
102302145 黄加鸿 数据采集与融合技术作业3
作业3
作业①
1)代码与结果
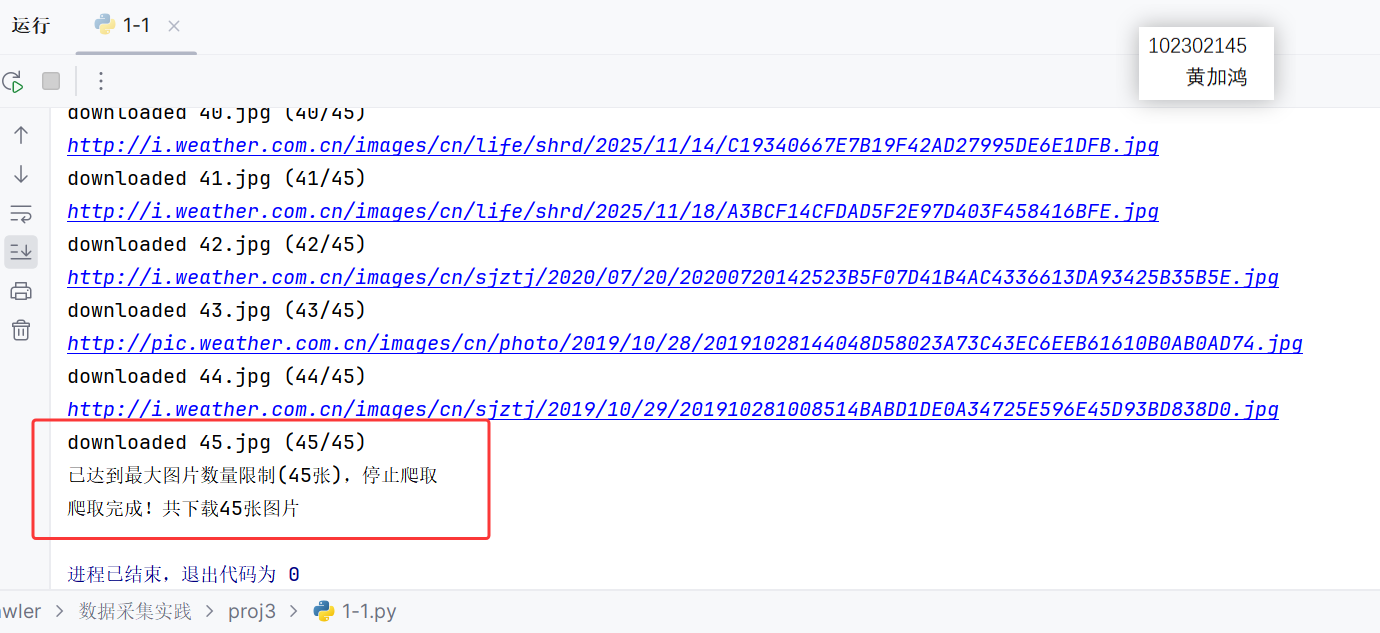
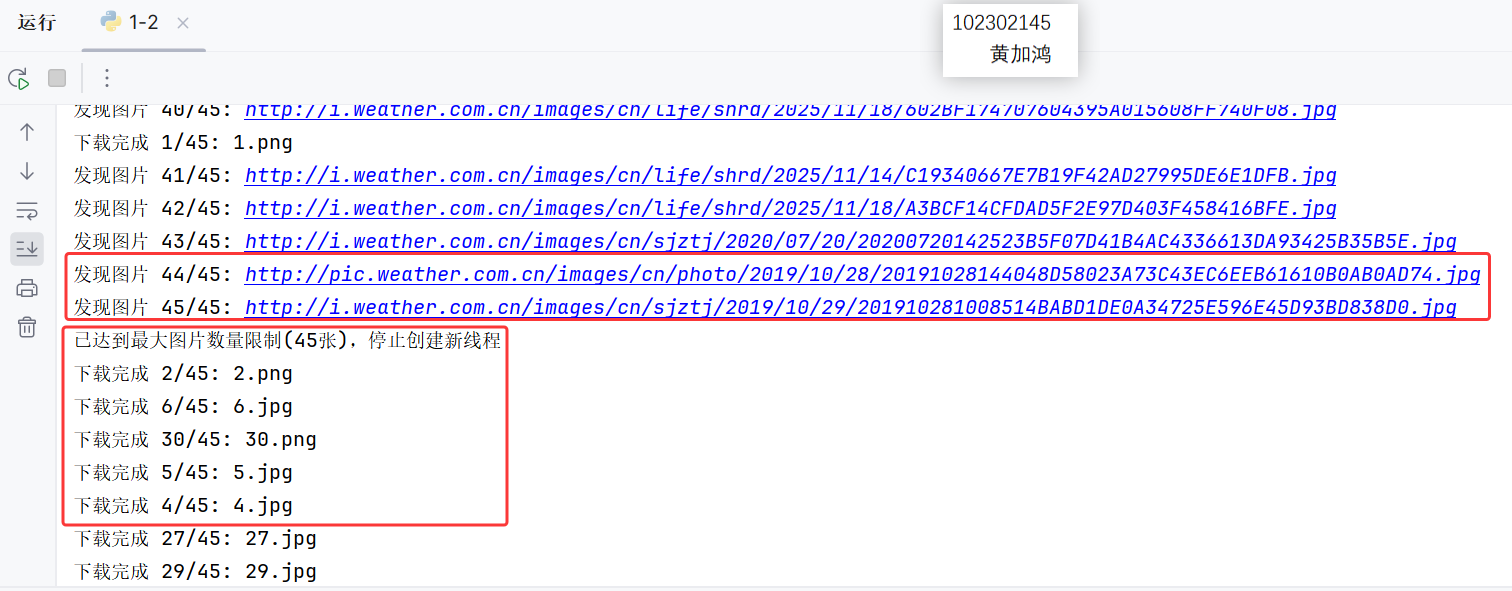
中国气象网此前已经过分析,不再赘述,本次任务目标是实现单线程和多线程爬取指定数目(最大45张)的图像并保存至本地。
网站:http://www.weather.com.cn/weather/101280601.shtml
核心代码
单线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import os
def imageSpider(start_url):
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
# 检查是否达到最大数量
if count >= MAX_IMAGES:
print(f"已达到最大图片数量限制({MAX_IMAGES}张),停止爬取")
return
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
if count >= MAX_IMAGES:
return
count = count + 1
if "." in url.split("/")[-1]:
ext = "." + url.split(".")[-1]
else:
ext = ".jpg" # 默认扩展名
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
# 确保缩进正确
with open("images\\" + str(count) + ext, "wb") as fobj:
fobj.write(data)
print("downloaded " + str(count) + ext + f" ({count}/{MAX_IMAGES})")
except Exception as err:
print(err)
# 配置参数
start_url = "http://www.weather.com.cn/weather/101280601.shtml"
MAX_IMAGES = 45
count = 0
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.8151 SLBChan/111 SLBVPV/64-bit"
}
# 创建图片目录
if not os.path.exists("images"):
os.makedirs("images")
print(f"开始爬取图片,最多爬取{MAX_IMAGES}张...")
imageSpider(start_url)
print(f"爬取完成!共下载{count}张图片")
多线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import os
# 创建线程锁和全局变量
lock = threading.Lock()
