
python中的函数
函数是组织好的,是一个固定的可重复使用的程序段,或称其为一个子程序,在接收了定义的参数后,实现单一或相关联功能,最后还可以返回定义的内容。
函数的主要作用:1,避免代码重复;2,方便修改;3,能保持代码的一致性。
函数主要为两类:内置函数和自定义函数,内置函数可以直接引用,下面重点说一下自定义函数。
函数的定义、函数的命名规则、函数定义的基本语法格式、函数的调用、参数、函数的作用域
递归函数、嵌套函数、闭包、高阶函数、匿名函数、自执行函数、回调函数、常用内置函数、
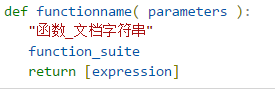
- def 关键字开头,后面加函数名和括号以及冒号,括号中根据需要定义需要传入的参数
- 函数体严格遵守缩进原则
- 根据需要,return所需信息
- 本质上,可以将函数名理解成是数据类型是“function”的特殊变量,函数名存储的是储存函数体的 “ 数据类型,函数名,函数的内存地址 ” ,函数体是对象。所以函数名作为一种变量可以 赋值 给其他变量,并且函数名也可以当做参数传递给特定的函数,另外,函数名也可以作为函数调用的结果,返回值是函数名。只有当函数名后面加上包含指定类型参数的括号,才能调用执行函数体。
- 字母数字下划线的组合,数字不能开头,不能用特殊字符
- 不能使用保留字符
- 字母一律小写
- 私有函数在函数前加一个下划线_
- 调用自定义函数,必须先对函数定义,再调用。顺序错,程序报错
- 函数名加括号,进行函数的调用
- 传入参数,一定根据定义函数时对参数的规定传入
- 如果调用的函数有返回值,可通过定义变量进行接收(方便重复使用)或者直接在语句中使用
函数定义过程中的是形式参数(形参),起到占位符的作用,函数在调用过程中传入的参数是实际参数(实参)。python中的基本数据类型(字符串、数字、列表、元组、字典、集合)都可以作为实参直接传递给调用的函数,传递参数时可根据实际需要,以键值对形式传递。
在调用函数使用的参数类型又可以分为四类:必备参数、关键字参数、默认参数和不定长参数。
- 必备参数必须传入的参数,以正确的顺序传入函数。调用时的数量必须和声明时的一样。
- 默认参数(和必备参数相对应的),调用函数时,默认参数的值如果没有传入,则被认为是默认值。
- 位置参数,按参数的指定顺序进行传递的参数。
- 关键字参数,使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
- 不定长参数,需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。
- 在函数定义、函数调用过程中,函数的排放顺序,要严格按照(位置参数,关键字参数 / 默认参数,不定长参数)。先传value参数,然后传key-value参数
- 在函数调用时,括号中实际参数顺序必须是(基本数据类型形式的参数,键值对形式的参数),当默认参数前出现了关键字参数(键值对形式),则默认参数或者不传递进而使用默认值,如果传递的话,则同样要以键值对形式传递。当默认参数之前都是位置参数时(基本数据类型形式的参数),则需要传递默认参数的时候,可以用键值对,也可以用基本数据类型。另外,不定长参数前如果出现了键值对类型的实参,则只能再传递键值对类型的参数
- 不定长参数类型可分为 *args,**kwargs两部分, *args 用于接收多余的基本数据类型的参数,以元组形式存储到变量args中;**kwargs用于接收多余的键值对实参,以字典形式存储到变量kwargs中。
上一个简单的例子:


1 a = 8 2 b =10 3 def func (i, j,name1, age1, n = 100, m = 50,*args,**kwargs): 4 5 print(""" 6 必备参数---->%s %s 7 关键字参数---->%s %s 8 默认参数----->%s %s 9 """%(i,j,name1,age1,n,m)) 10 print("*args------>",args) 11 print("**kwargs--->",kwargs) 12 func(a,[1,"来个列表"],age1 = 12,name1 = "sen",m =20,n = 5,c='你好',d=200)
命名空间,是存储变量的绑定关系的空间,不同变量的作用域不同,最主要的就是源于这个变量所在的命名空间决定的。查看变量作用域的方法,globals() locals()
在python中,能独自开辟和定义作用域的只有函数、类、模块。
函数作用域的寻址顺序(LEGB):
- L(local),局部,即当前代码块中
- E(Enclosing function locals),嵌套的父级函数作用域
- G(global),全局,此是模块级别的
- B(build-in),系统固定模块中
在内层函数局部拿到全局变量时,如果局部需要重新定义(初始化,此时会创建一个作用域在局部内的新变量,变量名和全局变量相同,但不是同一个),必须在其他的引用语句之前完成定义,即先赋值再引用,否则会出现局部变量的引用报错。如果要对全局变量进行改动,则要通过(global 变量名)提前对变量进行声明。类似的操作,在有多层嵌套函数时,要拿到本层函数的上一层函数的变量并修改,则用(nonlocal 变量)提前声明。在使用nonlocal 必须保证外部函数的变量在内部函数 执行 之前完成了初始化(内层函数的执行之前,而非定义之前完成外部变量的初始化)。使用nonlocal 绑定外层函数的变量时,必须保证所绑定的目标变量是外层函数的局部变量,而非经过global处理的全局变量,否则会出现找不到需要绑定的目标变量的错误。
