常用集合类:
1、iterator便利:
所有的集合父类collection实现了Iterable。该集合里有三个方法 其中一个重要的方法 iterator()方法。在所有集合的实现类重写了这个方法。
ArrayList list= new ArrayList(); list.add(1); list.add(2); list.add(3); list.add(4); Integer integer = new Integer(2); list.remove(integer); Iterator iterator = list.iterator(); // ListIterator iterator = list.listIterator(); while(iterator.hasNext()){ Object o = iterator.next(); if(o.equals(1)){ iterator.remove(); //此处遍历器已经不支持删除操作 也不zhichilist.remove(o) 所以用list。listIterator() } System.out.println(o); } }
但是通过便利删除list.remove()会数据上移,造成游标的混乱判断。所以会报异常,那么可以用通过iterator 的remove方法实现,通过源码可以看到此处抛出了一个异常,不支持这个方法。
那么可以通过arraylIst的listIterator()来进行便利实现。
在使用iterator进行迭代的过程中如果删除其中的某个元素会报错,并发操作异常,因此 * 如果遍历的同时需要修改元素,建议使用listIterator(), * ListIterator迭代器提供了向前和向后两种遍历的方式 * 始终是通过cursor和lastret的指针来获取元素值及向下的遍历索引 * 当使用向前遍历的时候必须要保证指针在迭代器的结果,否则无法获取结果值
Iterator iterator = list.iterator(); // ListIterator iterator = list.listIterator(); while(iterator.hasNext()){ Object o = iterator.next(); if(o.equals(1)){ iterator.remove(); } System.out.println(o); } // System.out.println("-------------"); // while (iterator.hasPrevious()){ // System.out.println(iterator.previous()); // } // for(Object i : list){ // System.out.println(i); // }
如上图:此时向前便利,向后便利。如果指针在最后面获取不到元素。
2、vector也是list的实现类,他是线程安全的。
3、list的实现类主要有arrayList和LinkList两类。arraylist底层是数组实现,那么查找会快一些。linkList底层是链表实现。删除和插入快一些。修改的查询话都需要逐个便利元素。
