[Deep Learning] How deep is the Deep Learning - Revolution
《王川: 深度学习有多深?》 - 阅读笔记
深度学习的革命
Hinton 教授在和记者的访谈中说,
"我们会得到非常好的证据,最终学术界会改变观点.
也许那些和你争论的科学家永远不会回心转意,
但是年轻一代会,
这就是在深度学习领域正在发生的事.
传统的人工智能领域的老家伙们还是不信,但是年轻一代的研究生们都看到了事情在朝什么方向发展."
新世界的浪潮
2012 年 ImageNet 图像识别竞赛中的突破,只是一个开端。
仅仅是三年之后,一群80后的中国学者,又把图像识别的成就,推到一个全新的高度,一个超越受过良好训练的正常人的识别能力的新高度。
2013 年的 ImageNet 竞赛, 获胜的团队是来自纽约大学的研究生 Matt Zeiler, 其图像识别模型 top 5 的错误率, 降到了 11.5%。
Zeiler 的模型共有六千五百万个自由参数, 在 Nvidia 的GPU 上运行了整整十天才完成训练。
2014年, 竞赛第一名是来自牛津大学的 VGG 团队, top 5 错误率降到了 7.4%。
VGG的模型使用了十九层卷积神经网络, 一点四亿个自由参数, 在四个 Nvidia 的 GPU 上运行了将近三周才完成培训。
- 如何继续提高模型的识别能力? 是不断增加网络的深度和参数数目就可以简单解决的吗?
来自
微软亚洲研究院的 何恺明 和 孙健 (Jian Sun, 音译),
西安交通大学的 张翔宇 (Xiangyu Zhang, 音译),
中国科技大学的 任少庆 (Shaoqing Ren, 音译)
四人的团队 MSRA (MicroSoft Research Asia),在2015 年十二月的 Imagenet 图像识别的竞赛中, 横空出世.
在研究一个图像识别的经典问题 CIFAR-10 的时候,他们发现一个 56层的简单神经网络,识别错误率反而高于一个20层的模型.
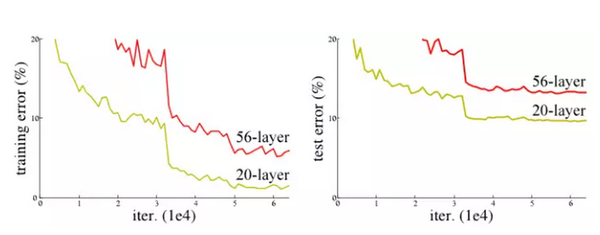
网络深度增加,学习的效率反而下降.
为了解决有效信息在层层传递中衰减的问题, MSRA团队尝试了一种称为 "深度残余学习" (Deep Residual Learning) 的算法.
本质上, 所谓'深度残余算法', 就是把神经网络一层层之间的非线性转换问题, 变成一个所谓的 "相对于本体的残余转换" (Residual mapping with respect to identity) 的问题,
实践上,使用所谓 "跳跃链接" (shortcut connection)的方法,把底层的输出值每隔几层跳跃直接传递成更高层的输入, 这样有效的信息不会在深层网络中被淹没.

MSRA 的深度残余学习模型,使用了深达 152层的神经网络, top 5 的识别错误率创造了 3.57%的新低, 这个数字, 已经低于一个接受良好培训的正常人的大约 5% 的错误率.
更有意思的是, MSRA 计算模型的复杂度, 实际上还不到2014年获奖团队 VGG 的十九层神经网络的 60%. 甚至连前几年极为流行的丢弃 (dropout) 算法, 都没有用上.