注意的是,如果引用的上一级参数,或者是全局参数时,如果被引用的参数是列表、字典、集合等可变数据类型,当改变引用参数的元素时,参数本身的内存地址即参数本身不会发生变化,但其内部元素会根据操作变化。
来一段练习用的代码:
1 a_global = 0 2 def func_1(): 3 lst1 = ["第一层",1,2,3] 4 #global a_global #如果有对全局a_global进行修改的操作,提前声明 5 # a_global = 1 # 定义或初始化,需要在所有的引用之前,否则会报错 6 # print(a_global,id(a_global)) 7 print(lst1, id(lst1)) 8 def func_2(): 9 nonlocal a_global 10 print("第二层修改前------->",a_global,id(a_global)) 11 a_global = 2 12 nonlocal lst1 13 lst1 = ["第二层","a",1,2,3] 14 print("第二层修改后------->",a_global,id(a_global)) 15 print(lst1,id(lst1)) 16 a_global = 11 17 print(a_global, id(a_global)) 18 func_2() 19 20 print(lst1,id(lst1)) 21 print("第一层--------->",a_global,id(a_global)) 22 func_1() 23 print(a_global,id(a_global))
在函数内部可以调用函数,包括调用自身和调用其他函数。在函数内部调用当前函数本身,此类函数即递归函数。
递归函数的基本特点:
- 设置有明确的结束条件
- 每进行一次运算,问题的规模都会有所减小
- 递归的次数过多会造成栈溢出。(计算机中的函数调用时通过栈——stack又称堆栈,它是一种运算受限的线性表,这种数据结构实现的,调用一次加一层,返回退出一层减一层,调用过多会栈溢出。)
形象点一个比喻,将两块镜子相对而放,(放好的一瞬间)各种重叠各种包含的现象出来了,当然,如果镜子完全是平行相对放着的,则两面镜子之间相互嵌套的层次是无限的,防止这种现象出现,就需要在放置镜子的时候不能是平行的。另外一个例子,“从前有座山,山上有座庙,庙里有个老和尚,老和尚再给小和尚讲故事:从前有座山……”,当故事中最后一个老和尚把他的故事讲完,外层讲故事的的老和尚也就把故事讲完了。
通过上面的例子可以直观理解下递归函数,明显的优点是结构简单、逻辑上清晰,可读性好。但是,短板是,计算机的内存空间和运行空间是有限的,不能对无限次的嵌套进行存储和运算,否则会出现栈溢出的现象。这样就需要我们在定义递归函数的时候,设定好结束递归的最内层的限制条件。一般情况下,递归函数都是可以通过循环来实现的。此外,由于物理限定,当递归的次数上升后会严重影响计算机的运行效率,所以递归函数相对于循环实现,在大部分情况下效率是比较低的,除非在极个别的允许的递归次数内,单层执行耗时在不大不小的范围内,递归效率稍微好于循环。
为了提升代码的执行效率,在一般情况下,尽量用循环来替代递归。
简单做个试验:
1 import time 2 def sum_cycle(n): 3 ''' 4 实现 从1加到n,并返回结果 5 ''' 6 sum = 0 7 for i in range(1,n + 1): 8 sum += i 9 time.sleep(0.001) #代指功能代码块的运行过程 10 return sum 11 12 def sum_recu(n): 13 ''' 14 实现 从1加到n,并返回结果 15 ''' 16 time.sleep(0.001) #代指功能代码块的运行过程 17 if n > 0: 18 return n + sum_recu(n - 1) #调用函数自身 19 else: 20 return 0 21 t_start = time.time() 22 print("循环求和:",sum_cycle(900)) 23 t_stop = time.time() 24 print("循环用时----->",t_stop-t_start) 25 26 t_start = time.time() 27 print("递归求和:",sum_recu(900)) 28 t_stop = time.time() 29 print("递归用时----->",t_stop-t_start)
在函数内部又定义了一个全新的函数,这种函数对象称为嵌套函数,此操作过程即函数的嵌套。一般情况下,如果外层函数没有将内部函数作为结果返回出函数体,那么内部函数的作用区域仅为当前函数体内。
闭包就是能够读取其他函数内部变量的函数。在本质上,闭包是一个嵌套函数,是将函数内部和函数外部连接起来的桥梁。闭包包含函数快(内部函数)及内部函数定义时的环境。