4、以后尽量减少使用增强for循环,不变与对数据的操作。
5、摘要
ListIterator的作用解决并发操作异常 ▪ 在迭代时,丌可能通过集合对象的方法(al.add(?))操作集合中的元素, ▪ 会发生并发修改异常。 ▪ 所以,在迭代时只能通过迭代器的方法操作元素,但是Iterator的方法 ▪ 是有限的,只能进行判断(hasNext),取出(next),删除(remove)的操作, ▪ 如果想要在迭代的过程中进行向集合中添加,修改元素等就需要使用 ▪ ListIterator接口中的方法
ListIterator li=al.listIterator(); while(li.hasNext()){ Object obj=li.next(); if ("java2".equals(obj)) { li.add("java9994"); li.set("java002"); } }
6、迭代器会维持到方法体结束,消耗内存空间。迭代器从创建一开始,一直到方法结束。所以建议用第二种方法。写在for 循环里作用域是这个循环内。
建议用第二中反方法,放到for循环里实现。

二、set set是无序的且不重复的集合。常见的实现有hashSet和TreeSet和LinkHashSet。
通过底层代码,我们可以看到hashSet就是hashMap。是通过计算添加数据的hashcode值。在比较equas方法,通过算法去重,数据散列,实现无序且不可重复的集合。好的算法可以减少数据的散列。
TreeSet可以确保数据的一致性,底层是TreeMap 红黑树。查询速度快一些。红黑树与平衡树最大的区别就是减少了自旋所带来的性能消耗,提升了插入效率。
1、hashSet和TreeSet的区别:
Set接口中的实现类
▪HashSet:采用Hashtable哈希表存储结构
–优点:添加速度快,查询速度快,删除速度快
–缺点:无序
–LinkedHashSet
▪ 采用哈希表存储结构,同时使用链表维护次序
▪有序(添加顺序)
▪TreeSet
–采用二叉树(红黑树)的存储结构
–优点:有序(排序后的升序)查询速度比List快
–缺点:查询速度没有HashSet快
不同点:treeSet添加数据的时候,必须要添加同一类型,并且有可以排序的数据比较。

内部比较器:实现compareable接口。
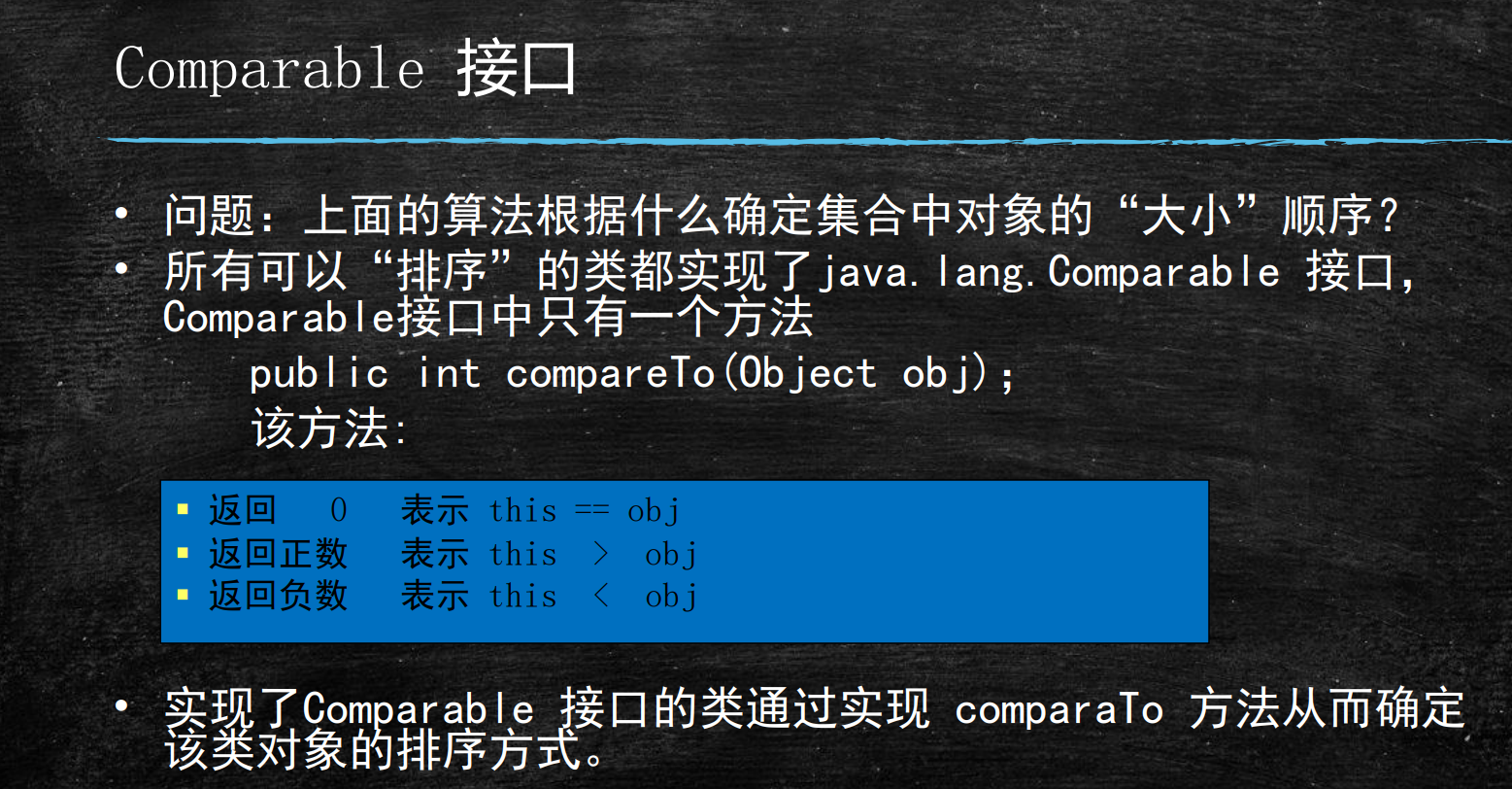
外部比较器的使用:
在当前类中实现 Comparator接口,并重写了 compare方法。然后把该比较器传入到集合中。
