点之间互信认证
在所有节点上执行如下操作
(1)ssh-keygen (然后一直回车)
(2)ssh-copy-id -i /root/.ssh/id_rsa.pub [root@192.168.245.132](mailto:root@192.168.245.132)
ssh-copy-id -i /root/.ssh/id_rsa.pub [root@192.168.245.128](mailto:root@192.168.245.128)
ssh-copy-id -i /root/.ssh/id_rsa.pub [root@192.168.245.129
在任一节点上测试ssh别的节点,看是否是免密码登录的。
3、在所有的节点安装MHA node:
(1)在所有的节点上yum install epel-release #安装完这个以后基本常用的rpm都可以找到
(2)访问官网下载MHA node和MHA Manager安装包(需要FQ):
https://code.google.com/p/mysql-master-ha/wiki/Downloads?tm=2
(3)把4个包放到所有节点中(可通过rz命令),然后进入该tar包所在目录:
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
yum install -y perl-DBD-MySQL perl-devel perl-CPAN
tar xf mha4mysql-node-0.56.tar.gz
cd mha4mysql-node-0.56
perl Makefile.PL
make && make install
(4)在manager节点上安装MHA manager
yum install -y perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes #安装依赖关系
进入manager的rpm包所在目录,
然后
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
4、配置MHA(在manager节点上操作)(在软件包解压后的目录里面有样例配置文件)
(1)在manager主机上,进入mha4mysql-manager压缩包所在目录,执行:
tar xzf mha4mysql-manager-0.56.tar.gz
mkdir -p /etc/mha_master
cp mha4mysql-manager-0.56/samples/conf/app1.cnf /etc/mha_master
(2)修改app1.cnf配置文件,
vi /etc/mha_master/app1.cnf
全部文件内容如下(其中的注释需要去掉,不然后面检查SSH配置会报错):
[server default]
user=mhaadmin #mha管理用户
password=mhapass #mha管理用户密码
manager_workdir= /etc/mha_master/app1 #manager的工作目录
manager_log= /etc/mha_master/manager.log #manager的日志文件
master_ip_failover_script= /usr/bin/master_ip_failover #设置自动failover时候的切换脚本路径
remote_workdir= /mydata/mha_master/app1
\#每个远程主机的工作目录
ssh_user=root #基于ssh的密钥认证
repl_user=cpuser #设置复制环境中的复制用户名
repl_password=cppass #设置复制用户的密码
ping_interval=1 #ping间隔时长单位是秒,尝试三次没有回应则自动进行故障切换
[server1] #server1默认是主节点
hostname=192.168.245.132
candidate_master=1
[server2]
hostname=192.168.245.128
candidate_master=1
[server3]
hostname=192.168.245.129
candidate_master=1
5、配置MHA与keepalived联动脚本(在manager节点操作)
vim /usr/bin/master_ip_failover
\#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '192.168.245.150';
my $ssh_start_vip ="systemctl start keepalived";
my $ssh_stop_vip ="systemctl stop keepalived";
GetOptions(
'command=s' =>\$command,
'ssh_user=s' =>\$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' =>\$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' =>\$new_master_host,
