[Spark] 04 - What is Spark Streaming
前言
Ref: 一文读懂 Spark 和 Spark Streaming【简明扼要的概览】
在讲解 "流计算" 之前,先做一个简单的回顾,亲!
一、MapReduce 的问题所在
MapReduce 模型的诞生是大数据处理从无到有的飞跃。但随着技术的进步,对大数据处理的需求也变得越来越复杂,MapReduce 的问题也日渐凸显。
通常,我们将 MapReduce 的输入和输出数据保留在 HDFS 上,很多时候,复杂的 ETL、数据清洗等工作无法用一次 MapReduce 完成,所以需要将多个 MapReduce 过程连接起来:
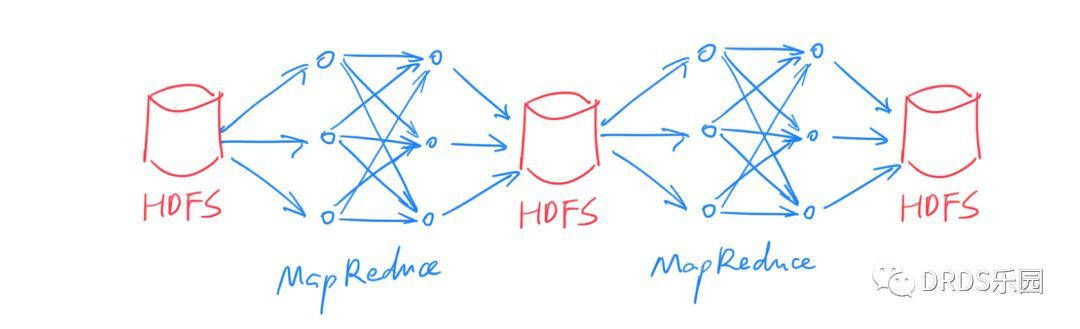
Figure,上图中只有两个 MapReduce 串联,实际上可能有几十个甚至更多,依赖关系也更复杂。
这种方式下,每次中间结果都要写入 HDFS 落盘保存,代价很大(别忘了,HDFS 的每份数据都需要冗余若干份拷贝)。
另外,由于本质上是多次 MapReduce 任务,调度也比较麻烦,实时性无从谈起。
二、Spark 与 RDD 模型
Fault-tolerance
一般来说,想做到 fault-tolerance 只有两个方案:
- 要么存储到外部(例如 HDFS),
- 要么拷贝到多个副本。
- Spark 大胆地提出了第三种——重算一遍。
但是之所以能做到这一点,是依赖于一个额外的假设:所有计算过程都是确定性的(deterministic)。
Spark 借鉴了函数式编程思想,提出了 RDD(Resilient Distributed Datasets),译作“弹性分布式数据集”。
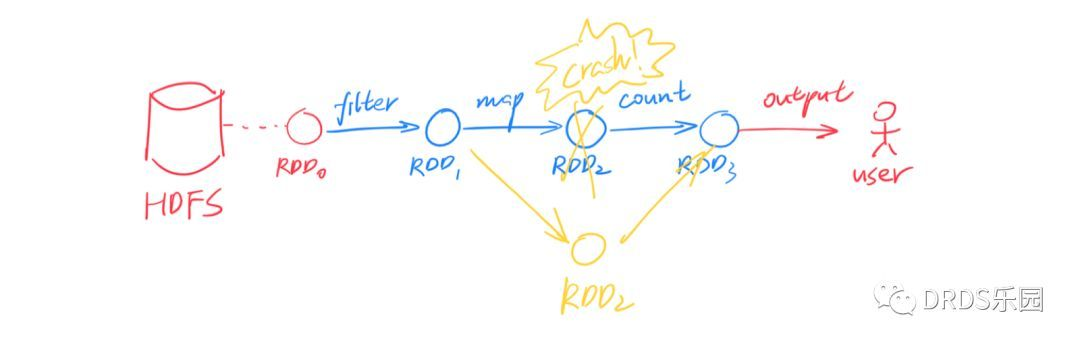
Figure,上图演示了 RDD 分区的恢复。为了简洁并没有画出分区,实际上恢复是以分区为单位的。
只读的、分区的 数据集合
RDD 的数据由多个分区(partition)构成,这些分区可以分布在集群的各个机器上,这也就是 RDD 中 “distributed” 的含义。
熟悉 DBMS(数据库管理系统)的同学可以把 RDD 理解为逻辑执行计划,partition 理解为物理执行计划。
窄依赖 & 宽依赖
之前有涉及到一部分内容:[Spark] 01 - What is Spark
简单的说,宽依赖就是 "一对多“。
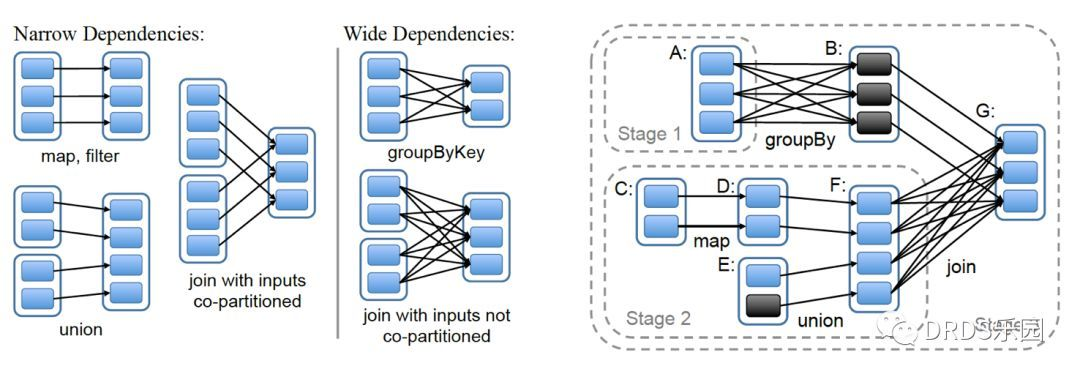