哥伦布之远征
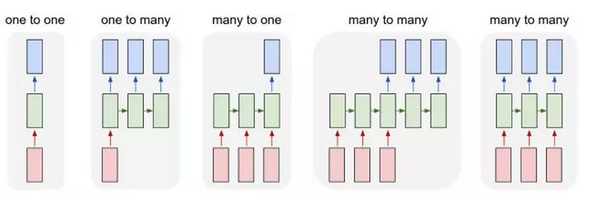
除了上述故事的主角,前馈网络 (feedforward network),RNN (Recurrent Neural Network), 也称循环神经网络, 多层反馈神经网络, 则是另一类非常重要的神经网络。
RNN, 可以接受一个序列的输入向量, 输出也可能是一个序列, 二者是多对多的关系. 应用上, 它可以解决的问题广泛得多, 包括给图像生成字幕, 自然语言处理, 机器翻译,等等.
1997年 Schmidhuber 和他的学生 Sepp Hochreiter 合作, 提出了 长短期记忆 (LSTM, Long Short-Term Memory) 的计算模型,如下:

LSTM 模块, 在神经网络里的角色, 是通过内在参数的设定 (如上图, input gate, output gate, forget gate),决定某个输入信息在很久以后是否还值得记住,何时取出使用, 何时废弃不用。
如果"忘记历史意味着背叛", 那么对于没有使用 LSTM 的神经网络, "忘记历史则意味着迷茫和不知所措"。
RNN 和 LSTM 发挥威力的重要应用之一, 是语音识别。
一直到2009年之前, 主流的语音识别技术, 依靠的是统计学上的两个算法模型, 高斯混合模型 (Gaussian Mixture Model) 和 隐藏马尔科夫模型 (Hidden Markov Model).
但生活中的很多系统,比马尔科夫模型更加复杂:
一个靠买彩票而发财的百万富翁, 和一个白手起家打拼十几年历经坎坷的百万富翁,虽然银行里都有一百万,用马尔科夫模型来看没有区别.但过去的历史不一样,未来的路径和风险实际上差别极大。
简而言之, GMM-HMM 就是用概率上的算法, 来猜测语音对应的文字。
实践上 GMM-HMM的算法 一直到 2009年, 都是错误率最低的算法. 但即使如此, 对大多数基准测试, 其单词识别错误率 (Word Error Rate) 一直接近 30%甚至更高.
这颇有点像2012年之前, 支持向量机 (SVM) 的技术在图像识别领域的地位。
邓力, 中国科技大学生物系78级的校友, 郭沫若奖学金 (科大学霸的最高荣誉) 获得者. 他八十年代就开始做语音识别方面的研究, 1989年在威斯康辛大学麦迪逊分校获得博士学位. 在加拿大的滑铁卢大学做了十年教授后, 1999年到微软研究院工作.
九十年代初期, 研究者们曾经试图把神经网络的技术用于语音识别. 但受当时计算速度和算法的限制, 只有一两个隐层的神经网络, 在效果上完全无法挑战 GMM-HMM.
2009年, Hinton 和他的研究生, Ahmed-Rahman Mohamed 和 George Dahl, 合作发表论文, "Deep Belief Network for Phone Recognition" (深信度网络用于电话语音识别), 在一个叫做 TIMIT 的标准测试上, 识别错误率降到了 23%, 超过了当时其它所有算法的技术水平。
Hinton 和邓力早在九十年代初就有联络与合作。Hinton 和他的研究生, 2009年被邀请来微软合作研究, 把深度学习的最新成就应用到语音识别上。
2012年十月, Geoffrey Hinton, 邓力和其他几位代表四个不同机构 (多伦多大学, 微软, 谷歌, IBM) 的研究者, 联合发表论文, "深度神经网络在语音识别的声学模型中的应用: 四个研究小组的共同观点" (Deep Neural Networks for Acoustic Modelling in Speech Recognition: The Shared Views of Four Research Groups ).
研究者们借用了Hinton 使用的"限制玻尔兹曼机" (RBM) 的算法 (这个系列的第四篇有介绍过), 对神经网络进行了"预培训".
