[Airflow] 01 - Install and UI
Ref: https://airflow.apache.org/

Ref: Extra Packages
Ref: https://github.com/tuanavu/airflow-tutorial [youtube教程和代码]
有点太全了,还是i一步一步的学习的代码demo为好。
Ref: How to write your first DAG in Apache Airflow - Airflow tutorials.
Ref: Airflow tutorial 2: Set up airflow environment with docker
学习向导
一、跟着官方教程走
安装Airflow。
pip install \ apache-airflow[postgres,gcp]==1.10.12 \ --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-1.10.12/constraints-3.7.txt"
可能安装过程中,会出现类似的报错。
ERROR: Cannot uninstall 'PyYAML'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
暂时降级pip的版本,安装即可。安装完毕后,再reset pip version to latest。
I used follow steps and resolved this problem
Reduced version:
pip install --upgrade --force-reinstall pip==9.0.3
Tried to re-install package:
pip install xxx --disable-pip-version-check
At last, recover the latest version for pip:
pip install --upgrade pip
Ref: Ubuntu18.04安装Airflow
运行需要以下几步。
export AIRFLOW_HOME=~/airflow
9、初始化数据库
airflow initdb
10、启动Web服务器,默认端口为8080
airflow webserver -p 8080
11、启动调度程序
airflow scheduler
二、跟着example走
Ref: airflow环境搭建与使用

DAG:dag_id
Schedule:调度时间
Owner:dag拥有者
Recent Tasks:这里包含9个圆圈,每个圆圈代表task的执行状态和次数
圈1 success:现实成功的task数,基本上就是该tag包含多少个task,这里基本上就显示几。
圈2 running:正在运行的task数
圈3 failed:失败的task数
圈4 unstream_failed:
圈5 skipped:跳过的task数
圈6 up_for_retry:执行失败的task,重新执行的task数
圈7 queued:队列,等待执行的task数
圈8 :
圈9 scheduled:刚开始调度dag时,这一次执行总共调度了dag下面多少个task数,并且随着task的执行成功,数值逐渐减少。
Last Run:dag最后执行的时间点
DAG Runs:这里显示dag的执行信息,包括3个圆圈,每个圆圈代表dag的执行状态和次数
圈1 success:总共执行成功的dag数,执行次数
圈2 runing:正在执行dag数
圈3 faild:执行失败的dag数
Links:
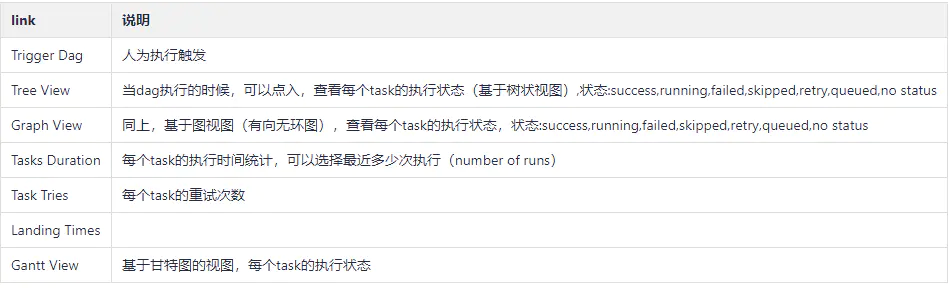
Code View: 查看任务执行代码
Logs :查看执行日志,比如失败原因
Refresh :刷新dag任务
Delete Dag :删除该dag任务
三、跟着教学视频走
Ref: [Getting started with Airflow - 1] Installing and running Airflow using docker and docker-compose [视频不错]
Ref: https://www.manning.com/books/data-pipelines-with-apache-airflow