MAX_IMAGES = 45
def imageSpider(start_url):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
# 检查是否达到最大数量
with lock:
if count >= MAX_IMAGES:
print(f"已达到最大图片数量限制({MAX_IMAGES}张),停止创建新线程")
break
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
# 使用线程锁保护count变量
with lock:
if count >= MAX_IMAGES:
break
current_count = count + 1
count = current_count
print(f"发现图片 {current_count}/{MAX_IMAGES}: {url}")
T = threading.Thread(target=download, args=(url, current_count))
T.start()
threads.append(T)
except Exception as err:
print(f"解析图片时出错: {err}")
except Exception as err:
print(f"爬取页面时出错: {err}")
def download(url, current_count):
try:
if current_count > MAX_IMAGES:
return
if "." in url.split("/")[-1]:
ext = "." + url.split(".")[-1].lower()
# 限制扩展名长度
if len(ext) > 5:
ext = ".jpg"
else:
ext = ".jpg" # 默认扩展名
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
# 使用with语句确保文件正确关闭
with open("images\\" + str(current_count) + ext, "wb") as fobj:
fobj.write(data)
print(f"下载完成 {current_count}/{MAX_IMAGES}: {str(current_count) + ext}")
except Exception as err:
print(f"下载图片时出错: {err}")
# 主程序
start_url = "http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.8151 SLBChan/111 SLBVPV/64-bit"
}
count = 0
threads = []
if not os.path.exists("images"):
os.makedirs("images")
print(f"开始多线程爬取图片,最多爬取{MAX_IMAGES}张...")
