
小白给小白详解维特比算法(二)
https://blog.csdn.net/athemeroy/article/details/79342048
本文致力于解释隐含马尔科夫模型和上一篇我们提到的篱笆网络的最短路径问题的相同点和不同点,尽量通俗易懂但是也有些必要的公式。如果你有数学恐惧症,请无视所有的“注”。我的概率论学的很烂,如果“注”里面有错误,请务必直接喷,不要留情,谢谢!
隐马尔科夫模型(HMM)和篱笆网络(神马关系)
咱先别”隐身”,先说说啥是马尔科夫模型?
隐马尔科夫模型,一听这个名字就和马尔科夫模型有着隐藏的联系。
所谓的马尔科夫模型,其实说的就是好好一个人,是怎么变来变去的(旁白:???)。比如说,一个人某一天可能轻微感冒,也可能正常,还可能重感冒(请原谅我对病不是很了解)。如果你认为这个是上天随机抛硬币决定的倒也可以,比如我们可以认为:
P(身体状态=正常)=0.7
P(身体状态=轻感冒)=0.2
P(身体状态=重感冒)=0.1
- 1
- 2
- 3
但是可能更多的,某一天的身体状态是由这个人长期以来作出来的……啊不是,是和前一天(或者N天)的身体状态变来的。比如正常可能会更大概率让第二天依然正常,而轻感冒比正常更容易让第二天表现为重感冒。
如果我们认为某一天的身体状态完全由前一天的身体状态来决定(这叫做一阶马尔科夫假设,这算是这个世界上最不负责任的10000个假设之一了,好在很多情况下这种假设还蛮好用),那么我们可以画这样一个图出来: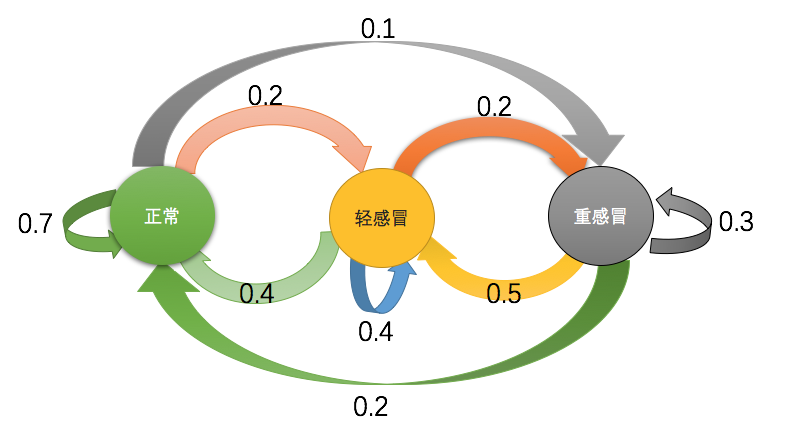
简单解释一下,如果某个人在昨天是轻感冒,那么在今天他有0.4的概率维持轻感冒的状态,0.4的概率病情好转,还有0.2的概率病情恶化。
Emmmm…看上去有点乱,如果只有这么三个状态还好,如果状态再多点,感觉就要眼花缭乱了!
