
并发
一、POSIX Threads
thread.h,简化的线程 API。线程:共享内存的执行流。POSIX 提供了线程库标准,Linux(pthreads) 和 Windwos(API) 都有实现


#include <stdlib.h> #include <stdio.h> #include <string.h> #include <stdatomic.h> #include <assert.h> #include <unistd.h> #include <pthread.h> #define NTHREAD 64 enum { T_FREE = 0, T_LIVE, T_DEAD, }; struct thread { int id, status; pthread_t thread; void (*entry)(int); }; struct thread tpool[NTHREAD], *tptr = tpool; void *wrapper(void *arg) { // pthreads 线程接受一个 void * 类型的参数,且必须返回一个 void *。我们用 wrapper function 的方法解决这个问题:所有的线程的实际入口都是名为 wrapper 的函数,它会在内部调用线程的 entry 函数 struct thread *thread = (struct thread *) arg; thread->entry(thread->id); return NULL; } /** * 创建一个入口函数是 fn 的线程,并立即开始执行 * void fn(int tid) { ... } 参数 tid 从 1 开始编号 */ void create(void *fn) { assert(tptr - tpool < NTHREAD); *tptr = (struct thread) { .id = tptr - tpool + 1, .status = T_LIVE, .entry = fn, }; pthread_create(&(tptr->thread), NULL, wrapper, tptr); ++tptr; } void join() { // 等待所有运行线程的返回 for (int i = 0; i < NTHREAD; i++) { struct thread *t = &tpool[i]; if (t->status == T_LIVE) { pthread_join(t->thread, NULL); t->status = T_DEAD; } } } __attribute__((destructor)) void cleanup() { join(); }
使用 thread.h,gcc -ggdb -Wall main.c -o main && main
#include "thread.h" void Ta() { while (1) { printf("a"); } } void Tb() { while (1) { printf("b"); } } void Thello(int id) { while (1) { printf("%c", "_ABCDEFGHIJKLMNOPQRSTUVWXYZ"[id]); } } int main() { for (int i = 0; i < 10; i++) { create(Thello); } create(Ta); create(Tb); }
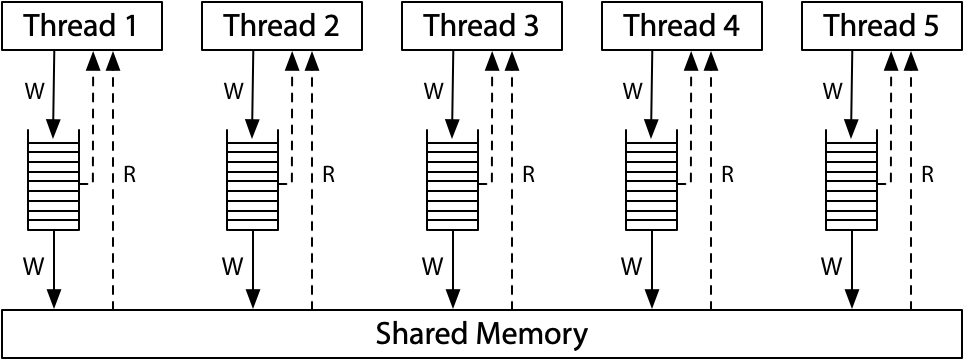
证实线程共享内存且有独立的堆栈
#include "thread.h" int x; // 线程共享内存,每个线程都可以修改 x void Thello(int id) { // int x; // 线程有独立的堆栈,每个线程都有自己的 x x++; printf("%d-%d\n", id, x); } int main() { for (int i = 0; i < 10; i++) { create(Thello); }}
用代码大概确定线程堆栈大小,结果排序:a.out | sort -nk 3。用 ulimit -a 可直接看到默认 stack size (kbytes, -s) 8192
#include <stdint.h> #include "thread.h" void *volatile low[4]; // void volatile *low[4]; ? void *volatile high[4]; void update_range(int T, void *ptr) { // 方法入参分配在栈上,记录入参地址的最值 if (ptr < low[T]) low[T] = ptr; if (ptr > high[T]) high[T] = ptr; } void probe(int T, int n) { update_range(T, &n); long sz = (uintptr_t) high[T] - (uintptr_t) low[T]; // 指针的整数表示 if (sz % 1024 < 32) printf("Stack(T%d) >= %ld KB\n", T, sz / 1024); probe(T, n + 1); // Infinite recursion } void Tprobe(int T) { low[T] = (void *) -1; high[T] = (void *) 0; update_range(T, &T); probe(T, 0); } int main() { // 通过递归,并在递归时通过局部变量的地址来估算分配给线程的栈空间 setbuf(stdout, NULL); // 设置输出缓冲区为空,以便立即显示输出内容,避免异常后无法输出 for (int i = 0; i < 4; i++) create(Tprobe); }
可以修改 thread.h 中的 create 方法设置栈大小
pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setstacksize(&attr, 2 * 1024 * 1024); // 设置堆栈大小为 2MB pthread_create(&(tptr->thread), &attr, wrapper, tptr);
创建线程使用的 clone 系统调用
#define _GNU_SOURCE #include <sys/wait.h> #include <stdio.h> #include <stdlib.h> #include <sched.h> #define STACK_SIZE 8192 // 定义线程的栈大小 int thread_function(void *arg) { printf("Thread PID: %d, Thread ID: %d, Thread Argument: %d\n", getpid(), gettid(), (int) arg); sleep(1); printf("Thread function completed\n"); return 0; } int main() { // 创建新线程的栈 void *stack = malloc(STACK_SIZE); if (stack == NULL) { perror("malloc failed"); exit(EXIT_FAILURE); } // 使用 clone 系统调用创建新线程 int flags = CLONE_THREAD | CLONE_VM | CLONE_FILES | CLONE_SIGHAND | CLONE_FS; // 设置标志位 int thread_id = clone(thread_function, stack + STACK_SIZE, flags, (void *) 88); if (thread_id == -1) { perror("clone failed"); exit(EXIT_FAILURE); } printf("Created a new thread with thread ID: %d\n", thread_id); // 等待新线程完成 int status; if (waitpid(thread_id, &status, WUNTRACED | WSTOPPED) == -1) { perror("Failed to wait for thread"); exit(EXIT_FAILURE); } printf("Thread exited with status %d\n", WEXITSTATUS(status)); // 获取线程返回值 printf("Main process completed\n"); free(stack); // 释放线程栈内存 return 0; }
二、线程安全
单处理器多线程:线程在运行时可能被中断,切换到另一个线程执行
多处理器多线程:线程根本就是并行执行的
原子性:指令/代码执行原子性假设
求和:并发执行 sum++。即使用 inline assembly 把求和翻译成一条指令,依然无法保证单条指令在多处理器上执行的原子性,结果大概率是不正确的。除非引入额外的硬件机制,例如 lock 指令
#include "thread.h" #define N 100000000 long sum = 0; void Tsum() { for (int i = 0; i < N; i++) sum++; } // void Tsum() { for (int i = 0; i < N; i++) asm volatile("incq %0": "+m"(sum)); } int main() { create(Tsum); create(Tsum); join(); printf("sum = %ld\n", sum); }
支付:并发执行 + 整数溢出,结果大概率是不正确的
#include "thread.h" unsigned long balance = 100; void Alipay_withdraw(int amt) { if (balance >= amt) { usleep(1); // Unexpected delays balance -= amt; } } void Talipay(int id) { Alipay_withdraw(100); } int main() { create(Talipay); create(Talipay); join(); printf("balance = %lu\n", balance); }
不管是代码 sum++、balance -= amt 还是汇编指令 incq 都是可以被打断执行的
有序性:程序的顺序执行假设
以上面求和的例子,O2 编译优化可以输出正确结果,O1 却不能。使用 objdump -d 反汇编,分别查看 O1 和 O2 可执行文件:
- O1:把值存入寄存器,对寄存器中的值操作,最后把寄存器结果写出到值。 R[eax] = sum; R[eax] += N; sum = R[eax];
- O2:直接去掉了循环变成一条相加指令。sum += N;
// O1 000000000000118f <Tsum>: 118f: 48 8b 15 ca 2e 00 00 mov 0x2eca(%rip),%rdx # 4060 <sum> 1196: 48 8d 42 01 lea 0x1(%rdx),%rax 119a: 48 81 c2 01 e1 f5 05 add $0x5f5e101,%rdx 11a1: 48 89 c1 mov %rax,%rcx 11a4: 48 83 c0 01 add $0x1,%rax 11a8: 48 39 d0 cmp %rdx,%rax 11ab: 75 f4 jne 11a1 <Tsum+0x12> 11ad: 48 89 0d ac 2e 00 00 mov %rcx,0x2eac(%rip) # 4060 <sum> 11b4: c3 ret // O2 00000000000011f0 <Tsum>: 11f0: 48 81 05 65 2e 00 00 addq $0x5f5e100,0x2e65(%rip) # 4060 <sum> 11f7: 00 e1 f5 05 11fb: c3 ret 11fc: 0f 1f 40 00 nopl 0x0(%rax)
