2018-2019-1 20165202 《信息安全系统设计基础》第九周学习总结
本周学习内容
虚拟存储器的概念和作用
虚拟存储器的概念:
- 虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。目前,大多数操作系统都使用了虚拟内存,如Windows家族的“虚拟内存”;Linux的“交换空间”等。
虚拟存储器的作用:
-
内存在计算机中的作用很大,电脑中所有运行的程序都需要经过内存来执行,如果执行的程序很大或很多,就会导致内存消耗殆尽。为了解决这个问题,Window 虚拟存储器s中运用了虚拟内存技术,即拿出一部分硬盘空间来充当内存使用,当内存占用完时,电脑就会自动调用硬盘来充当内存,以缓解内存的紧张。举一个例子来说,如果电脑只有128MB物理内存的话,当读取一个容量为200MB的文件时,就必须要用到比较大的虚拟内存,文件被内存读取之后就会先储存到虚拟内存,等待内存把文件全部储存到虚拟内存之后,跟着就会把虚拟内存里储存的文件释放到原来的安装目录里了。
-
总结起来说:虚拟存储器简化了链接、简化了加载、简化共享和简化存储器分配。
地址翻译的概念
- IP地址耗尽促成了CIDR的开发,但CIDR开发的主要目的是为了有效的使用现有的internet地址。而同时根据RFC 1631(IP Network Address Translator)开发的NAT却可以在多重的internet子网中使用相同的IP,用来减少注册IP地址的使用。
NAT技术使得一个私有网络可以通过internet注册IP连接到外部世界,位于inside网络和outside网络中的NAT路由器在发送数据包之前,负责把内部IP翻译成外部合法地址。内部网络的主机不可能同时于外部网络通信,所以只有一部分内部地址需要翻译。 - NAT的翻译可以采取静态翻译(static translation)和动态翻译(dynamic translation)两种。静态翻译将内部地址和外部地址一对一对应。当NAT需要确认哪个地址需要翻译,翻译时采用哪个地址pool时,就使用了动态翻译。采用portmultiplexing技术,或改变外出数据的源port技术可以将多个内部IP地址影射到同一个外部地址,这就是PAT(port address translator)。
- 当影射一个外部IP到内部地址时,可以利用TCP的load distribution技术。使用这个特征时,内部主机基于round-robin机制,将外部进来的新连接定向到不同的主机上去。注意:load distributiong只有在影射外部地址到内部的时候才有效。
存储器映射的概念
- 计算机硬件部分主要由微处理器(CPU),存储器,输入输出接口,总线等组成。其中存储器是计算机最重要的功能单元之一。最近在学习时经常碰到“存储器映射”这个概念,开始感觉比较抽象,经过思索,逐渐对这个概念有了一点了解,故写出来与大家分享,同时希望大家帮助指正。 存储器是一系列存储单元的集合,一般情况下存储器主要有随机存取存储器RAM(Random Access Memory)和只读存储器ROM(Read Only Memory)两种,随机存取存储器RAM就像黑板一样,可以在里面写上东西,也可以擦掉后再写上新的内容,即既可以读数据也可以写数据。只读存储器ROM事先把规定好的内容存入存储器,只能将规定内容读出,不能改写。无论是RAM还是ROM,为使CPU能准确找到存储有某个信息的存储单元,就必须为这些存储单元分配一个能相互区别的标识,这些标识就是我们通常所说的地址编码。实际情况下,计算机或其他处理器(如ARM,在ARM中内核采用冯。诺依曼结构,即数据和指令共用一个存储器混合编址)在上电或复位之前,存储器只是一些没有地址编码的物理存储器,计算机或嵌入式系统在上电后要想很好的工作,就要求存储器与计算机或处理器所拥有的地址编码资源建立一一映射的关系。一般情况下,处理器设计者会为每一个存储器分配一个数值连续,数目与其存储单元数相等,以16进制表示的自然数的集合作为该存储器的地址编码,这种自然数集合与存储器的对应关系就是存储器映射,可以把存储器映射理解为嵌入式系统上电(复位)时的预备动作。
动态存储器的分配方法
- 动态存储分配,即指在目标程序或操作系统运行阶段动态地为源程序中的量分配存储空间,动态存储分配包括栈式或堆两种分配方式。需要主要的是,采用动态存储分配进行处理的量,并非所有的工作全部放在运行时刻做,编译程序在编译阶段要为其设计好运行阶段存储组织形式,并为每一个数据项安排好它在数据区中的相对位置。
- 主要分为以下5种方法。
首次适应算法(first fit)
- 我们以空闲分区链为例来说明采用 首次适应算法(first fit)时的分配情况。FF 算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。该算法倾向于优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区。这给为以后到达的大作业分配大的内存空间创造了条件。其缺点是低址部分不断被划分,会留下许多难以利用的、很小的空闲分区,而每次查找又都是从低址部分开始,这无疑会增加查找可用空闲分区时的开销。
循环首次适应算法(next fit)
