

盘点一下后训练量化的基本操作
(本文首发于公众号,没事来逛逛)
这篇文章简单聊聊后训练量化的一些常规操作。
一些基础知识
在此之前,还是需要先了解一下后训练量化 (下面简称 PTQ,Post-training Quantization) 是啥?具体细节这里就不展开了,不熟悉的读者欢迎看回我之前的文章 (神经网络量化入门--后训练量化)。简单来说,后训练量化就是在不重新训练网络 (即不更新 weight) 的前提下,获取网络的量化参数。
说到量化参数,就不得不祭出量化的基本公式了 (假设用非对称量化,8bit):
这里面的 \(r\) 和 \(q\) 分别表示量化前的浮点数和量化后的定点数。而 \(S\) 和 \(Z\) 就是两个重要的量化参数 scale (步长) 和 zero point (零点)。除此之外,还有两个非常重要的量化参数:\(r_{min}\)、\(r_{max}\),分别表示浮点数 \(r\) 的数值范围。
\(S\)、\(Z\)、\(r_{min}\)、\(r_{max}\) 构成了网络量化里面四个最重要的量化参数,几乎所有后训练量化算法,都是为了找到这几个东西。这里面,\(S\)、\(Z\) 和 \(r_{min}\)、\(r_{max}\) 之间又是可以相互转换的:
公式里面的 \(q_{max}\)、\(q_{min}\) 表示定点数 \(q\) 的数值范围,在量化策略确定之后,数值一般就确定下来了。比如说,我这里采用 8bit 的非对称量化,那么量化后的数值范围一般就是 0~255,即 \(q_{max}=255\),\(q_{min}=0\)。
公式 (3) 大家都能理解,但公式 (4) 写法比较多,容易搞晕。我简单画了张图,不明白的同学再琢磨琢磨。
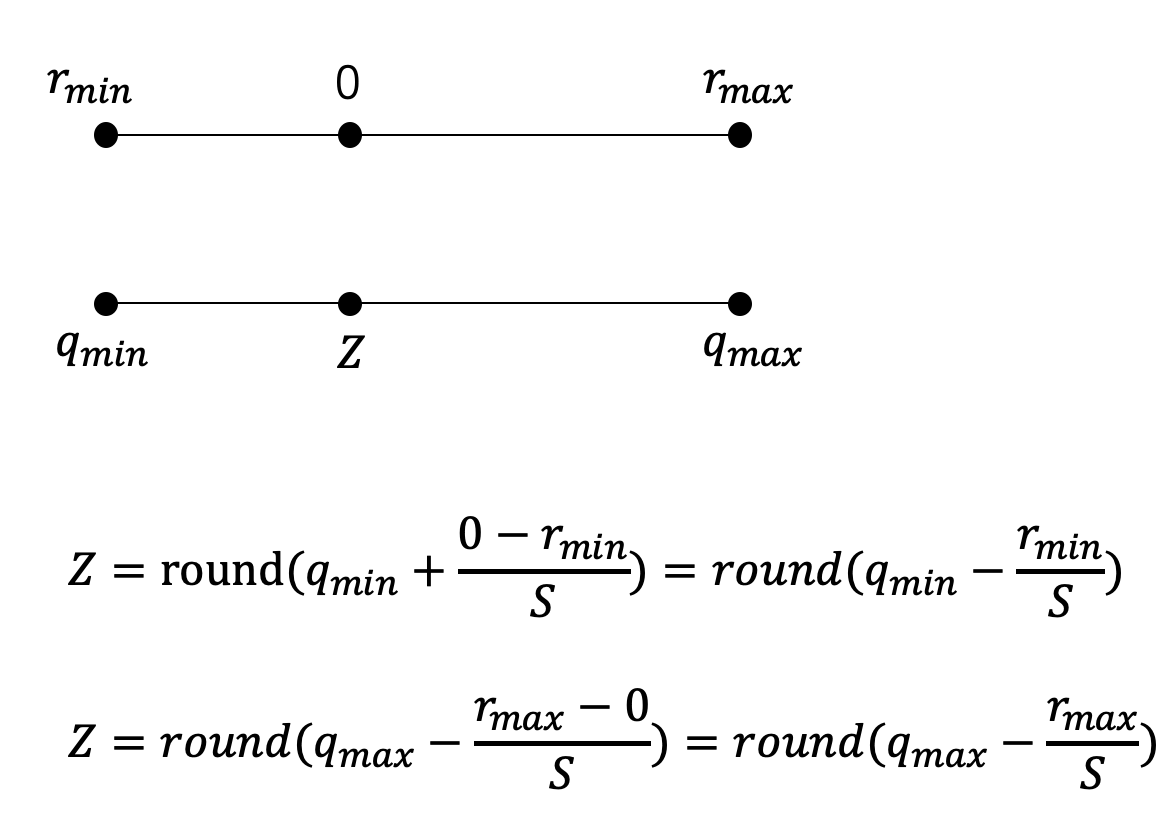
对于一个常规的神经网络来说,只要我们知道了每一层权重 (weight、bias) 和每一层特征 (feature map) 的 \(S\) 和 \(Z\) (或者 \(r_{min}\)、\(r_{max}\),反正可以相互转换),理论上我们就可以用定点的方式跑网络了,从而获得内存访问和计算效率上的提升。为什么这里要说常规呢?因为有一些激活函数在定点的情况下难以运行,这类函数通常还是只能以浮点的形式计算,在一些只能跑定点运算的芯片上令人头疼不已。
后训练量化
了解完这些基础后,现在回到正题:如何找到合适的量化参数呢?