简单理解为,如果在一个嵌套函数的内部函数里,对外部函数的局部变量(注意不是全局作用域的变量)进行引用,并且外部函数以内部函数名作为返回值,那么内部函数就被认为是闭包(closure)。此时,运行嵌套函数得到的结果是,以外部函数执行时形成的定义环境为背景定义的内部函数名,通过传入响应的参数进行调用可得到内部函数的运行结果。
重要意义:可以通过外部函数,改变内部函数的定义环境,也就是改变了内部函数的某些定义参数。
上个简单小栗子:
View Code
高阶函数的基本定义包括两点(1接受一个或多个函数作为参数输入,2输出一个函数,注意不是函数执行结果而是函数体,简单点就是返回函数名),满足上述两点中 至少 一个条件的即称之为高阶函数。简单理解下,接收函数名作为参数的函数就是高阶函数,另外在函数执行返回的参数是函数名的也属于高阶函数。在函数式编程中,返回另一个函数的高阶函数被称为柯里化的函数。
高阶函数的基本语法结构及其调用如下:

高阶函数的主要作用:根据高阶函数的定义,满足接受一个或多个函数作为输入,这样就能在不改变原函数代码基础上,为原函数添加功能,如果能满足第二点,当返回的函数名和传入的函数名一致的时候,就实现了不改变元函数的调用方式的条件下实现新的功能。
比较有代表性的内置高阶函数有:
- map(),接收两个参数,一个是函数,一个是序列,
map将传入的函数依次作用到序列的每个元素,返回结果,在python2.x中是list,而在python3.x中结果是以迭代器形式返回的是一个map对象,使用时可用list()强转。 基本格式: map(函数名,序列) - reduce(),不同于python2.x,在python3.x中,reduce被移到了functools 模块里,可以通过调用模块来使用,作用是对序列中的元素反复调用函数 f ,并返回最终结果值。基本格式 :functools.reduce(函数名, 序列,“初始值”),其中第三个参数“初始值”是可选的
- filter():用于过滤序列,过滤掉不符合条件的元素,在python2.x中返回由符合条件元素组成的新列表,python3.x中返回的是filter对象。基本格式:filter(过滤操作的执行函数名,序列)
匿名函数,字面上理解,就是没有命名的函数,返回的是一个lambda函数对象。
- 基本格式:lambda 参数1,参数2,参数3…… :函数体
- 匿名函数的函数体只是一个表达式,不是代码块。
- 那怎么去找到这个函数并执行呢,要么,把匿名函数赋值给一个变量,通过变量实现匿名函数的调用,要么将lambda函数直接作为变量传递(高阶函数中的函数名参数)
- 匿名函数有自己的命名空间
- 匿名函数的优点:1,可以精简代码 2,防止不重复使用的函数和其他函数出现命名重复,进而覆盖 3,在一定程度上增强了代码的可读性
来一个利用lambda函数构建高阶函数的简单栗子:
def func_1(i): return lambda x:x*i
一般地命名函数都是命名过程和调用过程分开的,但自执行函数或(立即执行函数)是函数构建完成后直接调用,一气呵成。
基本语法格式:(匿名函数)(参数)
直接上个栗子吧:
(lambda x:print(x*x))(3) #构建完成,马上调用
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。
觉得主函数类似于一个多功能螺丝刀,传递进去的函数就是各种型号的螺丝刀头,根据实际需要组合起来能实现一定的功能。好像是这么个东东,后期在更新吧。
来一个根据理解搞得栗子:
def func_1(): print("我是函数1") def func_2(): print("我是函数2") def func_3(): print("我是函数3") def func_4(): print("我是函数4") def func_0(f): print("我是函数0") f() func_0(func_1) func_0(func_4) func_0(func_2)
回调函数参考链接:https://www.zhihu.com/question/19801131/answer/27459821
|
常见函数 |
备注功能简介 |
|
abs() |
返回绝对值 |
|
all() |
如果可遍历对象中,元素全都可以通过bool判断,就为true |
|
any() |
遍历对象中,任一元素能通过bool判断,返回true |
|
ascii() |
返回unicode字节码 |
|
|
|
|
|
|
|
|
|
|
bin() |
将十进制转化为 |
|
bool() |
判断数据结构为true或false。空或者0为false |
|
bytearray() |
|
|
bytes() |
|
|
callable |
|
|
chr() |
|
|
complex() |
|
|
credits() |
|
|
delattr |
|
|
dir() |
|
|
dict() |
创建一个字典 |
|
divmod() |
|
|
enumerate() |
返回的是一个枚举对象。常和遍历循环结合使用 |
|
eval() |
把字符串中包含的特殊字符(列表、字典等)转化为原有数据类型 |
|
exec() |
把字符串类型的代码直接执行。并按原有语句进行输出 |
|
filter() |
按条件进行筛选,对列表、集合等进行筛选 |
|
float() |
将数据转化为浮点型 |
|
frozenset() |
返回一个冻结的集合对象 |