再例如 while (!done) 可以被优化为 if (!done) while (1)。编译器对内存访问 "eventually consistent" 的处理导致共享内存作为线程同步工具的失效
保证执行顺序:
- 插入 “不可优化” 代码:asm volatile ("" ::: "memory"); // Clobbers memory
- 标记变量 load/store 为不可优化:extern int volatile done; // 使用 volatile 变量
可见性:多处理器间内存访问的即时可见性
看个例子,执行 { for i in $(seq 999); do main; done } | uniq 可看到输出可能有 01、10、11
#include "thread.h" int x = 0, y = 0; // void T1() { // x = 1; // Store(x) // printf("%d", y); // Load(y) // } void T1() { x = 1; int t = y; // Store(x); Load(y) __sync_synchronize(); printf("%d", t); } // void T2() { // y = 1; // Store(y) // printf("%d", x); // Load(x) // } void T2() { y = 1; int t = x; // Store(y); Load(x) __sync_synchronize(); printf("%d", t); } int main() { create(T1); create(T2); join(); printf("\n"); }
这个例子换个写法,执行 mainc | head -n 99999 | sort | uniq -c 可以看到 00、01、10、11
#include "thread.h" #include <stdatomic.h> int x = 0, y = 0; atomic_int flag; #define FLAG atomic_load(&flag) #define FLAG_XOR(val) atomic_fetch_xor(&flag, val) #define WAIT_FOR(cond) while (!(cond)) ; __attribute__((noinline)) void write_x_read_y() { int y_val; asm volatile( "movl $1, %0;" // x = 1 "movl %2, %1;" // y_val = y : "=m"(x), "=r"(y_val) : "m"(y) ); printf("%d ", y_val); } __attribute__((noinline)) void write_y_read_x() { int x_val; asm volatile( "movl $1, %0;" // y = 1 "movl %2, %1;" // x_val = x : "=m"(y), "=r"(x_val) : "m"(x) ); printf("%d ", x_val); } void T1(int id) { while (1) { WAIT_FOR((FLAG & 1)); write_x_read_y(); FLAG_XOR(1); } } void T2() { while (1) { WAIT_FOR((FLAG & 2)); write_y_read_x(); FLAG_XOR(2); } } void Tsync() { while (1) { x = y = 0; __sync_synchronize(); // full barrier usleep(1); // + delay assert(FLAG == 0); FLAG_XOR(3); // T1 and T2 clear 0/1-bit, respectively WAIT_FOR(FLAG == 0); printf("\n"); fflush(stdout); } } int main() { create(T1); create(T2); create(Tsync); }
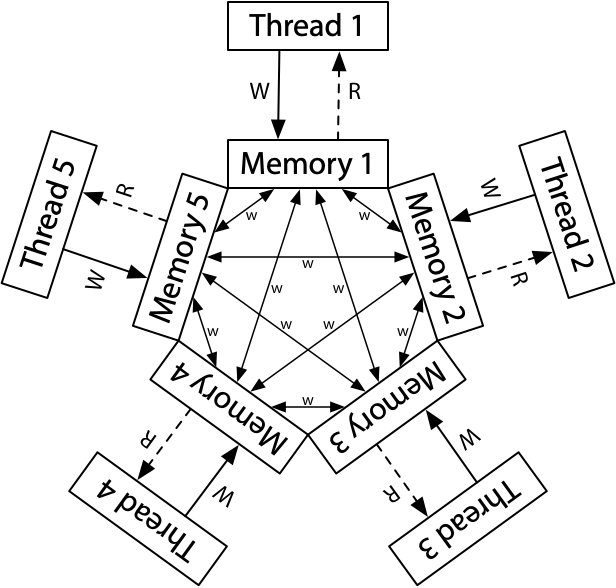
为了提高共享内存系统的性能,系统中并非只有一个"全局共享内存"。每个处理器都有自己的缓存,并且通过硬件实现的协议维护一致性
在 x86 多处理器系统中,允许 store 时暂时写入处理器本地的 store buffer,从而延迟对其他处理器的可见性
1、现代处理器电路会将连续的指令"编译"成更小的 μops,并在任何时刻都维护一个 μop 的"池子":
- 与编译器一样,做"顺序执行"假设:没有其他处理器"干扰"
- 每一周期执行尽可能多的 μop - 多路发射、乱序执行、按序提交
2、满足单处理器 eventual memory consistency 的执行,在多处理器系统上可能无法序列化
3、当 x ≠ y 时,对 x,y 的内存读写可以交换顺序
- 它们甚至可以在同一个周期里完成 (只要 load/store unit 支持)
- 如果写 x 发生 cache miss,可以让读 y 先执行。满足"尽可能执行μop"的原则,最大化处理器性能
- 在多处理器上的表现:两个处理器分别看到 y=0 和 x=0
4、A Primer on Memory Consistency and Cache Coherence
三、宽松内存模型 (Relaxed/Weak Memory Model)
宽松内存模型的目的是使单处理器的执行更高效,Russ Cox 关于内存模型的文章:https://research.swtch.com/mm
x86 Total Store Order (x86-TSO) in Hardware memory models
