
激活函数


作用:增加非线性因素
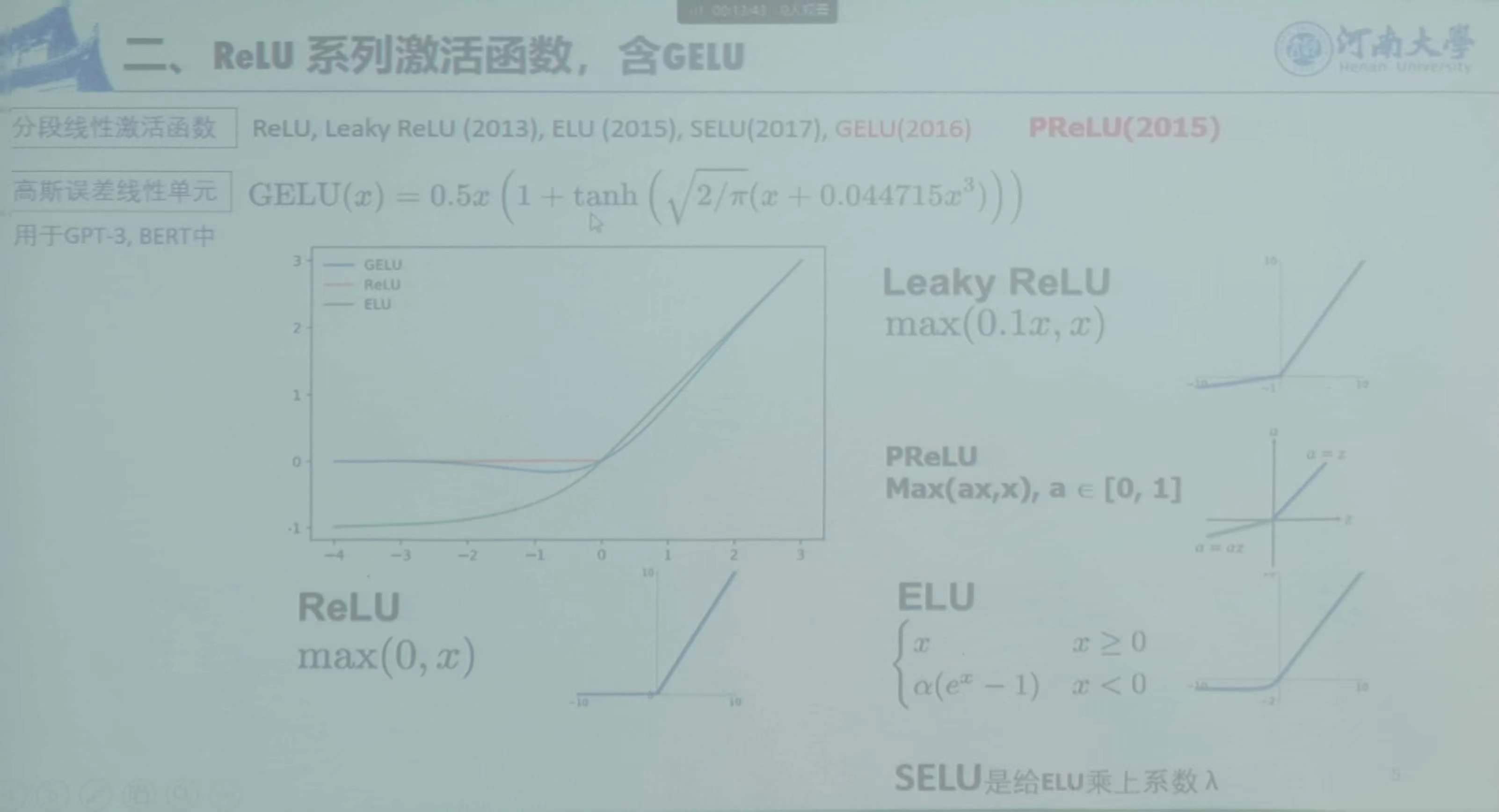
Relu激活函数,含GELU
softmax激活函数:优势和劣势都无限扩大,每个都是自然数次方