深度神经网络模型 (DNN), 在这里, 部分地替代了高斯混合模型 (GMM) 来估算识别文字的几率, 其底层的语音识别,还是依靠"隐藏马尔科夫模型" (HMM) 的概率模型的架构。
在许多不同的语音识别的基准测试里,深度神经网络和隐形马尔科夫模型结合的 DNN-HMM 模型的表现,全面超越了传统的 GMM-HMM模型,有的时候错误率降低超过20%以上。
在谷歌的一个语音输入基准测试中,单词错误率 (Word Error Rate) 最低达到了 12.3%。
- 一个简单的例子, 如果一个人说 "我在法国长大.. 我说一口流利的 (哪国的语言?) ". 如果要让机器准确预测最后一个词, 是什么语言的话, 对于语境的记忆至关重要. 机器需要记得,在前面几句话里,说话人提到他在哪个国家长大. 简单的 HMM 模型, 处理这类语境问题, 显然不够.
2013年三月, 多伦多大学的 Alex Graves 领衔发表论文, "深度循环神经网络用于语音识别" (Speech Recognition with Recurrent Neural Network). 论文中使用 RNN/LSTM 的技术,
一个包含三个隐层, 四百三十万个自由参数的网络, 在一个叫做 TIMIT 的基准测试中, 所谓的"音位错误率"达到 17.7%, 优于同期的其它所有技术的表现水准.
2015年五月, 谷歌宣布, 依靠 RNN/LSTM 相关的技术, 谷歌语音 (Google Voice) 的单词错误率降到了8% (正常人大约 4%).
2015年十二月, 百度 AI 实验室的 Dario Amodei 领衔发表论文, "英语和汉语的端对端的语音识别". (之所以叫端对端, 是指一个模块就可以解决整个问题, 不需要多个模块和太多人工干预.)
论文的模型, 使用的是 LSTM 的一个简化的变种, 叫做"封闭循环单元" (Gated Recurrent Unit).
百度的英文语音识别系统, 接受了将近一万两千小时的语音训练, 在 16个GPU上完成训练需要 3-5 天.
在一个叫 WSJ Eval'92 的基准测试中, 其单词错误率达到3.1%, 已经超过正常人的识别能力 (5%). 在另外一个小型汉语基准测试中, 机器的识别错误率只有3.7%, 而一个五人小组的集体识别错误率则为4%.
好玩的东西才刚刚开始, RNN/LSTM 很快被程序猿们开发出新的应用,例如:把大量文字作为输入培训 RNN, 让它掌握语言的规律, 自己也可以写文章。
循环神经网络 (RNN)的本质, 是可以处理一个长度变化的序列的输出和输入 (多对多).
-
- 广义的看,如果传统的前馈神经网络做的事, 是对一个函数的优化 (比如图像识别).
- 那么,循环神经网络做的事, 则是对一个程序的优化,应用空间宽阔得多.
斯坦福大学的计算机博士 Andrej Kapathy 使用了一种所谓的 "字母为基础的语言模型" (Character Based Language Model )来训练 RNN. 简而言之, 就是通过不断阅读大量文字, 让 RNN 自己可以较为准确地估计下面一个字母出现的几率. 当概率模型培训得慢慢成熟以后, RNN 就可以自己逐渐写出流畅通顺的文字。
Kapathy 用托尔斯泰的小说 "战争与和平"来训练 RNN. 每训练一百个回合以后, 他让 RNN 输出一段自己创作的文字, 检查其学习效果.
100 回合: tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh
机器知道要空格, 有时要逗号, 但是其它都是乱码
500 回合: we counter. He stutn co des. His stanted out one ofler that
现在知道大小写, 可以正确拼写一些短单词.
1200 回合: he repeated by her door. "But I would be done and quarts, feeling, then, son is people...."
可以使用复杂的标点符号, 较长的单词也可以拼写
2000 回合: "Why do what that day," replied Natasha, and wishing to himself the fact the princess, Princess Mary was easier,
可以正确拼写更复杂的语句.
