[Deep Learning] How deep is the Deep Learning - History
《王川: 深度学习有多深?》 - 阅读笔记
深度学习的历史
“如果你是在machine learning学习初期接触此文,那么,你是幸运的”
王川: 深度学习有多深? 学了究竟有几分? (一至八)
人工智能研究的方向之一, 是以所谓 "专家系统" 为代表的, 用大量 "如果-就" (If - Then) 规则定义的, 自上而下的思路.
人工神经网络 ( Artifical Neural Network),标志着另外一种,自下而上的思路.
拓荒者
1969 年, Marvin Minsky 和 Seymour Papert 出版了新书: "感知器: 计算几何简介". 书中论证了感知器模型的两个关键问题:
-
- 第一, 单层的神经网络无法解决不可线性分割的问题, 典型例子如异或门, XOR Circuit.
- 第二, 更致命的问题是,当时的电脑完全没有能力完成神经网络模型所需要的超大的计算量.
此后的十几年,以神经网络为基础的人工智能研究进入低潮,相关项目长期无法得到政府经费支持,这段时间被称为业界的核冬天.
神
1970年,当神经网络研究的第一个寒冬降临时,在英国的爱丁堡大学,一位二十三岁的年轻人, Geoffrey Hinton, 刚刚获得心理学的学士学位.
1986年七月, Hinton 和 David Rumelhart 合作在自然杂志上发表论文, "Learning Representations by Back-propagating errors", 第一次系统简洁地阐述,反向传播算法在神经网络模型上的应用.
反向传播算法,把纠错的运算量, 下降到只和神经元数目本身成正比.
天将
Yann Lecun (我给他取个中文名叫 "严乐春"吧) 1960年出生于巴黎. 1987年在法国获得博士学位后,他曾追随 Hinton 教授到多伦多大学做了一年博士后的工作, 随后搬到新泽西州的贝尔实验室继续研究工作.
在贝尔实验室,严乐春 1989年发表了论文, "反向传播算法在手写邮政编码上的应用".他用美国邮政系统提供的近万个手写数字的样本来培训神经网络系统, 培训好的系统在独立的测试样本中, 错误率只有5%.
上古神
早在1963年, Vapnik 就提出了 支持向量机 (Support Vector Machine) 的算法.支持向量机, 是一种精巧的分类算法.
在贝尔实验室的走廊上,严乐春和 Vapnik 常常就(深度)神经网络和 SVM,两种技术的优缺点,展开热烈的讨论.
严乐春的观点是, 用有限的计算能力,解决高度复杂的问题,比"容量调节"更重要. 支持向量机,虽然算法精巧,但本质就是一个双层神经网络系统.它的最大的局限性,在于其"核机制"的选择. 当图像识别技术需要忽略一些噪音信号时,卷积神经网络的技术,计算效率就比 SVM 高的多.
但,在手写邮政编码的识别问题上, SVM 的技术不断进步,1998年就把错误率降到低于 0.8%,2002年最低达到了 0.56%, 这远远超越同期传统神经网络算法的表现.
支持向量机 (SVM) 技术在图像和语音识别方面的成功, 使得神经网络的研究重新陷入低潮.
神经网络的计算,在实践中还有另外两个主要问题:
-
- 第一, 算法经常停止于局部最优解,而不是整体最优解.
- 第二, 算法的培训,时间过长时,会出现过度拟合 (overfit),把噪音当做有效信号.
- 另外,抛开计算速度的因素,传统神经网络的反向传播算法会有 vanishing gradient problem (梯度消失问题).
武林至尊
黄仁勋, 1963年出生于台湾. 1993年从斯坦福大学硕士毕业后不久,创立了 Nvidia.
PU 的主要任务, 是要在最短时间内显示上百万,千万甚至更多的像素.这在电脑游戏中是最核心的需求. 这个计算工作的核心特点, 是要同时并行处理海量的数据.