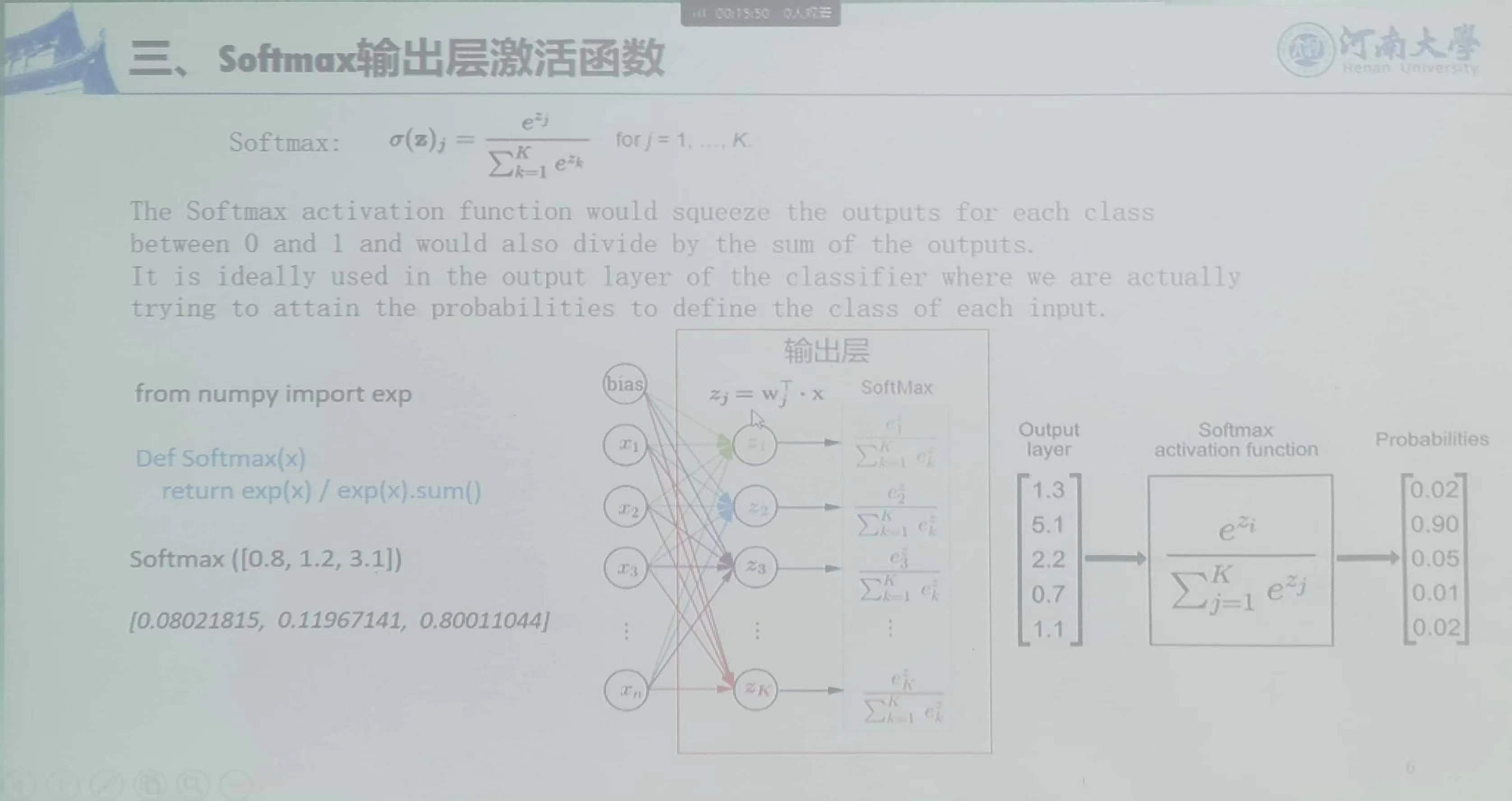
sofrmax和sigmoid的区别:
sigmoid激活函数:
每个神经元激活时只看自己激活前的值,不满足各个神经元激活后的输出值相加等于1的性质,个神经元之间是独立的。
softmax激活函数:
每个神经元激活时要看其它同层神经元的值,分别指数次幂后再归一化,满足各个神经元激活后的输出值相加等于1的性质。个神经元之间是相互依赖的。
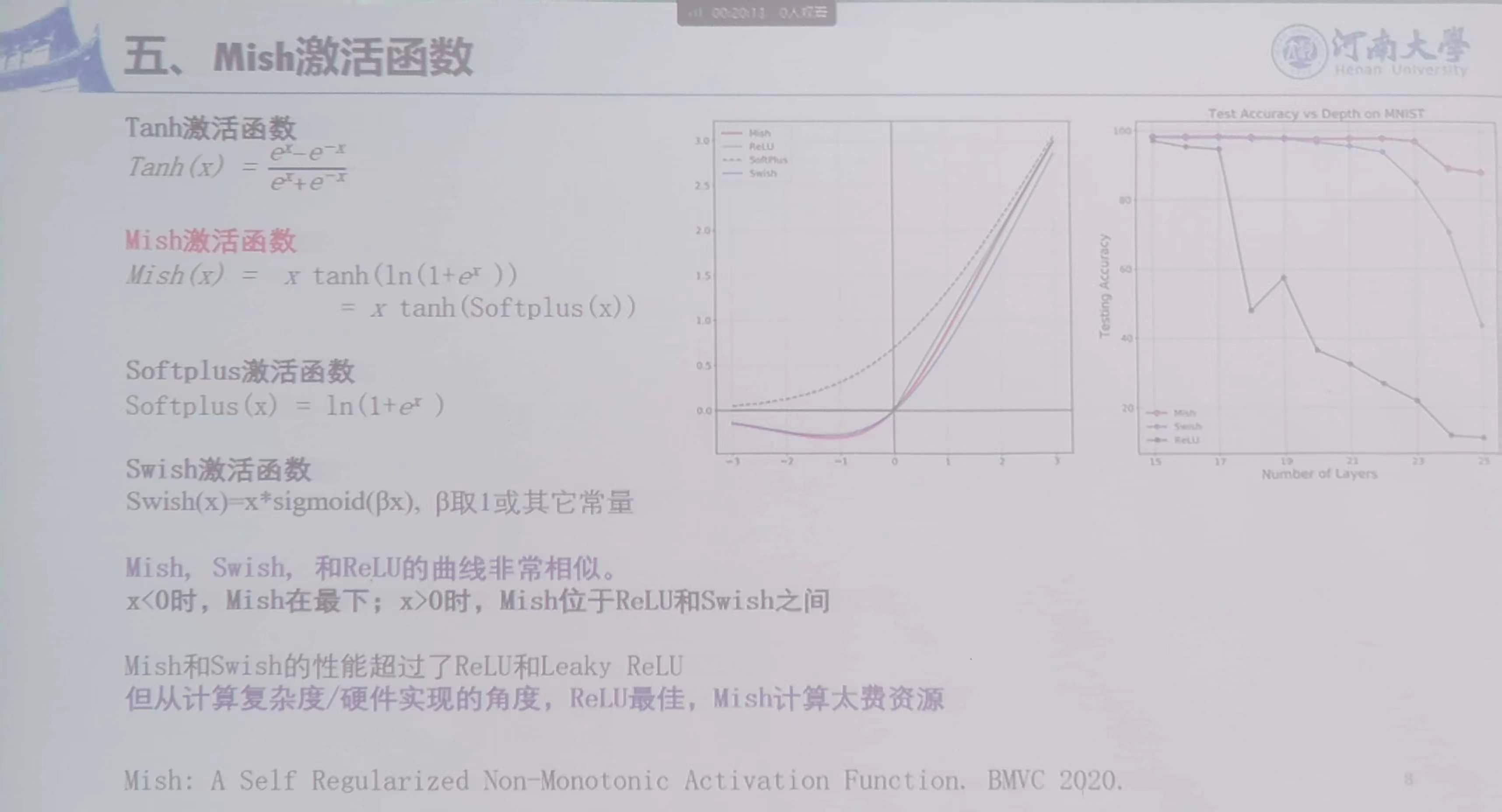
MIsh激活函数:
常用激活函数汇总:

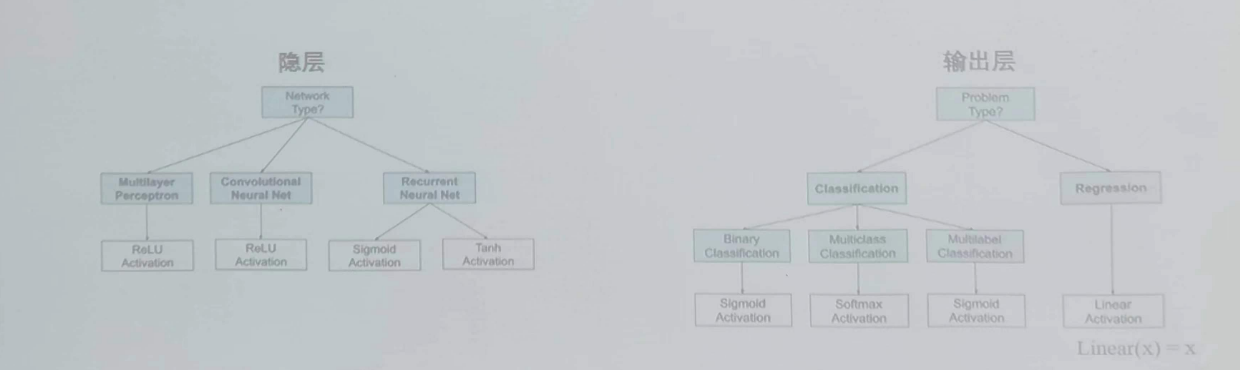
激活函数的选择策略:
没有适用于所有情况的激活函数。综合考虑计算偏导值的难度、训练速度、平滑性、是否满足归一化;
1、隐层:默认情况下,隐层的激活函数,广泛使用ReLU(或其变种的Leaky ReLU,PReLU等),或Mish;
2、输出层:默认情况下,对分类任务,广泛使用softmax作为输出层的激活函数(得到的每一类输出的概率,这些概率的和相加为1)
激活函数和损失函数:
激活函数则用于引入非线性因素,增强模型的表达能力;而损失函数用于衡量模型预测结果与真实结果之间的差距。
一般来说是先激活在计算损失。
权值初始化
神经网络开始前,指定权值,在神经网络训练中不参与
1、全零初始化和随机初始化(Zero Initialization and Random Initialization)
全零初始化:所有中间层节点对应的参数值都置为零。第一次BP后,更新后的网络参数将相同。
随机初始化:所有中间层节点对应的参数值都置为一个随机生成的比较小的值。
2、针对Sigmoid等激活函数的Xavier初始化方法
随机生成一个随机数后,乘以上述值。适用于Sigmoid()、Tanh()、Softsign()等激活函数。
3、针对ReLU激活函数的He初始化方法
4、适用Pretrained模型中的参数
例如再ImageNet数据集上预训练的ResNet50模型。
5、Zer0初始化
仅仅使用0和1进行初始化。
Xavier和He权值初始化对比
公式!

