
论文笔记:Mask R-CNN
之前在一次组会上,师弟诉苦说他用 UNet 处理一个病灶分割的任务,但效果极差,我看了他的数据后发现,那些病灶区域比起整张图而言非常的小,而 UNet 采用的损失函数通常是逐像素的分类损失,如此一来,网络只要能够分割出大部分背景,那么 loss 的值就可以下降很多,自然无法精细地分割出那些细小的病灶。反过来想,这其实类似于正负样本极不均衡的情况,网络拟合了大部分负样本后,即使正样本拟合得较差,整体的 loss 也已经很低了。
发现这个问题后,我就在想可不可以先用 Faster RCNN 之类的先检测出这些病灶区域的候选框,再在框内做分割,甚至,能不能直接把 Faster RCNN 和分割部分做成一个统一的模型来处理。后来发现,这不就是 Mask RCNN 做的事情咩~囧~
这篇文章,我们就从无到有来看看 Mask RCNN 是怎么设计出来的。
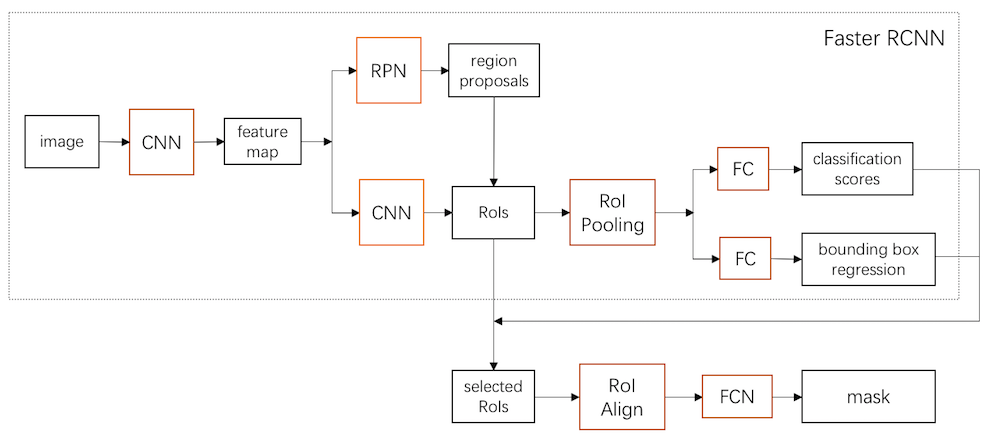
回顾 Faster RCNN
首先,我们简单回忆一下 Faster RCNN 的结构,看看如何针对它进行拓展。上面这个框架图中,虚线框内就是 Faster RCNN 的大致结构了。算法过程可以粗略分为以下几步:
- 将图片输入 CNN 中,得到 feature map;
- 用一个 RPN 网络在 feature map 提取出候选框(region proposals)。这一步对应 RPN 网络分支;
- 用另一个 CNN 进一步对该 feature map 进行特征提取,结合候选框得到很多 RoI,然后在每个 RoI 内用 RoI Pooling 提取特征,之后接上 FC 层分别预测框内物体的类别以及做 bounding box 微调。这一步对应 Fast RCNN 网络分支。
整个流程其实非常简洁。既然我们是想在候选框内进一步做分割,那么很自然的想法,就是在原 Faster RCNN 选出来的 RoI 中,根据 classification score 和 bounding box regression 选出得分最高的 RoI,并对这些 RoI 的框进行微调。这样,这些 RoI 就是最可能包含物体,同时定位也更为准确的 RoI 了,之后继续在这些 RoI 内做分割即可。另外,这个想法还能沿用之前得到的 feature map,避免卷积重复计算,可以说是一举两得。
事实上,Mask RCNN 采用的也是这一套思路。这种先检测物体再做分割的两步走策略,江湖人称 two stage,而 UNet 这种一步到位的分割方法,则被称为 one stage。显然,一步到位的 UNet 实现起来简单,大部分情况下效果也还行,但论精度,还是 Mask RCNN 更胜一筹,毕竟有候选框作为先验支撑。
这里要注意另一个问题,虽然 UNet 和 Mask RCNN 都是处理分割,但前者又称为 semantic segmentation,后者称为 instance segmentation。两者的区别可以用下面这张图体现,semantic segmentation 在分割的时候对同一类物体一视同仁,而 instance segmentation 则需要把每个个体都单独分割出来。因此,把 UNet 和 Mask RCNN 进行对比其实不太公平。instance segmentation 由于需要单独分割每个个体,因此基本上所有针对 instance segmentation 的方法都需要先用一个候选框把物体找出来,之后再分割。

