
MySQL Optimization
一、Slow Query
-- 查看当前配置 SHOW VARIABLES LIKE 'slow_query_log'; -- 查看慢查询日志状态,默认关闭 SHOW VARIABLES LIKE 'long_query_time'; -- 查看当前慢查询阈值,默认 10,不含 10 SHOW VARIABLES LIKE 'min_examined_row_limit'; -- 判定条件(满足任一):1. 执行时间 > long_query_time 2. 扫描行数 > min_examined_row_limit SHOW VARIABLES LIKE 'log_queries_not_using_indexes'; -- 记录未使用索引的查询 SHOW VARIABLES LIKE 'slow_query_log_file'; -- 查看日志文件路径 -- 临时开启慢查询日志(无需重启MySQL) SET GLOBAL slow_query_log = 'ON'; -- 开启慢查询日志 SET GLOBAL long_query_time = 0.1; -- 时间阈值(单位:秒,建议从0.1开始) SET GLOBAL min_examined_row_limit = 1000; -- 扫描行数阈值(需SYSTEM_VARIABLES_ADMIN权限) SET GLOBAL log_output = 'FILE'; -- 确保输出到文件 FLUSH SLOW LOGS; -- 刷新慢查询日志 -- 捕获慢SQL(保持业务运行) tail -f /var/lib/mysql/your_hostname-slow.log -- 查看实时日志(替换实际路径) -- -a : 显示完整SQL(默认抽象化SQL) -- -s 排序方式:t : 按总时间排序(默认)、l : 按锁定时间排序、r : 按返回行数排序、c : 按执行次数排序 -- -t : 显示前N条记录 mysqldumpslow -a -s t -t 5 /var/lib/mysql/user-slow.log -- 慢查询日志分析 SELECT * FROM mysql.slow_log WHERE start_time > NOW() - INTERVAL 5 MINUTE; -- 或使用MySQL内置分析(需登录MySQL) mysqladmin -uroot-p flush-logs slow -- 慢查询日志删除重建(需要旧的要事先备份) -- 分析完成后关闭,不是调优需要,不建议启动该参数 SET GLOBAL slow_query_log = 'OFF'; -- 关闭慢查询日志
