


1、深度指定
DEPTH_LIMIT=1
2、常用命令
scrapy startproject name
scrapy genspider name name.com
scrapy crawl name
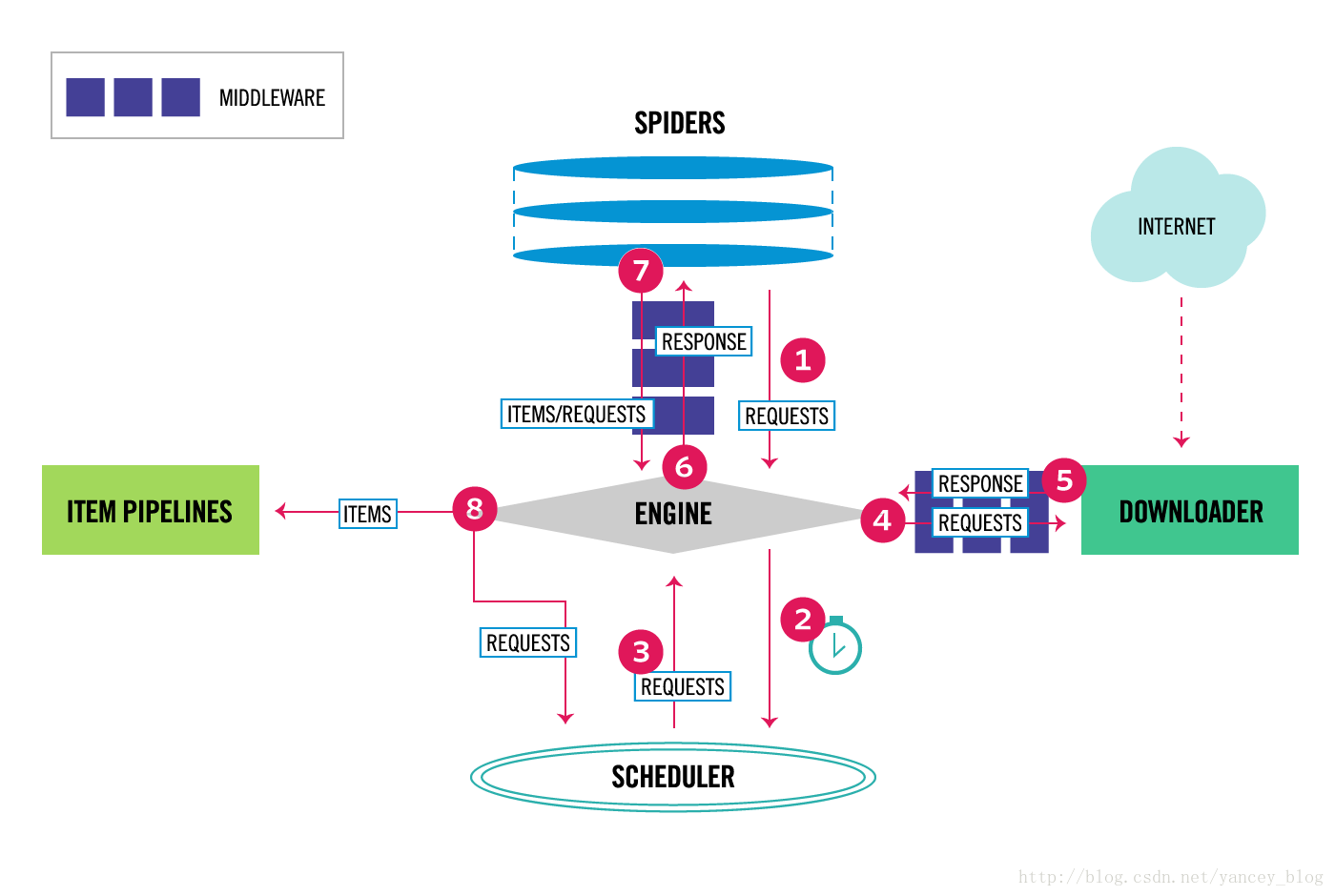
3、结构
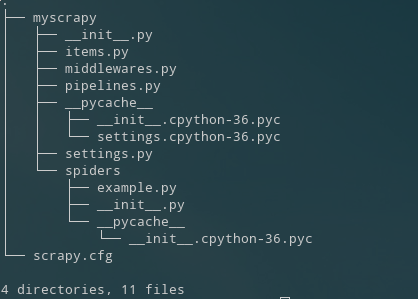
4、目录
5、多pipeline情况
权重高的必须在process_item()里 return item才能使下一个pipeline生效
如果不想交给下一个,可以
1 from scrapy.exceptions import DropItem 2 3 def process_item(self, item, spider): 4 raise DropItem()
表示丢弃
在from_crawler(cls, crawler)中
用crawler.setting.get('') 读取配置文件
6 yield Request(url=url, callback=self.parse)
反复执行解析方法
7 yield Request(url, meta={'name':name}, call_back=self.parse)
使用meta进行传参
在parse中
使用 name = response.meta['name']来接收参数
8 辅助工具:chrome + xpath helper 插件
便于分析网页结构,抽取可用内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号