下面,我们就来看看 Mask RCNN 是怎么在 Faster RCNN 的基础上实现分割的。
Mask RCNN
Mask RCNN 的整体流程图可以参考文章开头那个框架图。它在 Faster RCNN 的基础上,延伸出了一个 Mask 分支。根据 Faster RCNN 计算出来的每个候选框的分数,筛选出一大堆更加准确的 RoI(对应图中 selected RoI),然后用一个 RoI Align 层提取这些 RoI 的特征,计算出一个 mask,根据 RoI 和原图的比例,将这个 mask 扩大回原图,就可以得到一个分割的 mask 了。
RoI Align 之后打算新开一篇文章针对代码细讲,本文只稍微提及 RoI Align 背后的机理,暂且就将它当作一个黑盒。
现在,我们从零出发,假设让我们来设计 Mask RCNN,这中间每一步要如何操作,以及会面临哪些问题。
RoI 如何到 Mask
首先第一个问题是如何处理这些 RoI 的特征,输出分割的 mask。在 UNet 和 FCN 中,是先将图片通过卷积操作得到 feature map,再通过 deconvolution(或者 upsample + convolution)的方法将 feature map 的尺寸还原成原图大小。因此,我们也可以借用同样的思路,先根据 RoI 的尺寸换算回原图,看看这个 RoI 对应到原图上的尺寸有多大,再将 RoI 内的 feature map 上采样成对应尺寸的 mask,然后接一个 FCN 网络将 mask 的通道数处理成 \(K\) 即可(假设总共有 \(K\) 种类别)。由于上采样是可以求导的,因此反向传播依然有效。
写到这里,我突然觉得,Fast RCNN 中提出的 RoI Pooling 是不是也可以换成这种上/下采样 + 卷积的方式来得到一个固定大小的 feature map,这样,之后的 FC 层的维度也是可以匹配上的。而且 RoI Pooling 本质上也类似一种下采样的操作,只不过采样的方式是取邻域中最大的数值。但转念一想,这其实就是在问 Pooling 操作能不能用下采样来代替,从大佬们设计的网络结构中普遍采用 Pooling 而不是下采样来看,应该是 Pooling 的效果会更好。这个问题就此打住,暂且认为 Pooling 的效果好于下采样。
可以看出,我们设计的这个 mask 分支跟 UNet 或 FCN 的思路其实一样。不过,直接下采样可能会导致 feature map 中一些重要的信息丢失,因此,我们可以沿用 RoI Pooling 的思路,将 RoI 内的那块 feature map 处理成指定大小的 feature map,然后采用 conv/deconv 的方法进一步转换成 \(K \times H \times W\) 的 mask,其中 \(K\) 表示物体的类别。最后把这个 mask 按照 RoI 对应的 bounding box 换算回原图中即可。这一步在训练上也可以类比 FCN,先根据 bounding box 找到 ground truth 中对应的那块 mask,再按比例缩成跟网络输出的 mask 一样大小,然后根据分类损失或者 MSE 构造 Loss 函数即可。
大部分人都能走到这一步,但也就仅仅走到这一步而已。这个流程简单直接,而且也能 work,但实操后会发现效果不佳。这里就涉及到论文中提及的 misalignment 问题。