GPU 在芯片层面的设计时, 专门优化系统, 用于处理大规模并行计算. 而神经网络的计算工作, 本质上就是大量的矩阵计算的操作, 因此特别适合于使用 GPU.
Intel 技术人员2010年专门发表文章驳斥,大意是 Nvidia 实际上只比 intel 快 14倍,而不是传说中的 100 倍.
一个蛮力, 一个来自 GPU 的计算蛮力, 要在深度学习的应用中爆发了.
神的蛰伏
2003年, Geoffrey Hinton, 还在多伦多大学, 在神经网络的领域苦苦坚守.
一个五十六岁的穷教授, 搞了三十多年没有前途的研究,要四处绞尽脑汁, 化缘申请研究经费。
2003年在温哥华大都会酒店, 以Hinton 为首的十五名来自各地的不同专业的科学家, 和加拿大高科技研究院 (Canadan Institue oF Advanced Research, 简称 CIFAR) 的基金管理负责人, Melvin Silverman 交谈.
从2004年开始资助这个团体十年,总额一千万加元. CIFAR 成为当时, 世界上唯一支持神经网络研究的机构.
不夸张地说, 如果没有 2004年 CIFAR 的资金支持, 人类在人工智能的研究上可能还会在黑暗中多摸索几年.
Hinton 拿到资金支持不久,做的第一件事,就是先换个牌坊.
鉴于"神经网络"口碑不好,也被 Hinton 改了名, 换了姓, 叫 "深度学习" (Deep Learning) 了.
2006年, Hinton 和合作者发表论文, "A fast algorithm for deep belief nets" (深信度网络的一种快速算法).
在这篇论文里, Hinton 在算法上的核心,是借用了统计力学里的"玻尔兹曼分布"的概念 (一个微粒在某个状态的几率,和那个状态的能量的指数成反比, 和它的温度的倒数之指数成反比), 使用所谓的"限制玻尔兹曼机" (RBM)来学习.
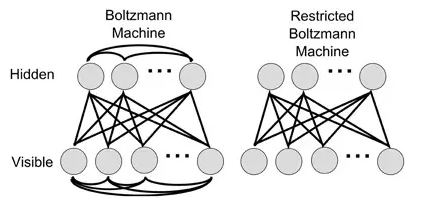
RBM 引入了统计力学常用的概率工具. 而在七十年代, 概率和不确定性恰恰是主流的人工智能的研究者极为痛恨的.
RBM 相当于一个两层网络,同一层神经元之间不可连接 (所以叫 "限制"), 可以对神经网络实现"没有监督的训练" (unsupervised training). 深信度网络就是几层 RBM 叠加在一起.
略掉技术细节, RBM 可以从输入数据中进行预先训练, 自己寻找发现重要的特征, 对神经网络连接的权重进行有效的初始化. 这属于一种叫做特征提取器 (feature extractor)的神经网络, 也称自动编码器 (autoencoder).
经过 RBM 预先训练初始化后的神经网络,再用反向传播算法微调,效果就好多了.
Hinton 后来指出, 深度学习的突破:
- 计算蛮力的大幅度提高;
- 聪明有效地对网络链接权重的初始化也是一个重要原因。
Hinton 的论文里,经过六万个MNIST 数据库的图像培训后, 对于一万个测试图像的识别错误率最低降到了只有 1.25%.
虽然这还不足以让主流学术界改变观点,但深度学习的发展已经见到一丝曙光.
黎明
2009年六月, 斯坦福大学的 Rajat Raina 和 Andrew Ng(吴恩达) 合作发表论文, "用GPU大规模无监督深度学习" ("Large-scale Deep Unsupervised Learning using Graphic Processors).
论文模型里的参数总数 (就是各层不同神经元之间链接的总数),达到一亿,与之相比, Hinton 2006年的论文里用到的参数数目,只有一百七十万.