对于权重而言,在模型训练完成后数值就基本确定了,而对于 feature map 来说,却没法事先得知,因此会用一批矫正数据集 (通常就是训练集的一小部分) 跑一遍网络,以此来统计每一层 feature map 的数值范围。
navie的想法
有了权重和特征的数值范围后,一种很直接的方法就是根据数值范围的大小来确定 \(r_{min}\)、\(r_{max}\)。我之前的文章()就简单采用了这种方法。但这种方法容易受到噪声的影响,比如,有些 weight 或者 feature 中可能存在某些离群点,它的数值较大,但对结果影响又很小,如果把这些数值也统计到 minmax 里面,就容易造成浪费。
举个栗子,如果某个 weight 里面的数值是 [-0.1, 0.2, 0.3, 255.1],那我们统计出来的 minmax 就是 -0.1 和 255.1,如此一来,0.2、0.3 这样的数值就会被映射到同一个定点数,信息损失相当严重,而它们对结果影响可能远大于 255.1。因此,在这种情况下,我们宁愿把 255.1 损失掉,也希望尽可能把 0.2、0.3 保持下来。
一些简单的改进
那该如何改进呢?
1. 直方图截断
既然离群点影响很大,那最容易想到的解法就是排除这些离群点的干扰。我们可以把 weight 或者 feature map 的数值范围统计出一个直方图,根据直方图舍弃前后 m% 的数值,直接用剩下的数值来确定 minmax。
2. 滑动平均
除此之外,还有一种对 feature map 比较有效的统计方法。 这也是 Google 论文提到的一种技巧\(^1\)。我们把矫正数据集分为几个 batch,逐次输入到网络中统计数值。每次更新数值范围时,按照 \(r_{max}^t=r_{max}^t*(1-\alpha)+r_{max}^{t-1}*\alpha\) 来更新,其中,\(r_{max}^{t-1}\) 是上一次统计到的最大值。通过控制 \(\alpha\) 的数值,可以控制新数据对历史统计数据的影响,让最终统计到的数值能大致涵盖大部分数值,但又不会被一些离群点主导。
3. 均值和方差
一个不成文的约定:我们通常会假设 weight 和 feature 的数值呈正态分布。在此假设下,我们可以统计出测试数据中 weight 或者 feature 的均值 \(\mu\) 和方差 \(\sigma\),然后,根据正态分布的性质,在区间 \((\mu-3\sigma, \mu+3\sigma)\) 之间的数值占了 99+%,因此,可以令 \(r_{min}=\mu-3\sigma\)、\(r_{max}=\mu+3\sigma\),这样就基本涵盖了大部分数值,也避免了一些离群点的影响。
当然,如果实际的数值分布不是正态的,比如,是个双峰分布,那可能就 gg 了。
加点数学的味道
以上这些方法都比较 tricky (直方图要舍弃多少才合适?滑动平均的 \(\alpha\) 怎么设置?正态分布一定要取 \(3\sigma\)?万一离群点很重要怎么办?),效果好坏全靠灵巧的双手。下面介绍几种更加 mathematic 的方法,看起来理论更加完备一些 (虽然对于神经网络来说, 有时候仍然很玄学)。
虽然扯到数学,但其实也没什么高大上的,无非就是找一些方法,可以让这些 tricky 的事情更加自动化一些。
这其中最关键的,就是找到一种度量信息损失的方法,可以告诉我们,当前取到的 minmax 值合不合适,是不是精度最高的。这些度量方法中,最常用的如欧式距离 (L2距离)、L1距离、KL散度、余弦距离等。
1. 搜索minmax
确定好度量方法后,我们就可以自动化地搜索最合适的数值范围了。最简单的思路就是在原本的 minmax 区间内,逐步搜索一个更小的数值范围,然后计算这个范围内的信息做了量化后有多少信息损失,损失越小,证明这个数值范围越合适。
江湖中人用的较多的 TensorRT 量化算法就是基于 KL 散度来搜索 minmax 的。TRT 采用的是 8bit 对称量化,即正数区间量化到 [0, 127],负数区间量化到 [-128, 0)。量化的大致过程如下:
- 首先根据矫正数据集确定数值范围 [\(r_{min}\), \(r_{max}\)];
- 把这个范围区间划分为 2048 份 (相当于离散化成 2048 个 bin 的直方图,具体多少 bin 可以调整);