在执行时,窄依赖可以很容易的按流水线(pipeline)的方式计算:对于每个分区从前到后依次代入各个算子即可。
然而,宽依赖需要等待前继 RDD 中所有分区计算完成;
换句话说,宽依赖就像一个栅栏(barrier)会阻塞到之前的所有计算完成。整个计算过程被宽依赖分割成多个阶段(stage),如上右图所示。
声明式编程 - Spark SQL
命令式 & 声明式 编程:声明式的要简洁的多!但声明式编程依赖于执行者产生真正的程序代码,所以除了上面这段程序,还需要把数据模型(即 schema)一并告知执行者。
声明式编程最广为人知的形式就是 SQL。Spark SQL 就是这样一个基于 SQL 的声明式编程接口。
你可以将它看作在 Spark 之上的一层封装,在 RDD 计算模型的基础上,提供了 DataFrame API 以及一个内置的 SQL 执行计划优化器 Catalyst。
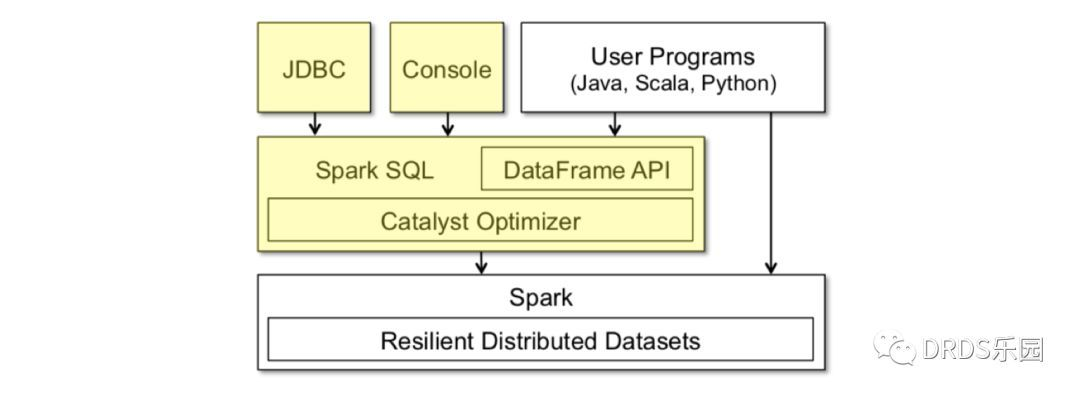
代码生成(codegen)转化成直接对 RDD 的操作
DataFrame 就像数据库中的表,除了数据之外它还保存了数据的 schema 信息。
Catalyst 是一个内置的 SQL 优化器,负责把用户输入的 SQL 转化成执行计划。
Catelyst 强大之处是它利用了 Scala 提供的代码生成(codegen)机制,物理执行计划经过编译,产出的执行代码效率很高,和直接操作 RDD 的命令式代码几乎没有分别。
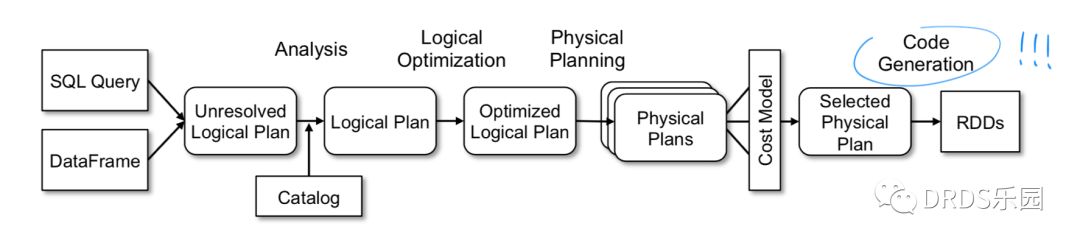
上图是 Catalyst 的工作流程,与大多数 SQL 优化器一样是一个 Cost-Based Optimizer (CBO),但最后使用代码生成(codegen)转化成直接对 RDD 的操作。
流计算框架:Spark Streaming
基本认识
一、批处理 & 流计算
"批处理"和"流计算"被看作大数据系统的两个方面。
-
- 以 Kafka、Storm 为代表的流计算框架用于实时计算,
- 而 Spark 或 MapReduce 则负责每天、每小时的数据批处理。
在 ETL 等场合,这样的设计常常导致同样的计算逻辑被实现两次,耗费人力不说,保证一致性也是个问题。
Spark Streaming 基于 Spark,另辟蹊径提出了 D-Stream(Discretized Streams)方案:将流数据切成很小的批(micro-batch),用一系列的短暂、无状态、确定性的批处理实现流处理。