imageSpider(start_url)
# 等待所有线程完成
for t in threads:
t.join()
print(f"爬取完成!共下载{min(count, MAX_IMAGES)}张图片")
print("The End")
运行结果
单线程:
多线程:
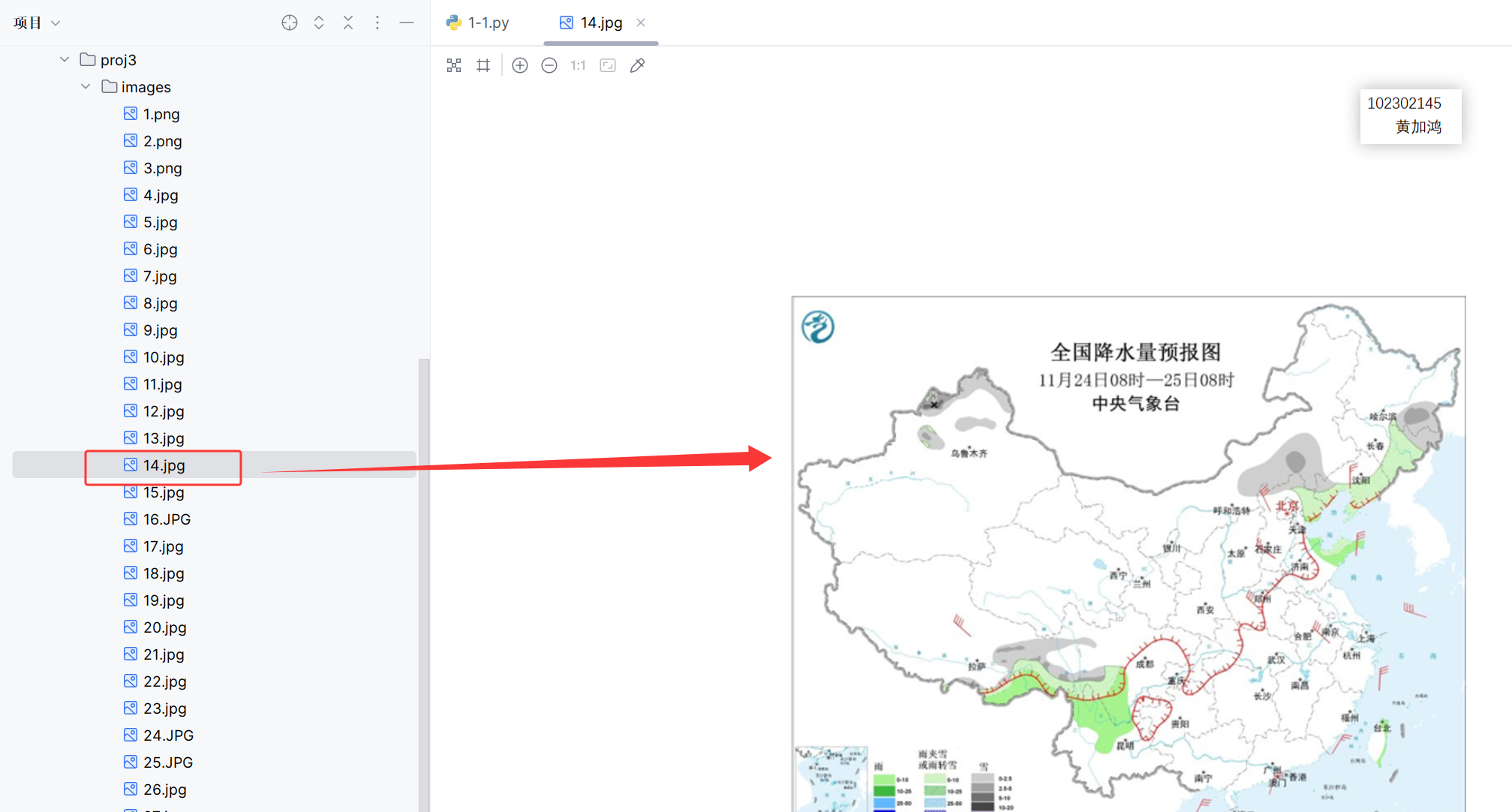
查看图片保存情况:
2)心得体会
学会了用单线程或多线程改进爬虫程序。
3)Gitee链接
· https://gitee.com/jh2680513769/2025_crawler_project/tree/master/%E4%BD%9C%E4%B8%9A3/q1
作业②
1)代码与结果
目标:使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息
网站:https://quote.eastmoney.com/center/gridlist.html#hs_a_board
核心代码
items:
import scrapy
class StockItem(scrapy.Item):
# define the fields for your item here like:
sNum = scrapy.Field() # 序号
sCode = scrapy.Field() # 股票代码
sName = scrapy.Field() # 股票名称
sNewest = scrapy.Field() # 最新价
sUpdown = scrapy.Field() # 涨跌幅
sUpdown_num = scrapy.Field() # 涨跌额
sTurnover = scrapy.Field() # 成交量(手)
sAmplitude = scrapy.Field() # 振幅
spider:
def parse(self, response):
page = response.meta['page']
self.logger.info(f'开始解析第 {page} 页数据')
# 方法一:使用XPath提取JSONP响应中的JSON部分
# 首先获取整个响应文本
response_text = response.xpath('//text()').get()
if response_text:
structure_data = self.parse_jsonp(response_text)
if structure_data:
# 方法二:如果API返回的是纯JSON(非JSONP),可以直接用XPath
# 但这里我们仍然用JSON解析,因为数据是JSONP格式
if 'data' in structure_data and 'diff' in structure_data['data']:
stocks = structure_data['data']['diff']
global_num = (page - 1) * 20
if page == 1:
self.logger.info(
f"{'序号':<6}{'代码':<12}{'名称':<12}{'最新价':<8}{'涨跌幅':<8}{'涨跌额':<8}{'成交量(手)':<8}{'振幅':>6}")
for i, stock in enumerate(stocks):
item = StockItem()
global_num += 1
# 使用类XPath的嵌套字典访问方式
code = stock.get('f12', '')
name = stock.get('f14', '')
# 处理数值数据
f2 = stock.get('f2', 0)
newest = f"{f2 / 100:.2f}" if f2 else "0.00"
f3 = stock.get('f3', 0)
updown = f"{f3 / 100:.2f}%" if f3 else "0.00%"
f4 = stock.get('f4', 0)
updown_num = f"{f4 / 100:.2f}" if f4 else "0.00"
f5 = stock.get('f5', 0)
turnover = f"{f5 / 10000:.2f}万" if f5 else "0.00万"
f7 = stock.get('f7', 0)
amplitude = f"{f7 / 100:.2f}%" if f7 else "0.00%"
item['sNum'] = str(global_num)
item['sCode'] = code
item['sName'] = name
item['sNewest'] = newest
item['sUpdown'] = updown
item['sUpdown_num'] = updown_num
item['sTurnover'] = turnover
item['sAmplitude'] = amplitude
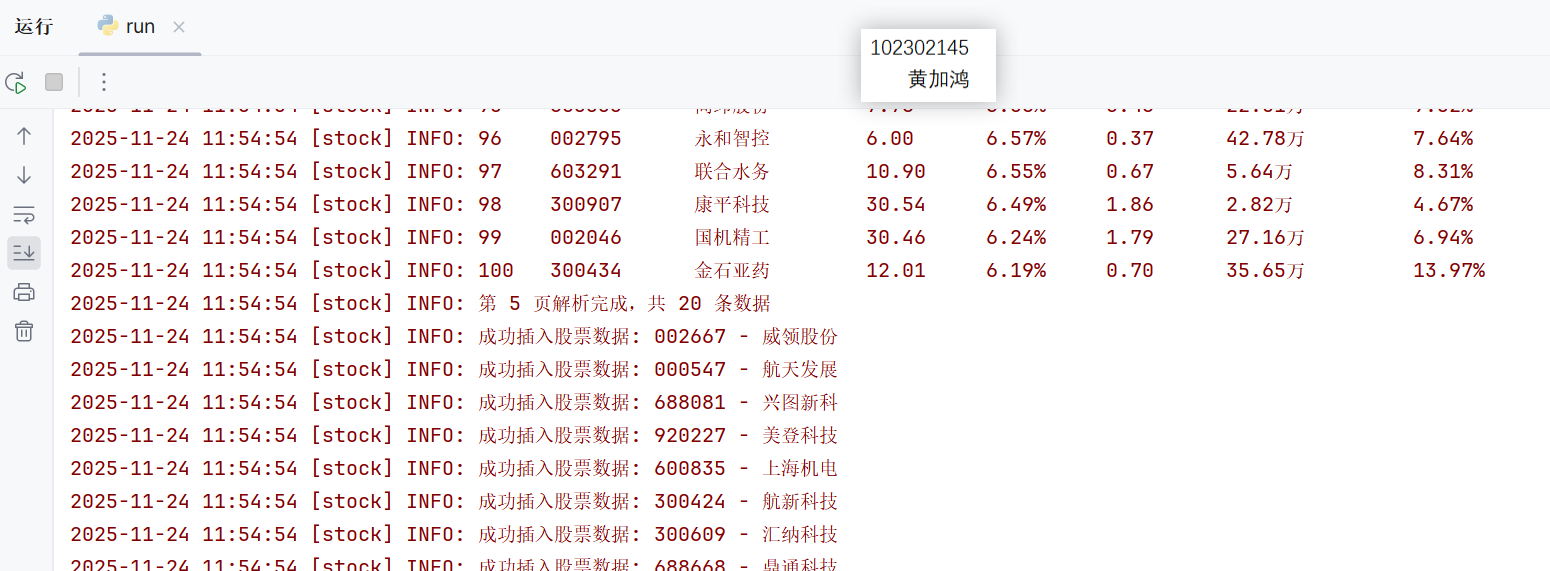
if global_num <= 10 or global_num >= 90:
self.logger.info(
"%-6d%-12s%-12s%-10s%-10s%-10s%-15s%-10s" % (
global_num, code, name, newest, updown, updown_num, turnover, amplitude
)
)
yield item
self.logger.info(f'第 {page} 页解析完成,共 {len(stocks)} 条数据')
if page < 5:
self.logger.info("... ...")