ARM/POWER/RISC-V in Hardware memory models,quite a bit weaker than x86-TSO or even x86-TLO+CC
四、并发控制
并发编程困难的原因:多处理器编程(weak memory model) + 编译优化,必须放弃许多对顺序程序编程时的基本假设
解决手段:通过互斥实现 stop/resume the world("回退到"顺序执行)。只要程序中"能并行"的部分足够多,串行化一小部分也并不会对性能带来致命的影响
只有软件(编译器)和硬件(处理器指令)"协同工作",才能正确实现多处理器上的并发
Peterson 算法
#include "thread.h" #define A 1 #define B 2 #define BARRIER __sync_synchronize() // asm volatile ("mfence" ::: "memory") atomic_int nested; atomic_long count; void critical_section() { atomic_long cnt = atomic_fetch_add(&count, 1); int i = atomic_fetch_add(&nested, 1) + 1; if (i != 1) { printf("%d threads in the critical section @ count=%ld\n", i, cnt); assert(0); } atomic_fetch_add(&nested, -1); } int volatile x = 0, y = 0, turn; void TA() { while (1) { x = 1; BARRIER; turn = B; BARRIER; // <- this is critcal for x86 while (1) { if (!y) break; BARRIER; if (turn != B) break; BARRIER; } critical_section(); x = 0; BARRIER; } } void TB() { while (1) { y = 1; BARRIER; turn = A; BARRIER; while (1) { if (!x) break; BARRIER; if (turn != A) break; BARRIER; } critical_section(); y = 0; BARRIER; } } int main() { create(TA); create(TB); }
barrier(屏障):Compiler barrier / Memory barrier / Memory order
- volatile
- asm volatile ("" : : : "memory")
- __sync_synchronize(),x86: mfence、ARM: dmb ish、RISC-V: fence rw, rw
编译器到底做了什么:https://godbolt.org
原子指令
Atomic Exchange 实现
int xchg(int volatile *ptr, int newval) { int result; asm volatile( // 指令自带 memory barrier "lock xchgl %0, %1" : "+m"(*ptr), "=a"(result) : "1"(newval) // Compiler barrier : "memory" ); return result; }
spinlock(自旋锁)
1、用 xchg 实现互斥
int table = YES; void lock() { retry: int got = xchg(&table, NOPE); if (got == NOPE) goto retry; assert(got == YES); } void unlock() { xchg(&table, YES); // 为什么不是 table = YES; ? } int locked = 0; void lock() { while (xchg(&locked, 1)); } void unlock() { xchg(&locked, 0); }
用自旋锁实现互斥,临界区(critical section)内代码不能并行,还是以求和为例:
#include "thread.h" #define N 100000000 #define M 10 long sum = 0; int xchg(int volatile *ptr, int newval) { int result; asm volatile( "lock xchgl %0, %1" : "+m"(*ptr), "=a"(result) : "1"(newval) : "memory" ); return result; } int locked = 0; void lock() { while (xchg(&locked, 1)); } void unlock() { xchg(&locked, 0); } void Tsum() { long nround = N / M; for (int i = 0; i < nround; i++) { lock(); for (int j = 0; j < M; j++) { sum++; // Non-atomic; can optimize } unlock(); } } int main() { assert(N % M == 0); create(Tsum); create(Tsum); join(); printf("sum = %ld\n", sum); }
自动释放锁可以借助 C++ 中 RAII 机制
2、用 cmpxchg 实现互斥,又称无锁算法 CAS(Compare and exchange/swap、test and set)
下面代码理解 cmpxchg 指令的行为