- 以最前面的 128 个 bin 作为基准,逐次向后搜索,每次扩增一个 bin 的长度,得到一个新的数值范围。然后把这个数值范围重新划分为一个 128 个 bin 的直方图 \(Q\) (这一步相当于舍弃了部分数值信息,并做了量化);
- 那要如何评价当前这个数值范围是否合适呢?这个时候 KL 散度就能派上用场了。我们把剩下那些没有搜索到的数值压缩到当前搜索到的 bin 上,得到一个信息基本没有损失的直方图 \(P\),如果我们之前搜索到的 \(Q\) 跟 \(P\) 相比信息损失最小 (即 KL 散度最小),那这个 \(Q\) 对应的数值范围就是最好的数值范围。不巧的是,KL 散度需要两个直方图的 bin 是一样的 (L1 距离等也有这个要求),而 \(Q\) 之前已经被量化到 128 个 bin 了。为了解决这个问题,需要把 \(Q\) 再反量化到跟 \(P\) 的 bin 数相同,这样就可以计算信息损失了。
- 重复步骤 3、4,记录每次搜索的 KL 散度大小,直到搜索完整个范围。KL 散度最小的搜索范围,就是理论上信息损失最小的 minmax。
其中的一些关键操作如量化、反量化等,限于篇幅这里就不展开讲了。
有人可能会问:按照这样搜索,那是不是最后一次把整个数值范围都包含进去的时候 KL 散度最小呢?毕竟搜索到最后一步我们没有舍弃任何数值。有这种疑惑是因为没有考虑到量化的影响。由于大部分情况下,数值分布都近似于正太分布 (即大部分数值会集中在一个区间内),而随着搜索范围增大,离群点会越来越多,但中间那些真正有用的、比较集中的数值就只能用更少的 bin 来表达 (要知道总共只有 128 个 bin 可以承载信息)。因此,绝大部分情况下,舍弃离群点 (outlier) 获得的收益往往是更大的。
以上就是 TRT 量化的大致过程,基本套路就是:从一个小的搜索范围逐渐扩大出去,每次搜索都量化一遍信息 (比如划分成固定 bin 数的直方图),然后用一种度量方式 (KL 散度、L1 距离等) 来衡量完整信息和量化信息之间的差异,差异最小的区间就是我们需要的 minmax。
2. 搜索S和Z
除了 minmax,我们也可以搜索合适的 \(S\) 和 \(Z\)。这里的套路和前面是类似的,也是根据量化前后的信息损失来找出最优解。
假设量化前的浮点 weight 或 feature map 为向量 \(r\),那么量化后为:
再进行反量化后得到:
接下来就可以度量量化的信息损失了,在论文 EasyQuant\(^2\) 中使用了余弦相似性,因此这里我们也以余弦相似性为例。
假设矫正数据集总共有 \(N\) 个样本,那么平均相似性为:
而我们要求解的,就是使得这个相似性最大的 \(S\) 和 \(Z\) (余弦相似性越大,信息损失越小):
搜索 \(S\) 和 \(Z\) 的方法有很多,比如可以参考前面 TRT 的思路,先设定 \(S\) 和 \(Z\) 的范围,然后我们用两个循环分别对 \(S\) 和 \(Z\) 进行搜索遍历,计算每一步搜索的相似性分数,分数最大的就是我们需要的 \(S\) 和 \(Z\)。这种方法就是通常所说的 Grid Search。
不过,由于我们已经有了 \(S\) 和 \(Z\) 的解析式了,所以完全可以梯度下降法,甚至直接对 (8) 式求解析解的方法,获得最优解。不过暂时没见过有文章这样处理,估计是因为解析式里面 round 这个函数不好求导吧。
当然,在网络结构比较复杂的情况下,单独针对每一层求解量化参数,并不一定能获得整个网络的最优精度,因此在 EasyQuant\(^2\) 论文中有很多 trick 来更好地求解量化精度,这个有机会后面再细讲。
总结
水了这么多,总算可以结尾了。这篇文章主要介绍了后训练量化的一些常用操作,包括如何用直方图简单地截取 minmax,以及 TensorRT 量化算法的套路等等。事实上,这些后训练量化的方法也完全可以用到量化感知训练中,后者无非是多了对权重的更新学习而已。
讲完基本操作,后面就是进阶版本了,可能会介绍一些更加前沿的后训练量化的论文。感兴趣的老铁点个赞和在看可好。
参考
- Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
- EasyQuant: Post-training Quantization via Scale Optimization
欢迎关注我的公众号:大白话AI,立志用大白话讲懂AI。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号