二、EXPLAIN(DESCRIBE)
id:在一个大的查询语句中每个 SELECT 关键字都对应一个唯一的 id,表示操作表的顺序,id 越大优先加载
select_type:小查询在大查询中扮演什么角色
table:表名,查询的每一行记录都对应着一个单表
partitions:代表分区表中的命中情况,非分区表,该项为 NULL
type:针对单表的访问方法,是较为重要的一个指标。比如,看到 type 列的值是 ref,表明 MySQL 将使用 ref 访问方法来执行对 s1 表的查询
possible_keys:可能用到的索引
key:实际用到的索引
key_len:实际用到的(联合)索引字段长度,越短越好
ref:当使用索引列等值查询时,与索引列进行等值匹配的对象信息
rows:扫描行数量
filtered:某个表经过搜索条件过滤后剩余记录条数的百分比
extra:一些额外的信息,执行情况说明与描述
https://github.com/major/MySQLTuner-perl & https://www.percona.com/percona-toolkit
-- 清理冗余数据 OPTIMIZE TABLE your_table; -- 重建表空间 ANALYZE TABLE your_table; -- 更新统计信息
三、索引
索引可以减少磁盘 IO 次数,索引是数据结构
1、索引结构
BTree
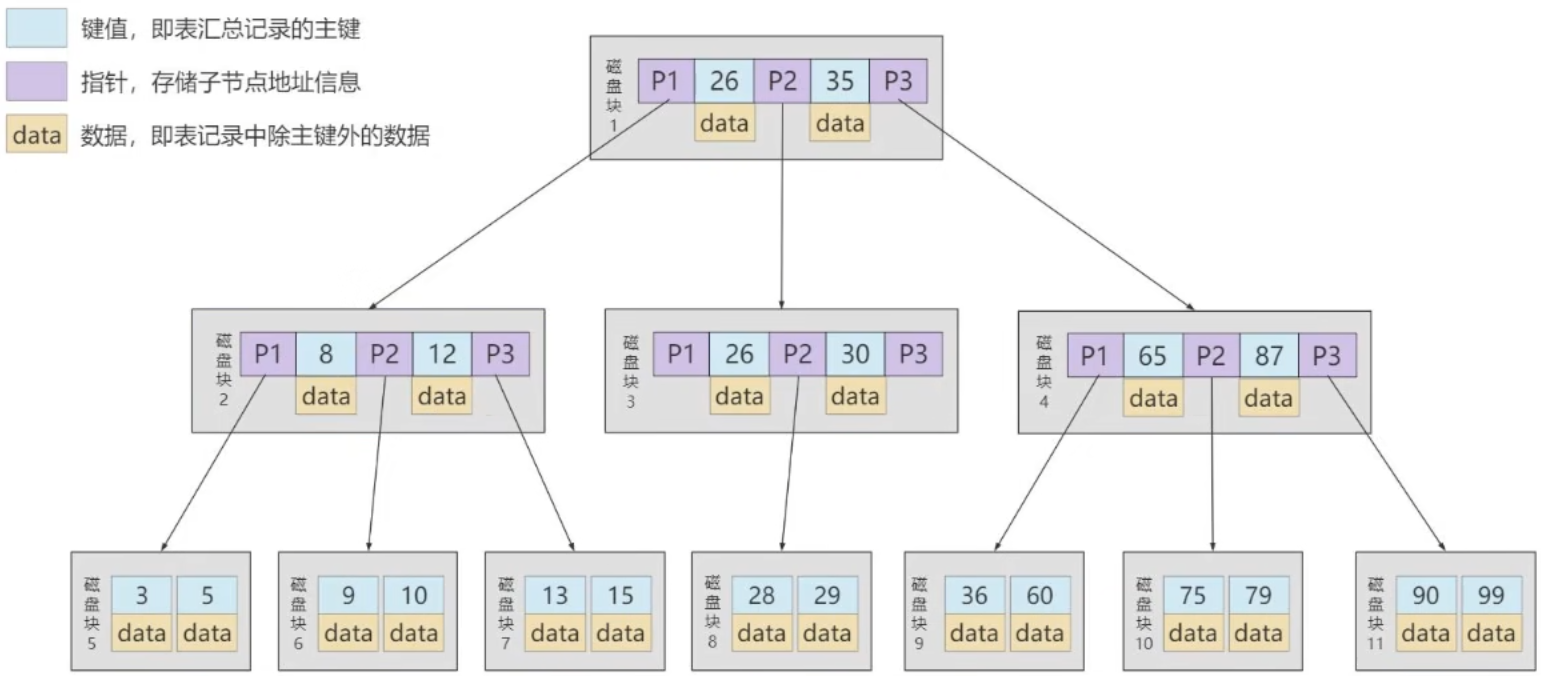
B+Tree
自适应 hash 索引
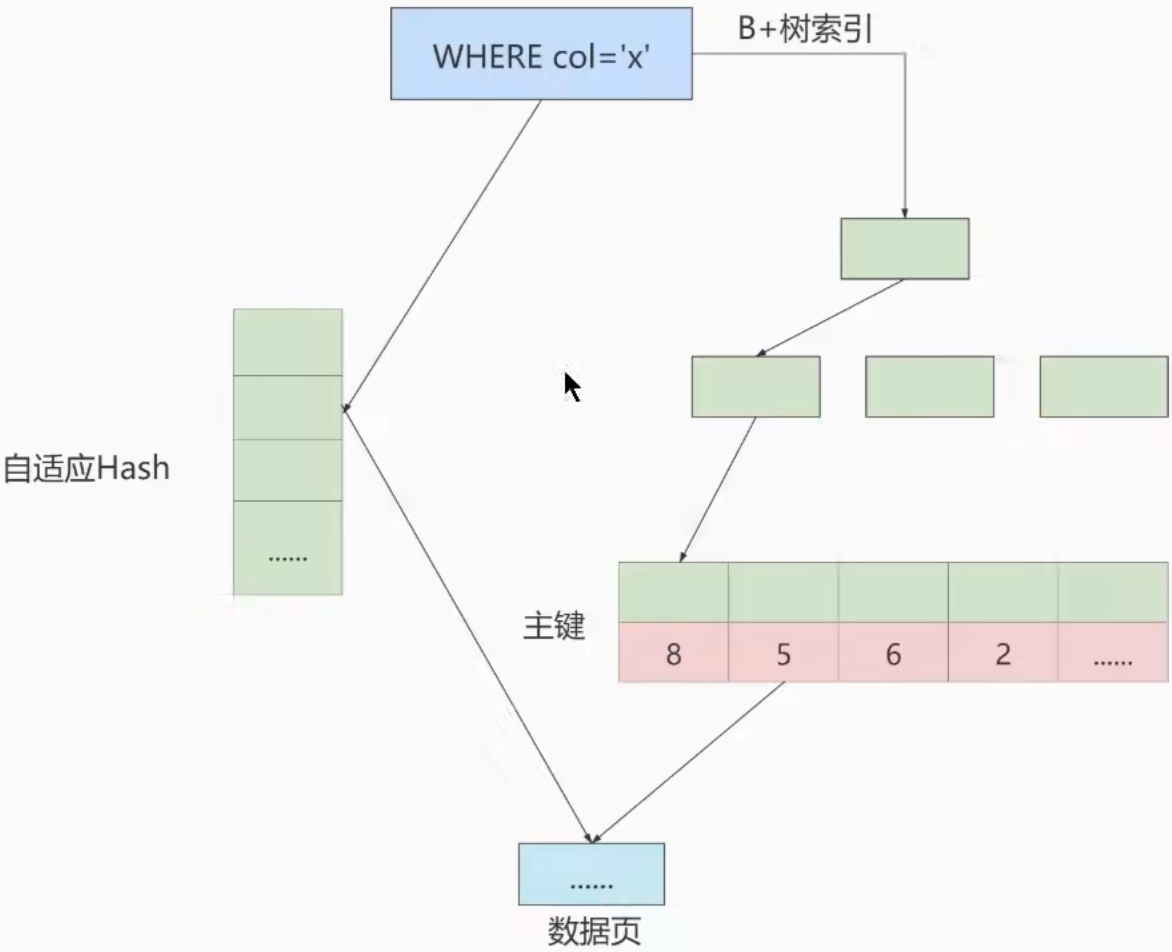
InnoDB 不支持 hash 索引,但有自适应 hash 索引(show variables like '%innodb_adaptive_hash_index%'),直接定位数据页
R-Tree
2、常见索引(数据存储方式)
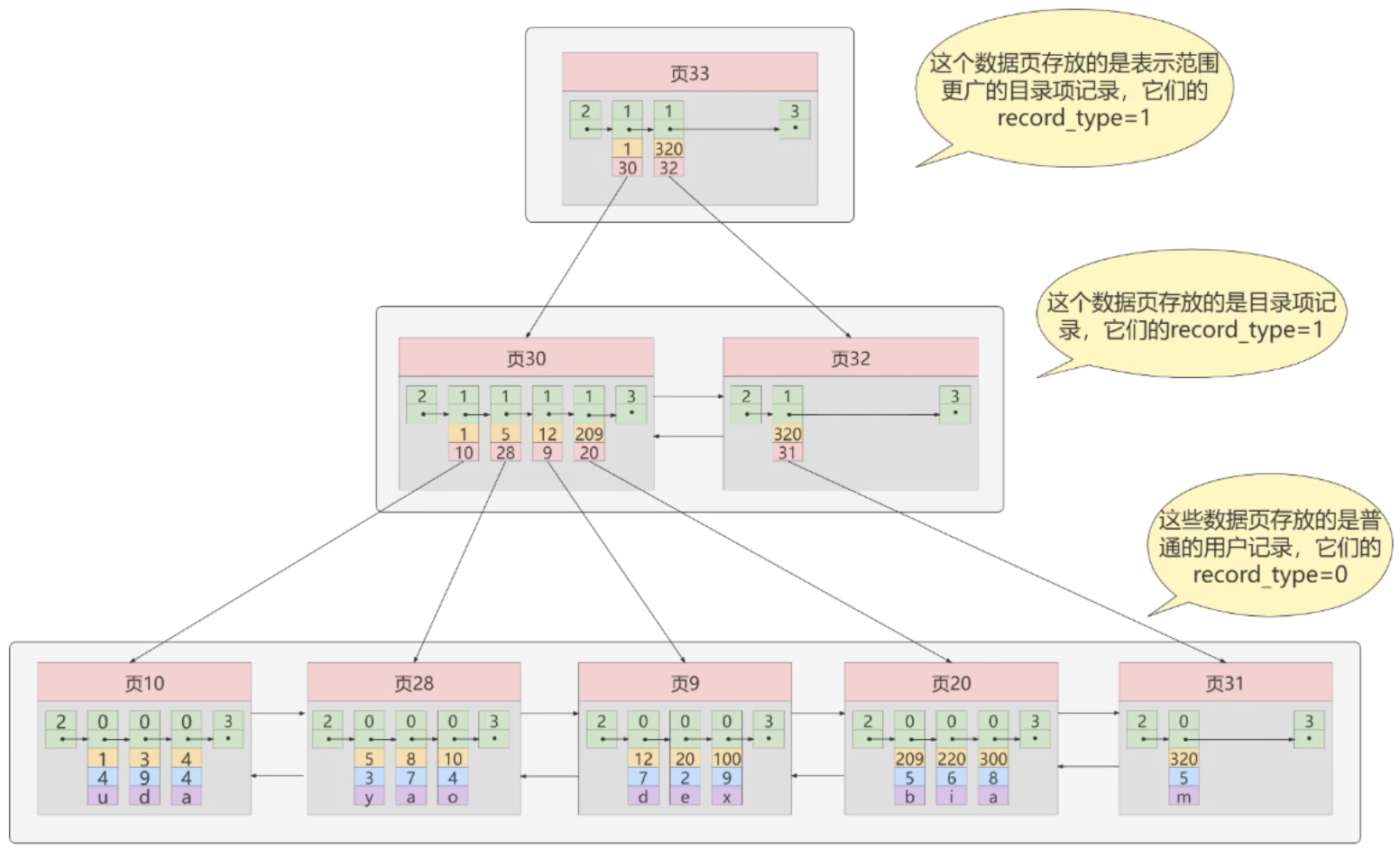
聚簇索引
主键构建的索引(有且只有一个,尽量选单调字段做主键),只有 InnoDB 支持,数据和索引放在一起,且按一定顺序,找到索引也就找到数据
非聚簇(二级、辅助)索引
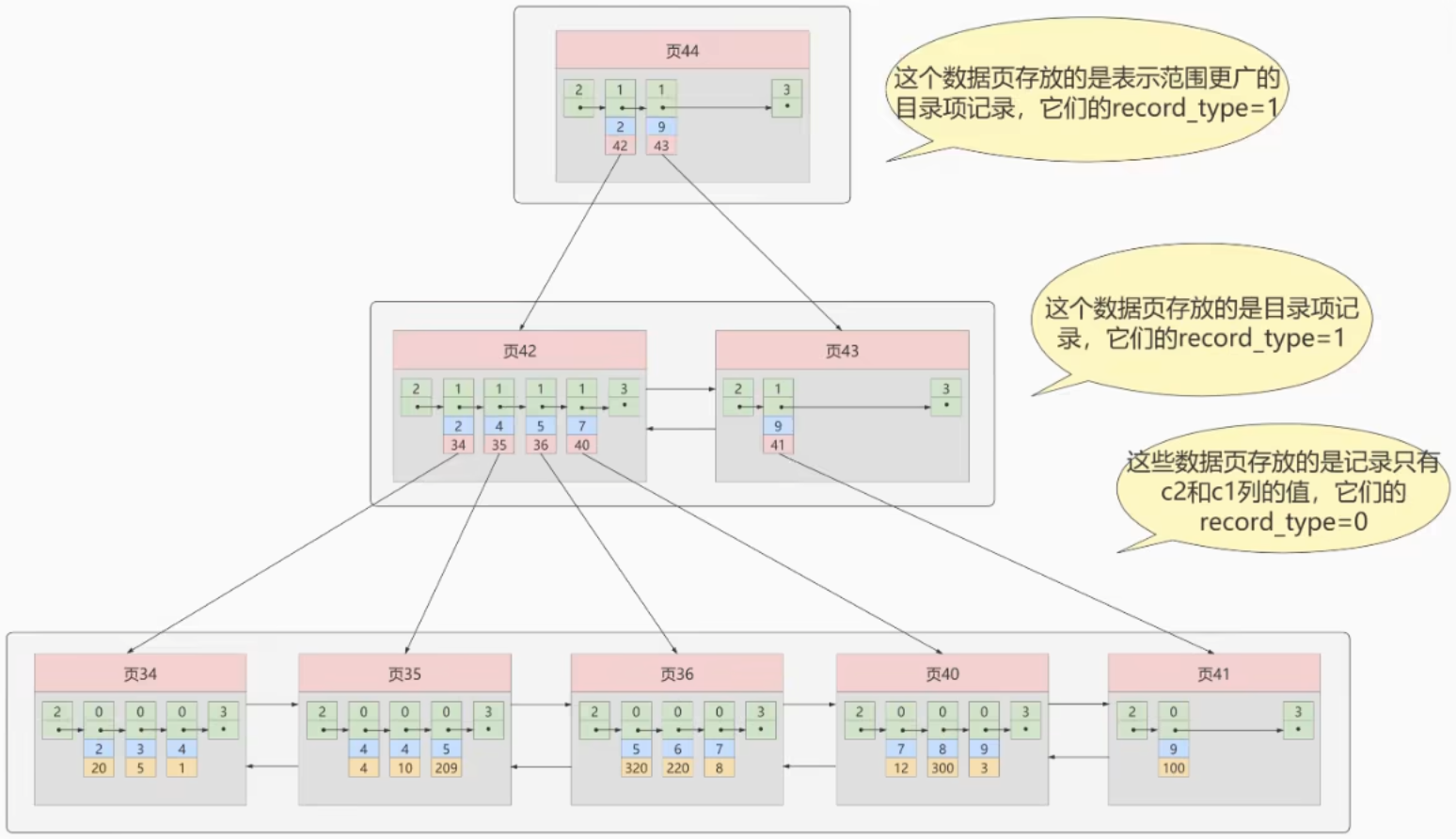