江湖地位
一、ETL
Ref: 英语流利说基础数据平台
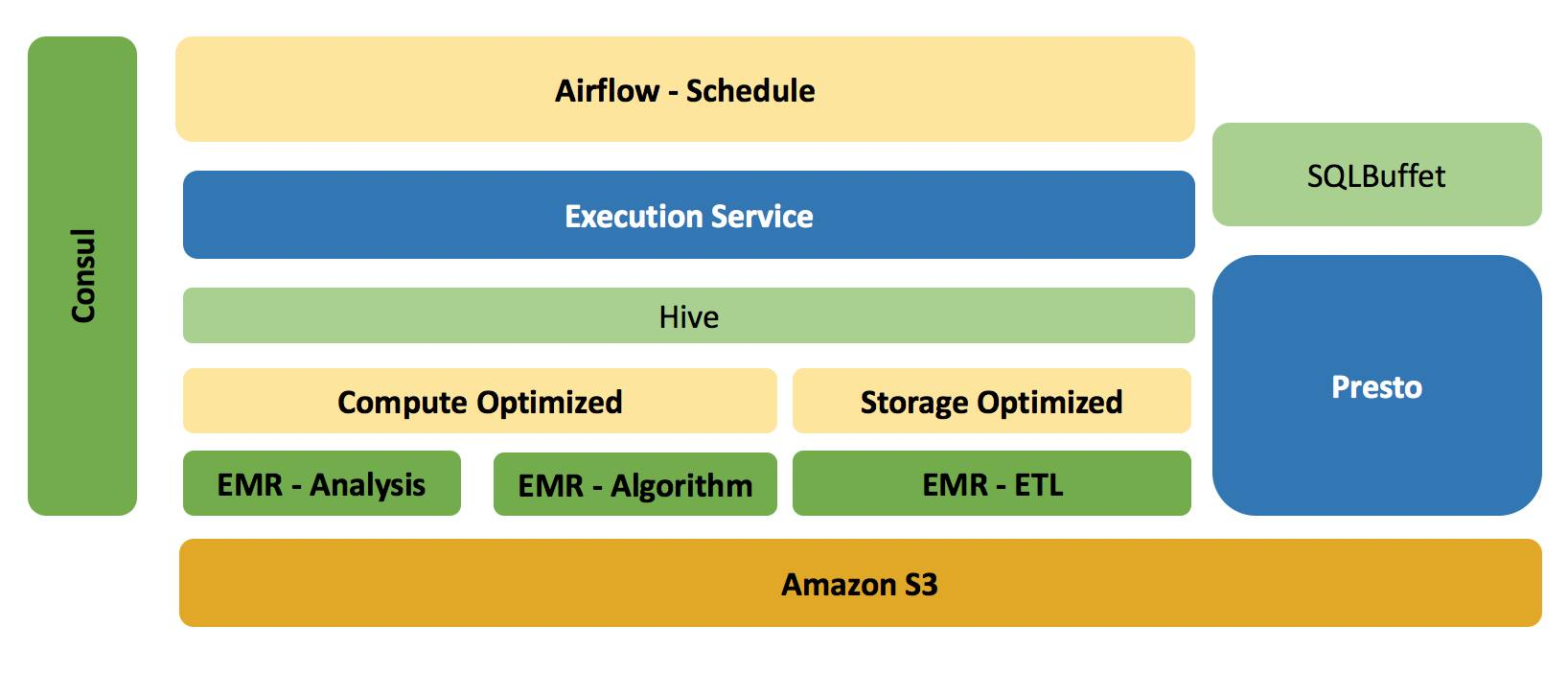
- 基于 S3 和 EMR 做到存储层面的共享,而在计算资源层面做到隔离。
- Amazon EMR 在于我们可以很方便并快速的构建一个基于 Hadoop,Spark,Hive等大数据产品的计算集群,如果不是需要长久服役,我们可以在其所有 Job 完成之后,销毁集群,而并不影响数据的持久化,因为所有的数据都保存在 S3。
对于集群上的任务,他们的特点可能都不太一样,比如
- 推荐和算法业务可能对集群的计算能力要求较高,
- 而 ETL 类型的任务,可能又对存储或内存要求较高。
- 任务与EMR集群管理系统 - Execution Service
Execution Service(以下称为ES)用来管理EMR集群的创建,扩容,以及销毁,另外还负责每天流利说所有调度任务的提交,执行,以及结果的反馈。 目前ES支持的任务类型包括 Bash,HQL(Hive SQL Script),以及 Spark。
所有对集群的操作,以及提交的任务,我们统一维护到 MySQL 中。
- Airflow
流利说目前所有的 ETL 任务都是通过 Airflow 来调度的,并且 Airflow Task 之间的依赖性可通过 Python 来定义,这使得我们的学习以及维护成本更低。
ETL 的基本流程是,我们通过数据同步工具,把数据以 T+1 的方式从 MongoDB / Redis Dump 到 S3,并且在此过程中,同样会把表的结构同步到 S3,然后利用最新的表结构和数据,在 Hive 中建立相对应的库和表。
对于原始数据,一般数据最初以 Json 的格式保存到一个名为 raw_data 的库中,在后续的 ETL Job 中,我们会对 raw_data 库中的表进行清洗,计算以及转换,最终数据以 ORC 或是 Parquet 的方式保存到 Prod 的库中。
另外,Airflow的调度同样承担每天集群的构建工作,整个生命周期类似:Start -> CreateCluster -> Jobs submission --> TerminateCluster --> End.
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号