所以通常来说,我们使用类似下面的表格来描述整个马尔科夫过程的。
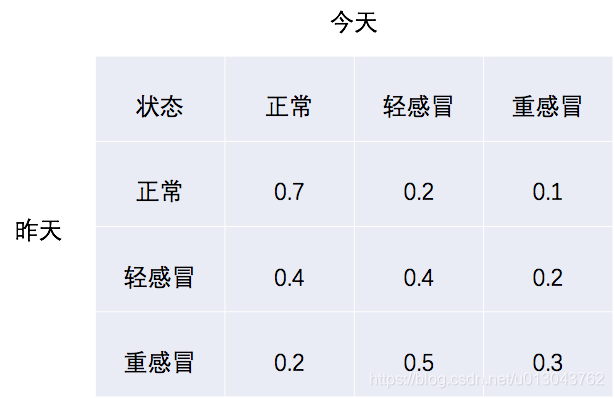
这样是不是清楚多了!那么如果我们省去不必要的字,仅仅用一个矩阵来表示的话,可以这样来写(称为状态转移矩阵):

当然了,既然有一阶马尔科夫假设,当然就有二阶、三阶乃至N阶,他们都是假设今天(t时刻)的状态仅仅和前n天(t-1,t-2…t-n时刻)的状态来决定。比如如果基于二阶马尔科夫假设,某个人前天和昨天分别是重感冒、轻感冒,那么今天说不定感冒也就快好了(美好的祝愿),而今天的状态仅仅和昨天前天有关,和再往前的历史已经没什么关系了。
马尔科夫模型和篱笆网络
那么这个时候我们就可以把上一篇文章的篱笆网络弄过来了。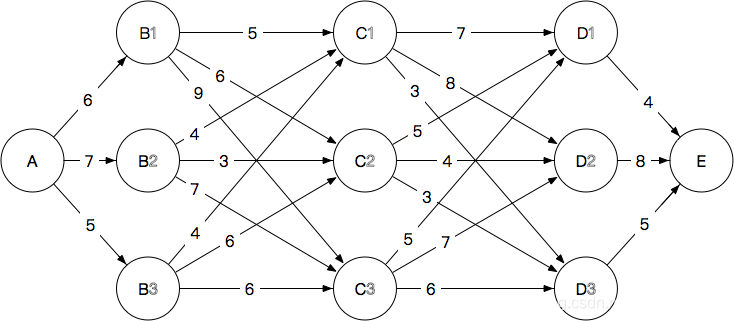
咱们把这幅图简单改一下,把A和E去掉(当然可以留下A,这个时候是所谓的”先验”,我们先不考虑这个),然后把节点的权重修改一下,就得到了“治病救人篱笆网络”: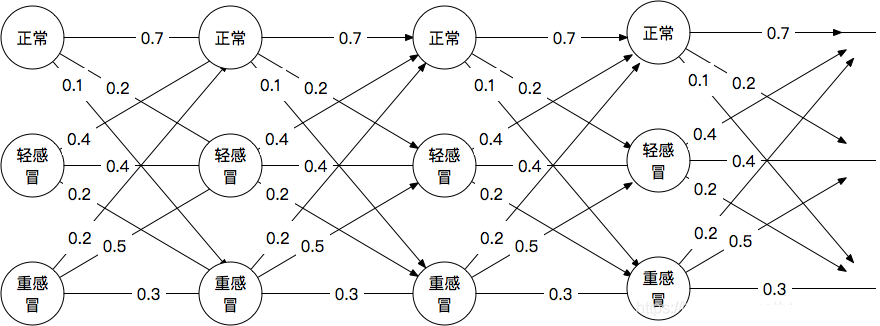
“我能在河边,画上一整天的图!”纳特·帕格兴高采烈地说道。
我们很容易发现,只要把原本的节点间的距离,换成状态转移矩阵中的转移概率,我们就轻松地把“跑腿不累篱笆网络”改成了“治病救人篱笆网络”。
那你看这个时候你的老师就很容易考你了,“已知一个人2月1号重感冒,2月5号正常,告诉我他经历了哪条状态序列的概率最大!”(旁白:鬼知道他经历了什么,大概是吃了感冒药吧!)你会发现这个问题和上一篇文章的“跑腿不累篱笆网络”几乎没什么区别,如果硬要说有区别的话,既然每一天转移都是独立的,那么概率需要乘在一起(见下注),最后看谁最大,而不是“跑腿”中的简单做加法。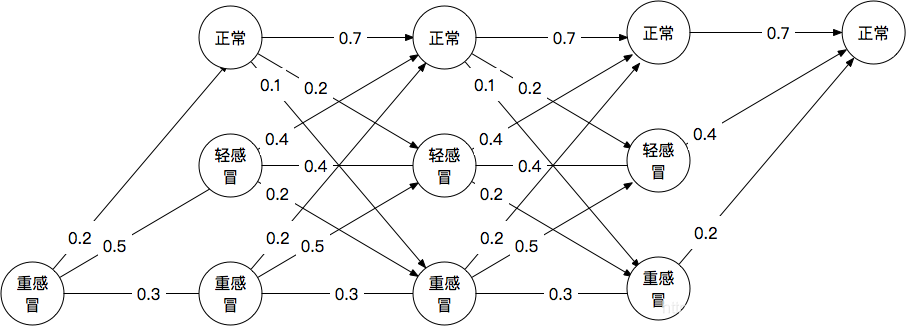
比如他经历了“重感冒、正常、轻感冒、重感冒、轻感冒、正常”(旁白:这个人也是体弱多病!)的概率是P=0.2×0.2×0.2×0.5×0.4=0.0016。我们可以算出所有路径的概率得到最大的那个,但是我们上一篇已经学会了维特比算法,你应该学会减少了很多路径。
注:为什么我们简单把路径上的概率乘在一起就可以呢?(一阶)马尔科夫假设事实上是这样一个东西(竖线|表示“给定,以…为条件”):image_1c6qsenns13e97qfd7k10bl1b6m9.png-1.9kB(来自维基百科),即在已经出现了前N个状态的条件下得到第N+1个状态的概率等于已经出现了第N个状态时出现第N+1个概率(所以才说“和前天无关只和昨天有关”)。而根据条件概率,我们有