else:
self.logger.error(f'第 {page} 页数据结构异常')
else:
self.logger.error(f'第 {page} 页响应为空')
pipelines:
class SQLitePipeline:
def __init__(self, sqlite_path):
self.sqlite_path = sqlite_path
@classmethod
def from_crawler(cls, crawler):
return cls(
sqlite_path=crawler.settings.get('SQLITE_PATH', './stocks.db')
)
def open_spider(self, spider):
# 确保目录存在
os.makedirs(os.path.dirname(self.sqlite_path), exist_ok=True)
self.connection = sqlite3.connect(self.sqlite_path)
self.cursor = self.connection.cursor()
self.create_table()
# 清空表数据(保持与原代码一致的行为)
self.cursor.execute("DELETE FROM stocks")
self.connection.commit()
def close_spider(self, spider):
self.connection.commit()
self.connection.close()
def create_table(self):
create_table_sql = """
CREATE TABLE IF NOT EXISTS stocks (
sNum VARCHAR(16),
sCode VARCHAR(16),
sName VARCHAR(32),
sNewest VARCHAR(16),
sUpdown VARCHAR(16),
sUpdown_num VARCHAR(16),
sTurnover VARCHAR(32),
sAmplitude VARCHAR(16),
CONSTRAINT pk_stocks PRIMARY KEY (sCode)
)
"""
self.cursor.execute(create_table_sql)
self.connection.commit()
def process_item(self, item, spider):
try:
insert_sql = """
INSERT INTO stocks (sNum, sCode, sName, sNewest, sUpdown, sUpdown_num, sTurnover, sAmplitude)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
"""