从程序的演化过程看, 机器模型先领悟了单词之间的空格的结构, 然后慢慢认识了更多单词, 由短到长. 标点符号的规则也慢慢掌握. 一些有更多长期相关性的语句结构, 慢慢地, 也被机器掌握。
整个过程的最核心优点是, 没有人告诉程序具体的语法是什么,标点符号的规则是什么. 一切都是直接用原始数据训练, 时间长了,机器自己就慢慢发现单词, 空格, 引号和括号等等的规则。
自学习,这就是人工智能,让人神往的重要原因。
2016 年五月, 来自谷歌的 AI 实验室报道, 研究者用两千八百六十五部英文言情小说培训机器,让机器学习言情小说的叙事和用词风格。
谷歌程序的写作水准, 已经可以和小学三年级学生比肩。但 AI 的最大优势, 是可以不断迅速地学习新的文字和数据, 而且这个能力在加速. 一本普通的两百页的小说, 其信息量大约在 0.6 个MB 上下. 三千部小说就是 1.8 GB, 在Nvidia 目前最新的 GPU上训练, 也不过就是几百个小时的事情.
乘风破浪
循环神经网络, 在文字处理上的表现, 只是小荷才露尖尖角.
自然语言处理, 英文是 Natural Language Processing (NLP).其基本定义为: 把一段文字, 转化成一个数据结构, 力求清晰无误地表达文字的意义。
自然语言处理包括对自然语言的理解和生成, 典型应用如机器翻译, 文字分类, 聊天机器人等等. 通过语言沟通, 是智人和其它动物的最重要区别, 这是人工智能技术的重要基石.
衡量 NLP 表现的一个重要变量是所谓语言模型 (Language Model, 简称 LM) 的perplexity (困惑度).
困惑度,是一个用概率计算的基准, 借用了信息论创始人, 著名科学家香农的信息熵的概念.
通俗地说, 用语言模型来评估一段测试语句的概率时, 困惑度和概率成反比, 概率越高, 困惑度越低, 语言模型越好.
打个比方, 如果有这样一段话:
"今天我吃了西红柿炒__ "
对一个好的语言模型, 这句话后面出现的词是"鸡蛋"的概率可能是 30%, "土豆"的概率是 5%, "豆腐"的概率是 5%, 但"石头"的概率则应当几乎为零.
如果神经网络的计算模型, 输出一些胡言乱语 (语法,逻辑和语意上的各种错误),那么这往往意味着这个模型,对一些不恰当的词语,给予了过高的几率, 它的困惑度, 还不够优化.
深度学习之前,传统的基于统计算法的语言模型,在测试时困惑度大多都在 80以上 (人工语言处理的困惑度的理论最低点大约在 10-20 之间).一方面是算法的局限,另一方面是来自培训语句数量规模的限制.
2013年,以 Ciprian Chelba 为首的来自谷歌的团队推出了一个叫做"十亿单词基准"(One Billion Word Benchmark) 的语料库.
这个语料库包含了接近十亿个英文单词组成的不同语句, 用来培训和测试不同的算法模型. 这个数据规模, 是先前流行的所谓 "Penn Treebank" 的包含四百五十万英文单词的语料库的大约两百倍.
Chelba 的团队, 使用一个包含二百亿个自由参数的循环神经网络的模型, 模型的训练消耗了十天的时间, 把困惑度下降到了 51 左右. (同期使用传统的统计算法, 最佳结果是 67)
2016年二月, 以 Rafal Jozefowicz 为第一作者的谷歌大脑的团队, 发表论文, "探索语言模型的极限" (Exploring the limits of language modeling).
该团队, 使用了 RNN/ LSTM 和所谓 "字母层面的卷积神经网络" (Character-Level Convolutional Neural Network) 的技术结合的模型,
在"十亿单词基准"的测试上把困惑度降低到了 30.
相应的模型自由参数的数目降到了只有十亿 (相当于 Chelba 团队的模型的百分之五), 计算量大大降低。
更有意思的是,当把十个经过微调的不同参数的LSTM模型综合起来,取其均值, 对测试数据验证时, 其困惑度最低达 23.7。
机器越来越懂人话, 越来越会说人话了。
唯快不破
回顾深度学习技术在图像识别,语音识别和自然语言处理上的突破, 可以看到的是一个很清晰的主脉络:
计算速度加快, 缩短了新算法的测试周期,
成功的新算法, 迅速彻底地淘汰老算法.