开发者只需要维护一套 ETL 逻辑即可同时用于批处理和流计算。
更快速的失败恢复 D-Stream
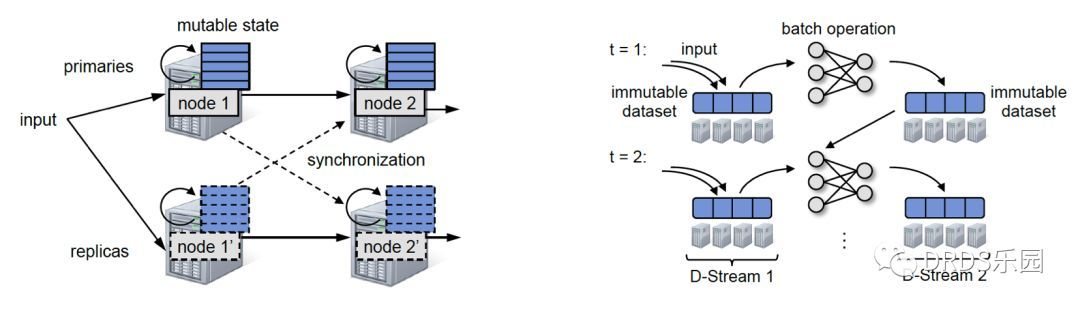
The figure,
-
- 左图,为了在持续算子模型的流计算系统中保证一致性,不得不在主备机之间使用同步机制,导致性能损失,Spark Streaming 完全没有这个问题;
- 右图,D-Stream 的原理示意图。
实际上,新的状态 RDD 总是不断生成,而旧的 RDD 并不会被“替代”,而是作为新 RDD 的前继依赖。
对于底层的 Spark 框架来说,并没有时间步的概念,有的只是不断扩张的 DAG 图和新的 RDD 节点。
Spark SQL 之 流处理 Spark Structured Streaming
Spark 通过 Spark Streaming 拥有了流计算能力,那 Spark SQL 是否也能具有类似的流处理能力呢?答案是肯定的。
只要将数据流建模成一张不断增长、没有边界的表,在这样的语义之下,很多 SQL 操作等就能直接应用在流数据上。
出人意料的是,Spark Structured Streaming 的流式计算引擎并没有复用 Spark Streaming,而是在 Spark SQL 上设计了新的一套引擎。
因此,从 Spark SQL 迁移到 Spark Structured Streaming 十分容易,但从 Spark Streaming 迁移过来就要困难得多。
基于这样的模型,Spark SQL 中的大部分接口、实现都得以在 Spark Structured Streaming 中直接复用。
将用户的 SQL 执行计划转化成流计算执行计划的过程被称为 增量化(incrementalize),这一步是由 Spark 框架自动完成的。
对于用户来说只要知道:每次计算的输入是某一小段时间的流数据,而输出是对应数据产生的计算结果。
二、窗口(window)
窗口(window)是对过去某段时间的定义。
批处理中,查询通常是全量的(例如:总用户量是多少);而流计算中,我们通常关心近期一段时间的数据(例如:最近24小时新增的用户量是多少)。
用户通过选用合适的窗口来获得自己所需的计算结果,常见的窗口有滑动窗口(Sliding Window)、滚动窗口(Tumbling Window)等。
三、水位(watermark)
水位(watermark)用来丢弃过早的数据。
在流计算中,上游的输入事件可能存在不确定的延迟,而流计算系统的内存是有限的、只能保存有限的状态,一定时间之后必须丢弃历史数据。