self.cursor.execute(insert_sql, (
item['sNum'],
item['sCode'],
item['sName'],
item['sNewest'],
item['sUpdown'],
item['sUpdown_num'],
item['sTurnover'],
item['sAmplitude']
))
self.connection.commit()
spider.logger.info(f"成功插入股票数据: {item['sCode']} - {item['sName']}")
except Exception as e:
spider.logger.error(f"插入数据失败: {e}")
# 如果主键冲突,使用更新操作
try:
update_sql = """
UPDATE stocks
SET sNum=?, sName=?, sNewest=?, sUpdown=?, sUpdown_num=?, sTurnover=?, sAmplitude=?
WHERE sCode=?
"""
self.cursor.execute(update_sql, (
item['sNum'],
item['sName'],
item['sNewest'],
item['sUpdown'],
item['sUpdown_num'],
item['sTurnover'],
item['sAmplitude'],
item['sCode']
))
self.connection.commit()
spider.logger.info(f"成功更新股票数据: {item['sCode']} - {item['sName']}")
except Exception as update_err:
spider.logger.error(f"更新数据也失败: {update_err}")
return item
运行结果
查看输出:
查看数据库保存情况:
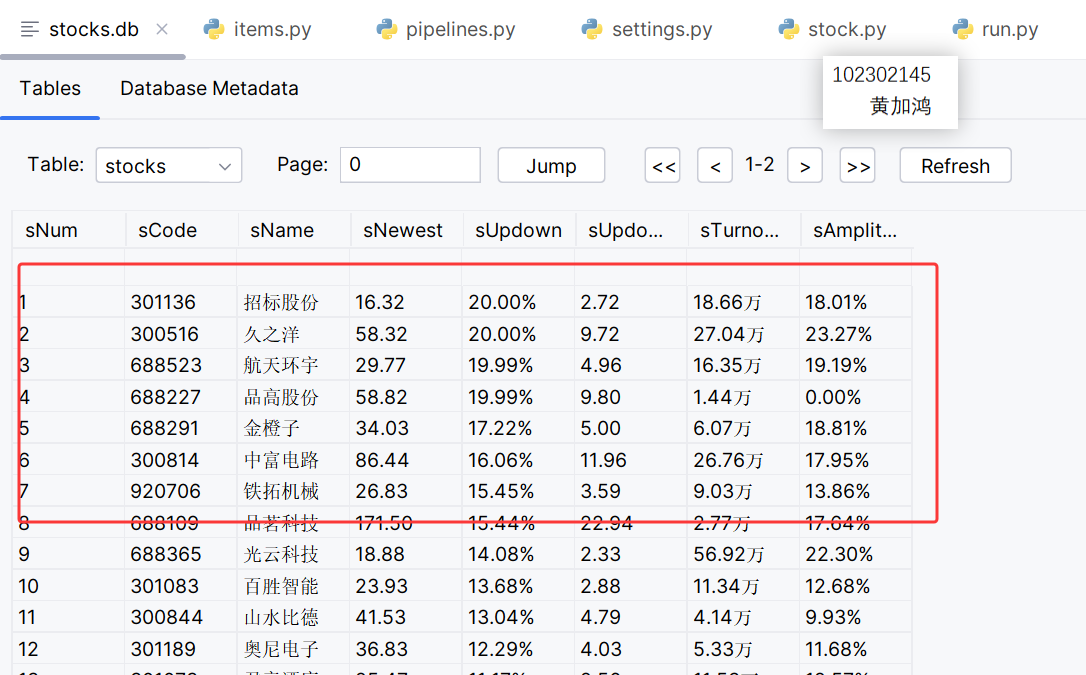
2)心得体会
基本学会了用scrapy+xpath+sql的技术路线,实际自己动手过程中,在提取信息方面并没有完全使用xpath方法,还是沿用了之前的json提取,因为api返回的数据格式显然更适合使用json提取的方式。
3)Gitee链接
·https://gitee.com/jh2680513769/2025_crawler_project/tree/master/%E4%BD%9C%E4%B8%9A3/stocks_scrapy
作业③
1)代码与结果
目标:使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据
网站:https://www.boc.cn/sourcedb/whpj/
网页分析
先对网页简单分析,定位到要爬取的元素
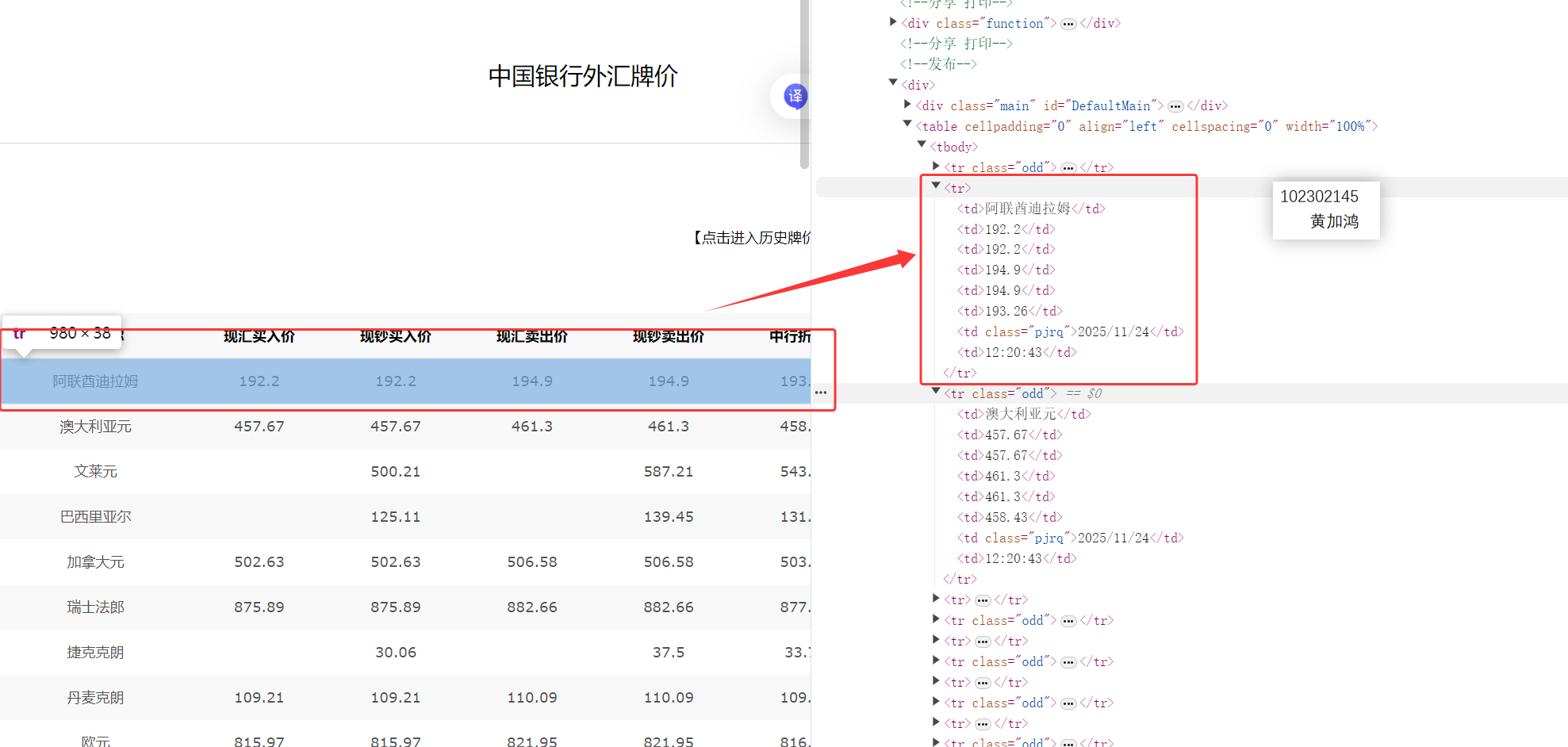