非主键字段构建的索引,需要显式创建,叶子节点不存数据,存索引字段和主键,需要回表(根据主键再去聚簇索引中查找)

非聚簇索引可以有多个
联(复、组)合索引

index-merge-optimization:https://dev.mysql.com/doc/refman/8.4/en/index-merge-optimization.html
非聚簇索引的一种,多个字段建立索引,存储时按照多个字段依次排序。二级索引的索引值默认包含主键,所以二级索引也是复合索引。
3、与 MyISAM 对比
索引结构(B+Tree)
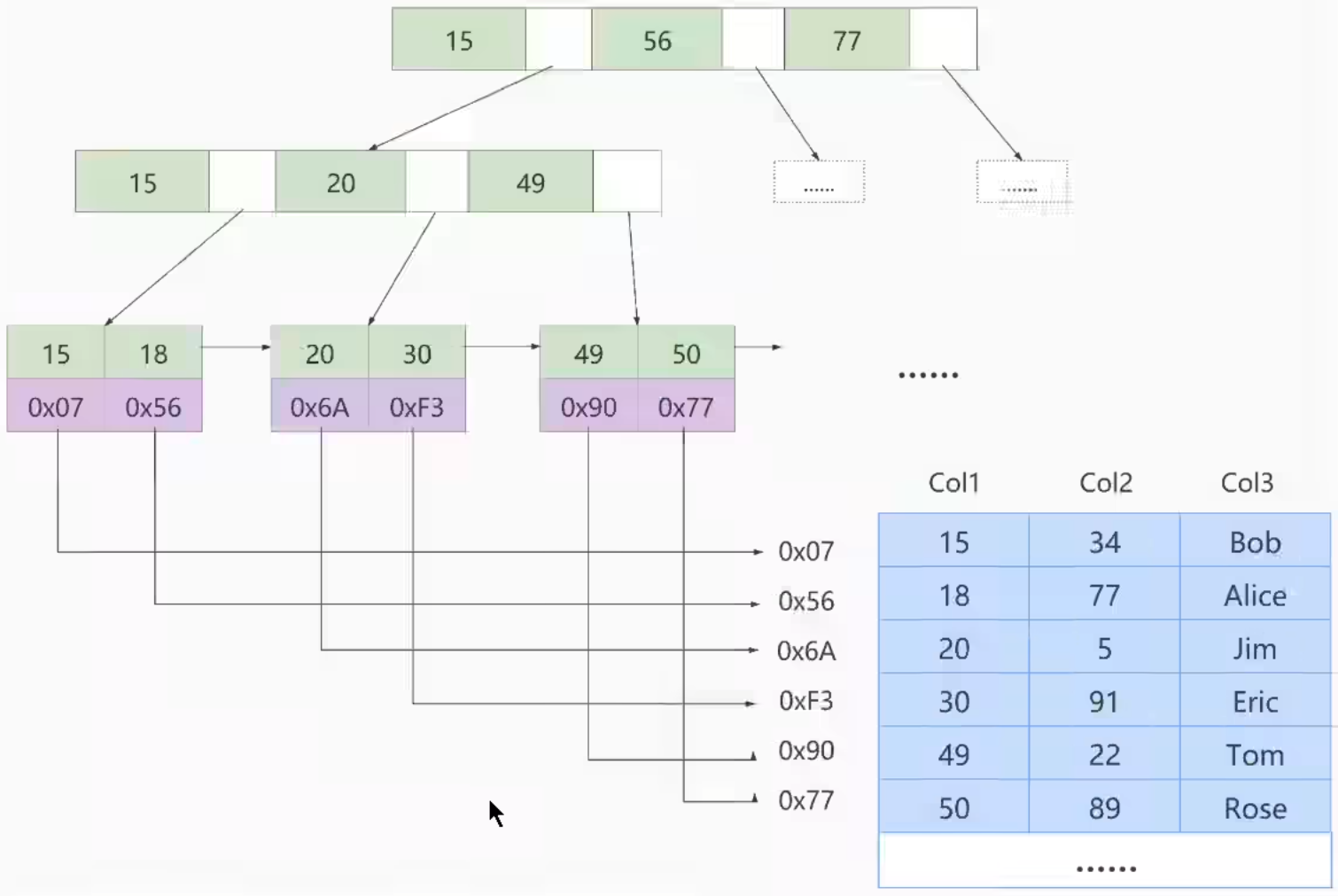
索引(myi,B+ 树)和数据(myd,不排序,按照插入顺序)分开存储。叶子节点 data 域存放对应数据的地址
常见索引(数据存储方式)
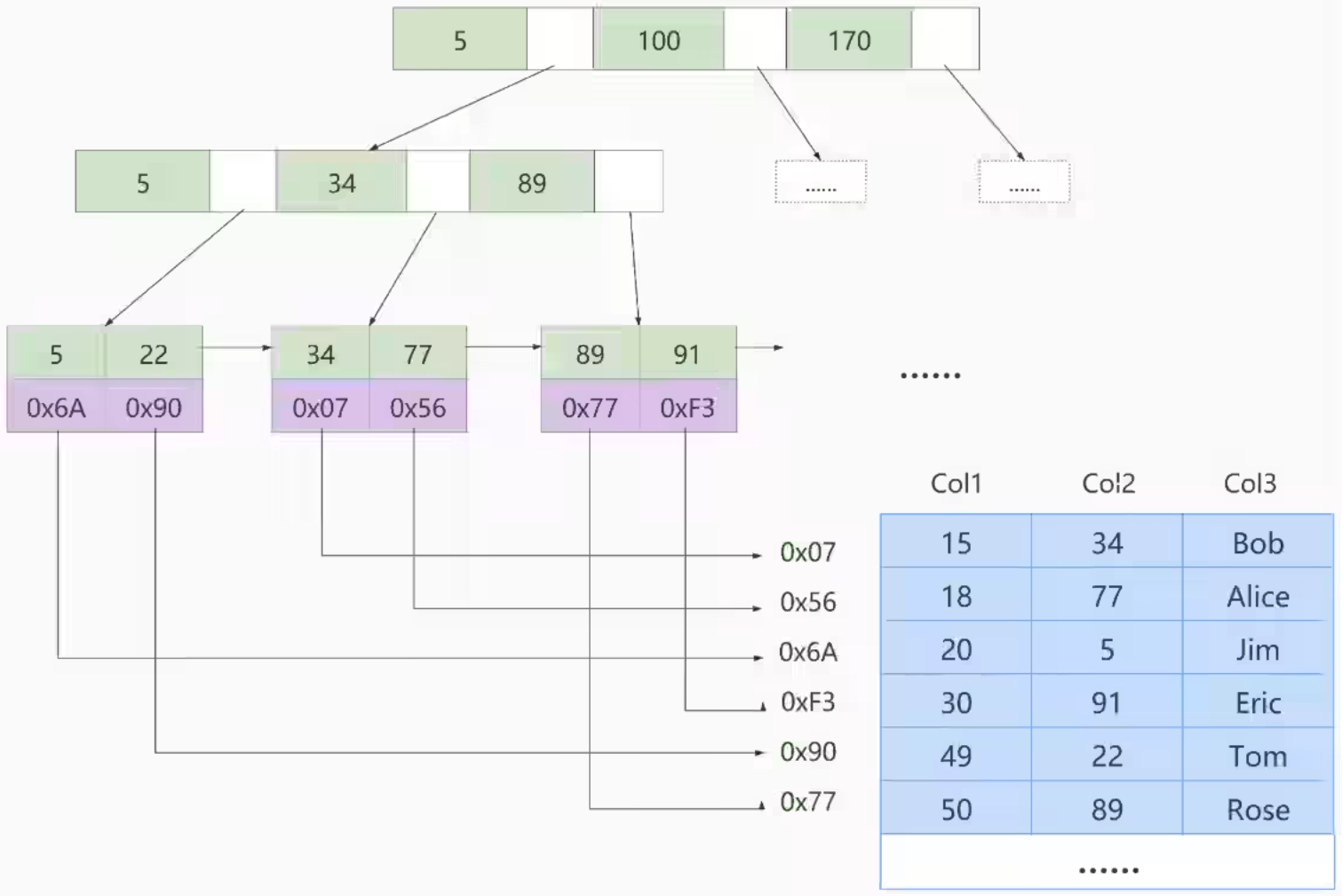
没有聚簇索引,全部是二级索引,需要回表(从 myi 中拿到偏移地址后去 myd 拿(很快)数据)
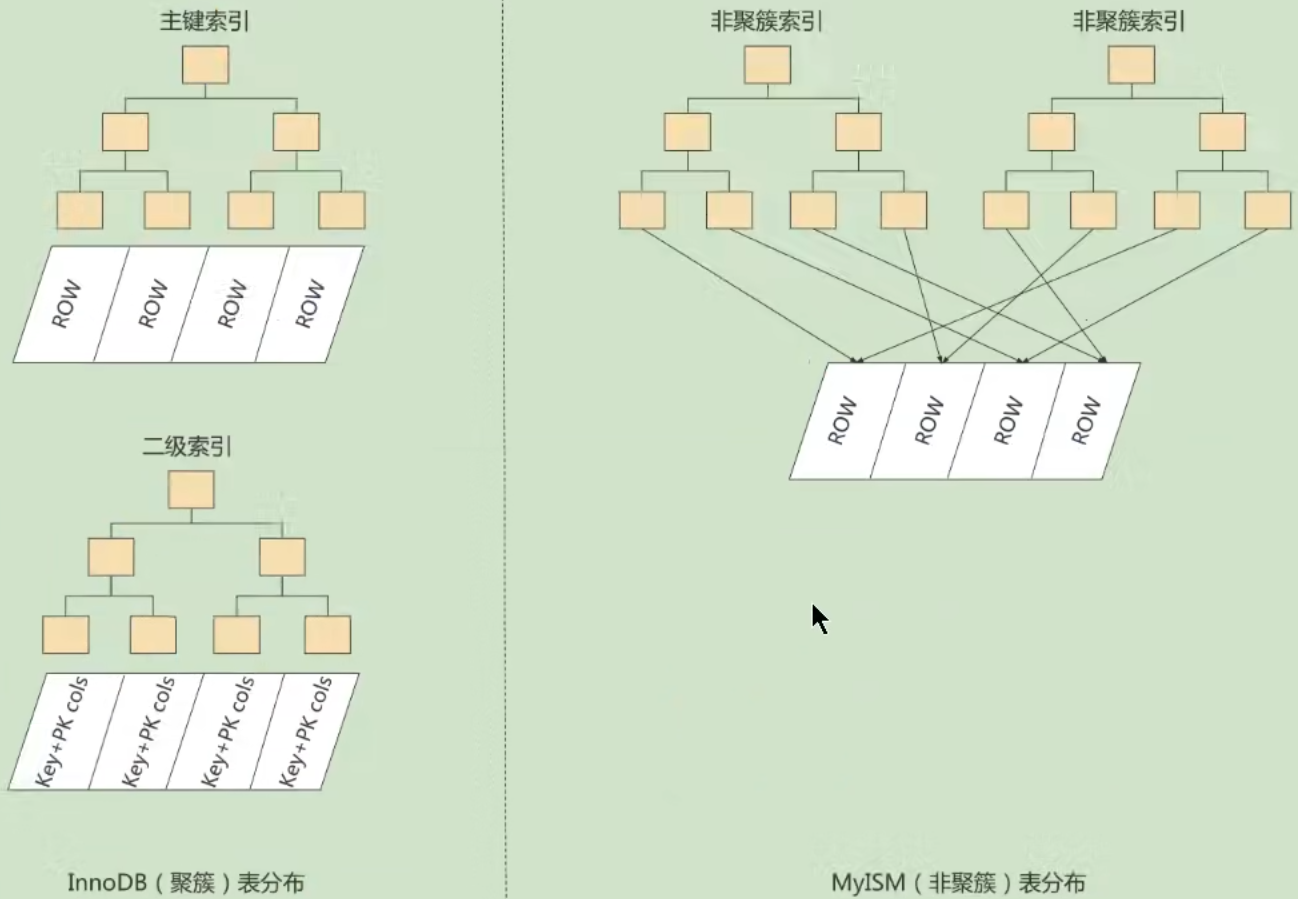
4、索引分类
功能上:普通索引、唯一索引(不可重复)、主键索引(一张表只有一个,唯一且不为空)、全文索引
作用字段数量上:单列(值)索引、联(组)合索引
物理实现上:聚簇索引、非聚簇(二级、辅助)索引
8.0 新增了隐藏索引(Invisible Indexes)和降序索引(Descending Indexes)
5、索引的设计(使用)原则
适合加索引(频繁的,区分度高的)
- 业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引
- 频繁作为 WHERE 查询条件的字段
- 经常 GROUP BY 和 ORDER BY 的列,多个字段就建立联合索引(注意先后顺序和升序降序)
- UPDATE、DELETE 的 WHERE 条件列
- DISTINCT 字段需要创建索引
- 多表 JOIN 连接操作
- 首先,连接表的数量尽量不要超过 3 张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长会非常快,严重影响查询的效率
- 其次,对 WHERE 条件创建索引,因为 WHERE 才是对数据条件的过滤。如果在数据量非常大的情况下,没有 WHERE 条件过滤是非常可怕的