以双流 A JOIN B 为例,假设窗口为 1 小时,那么 A 中比当前时间减 1 小时更早的数据(行)会被丢弃;如果 B 中出现 1 小时前的事件,因为无法处理只能忽略。
四、三个角色
Spark 中有三个角色:Driver, Worker 和 Cluster Manager。
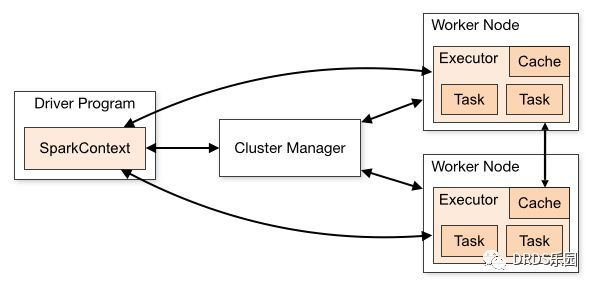
- 驱动程序(Driver)即用户编写的程序,对应一个 SparkContext,负责任务的构造、调度、故障恢复等。驱动程序可以直接运行在客户端,例如用户的应用程序中;也可以托管在 Master 上,这被称为集群模式(cluster mode),通常用于流计算等长期任务。
- Cluster Manager 顾名思义负责集群的资源分配,Spark 自带的 Spark Master 支持任务的资源分配,并包含一个 Web UI 用来监控任务运行状况。多个 Master 可以构成一主多备,通过 ZooKeeper 进行协调和故障恢复。通常 Spark 集群使用 Spark Master 即可,但如果用户的集群中不仅有 Spark 框架、还要承担其他任务,官方推荐使用 Mesos 作为集群调度器。
- Worker节点 负责执行计算任务,上面保存了 RDD 等数据。
五、总结
Spark 是一个同时支持批处理和流计算的分布式计算系统。Spark 的所有计算均构建于 RDD 之上,RDD 通过算子连接形成 DAG 的执行计划,RDD 的确定性及不可变性是 Spark 实现故障恢复的基础。Spark Streaming 的 D-Stream 本质上也是将输入数据分成一个个 micro-batch 的 RDD。
Spark SQL 是在 RDD 之上的一层封装,相比原始 RDD,DataFrame API 支持数据表的 schema 信息,从而可以执行 SQL 关系型查询,大幅降低了开发成本。
Spark Structured Streaming 是 Spark SQL 的流计算版本,它将输入的数据流看作不断追加的数据行。
"厦大" 流计算
至此,通过 一文读懂 Spark 和 Spark Streaming 了解了大概框架和概念,下面继续”厦大“课程的学习,goto: 流计算概述
一、概述、特征
流计算特征
- 快速到达,大小不定;
- 来源众多,格式复杂;
- 一次性处理,也可以之后丢弃;
- 总体价值大于个别数据;
- 顺序以及完整性不太重要;
流计算应用