论文结果显示,使用GPU运行速度和用传统双核CPU相比, 最快时要快近七十倍. 在一个四层, 一亿个参数的深信度网络上,使用GPU把程序运行时间从几周降到一天.
另一个关键点是:
把训练神经网络的图像,刻意通过旋转, 放大缩小和弹性形变等方式进行改变.这样用于训练的图像数目大大增加. 使用 GPU后,改变六万张训练图像的计算速度从93秒降到了9秒钟, 快了十倍.
不断用计算变形实现的图像, 等价于一个数量无限的训练数据库。
论文结果显示,一个六层, 拥有一千两百万个参数的神经网络模型:
- 经过2个小时的训练后,在测试图像上的错误率就降到1%.
- 经过114个小时训练后,模型的测试错误率更是降到了 0.35%.
2012 年还在斯坦福大学做研究生的黎越国同学 (Quoc Viet Le) 领衔, 和他的导师吴恩达,以及众多谷歌的科学家联合发表论文, "用大规模无监督学习建造高层次特征" (Building High-level Features Using Large Scale Unsupervised Learning).
黎越国的文章中, 使用了九层神经网络,网络的参数数量高达十亿, 是 2009年Raina 论文模型的十倍.
作为参照,按照丹麦学者 Bente Pakkenberg 2003年的估算, 人的脑皮层 (Neocortex) 内就有接近一百五十万亿个神经元突触 (Synapse, 是连接神经元传递信号的结构), 是黎同学的模型参数数量的十万倍.
用于训练这个神经网络的图像, 都是从谷歌的录像网站 youtube 上截屏获得. 一千万个原始录像, 每个录像只截取一张图片, 每张图片有四万个像素, 与之相比,先前大部分论文使用的训练图像,原始图像的数目大多在十万以下, 图片的像素大多不到一千.
黎越国的计算模型分布式地在一千台机器 (每台机器有 16个CPU内核)上运行,花了三天三夜才完成培训.
经过培训的神经网络,在一个名叫 ImageNet 的共享图像数据库里,面对两万两千个不同类别,一千四百万个图像中, 分类识别的正确率达到了 15.8%. 而在此之前最好的公开发表的模型,正确率只有 9.3%.
深度学习的研究进步在加速,但要说服更多的主流的人工智能研究者加入,需要的是更多的, 可直接对比的, 大幅领先的, 无可辩驳的计算结果,
Quoc Viet Le's Info.
Link: http://cs.stanford.edu/~quocle/
I did my undergraduate at ANU & NICTA (Canberra, Australia), under the supervision of Professor Alex Smola.
Made in Australia.
日出
性在生物进化中的目的,不是制造适合某个单一环境的, 最优秀的个体基因,而是为了制造最容易和其它多种基因合作的基因,这样在多变的外界环境下,总有一款可以生存延续下来.
优秀个体在有性繁殖中,虽然损失了一半的基因,短期内看上去不是好事.但是长期看,生物组织整体的存活能力,更加稳健强大.
2012年七月, Hinton 教授发表论文, "通过阻止特征检测器的共同作用来改进神经网络" (Improving neural networks by preventing co-adaptation of feature detectors).
论文中为了解决过度拟合的问题,采用了一种新的称为"丢弃" (Dropout) 的算法.
丢弃算法的具体实施,是在每次培训中, 给每个神经元一定的几率 (比如 50%),假装它不存在,计算中忽略不计.
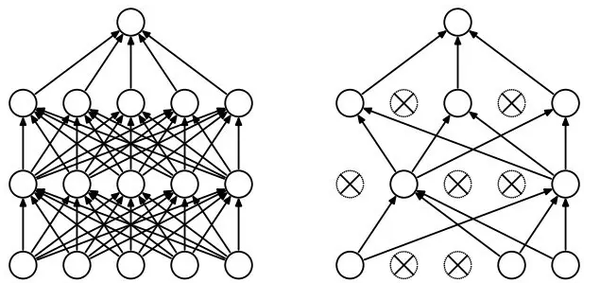
从一个角度看, 丢弃算法,每次训练时使用的是不同架构的神经网络 (因为每次都有部分神经元装死),最后训练出来的东西,相当于不同架构的神经网络模型的平均值.