- 该算法是由首次适应算法演变而成的。在为进程分配内存空间时,不再是每次都从链首开始查找,而是从上次找到的空闲分区的下一个空闲分区开始查找,直至找到一个能满足要求的空闲分区,从中划出一块与请求大小相等的内存空间分配给作业。为实现该算法,应设置一起始查寻指针,用于指示下一次起始查寻的空闲分区,并采用循环查找方式,即如果最后一个(链尾)空闲分区的大小仍不能满足要求,则应返回到第一个空闲分区,比较其大小是否满足要求。找到后,应调整起始查寻指针。该算法能使内存中的空闲分区分布得更均匀,从而减少了查找空闲分区时的开销,但这样会缺乏大的空闲分区。
最佳适应算法(Best Fit)
- 算法:将空闲分区链中的空闲分区按照空闲分区由小到大的顺序排序,从而形成空闲分区链。每次从链首进行查找合适的空闲分区为作业分配内存,这样每次找到的空闲分区是和作业大小最接近的,所谓“最佳”。
优点:第一次找到的空闲分区是大小最接近待分配内存作业大小的; - 缺点:产生大量难以利用的外部碎片。
最坏适应算法(Worst Fit)
- 算法:与最佳适应算法刚好相反,将空闲分区链的分区按照从大到小的顺序排序形成空闲分区链,每次查找时只要看第一个空闲分区是否满足即可。
- 优点:效率高,分区查找方便;
- 缺点:当小作业把大空闲分区分小了,那么,大作业就找不到合适的空闲分区。
快速适应算法(quick fit)
- 该算法又称为分类搜索法,是将空闲分区根据其容量大小进行分类,对于每一类具有相同容量的所有空闲分区,单独设立一个空闲分区链表,这样,系统中存在多个空闲分区链表,同时在内存中设立一张管理索引表,该表的每一个表项对应了一种空闲分区类型,并记录了该类型空闲分区链表表头的指针。空闲分区的分类是根据进程常用的空间大小进行划分,如 2 KB、4 KB、8 KB 等,对于其它大小的分区,如 7 KB 这样的空闲区,既可以放在 8 KB 的链表中,也可以放在一个特殊的空闲区链表中。该算法的优点是查找效率高,仅需要根据进程的长度,寻找到能容纳它的最小空闲区链表,并取下第一块进行分配即可。另外该算法在进行空闲分区分配时,不会对任何分区产生分割,所以能保留大的分区,满足对大空间的需求,也不会产生内存碎片。该算法的缺点是在分区归还主存时算法复杂,系统开销较大。此外,该算法在分配空闲分区时是以进程为单位,一个分区只属于一个进程,因此在为进程所分配的一个分区中,或多或少地存在一定的浪费。空闲分区划分越细,浪费则越严重,整体上会造成可观的存储空间浪费,这是典型的以空间换时间的作法。
垃圾收集的概念
- GC中的垃圾,是指的是在内存中不在不再被使用的对象。
常见的垃圾回收算法
-
引用计数算法(无法回收循环引用的对象)
-
标记清除算法
- 分为标记阶段和清除阶段(会产生内存的空间碎片)
- 复制算法(缺点是将系统内存折半,高效性是建立在存活对象少,垃圾对象多的前提下的)
-
在java新生代串行垃圾回收器中,使用了复制算法的思想,新生代分为eden,from,to三个部分。from,to空间成为survivor空间,用于存放未被回收的对象。
-
其中:新生代指得是存放年轻对象的空间。
-
老年代指的是存放垃圾回收存活的对象。
-
在新生代中的垃圾回收中,eden区存活的对象会放在to中,正在使用from中的年轻对象也会被复制到to中,此时eden区与from区可以直接清空。
- 标记压缩法(高效性是建立在大多数的对象都是存活的)
-
用于老年代中的垃圾回收:
-
在标记清除算法中做了优化:从根节点开始,对所有可达对象做了标记。然后将所有的可达对象都压缩到内存的另一边,之后清理边界外的所有空间。
- 分代算法:
- 就是将复制算法与标记压缩法整合到一起。
- 分区算法:
- 将整个内存的对空间划分为连续的不同的小空间,每个小空间都单独的使用,独立的回收。由于对空间越大,一次GC所花费的时间越长,所以会减少GC的时间。
对象回收的情况:
- java提供了四个类型的引用:强引用,软引用,弱引用,虚引用。
-
强引用所指的对象在任何时候都不会被GC回收。
-
GC未必会回收软引用的对象吗,但是当内存资源紧张时,软引用的对象会被回收。
-
在GC中还要发现弱引用就会被回收。
-
一个虚引用随时随地都会被回收。
新生代与老年代GC的区别:
新生代GC比较频繁,但是持续的时间较短。
老年代GC发生次数少,但是持续的时间比较长。
垃圾回收器的分类:
- 串行回收器
- 单线程进行垃圾回收的回收器,对于并性能力较弱的计算机来说,性能比较好,是最古老的垃圾回收器。在串行收集器回收时,所有的线程都需要暂停,等待垃圾回收的完成。“stop the world”。
- 并行回收器
- 采用多个线程进行垃圾回收,对于并行能力强的计算机,可以有效的缩短垃圾回收的时间。
- CMS回收器
- 主要关注于系统的停顿时间。意为并发标记清除。使用的是标记清除算法。同时他又是一个使用多线程并行回收的回收器。
C语言中与存储器有关的常见错误
-
- 间接引用坏指针
-
- 读未初始化的存储器
-
- 允许栈缓冲区溢出
-
- 假设指针和它们指向的对象是相同大小的
-
- 造成错位错误
-
- 引用指针,而不是它所指向的对象
-
- 误解指针运算
-
- 引用不存在的变量
-
- 引用空堆块中的数据
-
- 引起存储器泄露
本周学习问题总结
问题1:
- 通过DRAM中的页表来进行地址翻译的速度无法满足需求。而TLB作为SRAM的一部分,速度是快于页表查询的。TLB的实际作用,做一个映射,将VPN在TLB中寻找,找到对应的PPN。那么对于TLB是怎么做的映射的呢?
