kafka
1. linux安装
1.1. zookeeper
kafka2.8之前,依赖zookeeper
安装单节点,上面url也有,
- 启动脚本
bash /usr/zookeeper/apache-zookeeper-3.8.4-bin/bin/zkServer.sh start
1.2. kafka
- kafka安装
zk的安装也有,zk的数据目录,不建议放在/tmp下。
详情:https://www.cnblogs.com/jiangcong/p/14820403.html
1.2.1. server.properties
- 云服务器
如果生产者和消费者,同broker不在localhost下,需要配置如下:
【注意】,虚拟机先直接启动,win无法连接再去配置,否则不要配
listeners=INTERNAL://0.0.0.0:9092,EXTERNAL://0.0.0.0:9094
advertised.listeners=INTERNAL://broker自己内网IP:9092,EXTERNAL://公网IP:9094
# INTERNAL 使用PLAINTEXT协议,EXTERNAL 使用 SASL_PLAINTEXT 协议(即用户名和密码认证协议)
kafka_listener_security_protocol_map=INTERNAL:PLAINTEXT,EXTERNAL:SASL_PLAINTEXT
2. 启动
2.1. zk启动
- 0:确定配置文件名
// 1.进入配置文件目录
cd apache-zookeeper-3.7.1/conf
// 2.将zoo_sample.cfg这个文件复制为zoo.cfg (注意:文件名一定要是zoo.cfg)
cp zoo_sample.cfg zoo.cfg
// 3. 可选
修改zk数据存放位置
vi zoo.cfg 后
找到dataDir=/tmp/zookeeper 改成自己想存的位置
- 1:先要启动zk :
// 端口:2181
// 启动成功后jps命令,可看到QuorumPeerMain
bash /usr/local/zookeeper/apache-zookeeper-3.8.4-bin/bin/zkServer.sh start
2.2. kafka启动
- 再启动kafka:
先找到安装目录,再执行
// 默认端口9092
// jps 会看到Kafka
bin/kafka-server-start.sh config/server.properties
3. 终止进程
- 1:先停kafka
- 2: 再停zk
4. 集群配置
- 准备3台服务器
4.1. zk集群配置
4.1.1. zoo.cfg添加集群ip和端口
- 每个节点添加
zoo.cfg文件增加集群节点信息
# 末尾追加
# 2888: 数据同步(Follower节点从Leader同步事务日志),心跳检测(Leader和Follower维持心跳存活检查),请求转发(客户端写请求被Follower接收,会通过此请求转发给Leader处理)
# 3888: 单独用于Leader选举
server.0=192.168.153.0:2888:3888
server.1=192.168.153.1:2888:3888
server.2=192.168.153.2:2888:3888
4.1.2. 生成myid
- 在zoo.cfg的dataDir= 【实际目录】下
填写数字,即server.后面的数子,示例:0
4.1.3. 启动
// 第一步: cd 到zk安装目录的bin,conf,lib的父目录,示例:
cd /usr/local/zookeeper/apache-zookeeper-3.8.4-bin
// 第二步,执行命令
bin/zkServer.sh --config conf start
4.2. kafka集群配置
4.2.1. server.properties配置修改
-
1:broker.id
broker.id=2 -
2:listeners属性配置
示例:listeners=PLAINTEXT://192.168.153.0:9092 -
3: zookeeper.connect配置
示例:zookeeper.connect=192.168.153.0:2181,192.168.153.1:2181,192.168.153.2:2181 -
4:启动kafka:
先找到安装目录,再执行 ,示例:cd /usr/local/kafka/kafka_2.13-3.8.0
// 默认端口9092
// jps 会看到Kafka
bin/kafka-server-start.sh config/server.properties
5. 主题操作
5.1. 创建主题
1: cd 到kafka安装目录
- 用zk
// test换自己的主题名
bin/kafka-topics.sh --create --zookeeper kafka的ip:9092 --replication-factor 2 --partitions 1 --topic test
- 不用zk
bin/kafka-topics.sh --create --bootstrap-server kafka的ip:9092 --replication-factor 2 --partitions 1 --topic test