- 最后,对用于连接的字段创建索引,且该字段在多张表中的类型必须一致。若一个为 int 另一个为 varchar,则会发生转换,转换会使用函数,使用函数索引会失效
- 使用列的类型小的创建索引:类型大小指的就是该类型表示的数据范围的大小,能使用 INT 就不要使用 BIGINT,能使用 MEDIUMINT 就不要使用 INT
- 数据类型越小,在查询时进行的比较操作越快
- 数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘 I/O 带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率
- 对于主键来说更加适用,因为不仅聚簇索引中会存储主键值,其他所有二级索引的节点处都会存储记录的主键值,如果主键使用更小的数据类型,就意味着节省更多的存储空间(高效 I/O)
- 使用字符串前缀创建索引
- create table shop(address varchar(120) not null)
- alter table shop add index(address(12))
- select count(distinct left(address, 18))/count(*) as '截取前 18 个字符的选择度', count(distinct left(address, 12))/count(*)as '截取前 12 个字符的选择度' from shop
- 在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度
- 索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90% 以上,可以使用 count(distinct left(列名, 索引长度) / count(*) 的区分度来确定
- 使用索引列前缀的方式无法支持使用索引排序,只能使用文件排序
- 区分度高(散列性高)的列适合作为索引
- 使用公式 select count (distinct a) / count (*) from t1 计算区分度,越接近 1 越好,一般超过 33% 就算是比较高效的索引
- 联合索引把区分度高(散列性高)的列放在前面
- 使用最频繁的列放到联合索引的左侧:这样也可以较少的建立一些索引。同时,由于“最左前缀原则”,可以增加联合索引的使用率
- 在多个字段都要创建索引的情况下,联合索引优于单值索引