批归一化(Batch Normalization)


比较均匀,减少过大或过小的值,使网络更平稳,随着训练的进行不断地修改对应的神经元的值,即持续发生在后续迭代的训练中。
BN优缺点:
优点:
1、BN允许在训练过程中使用更大的学习率,超参数的寻找更加容易,也更健壮;
2、BN能够提升模型的预测准确率,减少学习模型过拟合风险;
3、BN能够加快梯度更新过程的收敛度,从而加快了训练速度;
4、BN能够减少对权值初始化的依赖(如He初始化)。
缺点:
BatchNorm对批大小比较敏感,对于较小的mini-batch,效果不好。
BN变种:
BatchNorm:分别计算所有样本在某个通道上的每个神经元上的均值及方差,适用于CNN(默认用);
InstanceNorm:当前样本在一个通道上的均值和归一化,与通道无关,只与当前样本有关;
以上属于同通道神经元跨样本。
LayerNorm:一个样本在所有通道上神经元的均值和归一化,跟样本数量无关,使用于批小的情况下,其与样本数量无关,对RNN作用明显;
GroupNorm:分组,每个组中等同于LayerNorm;
以上属于跨通道神经元同样本。
梯度更新策略与超参优化
1)梯度下降修正,每个参数梯度下降的值
2) 对超参数合理调整,主要是学习率最终目标:以加速训练过程,取得更好的模型准确度
1、梯度下降(Gradient Descent)的目的
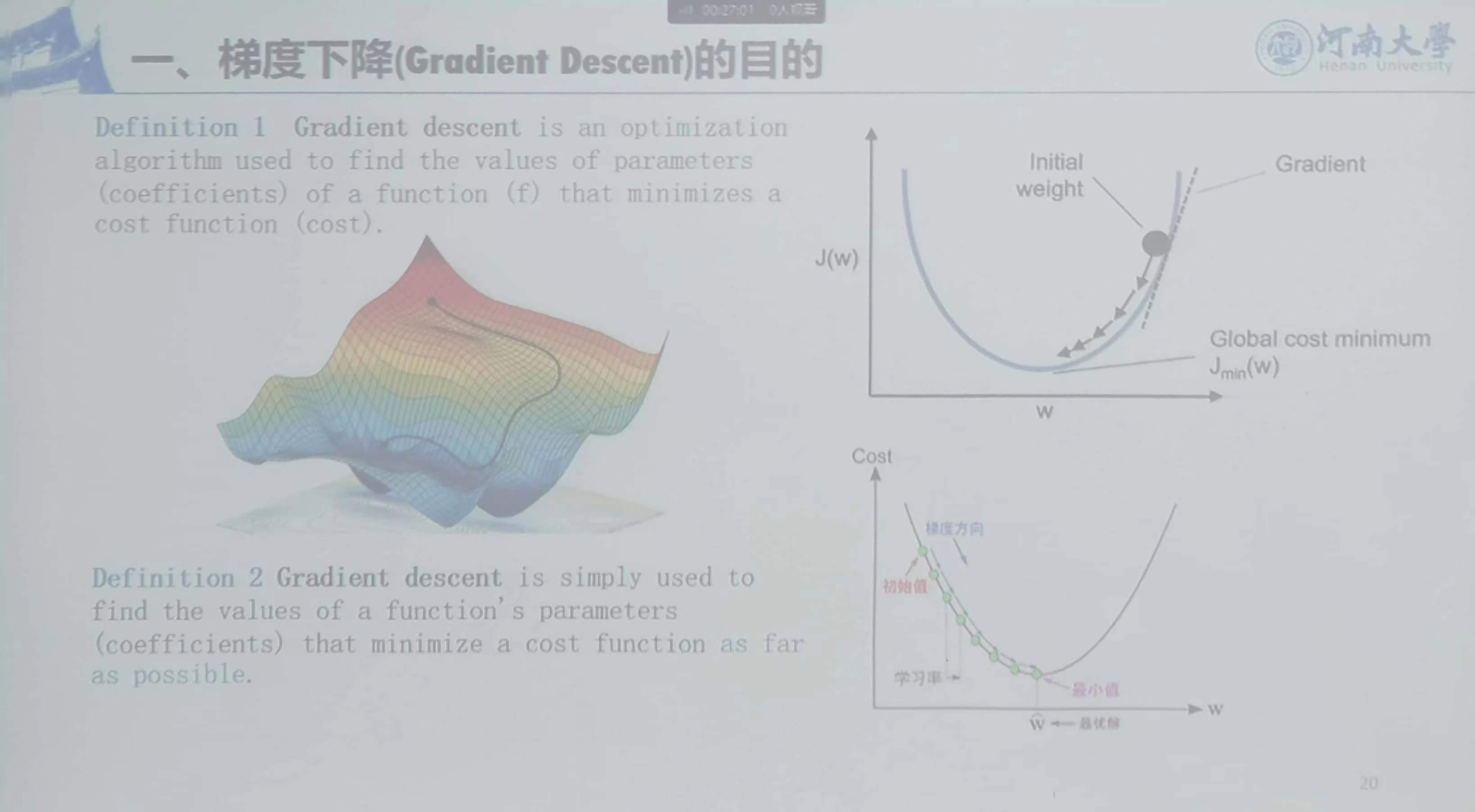
2、梯度下降的适用场景

3、缺点

4、不同变种类型

5、最基本的优化算法(SGD)和Momentum梯度下降法
SDW累积的梯度的偏导
SDB累积的权重的偏导

一般是W=W-lamda*Sdw 梯度的权重
b=b-lamda*Sdb 偏置的权重
6、自适应学习率
需要给一个初始学习率,随着训练自主更新

Adagrad自适应调整学习率
1)需要预先设置一个全局学习率λ;
2)增加一个二阶动量Sdw,以实现自适应学习率。二阶动量Sdw是迄今为止所有梯度值的平方和
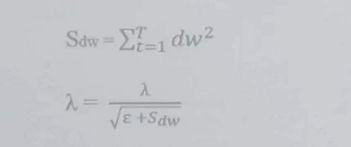 ;
;
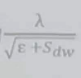
3)上一轮迭代的学习率为λ,而本轮迭代中的学习率为
 。
。
AdamDelta是Adagrad的改进,不再另外累积所有的历史梯度,而只计算一定时间段的梯度的平方和。
RMSProp
以上三种过去梯度的平方进行累加

Adam
其在某种程度上是Momentum(一阶)和RMSProp(二阶)的结合,自动的更新权值和学习率

7、优化器总结

8、默认优化器的选择

知识产权声明: 本博文中的ppt素材及相关内容和知识产权,均属于河南大学张重生老师所讲授的《深度学习》课程及张重生老师在2025年出版的著作《新一代人工智能 从深度学习到大模型》(机械工业出版社)。特此声明。
真挚地感谢张重生老师在本人于河南大学学习期间的教导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号