谷歌的资深研究者 Jeff Dean 这样描绘算法测试速度的重要性:
- 如果一个实验要一个月才会出结果, 没有人会去测试.
- 如果要花费一到四周, 那么只有特别高价值的测试才值得去做.
- 如果一到四天就可以出结果,那勉强可以忍受.
- 如果一天之内就可以出结果, BOOM! 研究的效率大大提高,新成果不断涌现.
深度学习在图像识别上的突破, 一下子让支持向量机 (SVM) 的统计算法过时;循环神经网络和长短期记忆 (RNN/LSTM) 在语音识别上的突破,也让传统的 GMM/HMM 技术被人冷落。
在这个时代,最重要的不是对某个具体算法的耳熟能详 (好比学习装填子弹和射击的技能), 而是研究如何持续更快地提高运算速度,打破各种计算瓶颈,来缩短新算法测试的周期.
这需要对 CPU, GPU 这些底层硬件的计算构架, 以及指引硬件性能进步的摩尔定律的未来路线图, 有深刻的理解。(AI芯片诞生的前奏)
一个典型的计算流程是这样的:
1)数据从 CPU 的内存拷贝到 GPU 的内存.
2) CPU 把计算指令传送给 GPU
3) GPU 把计算任务分配到各个 CUDA core 并行处理
4) 计算结果写到 GPU 内存里, 再拷贝到 CPU 内存里.
除了时钟的速度, 衡量GPU计算能力的其它几个重要参数是:
1. (CUDA cores) 并行计算的核心处理器的数目. (类似轮船的吨位)
2. 内存大小 (类似港口的大小).
3. 内存带宽 (Bandwidth, 指数据传输的速度, 类似轮船装卸货的速度)
4. GPU/CPU之间通讯的带宽. (类似从港口到火车/卡车上的装卸货的速度)
如何改进提高计算过程中的瓶颈。
2016年四月, 在硅谷的 GPU 开发者大会上, Nvidia 的黄仁勋宣布推出最新的超算系统 DGX-1.
这是一个拥有八个最新的代号 P100 的GPU的系统,售价接近十三万美元。
在运行 alexnet 的训练计算时间上, 只花费了两个小时, 比2012年十月 Alex Krizhevsky 团队使用两个 GTX 580 GPU, 六天的运算时间快了 75倍。
P100 的时钟频率是 1328 Mhz, 比 GTX580 的时钟频率 1544 Mhz 实际上还略低一些. 但是:
第一, P100 有 3800 个core, 和 GTX 580 的 512个 core 相比, 并行程度增加了六倍以上.
第二, P100 的内存达到 16 GB, 是GTX 580的十倍以上. 内存带宽为 720 GB/s, 是 GTX 580 的三倍以上. (芯片的内存又细分为 Register/寄存器, Cache/缓存, Memory/内存, 这里暂不细表) 内存读写的瓶颈大大减小.
第三, P100 在硬件上实现了一些算法的直接支持,比如十六位的浮点数计算. 由于深度学习计算许多时候对精度要求并不高, 十六位浮点数的计算速度, 就比传统的三十二位浮点数计算速度快了两倍.
第四, 由于 P100使用了新的所谓 NVlink 的架构, GPU/CPU 直接通讯的带宽高达 160 GB/s, 是 GTX 580 的二十倍. GPU 之间数据传输, 不再是大的瓶颈. Nvidia 把八个 GPU 放在一起并行运算, 这和 2012年 Krizhevsky 团队使用两个 GPU 相比, 并行程度增加了四倍.
计算能力的提高,不再主要依靠芯片时钟速度的提高,而是通过提升不同模块之间的通讯带宽,加大并行程度而实现.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号