对时间比较敏感,过去太久的数据,其价值迅速降低。比如:用户点击流。
根据大数据,进行秒级响应进行商品推荐。
流计算框架
- 高性能
- 海量式
- 实时性
- 分布式
- 可靠性
- 商业级流计算平台:IBM StreamBase, IBM InfoSphere Streams
- 开源流计算框架:Twitter Storm, Yahoo! S4
- 定制流计算框架:Dstream (Baidu), Puma (Facebook)
- 数据实时采集(每秒数百MB的数据采集,such as Facebook Scribe, Linkedin Kafka, Chukwa, Flume)
- 数据实时计算
- 数据实时服务
既然是实时结果,那自然是主动推送给用户,也就是实时推荐。
二、SparkStreaming 解析
DStream 角色
本质是“tiny batch processing",切分到秒级响应。
DStream就是一堆Tiny RDD的集合,使用”微小“批处理模拟流计算。

Receiver 角色
每个receiver 单独负责一个 Input DStream。
-
- 套接字流(基本输入源)
- 文件流(基本输入源)
- RDD 队列流(基本输入源)
- 从Kafka中读取的输入流(高级输入源)
Receiver监控这几种流,然后交给流计算组件去处理。
三、SparkStreaming 编程
SparkStream 的指挥官
编写Streaming程序的套路,指挥官:streamingContext。
(1) 创建DStream,也就定义了输入源。
(2) 对DStream进行一些 “转换操作” 和 "输出操作"。
(3) 启动流计算,接收数据:streamingContext.start()
(4) 结束流计算,streamingContext.awaitTermination()
(5) 手动结束流计算进程:streamingContext.stop()
交互环境
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, 1)
独立程序
from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext conf = SparkConf() conf.setAppName('TestDStream') conf.setMaster('local[2]') sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 1)