|
getattr() |
|
|
globals() |
|
|
hasattr() |
|
|
hash() |
对传入的对象进行hash,哈希的对象必须是不可变的。 |
|
hex() |
将十进制数值转化为十六进制形式 |
|
id() |
返回对象的内存地址 |
| input() |
接收用户输入,常用语交互 |
|
int() |
截取数据整形 |
|
isinstance() |
判断数据结构的具体数据类型 |
|
issubclass() |
|
|
iter() |
|
|
len() |
获取对象的长度 |
|
list() |
将对象拆开,作为元素放入新建列表 |
|
locals() |
查看局部变量 |
|
map() |
用于构建组合列表,常和lambda组合使用 |
|
max() |
最大值 |
|
memoryview() |
|
|
min() |
最小值 |
|
next() |
在迭代器中,取出对象。 __next__() |
|
object() |
|
|
oct() |
|
|
open() |
打开文件,并返回操作句柄 |
|
ord() |
|
|
print() |
打印输出 |
|
property() |
|
|
quit() |
|
|
range() |
返回按参数给定的范围 |
|
repr() |
|
|
reverse() |
列表等序列翻转 |
|
round() |
四舍五入 |
|
set() |
|
|
setattr() |
|
|
slice() |
常作用于遍历对象,设置起止索引和步长 |
|
sorted() |
排序 |
|
str() |
返回对象的字符串形式,作用类似于给操作对象加引号 ” “ |
|
sum() |
|
|
super() |
常用于类的继承,根据mro列表,构建上一级类(不一定是当前类的父类)的对象.在pyt2中需要传参数super(Class, self).*** ,在py3中参数可以传也可以省略,super().*** |
|
vars() |
|
|
zip() |
把2个以上的列表拼成一个,作用类似于extend |
函数部分示例
1 # !/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 # ----------函数、参数作用域------------ 5 # def func1(a,b,c='sss',d='cnn'): 6 # print(a,b,c,d) 7 8 9 # def func2(a,*args,**kwargs): 10 # print(a,args,kwargs) 11 12 13 # -------嵌套函数------ 14 # func2(111,'sss',2222222,name="zhangsan") 15 16 # name = 1 17 # 18 # 19 # def func3(): 20 # name = 2 21 # 22 # def func31(): 23 # print(name) 24 # return func31 25 # return func31 26 # name =3 27 # func3()()() 28 29 30 # ----------高阶函数---------- 31 # def divs(a,b): 32 # return float(a)/float(b) 33 # 34 # 35 # def rms(num1,num2,rm=2,f=divs): 36 # resault = f(num1,num2) 37 # return resault.__round__(rm) 38 # 39 # 40 # print(rms(51230328238,8126264,4)) 41 42 43 # -----------递归函数--------------- 44 45 # def func_half(n): 46 # print(n) 47 # if n > 0: 48 # n = int(n/2) 49 # func_half(n) 50 # print(n) 51 # 52 # 53 # func_half(1000) 54 55 56 def func_find(root_list,num): 57 if len(root_list)>1: 58 if root_list[int(len(root_list)/2)] == num: 59 print("found it") 60 else: 61 root_list = root_list[int(len(root_list)/2):] if root_list[int(len(root_list)/2)] < num else root_list[:int(len(root_list)/2)] 62 func_find(root_list,num) 63 elif root_list[0] == num: 64 print('found it finally') 65 else: 66 print('not in') 67 68 69 list1 = [i for i in range(100)] 70 71 # func_find(list1, 20) 72 73 print(globals()) 74 print(locals())