事实上,分割对模型精度的要求比分类以及检测要高得多,因为前者需要逐像素的标注类别信息。这意味着,如果 RoI 中的 feature map 跟原图中对应的区域存在偏差,就可能导致计算出来的 mask 跟 ground truth 是对不齐的。我们用一张图来说明:
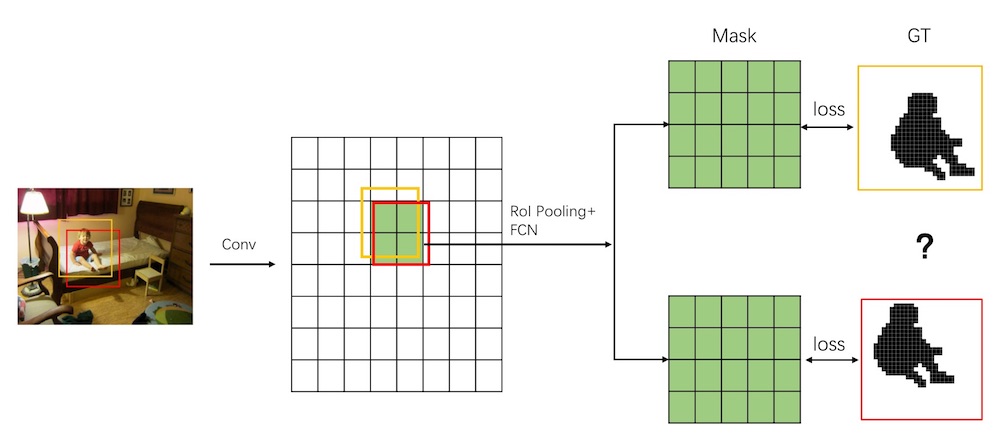
原图中的小男孩有两个 bounding box 框住他,我们用卷积操作对图像进行 downsample,然后根据 feature map 和原图的比例,推算出这两个 bounding box 对应在 feature map 上的位置和大小。结果,很不幸这两个框的位置四舍五入后刚好对应同一块 feature map。接着,RoI Pooling 和 FCN 会对这块 feature map 进行处理得到 mask,再根据 ground truth 计算 Loss。两个框对应的 ground truth 当然是不一样的。这个时候,网络就左右为难,同样一个 feature map,居然要拟合两个不同的结果,它左右为难一脸懵逼,直接导致模型无法收敛。
这就是所谓的 misalignment。问题的根源在于 bounding box 缩放时的取整。当然,RoI Pooling 本身在 pooling 的时候也是存在取整误差的。
既然问题出在取整上,那么,很自然想到的解决思路就是放弃取整,直接根据推算得到的浮点数来处理 bounding box。如此一来,bounding box 对应到的 feature map 上就会有一些点的坐标不是整数,于是,我们需要重新确定这些点的特征值。而这一步也是 RoI Align 的主要工作。其具体的做法是采用双线性插值,根据相邻 feature map 上的点来插值一个新的特征向量。如下图所示:

图中,我们先在 bounding box 中采样出几个点,然后用双线性插值计算出这几个点的向量,之后,再按照一般的 Pooling 操作得到一个固定大小的 feature map。具体的细节,之后开一篇新的文章介绍。
论文中通过 RoI Align 和 FCN 将 RoI 内对应的 feature map 处理成固定大小的 mask(\(K \times m \times m\),\(K\) 表示分割的类别数目),然后将该 mask 还原回原图后,就可以得到对应的分割掩码了。
Loss 的设计
在损失函数的设计方面,除了原本 Faster RCNN 中的分类损失和 bounding box 回归损失外,我们还需要针对 mask 分支设计一个分割任务的损失函数。最容易想到的函数自然是 FCN 和 UNet 中用到的 Softmax + Log 的多分类损失。如下图所示:
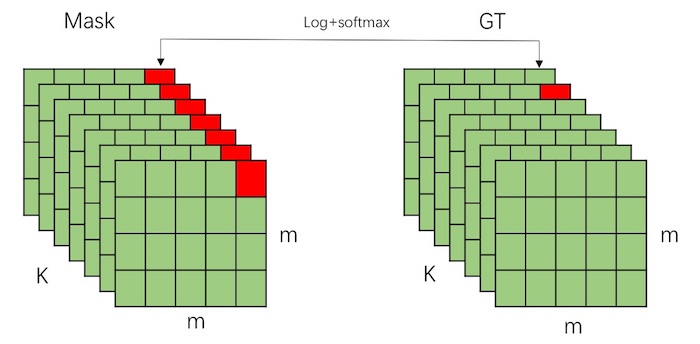
Mask 中的每个点都是一个 \(K\) 维的向量,我们把 ground truth 中对应的那个 mask 也缩放到 \(m \times m\) 大小,然后就可以针对每个点的向量做多分类损失。
不过,作者在做实验的时候估计是发现这种方式训练的网络收敛不好,进而发现这个损失函数会出现所谓的 class competition 的问题。
class competition,顾名思义,就是不同类别之间存在竞争关系,这种竞争关系直接导致的结果就是网络在训练过程中,回传的梯度存在前后不一致的地方。