基本输入源编程
* 文件流
实时自动监控文件内容、目录内容。文件夹中新的文件添加进来,就会形成流,读入。
from pyspark import SparkContext from pyspark.streaming import StreamingContext
# 定义输入源 ssc = StreamingContext(sc, 10) lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile') # <---- 这是文件夹!
# 转换和输出操作 words = lines.flatMap(lambda line: line.split(' ')) # 拍扁了一个个可乐罐,得到单词集合 wordCounts = words.map(lambda x: (x,1)).reduceByKey(lambda a,b: a+b) # 词频汇总
wordCounts.pprint() ssc.start() ssc.awaitTermination()
运行代码:
/usr/local/spark/bin/spark-submit FileStreaming.py
* 套接字流
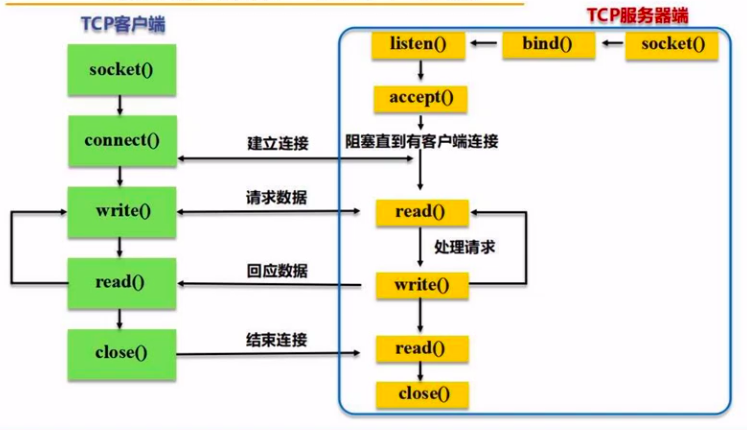
客户端,接收
客户端进行刺频统计,并显示结果。
#!/usr/bin/env python3 # NetworkWordCount.py from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: NetworkWordCount.py <hostname> <port>", file=sys.stderr) exit(-1) sc = SparkContext(appName = "PythonStreamingNetworkWordCount") ssc = StreamingContext(sc, 1) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) counts = lines.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a,b: a+b) counts.pprint() ssc.start() ssc.awaitTermination()
客户端从服务端接收流数据:
# 用客户端向服务端发送流数据 $ /usr/local/spark/bin/spark-submit NetworkWordCount.py localhost <端口>
服务端,发送
(a) 系统自带服务端 nc。
# 打开服务端 $nc -lk <端口号>
(b) 自定义服务端:有连接则发送一段字符串过去。
#!/usr/bin/env python3
# DataSourceSocket.py import socket server =socket.socket() server.bind('localhost', 9999) server.listen(1) while 1:
# step 1 print("I'm waiting for the connect") conn, addr = server.accept() print("Connect success! Connection is from %s " % addr[0])
# step 2,发送的内容作为测试例子 print("Sending data ...") conn.send('I love hadoop I love spark hadoop is good spark is fast'.encode())
# step 3 conn.close() print('Connection is broken.')
启动服务端发送流数据:
# 用客户端向服务端发送流数据 $ /usr/local/spark/bin/spark-submit DataSourceSocket.py
* RDD队列流
#!/usr/bin/env python3 import time from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__name__": sc = SparkContext(appName="PythonStreamingQueueStream") ssc = StreamingContext(sc, 2) rddQueue = [] for i in range(5): # 每个rdd包含这1000个数字。 rddQueue += [ssc.sparkContext.parallelize( [j for j in range(1, 1001) ], 10)] time.sleep(1)
# 创建了一个RDD队列流 inputStream = ssc.queueStream(rddQueue) # 转换和输出操作:统计每个余数出现的频率 mappedStream = inputStream.map(lambda x: (x % 10, 1)) reducedStream = mappedStream.reduceByKey(lambda a, b: a+b) reducedStream.pprint() ssc.start() ssc.stop(stopSparkContext = True, stopGraceFully = True) # 等待所有的数据处理完后优雅地退出
DStream转换操作
Ref: Spark入门:DStream转换操作
一、DStream "无状态" 转换操作
何为“无状态”?
我们之前 “套接字流” 部分介绍的词频统计,就是采用无状态转换;
每次统计,都是只统计当前批次到达的单词的词频,和之前批次无关,不会进行累计。
下面给出一些无状态转换操作的含义:
* map(func) :对源DStream的每个元素,采用func函数进行转换,得到一个新的DStream;
* flatMap(func): 与map相似,但是每个输入项可用被映射为0个或者多个输出项;
* filter(func): 返回一个新的DStream,仅包含源DStream中满足函数func的项;
* repartition(numPartitions): 通过创建更多或者更少的分区改变DStream的并行程度;
* union(otherStream): 返回一个新的DStream,包含源DStream和其他DStream的元素;
* count():统计源DStream中每个RDD的元素数量;
* reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream;
* countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数;
* reduceByKey(func, [numTasks]):当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来;
* join(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新DStream;
* cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组;
* transform(func):通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作。
二、DStream "有状态" 转换操作
基于滑动窗口的转换
下面给给出一些窗口转换操作的含义:
* window(windowLength, slideInterval):基于源DStream产生的窗口化的批数据,计算得到一个新的DStream;
* countByWindow(windowLength, slideInterval):返回流中元素的一个滑动窗口数;
* reduceByWindow(func, windowLength, slideInterval):返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算;
* reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数;
* reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]):更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
* countByValueAndWindow(windowLength, slideInterval, [numTasks]):当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
逆操作,如何减少计算量?
