分布式事务
2pc
两个阶段 投票和事务提交
第一阶段:投票
leader 就是检录员
- leader 发送执行请求
- 所有节点收到请求开始执行,但是执行完不提交,写入事务日志,向leader 发送自己成功执行,自己阻塞等待 leader 的后续指令
- leader 如果收到 一个失败请求 就向所有节点发送回滚
第二阶段:事务提交
经过第一阶段的协调者询问之后,各个参与者回复自己事务的执行情况,存在三种可能:
- 所有参与者都回复能正常执行事务
- 一个或者多个参与者回复事务执行失败
- 协调者等待超时
对于 ① 这种情况来说, leader 就会发送事务提交消息,所有节点就会提交。
但是 其他情况就是 leader 发送事务回滚。
出现的问题
两阶段提交协议原理简单、易于实现,但是缺点也是显而易见的,包含如下:
- ** 单点问题:**leader 挂了,所有节点都在等着leader 发送
commit || rollback消息,都堵塞住了 - ** 同步阻塞**,所有节点在发送完消息都在等待
leader发送消息 - ** 数据不一致性:**节点 收到消息 由于网络
commit消息没有接收到。
总结一下:
就是因为所有的参与者都知识告诉 Leader 自己的状态,,当Leader没有发送给命令时,无法得知其他人的状态。
针对上述问题可以引入 超时机制 和 互询机制 在很大程度上予以解决。
- 协调者 -- 超时机制: 对于协调者来说如果在指定时间内没有收到所有参与者的应答,则可以自动退出 WAIT 状态,并向所有参与者发送 rollback 通知。对于参与者来说如果位于 READY 状态,(对于 节点而言,不能使用超时机制,是因为 如果 节点可能因为网路原因没有收到
commmit消息,但是我们不能 回滚,否则数据不一致)
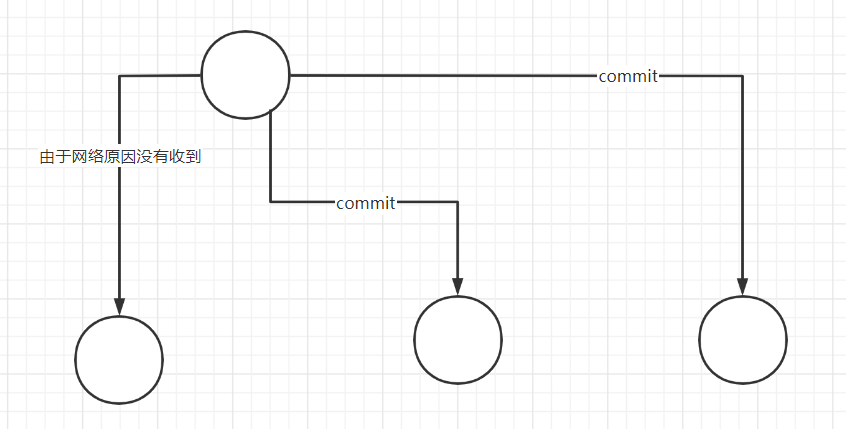
- 所以 节点之间采用
互询的方式来同步。
3pc
针对两阶段提交存在的问题,三阶段提交协议通过引入一个 预询盘 阶段,以及超时策略来减少整个集群的阻塞时间,提升系统性能。三阶段提交的三个阶段分别为:预询盘(can_commit)、预提交(pre_commit),以及事务提交(do_commit)。
第一阶段:预询盘
该阶段协调者会去询问各个参与者是否能够正常执行事务,参与者根据自身情况回复一个预估值,相对于真正的执行事务,这个过程是轻量的,具体步骤如下
- 发送事务查询消息,询问事务能否正常执行,等待回复
- 各个参与者依据自身状况回复一个预估值,如果预估自己能够正常执行事务就返回确定信息,并进入预备状态,否则返回否定信息
第二阶段:预提交
本阶段协调者会根据第一阶段的询盘结果采取相应操作,询盘结果主要有 3 种:
- 所有都正常 (下来操作来 2pc 一样 发送执行,等待)
- 一个或多个参与者返回否定信息。
- 协调者等待超时。
在上述步骤中,如果参与者等待超时,则会中断事务。 针对第 2 和第 3 种情况,协调者认为事务无法正常执行,于是向各个参与者发出 abort 通知,请求退出预备状态,具体步骤如下:
- 协调者向所有事务参与者发送 abort 通知;
- 参与者收到通知后中断事务。
第三阶段:事务提交
如果第二阶段事务未中断,那么本阶段协调者将会依据事务执行返回的结果来决定提交或回滚事务,分为 3 种情况:
- 所有都正常
- 一个或多个参与者返回否定信息。
- 协调者等待超时
针对第 1 种情况,协调者向各个参与者发起事务提交请求,具体步骤如下:
- 协调者向所有参与者发送事务
commit通知; - 所有参与者在收到通知之后执行
commit操作,并释放占有的资源; - 参与者向协调者反馈事务提交结果。
针对第 2 和 3 种情况,协调者认为事务无法成功执行,于是向各个参与者发送事务回滚请求,具体步骤如下:
- 协调者向所有参与者发送事务 rollback 通知
- 所有参与者在收到通知之后执行 rollback 操作,并释放占有的资源
- 参与者向协调者反馈事务回滚操作
在本阶段如果协调者或者网络问题,导致参与者迟迟不能收到来自协调者的 commit 或者 rollback 请求,那么参与者将不会如两阶段提交中那样陷入阻塞,而是等待超时后继续 commit,相对于两阶段提交虽然降低了同步阻塞,但是还是无法完全避免数据的不一致
问题
- 仍然存在单点故障的问题,如果协调者节点出现故障,那么整个事务将无法继续进行。此外,在网络分区的情况下,3PC 可能会导致一些数据不一致的问题,需要额外的机制来解决。
- 3PC 与 2PC 相比,虽然解决了两阶段阻塞问题,但仍然存在第三阶段阻塞的问题。在预备提交阶段和提交阶段之间,如果协调者节点发生故障,那么参与者节点可能会出现阻塞的情况,无法进一步完成事务的提交,从而导致事务的失败。因此,3PC 仍然存在可用性和性能等方面的问题,需要根据具体的应用场景来选择合适的分布式事务协议。
precolator
大体流程:
有三个角色,分配时间戳,拥有主键的节点,其他节点。
读取
- p
- 有就失败,准备清理
![14782C6F.png]()
- 有就失败,准备清理
- 读取小于 ts 的最新的 commit 的数据