打个比方,在 Faster RCNN 做 object detection 的时候,已经把某一块 RoI 识别为汽车,但这个 RoI 内可能存在其他物体的一部分,因此分割的 mask 中,除了要将汽车分割出来外,还要把另外那个物体也分割出来。这就导致这样的情况,在 object detection 的分支中,这块 RoI 整体被识别为汽车,但在 segmentation 的时候,这块 RoI 一部分被识别为汽车,一部分又要当作其他物体,如此一来,这两个分支回传到前面的梯度多少存在冲突,而前面的特征提取网络可是共享的,结果网络在学习的时候就可能出现左右为难的情况。不然,单纯从 Mask 分支来看,feature map 上每个点(包括 RoI Align 插值的点)本来就和 ground truth 是一一对应的,彼此之间又哪有 competition 之说呢?当然,以上只是我看论文时的想法,并没有做具体的实验,所以也不一定正确。
之后我又想,在 object detection 的时候,那些 bounding box 本身就是有重叠的,换句话说,RoI 之间也是有重叠的,如果两个 RoI 被识别为不同的物体,那么重叠那部分不也是冲突的吗?这个时候应该找个例子看看重叠那部分的特征图是什么样子的。不过,我个人的想法是,网络对这些重叠的区域可能会起到抑制作用。比如说,一辆汽车前面被一辆自行车挡着,那么汽车的 bounding box 多少会覆盖到自行车,而自行车的 bounding box 也多少包含了汽车的一部分,但这个交集相比各自的 bounding box 而言,可能不是主体作用,网络在对汽车的 RoI 做识别的时候,更多的会把注意力放在非重叠的那部分汽车上,而重叠那部分,虽然有一点点汽车的东西,但由于有自行车的遮挡,起到的作用不会太大。
最后需要声明一下,这个想法完全是我个人瞎猜的,并没有做实验证明.
既然多分类效果不好,那我们就尝试二分类。如下图所示:
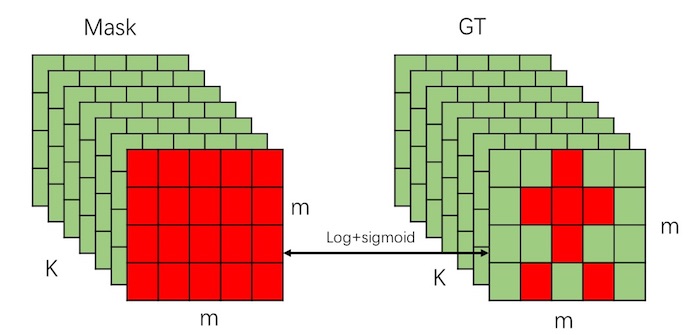
二分类的话,我们只考虑一种类别,比如,如果 ground truth 中标记了这个 bounding box 中是个人的话,那我们就只针对人的 mask 进行分割,而对这个 bounding box 中其他可能存在的物体一律忽视。上图中,假设人的类别是第 \(K\) 类,那么,我们就只在第 \(K\) 个 mask 上和 ground truth 中人的 mask 做 sigmoid 的二分类损失。如果某个点被标注是人的一部分,就识别为 1,否则全部识别为 0。
有同学可能会有疑惑,二分类只考虑一种物体,而把其他物体的部分直接忽略掉,如果出现一种极端情况,比如有一个人的一只手出现在一个汽车的 bounding box 中,然后网络计算这个人的 RoI 的时候,bounding box 刚好没有把这只手包含进来,而在汽车那个 RoI 里面又不会对这只手做分割,这样的话,这只手不就直接漏掉了吗?确实,这种情况下,这只手会被直接忽略。不过,这种情况属于 bounding box regression 没有做好,因此不在本文讨论范围内。
总结一下,损失函数可以表示为:
\(L_{cls}\) 和 \(L_{box}\) 是 Faster RCNN 中的损失函数,而 \(L_{mask}\) 则是 mask 分支中的 sigmoid 二分类损失。
特征提取
特征提取部分其实可以有多种选择,具体哪种选择好,可能要依据具体的任务来确定。论文尝试了 ResNet、FRN、ResNeXt 等网络。这一部分我没有去细究,因为这里变数比较大,针对不同的场景可以适当调整,因此这一块就不细谈了。
训练和预测