不适合加索引
- 在 where 中使用不到的字段,不要设置索引
- 数据量小的表最好不要使用索引,例如不到 1000 行
- 有大量重复数据的列上不要建立索引,比如高于 10% 的时候,不需要对这个字段使用索引
- 避免对经常更新的表创建过多的索引
- 不建议用无序的值作为索引
- 删除不再使用或者很少使用的索引
- 不要定义冗余或重复的索引
建议单张表索引数量不超过 6 个
- 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间越大
- 索引影响 INSERT、DELETE、UPDATE 等语句性能,因为表中数据更改的同时,索引也会进行调整和更新,会造成负担
- 优化器在优化查询时,会根据统一信息,对每个可用的索引进行评估,生成最优的执行计划,若同时有很多索引都可用,会增加优化器生成执行计划的时间,降低查询性能
四、性能分析
Performance Schema Lock Tables
-- 查看当前所有事务 SELECT * FROM information_schema.innodb_trx; -- 查看正在锁的事务 SELECT * FROM performance_schema.data_locks; -- SELECT * FROM information_schema.innodb_locks; -- 查看等待锁的事务 SELECT * FROM performance_schema.data_lock_waits; -- SELECT * FROM information_schema.innodb_lock_waits; -- 查看当前连接 SHOW STATUS LIKE 'Threads%'; -- Threads_connected:打开的连接数 -- Threads_created:表示创建过的线程数 -- Threads_running:激活的连接数(并发数,一般远低于 connected) -- 如果 Threads_created 值过大的话,表明 MySQL 服务器一直在创建线程,可以适当增加 thread_cache_size 值 SHOW VARIABLES LIKE 'thread_cache_size'; -- 查询最大连接数 SHOW VARIABLES LIKE '%max_connections%'; -- 设置最大连接数 SET GLOBAL max_connections=1000; -- 在 /etc/my.cnf 里设置数据库最大连接数 -- [mysqld] -- max_connections = 1000