写:
Prewrite
- 获取时间戳 startTs
- 检查是否有之前(<startTs)未释放的
![148987CB.png]()
- 如果有立即返回即可
- 获取每个key最近的write
- 如果commitTs是在 startTs 之后,那么就算失败。表明中间这段时间被别人抢占先机了。(不能改变过去的数据,需要重新开始一轮)
- 写入(可以利用一致性算法同步),加锁 lock.ts = startTs

Commit
- 检查是否重复提交
- 获取最新的 write 列, 检查startTs 是否是preWrite的startTs,如果 write.Kind != RollBack,说明我们已经提交过了,退出即可
- 检查
![1493A48A.png]()
- 锁是否存在
- lock.Ts 是否为 preWrite 的 startTs。
- 其中有一个不满足,则需要退出。
- 清理锁,并写入 write 列。

当时失败时,需要回滚,我们需要向 write 列插入一条 startTs 为当前事务的 startTs,并且 writeKind = RollBack,我们辨别在rollback 之后收到同一个事务的 prewrite请求。
锁的结构
type Lock struct {
Primary []byte
Ts uint64
Ttl uint64
Kind WriteKind
}
// lock.Ts + ttl < ts -> return nil
清理![1478499C.png]()

| primary | 超时就清理 |
|---|---|
| secondary | 主锁 commit ,提交 |
| 主锁未 commit 超时,清理 | |
| 未commit 未超时,不做处理 |
解决![14EC1190.png]() 冲突
冲突
 冲突
冲突获取锁住的key进行批量回滚
- 获取 key 的当前写 ( write.startTs = txn.startTs),如果有 write的话
- 如果 kind = rollback继续
- 说明之前没有写入 rollback, abort
- 获取锁
- 如果不是当前事务的锁,或者没有锁,往 write 写入回滚
- 删除lock,default,添加回滚。
崩溃恢复
切记: 一切提交以拥有pk的节点为主,想一想2pc的缺点,不就是只告诉 leader 自己的状态,而 precolator 恰恰相反。
所有的 都是 lazy 删除的。
都是 lazy 删除的。
当其他节点发现自己有锁时,会查找 Primay 字段,通过询问拥有该pk的节点,从而得知pk的锁是否还在,如果存在,当然判断是否需要清理锁。如果不存在,那就说明有可能提交,有可能清理,看write列,如果write列的startTs是否为自己的事务的startTs以及Kind是否为RollBack,如果不是,那么就说明已经提交了。检验完成顺便清理自己的锁。
检查事务状态
- 获取当前主锁的 write 列 ( write.startTs = txn.startTs)
- 如果不是 rollback,返回 commitTs
- 现在是 rollback, 获取 lock
- 如果没有锁 或者过期,那么回滚

 浙公网安备 33010602011771号
浙公网安备 33010602011771号