
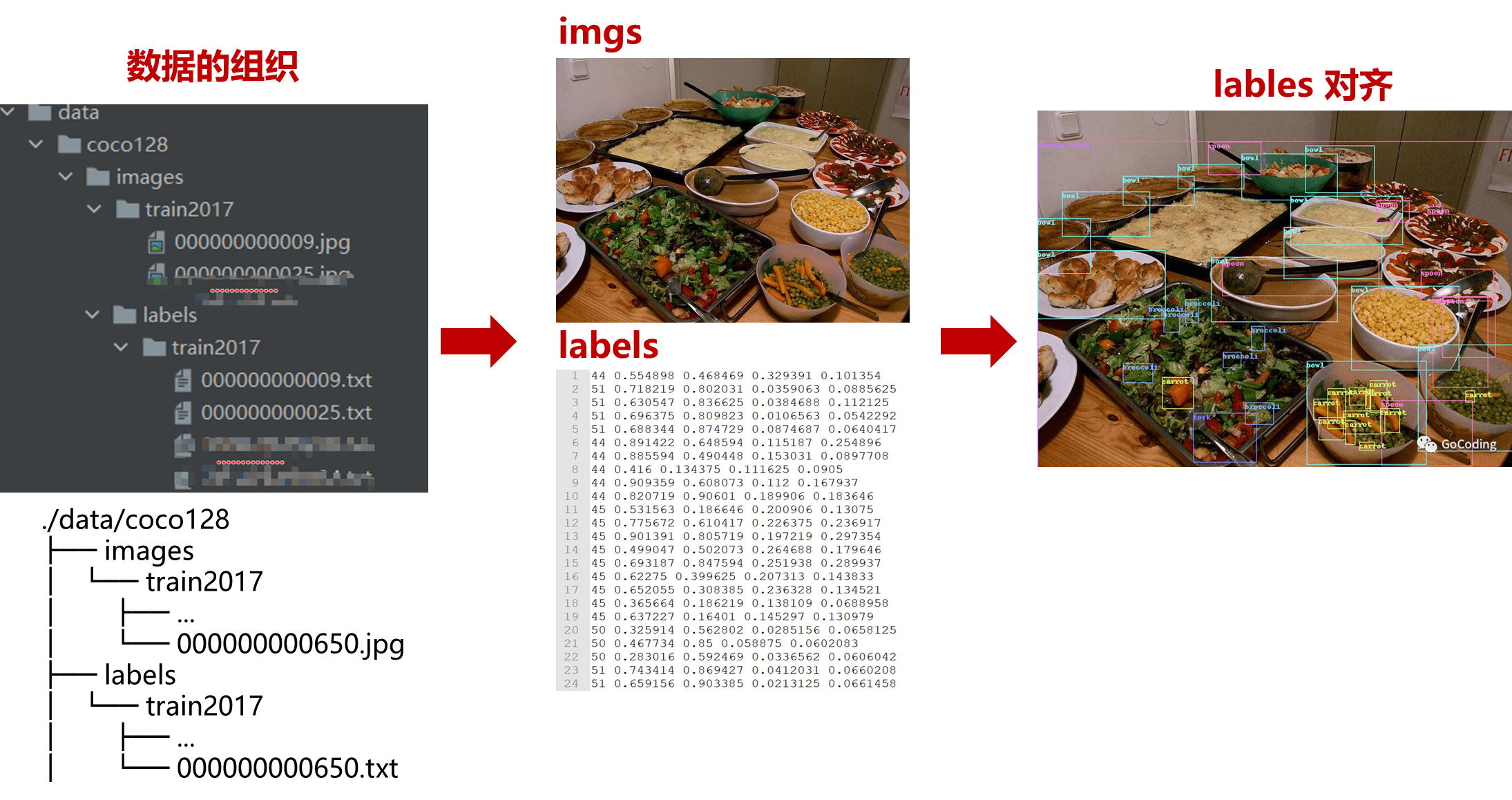
pytorch自定义或自组织数据集
import os
from pathlib import Path
from typing import Any, Callable, Optional, Tuple
import numpy as np
import torch
import torchvision
from PIL import Image
class DatasetSelfDefine(torchvision.datasets.vision.VisionDataset):
def __init__(
self,
root: str,
name: str,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
transforms: Optional[Callable] = None,
) -> None:
super(DatasetSelfDefine, self).__init__(root, transforms, transform, target_transform)
images_dir = Path(root) / 'images' / name
labels_dir = Path(root) / 'labels' / name
self.images = [n for n in images_dir.iterdir()]
self.labels = []
for image in self.images:
base, _ = os.path.splitext(os.path.basename(image))
label = labels_dir / f'{base}.txt'
self.labels.append(label if label.exists() else None)
# 获取数据集大小
def __getitem__(self, idx: int) -> Tuple[Any, Any]:
img = Image.open(self.images[idx]).convert('RGB')# PIL Image, 大小为 (H, W)
label_file = self.labels[idx]
if label_file is not None: # found
with open(label_file, 'r') as f:
labels = [x.split() for x in f.read().strip().splitlines()]
labels = np.array(labels, dtype=np.float32)
else: # missing
labels = np.zeros((0, 5), dtype=np.float32)
boxes = []
classes = []
for label in labels:
x, y, w, h = label[1:]
boxes.append([
(x - w / 2) * img.width,
(y - h / 2) * img.height,
(x + w / 2) * img.width,
(y + h / 2) * img.height])
classes.append(label[0])
target = {}
target["boxes"] = torch.as_tensor(boxes, dtype=torch.float32)# 真实标注框 [x1, y1, x2, y2], x 范围 [0,W], y 范围 [0,H]
target["labels"] = torch.as_tensor(classes, dtype=torch.int64)# 上述标注框的类别标识
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
# 访问第 i 个数据
def __len__(self) -> int:
return len(self.images)
if __name__ == '__main__':
batch_size = 64
dataset = DatasetSelfDefine('./data/coco128', 'train2017', transform=torchvision.transforms.ToTensor())
print(f'dataset: {len(dataset)}')
print(f'dataset[0]: {dataset[0]}')
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True,
collate_fn=lambda batch: tuple(zip(*batch)))
for batch_i, (images, targets) in enumerate(dataloader):
print(f'batch {batch_i}, images {len(images)}, targets {len(targets)}')
print(f' images[0]: shape={images[0].shape}')
print(f' targets[0]: {targets[0]}')
个人学习记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号