5.2. 查看所有主题
bin/kafka-topics.sh --bootstrap-server 192.168.153.2:9092 --list
5.3. 查看主题详情
bin/kafka-topics.sh --bootstrap-server 192.168.153.2:9092 --topic test0216 --describe
6. kafkatool
6.1. 安装
- 双击.exe
- 下一步
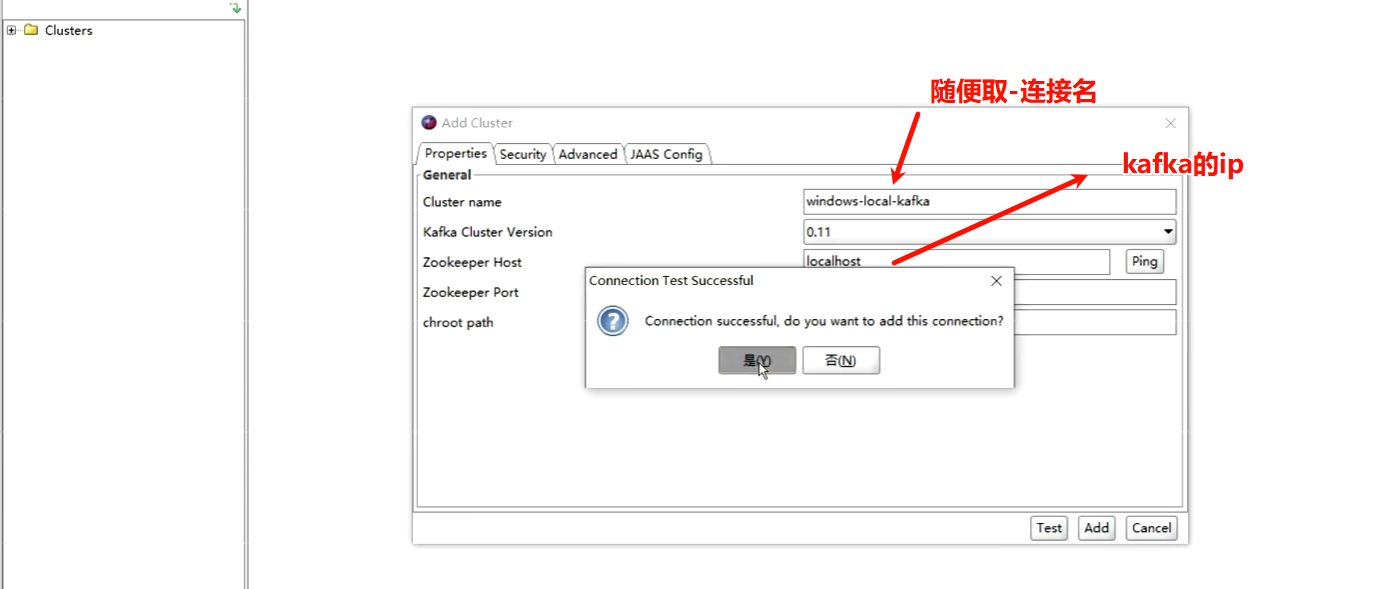
6.2. 连接kafka
7. 代码
7.1. 原生方式
7.1.1. pom依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.0</version>
</dependency>
7.1.2. 生产者
// 配置类
Map<String, Object> conf = new HashMap<>();
// Broker集群ip和端口
conf.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.153.2:9092");
// 指定key序列化器, kafka-client包下
conf.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 指定value序列化器
conf.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(conf);
// 封装数据对象
// topic: 官方不推荐 点和下划线同时出现 ._
for(int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("Order","key"+i,"value"+i);
producer.send(record);
}
// 释放资源
producer.close();
7.1.3. 消费者
// 配置
Map<String, Object> conf = new HashMap<>();
// broker集群地址
conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
// key的反序列化器【和生产者保持一致】
conf.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// value反序列化器【和生产者保持一致】
conf.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 消费者组
conf.put(ConsumerConfig.GROUP_ID_CONFIG, "OrderGroup1");
// 消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer(conf);
// 从多个主题获取数据
consumer.subscribe(Arrays.asList("Order", "User"));
// 消费者从broker拉取消息
final ConsumerRecords<String, String> records = consumer.poll(500);
for (ConsumerRecord<String, String> msg : records) {
System.out.println(msg);
}
// 释放资源
consumer.close();
8. 常见问题
8.1. 多个Broker如何确定谁是leader
- leader的确定
第一个和Zookeeper建立连接,创建临时节点/controller 的节点就是,会将自己的id写入。 - 从节点如何知道谁是leader
从节点查看/controller下已有id,并且不是自己,则监听该临时节点。
8.2. leader挂掉如何选举新的主节点的
- leader节点挂掉
ZK中临时节点/controller会被清除;
Broker从节点监听到临时节点被清除后,触发新的leader选举。
8.3. kafka主题命名规则
- 组成规则:只能由大小写字母、数字、连字符及减号(-)、下划线(_)、英文句号(.)组成;
- 名称长度:不能超过249或255;
- 必须以字母开头;
- 大小写敏感;
- 不能用保留字;
8.3. kafka发送消息后的应答机制
- 应答级别(acks)
- acks=0:生产者发送消息后,无需Broker应答,吞吐量最高但
| 取值 | 吞吐量 | 可靠性 | 延迟性 | 消息丢失可能性 | 具体实现 | 适用场景 |
|---|---|---|---|---|---|---|
| 0 | 最高 | 最低 | 最低 | 最大 | 生产者发送后无需Broker应答 | 日志收集,可容忍数据丢失场景 |
| 1 | 中等 | 中等 | 中等 | 中等 | Leader副本写入成功,及触发应答 | 对吞吐性能有要求,并且可可容忍数据丢失场景 |
| all/-1 | 最低 | 最高 | 最高 | 最低 | 需Leader及所有ISRF副本们确认 | 适用于金融数据,要求强一致性的场景 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号