SHOW STATUS
SHOW [GLOBAL | SESSION] STATUS LIKE '参数' -- last_query_cost:上一条 SQL 语句所需要读取的页的数量 -- Aborted_clients:由于客户没有正确关闭连接已经死掉,已经放弃的连接数量。 -- Aborted_connects:尝试已经失败的 MySQL 服务器的连接的次数。 -- Connections:试图连接 MySQL 服务器的次数。 -- Created_tmp_tables:当执行语句时,已经被创造了的隐含临时表的数量。 -- Delayed_insert_threads:正在使用的延迟插入处理器线程的数量。 -- Delayed_writes:用 INSERT:DELAYED 写入的行数。 -- Delayed_errors:用 INSERT:DELAYED 写入的发生某些错误(可能重复键值)的行数。 -- Flush_commands:执行 FLUSH 命令的次数。 -- Handler_delete:请求从一张表中删除行的次数。 -- Handler_read_first:请求读入表中第一行的次数。 -- Handler_read_key:请求数字基于键读行。 -- Handler_read_next:请求读入基于一个键的一行的次数。 -- Handler_read_rnd:请求读入基于一个固定位置的一行的次数。 -- Handler_update:请求更新表中一行的次数。 -- Handler_write:请求向表中插入一行的次数。 -- Key_blocks_used:用于关键字缓存的块的数量。 -- Key_read_requests:请求从缓存读入一个键值的次数。 -- Key_reads:从磁盘物理读入一个键值的次数。 -- Key_write_requests:请求将一个关键字块写入缓存次数。 -- Key_writes:将一个键值块物理写入磁盘的次数。 -- Max_used_connections:同时使用的连接的最大数目。 -- Not_flushed_key_blocks:在键缓存中已经改变但是还没被清空到磁盘上的键块。 -- Not_flushed_delayed_rows:在 INSERT:DELAY 队列中等待写入的行的数量。 -- Open_tables:打开表的数量。 -- Open_files:打开文件的数量。 -- Open_streams:打开流的数量(主要用于日志记载) -- Opened_tables:已经打开的表的数量。 -- Questions:发往服务器的查询的数量。 -- Slow_queries:要花超过 long_query_time 时间的查询数量。 -- Threads_connected:当前打开的连接的数量。 -- Threads_running:不在睡眠的线程数量。 -- Uptime:服务器工作了多长时间,单位秒。
SHOW PROFILE
-- 查看 profile 是否开启 show variables like '%profiling%'; -- 开启 profile set profiling=1; -- 查看最近一次 sql 的执行周期 show profile; -- 查看最近的几次 show profiles; -- 根据 Query_ID 来查看 sql 的具体执行步骤 show profile cpu,block io for query Query_id;
索引失效的几种情况
-- where 条件有多个字段时,会优先选择多个字段的联合索引,而不会选择多个单个索引 -- 最左前缀:使用联合索引有顺序要求,换言之联合索引的创建有字段顺序之分 -- 主键最好使用递增序列 -- name like ‘a%’ 和 LEFT(name,1) = 'a',函数放在左边会使索引失效,类似还有计算和隐式类型转换等 -- 范围条件右侧的列索引失效:age=30 and id > 10 and name='zs',使用 age,id,name 联合索引会使 name 失效,使用 age,name,id 联合索引就没问题 -- 不等于会使索引失效 -- is null(相当于等于某值)可以使用索引,is not null(相当于不等于某值)不能使用索引,同理 not like 也不能使用索引 -- like '%xxx' 索引失效 -- or 前后存在非索引列,索引失效,必须 or 前后都有索引才会使用索引去查找 -- 库和表字符集不同,索引失效,相当于有隐式转换
JOIN