参考:https://blog.csdn.net/qq_39394264/article/details/90721719
问:reduceByWindow() 和 reduceByKeyAndWindow() 让我们可以对每个窗口更高效地进行归约操作。
它们接收一个归约函数,在整个窗口上执行,比如 +。除此以外,它们还有一种特殊形式,通过只考虑新进入窗口的数据和离开窗 口的数据,让 Spark 增量计算归约结果。
这种特殊形式需要提供归约函数的一个逆函数,比 如 + 对应的逆函数为 -。对于较大的窗口,提供逆函数可以大大提高执行效率。

[左图] 原本的意图是”重新计算这个窗口”,但没有必要。
[右图] 只计算“增量”。
代码展示:
归约操作在如下代码中的体现:30代表窗口大小,10是步长;
两个lambda中的y的理解,第一个代表“新增”,第二个代表“淘汰出窗口“的内容。

“数据源”终端:
nc -lk 9999
“流计算”终端:
/usr/local/spark/bin/spark-submit \
> WindowedNetworkWordCount.py localhost 9999
追踪状态变化的转换
通过 updateStateByKey() 操作实现历史状态不断地累加,第二个参数last_sum相当于static变量。
通过 ssc.checkpoint() 声明一个检查点,防止数据丢失
代码展示:
from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr) exit(-1)
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount") ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/")
# RDD with initial state (key, value) pairs initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)]) def updateFunc(new_values, last_sum): return sum(new_values) + (last_sum or 0) # 第一次时last_sum不存在的,就使用0
# 创建“套接字流” lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\ .map(lambda word: (word, 1))\ .updateStateByKey(updateFunc, initialRDD=initialStateRDD) # <--- 跨批次的状态累加
# map之后,按正常来讲用reduceByKey(),是“无状态”模式;
# (hadoop,1), (hadoop,1), (spark,1), (spark,1)
# (hadoop,2), (spark,2)
# 将结果保存在文本或打印出
running_counts.saveAsTextFiles("file:///usr/local/spark/mycode/streaming/output.txt")
running_counts.pprint()
ssc.start()
ssc.awaitTermination()
"数据源" 终端:
nc -lk 9999
测试“跨批次”状态维护,所以先后输入若干句子,词频结果能够“跨批次”累计。
“流计算” 终端:
/usr/local/spark/bin/spark-submit \
NetworkWordCountStateful.py localhost 9999
DStream输出操作
一、输出到文本
流计算的结果保存到文本文件中去,放在updateStateByKey之后。
running_counts.saveAsTextFiles("file:///usr/local/spark/mycode/streaming/output.txt")
二、写入数据库
数据库方面的操作。
service mysql start mysql -u root -p # 提示输入密码
mysql> use spark mysql> create table wordcount(word char(20), count int(4));
为了让MySQL支持Python,需要安装 PyMySQL。
流计算的结果保存到数据库中去,放在running_counts.pprint() 之后。
# 写入操作: each partition
def dbfunc(records): db = pymysql.connect("localhost", "root", "123456", "spark") cursor = db.cursor()
def doinsert(p): sql = "insert into wordcount(word,count) values ('%s','%s')" % (str(p)[0]),str(p[1])) try: cursor.execute(sql) db.commit() except: db.rollback()
# 每一个分区中的每一条记录,进行sql操作 for item in records: doinsert(item)
def func(rdd):
# 分区太多,可能会并发连接数据库;故,这里改为3个分区 repartitionedRDD = rdd.repartition(3)
# 处理每一个分区 repartitionedRDD.foreachPartition(dbfunc)
# DStream 类型:running_counts,本质上就是一堆rdd的集合,这里自然就能够挨个遍历rdd running_counts.foreachRDD(func) ssc.start() ssc.awaitTermination()
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号