'new_master_ip=s' =>\$new_master_ip,
'new_master_port=i' =>\$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPTTEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
\# A simple system call that disable the VIPon the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status--orig_master_host=host --orig_master_ip=ip --orig_master_port=port--new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
注意:
①MHA的包里有master_ip_failover脚本模板,可通过
find / -name master_ip_failover找到路径
②同模板相比,最终脚本在不同的位置总共多了以下内容:
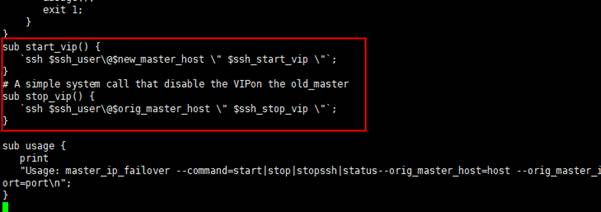
③my $vip = 'xxxxxxxx';这一行中的vip根据实际情况改成自己的虚拟IP。
(2)chmod +x /usr/bin/master_ip_failover
6、设置relay log的清除方式(在从数据库节点上执行)
(1)mysql -uroot -ps138791 -e"set global relay_log_purge=0"
说明:在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF(0),采用手动清除relay log的方式。
定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。
(2)设置定期清理relay脚本(两台slave节点上操作一样):
/root目录下:vi purge_relay_log.sh
#!/bin/bash
user=root
passwd=s138791
port=3306
log_dir='/data/masterha/log'
work_dir='/data'
purge='/usr/local/bin/purge_relay_logs'
if [ ! -d $log_dir ]
then
mkdir $log_dir -p
fi
$purge --user=$user --password=$passwd --disable_relay_log_purge --port=$port --workdir=$work_dir >> $log_dir/purge_relay_logs.log 2>&1
###参数描述
--user mysql 用户名,缺省为root
--password mysql 密码
--port 端口号
--host 主机名,缺省为127.0.0.1
--workdir 指定创建relay log的硬链接的位置,默认是/var/tmp,成功执行脚本后,硬链接的中继日志文件被删除
由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,建议指定为relay log相同的分区
--disable_relay_log_purge 默认情况下,参数relay_log_purge=1,脚本不做任何处理,自动退出
设定该参数,脚本会将relay_log_purge设置为0,当清理relay log之后,最后将参数设置为OFF(0)
2>&1 #将标准错误重定向到标准输出,此时的标准输出为
# $log_dir/purge_relay_logs.log
chmod +x purge_relay_log.sh
(3)crontab -e
0 4 * * * /root/purge_relay_log.sh 每天凌晨4点执行脚本
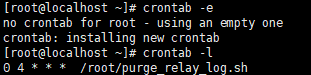
(4)两台slave节点上手动执行脚本看有没有问题
purge_relay_logs --user=root --password=s138791 --port=3306 -disable_relay_log_purge --workdir=/data/
正常情况和下图显示一致:

7、检查配置(在manager节点上操作)
(1)检查各节点间ssh互信通信配置是否Ok
masterha_check_ssh -conf=/etc/mha_master/app1.cnf
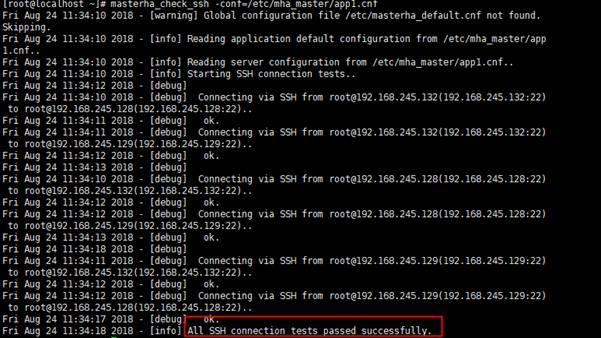
(2)检测各节点权限设置是否生效
masterha_check_repl -conf=/etc/mha_master/app1.cnf
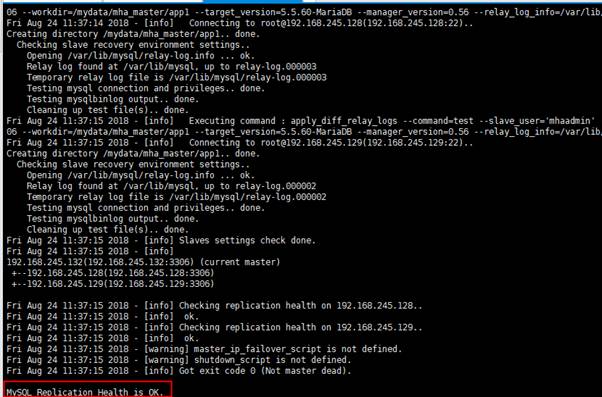
8、启动MHA(在manager节点执行)
nohup masterha_manager --conf=/etc/mha_master/app1.cnf &> /etc/mha_master/manager.log &