训练阶段依赖 Faster RCNN 的输出结果。首先根据 Faster RCNN 找出一大堆 RoI,再根据 classification score 对这些 RoI 进行排序,选出分类分数最高的前 \(N\) 个 RoI,然后根据 ground truth 中的 mask 和这个 RoI 取个交集,这个交集作为 \(L_{mask}\) 的 target。实际预测的时候,同样先根据 Faster RCNN 选出前 100 个分数最高的 RoI,然后计算每个 RoI 的 mask。不过,由于这些 mask 是根据二分类损失训练出来的,因此,我们要根据 Faster RCNN 提供的每个 RoI 的类别,在 mask 中找出对应的那一层作为最终分割的结果。
从这个训练过程也可以找出一些不足的地方。比如,挑选 RoI 送入 mask 分支那一步,这个挑选的结果完全依赖于 Faster RCNN 计算的分数,一旦 Faster RCNN 出了差错,给一些很重要的 RoI 打了很低的分,那么这些 RoI 就可能被忽略掉,之后分割就没它们什么事了。因此,有人提出了一些改进,认为应该对这个筛选的打分机制进行修改,不应该完全依赖于 Faster RCNN 的结果,比如,Mask Scoring RCNN 就在打分中加入了 ground truth 的 mask 的 IoU 分数,从而把那些容易被忽略的 RoI 找出来。这有点像是难样本挖掘了。
实验
何凯明在论文中一直强调 Mask RCNN 是 without bells and whistles,意思就是 Mask RCNN 的算法中没有什么花里胡哨的东西,都是实打实的干货,无需特殊的调参技巧,经得起时间的考验。为此论文中还提供了很多对比实验来一一验证每个模块的作用。
-
首先是 RoIAlign 和 RoIPooling 的对比:
![]()
在 instance segmentation 和 object detection 上都有不小的提升。如此看来,RoIAlign 其实就是一个更加精准的 RoIPooling,把前者放到 Faster RCNN 中,对结果的提升应该也会有帮助。
-
sigmoid 和 softmax 的对比
![]()
这里同样可以取得不小的提升。
-
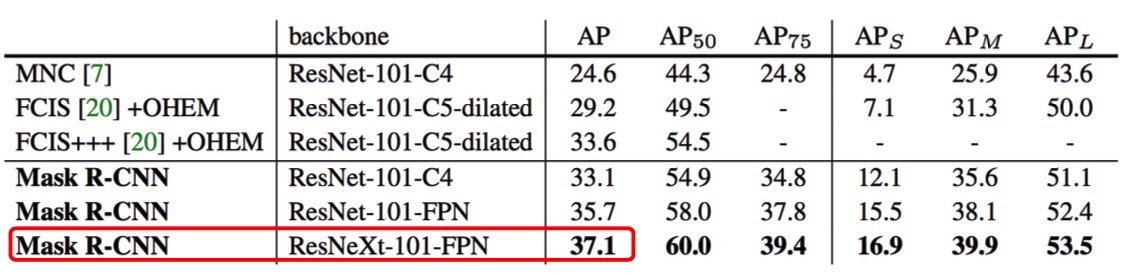
特征网络的选择
![]()
总体来说,加上 FPN 网络的效果会更好,可能因为 FPN 综合考虑了不同尺寸的 feature map 的信息,因此能够把握一些更精细的细节。
-
另外,论文还针对人体关键点检测做了一个实验,来体现 Mask RCNN 框架的通用性,这部分内容我还不太熟悉,就先略过了。


总结
总的来说,Mask RCNN 这种先检测物体,再分割的思路,简单直接,在建模上也更有利于网络的学习。而其中,我认为两个最重要的改进点,分别是 RoIAlign 和采用 sigmoid 二分类损失。这两个改进的目标都是让网络在学习的时候能保持一致性,使得输入到输出之间的映射关系更加简单直接。
参考
- 令人拍案称奇的Mask RCNN
- A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
- Mask RCNN tutorial
- Mask Scoring RCNN
- Mask RCNN
欢迎关注我的公众号「AI小男孩」,立志用大白话讲懂AI


 浙公网安备 33010602011771号
浙公网安备 33010602011771号