public class SetDemo implements Comparator<Person> { public static void main(String[] args) { TreeSet treeSet = new TreeSet(new SetDemo()); treeSet.add(new Person("lisi",15)); treeSet.add(new Person("wangwu",13)); treeSet.add(new Person("maliu",12)); treeSet.add(new Person("zhangsan",19)); treeSet.add(new Person("zhangsan",12)); System.out.println(treeSet); } @Override public int compare(Person o1, Person o2) { if(o1.getAge()>o2.getAge()){ return -1; }else if(o1.getAge() < o2.getAge()){ return 1; }else{ return 0; } }
set内容总结:
* 1、set中存放的是无序,唯一的数据 * 2、set不可以通过下标获取对应位置的元素的值,因为无序的特点 * 3、使用treeset底层的实现是treemap,利用红黑树来进行实现 * 4、设置元素的时候,如果是自定义对象,会查找对象中的equals和hashcode的方法,如果没有,比较的是地址 * 5、树中的元素是要默认进行排序操作的,如果是基本数据类型,自动比较,如果是引用类型的话,需要自定义比较器 * 比较器分类: * 内部比较器 * 定义在元素的类中,通过实现comparable接口来进行实现 * 外部比较器 * 定义在当前类中,通过实现comparator接口来实现,但是要将该比较器传递到集合中 * 注意:外部比较器可以定义成一个工具类,此时所有需要比较的规则如果一致的话,可以复用,而 * 内部比较器只有在存储当前对象的时候才可以使用 * 如果两者同时存在,使用外部比较器 * 当使用比较器的时候,不会调用equals方法
当使用比较器的时候,如果比较的值相当,那么会进行去重操作。
三、泛型
泛型的使用:
泛型的高阶应用: * 1、泛型类 * 在定义类的时候在类名的后面添加<E,K,V,A,B>,起到占位的作用,类中的方法的返回值类型和属性的类型都可以使用 * 2、泛型接口 * 在定义接口的时候,在接口的名称后添加<E,K,V,A,B>, * 1、子类在进行实现的时候,可以不填写泛型的类型,此时在创建具体的子类对象的时候才决定使用什么类型 * 2、子类在实现泛型接口的时候,只在实现父类的接口的时候指定父类的泛型类型即可,此时,测试方法中的泛型类型必须要跟子类保持一致 * 3、泛型方法 * 在定义方法的时候,指定方法的返回值和参数是自定义的占位符,可以是类名中的T,也可以是自定义的Q,只不过在使用Q的时候需要使用< * Q>定义在返回值的前面 * 4、泛型的上限(工作中不用) * 如果父类确定了,所有的子类都可以直接使用 * 5、泛型的下限(工作中不用) * 如果子类确定了,子类的所有父类都可以直接传递参数使用 *
1、定义泛型类 默认E代表element k是key v是value