P(Xn+1=轻感冒,Xn=重感冒)=P(Xn+1=轻感冒|Xn=重感冒)P(Xn=重感冒)(0)
即这个人昨天重感冒今天轻感冒的概率(联合概率)=在昨天重感冒的情况下今天轻感冒的概率(转移概率)×这个人昨天重感冒的概率。所以如果我们已知昨天这个人重感冒,那么P(Xn=重感冒)=1,这个联合概率和转移概率就相等了。
那么如果转移两天呢?比如我们已知一个人第n天重感冒,求第n+1天第n+2天分别是轻感冒、正常的概率呢?我们尝试着把公式写出来:
P(Xn+2=正常,Xn+1=轻感冒,Xn=重感冒)=(1)
P(Xn+2=重感冒|Xn+1=轻感冒,Xn=重感冒)×P(Xn+1=轻感冒,Xn=重感冒)
也就是说,这三天出现“重感冒、轻感冒、正常”的概率,等于在已知前两天分别是“重感冒、轻感冒”而最后一天“正常”的概率,乘以前两天分别“重感冒、轻感冒”的概率。而根据一阶马尔科夫假设,我们知道最后一天“正常”和第一天是什么状态并没有什么关系,仅仅和第二天的状态有关,也就意味着我们发现等式右边的第一项其实与第二天到第三天的转移概率相等:
P(Xn+2=正常|Xn+1=轻感冒,Xn=重感冒)=P(Xn+2=正常|Xn+1=轻感冒)
所以(1)式就变为了:
P(Xn+2=正常,Xn+1=轻感冒,Xn=重感冒)=
P(Xn+2=正常|Xn+1=轻感冒)×P(Xn+1=轻感冒,Xn=重感冒)
这时候再看最后一项:这个我们熟,在上面(0)呢:
P(Xn+1=轻感冒,Xn=重感冒)=P(Xn+1=轻感冒|Xn=重感冒)P(Xn=重感冒)
所以最后(1)式就变为:
P(Xn+2=正常,Xn+1=轻感冒,Xn=重感冒)=
P(Xn+2=正常|Xn+1=轻感冒)P(Xn+1=轻感冒|Xn=重感冒)P(Xn=重感冒)
也就是说,如果我们知道了第一天“重感冒”的概率P(Xn=重感冒),想要得到接下来两天“轻感冒、正常”的概率,我们只需要把相应的转移概率乘在上面就可以了。所以说如果给定了马尔科夫链的状态序列,我们就从头到尾把所有的转移概率乘在一起就得到了最终这条状态序列出现的概率。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
什么是隐马尔科夫模型?
马尔科夫模型介绍完了,那么什么是隐马尔科夫模型?