#include <stdio.h> #include <assert.h> int cmpxchg(int old, int new, int volatile *ptr) { asm volatile( "lock cmpxchgl %[new], %[mem]" : "+a"(old), [mem] "+m"(*ptr) : [new] "S"(new) : "memory" ); return old; } int cmpxchg_ref(int old, int new, int volatile *ptr) { int tmp = *ptr; // Load if (tmp == old) { *ptr = new; // Store (conditionally) } return tmp; } void run_test(int x, int old, int new) { int val1 = x; int ret1 = cmpxchg(old, new, &val1); int val2 = x; int ret2 = cmpxchg_ref(old, new, &val2); assert(val1 == val2 && ret1 == ret2); printf("x = %d -> (cmpxchg %d -> %d) -> x = %d\n", x, old, new, val1); } int main() { for (int x = 0; x <= 2; x++) for (int old = 0; old <= 2; old++) for (int new = 0; new <= 2; new++) run_test(x, old, new); }
相比 xchg 会在自旋失败的时候减少了一次 store。当然,现代处理器也可以优化 xchg
相比 xchg 多出的 Compare 用处:同时检查上一次获得的值是否仍然有效 + 修改生效。例如并发下链表的增加操作
// Create a new node retry: expected = head; node->next = expected; seen = cmpxchg(expected, node, &head); if (seen != expected) goto retry;
3、自旋锁的缺陷
除了进入临界区的线程,其他处理器上的线程都在空转。例如 2 cpu 执行两个 spinlock,就浪费了 50% 的 cpu
持有自旋锁的线程可能被操作系统切换出去,实现 100% 的资源浪费。例如 2 个 cpu 执行三个 spinlock,当拿到锁的那个 cpu 被操作系统切到另一个没拿到锁的线程上,这时就浪费了 100% 的 cpu
以求和为例,把 sum++ 均匀地分到 n 个线程。临界区的代码不能并行,因此无论开启多少个线程,执行 sum++ 指令的数量是完全相同的
thread-sync.h
#include <semaphore.h> #include <pthread.h> // Spinlock typedef int spinlock_t; #define SPIN_INIT() 0 static inline int atomic_xchg(volatile int *addr, int newval) { int result; asm volatile ("lock xchg %0, %1": "+m"(*addr), "=a"(result) : "1"(newval) : "memory"); return result; } void spin_lock(spinlock_t *lk) { while (1) { int value = atomic_xchg(lk, 1); if (value == 0) { break; } } } void spin_unlock(spinlock_t *lk) { atomic_xchg(lk, 0); } // Mutex typedef pthread_mutex_t mutex_t; #define MUTEX_INIT() PTHREAD_MUTEX_INITIALIZER void mutex_lock(mutex_t *lk) { pthread_mutex_lock(lk); } void mutex_unlock(mutex_t *lk) { pthread_mutex_unlock(lk); } // Conditional Variable typedef pthread_cond_t cond_t; #define COND_INIT() PTHREAD_COND_INITIALIZER #define cond_wait pthread_cond_wait #define cond_broadcast pthread_cond_broadcast #define cond_signal pthread_cond_signal // Semaphore #define P sem_wait #define V sem_post #define SEM_INIT(sem, val) sem_init(sem, 0, val)
sum-scalability.c
#include "thread.h" #include "thread-sync.h" #define N 10000000 spinlock_t lock = SPIN_INIT(); long n, sum = 0; void Tsum() { for (int i = 0; i < n; i++) { spin_lock(&lock); sum++; spin_unlock(&lock); } } int main(int argc, char *argv[]) { assert(argc == 2); int nthread = atoi(argv[1]); n = N / nthread; for (int i = 0; i < nthread; i++) { create(Tsum); } join(); assert(sum == n * nthread); }
执行 time a.out 1、time a.out 2...,随着线程数的提升,多个处理器之间争抢锁和 sum 变量,将会引起 MESI(缓存一致性) 协议的额外开销。随着线程数量的增长,程序的效率逐渐降低