public class FanXingClass<A> { private int id; private A a; public int getId() { return id; } public void setId(int id) { this.id = id; } public A getA() { return a; } public void setA(A a) { this.a = a; } public void show(){ System.out.println("id : "+id+" ,A : "+a); } public A get(){ return a; } public void set(A a){ System.out.println("执行set方法:" + a); }
2、定义泛型的接口实现:
package _05_第五章泛型.E202_05_02_数据相加; public class Test { public static void main(String[] args) { Point p1 = new Point(1,1); Point p2 = new Point(3,2); Circle circle = new Circle(p1,2); Circle circle2 = new Circle(p2,3); System.out.printf("两个 圆 相加结果:\n"); System.out.println(circle2.add(circle)); Complex complex = new Complex(1,1); Complex complex2 = new Complex(2,2); System.out.printf("两个 复数 相加结果:\n"); complex2.Print(complex2.add(complex)); } } package _05_第五章泛型.E202_05_02_数据相加; public interface Add<T> { public T add(T t); } package _05_第五章泛型.E202_05_02_数据相加; public class Circle implements Add<Circle> { private Point p;//圆心 private float r;//半径 public Circle(Point p, float r) { this.p = p; this.r = r; } public Circle add(Circle circle2){ circle2.p =this.p.add(circle2.p); circle2.r =this.r + circle2.r ; return circle2; } @Override public String toString() { return String.format("圆心:(%f,%f) 半径:%f",p.x,p.y,r); } }
3、泛型的方法比较特殊,如果没有返回值,那么需要添加哥泛型。