核心代码
items:
import scrapy
class ForexItem(scrapy.Item):
# define the fields for your item here like:
currency_name = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价 (Telegraphic Transfer Buying Price)
cbp = scrapy.Field() # 现钞买入价 (Cash Buying Price)
tsp = scrapy.Field() # 现汇卖出价 (Telegraphic Transfer Selling Price)
csp = scrapy.Field() # 现钞卖出价 (Cash Selling Price)
reference_rate = scrapy.Field() # 中行折算价
date = scrapy.Field() # 发布日期
time = scrapy.Field() # 发布时间
spider:
import scrapy
from forex_scrapy.items import ForexItem
class ForexSpider(scrapy.Spider):
name = 'forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
self.logger.info('开始解析外汇数据页面')
# 使用XPath定位表格中的所有数据行(跳过表头)
rows = response.xpath('//table[@cellpadding="0" and @cellspacing="0"]/tr[position()>1]')
self.logger.info(f'找到 {len(rows)} 行外汇数据')
# 打印表头
self.logger.info(
f"{'货币名称':<12}{'现汇买入价':<10}{'现钞买入价':<10}{'现汇卖出价':<10}{'现钞卖出价':<10}{'中行折算价':<10}{'日期':<12}{'时间':<10}")
self.logger.info("-" * 90)
for i, row in enumerate(rows):
item = ForexItem()
# 使用XPath提取每个字段
# 货币名称 - 第一个td
item['currency_name'] = row.xpath('./td[1]/text()').get()
# 现汇买入价 - 第二个td
item['tbp'] = row.xpath('./td[2]/text()').get()
# 现钞买入价 - 第三个td
item['cbp'] = row.xpath('./td[3]/text()').get()