解决方案1:
- 这时候就要说明一下VPN对于TLB来说可以分成那几块,如下图所示:
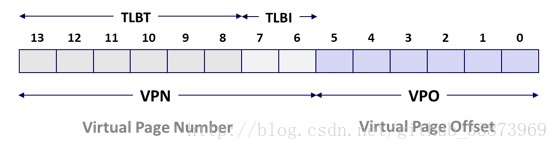
- 可以看见VPN被分为(TLBT:TLB标记,TLBI:TLB索引)
- 这是再看看TLB的结构图:
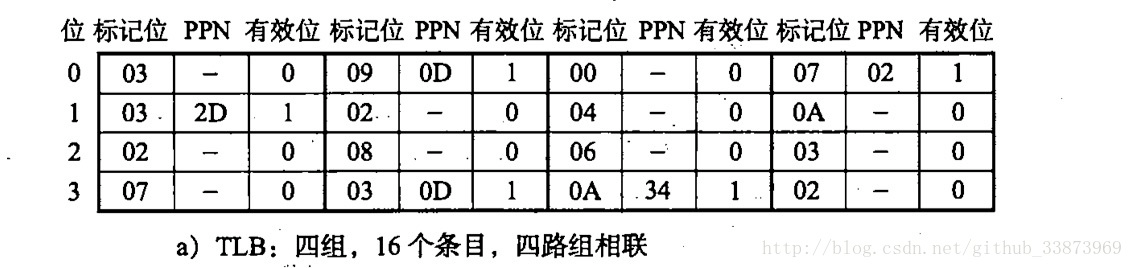
- TLBI的两位就说明该选TLB的那一组,前面的6位TLBT说明标记位。
问题2:
- 得到了物理地址,那么通过物理地址又怎么在物理存储器中寻找到我们想要的数据呢?
解决方案2:
- 首先来看一下我们的物理地址分成那几个部分:
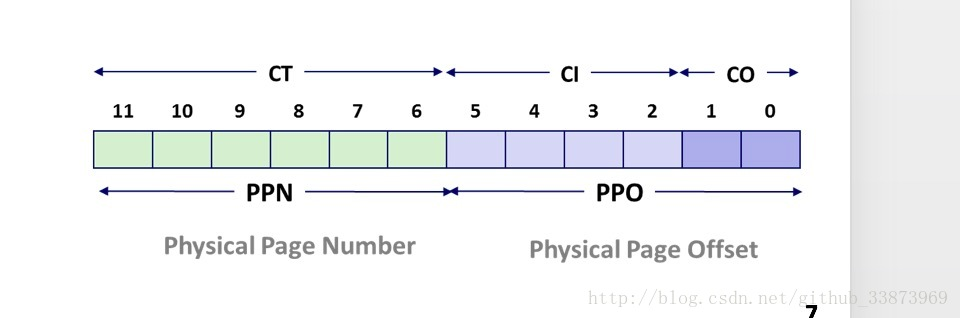
- 可以看到物理地址被分成了三个部分:CO(块偏移),CI(索引),CT(标签)三个部分
- 物理存储器的结构请看下图:

- 物理地址先找到CI索引,找到对应的set集合,然后判断这个集合的valid bit是否等于一并且tag是否与CT一致。如果这些条件都符合,在通过CO偏移找到想要的数据。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 20篇 | 400小时 | |
| 第一周 | 100/100 | 1/1 | 5/5 | |
| 第二周 | 100/200 | 2/3 | 5/10 | |
| 第三周 | 100/300 | 2/5 | 5/15 | |
| 第四周 | 100/400 | 1/6 | 5/20 | |
| 第六周 | 100/500 | 1/7 | 5/25 | |
| 第七周 | 100/600 | 1/8 | 5/30 | |
| 第八周 | 800/1400 | 3/11 | 10/40 | |
| 第九周 | 1000/2400 | 3/14 | 15/55 | |
| 第十一周 | 300/2700 | 2/16 | 20/75 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号