同一份计算任务,时间(CPU cycles)和空间(mapped memory)会随处理器数量的增长而变化
自旋锁的使用场景:短临界区
mutex(互斥锁):在操作系统上实现互斥(实现线程 + 长临界区的互斥)
操作系统提供了互斥锁,以应对多处理器自旋带来的 CPU 浪费。以求和为例:
#include "thread.h" #include "thread-sync.h" #define N 10000000 mutex_t lock = MUTEX_INIT(); long n, sum = 0; void Tsum() { for (int i = 0; i < n; i++) { mutex_lock(&lock); sum++; mutex_unlock(&lock); } } int main(int argc, char *argv[]) { assert(argc == 2); int nthread = atoi(argv[1]); n = N / nthread; for (int i = 0; i < nthread; i++) { create(Tsum); } join(); printf("sum = %ld\n", sum); assert(sum == n * nthread); }
互斥锁会先试着自旋;如果没能获得锁,则会进入 Slow Path,由操作系统接管锁的实现。由于无法预知多久后锁才会被释放,操作系统会将上锁的线程暂停并不再调度它,直到持有锁的线程释放锁为止
从使用的角度,互斥锁的行为与自旋锁完全相同 (除了更少的 CPU 浪费)
- 自旋锁 (线程直接共享 locked)
- 更快的 fast path,xchg 成功 → 立即进入临界区,开销很小
- 更慢的 slow path,xchg 失败 → 浪费 CPU 自旋等待
- 互斥锁 (通过系统调用访问 locked)
- 更经济的 slow path,上锁失败线程不再占用 CPU
- 更慢的 fast path,即便上锁成功也需要进出内核(syscall)
- 只有一个线程上锁解锁的时候不需要进入内核,在上锁失败的时候再进入内核
synchronization(同步)
线程同步:在某个时间点共同达到互相已知的状态(由条件不成立等待和被唤醒后同步条件达成继续构成)
99% 的实际并发问题都可以用生产者-消费者解决。并行计算基础:计算图
- 计算任务构成有向无环图。(u,v) ∈ E 表示 v 要用到前 u 的值
- 只要调度器 (生产者) 分配任务效率够高,算法就能并行。生产者把任务放入队列中,消费者 (workers) 从队列中取出任务
以打印括号模仿生产者-消费者为例:
1、使用互斥锁和自旋解决生产者-消费者问题
为生产者和消费者分别设置了 CAN_PRODUCE 和 CAN_CONSUME 两个条件。在持有互斥锁的前提下检查条件是否满足,且只有条件满足时才能生产/消费。条件不满足时,必须释放锁,并再次等待。如果不释放锁,其他生产者/消费者就无法生产/消费,从而造成死锁
#include "thread.h" #include "thread-sync.h" int n, count = 0; mutex_t lk = MUTEX_INIT(); #define CAN_PRODUCE (count < n) #define CAN_CONSUME (count > 0) void Tproduce() { while (1) { retry: mutex_lock(&lk); if (!CAN_PRODUCE) { mutex_unlock(&lk); goto retry; } count++; printf("("); // Push an element into buffer mutex_unlock(&lk); } } void Tconsume() { while (1) { retry: mutex_lock(&lk); if (!CAN_CONSUME) { mutex_unlock(&lk); goto retry; } count--; printf(")"); // Pop an element from buffer mutex_unlock(&lk); } } int main(int argc, char *argv[]) { assert(argc == 2); n = atoi(argv[1]); setbuf(stdout, NULL); for (int i = 0; i < 8; i++) { create(Tproduce); create(Tconsume); } }
2、condition variable(条件变量)
相比互斥锁方式可减少锁竞争(自旋)带来的性能消耗,在条件不成立时线程就休眠了,直到被唤醒时才会去竞争锁。使用条件变量时,要注意唤醒的线程是不受控制的。
#include "thread.h" #include "thread-sync.h" int n, count = 0; mutex_t lk = MUTEX_INIT(); cond_t cv = COND_INIT(); #define CAN_PRODUCE (count < n) #define CAN_CONSUME (count > 0) void Tproduce() { while (1) { mutex_lock(&lk); while (!CAN_PRODUCE) { // 被唤醒拿到锁后要重新判断条件是否成立 cond_wait(&cv, &lk); // 睡眠时会释放锁(不浪费 CPU)。被唤醒后会尝试获取锁(可能导致自旋等待,消耗一定的 CPU) } printf("("); count++; // cond_signal(&cv); // 先唤醒再释放锁 cond_broadcast(&cv); mutex_unlock(&lk); } } void Tconsume() { while (1) { mutex_lock(&lk); while (!CAN_CONSUME) { // 被唤醒拿到锁后要重新判断条件是否成立 cond_wait(&cv, &lk); // 睡眠时会释放锁(不浪费 CPU)。被唤醒后会尝试获取锁(可能导致自旋等待,消耗一定的 CPU) } printf(")"); count--; // cond_signal(&cv); // 先唤醒再释放锁 cond_broadcast(&cv); mutex_unlock(&lk); } } int main(int argc, char *argv[]) { assert(argc == 3); n = atoi(argv[1]); int T = atoi(argv[2]); setbuf(stdout, NULL); for (int i = 0; i < T; i++) { create(Tproduce); create(Tconsume); } }