咱们再举个栗子,某个小镇的医疗水平,根本测不出某个人到底是正常,还是轻感冒,还是重感冒。他们镇的赤脚医生只能看出来这个人到底是没什么症状、咳嗽、发烧还是拉肚子(旁白:拉肚子是怎么看出来的!)。在这个例子里我们可以认为这四种(活蹦乱跳、咳嗽、发烧、拉肚子)是外在表现,而正常和感冒等等被称为内在的状态(事实上是状态的“输出”)。我们没有办法直接观测内在状态,因为他们是隐藏的(没有医疗器械),但是我们可以直接观测外在表现。
假设病人的外在表现仅仅和他当天的内在状态有关,和其他的条件无关(这叫做独立输出假设),关系如下表(对应的矩阵叫做发射矩阵,大概是因为是从内在状态发射出来的外在表现(输出)吧):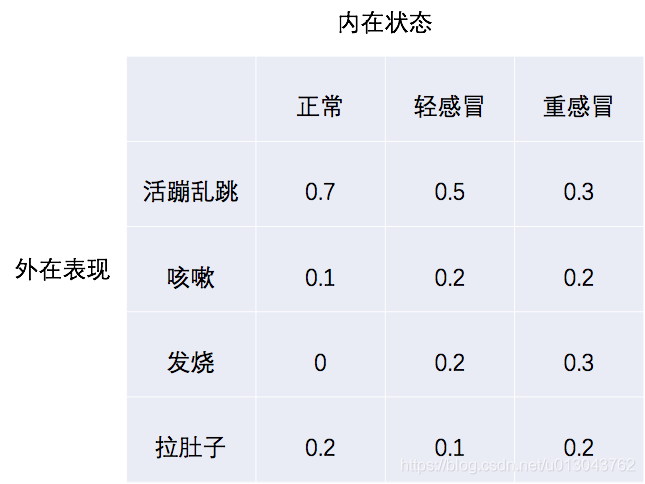
我们就可以通过观察他的外在表现来推断他的内在状态了。比如如果一个人活蹦乱跳,常识你应该推断他是正常的(事实上是基于极大似然,咱们先不提),但是如果告诉你这个人2月1号到5号分别是拉肚子、咳嗽、发烧、咳嗽、活蹦乱跳(这个序列叫做输出序列),让你写出可能性最大的状态序列,也就是他每一天的内在状态分别是什么,难度上就会大很多了。
隐马尔科夫模型与篱笆网络
事实上,在我们不考虑路径的权重的情况下,整个问题和图4的网络没什么区别。每一天都有可能是三个状态之一(当然从发射矩阵来看,如果第三天发烧,第三天不大可能是正常的,为什么?),而每一天的状态遵循一阶马尔科夫假设,仅仅和前一天的状态有关,所以整个图的节点是没有任何区别的。
但是概率(节点的权重)有区别。咱们举个刚才提到过的例子:第三天是发烧,第二天的任意一个节点指向第三天“正常”这个状态的概率应该都是0:因为正常这个状态对发烧的发射概率是0。所以虽然t时刻的状态仅仅和t-1时刻的状态有关,但是既然给定了输出序列,每一个时刻的输出都给了我们更多关于当天的状态的信息。
我们举个更简单的例子:
已知某人第一天轻感冒,第二天发烧,求第二天最可能的内在状态。
- 1
表面上看是这样:从第一天的轻感冒到第二天的三种状态,仅仅对应着转移概率: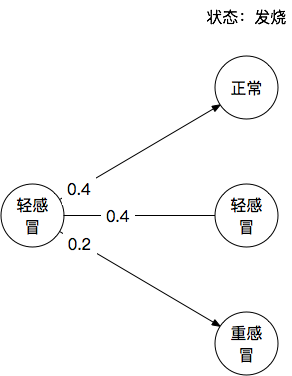
但是其实可以认为是从这样:第一天轻感冒,经过转移之后变为第二天有可能的三种状态,而每种状态都会根据他们不同的发射概率发射出四类不同的外在表现: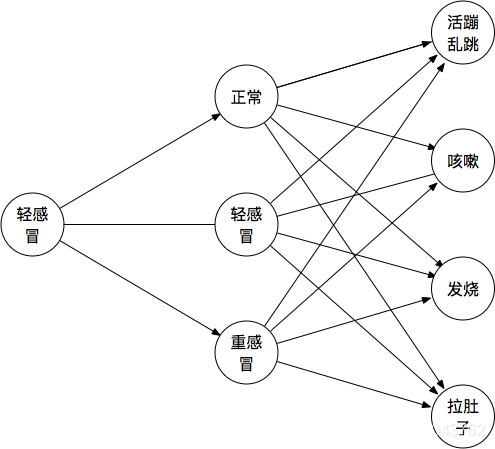
退化成了这样:因为这个人第二天的外在表现是发烧,所以其他的外在表现就不考虑了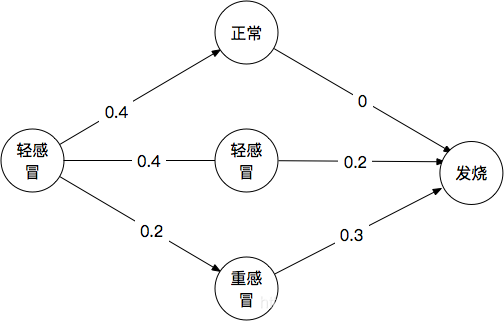
不过请注意这不是真正的状态转移,因为内在的状态依然是仅仅和前一天的状态有关,只是因为给了一些新的附加的条件,我们可以对内在状态的估计进行一定的“修正”。
注:这里的0.4×0.2=0.08事实上是联合概率 P(Xn−1=轻感冒,Xn=轻感冒,Yn=发烧)(2)