使用丢弃算法的神经网络,被强迫用不同的,独立的,神经元的子集来接受学习训练. 这样网络更强健,避免了过度拟合的死胡同,不会因为外在输入的很小变化,导致输出质量的很大差异.
论文结果显示,使用丢弃算法后, 在诸如 MINST, TIMID, CIFAR-10 等多个经典语音和图像识别的问题中, 神经网络在测试数据中的错误率, 相对于经典的深度学习算法,都获得了可观的进步 (错误率下降了 10% 到 30% 不等).
严乐春老师, 使用卷积神经网络的技术, 八十年代末, 在手写数字识别上获得突破. 但是后来,在通用的图像识别问题上, 支持向量机 (SVM) 的技术逐渐成为业界的主流.
二十多年后, 仰仗着计算速度, 数据量和算法的迅速进步,卷积神经网络又卷土重来了.
2012年,Hinton 教授和他的两个研究生 Alex Krizhevsky, Illya Sutskever 将深度学习的最新技术用到 ImageNet 的问题上.
这个神经网络, 使用了丢弃 (Dropout) 算法, 和修正线性单元 (RELU)的激励函数.
2011 年, 加拿大的蒙特利尔大学学者 Xavier Glorot 和 Yoshua Bengio 发表论文, "Deep Sparse Rectifier Neural Networks". (深而稀疏的修正神经网络).
论文的算法中使用一种称为"修正线性单元" (REctified Linear Unit, 又称 RELU) 的激励函数. 用数学公式表达: rectifier (x) = max (0, x ).

对于 RELU 而言, 如果输入为负值, 输出为零. 否则输入和输出相等.
换而言之,对于特定的输入, 统计上有一半神经元是没有反应,保持沉默的.
对于神经网络是否进行"预先训练"过并不敏感。
RELU 的优势还有下面三点:
-
传统的激励函数,计算时要用指数或者三角函数,计算量要比简单的RELU 至少高两个数量级.
-
RELU 的导数是常数, 非零即一, 不存在传统激励函数在反向传播计算中的"梯度消失问题".
-
由于统计上,约一半的神经元在计算过程中输出为零,使用 RELU 的模型计算效率更高,而且自然而然的形成了所谓 "稀疏表征" (sparse representation), 用少量的神经元可以高效, 灵活,稳健地表达抽象复杂的概念.
他们的模型,是一个总共八层的卷积神经网络,有六十五万个神经元,六千万个自由参数.
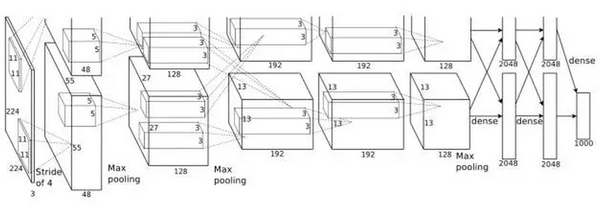
Hintong 教授的团队, 使用了 两个 Nvidia 的 GTX 580 GPU (内存 3GB, 计算速度 1.6 TFLOPS), 让程序接受一百二十万个图像训练, 花了接近六天时间.
经过训练的模型,面对十五万个测试图像时,预测的头五个类别的错误率只有 15.3%, 在2012年 ImageNet 的竞赛, 三十个团队的测试结果中, 稳居第一.
排名第二的来自日本团队的模型,相应的错误率则高达 26.2%.
所有其他团队, 采用的都是流行将近二十年的的支持向量机的技术。但是这一次,毫无疑义的,被神经网络的技术彻底超越了。
Now this is not the end. It is not even the beginning of the end. But it is, perhaps, the end of the beginning.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号