另一个例子,并发打印 <><_ 与 ><>_ 的组合。其中每个线程只能输出一种字符,即这里至少要使用三个线程配合才行
#include "thread.h" #include "thread-sync.h" #define LENGTH(arr) (sizeof(arr) / sizeof(arr[0])) enum { A = 1, B, C, D, E, F, }; struct rule { int from, ch, to; } rules[] = { { A, '<', B }, { B, '>', C }, { C, '<', D }, { A, '>', E }, { E, '<', F }, { F, '>', D }, { D, '_', A }, }; int current = A, quota = 1; mutex_t lk = MUTEX_INIT(); cond_t cv = COND_INIT(); int next(char ch) { for (int i = 0; i < LENGTH(rules); i++) { struct rule *rule = &rules[i]; if (rule->from == current && rule->ch == ch) { return rule->to; } } return 0; } static int can_print(char ch) { return next(ch) != 0 && quota > 0; } void fish_before(char ch) { mutex_lock(&lk); while (!can_print(ch)) { // can proceed only if (next(ch) && quota) cond_wait(&cv, &lk); } quota--; mutex_unlock(&lk); } void fish_after(char ch) { mutex_lock(&lk); quota++; current = next(ch); assert(current); cond_broadcast(&cv); mutex_unlock(&lk); } const char roles[] = ".<<<<<>>>>___"; void fish_thread(int id) { char role = roles[id]; while (1) { fish_before(role); putchar(role); // Not lock-protected fish_after(role); } } int main() { setbuf(stdout, NULL); for (int i = 0; i < strlen(roles); i++) create(fish_thread); }
3、semaphore(信号量)
一种条件变量的特例(可以在操作系统上被高效地实现),也因为条件的特殊性,信号量不需要 broadcast。互斥锁是信号量的特例(count = 1 的情况)
对信号量有两种操作:
- P - prolaag (try + decrease/down/wait/acquire):试着从袋子里取一个球。如果拿到了,离开。如果袋子空了(没拿到),排队(休眠)等待
- V - verhoog (increase/up/post/signal/release):往袋子里放一个球。如果有人在等球,(任意唤醒)他就可以拿走刚放进去的球了。放球-拿球的过程实现了同步
信号量对应了 “资源数量”,还是以打印括号模仿生产者-消费者为例,参数是括号可嵌套的深度:
#include "thread.h" #include "thread-sync.h" sem_t fill, empty; void Tproduce() { while (1) { P(&empty); printf("("); V(&fill); } } void Tconsume() { while (1) { P(&fill); printf(")"); V(&empty); } } int main(int argc, char *argv[]) { assert(argc == 2); SEM_INIT(&fill, 0); SEM_INIT(&empty, atoi(argv[1])); for (int i = 0; i < 8; i++) { create(Tproduce); create(Tconsume); } }
与条件变量相比,信号量有两种典型应用,对应了两种线程 join 的方法:
- 实现一次临时的 happens-before。T1 → T2 → …
- 实现计数型的同步。完成就行,不管顺序
实现计数型的同步例子,这里是只使用一个信号量完成的:
#include "thread.h" #include "thread-sync.h" #define T 4 #define N 10000000 sem_t done; long sum = 0; void atomic_inc(long *ptr) { asm volatile( "lock incq %0" : "+m"(*ptr) : : "memory" ); } void Tsum() { for (int i = 0; i < N; i++) { atomic_inc(&sum); } V(&done); // 执行完了就信号量+1 } void Tprint() { for (int i = 0; i < T; i++) { P(&done); // 一个线程执行完了这里就会被唤醒一次。循环 T 次(要等 T 个线程都结束) } printf("sum = %ld\n", sum); } int main() { SEM_INIT(&done, 0); for (int i = 0; i < T; i++) { create(Tsum); } create(Tprint); // 等待所有的 Tsum 线程结束 }
信号量真正的作用:实现计算图。任何并发计算任务都可以看作计算图上的一个拓扑排序 (调度)。用信号量实现 happens-before 在原则上能够解决任何"调度由完成任务的线程控制"类型的并发同步问题
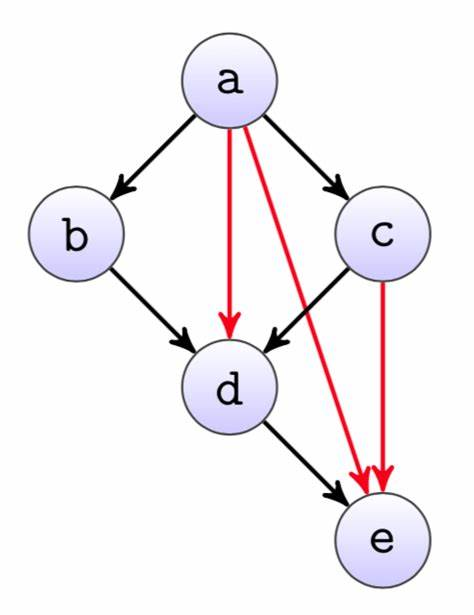
对于任何计算图,为每个节点分配一个线程:1、对每条入边执行 P (wait) 操作。2、完成计算任务。3、对每条出边执行 V (post/signal) 操作
以 d 节点为例,等 bd、ad、cd 执行完后再执行,自己执行完后再唤醒 de
void Tworker_d() { P(bd); P(ad); P(cd); // 完成节点 d 上的计算任务 V(de); }
似乎是完美解决了并行问题,但当图大了之后,会创建很多线程和信号量 = Time Limit Exceeded
- 线程太多:一个线程负责多个节点的计算。静态划分 → 覆盖问题、动态调度 → 又变回了生产者-消费者
- 信号量太多:计算节点共享信号量,可能出现 “假唤醒” → 又变回了条件变量
再看上面那个例子,并发打印 <><_ 与 ><>_ 的组合。用信号量解决
#include "thread.h" #include "thread-sync.h" #define LENGTH(arr) (sizeof(arr) / sizeof(arr[0])) enum { A = 1, B, C, D, E, F, }; struct rule { int from, ch, to; } rules[] = { { A, '<', B }, { B, '>', C }, { C, '<', D }, { A, '>', E }, { E, '<', F }, { F, '>', D }, { D, '_', A }, }; int current = A; sem_t cont[128]; void fish_before(char ch) { P(&cont[(int)ch]); // Update state transition for (int i = 0; i < LENGTH(rules); i++) { struct rule *rule = &rules[i]; if (rule->from == current && rule->ch == ch) { current = rule->to; } } } void fish_after(char ch) { int choices[16], n = 0; // Find enabled transitions for (int i = 0; i < LENGTH(rules); i++) { struct rule *rule = &rules[i]; if (rule->from == current) { choices[n++] = rule->ch; } } // Activate a random one int c = rand() % n; V(&cont[choices[c]]); } const char roles[] = ".<<<<<>>>>___"; void fish_thread(int id) { char role = roles[id]; while (1) { fish_before(role); putchar(role); // Not lock-protected fish_after(role); } } int main() { setbuf(stdout, NULL); SEM_INIT(&cont['<'], 1); SEM_INIT(&cont['>'], 0); SEM_INIT(&cont['_'], 0); for (int i = 0; i < strlen(roles); i++) create(fish_thread); }
使用信号量实现条件变量
五、并发 Bug 分类
Deadlock(死锁)
System deadlocks (1971):死锁产生的四个必要条件,用校园卡来描述。
- Mutual-exclusion - 一张校园卡只能被一个人拥有
- Wait-for - 一个人等其他校园卡时,不会释放已有的校园卡
- No-preemption - 不能抢夺他人的校园卡
- Circular-chain - 形成校园卡的循环等待关系
四个条件缺一不可,打破任何一个即可避免死锁。
数据竞争
不同的线程同时访问同一内存,且至少有一个是写。
用锁保护好共享数据:https://zh.cppreference.com/w/c/language/memory_model
原子性和顺序违反
人类是 sequential creature,我们只能用 sequential 的方式来理解并发
- 程序分成若干 “块”,每一块看起来都没被打断 (原子)
- 具有逻辑先后的 “块” 被正确同步。例子:produce → (happens-before) → consume
并发控制的机制完全是 “后果自负” 的
- 互斥锁 (lock/unlock) 实现原子性。忘记上锁——原子性违反 (Atomicity Violation, AV)
- 条件变量/信号量 (wait/signal) 实现先后顺序同步。忘记同步——顺序违反 (Order Violation, OV)
六、并发 Bug 应对
死锁的应对
避免循环等待

 浙公网安备 33010602011771号
浙公网安备 33010602011771号