=P(Yn=发烧|Xn−1=轻感冒,Xn=轻感冒)P(Xn−1=轻感冒,Xn=轻感冒) 而因为独立输出假设,第n天外在表现为“发烧”,仅仅和第n天内在的状态有关,和前一天的状态无关:P(Yn=发烧|Xn−1=轻感冒,Xn=轻感冒)=P(Yn=发烧|Xn=轻感冒)
所以最终(2)式就表现为 P(Xn−1=轻感冒,Xn=轻感冒,Yn=发烧)
=P(Yn=发烧|Xn=轻感冒)P(Xn−1=轻感冒,Xn=轻感冒)其中后一项我们上文已经讨论过很多次了,通过转移概率很容易计算,而前一项就是内在状态到外在表现的发射概率。
所以最后权重变成了这样: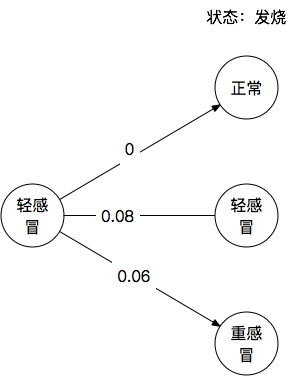
从图上可以看出,第二天内在状态为轻感冒的概率最大(0,0.08,0.06)。
细心的小伙伴可以看出,三条路径加在一起并不等于1。的确是的,因为这个联合概率是要比原本的转移概率“多了一个条件的”,需要利用贝叶斯公式进行“归一化”的处理,但是因为我们只需要比较哪条路径的概率更大,所以我们简单的把他们乘在一起也不算什么错误。
注:理论上来讲,我们路径上标明的其实应该是“已知第一天轻感冒,在给定第二天发烧的条件下,求第二天内在状态是轻感冒的概率”所以事实上是一个条件概率:
P(Xn=轻感冒|Yn=发烧,Xn−1=轻感冒)而不单单是联合概率。根据贝叶斯公式我们有 P(Xn=轻感冒|Yn=发烧,Xn−1=轻感冒)=P(Xn−1=轻感冒,Xn=轻感冒,Yn=发烧)P(Yn=发烧,Xn−1=轻感冒)
=P(Yn=发烧|Xn−1=轻感冒,Xn=轻感冒)P(Xn−1=轻感冒,Xn=轻感冒)P(Yn=发烧,Xn−1=轻感冒)
=P(Yn=发烧|Xn=轻感冒)P(Xn−1=轻感冒,Xn=轻感冒)P(Yn=发烧,Xn−1=轻感冒) 而分数线下面的概率(归一化系数),输出仅与当天的内在状态有关,和前一天的状态无关
=P(Yn=发烧|Xn=轻感冒)P(Xn−1=轻感冒,Xn=轻感冒)P(Yn=发烧)P(Xn−1=轻感冒) 根据全概率公式
=P(Yn=发烧|Xn=轻感冒)P(Xn−1=轻感冒,Xn=轻感冒)∑XnP(Yn=发烧|Xn)P(Xn−1=轻感冒) 看得出这个归一化系数就是各条路径的和,它总是个常数。所以如果我们仅仅考虑哪条路径最大,是否归一化其实也区别不大。
同时,对于标注问题来说,隐马尔科夫模型求得的是一种生成模型,我们本身应该求的就是整条路径的联合概率,所以考虑这个问题其实没有特别大的意义。
下篇文章:
为什么说标注问题可以看做隐马尔科夫过程?
- n-gram语言模型
- 不是题外话的题外话:拼音输入法
- 标注问题
维特比算法怎么解决标注问题?
参考:
http://www.52nlp.cn/hmm-learn-best-practices-two-generating-patterns

 浙公网安备 33010602011771号
浙公网安备 33010602011771号