public class FanXingMethod<T> { private T t; public T getT() { return t; } public void setT(T t) { this.t = t; } public <Q> void show(Q q){ System.out.println(q); System.out.println(t); }
三、Map类
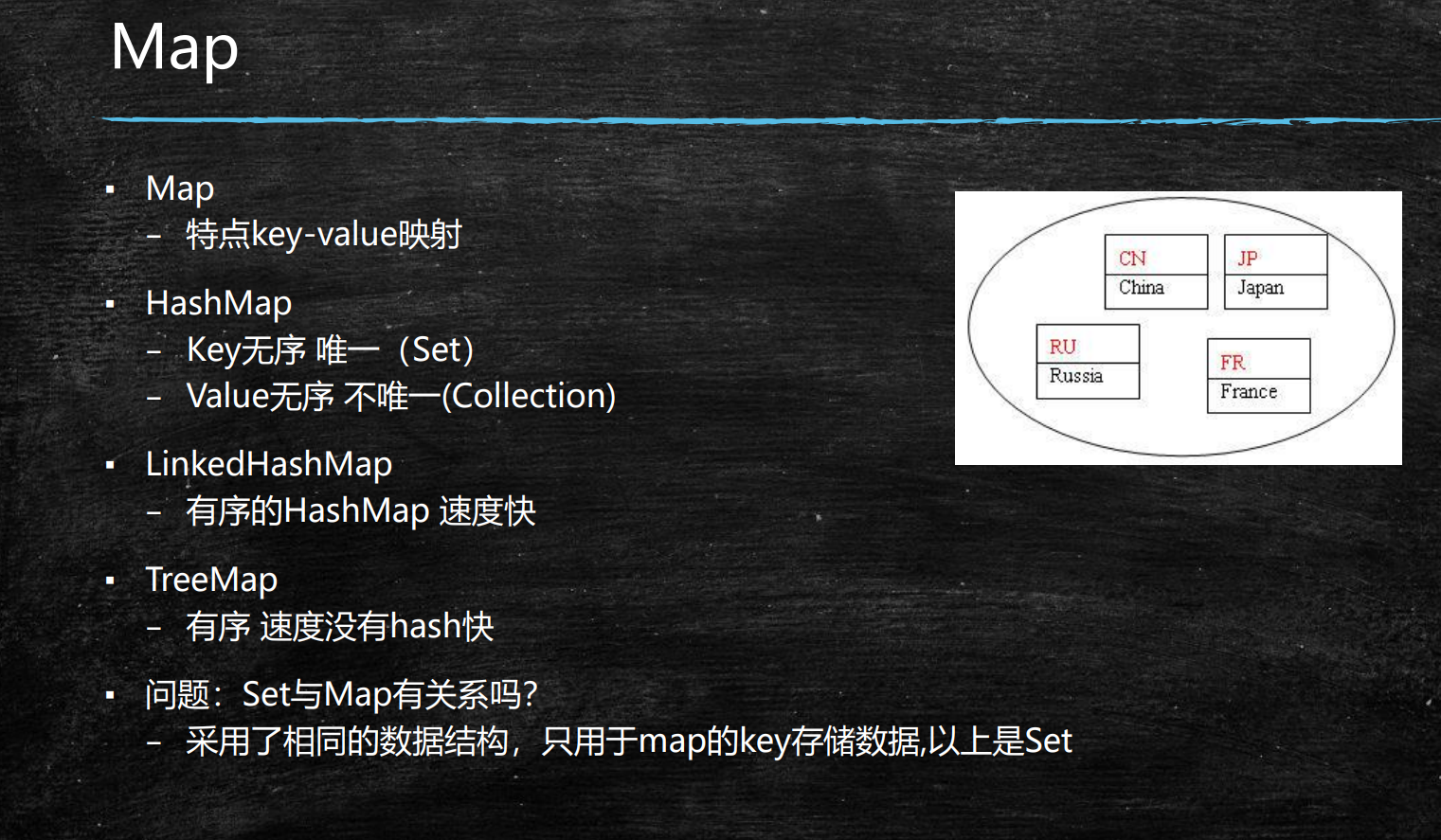
1、hashmap跟hashtable的区别:
1、hashmap线程不安全,效率比较高,hashtable线程安全,效率低
2、hashmap中key和value都可以为空,hashtable不允许为空
map存储的是k-v键值对映射的数据 * 实现子类: * HashMap:数据+链表(1.7) 数组+链表+红黑树(1.8) * LinkedHashMap:链表 * TreeMap:红黑树
2、常见的hashMap便利操作
//遍历操作 Set<String> keys = map.keySet(); for(String key:keys){ System.out.println(key+"="+map.get(key)); } //只能获取对应的value值,不能根据value来获取key Collection<Integer> values = map.values(); for (Integer i:values){ System.out.println(i); } //迭代器 Set<String> keys2 = map.keySet(); Iterator<String> iterator = keys2.iterator(); while(iterator.hasNext()){ String key = iterator.next(); System.out.println(key+"="+map.get(key)); } //Map.entry Set<Map.Entry<String, Integer>> entries = map.entrySet(); Iterator<Map.Entry<String, Integer>> iterator1 = entries.iterator(); while (iterator1.hasNext()){ Map.Entry<String, Integer> next = iterator1.next(); System.out.println(next.getKey()+"--"+next.getValue()); }
Map.ENtry格式类型:有key和value和hashCode值 有指针
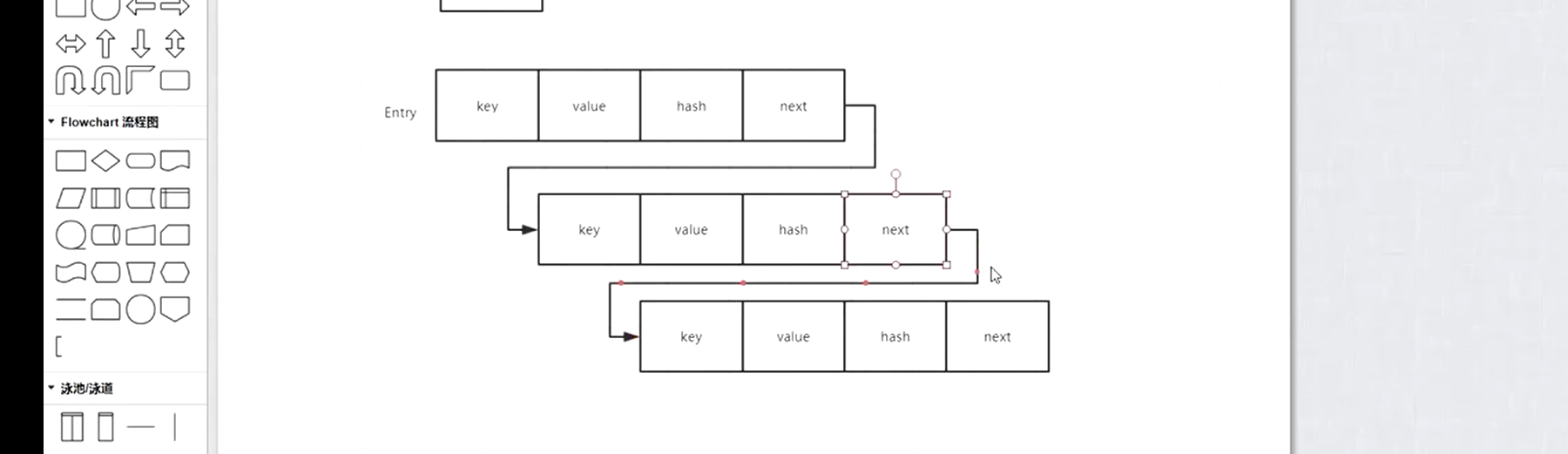
在java8以后hashMap是什么时候使用红黑树的?在大于8的时候。
hashMap初始化的数组长度为2的N次幂。这样便于位移运算扩容。
本文来自博客园,作者:Jerry&Ming,转载请注明原文链接:https://www.cnblogs.com/jerry-ming/p/16101878.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号