# 现汇卖出价 - 第四个td
item['tsp'] = row.xpath('./td[4]/text()').get()
# 现钞卖出价 - 第五个td
item['csp'] = row.xpath('./td[5]/text()').get()
# 中行折算价 - 第六个td
item['reference_rate'] = row.xpath('./td[6]/text()').get()
# 发布日期 - 第七个td(可能有class="pjrq")
date = row.xpath('./td[7][@class="pjrq"]/text()').get()
if not date:
date = row.xpath('./td[7]/text()').get()
item['date'] = date
# 发布时间 - 第八个td
item['time'] = row.xpath('./td[8]/text()').get()
# 处理空值
for field in ['tbp', 'cbp', 'tsp', 'csp', 'reference_rate']:
if not item[field]:
item[field] = 'N/A'
# 打印前10条和后10条数据(如果数据量大的话)
if i < 10 or i >= len(rows) - 10:
self.logger.info(
f"{item['currency_name']:<12}"
f"{item['tbp']:<10}"
f"{item['cbp']:<10}"
f"{item['tsp']:<10}"
f"{item['csp']:<10}"
f"{item['reference_rate']:<10}"
f"{item['date']:<12}"
f"{item['time']:<10}"
)
yield item
self.logger.info('外汇数据解析完成')
def closed(self, reason):
self.logger.info(f'爬虫结束: {reason}')
运行结果
查看输出:
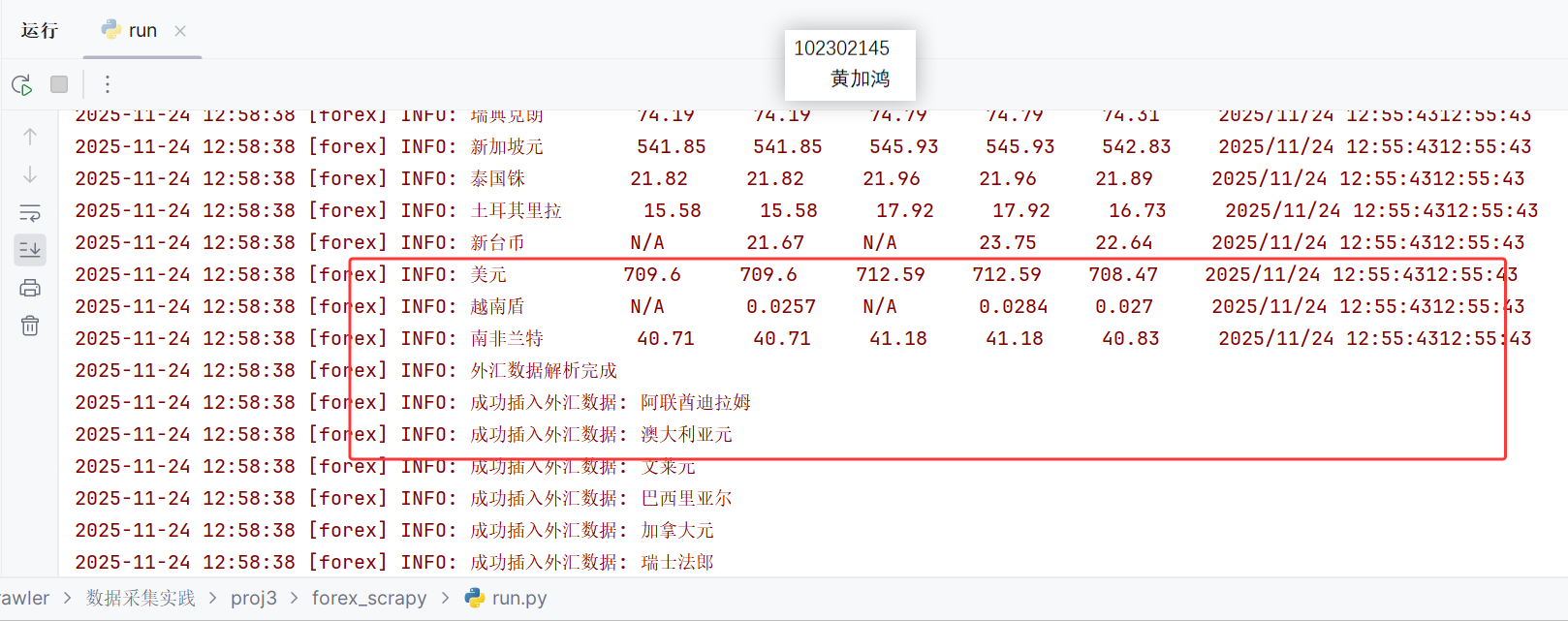
查看数据库保存情况:
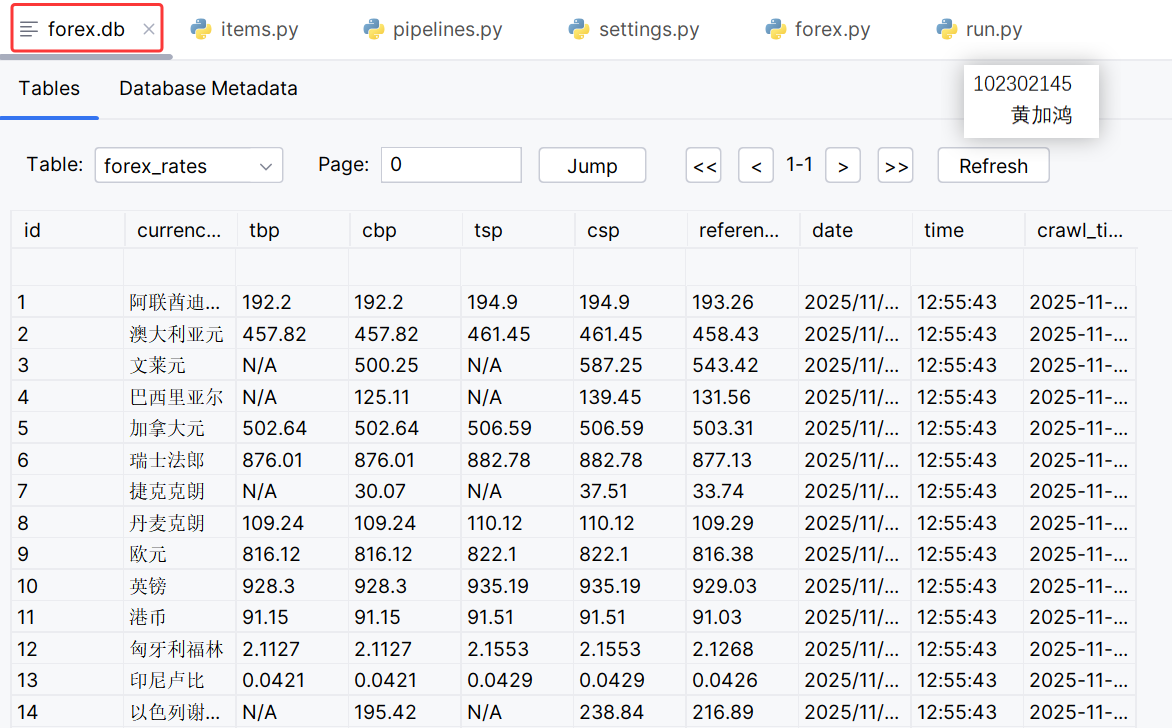
2)心得体会
巩固了scrapy+xpath+sql技术路线,这回提取信息就基本使用的xpath方法,发现了xpath提取信息与CCS、beautifulsoup等方法的异同点,text()可以很方便的获取到文本值。
3)Gitee链接
·https://gitee.com/jh2680513769/2025_crawler_project/tree/master/%E4%BD%9C%E4%B8%9A3/forex_scrapy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号