-- 驱动表(作为外循环,最好用结果集小(表行数*每行大小)的作为驱动表,也就是用小表驱动大表)是主表,被驱动表(作为内循环)是从表、非驱动表。EXPLAIN 结果中上面是驱动表,下面是被驱动表 -- 表连接的实现方式有三种:Simple Nested-Loop Join 简单嵌套循环连接、Index Nested-Loop Join 索引嵌套循环连接、Block Nested-Loop Join 块索引嵌套连接。整体效率:INLJ > BNLJ > SNLJ -- Block Nested-Loop Join 设置:通过 show variables like '%optimizer_switch%' 查看 block_nested_loop(默认开启)。驱动表能否被一次加载完,要看 join_buffer_size,默认 256K。最大值在 32 位系统为 4G,在 64 位可大于 4G(但 Windows 只能为 4G) -- 从 MySQL 8.0.20 版本开始将弃用 BNLJ,引入 Hash Join,默认会使用 Hash Join -- left join 以左表为驱动表,right join 反之,STRAIGHT_JOIN 用在内连接中,强制使用左表当驱动表,改变 mysql 优化器选择的执行计划 -- 尽量用 join 替代子查询
排序、分组、分页
-- where 使用索引是为了避免全表扫描,order by 使用索引是为了避免 FileSort,而使用索引排序。where 和 order by 字段不同时可以建立联合索引。 -- 分页可以影响是否走索引,例如:select * from user order by age 不走索引(因为要全部回表),select * from user order by age limit 3 走索引(回表数据少) -- order by 多个字段顺序不一致时索引会失效 -- where a in (...) order by b,c 不能使用 a,b,c 联合索引 -- sort_buffer_size 可提高效率 -- FileSort 分单路排序和双路排序,mysql 使用单路排序的前提是排序的字段大小要小于 max_length_for_sort_data -- order by 时不要使用 select * -- group by 中 where 效率高于 having
覆盖索引:查询的字段正好是建立索引的字段,这时 != 或 like ‘%xxx’ 条件在不回表的情况下也可能使用索引
索引条件下推(Index Condition Pushdown,简称 ICP):在回表之前进行过滤,没有回表也就不存在索引下推

 浙公网安备 33010602011771号
浙公网安备 33010602011771号