启动成功后,可用过如下命令来查看master节点的状态(启动完成需要一段时间):
masterha_check_status --conf=/etc/mha_master/app1.cnf

如果要停止MHA,需要使用master_stop命令。
masterha_stop --conf=/etc/mha_master/app1.cnf
六、验证MHA-keepalived效果
1、在master节点关闭mariadb服务,模拟主节点数据崩溃
systemctl stop mariadb
2、此时使用masterha_check_status 命令检测将会遇到错误提示,如下所示:
masterha_check_status --conf=/etc/mha_master/app1.cnf


3、/etc/mha_master/manager.log 日志文件中出现如下信息,表示manager检测到192168.245.132节点故障,而后自动执行故障转移,将192.168.245.128提升为主节点。
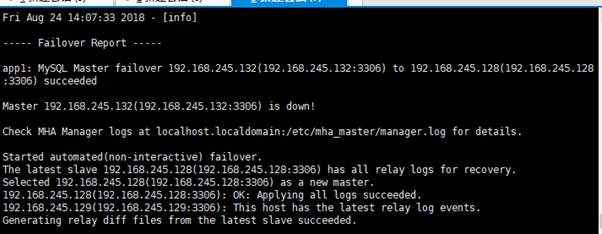
4、manager节点清除app1.failover.complete 这个文件(如果MHA切换失败了,那么清楚app1.failover.error文件)
cd /etc/mha_master/app1
rm -f app1.failover.*
注意:每次failover切换后会在管理目录生成文件app1.failover.complete(或error) ,下次在切换的时候会发现有这个文件导致切换不成功,需要手动清理掉。
5、提供新的slave节点以修复MHA集群。
此处的做法是让故障节点重新上线,以slave的身份加入集群,具体步骤:
(1)备份新的master节点的数据:mysqldump -uroot -ps138791 -A -F --single-transaction --master-data=2 > ./fullbak.sql
(2)清空新上线的故障节点数据:
systemctl stop mariadb
rm -rf /var/lib/mysql/*
systemctl start mariadb
(3)在新的master节点上把数据库备份复制给新上线的故障节点:
scp fullbak.sql 192.168.245.132:/opt/
(4)故障节点恢复数据
mysql < /opt/fullbak.sql
(5)故障节点上编辑/etc/my.cnf,添加两行:
read_only = ON #开启只读权限;
relay_log_purge = 0 #是否自动清空不再需要的中继日志;
然后:systemctl restart mariadb
(6)查看最新master的bin-log记录信息(先登录mariadb):
Show master status;
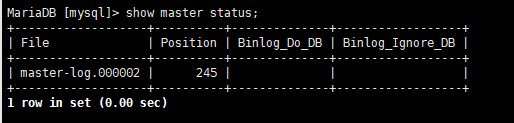
(7)故障节点数据库上执行
CHANGE MASTER TO MASTER_HOST='192.168.245.128',MASTER_USER='cpuser',MASTER_PASSWORD='cppass',MASTER_LOG_FILE='master-log.000002',MASTER_LOG_POS=245;
flush privileges;
start slave;
show slave status\G
show variables like '%read_only%';
set global read_only=on;
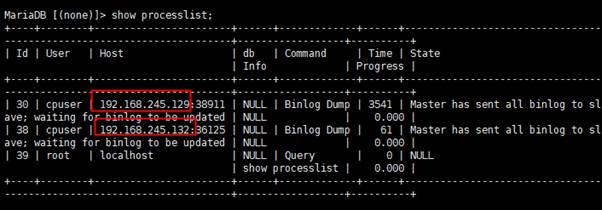
(4) 在新的主数据库上查看复制线程,新的slave已添加成功;然后检查新主数据库上的只读是否关闭,若未关闭则关闭。
show processlist;
show variables like '%read_only%';
set global read_only=off;
6、切换过后MHA失效,需要按照上面的步骤,在manager节点上重新检测、启动MHA
(1)masterha_check_ssh -conf=/etc/mha_master/app1.cnf
(2)masterha_check_repl -conf=/etc/mha_master/app1.cnf
(3)nohup masterha_manager -conf=/etc/mha_master/app1.cnf &> /etc/mha_master/manager.log &
(4)masterha_check_status -conf=/etc/mha_master/app1.cnf
7、故障节点启动keepalived
systemctl start keepalived
8、注意事项
新加入的slave节点如果为新增节点,其 IP 地址要配置为原来故障master 节点的 IP,否则,还需要修改 app1.cnf 中相应的 ip 地址。随后再次启动 manager,并再次检测其状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号